用于机器学习的可训练差分隐私的制作方法
用于机器学习的可训练差分隐私
背景技术:
1.用于训练机器学习模型的大量数据的可用性推动了机器学习的最新发展。但是,在一些情况下,该数据包含需要保密的敏感个人信息。即使当机器学习模型的输出不包括训练数据时,在一些场景中,也有可能推断用于训练机器学习模型的数据中包含某些数据项。这种敏感信息的泄露被称为成员推理 (membership inference)。在内部模型参数可访问的情况下,诸如当模型存在于第三方计算设备上时,通过成员推理的敏感信息的泄露可能成为更大的可能性。
2.在一些情况下,可以使用差分隐私(differential privacy)匿名化训练数据,以便使成员推理更加困难。然而,可能难以确定用于差分隐私机制的、将保护训练数据的隐私的参数,并且同时在用匿名数据训练的机器学习模型中提供足够的效用水平。这通常是一个耗时且劳动密集的人工处理。
3.因此,在开发与训练机器学习模型结合使用的差分隐私机制的技术中还存在改进空间。
技术实现要素:
4.提供本发明内容为了以简化的形式介绍将在下面的详细描述中进一步描述的一些概念。本发明内容不旨在标识所要求保护的主题的关键特征或必要特征,也不旨在用于限制所要求保护的主题的范围。
5.在示例实施例中,计算机实现的方法包括训练机器学习模型,其中训练机器学习模型包括:使用差分隐私机制变换训练数据;使用变换的训练数据确定机器学习模型的分类器损失(classifier loss),其中分类器损失包括类别预测损失和成员推理损失;使用分类器损失更新机器学习模型的分类器;以及使用分类器损失更新差分隐私机制的置信度参数(confidence parameter)。
6.在另一示例实施例中,一种系统包括计算设备,该计算设备包括处理器和存储指令的存储器,当由处理器运行该指令时,使得计算设备执行操作,该操作包括:接收训练数据;使用差分隐私机制变换训练数据;使用变换的训练数据确定用于机器学习模型的分类器损失,其中分类器损失包括类别预测损失和成员推理损失;使用分类器损失更新机器学习模型的分类器;以及使用分类器损失更新差分隐私机制的置信度参数。
7.在另一示例实施例中,存储指令的一个或多个计算机可读存储介质,当由一个或多个处理器运行该指令时,使得一个或多个处理器执行操作,其中该操作包括训练机器学习模型,其中该机器学习模型包括神经网络,并且训练机器学习模型包括:使用差分隐私机制变换训练数据,其中差分隐私机制包括神经网络的层,并且变换训练数据包括将置信度参数与来自拉普拉斯分布(laplace distribution)的样本相组合;使用变换的训练数据确定机器学习模型的分类器损失,其中分类器损失包括类别预测损失和成员推理损失;使用分类器损失更新机器学习模型的分类器,其中分类器包括神经网络的另外一个或多个层;以及使用分类器损失更新差分隐私机制的置信度参数,其中更新包括执行神经网络的反向
传播(backpropagation)。
8.如本文所述,多个其他特征和优点可以根据需要并入技术中。
附图说明
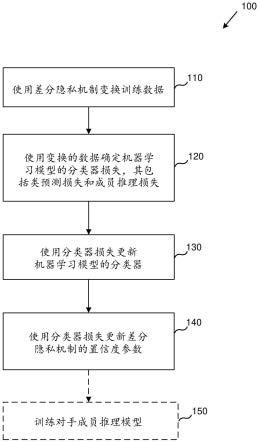
9.图1是用于使用差分隐私机制训练机器学习模型的示例方法的流程图。
10.图2是描绘用于使用差分隐私机制训练机器学习模型的示例系统的系统图。
11.图3是描绘用于使用差分隐私机制训练对手(adversary)成员推理模型的示例系统的系统图。
12.图4是描绘用于使用差分隐私机制和源预测(source prediction)训练机器学习模型的示例系统的系统图。
13.图5是描绘示例人工神经网络的图。
14.图6是描绘包括差分隐私机制和分类器的示例人工神经网络的图。
15.图7是示例计算系统的框图,可以在该示例计算系统中实现一些描述的实施例。
16.图8是可以结合本文描述的技术使用的示例云计算环境。
具体实施方式
17.示例1-概述
18.本文提供的描述针对用于将可训练差分隐私机制并入机器学习训练过程中的多种技术。
19.差分隐私技术可以用于防止成员推理攻击。在一些场景中,差分隐私机制已经被应用来防范尝试确定已经用于训练机器学习模型的数据集中特定记录的存在的成员推理攻击。然而,这种差分隐私机制的创建仍然是一个耗时的人工处理。
20.本文公开的至少一些实施例通过将可训练差分隐私机制并入机器学习训练过程中解决这些问题。可以使用包括可训练置信度参数的差分隐私机制来变换训练数据。变换的训练数据可用于使用机器学习模型生成类别预测。可以基于类别预测和用于训练数据的实际(actual)类别之间的差异确定类别预测损失。成员推理损失也可以基于变换的数据集中的示例记录是原始训练数据的实际成员的预测来确定。成员推理损失和类别预测损失可以被组合以生成分类器损失,该分类器损失可以用于更新机器学习模型和更新差分隐私机制的可训练置信度参数。训练可以重复多次,直到组合的分类器损失低于指定的阈值。例如,当已经花费了最小可能隐私预算(budget)以防范成员推理,同时仍然保持机器学习模型中期望的效用水平时,训练可以终止。
21.至少在一些场景中,将可训练差分隐私机制并入机器学习训练过程中可以导致机器学习任务的最大效用和最大隐私,而不需要对差分隐私机制人工调整(human tuning)。至少在一些情况下,这可以导致时间和精力的显著减少,同时也确保机器学习模型的最优效用和隐私特性。
22.示例2-示例差分隐私机制
23.在本文描述的任何示例中,差分隐私机制是这样的机制:将给定数据集变换成与给定数据集充分不同的另一数据集以满足隐私要求,同时包含与给定数据集充分相似度以使其成为处理和分析的可接受代替。差分隐私定义了对数据的处理的约束,使得两个数据
集的输出大约相同,同时确保对给定数据集的单个记录的添加不会使其与没有该记录的数据集是可区分的。
24.更正式地说,如果对于最多在一个元素上不同的所有数据库x1和x2,并且所有pr[m(x1)∈s]≤exp(ε)
×
pr[m(x2)∈s] +δ,其中ε是置信度参数,其也可以称为隐私预算,以及δ是小于数据库的大小中的任何多项式的倒数的值,则随机化算法m给定(ε,δ)-差分隐私。随着置信度参数ε降低,差分隐私机制的输出变得更加隐私。然而,ε的该降低可能伴随着变换数据集作为原始数据集的分析等效物的适用性的降低。
[0025]
示例3-示例成员推理
[0026]
在本文描述的任何示例中,成员推理包括尝试确定给定记录是否是用于训练机器学习模型的数据集的一部分。
[0027]
成员推理过程尝试评估(evaluate):当输入样本是训练集的一部分,而不是作为来自相同总体集合(population)的一部分的一组非训练数据时,机器学习模型表现不同的程度。为了确定记录是否是训练集的一部分,可以使用成员推理过程评估模型是否将训练数据的隐私置于危险之中。有两类成员推理过程:黑盒和白盒。黑盒推理是指成员推理过程只能访问到机器学习模型的输入和机器学习模型的输出的场景。相对地,白盒推理是指除了输入和输出之外,成员推理过程还可以访问机器学习模型的内部特征(例如观察到的损失、梯度和学习权重)时的情况。
[0028]
对抗训练过程可以用来提高模型对成员推理攻击的保护。两个机器学习模型(诸如两个神经网络)可以以对抗的方式进行训练。第一机器学习模型可以简单地称为机器学习模型,以及第二机器学习模型可以称为对手。可以确定成员推理损失,其量化对手在基于机器学习模型的输入和输出执行成员推理预测中的有效性。在每次训练迭代中,为了最小化对手的成员推理损失项的目标,可以更新机器学习模型的权重而对手的权重保持固定。随后,为了最大化成员推理的准确度(accuracy)的目标,可以更新对手的权重而机器学习模型的权重保持固定。该训练过程可以产生一个收敛到纳什均衡(nashequilibrium)的最小最大博弈(minmax game),其中,对于给定的数据集,机器学习模型针对最佳可能对手提供了最高的隐私可能级别。
[0029]
虽然成员推理隐私在黑盒成员推理攻击(诸如针对机器学习即服务 (machine learning as a service)平台的攻击)的情况下可能是有效的,但是它在保护机器学习模型免受白盒攻击方面可能不太有效。此外,训练过程提供的隐私没有正式保证。因此,成员推理隐私缺乏差分隐私提供的正式保证。通过包含差分隐私,模型可以防止黑盒和白盒成员推理攻击二者,还可以提供防止攻击者(attacker)中毒攻击(poisoning)训练数据的一些防御措施。
[0030]
示例4-用于机器学习的可训练差分隐私的示例系统和方法
[0031]
本文描述的任何例子中,系统和方法可以被提供用于机器学习的可训练差分隐私。
[0032]
图1是使用差分隐私机制训练机器学习模型的示例方法100的流程图。本文描述的任何示例系统可以用于执行示例方法100的全部或部分。例如,图2中描绘的示例系统200可以用于执行示例方法100的全部或部分。
[0033]
图2是描绘用于使用差分隐私机制训练机器学习模型的示例系统200的系统图。示
例系统200包括计算设备210。计算设备210可以包括一个或多个处理器以及一个或多个存储指令的存储器,当由一个或多个处理器运行该指令时,使得计算设备210执行本文描述的操作。附加地或替代地,计算设备可以包括一个或多个硬件组件(诸如专用集成电路(asic)、现场可编程门阵列(fpga)等)被配置为执行本文描述的操作的全部或部分。
[0034]
在110,使用差分隐私机制变换训练数据。例如,计算设备210可以接收训练数据221,并且可以使用差分隐私机制230对其进行变换。差分隐私机制230可以包括置信度参数231。变换训练数据可以包括将置信度参数231与来自分布(诸如固定分布)的一个或多个样本相组合。可以执行置信度参数 231和来自分布的样本的组合,以便产生等同于从不可微(non-differentiable) 分布(诸如随机变量)的采样的结果。然而,与不可微分布不同,置信度参数 231可以作为机器学习过程的一部分被训练。将置信参数231和来自分布(诸如固定分布)的样本的组合替换为来自不可微分布的样本可称为重新参数化 (reparameterization)。
[0035]
重新参数化的示例方法包括置信度参数231与来自“位置-尺度(location
‑ꢀ
scale)”分布族的分布的样本的组合。在特定实施例中,该分布包括拉普拉斯分布。在这样的实施例中,差分隐私机制230可以包括用于局部差分隐私的拉普拉斯机制。拉普拉斯机制可以包括从拉普拉斯分布中提取的尺度化噪声 (scaled noise),其中位置参数等于0并且尺度参数等于δf/ε的,其中ε是置信度参数(例如,231),并且δf是函数f的l2敏感度(sensitivity),定义为:
[0036]
δf=max
d,d
′ ||f(d)-f(d
′
)||,
ꢀꢀ
(1)
[0037]
其中d和d’是最多相差一个元素的数据库。置信度参数ε可以是可训练的变量。例如,ε可以用梯度下降迭代调整(tune),诸如通过反向传播成员推理损失项。例如,置信度参数ε可以经由重新参数化在拉普拉斯机制的情况下变得可训练:
[0038][0039]
其中lap(0,δf/ε)代表具有位置参数等于0和尺度参数等于δf/ε的拉普拉斯分布,z表示来自上述分布的样本,以及ζ表示来自具有算术平均值(mean) 等于0和方差等于1的拉普拉斯分布的样本。
[0040]
在120,使用变换的训练数据确定机器学习模型的分类器损失,其中分类器损失包括类别预测损失和成员推理损失。例如,计算设备210可以使用由差分隐私机制230生成的变换的训练数据确定机器学习模型240的分类器损失250。可以使用成员推理损失251和类别预测损失253生成分类器损失 250。
[0041]
至少在一些实施例中,机器学习模型240可以包括神经网络。在这样的实施例中,差分隐私机制可以包括神经网络的层(诸如神经网络的初始层)。
[0042]
变换的训练数据可以被提供给机器学习模型240的分类器241,以产生对变换的训练数据的类别预测。训练数据221的实际类别可以与预测的类别组合使用,以产生类别预测损失253。至少在一些实施例中,类别预测可以包括与训练数据221可能属于的可能类别(并且其中之一是训练数据221的实际类别)相关联的预测概率的向量。在不同或进一步的实施例中,可以使用关于由分类器241产生的类别预测和对训练数据221的实际类别的分类交叉熵(categorical cross entropy)确定类别预测损失253。
[0043]
成员推理损失251指示成员推理攻击的脆弱性水平。在至少在一些实施例中,对手260可以用于生成成员推理损失251。例如,变换的训练数据、由分类器241生成的类别预测以及对于训练数据的实际类别可以被提供给对手 260。基于变换的训练数据和预测的类别,对手可以生成提供的数据中的给定记录是训练数据221的成员的预测(或推理)。结合给定记录的实际成员,可以使用该预测生成成员推理损失251。至少在一些实施例中,对手可以包括对手推理模型,该模型可以用于为变换的训练数据中的记录生成成员预测。对手推理模型可以包括机器学习模型,诸如神经网络。在不同或进一步的实施例中,生成成员推理损失251可以包括计算变换的训练数据中的记录是训练数据221的成员的对数概率的总和。通过基于类别预测损失253和成员推理损失251,分类器损失250可以表示分类准确度(由类别预测损失表示)和差分隐私(由成员推理损失表示)的平衡。
[0044]
在130,使用分类器损失更新机器学习模型的分类器。例如,可以使用分类器损失250更新机器学习模型240的分类器241。在机器学习模型包括神经网络的实施例中,使用分类器损失250更新分类器241可以包括更新神经网络的一个层或多个层中的节点的权重。使用分类器损失更新权重可以作为反向传播操作的一部分执行。
[0045]
在140,使用分类器损失更新差分隐私机制的置信度参数。例如,可以使用分类器损失250更新差分隐私机制230的置信度参数231。在差分隐私机制230包括神经网络层的实施例中,更新置信度参数231可以包括更新置信度参数作为神经网络的反向传播的一部分。
[0046]
至少在一些实施例中,分类器和差分隐私机制的置信度参数的训练和更新可以重复多次,直到分类器损失小于指定的阈值,或者直到已经执行了指定的最大迭代次数。因此,至少在一些情况下,训练过程可以收敛于差分隐私机制和分类器,其表示分类准确度和防止成员推理攻击之间的期望平衡。
[0047]
示例5-示例对手成员推理模型训练
[0048]
在本文描述的任何示例中,可以提供系统和方法用于训练成员推理模型,供使用于执行成员推理预测。
[0049]
例如,方法100可以可选地包括训练对手(诸如图2中描绘的对手260) 的成员推理模型。本文描述的任何示例系统都可以用于执行成员推理模型的训练。例如,图3所描绘的系统300可以用于执行这种训练。
[0050]
图3是描绘用于使用差分隐私机制331训练对手成员推理模型361的示例系统300的系统图。计算设备310可以包括硬件(以及可选地软件组件) 被配置为执行用于训练对手360的成员推理模型361的操作。对手成员推理模型361可以使用机器学习模型340的分类器341的预测输出来训练。
[0051]
训练过程可以重复多次,直到对手损失370低于指定阈值或者已经执行了最大迭代次数。在成员推理模型361已经被训练之后,其可以被对手360 使用以提供成员预测,作为机器学习模型340的训练的一部分,如本文所述。
[0052]
至少在一些实施例中,训练对手成员推理模型361包括使用差分隐私机制331变换训练数据321,并使用变换的训练数据以使用机器学习模型340的分类器341生成类别预测。对手360可以基于分类器341对变换的训练数据输出的类别预测确定第一成员推理损失351。
[0053]
然后可以基于分类器341对测试数据集的类别预测输出确定第二成员推理损失
353。测试数据集323可以是在其被提供给分类器341之前没有被差分隐私机制变换的数据集。至少在一些实施例中,训练数据321和测试数据 323可以是来自相同样本总体的不相交数据集。
[0054]
第一成员推理损失351可以基于对手360使用成员推理模型361的预测的准确度(变换的训练数据中的记录是训练数据321的成员)来确定。可以对测试数据323执行类似的过程,以确定第二成员推理损失353。对手损失 370可以基于第一成员推理损失351和第二成员推理损失353的组合确定。在特定实施例中,对手损失370包括第一成员推理损失351和第二成员推理损失353的平均数(average)。
[0055]
然后,可以使用对手损失370更新成员推理模型361。在成员推理模型 361包括神经网络的实施例中,更新成员推理模型361可以包括通过诸如反向传播的技术使用对手损失370更新神经网络的权重。
[0056]
示例6-用于使用源预测的可训练差分隐私的示例系统和方法
[0057]
在本文描述的任何示例中,可以提供生成器(generator)用于生成由机器学习模型使用以预测伪造数据(fake data)的源的伪造数据。基于由机器学习模型做出的源预测的源预测损失可以用作分类器损失(也称为判别器 (discriminator)损失)的基础。
[0058]
可以生成伪造数据和相关联的类别标签(label),并将其作为输入提供到机器学习模型。机器学习模型可以被配置成基于数据和相关联的标签做出源预测,其中源预测指示数据是真实的(authentic)还是伪造的。可以基于伪造数据和相关联的类别标签确定源预测损失。这种源预测损失可以表示机器学习模型的源预测的准确度。
[0059]
至少在一些实施例中,可以使用生成对抗网络(generative adversarialnetwork)来生成伪造数据。在这样的实施例中,可以使用源预测损失和也由机器学习模型生成的类别预测损失的组合确定生成器损失。生成对抗神经网络可以使用生成器损失进行更新。例如,可以使用诸如反向传播的技术使用生成器损失更新生成对抗神经网络的权重。
[0060]
图4是描绘用于使用差分隐私机制431和源预测来训练机器学习模型450的示例系统400的系统图。示例系统400包括计算设备410,该计算设备 410包括被配置为执行本文描述的操作的硬件(以及可选地包括软件)组件。
[0061]
可以由包括可训练置信度参数431的差分隐私机制431来接收和变换训练数据421。机器学习模型440的分类器441可以使用变换的训练数据生成类别预测。变换的训练数据的类别预测和实际类别可用于生成类别预测损失 453。
[0062]
类别预测、变换的数据和实际类别也可以用于生成成员预测,该成员预测指示变换的训练数据中的记录是否是训练数据421的成员。可以基于这些预测的准确度生成成员推理损失451。至少在一些实施例中,对手460可用于生成如本文所述的成员推理损失。
[0063]
机器学习模型440还可以做出指示记录是真实的还是伪造的源预测。可以向机器学习模型440提供伪造数据,以便训练机器学习模型的该方面。可以基于源预测的准确度确定源预测损失455。至少在一些实施例中,伪造数据和相关联的类别标签可以由生成器470生成。至少在一些实施例中,生成器 470可以使用随机噪声的采样生成伪造数据。在不同或进一步的实施例中,生成器470可以包括机器学习模型,诸如神经网络。在一些这样的实施例中,生成器470和机器学习模型440可以组成生成对抗网络。源预测损失455和类别预测损失453可用于创建可用于训练生成器470的生成器损失480。例如,生成器损失480可以用于
通过诸如反向传播的技术更新生成器机器学习模型的权重。
[0064]
至少在一些实施例中,生成器470不能访问变换的训练数据,并且仅基于源预测损失455和类别预测损失453被训练。训练完成后,生成器能够产成新的匿名数据,至少在一些情况下,该匿名数据可以在不担心数据的隐私的情况下被发布。
[0065]
示例7-示例生成对抗网络
[0066]
在本文描述的任何示例中,生成对抗网络可以与可训练差分隐私机制一起使用,以生成差分隐私数据。
[0067]
生成对抗网络(gan)在被提供有训练数据集时,可以生成看起来来自与训练数据集中的记录相同的总体(population)的伪造数据。它由两个不同的神经网络组成:生成伪造记录的生成器神经网络和尝试确定给定记录是真实的还是伪造的判别器神经网络。这两种神经网络的架构因应用而异。至少在一些实施例中,生成器和判别器中的一个或两个可以包括深度神经网络。可以使用损失函数训练生成器和判别器,例如通过使用损失函数确定预测的准确度,并且通过将源预测损失反向传播到参数并且更新生成器和判别器中的一个或两个的参数权重。
[0068]
生成器可以提供从随机噪声到新数据样本的映射,该新数据样本看起来来自与真实的样本相同的潜在分布(underlying distribution)。判别器可以尝试通过估计给定样本来自训练数据而不是生成器的概率来区分生成的样本和真实的样本。通过以对抗的方式训练这些网络,在每次训练的迭代中,生成器可以更好地产生真实样本(realistic samples),而判别器可以更好地从生成的数据中区分真实的数据。这两个网络因此相互竞争。
[0069]
示例8-示例机器学习模型
[0070]
在本文描述的任何示例中,机器学习模型包括由机器学习过程生成的一个或多个数据结构。机器学习过程可以包括监督学习过程、无监督学习过程、半监督学习过程或其某种组合。示例机器学习模型包括人工神经网络、决策树、支持向量机等。机器学习模型可以通过使用机器学习过程来处理训练记录以生成。训练记录可以包括一个或多个输入字段(有时称为自变量)和一个或多个输出字段(有时称为因变量)。机器学习模型可以包括由机器学习过程基于训练记录来泛化(generalized)的一个或多个关系的表示 (representation)。在确定多个数据有效载荷适合于训练机器学习模型的情况下,多个数据有效载荷的全部或部分可以用作训练记录以训练机器学习模型。至少在一些情况下,可能有必要将多个数据有效载荷转换成可以由机器学习算法处理的另一种数据格式。
[0071]
在本文描述的任何示例中,机器学习模型、对手成员推理模型和生成器可以包括人工神经网络。
[0072]
人工神经网络包括多个人工神经元(也称为感知器或节点),该人工神经元可以被配置为接收输入,将输入与内部状态(有时称为激活)相结合,并产生输出。至少在一些实施例中,神经元可以与激活阈值相关联,该激活阈值将神经元的激活限制在给定激活值上升到给定阈值之上(或下降到给定阈值之下)的场景。人工神经网络的初始输入可以包括一个或多个数据值。示例输入可以包括图像、文档、数据阵列等的数字表示。人工神经网络的最终输出包括表示结果的一个或多个值。至少在一些实施例中,可以提供激活函数,该激活函数在输入值改变时提供平滑过渡(例如,输入中的小改变产生输出中的小改变)。
[0073]
人工神经网络包括边(edge)(也称为连接(connection))。边连接两个神经元,并且具有方向,其将神经元中的一个标识为输出神经以及另一神经元标识为输入神经元。如果输出神经元的激活函数生成一个值,该值作为输入神经元的输入值被提供。边可以与表示边的相对重要性的权重值相关联。在这样的实施例中,在输出神经元的输出值被提供给输入神经元之前,可以使用权重值修改输出神经元的输出值。给定的神经元可以具有多个输入和/或输出边。
[0074]
至少在一些人工神经网络中,神经元被组织成多个层。一个层的神经元可以连接到紧接地前层(immediately preceding layer)或紧接地后层 (immediately following layer)的神经元。接收外部数据作为输入值的层可以称为输入层。产生最终结果的层可以称为输出层。输入层和输出层之间可以存在神经元的零个或多个层。这些层可以称为隐藏层。然而,单个层和无分层(unlayered)网络也是可能的。可以使用多种连接模式将一个层的神经元连接到另一个层的神经元。例如,两个层的神经元可以完全连接,意味着一个层中的每个神经元都有边将其连接到下一个层中的每个神经元。在另一个示例中,可以使用连接池,其中一个层中的一组神经元都具有连接到下一个层中的单个神经元的边。在这样的实施例中,可以减少下一个层中的神经元的数量,从而将来自前层中的较大量神经元的输出集中到后层中的较少量神经元中。具有这种连接的神经元形成有向无环图,并可以称为前馈网络 (feedforward network)。替代地,网络可以允许相同层中节点之间的边和/或来自一个层中的神经元的边返回到前层中的神经元的边。这种网络可以称为循环网络。
[0075]
人工神经网络可以通过基于样本观察来调整(adapting)人工神经网络训练。训练可以包括调节边的权重(和/或可选的神经元激活阈值)以提高由人工神经网络生成的结果的准确度。这可以通过尝试最小化观察到的误差实现。这些观察到的误差可以称为损失。多种技术(诸如反向传播)可以用来调节边的权重。权重调节的示例方法包括梯度下降。至少在某些情况下,当检查额外的观察没有有效地降低人工神经网络的误差率(或损失)时,可以认为训练完成。然而,即使在初始训练阶段之后,如果新的结果和相关联的准确度值使得人工神经网络的误差率低于给定的阈值,学习仍然可以继续。
[0076]
至少在一些实施例中,可以基于反馈来调节权重。附加地或替代地,额外的输入层节点和/或附加隐藏层节点可以被添加到人工神经网络中,以尝试响应于反馈提高准确度。
[0077]
可以从一个或多个客户端计算设备接收反馈数据。例如,反馈数据可以识别被正确识别为成功和/或失败的测试场景和/或被错误识别为成功和/或失败的测试场景。如果反馈数据中的错误使得人工神经网络的误差率下降到可接受阈值以下,则计算设备可以使用反馈数据(以及可选地初始训练数据的全部或部分)以重新训练人工神经网络;从而生成更新的人工神经网络。
[0078]
多种训练模式都是可能的。至少在一些实施例中,每个输入创建一个或多个权重(和/或一个或多个激活阈值),其用于调整从一个神经元传输到另一个神经元的值。例如,在输入层神经元与数据有效载荷字段值相关联的实施例中,权重可用于改变提供给网络的后续层中的连接神经元的值。
[0079]
附加地或替代地,权重(和/或激活阈值)可以基于批次(batch)输入。至少在某些情况下,随机学习模式(stochastic learning modes)会引入噪声。例如,通过使用从一个数据点计算的局部梯度,可以减少人工神经网络将陷入局部最小值的机会。然而,批次学习
模式可以产生更快、更稳定的下降至局部最小值,因为每次更新可以在批次的平均误差的方向上执行。至少在一些实施例中,可以使用两种学习模式的组合。
[0080]
图5是描绘示例人工神经网络500的图。人工神经网络500可以包括多层感知器神经网络。神经网络500可以具有输入层561、一个或多个隐藏层 562、563和输出层564。每一层可以有一个或多个节点(或感知器)。至少在一些实施例中,每一层的节点数量跨层是相同的。因此,输入层561可以具有输入节点561a、561b至561n。类似地,隐藏层1 562至隐藏层n 563,隐藏层1 562可以具有节点562a、562b至562n等,隐藏层n 563可以具有节点 563a、563b至563n。输出层564可以具有节点564a、564b至564n。然而,具有不同数量的节点的层也是可能的。节点可以具有一个或多个参数、权重、系数或其他值,以及用于至该节点的多个输入的一个或多个函数。
[0081]
人工神经网络500的节点可以通过具有相关联的权重(例如,571a-571m 和577a-577m)的边连接。为了清楚起见,没有为图5中描绘的每个边描绘权重。权重可用于修改给定节点的输出值。然后,修改后的值可以作为输入提供给另一个节点。例如,在修改后的值被提供给节点562a作为输入之前,可以使用权重571a修改节点561a的输出。
[0082]
输入层561可以接受到神经网络500的输入向量,并且可以开始神经网络处理。(虽然神经网络在这里被称为开始“处理”,但是至少在一些实施例中,人工神经网络500包括神经网络的数据结构表示,并且相关联的可运行代码包含用于通过神经网络执行输入值的处理并产生输出值的指令。)在一些实施例中,输入层561不处理输入向量,除了对将由人工神经网络500可用的输入向量所必要的任何预处理(preprocessing)。在其他实施例中,类似于隐藏层562、563,输入层561可以使用每个节点处的函数和参数开始处理输入向量。
[0083]
每一层的输出可以是该层中各个节点的输出。此外,给定层的节点可以接受前层的一个或多个节点的输出作为输入。例如,输入节点561a的输出可以是到隐藏层1 562中的一个或多个节点的输入,以此类推对于每一连续层中的所有节点。输出层564可以包含对于给定输入值在其节点564a、564b至 564n上汇聚的最后输出值。以这种方式,人工神经网络500可以用于通过其各个层561、562、563、564、它们各自的节点561a-n、562a-n、563a-n、564a
‑ꢀ
n以及它们各自的参数和函数处理输入向量。在一些实施例中,层561、562、 563、564可以具有不同数量的节点,而在其他实施例中,层可以具有相同数量的节点。
[0084]
图6是描绘包括人工神经网络的示例系统600的图,该人工神经网络包括差分隐私机制和分类器。人工神经网络包括从训练数据集接收输入向量的节点661a-n的差分隐私层661,并使用包括可训练置信度参数671的差分隐私机制变换输入向量。差分隐私机制可以包括置信度参数671和来自本文描述的可微分布的样本的组合。人工神经网络还包括包含节点662a-n
–
663a-n 的一个或多个分类器层662-663以及基于变换的输入向量产生类别预测611 的输出层664。尽管输出层664在图6中被描绘为包括单个节点664a,但是其他配置也是可能的。例如,输出层664可以包括多个输出节点,该输出节点产生多个类别中成员的预测(诸如产生给定输入向量是n个不同类别的成员的n个概率的n个输出节点)。
[0085]
与输入向量相关联的类别预测611和实际类别613可用于产生反映预测准确度的类别预测损失621。类别预测损失621可以与成员推理损失651相组合,以产生如本文所述的分类器损失631。例如,输入向量、类别预测611 和实际类别613可以被提供给生成成员推理损失651的对手。
[0086]
然后,分类器损失631可用于更新一个或多个分类器层662-663中的分类器权重641,并更新置信度参数671。更新后的置信度参数和权重可用于后续的训练迭代。
[0087]
示例9-示例计算系统
[0088]
图7描绘了合适的计算系统700的泛化示例,在该计算系统700中可以实现所描述的创新。例如,计算系统700可以用作本文描述的计算设备。计算系统700不旨在对使用范围或功能提出任何限制,因为创新可以在不同的通用或专用计算系统中实现。
[0089]
参考图7,计算系统700包括一个或多个处理单元710、715和存储器 720、725。在图7中,基本配置730包括在虚线内。处理单元710、715运行计算机可运行指令。处理单元可以是通用中央处理单元(cpu)、专用集成电路(asic)中的处理器或任何其他类型的处理器。在多处理系统中,多个处理单元运行计算机可运行指令以增加处理能力。例如,图7示出了中央处理单元710以及图形处理单元或协处理单元715。有形存储器720、725可以是易失性存储器(例如,寄存器、高速缓存、ram)、非易失性存储器(例如, rom、eeprom、闪存、固态驱动器等),或两者的某种组合,可由(多个) 处理单元访问。存储器720、725可以以适于由(多个)处理单元运行的计算机可运行指令的形式存储实现本文描述的一个或多个创新的软件780。
[0090]
计算系统可以具有附加特征。例如,计算系统700包括储存器740、一个或多个输入设备750、一个或多个输出设备760以及一个或多个通信连接 770。诸如总线、控制器或网络的互连机制(未示出)互连计算系统700的组件。通常,操作系统软件(未示出)为在计算系统700中运行的其他软件提供操作环境,并协调计算系统700的组件的活动。
[0091]
有形储存器740可以是可移动的或不可移动的,并且包括磁盘、磁带或盒式磁带、固态驱动器、cd-rom、dvd或任何其他可用于以非暂时性方式存储信息并且可在计算系统700内访问的介质。储存器740可以存储用于实现本文描述的一个或多个创新的软件780的指令。
[0092]
(多个)输入设备750可以是触摸输入设备,诸如键盘、鼠标、笔或轨迹球、语音输入设备、扫描设备或向计算系统700提供输入的另一设备。对于视频编码,(多个)输入设备750可以是照相机、视频卡、tv调谐器卡或接受模拟或数字形式的视频输入的类似设备,或者是将视频样本读取到计算系统700中的cd-rom或cd-rw。(多个)输出设备760可以是显示器、打印机、扬声器、cd-刻录机或从计算系统700提供输出的另一设备。
[0093]
(多个)通信连接770使能通过通信介质与另一计算实体进行通信。通信介质传送信息,诸如计算机可运行指令、音频或视频输入或输出、或调制数据信号中的其他数据。调制数据信号是这样一种信号,它的一个或多个特性以编码信号中的信息的方式被设置或改变。作为示例而非限制,通信介质可以使用电、光、rf或其他载体。
[0094]
示例实施例可以包括由一个或多个处理器在计算系统中运行的计算机可运行指令,诸如包括在程序模块中的指令。通常,程序模块包括例程、程序、库、对象、类、组件、数据结构等,其执行特定任务或实现特定抽象数据类型。在多个实施例中,程序模块的功能可以根据需要在程序模块之间组合或分离。用于程序模块的计算机可运行指令可以在本地或分布式计算系统中运行。
[0095]
为了呈现,详细描述使用类似“确定”、“生成”和“使用”的术语来描述计算系统中的计算机操作。这些术语是由计算机执行的操作的高级抽象,并不应与人类执行的行为相
混淆。对应于这些术语的实际计算机操作因实现方式而异。
[0096]
示例10-示例云计算环境
[0097]
图8描绘了其中可以实现所描述的技术的示例云计算环境800。云计算环境800包括云计算服务810。云计算服务810可以包括多种类型的云计算资源,诸如计算机服务器、数据存储库、网络资源等。例如,云计算服务810 的一个或多个计算机服务器可以用作本文描述的服务器。云计算服务810可以位于中央(例如,由企业或组织的数据中心提供)或分布式(例如,由位于不同位置的多个计算资源提供,诸如不同的数据中心和/或位于不同的城市或国家)。
[0098]
云计算服务810由多种类型的计算设备(例如,客户端计算设备和服务器计算设备)利用,诸如计算设备820、822和824。例如,计算设备(例如, 820、822和824)可以是计算机(例如,台式或膝上型计算机)、移动设备(例如,平板计算机或智能电话)或其他类型的计算设备。例如,计算设备(例如,820、822和824)可以利用云计算服务810以执行计算操作(例如,数据处理、数据存储等)。一个或多个计算设备可以是包括集成电路的嵌入式设备(诸如物联网(iot)设备等)。
[0099]
示例11-示例实现
[0100]
尽管为了方便呈现,以特定的顺序描述了一些所公开的方法的操作,但是应当理解,这种描述方式包含重新排列,除非下面阐述的特定语言需要特定的顺序。例如,在某些情况下,顺序描述的操作可以被重新排列或同时执行。此外,为了简单起见,附图可能没有示出所公开的方法可以与其他方法结合使用的多种方式。
[0101]
任何公开的方法可以被实现为存储在一个或多个计算机可读存储介质上并在计算设备(例如,任何可用的计算设备,包括智能电话或包括计算硬件的其他移动设备)上运行的计算机可运行指令或计算机程序产品。计算机可读存储介质可以包括可以在计算环境内访问的任何有形介质(例如,一个或多个诸如dvd或cd的光学介质盘、易失性存储器组件(诸如dram或 sram)或非易失性存储器组件(诸如闪存、固态驱动器或诸如硬盘驱动器的磁介质))。作为示例并参考图7,计算机可读存储介质包括存储器720和725 以及储存器740。术语计算机可读存储介质不包括信号和载波。此外,术语计算机可读存储介质不包括通信连接(例如,770)。
[0102]
用于实现所公开的技术的任何计算机可运行指令以及在所公开的实施例的实现期间创建和使用的任何数据可以存储在一个或多个计算机可读存储介质上。计算机可运行指令可以是例如专用软件应用或经由网络浏览器或其他软件应用(例如远程计算应用)访问或下载的软件应用的一部分。这种软件可以例如在单个本地计算机(例如,任何合适的商业可用的计算机)上或在网络环境中(例如,经由互联网、广域网、局域网、客户端-服务器网络(诸如,云计算网络)或其他这种网络)使用一个或多个网络计算机运行。
[0103]
所公开的技术不限于任何特定的计算机语言或程序。例如,所公开的技术可以通过用c++、java、python、javascript、汇编语言或任何其他合适的编程语言编写的软件实现。同样,所公开的技术不限于任何特定的计算机或硬件类型。
[0104]
此外,任何基于软件的实施例(包括例如用于使计算机执行任何所公开的方法的计算机可运行指令)可以通过合适的通信手段被上传、下载或远程访问。这种合适的通信手段包括例如互联网、万维网、内联网、软件应用、电缆(包括光纤电缆)、磁通信、电磁通信(包
括rf、微波和红外通信)、电子通信或其他这种通信手段。
[0105]
所公开的方法、装置和系统不应被解释为以任何方式进行限制。相反,本公开针对单独地以及以多种组合和彼此的子组合的多个公开的实施例的所有新颖和非显而易见的特征和方面。所公开的方法、装置和系统不限于任何特定方面或特征或其组合,所公开的实施例也不要求存在任何一个或多个特定优点或解决任何问题。
[0106]
来自任何示例的技术可以与任何一个或多个其他示例中描述的技术相组合。鉴于可以应用所公开技术的原理的许多可能的实施例,应当认识到,所示实施例是所公开技术的示例,并且不应当被视为对所公开技术的范围的限制。相反,所公开技术的范围包括以下权利要求的范围和精神所涵盖的内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1