一种负载感知的路网最短路径距离计算方法及装置
1.本发明属于时空数据管理技术领域,更具体地,涉及一种负载感知的路网最短路径距离计算方法及装置。
背景技术:
2.随着社会经济的发展和城市化水平的提升,各类导航软件的应用愈加广泛,最典型的应用是查询城市路网中任意两点间的最短路径距离,城市的政务中心、交通枢纽、大型商圈和旅游景区等地区往往是用户查询的热点,反应出了路网中查询点的相对集中特征,同时,用户查询在时间上的分布又呈现一定的规律性。当大量用户集中查询路网中的点时,如何在更短时间内返回查询结果,提升导航软件的查询性能和用户出行体验,是最短路径距离查询算法需要考虑和研究的。
3.查询路网最短路径距离通常采用经典的dijkstra算法,其将城市路网的交叉路口作为图中的点,将道路长度或者行驶时间等作为图中边的权值,通过宽度优先搜索的策略获得图中任意两点间的最短路径距离,由于该算法在查询最短路径距离时需要遍历图中的所有点和边,查询效率很低,无法满足现实使用需求。为加快路网中任意两点间的最短路径距离查询,现有方法通过在预处理阶段对路网建立索引,然后利用索引来获得查询结果。2002年edith cohen等人提出了2-hop标签索引,该方法首先对路网中每一个点建立2-hop标签索引,然后通过线性扫描查询点的索引来计算最短路径距离,其查询时间复杂度与索引大小成正比。其中,在2013年提出的pll算法通过改进2-hop标签索引的计算方法,使得2-hop方法被广泛应用,且效率能满足现实需求。2018年欧阳典等人提出了层级2-hop标签索引(h2h),他们利用树分解将路网转化为树结构,然后在树结构上建立2-hop标签索引,在查询两点间最短距离时,h2h首先通过树结构找到查询点的最近共同祖先(lowest common ancestor,lca),然后利用lca确定需要扫描的查询点标签,从而避免了线性扫描整个2-hop标签索引,h2h算法在近距离查询时效率很高,然而远距离的查询效率比2-hop标签索引低。
4.现有算法只考虑了路网的拓扑结构,将路网所有节点等同对待来构建索引,没有考虑查询负载,这些算法无法根据查询负载进行动态优化。然而,现实场景中,用户的查询负载在空间上相对集中,在时间上又呈现规律性特征,与索引的查询性能具有很强的相关性,是不可忽略的因素。
技术实现要素:
5.针对现有技术的缺陷和改进需求,本发明提供了一种负载感知的路网最短路径距离计算方法及装置,旨在克服现有最短路径距离计算方法只考虑路网结构特征、未考虑最短路径查询负载所具有的时空特性而无法有效处理大规模负载的缺陷。
6.为实现上述目的,一方面,本发明提供了一种负载感知的路网最短路径距离计算方法,包括:
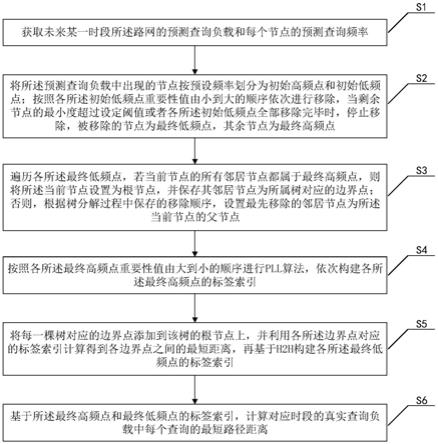
7.s1,获取未来某一时段所述路网的预测查询负载和每个节点的预测查询频率;
8.s2,将所述预测查询负载中出现的节点按预设频率划分为初始高频点和初始低频点;按照各所述初始低频点重要性值由小到大的顺序依次进行移除,当剩余节点的最小度超过设定阈值或者各所述初始低频点全部移除完毕时,停止移除,被移除的节点为最终低频点,其余节点为最终高频点;
9.s3,遍历各所述最终低频点,若当前节点的所有邻居节点都属于最终高频点,则将所述当前节点设置为根节点,并保存其邻居节点为所属树对应的边界点;否则,根据树分解过程中保存的移除顺序,设置最先移除的邻居节点为所述当前节点的父节点;
10.s4,按照各所述最终高频点重要性值由大到小的顺序进行pll算法,依次构建各所述最终高频点的标签索引;
11.s5,将每一棵树对应的边界点添加到该树的根节点上,并利用各所述边界点对应的标签索引计算得到各边界点之间的最短距离,再基于h2h构建各所述最终低频点的标签索引;
12.s6,基于所述最终高频点和最终低频点的标签索引,计算对应时段的真实查询负载中每个查询的最短路径距离。
13.进一步地,所述s1包括:
14.s11,将包含起点和终点信息的轨迹数据中的起点和终点分别匹配到所述路网中的节点上,获得训练数据集,所述训练数据集包括不同时间段内的查询负载和每个节点的查询频率;
15.s12,将所述训练数据集输入训练模型中进行训练,以获取未来某一时段所述路网的预测查询负载和每个节点的预测查询频率。
16.进一步地,所述s2中,在计算各所述初始低频点重要性值之前,先利用分块技术将所述初始低频点按照查询频率由小到大排序后放入不同的块b={bi|i=1,2,
…
,n}中;
17.各所述初始低频点重要性值通过以下方式计算:
[0018][0019]
其中,σ(u)表示节点u的重要性值;γ表示第一权重参数,范围为(0,1.0);bi表示节点u所属的块,b1和bn分别表示第一个分块和最后一个分块;示第一个分块和最后一个分块;和分别表示节点ui、u1、un的查询频率;和分别表示属于bi、b1和bn的节点的查询频率之和;du表示节点u的度大小,d
max
表示节点最大度。
[0020]
进一步地,所述s4中,各所述最终高频点重要性值通过以下方式计算:
[0021][0022]
其中,σ(v)表示节点v的重要性值,表示归一化处理后节点v的查询频率,表示归一化处理后节点v的中介中心度;β表示第二权重参数,范围为(0,1.0)。
[0023]
进一步地,所述s4包括:
[0024]
s41,按照各所述最终高频点重要性值由大到小的顺序,依次对每个节点x进行dijkstra搜索,并且只搜索重要性值比节点x小的节点y,得到二元组(x,dist(x,y)),dist
(x,y)表示节点x和y之间的距离;
[0025]
s42,若利用节点x和y已有的标签索引能够计算得到节点x和y之间的最短路径距离,则进行剪枝,否则将所述二元组添加到节点y的标签索引中。
[0026]
进一步地,所述s5之后,还包括:
[0027]
s5',对所述未来某一时段进行分片,采用基于dqn的强化学习算法,得到最佳分片方案;针对所述最佳分片方案对应的每一时间间隔,获取所述路网的预测查询负载和每个节点的预测查询频率,并执行所述s2至s5,得到所述每一时间间隔对应的最终高频点和最终低频点的标签索引。
[0028]
进一步地,所述对所述未来某一时段进行分片,采用基于dqn的强化学习算法,得到最佳分片方案,包括:
[0029]
s51',按照预设规则将所述未来某一时段划分为m个时间片段,再将所述m个时间片段划分为n个时间间隔,m≥n;将分片过程建模成马尔可夫决策过程,其中,马尔可夫决策过程包括以下四要素:
[0030]
状态s,一个状态表示成一个五元组其中,tj表示当前时间片段,j=1,2,
…
,m,ρ
*
表示上一个建立标签索引的时间间隔的查询负载,ρj表示当前时间片段的查询负载,表示上一个建立标签索引的时间间隔和当前时间片段的jensen-shannon散度,c表示已经划分的时间间隔的数量;
[0031]
行为a,一个行为用数字0或1表示,0表示不在当前时间片段分片,1表示在当前时间片段分片;
[0032]
奖励r,表示为其中,v表示所述路网中所有节点的集合,f
i,j
表示在tj时间片段节点vi的查询频率,cost
*
(vi)表示利用t
*
建立标签索引查询节点vi的开销,t
*
表示上一个已经划分好的时间间隔;
[0033]
状态转移,一个状态转移(s,a,r,s
′
)表示在当前状态s下选择行为a,得到奖励r,并进入下一个状态s
′
;
[0034]
s52',基于dqn求解马尔可夫决策问题,得到最佳分片方案。
[0035]
进一步地,所述s6包括:
[0036]
当所述每个查询中节点g和h都属于最终高频点时,在节点g和h的标签索引中寻找共同节点,以节点g到共同节点的距离与节点h到共同节点的距离之和的最小值作为节点g到h的最短路径距离;
[0037]
当所述每个查询中节点g属于最终高频点,节点h属于最终低频点时,若节点g属于边界点,则直接返回节点h中存储的到节点g的最短路径距离;否则,以节点h所属树中每个边界点到根节点的距离加上根节点到节点g的距离之和的最小值作为节点g到h的最短路径距离;
[0038]
当所述每个查询中节点g和h都属于最终低频点时,利用节点g和h标签索引中位置数组的第一个位置判断节点g和h是否属于同一棵树;若节点g和h属于同一棵树,则依次遍历节点g和h的最小共同祖先节点中的位置数组并比较节点g和h到各位置数组对应节点的距离之和,取最小值作为结果返回;若节点g和h不属于同一棵树,则分别将节点g所在树的边界点和节点h所在树的边界点的标签索引按照类似归并排序的过程赋给节点g和h,并在
节点g和h的标签索引中寻找共同节点,以节点g到共同节点的距离与节点h到共同节点的距离之和的最小值作为节点g到h的最短路径距离。
[0039]
进一步地,采用多线程并行计算的方式执行所述s5。
[0040]
另一方面,本发明提供了一种负载感知的路网最短路径距离计算装置,包括:
[0041]
预测数据获取模块,用于获取未来某一时段所述路网的预测查询负载和每个节点的预测查询频率;
[0042]
层级结构构建模块,用于将所述预测查询负载中出现的节点按预设频率划分为初始高频点和初始低频点;按照各所述初始低频点重要性值由小到大的顺序依次进行移除,当剩余节点的最小度超过设定阈值或者各所述初始低频点全部移除完毕时,停止移除,被移除的节点为最终低频点,其余节点为最终高频点;
[0043]
森林构建模块,用于遍历各所述最终低频点,若当前节点的所有邻居节点都属于最终高频点,则将所述当前节点设置为根节点,并保存其邻居节点为所属树对应的边界点;否则,根据树分解过程中保存的移除顺序,设置最先移除的邻居节点为所述当前节点的父节点;
[0044]
标签索引构建模块,用于按照各所述最终高频点重要性值由大到小的顺序进行pll算法,依次构建各所述最终高频点的标签索引;以及将每一棵树对应的边界点添加到该树的根节点上,并利用各所述边界点对应的标签索引计算得到各边界点之间的最短距离,再基于h2h构建各所述最终低频点的标签索引;
[0045]
最短路径距离计算模块,用于基于所述最终高频点和最终低频点的标签索引,计算对应时段的真实查询负载中每个查询的最短路径距离。
[0046]
总体而言,通过本发明所构思的以上技术方案,能够取得以下有益效果:
[0047]
(1)本发明通过分析预测历史数据得到未来某一时段路网的预测查询负载和每个节点的预测查询频率,基于此将路网中所有节点划分为高频点和低频点,并分别构建高频点和低频点的标签索引,然后通过减小查询负载中高频点的索引标签大小来提升高频点的查询速度,从而减小整个查询负载的查询开销,提升查询响应速度。
[0048]
(2)本发明中所采用的基于强化学习的方法,能够有效捕捉连续时间分片的查询分布局部相似性,对时间分片进行划分后指导索引的构建,从而进一步优化查询性能。
[0049]
(3)本发明利用层级结构构建的最短路径距离查询索引,相比于传统的基于2-hop标签索引的方法,具有更小的索引构建时间和索引存储开销,该构建过程能很好的支持并行化计算。
[0050]
(4)本发明提供的针对查询负载的最短路径距离计算方法能减小服务器资源占用,具有实用性,可以作为gps导航、自动驾驶、路径规划、交通管理调度以及基于网络关系分析的应用中的关键模块。
附图说明
[0051]
图1为本发明实施例提供的负载感知的路网最短路径距离计算方法的流程图;
[0052]
图2为本发明实施例提供的节点标签索引构建的流程图;
[0053]
图3为本发明实施例提供的利用强化学习进行时间分片的算法流程图;
[0054]
图4为本发明实施例提供的用于实施dqn的流程图;
[0055]
图5为本发明实施例提供的负载感知的路网最短路径距离计算装置的框图。
具体实施方式
[0056]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
[0057]
在本发明中,本发明及附图中的术语“第一”、“第二”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。
[0058]
参阅图1,结合图2至图4,本发明提供了一种负载感知的路网最短路径距离计算方法,该计算方法包括操作s1-操作s6。
[0059]
操作s1,获取未来某一时段所述路网的预测查询负载和每个节点的预测查询频率。
[0060]
本实施例中,基于历史查询数据来预测未来某一时段路网的预测查询负载和每个节点的预测查询频率。具体包括如下操作:
[0061]
(1)建立交通道路网络的模型
[0062]
交通道路网络通常被抽象为图论中的“图”,可构建一个路网模型g(v,e,w):
[0063]
v={vi|i=1,2,
…
,n}表示节点集合,即路网中道路的交叉点;
[0064]
e={(vi,vj)|vi,vj∈v}表示边的集合,即路网中的道路,对于有向图(vi,vj)和(vj,vi)指不同的边;
[0065]
w={w(vi,vj)|vi,vj∈v}表示权重集,可选择不同的标准作为权重,一般设置为道路的距离或者行驶时间。
[0066]
(2)处理历史查询数据
[0067]
将例如出租车订单数据等包含起点和终点信息的轨迹数据中的起点和终点分别匹配到g中的节点上,获得不同时间段t内的查询负载q={qi(si,ti)},其中q(s,t)表示一次最短路径查询,其返回起点s和终点t之间最短路径的距离dist(s,t);
[0068]
(3)模型训练与预测
[0069]
将历史20天的查询数据作为训练集输入训练模型中进行训练,从而预测得到未来10天的查询负载以及路网中每个点的查询频率fv(v∈v)。
[0070]
s2,将所述预测查询负载中出现的节点按预设频率划分为初始高频点和初始低频点;按照各所述初始低频点重要性值由小到大的顺序依次进行移除,当剩余节点的最小度超过设定阈值或者各所述初始低频点全部移除完毕时,停止移除,被移除的节点为最终低频点,其余节点为最终高频点。
[0071]
本实施例中,为了能够提取出层级结构,将查询负载q中出现的点vq按照预设频率划分为初始高频点和初始低频点,例如将查询频率超过10次的节点划分为初始高频点,其余节点划分为初始低频点。
[0072]
进一步地,为了使得树分解得到的树结构尽量最优,即树宽度和树高度尽可能小,首先利用分块技术将初始低频点按照查询频率由小到大排序后放入不同的块b={bi|i=1,2,
…
,n}中,每个块大小不超过η,η参数范围为(1,100),例如可以设置为30。再按照以下
公式计算各初始低频点重要性值:
[0073][0074]
其中,σ(u)表示节点u的重要性值;γ表示第一权重参数,范围为(0,1.0),本实施例中设置为0.1;bi表示节点u所属的块,b1和bn分别表示第一个分块和最后一个分块;和分别表示节点ui、u1、un的查询频率;和分别表示属于bi、b1和bn的节点的查询频率之和;du表示节点u的度大小,d
max
表示节点最大度。
[0075]
然后按照重要性值由小到大的顺序依次处理各初始低频点,当处理节点u时,连同其邻居节点ng′
(u)构成x(v),并保存到其邻居的边权值w
′
(u,v)。为了保证剩下的图是距离保留图,需要在删除节点及其邻接边前进行填边或者边权值更新操作,每处理完一个节点余下的图表示为g
′
(v
′
,e
′
,w
′
)。
[0076]
当剩余节点的最小度超过设定阈值ω
max
或者各初始低频点全部移除完毕时,停止移除,被移除的点即是最终低频点v
l
,剩下的距离保留图g
′
为高层覆盖图g
*
,重新定义其中包含的点为最终高频点vh。其中ω
max
取值范围为(0,100),本实施例中设置为30。
[0077]
s3,遍历各所述最终低频点,若当前节点的所有邻居节点都属于最终高频点,则将所述当前节点设置为根节点,并保存其邻居节点为所属树对应的边界点;否则,根据树分解过程中保存的移除顺序,设置最先移除的邻居节点为所述当前节点的父节点。
[0078]
本实施例中,遍历各最终低频点,若当前节点的所有邻居节点都属于最终高频点,则将当前节点设置为根节点,并保存其邻居节点为所属树tk对应的边界点vbk;否则,根据树分解过程中保存的移除顺序,设置最先移除的邻居节点为所述当前节点的父节点。对所有最终低频点进行连接操作就成功将树分解过程中形成的由最终低频点组成的区域转化为了森林t={tk}。
[0079]
s4,按照各所述最终高频点重要性值由大到小的顺序进行pll算法,依次构建各所述最终高频点的标签索引。
[0080]
本实施例中,基于节点重要性值,利用先进行标签索引构建的节点标签索引小于后进行标签索引构建的节点的算法特性以及查询时间与标签索引成线性关系,提高高频点的排序来减小高频点的标签索引大小从而减小整个查询负载的查询时间。
[0081]
首先同时考虑路网结构特征和查询频率来计算节点重要性,节点重要性的计算公式为:其中,σ(v)表示节点v的重要性值,表示归一化处理后节点v的查询频率,代表节点的查询重要性,表示归一化处理后节点v的中介中心度,用于近似估算经过节点v的最短路径数量,即节点v在路网特征中的重要性,β参数用来平衡查询重要性和结构重要性,参数范围为(0,1.0),本实施例中设置为0.1。
[0082]
然后按照各所述最终高频点重要性值由大到小的顺序,依次对每个节点x进行dijkstra搜索,并且只搜索重要性值比节点x小的节点y,得到二元组(x,dist(x,y)),dist(x,y)表示节点x和y之间的距离;若利用节点x和y已有的标签索引能够计算得到节点x和y
之间的最短路径距离,则进行剪枝,否则将所述二元组添加到节点y的标签索引中。
[0083]
操作s5,将每一棵树对应的边界点添加到该树的根节点上,并利用各所述边界点对应的标签索引计算得到各边界点之间的最短距离,再基于h2h构建各所述最终低频点的标签索引。
[0084]
本实施例中,对于最终低频点v
l
∈v
l
,采用一种从上到下的索引构建方式,该过程和h2h索引构建类似,区别在于本发明需要将每一棵树对应的边界点添加到该树的根节点上,并利用各边界点对应的标签索引计算得到各边界点之间的最短距离,再基于h2h构建各最终低频点的标签索引。其中,每个最终低频点的索引标签由两部分构成,其中,位置数组pos(v
l
)保存了x(v
l
)中点所处的树高度(根节点为1),并在位置数组的第一个位置保存根节点编号,距离数组dis(v
l
)保存了节点v
l
到所有祖先节点的最短距离。由于每棵树是互斥的,为了加快构建速度,该过程采用多线程并行计算进行计算加速,一般设置并行线程数为5。
[0085]
进一步地,由于查询负载随着时间会动态变化,为了能更好地捕捉连续时间片段查询分布的相似性,对时间段进行划分后指导索引的构建,从而进一步优化查询性能,本发明将未来某一时段进行分片操作,得到查询分布相似的多个时间间隔,再针对每一时间间隔构建对应的最终高频点和最终低频点的标签索引。具体分片过程如下:
[0086]
(1)时间分片问题建模成马尔可夫决策过程
[0087]
本实施例中,时间分片是将一天按照15分钟进行划分,得到共96个时间片段,并最终将96个时间片段分成5个时间间隔,该过程可以建模成马尔可夫决策过程,马尔可夫决策过程包含四要素。
[0088]
状态s,一个状态表示成一个五元组其中,tj表示当前时间片段,j=1,2,
…
,m,ρ
*
表示上一个建立标签索引的时间间隔的查询负载,ρj表示当前时间片段的查询负载,表示上一个建立标签索引的时间间隔和当前时间片段的jensen-shannon散度,c表示已经划分的时间间隔的数量;
[0089]
行为a,一个行为用数字0或1表示,0表示不在当前时间片段分片,1表示在当前时间片段分片;
[0090]
奖励r,一个奖励r表示对当前做出的行为a的一个评价,表示为奖励r,一个奖励r表示对当前做出的行为a的一个评价,表示为其中,v表示所述路网中所有节点的集合,f
i,j
表示在tj时间片段节点vi的查询频率,cost
*
(vi)表示利用t
*
建立标签索引查询节点vi的开销,t
*
表示上一个已经划分好的时间间隔;奖励越高,表示决策做的越好;
[0091]
状态转移,一个状态转移(s,a,r,s
′
)表示在当前状态s下选择行为a,得到奖励r,并进入下一个状态s
′
。
[0092]
解决马尔可夫决策问题的关键是找到一个行为函数q(s,a;θ)来做决策,使得得到的累计奖励∑λk·rji
最大,其中λ表示衰减因子。
[0093]
(2)运用深度神经网络进行强化学习
[0094]
强化学习的框架图参照图4所示,包含了环境,两个神经网络,和一个经验回放池。环境是对时间分片问题的建模,环境会提供当前时间片段的状态信息s,接收是否分片的行为决策a,返回奖励r和下一个时间片段的状态信息s
′
。两个神经网络,一个是行为网络,用来模拟行为函数q(s,a;θ),另一个是目标网络,帮助训练行为网络。行为网络和环境不断地
交互过程,产生一系列的经验(a,s,r,s
′
),这些经验被存入经验回放池中,每一次取出一批经验训练行为网络。
[0095]
(3)基于强化学习的时间分片算法的训练
[0096]
基于强化学习的时间分片选择算法训练过程如下。首先,用随即参数初始化行为网络q(s,a;θ),初始化目标网络的参数和行为网络一样,即θ-=θ。初始化经验回放池的容量为m。然后,算法会经历me个周期,每一个周期中,都会经历t个时间步,从第一个时间片段开始,从环境中得到状态s,使用行为网络q(s,a;θ)按照∈-greedy策略做出是否分片的决策,即,以∈的概率做出随机选择,以1-∈的概率选择∈的概率选择如果a=1,就在当前时间片段分片,如果a=0,就不进行分片。做出选择之后,会得到环境的反馈r,并进入下一个状态s
t+1
,直到到达最后一个时间片段。每一条经验都会被存入经验回放池中,每隔一段时间,从经验回放池中抽取一部分的经验,利用随机梯度下降法训练行为网络q(s,a;θ)的参数,误差函数l(θ)=[y
t-q(s
t
,a
t
;θ)]2,其中,y
t
的定义如下:
[0097][0098]
经过强化学习之后,连续的时间分片按照查询频率分布的相似性进行了划分。
[0099]
s6,基于所述最终高频点和最终低频点的标签索引,计算对应时段的真实查询负载中每个查询的最短路径距离。
[0100]
本实施例中,针对实时的批量查询负载q
′
,利用已经构建的负载感知的最短路径距离标签索引来计算对应时间段的查询负载q
′
中每个查询q(g,h)的最短路径距离dist(g,h),并返回最终结果,主要包括:
[0101]
(1)当节点g和h都属于最终高频点时,在节点g和h的标签索引中寻找共同节点k,以节点g到共同节点k的距离与节点h到共同节点k的距离之和的最小值作为节点g到h的最短路径距离,即:
[0102]
dist(g,h)=min
k∈l(g)∩l(h)
{dist(g,k)+dist(h,k)}
[0103]
(2)当节点g属于最终高频点,节点h属于最终低频点时,若节点g属于边界点,则直接返回节点h中存储的到节点g的最短路径距离;否则,以节点h所属树中每个边界点到根节点的距离加上根节点到节点g的距离之和的最小值作为节点g到h的最短路径距离;
[0104]
(3)当节点g和h都属于最终低频点时,利用节点g和h标签索引中位置数组的第一个位置pos(g)[1]和pos(h)[1]判断节点g和h是否属于同一棵树;
[0105]
1)若节点g和h属于同一棵树,则依次遍历节点g和h的最小共同祖先节点lca(g,h)中的位置数组并比较节点g和h到各位置数组对应节点的距离之和,取最小值作为结果返回,即:
[0106]
dist(g,h)=min
i∈pos(lca(g,h))
{dis(g)[i]+dis(h)[i]}
[0107]
2)若节点g和h不属于同一棵树,则分别将节点g所在树的边界点和节点h所在树的边界点的标签索引按照类似归并排序的过程赋给节点g和h,并在节点g和h的标签索引中寻找共同节点,以节点g到共同节点的距离与节点h到共同节点的距离之和的最小值作为节点
g到h的最短路径距离。
[0108]
图5为本发明实施例提供的负载感知的路网最短路径距离计算装置的框图。参阅图5,该负载感知的路网最短路径距离计算装置500包括预测数据获取模块510、层级结构构建模块520、森林构建模块530、标签索引构建模块540以及最短路径距离计算模块550。
[0109]
预测数据获取模块510例如执行操作s1,用于获取未来某一时段所述路网的预测查询负载和每个节点的预测查询频率;
[0110]
层级结构构建模块520例如执行操作s2,用于将所述预测查询负载中出现的节点按预设频率划分为初始高频点和初始低频点;按照各所述初始低频点重要性值由小到大的顺序依次进行移除,当剩余节点的最小度超过设定阈值或者各所述初始低频点全部移除完毕时,停止移除,被移除的节点为最终低频点,其余节点为最终高频点;
[0111]
森林构建模块530例如执行操作s3,用于遍历各所述最终低频点,若当前节点的所有邻居节点都属于最终高频点,则将所述当前节点设置为根节点,并保存其邻居节点为所属树对应的边界点;否则,根据树分解过程中保存的移除顺序,设置最先移除的邻居节点为所述当前节点的父节点;
[0112]
标签索引构建模块540例如执行操作s4和s5,用于按照各所述最终高频点重要性值由大到小的顺序进行pll算法,依次构建各所述最终高频点的标签索引;以及将每一棵树对应的边界点添加到该树的根节点上,并利用各所述边界点对应的标签索引计算得到各边界点之间的最短距离,再基于h2h构建各所述最终低频点的标签索引;
[0113]
最短路径距离计算模块550例如执行操作s6,用于基于所述最终高频点和最终低频点的标签索引,计算对应时段的真实查询负载中每个查询的最短路径距离。
[0114]
负载感知的路网最短路径距离计算装置500用于执行上述图1所示实施例中的负载感知的路网最短路径距离计算方法。本实施例未尽之细节,请参阅前述图1所示实施例中的负载感知的路网最短路径距离计算方法,此处不再赘述。
[0115]
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1