一种用于过滤垃圾邮件的方法
1.本发明涉及信息安全技术领域,具体为一种用于过滤垃圾邮件的方法。
背景技术:
2.电子邮件(e-mail)以其方便、快捷、低成本的独特魅力成为人们日常生活中不可缺少的通信手段之一。但电子邮件给人们带来极大便利的同时,也日益显示出其负面影响,出现了通过电子邮件进行的广告推销和诈骗犯罪等行为,而含有诈骗、推销和不良内容的电子邮件就被称为垃圾邮件,这种邮件已经严重危害人们的日常生活和工作,过滤掉包含这种信息的邮件从而保障人们生活安全和质量成为重中之重。
3.垃圾邮件没有一个统一的定义,一般被理解为“不请自到的邮件”还有一些垃圾邮件是因为它所带的附件包含有病毒,或所含的链接是一个病毒网站,垃圾邮件过滤就是识别出所接收到的邮件中哪些邮件是对接收方完全没有意义的邮件,并进行拦截,删除等操作。
4.垃圾邮件一般具有批量发送的特征。其内容包括赚钱信息、成人广告、商业或个人网站广告、电子杂志、连环信等。垃圾邮件可以分为良性和恶性的。良性垃圾邮件是各种宣传广告等对收件人影响不大的信息邮件。恶性垃圾邮件是指具有破坏性的电子邮件。
5.有些垃圾邮件发送组织或是非法信息传播者,为了大面积散布信息,常采用多台机器同时巨量发送的方式攻击邮件服务器,造成邮件服务器大量带宽损失,并严重干扰邮件服务器进行正常的邮件递送工作。
技术实现要素:
6.本发明针对上述现有技术存在的不足,提供一种用于过滤垃圾邮件的方法。
7.为了解决上述技术问题,本发明提供了如下的技术方案:
8.一种用于过滤垃圾邮件的方法,包括以下步骤:
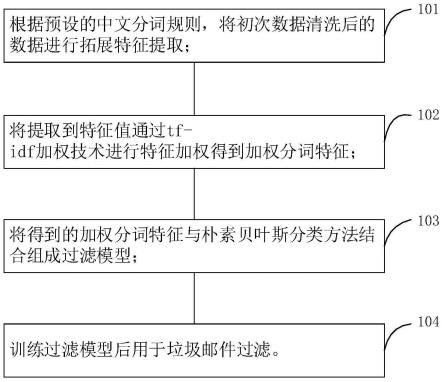
9.根据预设的中文分词规则,将初次数据清洗后的数据进行拓展特征提取;
10.将提取到特征值通过tf-idf加权技术进行特征加权得到加权分词特征;
11.将得到的加权分词特征与朴素贝叶斯分类方法结合组成过滤模型;
12.训练过滤模型后用于垃圾邮件过滤。
13.作为本发明的进一步技术方案为,所述根据预设的中文分词规则,将初次数据清洗后的数据进行拓展特征提取;具体包括:所述过滤模型通过卡方统计(统计)选择重要的特征,引入tf-idf加权技术来减少朴素贝叶斯分类器对于属性相互独立的依赖。
14.作为本发明的进一步技术方案为,所述将提取到特征值通过tf-idf加权技术进行特征加权得到加权分词特征;具体包括:
15.通过卡方处理后得到分词文档矩阵;
16.通过tf-idf加权技术对每个特征进行加权;
17.运用k-mean聚类,通过多次迭代来找到最佳的特征数量,将减少的特征集合输出
为分词矩阵。
18.作为本发明的进一步技术方案为,所述通过卡方处理后得到分词文档矩阵;具体为:通过卡方统计(统计)来选择重要的特征,通过卡方处理后可以得到分词文档矩阵,
19.作为本发明的进一步技术方案为,通过卡方处理后得到分词文档矩阵;还包括:通过卡方值来选择重要的分词;具体为:选择高于或者等于阈值的分词,其中,阈值为0;
[0020][0021]
其中d表示文档总数,q是包含属于t的c类文档的数量,p是不包含t的非c类文档的数量,m是不含t的c类文档数量,n是不含t的其他类别文档数量。
[0022]
作为本发明的进一步技术方案为,所述通过tf-idf加权技术对每个特征进行加权,具体包括:
[0023]
根据卡方和k-mean聚类进行数据预处理之后,结合朴素贝叶斯的算法原理,可以得到一个mi*nj的文本和分词特征的矩阵;
[0024]
其中m表示样本邮件,n表示不同的特征属性;
[0025]
因此该数据集可以表示为d={xi,cj},其中xi表示数据预处理后的电子邮件样本,cj表示这样本所属的类别;
[0026]
设定qi是经过分词特征矩阵得出xi的分词特征权重,x
ik
表示样本数据中第i个电子邮件样本中的第k个分词特征属性,同理c
jk
表示特征类别j中所定义的电子邮件样本的类别k。
[0027]
进一步的,作为本发明的进一步技术方案为,所述将得到的加权分词特征与朴素贝叶斯分类方法结合组成过滤模型;具体为:
[0028]
基于特征权重的朴素贝叶斯分类算法的条件概率为:
[0029][0030]
其中,qi是经过分词特征矩阵得出xi的分词特征权重,x
ik
表示样本数据中第i个电子邮件样本中的第k个分词特征属性,同理c
jk
表示特征类别j中所定义的电子邮件样本的类别k;
[0031]
后验概率为:
[0032][0033]
作为本发明的进一步技术方案为,所述训练过滤模型后用于垃圾邮件过滤;具体包括:通过已知的样本数据集对分类模型进行训练,再将构建好的垃圾邮件分类模型对待测邮件样本进行验证;通过计算待测电子邮件中出现的分词特征,来对待测样本进行分类。
[0034]
本发明的有益效果是:
[0035]
本发明提供的一种用于过滤垃圾邮件的方法为基于特征权重的朴素贝叶斯分类模型,减少无用特征来增强朴素贝叶斯分类模型的效率和准确性,同时通过给予不同特征
属性不同的权重来解决传统朴素贝叶斯分类模型对于特征属性相互独立的依赖,从而优化朴素贝叶斯模型来得到一种准确率高的垃圾邮件过滤模型,增强了朴素贝叶斯分类模型的性能并且削弱了原本朴素贝叶斯分类模型基于特征相互独立的影响。结合特征选择和特征权重的朴素贝叶斯分类策略,通过先验概率、后验概率和条件概率三部分组成。优化了传统朴素贝叶斯模型,从而得到准确性更高的过滤模型,更有效地解决人们的信息安全问题。
附图说明
[0036]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
[0037]
图1是本发明提出的一种用于过滤垃圾邮件的方法流程图;
[0038]
图2是本发明提出的一种用于过滤垃圾邮件的方法工作流程图。
具体实施方式
[0039]
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
[0040]
参见图1,本发明提供一种用于过滤垃圾邮件的方法,包括以下步骤:
[0041]
步骤101,根据预设的中文分词规则,将初次数据清洗后的数据进行拓展特征提取;
[0042]
步骤102,将提取到特征值通过tf-idf加权技术进行特征加权得到加权分词特征;
[0043]
步骤103,将得到的加权分词特征与朴素贝叶斯分类方法结合组成过滤模型;
[0044]
步骤104,训练过滤模型后用于垃圾邮件过滤。
[0045]
本发明基于特征权重的朴素贝叶斯分类模型,减少无用特征来增强朴素贝叶斯分类模型的效率和准确性,同时通过给予不同特征属性不同的权重来解决传统朴素贝叶斯分类模型对于特征属性相互独立的依赖,从而优化朴素贝叶斯模型来得到一种准确率高的垃圾邮件过滤模型方法。
[0046]
本发明实施例中,所述根据预设的中文分词规则,将初次数据清洗后的数据进行拓展特征提取;具体包括:所述过滤模型通过卡方统计(统计)选择重要的特征,引入tf-idf加权技术来减少朴素贝叶斯分类器对于属性相互独立的依赖。
[0047]
将以上方法策略引进到朴素贝叶斯方法的条件概率公式中,从而增强了朴素贝叶斯分类模型的性能并且削弱了原本朴素贝叶斯分类模型基于特征相互独立的影响。结合特征选择和特征权重的朴素贝叶斯分类策略,通过先验概率、后验概率和条件概率三部分组成。优化了传统朴素贝叶斯模型,从而得到准确性更高的过滤模型,更有效地解决人们的信息安全问题。
[0048]
所述将提取到特征值通过tf-idf加权技术进行特征加权得到加权分词特征;具体包括:
[0049]
通过卡方处理后得到分词文档矩阵;
[0050]
通过tf-idf加权技术对每个特征进行加权;
[0051]
运用k-mean聚类,通过多次迭代来找到最佳的特征数量,将减少的特征集合输出为分词矩阵。
[0052]
其中,所述通过tf-idf加权技术对每个特征进行加权,具体包括:
[0053]
根据卡方和k-mean聚类进行数据预处理之后,结合朴素贝叶斯的算法原理,可以得到一个mi*nj的文本和分词特征的矩阵;
[0054]
其中m表示样本邮件,n表示不同的特征属性;
[0055]
因此该数据集可以表示为d={xi,cj},其中xi表示数据预处理后的电子邮件样本,cj表示这样本所属的类别;
[0056]
设定qi是经过分词特征矩阵得出xi的分词特征权重,x
ik
表示样本数据中第i个电子邮件样本中的第k个分词特征属性,同理c
jk
表示特征类别j中所定义的电子邮件样本的类别k。
[0057]
本发明实施例中,将得到的加权分词特征与朴素贝叶斯分类方法结合组成过滤模型;具体为:
[0058]
基于特征权重的朴素贝叶斯分类算法的条件概率为:
[0059][0060]
其中,qi是经过分词特征矩阵得出xi的分词特征权重,x
ik
表示样本数据中第i个电子邮件样本中的第k个分词特征属性,同理c
jk
表示特征类别j中所定义的电子邮件样本的类别k;
[0061]
后验概率为:
[0062][0063]
通过结合特征权重的朴素贝叶斯分类策略,对传统的朴素贝叶斯算法进行改进,并将添加量信号量的样本数据集保存为数据样本,形成过滤模型。
[0064]
其中,所述过滤模型通过卡方统计(统计)来选择重要的特征,具体为,通过卡方值来选择重要的分词;通过卡方处理后可以得到分词文档矩阵,
[0065]
通过卡方处理后得到分词文档矩阵;还包括:通过卡方值来选择重要的分词;具体为:选择高于或者等于阈值的分词,其中,阈值为0;
[0066]
公式如下:
[0067][0068]
其中d表示文档总数,q是包含属于t的c类文档的数量,p是不包含t的非c类文档的数量,m是不含t的c类文档数量,n是不含t的其他类别文档数量。
[0069]
本发明实施例中,所述训练过滤模型后用于垃圾邮件过滤;具体包括:通过已知的样本数据集对分类模型进行训练,再将构建好的垃圾邮件分类模型对待测邮件样本进行验证;通过计算待测电子邮件中出现的分词特征,来对待测样本进行分类。
[0070]
本发明基于朴素贝叶斯算法的原理和分类方法,根据已知的经验得出先验概率,再通过先验概率来预测样本数据的后验概率。而在技术方案中朴素贝叶斯分类模型是通过
已知的样本数据集对分类模型进行训练,再将构建好的垃圾邮件分类模型对待测邮件样本进行验证的过程。通过计算待测电子邮件中出现的分词特征,来对待测样本进行分类。将加权分词特征和特征过滤结合到朴素贝叶斯分类方法中,应用到本发明的垃圾邮件过滤当中。
[0071]
本发明通过卡方统计(统计)来选择重要的特征,引入tf-idf加权技术来减少朴素贝叶斯分类器对于属性相互独立的依赖,将以上方法策略引进到朴素贝叶斯方法的条件概率公式中,从而增强了朴素贝叶斯分类模型的性能并且削弱了原本朴素贝叶斯分类模型基于特征相互独立的影响。结合特征选择和特征权重的朴素贝叶斯分类策略,通过先验概率、后验概率和条件概率三部分组成。优化了传统朴素贝叶斯模型,从而得到准确性更高的过滤模型,更有效地解决人们的信息安全问题。
[0072]
本发明通过对邮件本文的特征属性提取和特征属性加权,解决了朴素贝叶斯模型对于属性特征相互独立的依赖,可以得到更加准确的分类结果,从而更加准确的对垃圾邮件进行过滤,有效的解决了人们日常生活中的信息安全问题。
[0073]
本发明可以长期自动过滤垃圾邮件,将模型训练完成后,只需要与相关软件进行结合就可以长期自动工作,不需要进行多余操作就可以过滤垃圾邮件,可以同时过滤大量邮件,摆脱了人工查验的困扰。
[0074]
其中,垃圾邮件过滤模型可以同时用于pc端和手机端,全面解决垃圾邮件的困扰。
[0075]
参见图2,为本发明提供的一具体实施例结构图,一种用于过滤垃圾邮件的方法,包括模型训练与模型应用;
[0076]
首先通过卡方值来选择重要的分词,仅选择高于或者等于阈值的分词;本文中选择的阈值为0;卡方通常用于测试t和c之间的缺乏独立性(其中t表示项,c表示类别);公式如下:
[0077][0078]
其中d表示文档总数,q是包含属于t的c类文档的数量,p是不包含t的非c类文档的数量,m是不含t的c类文档数量,n是不含t的其他类别文档数量。
[0079]
通过卡方处理后可以得到分词文档矩阵,例如:有三个文档d1、d2、d3和四个分词w1、w2、w3、w4。如下表:
[0080][0081]
本发明实施例中,单个特征,即分词,可以表示他们在文档中的出现,所以w1可以表示为向量{1.1,2.3,1.0},通过这种方式本文认为当这个向量越接近,则表示两个特征约相似。
[0082]
通过tf-idf加权技术对每个特征进行加权,然后运用k-mean聚类,通过多次迭代
来找到最佳的特征数量,将减少的特征集合输出为分词矩阵。
[0083]
根据卡方和k-mean聚类进行数据预处理之后,结合朴素贝叶斯的算法原理,可以得到一个mi*nj的文本和分词特征的矩阵。其中m表示样本邮件,n表示不同的特征属性。因此该数据集可以表示为d={xi,cj},其中xi表示数据预处理后的电子邮件样本,cj表示这样本所属的类别。
[0084]
设定qi是经过分词特征矩阵得出xi的分词特征权重,x
ik
表示样本数据中第i个电子邮件样本中的第k个分词特征属性,同理c
jk
表示特征类别j中所定义的电子邮件样本的类别k。
[0085]
基于以上属性参数,得出基于特征权重的朴素贝叶斯分类算法的条件概率为:
[0086][0087]
后验概率为:
[0088][0089]
通过结合特征权重的朴素贝叶斯分类策略,对传统的朴素贝叶斯算法进行改进,并将添加量信号量的样本数据集保存为数据样本,为后面的模型训练做准备。
[0090]
将训练样本导入模型中进行训练,得到训练好模型直接用于待分类邮件中起到过滤垃圾邮件的效果。
[0091]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1