一种基于深度学习的遥感图像语义分割方法
1.本发明属于计算机视觉领域,特别涉及一种适用于农业大数据的基于深度学习的遥感图像语义分割方法。
背景技术:
2.随着遥感技术的发展,遥感图像数据量越来越大,分辨率越来越高。遥感图像包含了大量的信息,因此遥感图像在环境评价、灾害评估、林业测量、精细农业、城市规划、地图的生产与更新、变化检测和军事目标识别等领域存在巨大的应用潜力。语义分割是一种像素级分类方法,他将每个像素标记为某种对象的标签,赋予每个像素类别意义。利用深度学习可以提取抽象特征,对复杂的场景有很好的解析能力,因此可以有效的提高遥感图像分割效果。
3.传统的卷积神经网络虽然可以挖掘都图像深层语义特征,实现图像级的分类,但是无法直接对图像每个像素进行语义识别,难以从像素层面分解出图像的不同类别。全卷积神经网络是用于语义分割最简单、最流行的架构之一。通常用于分类的卷积神经网络在若干个卷积层后会连接全连接层,全卷积神经网络的关键在于将全连接层转换成卷积层,并采用上采样操作,以产生预测图。
4.近年来,深度学习被广泛运用在计算机视觉领域,语义分割取得了一些成果,但仍面临着很多挑战,因为遥感图像包含大量的信息,在实际场景中以多尺度存在,并同时有光照、白云、阴影、遮挡等复杂场景,且不同场景下的样本也各不相同,相同种类的样本也有不同的信息特征,比如不同颜色的树木植被,建筑的顶色也各有不同。因拍摄角度或者时间的不同,比如太阳的不同角度会在图像上会形成阴影,给图像带来噪声。这些是目前进行语义分割精度较低的主要原因。遥感图像需要高质量的分割,分割效果仍有待提高,深度学习对复杂场景有很好的解析能力,减少遥感图像对专家知识的依赖,提高分类精度和识别效率,因此结合深度学习解决遥感图像分割问题具有现实的意义。常见的aspp模块位于编码器的末端,来提取多尺度的特征,但是在信息量较大的遥感图像中,这种操作不足以提取更多的特征,并且随着网络的深入导致目标的浅层特征丢失严重。因此即使普通的网络可以在一定程度上分割遥感图像,分割算法并没有得到很大改进。
技术实现要素:
5.为解决上述技术问题,本发明提供了一种基于深度学习的遥感图像语义分割方法,利用深度学习实验对遥感图像的语义分割,并对特征提取部分的网络进行优化,有效提取图像的多尺度特征,提高了分割的精确度。
6.为达到上述目的,本发明的技术方案如下:
7.一种基于深度学习的遥感图像语义分割方法,包括以下步骤:
8.(1)改进segnet网络模型,以segnet为骨干网络,增加两个空洞空间金字塔池化aspp模块;
9.(2)segnet编码阶段结合两个空洞空间金字塔池化aspp模块作为整个网络的编码器,形成多分支的训练网络;
10.(3)两个空洞空间金字塔池化aspp模块的输出特征图在解码器中进行相应的特征图拼接;
11.(4)完成整个网络的训练,保存最优的网络模型用于网络融合以获得更精确的分割效果。
12.进一步优选的,步骤(1)中空洞空间金字塔池化aspp模块的构建具体方法如下:
13.(1.3)构建四个不同空洞率r的n*n并行空洞卷积,设置步长和填充参数,得到相同大小的空洞特征图o
x,y
,对于输入的特征图i
x,y
,分别经过四个不同空洞率r的空洞卷积计算得到的四个空洞输出特征图得到的四个空洞输出特征图n为卷积核长度,w
u,v
为卷积核权重,b为偏差;x,y代表像素的位置,u,v代表卷积核中权重的位置,将四个不同的空洞卷积和一个全局平均池化并行组成空洞空间金字塔池化aspp模块,为匹配空洞卷积输出特征图的大小,全局平局池化操作后添加双线性插值操作;
14.(1.4)空洞空间金字塔池化aspp模块配置为两个,经过segnet的第一个卷积模块的得到的特征图为第一特征图,作为第一个空洞空间金字塔池化aspp模块中输入,经过segnet的第二个卷积模块的得到的特征图为第二特征图,作为第二个空洞空间金字塔池化aspp模块中输入。
15.进一步优选的,步骤(2)具体方法如下:
16.(2.1)segnet编码器包括五个卷积模块,前两个卷积模块中每个模块包含两个3
×
3卷积操作和一个池化操作,后三个卷积模块中每个模块包含三个3
×
3卷积操作和一个池化操作;
17.(2.2)在segnet编码器的第一个卷积模块后,建立第一个空洞空间金字塔池化aspp模块,在segnet编码器的第二个卷积模块后建立第二个空洞空间金字塔池化aspp模块,形成多分支并行训练网络;
18.(2.3)经过segnet的第一个卷积模块输出的第一特征图输入到第一个空洞空间金字塔池化aspp模块充分提取多尺度特征,将其5个并行输出的特征图进行拼接,得到第一拼接特征图,通过第一个空洞空间金字塔池化aspp模块自身的卷积进行卷积并降维,得到第一降维特征图;
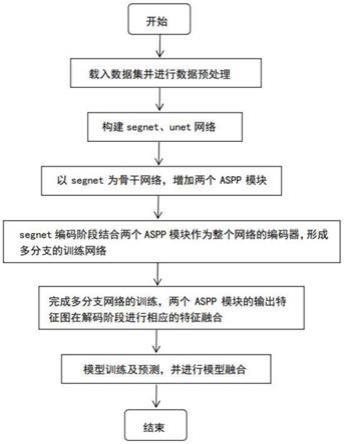
19.(2.4)经过segnet的第二个卷积模块,得到的第二特征图输入到第二个空洞空间金字塔池化aspp模块中,通过5个并行操作充分提取多尺度特征,将并行操作输出的特征图进行拼接,得到第二拼接特征图,通过第二个空洞空间金字塔池化aspp模块自身卷积降维得到第二降维特征图;
20.(2.5)segnet编码阶段的五个卷积模块和两个空洞空间金字塔池化aspp模块组成的多分支并行训练网络作为整个网络的编码器。
21.进一步优选的,步骤(3)中特征图拼接的具体方法如下:
22.(3.1)segnet解码器包含五个卷积模块,前三个卷积模块中每个模块包含三个3
×
3的卷积计算和一个2倍的上采样操作,前三个卷积模块分别输出第一上采样特征图、第二上采样特征图和第三上采样特征图,后两个卷积模块中每个模块包含两个3
×
3的卷积计算和一个2倍的上采样操作;
23.(3.2)第二个空洞空间金字塔池化aspp模块的输出第二降维特征图与segnet解码阶段中第三次上采样特征图进行拼接,经过卷积和上采样后,得到第四上采样特征图,第四上采样特征图与第一个空洞空间金字塔池化aspp模块的输出第一降维特征图进行拼接,经过卷积和上采样后,得到第五次上采样特征图。
24.进一步优选的,步骤(4)具体方法如下:
25.(4.1)经过步骤(2.5)整个网络的编码器、解码器的训练后,通过softmax层完成分类,设遥感图像分类为c,对于每个像素i{i=1,2,3,.....,n},真实类别标签为样本经过编解码器得到c维输出特征向量为使用softmax函数将特征向量中所有类别的线性预测值转换为概率值,则属于第c类的预测概率值为
26.(4.2)求得概率值后,使用交叉熵损失函数计算真实数据和预测值之间的loss值来量化两者之间的差距:n为像素总数,使用sgd优化算法进行模型训练;
27.(4.3)将该改进的segnet模型与segnet、unet网络模型采用投票法进行模型融合:使用三个模型进行预测分别得到预测图,对每张图的每个像素点进行投票,票数最多的类别即为该像素点的类别。
28.通过上述技术方案,本发明提供的一种适用于农业大数据的基于深度学习的遥感图像语义分割方法具有以下效果:
29.本发明考虑了改进segnet网络,在网络的前两个阶段引入空洞空间金字塔池化aspp模块,保证了图像的空间位置信息不会丢失严重并提取了不同训练阶段的多尺度特征,提高了分割精度。完成两个空洞空间金字塔池化aspp模块的训练后,在解码阶段进行相应的融合,有效的利用网络上下文的信息。空洞卷积在增大感受野的同时不丢失分辨率,且不需要引入额外的参数。对不同模型进行融合,采用投票机制有效的去掉一些分类错误的像素点,改善了模型的预测能力,可从复杂的背景中精准分割作物区域,对土地的有效利用,作物种植面积监测和提高作物的生产有重要意义。
附图说明
30.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。
31.图1为本发明实施例流程图;
32.图2为本发明实施例所公开的sgenet网络中引入aspp模块的示意图。
33.图3为本发明实施例所公开的空洞空间金字塔池化aspp模块示意图。
34.图4为unet网络模型。
35.图5为本发明实施例所公开的部分预测效果图。
具体实施方式
36.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
37.本发明提供了一种适用于农业大数据的基于深度学习的遥感图像语义分割方法,
如图1所示,具体实施例如下:
38.(1)数据预处理阶段:
39.(1.1)加载原始数据集,训练集为5张大尺寸且尺寸各不相同的遥感图像,测试集为3张大尺寸遥感图像;
40.(1.2)对训练集数据随机生成二维像素坐标,抠出该坐标下的256
×
256的小图;
41.(1.3)做数据增强操作,遥感图像和标签图都做旋转90
°
、180
°
、270
°
操作,遥感图像和标签图都做沿y轴镜像操作,原图做模糊操作,原图做光照调整操作,原图做增加噪声操作(高斯噪声、椒盐噪声);
42.(1.4)得到遥感图像和标签图各10000张的训练集。
43.(2)构建网络模型阶段:
44.(2.1)构建segnet模型,segnet模型为编解码结构,编码器中包含五个卷积模块(第一卷积模块输出第一特征图,第二卷积模块输出第二特征图,第三卷积模块输出第三特征图,第四卷积模块输出第四特征图,第五卷积模块输出第五特征图),每个卷积模块中包含多个3
×
3卷积、bn、relu及池化操作,最终编码器输出8
×8×
512的特征图;解码器也包括五个卷积模块,分别输出第一次上采样特征图、第二次上采样特征图、第三次上采样特征图、第四次上采样特征图和第五次上采样特征图,每个卷积模块包含多个3
×
3卷积、bn、relu及上采样操作,最终通过softmax层完成分类;
45.(2.2)图4所示,构建unet网络模型,unet模型为编解码结构,编码器中首先进行一次卷积操作,将输入数据转换为32维的特征图(256*256*32),然后重复采用两个卷积层和一个池化层的结构,输出16
×
16
×
512的特征图;解码器中每个模块与对应的编码器模块的特征图进行拼接,再重复做上采样和两个3
×
3卷积操作,最后通过softmax层完成分类;
46.(2.3)构建四个空洞率分别为1、6、12、18的3
×
3并行空洞卷积,卷积操作设置步长strides=1,填充padding=same,得到相同大小的空洞特征图o
x,y
,经过空洞率r=(1,6,12,18)的空洞卷积计算得到空洞输出特征图o
x,y
,,n为卷积核长度,w
u,v
为卷积核权重,b为偏差;x,y代表像素的位置,u,υ代表卷积核中权重的位置;四个空洞卷积及2
×
2的全局平均池化操作并行,组成空洞空间金字塔池化aspp模块,为匹配空洞卷积输出特征图的大小,全局平局池化操作后添加双线性插值操作;
47.(2.4)以segnet网络为骨干网络,在segnet编码器的第一个卷积模块后,建立第一个空洞空间金字塔池化aspp模块,在第二个卷积模块后建立第二个空洞空间金字塔池化aspp模块,形成多分支并行训练网络;图2所示,input(输入)256*256的特征图,经过segnet编码器的第一个卷积模块后的得到128*128*64的第一特征图,作为第一个空洞空间金字塔池化aspp模块的输入,第一个空洞空间金字塔池化aspp模块将5个并行操作的特征图进行拼接,得到第一拼接特征图128
×
128
×
320,通过1
×
1卷积进行卷积并降维,得到128
×
128
×
64第一降维特征图;128
×
128
×
64的第一特征图经过segnet编码器的第二个卷积模块后,得到64
×
64
×
128的第二特征图,将其作为第二个空洞空间金字塔池化aspp模块的输入,通过并行的空洞卷积及池化充分提取多尺度特征,第二个空洞空间金字塔池化aspp模块拼接得到64
×
64
×
320第二拼接特征图,通过1
×
1卷积降维得到64
×
64
×
64的第二降维特征图;
48.(2.5)完成两个空洞空间金字塔池化aspp模块的训练后,在解码阶段进行相应的
特征图融合;segnet解码器包含五个卷积模块,前三个卷积模块中每个模块包含三个3
×
3的卷积计算和一个2倍的上采样操作,后两个卷积模块中每个模块包含两个3
×
3的卷积计算和一个2倍的上采样操作,每个卷积操作都会增加bn结构和relu激活函数;解码阶段第一次上采样特征图的输入是编码阶段的第五特征图8
×8×
512,经过三个3
×
3的卷积计算和一个2倍的上采样操作得到第一次上采样特征图16
×
16
×
512,再经过三个3
×
3的卷积计算和一个2倍的上采样操作得到第二次上采样特征图32
×
32
×
512,再经过三个3
×
3的卷积计算和一个2倍的上采样操作得到第三次上采样特征图64
×
64
×
512,此时,第二个空洞空间金字塔池化aspp模块的输出64
×
64
×
64的第二降维特征图与segnet解码阶段中第三次上采样后的输出64*64*512特征图进行拼接,得到64
×
64
×
576的特征图,经过进行三个3
×
3的卷积计算和一个2倍的上采样操作得到第四次上采样输出128
×
128
×
256的特征图;第四次上采样后的输出128
×
128
×
256特征图与segnet解码阶段中的128
×
128
×
64第一降维特征图进行拼接,得到128
×
128
×
320的特征图,在进行两个3
×
3的卷积计算和一个2倍的上采样操作得到第五次上采样特征图256
×
256
×
128,经过五次上采样操作恢复图像大小后通过softmax层完成分类;
49.(3)训练阶段:
50.(3.1)首先将数据集分割成训练集和验证集,验证集的大小是训练集的0.25倍,训练集大小为7500张图片,验证集为2500张图片;
51.(3.2)设遥感图像分类为c,真实类别标签为yc,样本经过编解码器得到c维输出特征向量为oc,使用softmax函数将特征向量oc中所有所有类别的线性预测值转换为概率值,则属于第c类的预测概率值为
52.(3.3)求得概率值后,使用交叉熵损失函数计算真实数据和预测值之间的loss值来量化两者之间的差距:使用sgd、adma优化算法进行模型训练;
53.(3.4)对每个模型进行1000轮的训练,每一轮训练的批次大小为20,每一轮的训练保存最佳模型。
54.(4)预测阶段:
55.(4.1)加载训练好的网络模型,使用测试图片进行预测,对每个像素i,属于第c类的概率为pc(xi),计算该像素的类别标签ci,ci=argmaxpc(xi);
56.(4.2)预测得到mask图,因每类物体对应的像素值为0~4,都显示为黑色,像素值1为作物区域,像素值2为道路,3为建筑,4为水体,0是其他背景。可视化将作物区域标注为绿色,水体标注为蓝色,道路标注为棕色,建筑标注为黄色,其他背景为黑色。
57.(5)模型融合阶段:
58.(5.1)分别保存用三个模型进行预测得到的预测图;
59.(5.1)对每张预测图的每个像素点进行投票;
60.(5.2)少数服从多数的投票表决,票数最多的类别即为该像素点的类别。
61.对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明
将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1