一种射孔大数据的开放应用平台的构建方法与流程
本发明涉及大数据处理,尤其涉及测井射孔作业大数据处理,更具体地说涉及一种射孔大数据的开放应用平台的构建方法。
背景技术:
1、随着射孔工艺技术不断发展,储层条件的不断变差,以往的研究成果算法准确率低、优化模型适应性差,无法满足现阶段复杂油气藏的开发。同时随着“地质工程一体化”对射孔提出了“多样化”、“个性化”的设计要求,以及人工智能和大数据技术的蓬勃发展。人们迫切希望能通过大数据和人工智能技术来解决信息孤岛和软件碎片化的问题。
2、近年来,虽然国内外诸多企业一直在尝试利用大数据技术在油气藏开放方面进行相关研究,但相比于国外(美国howard county利用大数据关联分析寻找非常规油气甜点),国内仍处于起步阶段,此项研究仍需伸入,其预报研究工作还比较少见。
技术实现思路
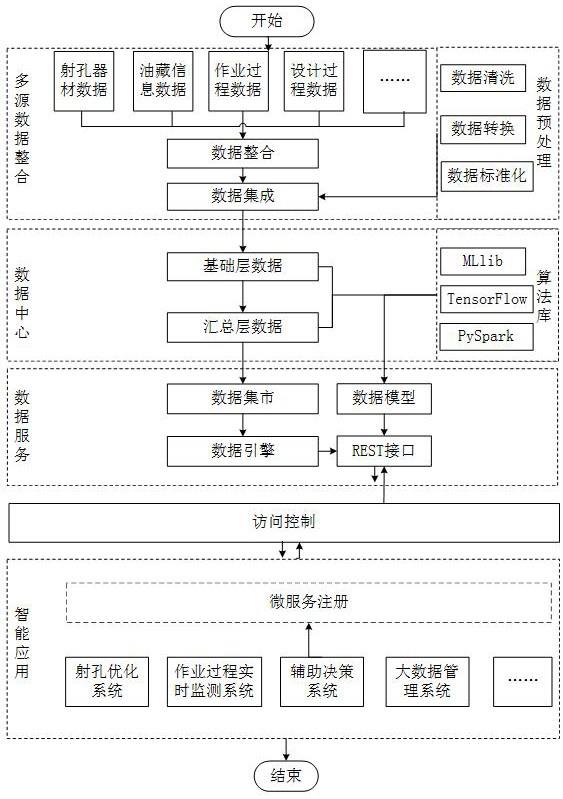
1、为了克服上述现有技术中存在的缺陷和不足,本发明提供了一种射孔大数据的开放应用平台的构建方法,本发明在上述背景下,通过hadoop大数据生态技术构建一种基于射孔大数据的开放应用平台,通过大数据平台可以在底层汇聚所有射孔行业的数据,打通数据壁垒解决数据孤岛问题,从而使得通过数据挖掘方法,建立射孔层位、压力层位与生产数据之间的关联规则成为可能;利用微服务架构,对应用服务进行拆解、最终实现软件自由挂载,解决软件碎片化问题。本发明利用大数据技术对射孔工程中涉及的数据进行平台化建设,首先将射孔工程相关烟囱数据进行数据集成,然后利用hadoop、spark和微服务技术来实现数据的清洗、转换与分析存储,最后根据实际应用需求以统一标准的rest api接口来提供数据应用服务。本发明通过hadoop分布式体系结构和实时流处理技术实现射孔工程相关烟囱数据的融合与汇聚,为射孔工程的“地质工程一体化”要求提供数据基础。通过微服务技术解决射孔工程中软件碎片化问题,实现软件模块自由挂载;本发明可使射孔行业决策模式从传统的专家经验逐渐转变为“用数据说话”的数据驱动模式。
2、为了解决上述现有技术中存在的问题,本发明是通过下述技术方案实现的。
3、本发明提供了一种射孔大数据的开放应用平台的构建方法,该方法采用hadoop分布式体系结构为基础,具体包括以下步骤:
4、s1、数据集成步骤:获取射孔业务原始数据,通过kettle完成数据etl过程;
5、s2、数据预处理步骤:通过数据预处理手段完成对数据集成步骤处理后的多源异构数据的清洗、转换和标准化处理;
6、s3、数据中心构建步骤:通过对底层数据的数据集成和数据预处理后,采用雪花模型构建数据仓库完成数据的分层管理;
7、s4、数据模型构建步骤:基于用户业务需求完成数据筛选,结合spark计算框架中已有算法或自定义算法构建满足用户业务需求的算法模型并存储;
8、s5、数据服务与访问控制:以统一标准的rest api接口对外提供数据服务,并增加token身份认证进行接口访问权限控制;
9、s6、智能应用的微服务架构:对各智能应用进行微服务拆分和微服务注册。
10、进一步的,所述s1数据集成步骤中,射孔业务原始数据包括半结构化数据和结构化数据,所述半结构化数据为实时数据,具体是指作业车产生的现场作业数据;所述结构化数据为传统关系模型业务系统中生成的数据,包括射孔器材、射孔效果和油藏信息。
11、进一步的,s1数据集成步骤中,对于半结构化数据进行数据映射,并将完成数据映射的半结构化数据与结构化数据统一通过kettle完成数据etl过程。
12、进一步的,对于半结构化数据,采用基于人工提取的表头信息,通过计算机自动抽取相应字段信息完成数据映射。
13、更进一步的,所述s1数据集成步骤包括以下子步骤:
14、s101、通过kettle将数据源为传统关系模型业务系统的结构化数据传输到hdfs文件系统中;
15、s102、通过采用flume+kafka的方式完成半结构化数据的实时写入,即采用flume作为消息的生产者,在每个作业车的后端服务中安装agent代理,通过agent代理将现场作业数据通过kafka sink发布到kafka中,同时采用kafka channel作为flume的channel,在spark streaming进行流式数据分析或直接存储在hbase中。
16、更进一步的,所述s2数据预处理步骤中,数据预处理手段包括缺失值处理、噪声数据处理和数据归一化处理中的一种或多种的组合。
17、进一步的,所述s2数据预处理步骤包括以下子步骤:
18、s201、数据清洗,修正填写不规范的字段,去除噪声数据;射孔数据缺失值处理,直接剔除缺失程度大于70%的行或列;对射孔噪声数据采用统计学假设检验和人工检验出可疑值的方法进行离群点检测;
19、s202、数据转换,通过数据规范化进行数据转换,确保数据一致性;
20、s203、进行多源数据关联整合,且在多源数据关联整合的过程中,对字段进行统一标准化处理;同时,通过构建模型依据相关联字段的数据值预测缺失字段的值,以补全数据。
21、所述s3数据中心构建步骤包括以下子步骤:
22、s301、梳理射孔业务逻辑和射孔业务原始数据,采用雪花模型完成数据仓库逻辑设计,制定数据更新策略,完成数据仓库基础层构建;
23、s302、根据应用需求,设计汇总层数据指标并根据应用需求构建数据集市。
24、所述数据更新策略具体是指,传统关系模型业务系统中生产的结构化数据按天进行更新,现场作业数据实时更新。
25、所述s4数据模型构建步骤包括以下子步骤:
26、s401、根据用户业务需求少选数据,基于s3数据中心构建步骤构建的数据中心中数据仓库基础层的基础数据和汇总层信息筛选出构建模型需要的数据;
27、s402、根据应用需求选取算法,从机器学习算法库或人工神经网络算法库中选取一种合适有效的算法构建数据模型;
28、s403、对s402步骤构建的数据模型进行评估,评价该数据模型是否满足实际应用需求,若通过模型评估,则将该数据模型作为业务应用模型;若未通过模型评估,则重复上述s401和s402步骤,直至满足实际应用需求为止。
29、所述s5数据服务与访问控制包括以下子步骤:
30、s501、上层应用根据其自身需求提出接口开发需求,根据该接口开发需求开发出标准的rest kpi接口供上层应用调用;
31、s502、采用动态token技术完善安全访问控制。
32、所述s502步骤,具体为:当第一次登录后,服务器根据用户信息生成一个token,将生成的token返回给客户端,以后客户端只需带上该token请求数据。
33、所述s6智能应用的微服务架构包括以下子步骤:
34、s601、对智能应用按照服务拆分原则,拆分为多个微服务;
35、s602、拆分的微服务进行注册请求,所有请求皆通过网关zull进行权限认证,认证通过后网关会从注册中心eureka拉群活跃的服务列表,并将请求转发到对应的服务。
36、所述服务拆分原则包括单一职责拆分和面向服务拆分;单一职责拆分是指一个微服务解决一个业务问题;面向服务拆分是指,将自己的业务能力封装并对外提供服务,及将不同应用单独设置为微服务。
37、每一个微服务都运行在docker提供的虚拟容器中,分布在不同的物理机上,且每一个微服务都存在多个,网关转发时会根据负载均衡策略发送到某一个应用服务进行处理;所有应用微服务产生的数据均汇入地数据中心,通过定时任务更新到数据仓库。
38、与现有技术相比,本发所带来的有益的技术效果表现在:
39、1、通过大数据平台可以在数据中心汇聚所有射孔行业的数据,打通数据壁垒,有效解决射孔行业数据孤岛问题,形成唯一、标准的数据。
40、2、针对射孔行业数据和业务特点,通过从数据采集、预处理、分析到应用进行全流程、多角度的系统化设计,能有效构建一套完善的射孔大数据开放应用服务平台。
41、3、利用微服务架构,对应用服务进行拆解、最终实现软件自由挂载,有效解决射孔行业软件碎片化的问题。
42、4、射孔大数据开放应用服务平台建设方法极具推广价值,且对能源领域其他行业具有重要借鉴意义。
- 还没有人留言评论。精彩留言会获得点赞!