三维模型的智能驱动方法与流程
1.本技术的实施例涉及跨模态人工智能领域,尤其涉及三维模型的智能驱动方法。
背景技术:
2.从互联网到移动互联网,技术不断地与人们的生活发生各种各样的融合。互联网时代的商业模式的变化,是一个商业向消费者贴近,功能向终端贴近,数据向现场贴近的过程,是一个技术走向人的过程。
3.什么是下一代互联网,如何捕捉下一代互联网的创业方向,如何真正抵御gartner曲线穿越死亡谷的前沿创新,如何不依赖于下一代互联网不确定的时间性且伴随时间的推移持续积累、沉淀和创造价值;从上述维度出发,下一代互联网最重要的是体验的提升
‑‑
还原人类在现实世界中的四维时空体验,对时间、空间、效率和成本等多维度的改善和升级,即“升维”的互联网时代。
4.下一代“升维”的互联网最需要的是底层技术,其内容载体需要是智能化的、实时互动的和动态视觉化的(三维视觉呈现的),从ai角度理解为多模态智能交互,从cg角度理解为智能虚拟化技术。影视级科幻巨制在制作过程中都是通过专业设备捕捉真人的表情动作,映射为虚拟人物的表情及动作,用cg技术构建出逼真的场景和角色交互。但这些影视级的cg内容生产技术并不能实现消费化,如何让每个人都平等地拥有用cg视觉化语言表达创意和想象力的能力,是当前急需解决的问题。
技术实现要素:
5.根据本技术的实施例,提供了一种三维模型的智能驱动方案。
6.本技术提供了一种三维模型的智能驱动方法。该方法包括:
7.获取脚本文件;
8.将所述脚本文件输入至情感分析模型,得到与所述脚本文件对应的情感标签;
9.基于所述脚本文件和情感标签,生成有感情的语音;基于所述情感标签或所述语音,生成面部表情关键点;同时基于所述情感标签生成三维模型动作;
10.基于所述表情关键点、语音、三维模型动作和脚本文件,构建三维角色及其应用场景,驱动所述三维角色进行展示及互动。
11.进一步地,所述脚本文件包括已进行关联的图片、视频、语音和/或文本。
12.进一步地,所述获取脚本文件包括:
13.从多模态知识图谱中,获取所述脚本文件;所述多模态知识图谱中包括各类自然语言信息以及与其对应的物料信息;所述物料信息包括图片、视频和/或文字。
14.进一步地,所述情感分析模型通过如下方式进行训练:
15.生成训练样本集合,其中,训练样本包括带有标注信息的脚本文件;所述标注信息为情感标签;
16.利用所述训练样本集合中的样本对情感分析模型进行训练,以脚本文件作为输
入,以情感标签作为输出,当输出的情感标签与标注的情感标签的统一率满足预设阈值时,完成对基于语义理解的情感分析模型的训练。
17.进一步地,所述基于所述脚本文件和情感标签,生成有感情的语音包括:
18.基于所述脚本文件和情感标签,通过tts生成有感情的语音。
19.进一步地,所述基于所述表情关键点、语音和脚本文件,构建三维角色及其应用场景,驱动所述三维角色进行互动包括:
20.基于所述表情关键点,驱动三维角色的面部表情;
21.基于脚本文件,构建与所述三维角色对应的应用场景;
22.基于所述应用场景,通过多模态智能脚本及知识图谱驱动所述三维角色进行展示及互动。
23.进一步地,所述三维角色包括面部表情、口型、头部运动和肢体动作。
24.本技术实施例提供的三维模型的智能驱动方法,通过获取脚本文件;将所述脚本文件输入至情感分析模型,得到与所述脚本文件对应的情感标签;基于所述脚本文件和情感标签,生成有感情的语音;基于所述情感标签或所述语音,生成面部表情关键点;同时基于所述情感标签生成三维模型动作;基于所述表情关键点、语音、三维模型动作和脚本文件,构建三维角色及其应用场景,驱动所述三维角色进行展示及互动,丰富了交互形式,提升了用户体验。
25.应当理解,发明内容部分中所描述的内容并非旨在限定本技术的实施例的关键或重要特征,亦非用于限制本技术的范围。本技术的其它特征将通过以下的描述变得容易理解。
附图说明
26.结合附图并参考以下详细说明,本技术各实施例的上述和其他特征、优点及方面将变得更加明显。在附图中,相同或相似的附图标记表示相同或相似的元素,其中:
27.图1示出了本技术的实施例提供的方法所涉及的系统架构图。
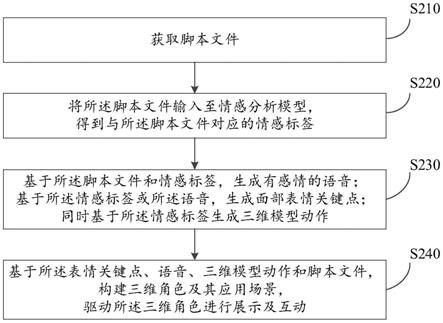
28.图2示出了根据本技术的实施例的三维模型的智能驱动方法的流程图;
具体实施方式
29.为使本公开实施例的目的、技术方案和优点更加清楚,下面将结合本公开实施例中的附图,对本公开实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本公开一部分实施例,而不是全部的实施例。基于本公开中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的全部其他实施例,都属于本公开保护的范围。
30.另外,本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。
31.图1示出了可以应用本技术的三维模型的智能驱动方法或三维模型的智能驱动装置的实施例的示例性系统架构100。
32.如图1所示,系统架构100可以包括终端设备101、102、103,网络104和服务器105。网络104用以在终端设备101、102、103和服务器105之间提供通信链路的介质。网络104可以
包括各种连接类型,例如有线、无线通信链路或者光纤电缆等等。
33.用户可以使用终端设备101、102、103通过网络104与服务器105交互,以接收或发送消息等。终端设备101、102、103上可以安装有各种通讯客户端应用,例如模型训练类应用、视频识别类应用、网页浏览器应用、社交平台软件等。
34.终端设备101、102、103可以是硬件,也可以是软件。当终端设备101、102、103为硬件时,可以是具有显示屏的各种电子设备,包括但不限于智能手机、平板电脑、智能电视、智能设备的显示屏、拼接大屏幕、全息投影设备及膝上型便携计算机和台式计算机等等。当终端设备101、102、103为软件时,可以安装在上述所列举的电子设备中。其可以实现成多个软件或软件模块(例如用来提供分布式服务的多个软件或软件模块),也可以实现成单个软件或软件模块。在此不做具体限定。
35.当终端设备101、102、103为硬件时,其上还可以安装有视频采集设备。视频采集设备可以是各种能实现采集视频功能的设备,如摄像头、传感器等等。用户可以利用终端设备101、102、103上的视频采集设备来采集视频。
36.服务器105可以是提供各种服务的服务器,例如对终端设备101、102、103上显示的数据处理的后台服务器。后台服务器可以对接收到的数据进行分析等处理,并可以将处理结果反馈给终端设备。
37.需要说明的是,服务器可以是硬件,也可以是软件。当服务器为硬件时,可以实现成多个服务器组成的分布式服务器集群,也可以实现成单个服务器。当服务器为软件时,可以实现成多个软件或软件模块(例如用来提供分布式服务的多个软件或软件模块),也可以实现成单个软件或软件模块。在此不做具体限定。
38.应该理解,图1中的终端设备、网络和服务器的数目仅仅是示意性的。根据实现需要,可以具有任意数目的终端设备、网络和服务器。特别地,在目标数据不需要从远程获取的情况下,上述系统架构可以不包括网络,而只包括终端设备或服务器。
39.如图2所示,是本技术实施例三维模型的智能驱动方法的流程图。从图2中可以看出,本实施例的三维模型的智能驱动方法,包括以下步骤:
40.s210,获取脚本文件。
41.在本实施例中,用于三维模型的智能驱动方法的执行主体(例如图1所示的服务器)可以通过有线方式或者无线连接的方式获取脚本文件。
42.进一步地,上述执行主体可以获取与之通信连接的电子设备(例如图1所示的终端设备)发送的脚本文件,也可以是预先存储于本地的脚本文件。
43.其中,所述脚本文件包括已进行关联的图片、视频、语音和/或文本,如,通过文本“场景介绍”可直接关联出与其相关的图片、视频和/或语音;关联方式包括,字符串关联、id关联、音频关联、视频关联等。
44.在一些实施例中,可从多模态知识图谱中,获取所述脚本文件;所述多模态知识图谱中包括各类自然语言信息以及与其对应的物料信息;所述自然语言信息包括与用户互动的交流信息等;所述物料信息包括与所述自然语言对应的图片、视频和/或文字等;
45.进一步地,所述自然语言信息包括国内外的各类自然语言(人类日常相互沟通所使用的语言)。
46.通常所述脚本文件是基于用户表达的交互信息进行获取的,如,接收到用户输入
的交互信息(语音和/或文字等)“a场景介绍”,则从所述多模态知识图谱中调取与其相关的脚本文件。
47.s220,将所述脚本文件输入至情感分析模型,得到与所述脚本文件对应的情感标签。
48.其中,所述情感标签,即,对人类情感进行的标定,如,喜、怒、哀、乐等。
49.在一些实施例中,所述情感分析模型,可通过如下步骤进行训练:
50.生成训练样本集合,其中,训练样本包括带有标注信息的脚本文件;所述标注信息为情感标签(根据实际应用场景进行设定,为一个或多个,通常为多个,例如27);
51.利用所述训练样本集合中的样本对情感分析模型进行训练,以脚本文件作为输入,以情感标签作为输出,当输出的情感标签与标注的情感标签的统一率满足预设阈值时,完成对情感分析模型的训练。
52.在一些实施例中,将所述脚本文件输入至上述训练完成的情感分析模型,得到与所述脚本文件对应的情感标签;
53.其中,与所述脚本文件对应的情感标签可以为多个,例如,对某一场景进行介绍时,根据不同的语境可以分别标注多个情感标签。
54.s230,基于所述脚本文件和情感标签,生成有感情的语音;基于所述情感标签或所述语音,生成面部表情关键点;同时基于所述情感标签生成三维模型动作。
55.在一些实施例中,基于所述脚本文件和步骤s220得到的情感标签,通过tts方法,生成有感情的语音,所述有感情的语音可以为多段带有不同和/或相同感情的语音。
56.在一些实施例中,根据所述情感标签,通过自研算法生成一组或多组面部表情关键点。
57.在一些实施例中,也可基于所述语音,通过多模态算法模型生成面部表情关键点;
58.具体地,将所述语音输入至多模态算法模型中,得到与其对应的面部表情关键点(头部关键点等);
59.所述多模态算法模型可通过如下方式进行训练:
60.生成训练样本集合,其中,训练样本包括带有标注信息的声音文件及对应表情动作的表情关键点;所述标注信息为语音文件及对应表情动作的表情、头部关键点;
61.利用所述训练样本集合中的样本对多模态模型进行训练,以带有标注信息的声音文件作为输入,以与其对应的表情、头部关键点作为输出,当输出的情感标签与标注的情感标签的统一率满足预设阈值时,完成对智能驱动模型的训练;
62.在一些实施例中,基于所述情感标签生成三维模型动作;
63.基于所述情感标签,从多模态知识图谱中获取与其对应的三维动作,如,通过情感标签“愤怒”,从多模态知识图谱中获取与其对应的一组或多组愤怒动作数据;
64.其中,为了提高后续构建的三维角色的拟人性,基于所述语音和/或情绪标签构建的面部表情关键点,和所述从多模态知识图谱中获取与其对应的三维动作,可存在一定的随机性;如,通过情绪“愤怒”可构建多组与其对应的面部表情,所述面部表情可以与不同的“愤怒”三维模型动作进行随机组合,避免了现有模型表情和动作过于单一的缺陷,大幅度提升了模型的拟人性,增强了互动体验。
65.s240,基于所述表情关键点、语音、三维模型表情、动作和脚本文件,构建三维角色
及其应用场景,驱动所述三维角色进行展示及互动。
66.在一些实施例中,基于所述表情关键点,通过自研算法构建三维角色的面部表情,所述面部表情和三维模型动作可以为多组,根据应用场景和播放语音(有感情的语音)的语境进行同步切换。
67.在一些实施例中,基于脚本文件,构建与所述三维角色对应的应用场景,所述应用场景包括图片、视频、三维场景及道具等物料信息;例如,进行场景介绍时,可跟随语音的播放节点,调取对应的多模态物料,使用户达到更好的互动体验;
68.其中,所述三维角色包括面部表情和肢体动作(如手势动作等),其肢体动作与表情和语音播放节点相对应,可通过自研引擎或第三方工具进行实时渲染;所述面部表情包括口型、眉眼、肌肉表情及头部运动等。
69.在一些实施例中,可使用多模态知识图谱驱动所述三维角色在适合的应用场景中与用户进行实时互动。
70.根据本技术的实施例,实现了以下技术效果:
71.通过从多模态知识图谱中获取的脚本文件,智能驱动具有感情的语音表达功能和多种情感表达能力(表情和肢体动作等)的三维模型,并基于脚本文件中已关联的图片、视频、语音和/或文本等信息,构建与所述三维模型对应的应用场景,使得智能驱动的三维角色具有高度拟人的特征(对应的表情、动作和有感情的语音),大幅提升了用户的交互体验。
72.所构建的智能虚拟形象从人控迭代到智控,不止可以由真人通过表情、手势和声音进行实时控制,实时驱动3d虚拟形象(ip)进行内容生产和交互,还可以基于自研算法和自研引擎实现形神合一的全智能,结合多模态知识库和知识图谱构建avatar数字形象的“思想和意识”,使其以活灵活现的表情动作、语音语调进行跨模态智能交互,7*24小时不间断服务,成为与真人优势互补的数字化身、替身和分身。
73.需要说明的是,对于前述的各方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本技术并不受所描述的动作顺序的限制,因为依据本技术,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于可选实施例,所涉及的动作和模块并不一定是本技术所必须的。
74.随着元宇宙(下一代互联网)、虚拟现实等浪潮迭起,行业拐点渐近。信息技术和网络技术的迭代改变了人们的生活方式,改变了商业的运行环境,改变了竞争的规则,逐渐成为改变世界的新基础设施,也带来了新的互联网商业浪潮,商业模式也随着互联网的发展而改变。
75.metaverse(元宇宙)中最重要的是“virtual beings”,即角色是至关重要的主体,相对于无机物、植物、动物而言人类是高等智能生命体,聚焦智能虚拟化技术(即ai+cg的融合),构建智能虚拟角色来作为数智世界中的参与主体avatar(化身/替身/分身),在下一代“升维”的互联网中处于核心地位。
76.真正的元宇宙世界中人也会像使用互联网一样不可能7*24小时实时在线,必然需要智能的分身(甚至不止一个)来实现效率的提升,这才是技术进步带来的真正价值:减少人类的重复性劳动,让人有更多时间聚焦在更有意义的事情上。技术可以帮助人类突破想象力和创意的边界,把原本需要专业设备支撑、昂贵的影视级cg技术消费化,以多模态、富
媒体、动态视觉化的表达和沟通方式,让现在的每家企业(合作伙伴)和未来的每个人都可以拥有“升维数智化”的能力来进行内容生产、实时互动以及企业级(个性化)数智资产的沉淀,实现人类超越时空、数智化永生的终极梦想。
[0077]“普罗透斯效应”这一心理研究表明,虚拟化身作为人类在虚拟世界中的理想化自己,是用户在虚拟世界中的个人呈现,能够以一系列不同的方式融入于生活中,让现实的人们变得更加积极健康。对人类社会正面的影响,必然会让虚拟化身在未来大受欢迎,并成为人类自我意识中不可或缺的一部分。未来,虚拟化身的展现风格和应用场景必然会更丰富,随着虚拟化身作为元宇宙必不可少的一部分,围绕虚拟化身的虚拟妆容美发、虚拟服饰造型、定制化虚拟物品等将会成为全新的产业,在这个过程中,虚拟世界或许会形成完整的经济体系并和现实世界连通。多模态智能虚拟数字形象将给人类提供的数字生活体验,可能是另一种人生的维度,一种可重启、可重置、脱离物理世界的生活方式,一种可以拥有“72变”的多维度生命体验和奇迹之旅
…
[0078]
目前在元宇宙、人工智能、虚拟现实等新技术浪潮的带动下,虚拟数字角色制作过程得到有效简化、各方面性能获得飞跃式提升,开始从外观的数字化逐渐深入到行为的交互化、思想的智能化。虚拟数字形象,是存在于数字世界中的“人”,通过动作捕捉、三维建模、语音合成、智能驱动等技术高度还原或模仿的数字存在,以虚拟主播、虚拟员工等为代表的数字人成功进入大众视野,并以多元的姿态在影视、游戏、传媒、文旅、金融和电商等众多领域大放异彩,而本专利进一步推动虚拟数字形象从人控场景进化为智控场景,最大程度的解放对人的依赖和限制,减少人的重复性劳动,智能虚拟角色即是企业级的智能数字资产,亦是每个人的智能数字资产,未来带来的想象空间和商业路径近乎拥有无限可能。
[0079]
本公开的技术手段,作为元宇宙中的底层构建能力和技术,可以解决现有新媒体时代的核心问题和痛点,以技术进步改变现有商业模式,推动生产力和生产效率的提升,亦为每家企业创造通往元宇宙时代的必然路径(智能数字资产即智能商业体),未来可以为每个人创造智能数字分身,给下一代互联网带来了巨大的希望和曙光。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1