基于多元时序数据分析的高精度长期时间序列预测方法
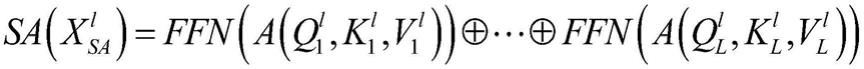
1.本发明属于时间序列预测领域,具体涉及一种基于多元时序数据分析的高精度长期时间序列预测方法。
背景技术:
2.时间序列预测是时间序列分析领域的一个重要分支,其广泛应用于天气预测、股票预测和异常检测等领域中。时间序列预测方法通过学习过去的时间序列的特征规律,从而预测未来一段时间内的时间序列。随着预测序列长度的增加与单变量时间序列向多变量时间序列的转变,时间序列预测问题的难度相应增加,长时间序列预测问题要求方法具有更长的预测能力和更高的预测精度,而多元变量时间序列预测要求方法可以捕捉到多元变量之间的关系,在这种依赖关系的基础上,同时对多个变量的时间序列进行高精度的预测。
3.近年来,越来越多的新方法被提出,它们增加了模型在长序列上的预测能力与捕获多元变量间关系的能力。随着时间序列预测问题的要求逐渐增高,众多方法在学习时间序列中存在的长距离依赖关系等问题上越来越乏力,难以取得进一步的突破。直到基于注意力机制(attention,at)的transformer方法被提出,其在提取距离较长的两个元素之间依赖关系问题上有着突破性的提高。近年来,越来越多的方法将transformer方法或注意力机制用于时间序列预测问题上,取得了较大的进展。但transformer方法以及注意力机制都有着较高的计算复杂度,使得它们对内存具有很高的要求,从而无法直接用于更长的预测要求。于是,越来越多的模型对transformer的计算复杂度等问题进行改善,使其在更长的时间序列预测中取得更好的效果。在众多变体模型中,informer方法在各个方面取得最好的效果。
4.informer对transformer的结构进行了改进,采用多头稀疏自注意力机制(multi-head probsparse self-attention)与自注意力蒸馏机制(self-attention distilling),在降低模型计算复杂度至o(n log n)(n为输入序列的长度)的同时还提高了多元变量长时间序列预测的精度。但是它还具有一些问题:1)较高的计算复杂度和较多的内存使用;2)不具备对时间序列的局部细微波动部分的拟合与预测能力,致使预测精度还有提升空间;3)方法中提取出的特征可解释性低;4)预测长度有限,不能满足更长的时间序列预测问题。
技术实现要素:
5.本发明要解决的技术问题是已有模型精度不足,计算复杂度过高、占用内存规模较大和预测长序列能力不足。本发明提出了一种基于多元时序数据分析的高精度长期时间序列预测方法。经过测试后,对informer中存在的四个问题均有一定的改善,从而在多元变量时间序列预测问题上取得了更佳的结果。
6.本发明采用的技术方案是:采用具有分层平行提取特征的离散网络(separate network)作为核心模块,整体架构采用分层机制,逐层平行提取多元时间序列的全局特征与局部特征,对所有特征加以分析后,以全局特征为纲,结合各层局部特征来对输入的多元
时间序列以及需要预测的部分进行构建,最终输出预测部分。
7.基于多元时序数据分析的高精度长期时间序列预测方法,步骤如下:
8.步骤1:数据预处理,获得训练数据集和验证数据集。
9.步骤2:借助于步骤1得到的训练数据集,每次随机选取32组训练数据,输入到离散框架模型中,每组数据中的历史序列和起始序列分别输入到离散框架模型中的真实编码器和预测编码器中,两个编码器通过离散网络(separate network)对输入序列提取全局特征和局部特征。
10.步骤3:将真实编码器(true encoder)输出的全局特征和局部特征进行维度变换,将变换后的特征与预测编码器(pred encoder)输出的特征进行拼接,作为最终的全局特征和局部特征。
11.步骤4:将最终的全局特征和局部特征输入至解码器(decoder)中,通过离散网络(separate network)对步骤3最终得到的全局特征与各层局部特征进行重构,从而得到最终的生成预测序列。
12.步骤5:计算步骤4得到最终的生成预测序列与预测序列之间的均方误差(mse)和平均绝对误差(mae),然后通过adam优化器进行反向传播,更新网络参数。最终得到训练好的离散框架模型。
13.步骤6:通过验证数据集集对离散框架模型进行测试;
14.将步骤1得到的验证数据集输入至训练好的离散框架模型中,最终得到基于验证数据集生成的预测序列。
15.步骤7:计算基于验证数据集生成的预测序列与真实预测序列之间的均方误差(mse),求得所有组数据的均方误差(mse)后求均值,得到基于验证数据集的mse误差。
16.步骤8:重复步骤2至步骤7,直至步骤7得到的均方误差(mse)不再减小,说明模型表现无法再变好,则网络参数更新完毕,模型结束训练。
17.步骤9:将预测任务所给的输入序列输入到步骤8最终得到的训练好的模型中,进行序列预测,输出最终得到的预测序列,完成预测。
18.进一步的,步骤1具体方法如下:
19.选取合适的公共时间序列数据集,对其进行分组与分割以适应模型对数据格式的要求。首先根据需求设定每组数据中的历史序列长度、预测序列长度和起始序列长度,这三个长度分别对应每组数据中的三个部分:历史序列、预测序列和起始序列。采用滑窗机制进行分组,窗口长度为历史序列长度与预测序列长度之和,每次窗口移动一位,即相邻两组数据之间只有一位上的不同。在完成数据分组之后,截取70%组数据作为训练数据集,30%组数据作为验证数据集。
20.进一步的,在长度上,起始序列长度小于等于历史序列长度,在数值上,起始序列与历史序列的后部分相同。历史序列与预测序列在位置上是前后相接的,每组数据的长度为历史序列长度与预测序列长度之和。
21.进一步的,步骤2所述的离散框架sepformer模型由真实编码器true encoder、预测编码器pred encoder和一个解码器decoder构成。真实编码器需要输入每组数据中的历史序列,从中提取序列的历史特征;预测编码器需要输入每组数据中的起始序列,使用起始序列来预测后边预测序列长度的序列;每组数据中的预测序列作为正确的结果与模型最终
输出的生成预测序列进行比较,计算二者之间的误差。
22.进一步的,真实编码器true encoder和预测编码器pred encoder的核心模块都是离散网络(separate network,sn)。
23.离散网络(separate network)采用波形提取模块(waveform extraction,we)和离散注意力机制模块(separate attention,sa)层层提取全局特征(global feature)和局部特征(local feature)。波形提取模块会对输入序列进行分解,通过滑窗机制遍历整个输入序列求得窗口内均值,得到输入序列的全局趋势,使用输入序列减去得到的全局趋势,得到输入序列的局部波动。波形提取模块(we)整体公式如下所示:
[0024][0025][0026][0027][0028]
其中和分别表示波形的全局趋势和局部波动,用于作为输入,通过离散注意力模块提取全局特征和局部特征;为第l层we的输入序列;为连接符号,用于连接不同的分块;avgpool函数为均值池化函数,其设定一个滑动窗口,每次滑动一个单元,然后对窗口内的所有元素求均值,将所得数值赋值给当前单元。将进行分块,然后输入avgpool中,表示第i个分块。
[0029]
离散注意力机制模块(separate attention,sa)用于进行特征提取。离散注意力机制模块先将输入序列分割成长度相同的块(block,b),然后通过共享注意力机制模块(attention,at)提取特征,接着通过前馈网络(feed-forward network,ffn)进行维度变换,按比例缩短每个块的长度,最终拼接后输出。离散注意力机制的计算公式如下所示:
[0030][0031][0032]
其中,为第l层离散注意力模块(sa)的输入序列;b表示输入序列得到的分块(block);分别表示q、k、v在第l层第i个分块上的可学习权重矩阵;v
il
和分别表示第l层q、k、v和b的第i个分块。q、k和v分别表示分块经过线性变换后得到的问题矩阵(query)、键值矩阵(key)和数值矩阵(value)。其中注意力机制定义为:
[0033]
[0034]
其中d
model
表示特征维度。
[0035]
离散网络整体函数表达式如下所示:
[0036][0037]
其中z
l
表示离散网络第l层的全局特征;h
l
表示离散网络第l层的局部特征;x
sn
表示sn的输入。
[0038]
进一步的,步骤3具体方法如下:
[0039]
真实编码器(true encoder)和预测编码器(pred encoder)输出的全局特征和局部特征分别进行拼接,其中真实编码器(true encoder)输出的两种特征将经过前馈网络(feed-forward network,ffn)进行纬度变换至与预测编码器(pred encoder)具有相同的维度,然后对两种特征各自进行拼接,得到整体的全局特征和局部特征。
[0040]
将真实编码器(true encoder)输出的全局特征和局部特征进行维度变换,将变换后的特征与预测编码器(pred encoder)输出的特征进行拼接,作为最终的全局特征和局部特征。
[0041]
进一步的,步骤6所述的均方误差(mse)和平均绝对误差(mae)公式如下所示:
[0042][0043][0044]
其中,y为预测值;为真实值;n表示序列的长度。
[0045]
本发明的有益效果:
[0046]
本发明使用离散网络(separate network)用于分层平行提取多元时间序列的全局特征和局部特征,在提高多元时间序列预测精度的同时降低了计算复杂度、减少了模型规模并且增加了模型的预测长度。
[0047]
在多元时间序列预测中,预测精度、预测序列长度、对局部细微波动的拟合能力等问题都是影响预测效果的重要因素。本发明采用分层平行提取多元时间序列的全局特征和局部特征机制,提升了预测精度,降低了模型的内存使用量,利用局部特征提高对多元时间序列的局部细微波动的拟合能力,并且增加了模型的预测长度,大大提升了模型在多元时间序列预测上的效果。
附图说明
[0048]
图1为本发明实施例的整体结构示意图。
[0049]
图2为本发明实施例的离散框架结构示意图。
[0050]
图3为本发明实施例离散网络(separate network)的结构图。
[0051]
图4为本发明实施例离散注意力机制模块(separate attention)的结构图。
[0052]
图5是本发明实施例在etth1、etth2、ettm1、weather和ecl五种公开数据集下,与五个已有的方法在均方误差(mse)上的比较。
[0053]
图6是相同条件下,本发明离散特征提取方法(sepformer)与informer的gpu使用量的比较。
具体实施方式
[0054]
下面结合附图和具体实施步骤对本发明做了进一步的说明:
[0055]
一种基于多元时间序列预测的高精度低内存的离散特征提取方法(sepformer),包括以下步骤:
[0056]
步骤1:数据预处理,获得训练数据集和验证数据集。
[0057]
选取合适的公共时间序列数据集,进行分组与分割以适应模型对数据格式的要求。首先根据需求设定每组数据中的历史序列长度、预测序列长度和起始序列长度,这三个长度分别对应每组数据中的三个部分:历史序列、预测序列和起始序列。在长度上,起始序列长度小于等于历史序列长度,在数值上,起始序列与历史序列的后部分相同。历史序列与预测序列在位置上是前后相接的,每组数据的长度为历史序列长度与预测序列长度之和。采用滑窗机制进行分组,窗口长度为历史序列长度与预测序列长度之和,每次窗口移动一位,即相邻两组数据之间只有一位上的不同。在完成数据分组之后,截取70%组数据作为训练数据集,30%组数据作为验证数据集。
[0058]
离散框架sepformer由两个编码器(真实编码器true encoder和预测编码器pred encoder)和一个解码器decoder构成。真实编码器需要输入每组数据中的历史序列,从中提取序列的历史特征;预测编码器需要输入每组数据中的起始序列,使用起始序列来预测后边预测序列长度的序列;每组数据中的预测序列作为正确的结果与模型最终输出的生成预测序列进行比较,计算二者之间的误差。
[0059]
如图1所示,展示了本发明的整体结构。数据处理与分割部分在本发明结构的入口处,负责对原始数据做初步处理,形成预测模型所需的数据结构。
[0060]
步骤2:借助于步骤1得到的训练数据集,在设备条件允许的情况下,每次随机选取32组训练数据,输入到模型中,每组数据中的历史序列和起始序列分别输入到模型中的真实编码器和预测编码器中,两个编码器通过离散网络(separate network)对输入序列提取全局特征和局部特征。
[0061]
如图2所示,展示了本发明离散特征提取方法(sepformer)的整体结构,离散框架sepformer包含两个编码器(encoder)和一个解码器(decoder),真实编码器(true encoder)和预测编码器(pred encoder)分别接收步骤1中得到的每组数据中的历史序列和预测序列,两个encoder的核心模块都是离散网络(separate network,sn)。
[0062]
如图3所示,展示了离散网络(separate network)的整体结构,离散网络(separate network)采用波形提取模块(waveform extraction,we)和离散注意力机制模块(separate attention,sa)层层提取全局特征(global feature)和局部特征(local feature)。波形提取模块会对输入序列进行分解,通过滑窗机制遍历整个输入序列求得窗口内均值,得到输入序列的全局趋势,使用输入序列减去得到的全局趋势,得到输入序列的局部波动。波形提取模块(we)整体公式如下所示:
[0063]
[0064][0065][0066][0067]
其中和分别表示波形的全局趋势和局部波动,用于作为输入,通过离散注意力模块提取全局特征和局部特征;为第l层we的输入序列;为连接符号,用于连接不同的分块;avgpool函数为均值池化函数,其设定一个滑动窗口,每次滑动一个单元,然后对窗口内的所有元素求均值,将所得数值赋值给当前单元。将进行分块,然后输入avgpool中,表示第i个分块。
[0068]
如图4所示,展示了离散注意力机制模块(separate attention,sa),该模块用于进行特征提取。离散注意力机制模块先将输入序列分割成长度相同的块(block,b),然后通过共享注意力机制模块(attention,at)提取特征,接着通过前馈网络(feed-forward network,ffn)进行维度变换,按比例缩短每个块的长度,最终拼接后输出。离散注意力机制的计算公式如下所示:
[0069][0070][0071]
其中,为第l层离散注意力模块(sa)的输入序列;b表示输入序列得到的分块(block);分别表示q、k、v在第l层第i个分块上的可学习权重矩阵;v
il
和分别表示第l层q、k、v和b的第i个分块。q、k和v分别表示分块经过线性变换后得到的问题矩阵(query)、键值矩阵(key)和数值矩阵(value)。其中注意力机制定义为:
[0072][0073]
其中d
model
表示特征维度。
[0074]
离散网络整体函数表达式如下所示:
[0075][0076]
其中z
l
表示离散网络第l层的全局特征;h
l
表示离散网络第l层的局部特征;x
sn
表示sn的输入。
[0077]
步骤3:将真实编码器(true encoder)输出的全局特征和局部特征进行维度变换,将变换后的特征与预测编码器(pred encoder)输出的特征进行拼接,作为最终的全局特征
和局部特征。
[0078]
如图2所示,真实编码器(true encoder)和预测编码器(pred encoder)输出的全局特征和局部特征分别进行拼接,其中真实编码器(true encoder)输出的两种特征会经过前馈网络(feed-forward network,ffn)进行纬度变换至与预测编码器(pred encoder)具有相同的维度,然后对两种特征各自进行拼接,得到整体的全局特征和局部特征。
[0079]
步骤4:将步骤3得到的全局特征和局部特征输入至解码器(decoder),通过离散网络(separate network)对输入的全局特征与各层局部特征进行重构,从而得到最终的生成预测序列。
[0080]
步骤5:计算其步骤4得到的最终的生成预测序列与预测序列之间的均方误差(mse)和平均绝对误差(mae),然后通过adam优化器进行反向传播,更新网络参数。最终得到训练好的离散框架模型。均方误差(mse)和平均绝对误差(mae)公式如下所示:
[0081][0082][0083]
其中,y为预测值;为真实值;n表示序列的长度。
[0084]
步骤6:通过步骤1得到的验证数据集训练步骤5更新网络参数后的模型,选取32组验证数据作为输入,执行步骤2至步骤4,其中将步骤2中的训练数据替换成选取的32组验证数据。最终得到基于验证数据生成的预测序列。
[0085]
步骤7:借助于步骤6得到的基于验证数据得到的生成预测序列,计算基于验证数据集生成的预测序列与真实预测序列之间的均方误差(mse),求得所有组数据的均方误差(mse)后求均值,得到基于验证数据集的mse误差。
[0086]
步骤8:重复步骤2至步骤7,直至步骤7得到的均方误差(mse)不再减小,说明模型表现无法再变好,则网络参数更新完毕,模型结束训练。
[0087]
步骤9:将预测任务所给的输入序列输入到步骤8最终得到的训练好的模型中,进行序列预测,输出最终得到的预测序列,完成预测。
[0088]
图5显示了在相同的实验条件下,sepformer、informer、logtrans、reformer、lstma和lstnet等六种方法在etth1、etth2、ettm1、weather和ecl等五种数据集上的实验结果,衡量标准为均方误差(mse)和平方绝对值(mae)。在每种实验条件下,表现最好的模型的实验结果在表格中加粗表示。从图5表格中可以看到离散特征提取方法(sepformer)对比其余五种方法有着较大的提升,而对比informer方法,离散特征提取方法(sepformer)在五个数据集上分别降低了均方误差(mse)28.68%、12.66%、26.55%、15.53%和29.23%,平均下降了22.53%。
[0089]
图6显示了在相同的实验条件下,随着预测序列长度的增加,离散特征提取方法(sepformer)与informer在内存使用量上的比较和变化。可以看到随着预测序列长度越来越长,离散特征提取方法在内存使用量上的优势会越来越大。对比informer,离散特征提取方法在内存使用量上平均降低了27.45%。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1