一种基于最大三角形三段算法的海量数据绘图优化方法
1.本发明属于数据可视化技术领域,具体涉及一种基于最大三角形三段算法的海量数据绘图优化方法。
背景技术:
2.近年来,工业上的远程运维和在线监控系统得到了广泛的应用,而在工业监控场景中,时序数据的可视化是一个无法回避的话题。因为许多监控系统中需要对现场设备的数据进行频繁地采集和上报,对其进行实时可视化图表展示。这些数据往往更新频率很高,每次更新的数据量比较大,这就会得到一个时序的超大数据量的数据集合。
3.这些海量数据在使用时存在一些问题:第一,特征不明显。数据量级大,波动频繁,数据点折线连接后相互重叠,无论是用于后续的数据挖掘还是直接进行绘制,都很难得到显著的趋势特征,不利于数据分析和可视化效果展示。第二,过多的数据点给图形的展示性能带来了挑战。系统页面的可视化技术如echarts、highcharts的绘制性能会随着绘制点的不断增多而快速下降,更新重绘会比较卡顿,而且内存占用高,严重影响系统的性能。
4.所以工业监控场景下,需要对海量的时序数据进行一些优化处理。针对时序数据量级大的问题,可以对时序数据进行降采样处理,同时尽可能保证原始数据的波动细节、趋势、形状,具体量化来说就是序列的统计特征(如均值、极值、方差)以及形态特征(如距离、角度、斜率)。
5.目前比较适合工业场景下使用的是冰岛大学的sveinn提出的lttb算法,但是在实际场景中该算法在数据陡峭处容易丢失“尖峰”,并不完美。广州虎牙公司的陈键冬等人采取在lttb处理之前先进行一次均值采样(如paa)的方法,意图降低尖峰后再进行lttb,但是paa容易丢失数据曲线更多的形状细节,得不偿失。王立峰等人先对时序数据以当前数据点与前一数据点的时间差值为权重值,选择某个权重和为阈值,把数据切分成段,来分段进行lttb。其分段的想法是正确的,但是以时间差值为权重忽视了尖峰产生的原因是由于数值的突变,而非时间差值过大的特点。而且该阈值的选取并不严谨,没有合适的固定值,实际设置时也不易于选取到合适的阈值。
技术实现要素:
6.针对以上问题,本发明提出了一种基于最大三角形三段算法的海量数据绘图优化方法,旨在提出一种适用于工业场景下,对海量时序数据进行lttb降采样的改进方法,以及使得后续的绘图过程性能更好的方案。
7.本发明包括以下步骤:
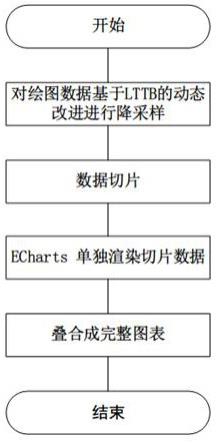
8.步骤s1、获取采集到的数据,基于最大三角形三段算法(large triangle three buckets,lttb)及其动态改进算法进行降采样;
9.步骤s2、设定阈值,对过大数据进行切片;
10.步骤s3、然后创建echarts实例,对给定的每一个切片数据单独进行渲染绘制。最
后叠合每一个子图表,形成一个完整的图表。
11.进一步说,步骤s1中,基于最大三角形三段算法(large triangle three buckets,lttb)进行改进。对于多数的较规则图形本发明使用lttb算法来降采样,但是对于一些特殊形状、数据分布严重不均匀的情况,改进为使用动态分段的算法,即:在数据相对平缓时将较多的点看作一段,在数据陡峭时将较少的点看作一段,在进行有效三角形区域的选取,采用这种方法,可以对变化趋势不规则的特殊数据曲线达到很好的采样效果。
12.进一步说,步骤s2中,对于仍然较大量级的数据,设定一个合理阈值来对数据进行切片,从而进一步减小数据量级。
13.进一步说,步骤s3中,使用数据化技术创建实例,把数据渲染绘制成可视化图表。对于经过了切片的数据,需要创建多个绘图实例,最终成图时将多个实例叠合,从而形成一个完整的图表。
14.进一步说,所述的数据可视化技术为开源产品echarts。echarts是百度公司开源的javascript可视化图表库,拥有丰富的图表类型和自研的高效渲染引擎zrender,可以实现优雅、友好的响应式图表设计。
15.进一步说,所述的echarts图表选取的是折线图。因为时序数据的可视化绘制更适合使用折线来表征,故本发明以折线为例。所述的echarts折线图表应当考虑到步骤s3、s4中提及的切片数据的叠合问题。具体来说,echarts图表的绘制应当使用给定数据来创建实例,交给渲染引擎zrender进行绘制。如果进行了数据的切分,对每一个切片数据要进行单独的实例创建,渲染得到的多个子图表进行单独的位置定位,定位到同一位置来达到叠合成一个完整图表的目的。
16.进一步说,使用层叠样式表语言(cascading style sheets,css)来完成子图表的定位叠合。设置子图表为相同的大小(width、height)、位置(top、left)以及定位方式(absolute),将父容器设置为相对定位,将每一子图表绝对定位到容器内的同一位置,叠合成为完整图表。
17.本发明主要提出了如下的改进:
18.第一,针对数据点过多的问题,提出基于最大三角形三段算法(large triangle three buckets,lttb)及其基于距离和离散程度的动态改进算法进行降采样。前面提到的paa分段聚合近似(piecewise aggregate approximation,paa)算法,是维护一个滑动窗口,取每个窗口内一个时间段内数据的平均情况,但是对于工业时序数据而言,均值处理过后频繁变化的序列会严重丢失形状细节,形状特征很难保持,所以只适合平稳变幅数据。
19.而本发明基于lttb,与paa计算均值来采样点不同,lttb通过计算最大有效面积来选择采样点,一个点的有效区域定义为与该点相邻两点所围成三角形的面积,通过选取当前段内使得有效区域最大的点,可以有效地保持住点与点间的距离、角度和轮廓特征。虽然算法较为复杂,但非常适合处理海量频繁变化的时序数据。
20.另外,为了处理局部过于陡峭的极端情况,本发明改进使用基于距离和离散程度的动态确定分段大小的方法。方法主要原理是拟合一条渐近线,数据点到渐近线的距离来表征其离散程度。将所有的距离和三等分,于是当遇到尖峰时,只要拟合线尽可能准确,那么尖峰有极大的概率会单独落在一个等分段,从而被采用。因为其他的点由于趋近于拟合线,不会或只能产生很小的距离。
21.第二,针对降采样后仍然可能数据过大的问题,设定阈值,把数据进行进一步的切片,对每一个切片数据单独进行渲染绘制。同时针对于echarts绘制大数据时耗时剧增的特点,提出将整体数据切分,而后分别进行渲染,最终将子图表定位叠合为一个完整的图表,完成绘制。这样可以把数据量级控制在一个可以接受的范围内。
22.本发明的有益效果:本发明可以在尽量不损失原始数据细节的前提下,大幅减小绘图所用的数据点,把数据量级控制在合理的阈值内,并且通过将二进制数据直接交给绘图程序取绘制,从而可以高效、高性能地对数据进行可视化绘图。
附图说明
23.图1是本发明整体流程图。
24.图2是本发明中所使用的降采样改进算法示意图。
25.图3是本发明中数据切片后进行绘制的流程示意图。
26.图4是本发明的测试绘图效果图。
具体实施方式
27.为了本发明的技术方案更加清楚明白,接下来结合附图来进行详细的说明,本发明所述如图1所示,具体步骤如下:
28.步骤s1、获取采集到的数据,基于最大三角形三段算法(large triangle three buckets,lttb)及其动态改进算法进行降采样。lttb算法的步骤如下:
29.s1-1、确定分段大小threshold:为了便于改变分段大小,把分段大小当作参数(threshold)传递给算法,这样如果需要采样100倍,只需要传递参数threshold=(总数据大小/倍数)。把total个数据点平分到这所有的段内,共分成了threshold段。另外为了确保数据分完后可以选中首尾,首和尾点各自单独占据一个段。
30.s1-2、选中第一个点(也就是第一个段)。
31.s1-3、从第二段开始,遍历段中所有点,计算每个点的有效三角区域,并选取有效区域面积最大的点作为该段的选中点(采样点)。其中,所述的有效三角区域是指以[前一段的选中点a,当前点f,后一个段的平均点b]三个点为顶点的三角形区域。
[0032]
s-4、遍历,直到选中最后一个点(也就是最后一个段),算法结束。
[0033]
lttb算法的问题在于平分了所有段,这在一些数据曲线比较陡峭的情况下表现不好。因为在平缓处较少的点就能反映出细节,而在陡峭处就需要较多的点才能反映出细节,而lttb为了节省分段需要消耗的时间,直接简单进行了平分。所以本发明在此做了动态分段的改进,也就是对上述算法的步骤(s1-1)进行的改进,于是步骤(s1-1)改进成下述的算法步骤:
[0034]
(1-1)还是把分段大小当作参数(threshold)传递给算法,先和lttb一样平分各段,首和尾点各自单独占据一个段。
[0035]
(1-2)从第二段开始遍历段中所有点(共计m=total/threshold),以前一段的选中点a,后一个段的平均点b为渐近线l,计算得到段中每一个点f’到直线l的垂直距离得到数组ss、所有垂直距离之和sse。
[0036]
(1-3)以target=1/3*sse为目标值,将数组ss进行值的三等分。对于寻找到的三
等分索引,也作为分段点进行分段,由于垂直距离一定程度上表征了相对于渐近线的离散程度,所以一个sse的分段切分成了三个比较均匀的target的分段,比较动态地应对了急剧变化的恶劣情况。其中,如果不存在恰好等于target的三等分点,就取左右比较近似的点。
[0037]
(1-4)这样进行分段后,再进行上述的lttb算法的步骤2即可,最终的改进算法流程如图2所示。
[0038]
步骤s2、数据切片。设定阈值,对于降采样后仍然较大的数据,进行切片操作,然后进入下一步骤。实验表明,同时进行的绘图实例不宜过多,而且数据量在百级以下绘图消耗几乎持平,所以本发明设定:切分的数据片个数最大阈值为10、单个数据片容量最小阈值为200。
[0039]
步骤s3、绘制渲染。本发明以echarts绘图为例,最主要的耗时操作是绘制数据点。不过本发明由于进行了降采样算法步骤,在实际的效果考量时,还要考虑到对数据进行处理的算法耗时。该绘制过程主要包括:
[0040]
s3-1、创建echarts实例:对给定的每一个切片数据单独进行渲染绘制。
[0041]
s3-2、使用层叠样式表语言,定位叠合每一个子图表,形成一个完整的图表。具体而言,只需要将父容器设置为相对定位,将每一子图表绝对定位到容器内的同一位置,然后把图表的轴线刻度仅保留一份,就可以进行叠合。虽然是多个子图表,但在人眼视觉上这个图表是完整的,具体流程见图3。
[0042]
所述技术方案如上面步骤所述。下面进行测试并对结果进行总结,用以说明本发明可以取得的优化成果,测试步骤如下:
[0043]
a、生成测试数据。随机生成10万个时序数据,具体的生成步骤如下:
[0044]
(1)生成过去的时间戳基数:base=new date(1988,9,3)
[0045]
(2)遍历,每次时序累积基数base:base+=24*3600*1000,now=new date(base)
[0046]
(3)数据集推入[now,随机取值]
[0047]
(4)遍历10万次后,就得到了10万个时序连续的随机值。
[0048]
b、降采样。对10万个数据采取不同的采样倍率1、10、100、500、1000、10000,使用所述步骤s1中的算法进行降采样,最终的绘图细节保留程度如图4,测试数据如下表二。
[0049]
c、切分数据渲染。对于采样倍率1、10、100的数据样本,采样后的数据仍然超过阈值,采取所述步骤s2、s3的方法进行数据的切分和单独渲染实例,测试数据如下表三。
[0050]
最终的测试数据如下:
[0051]
一、数据指标设置
[0052]
测试数据100000降采样倍率1、10、100、500、1000、10000数据切分阈值10(数据最大分片)、200(单个最小容量)
[0053]
二、绘图测试数据
[0054][0055]
三、切分数据后的绘图测试数据
[0056][0057]
由以上测试数据显示,采用本发明中的降采样及数据切分的绘图优化方法,对数据每降采样一个数据量级后,可以减小大约70~80%的绘图耗时,同时降低大约20~30%的内存占用,效果良好,尤其是在选取适当的采样倍率和阈值的情况下效果很好。比如结合图4的绘图效果图和表格数据可知,在降采样到1000个数据点、阈值采取方案所述的10*200的情况下,图形的细节特征很好地进行了保留,波峰和波谷点即使是降采到10个点也得到了保留。同时测得的绘图耗时及内存占用数据也比较理想,综上可以说明本发明取得了预期的效果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1