一种基于RFM模型泛化特征的金融类客户分级方法与流程
一种基于rfm模型泛化特征的金融类客户分级方法
技术领域
1.本发明涉及数据分类技术领域,特别是涉及一种基于rfm模型泛化特征的金融类客户分级方法。
背景技术:
2.rfm模型是衡量客户价值和客户创利能力的重要工具和手段。在众多的客户关系管理(crm)的分析模式中,rfm模型是被广泛提到的。该模型通过一个客户的近期购买行为、购买的总体频率以及花了多少钱3项指标来描述该客户的价值状况。最近一次消费(recency)指上一次购买距指定时间过去了多久。消费频率(frequency)指顾客在限定的期间内所购买的次数。消费金额(monetary)指顾客在限定期间内购买金额减去退货金额的差值,也就是顾客带来的净收入。rfm就是从最近消费时间、消费频率和消费金额三个维度去衡量客户的价值,进而进行分级。
3.传统rfm模型进行客户分级:r表示最近一次消费时间(recency),可取最近一次消费记录到当前时间的间隔,如7天、30天、90天未消费;f表示一定时间内消费频率(frequency),一般是一个时间段内用户消费频率;m表示一定时间内累计消费金额(monetary),一般是取一个时间段内用户消费金额;本质上是一种用三个分类维度,找判断标准方法;通过三个维度的组合计算,能判定出客户的分级,然后采取对应措施。
4.但本技术发明人在实现本技术实施例中发明技术方案的过程中,发现上述技术至少存在如下技术问题:
5.1、传统rfm模型过度依赖人工进行客户分级;
6.2、传统rfm模型在建模时所考虑的数据特征比较少,不能在特定业务上反应实际金融客户的分级情况。
7.基于此,本发明设计了一种基于rfm模型泛化特征的金融类客户分级方法,以解决上述问题。
技术实现要素:
8.为了解决目前背景技术提及的技术问题,本发明的目的是提供一种基于rfm模型泛化特征的金融类客户分级方法。
9.为了实现上述目的,本发明采用如下技术方案:
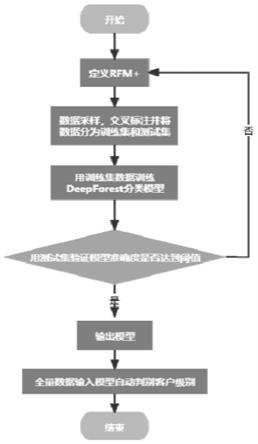
10.一种基于rfm模型泛化特征的金融类客户分级方法,包括以下步骤:
11.s1、采集客户数据,随机抽取预定比例的样本数据进行交叉标注;其中,所述客户数据包括rfm指标数据和针对特定场景的附加特征数据;
12.s2、对标记数据进行特征处理,并进行机器学习模型训练;
13.s3、在机器学习模型中对全量客户数据进行特定金融场所的分析处理。
14.优选的,所述交叉标注包括:
15.随机打乱需要标注的样本数据,通过多数原则标明抽取的客户级别。
16.优选的,所述对标记数据进行特征处理包括:
17.对已经标注的数据进行归一化处理,使每个特征的数据范围收敛到相同数量级。
18.优选的,所述机器学习模型训练包括:
19.将训练数据输入至分类算法供模型拟合训练,并将得到模型通过随机抽取数据验证模型分类是否准确,其中,标注数据包括训练数据和随机抽取数据。
20.优选的,所述训练数据和随机抽取数据的数据量比优选为7:3。
21.优选的,所述在机器学习模型中对全量客户数据进行特定金融场所的分析处理包括:
22.判断分类准确度是否达到业务期望阈值,若未达到期望阈值,提升分类准确度。
23.优选的,所述提升分类准确度包括:
24.重新定义rfm模型,并增加新特征,再次进行数据处理和模型训练,使分类准确度终值达到期望阈值。
25.本发明实施例中提供的一个或多个技术方案,至少具有如下技术效果或优点:
26.1、本发明通过机器学习的方式自动化对客户进行人员分级,降低了人力分级所消耗的成本;
27.2、本发明通过rfm模型结合不同金融场景下增加的特定场景特征,通过随机抽样并进行数据标注的方式结合分类算法进行客户分级,实现不同场景不同的客户分级,能促进场景化营销的精准性;
28.综上所述,本发明特别适用于不同金融场景下的客户精准性分级处理。
附图说明
29.以下结合附图和具体实施方式来进一步详细说明本发明:
30.图1为本发明分级方法分级过程的流程图;
31.图2为本发明采样数据的表图
具体实施方式
32.以下由特定的具体实施例说明本发明的实施方式,熟悉此技术的人士可由本说明书所揭露的内容轻易地了解本发明的其他优点及功效。
33.实施例一
34.请参阅图1至图2,本发明提供一种技术方案:一种基于rfm模型泛化特征的金融类客户分级方法,包括以下步骤:
35.s1、采集客户数据,随机抽取预定比例的样本数据进行交叉标注;其中,所述客户数据包括rfm指标数据和针对特定场景的附加特征数据;
36.s2、对标记数据进行特征处理,并进行机器学习模型训练;
37.s3、在机器学习模型中对全量客户数据进行特定金融场所的分析处理。
38.通过上述步骤不难发现,在本发明的金融类客户分级方法中,将金融场景分别传统的rfm模型和特定金融场景,即获取到的客户数据中包括与传统rfm相对应的rfm指标数据以及与特定金融场景相对应的附加特征数据,通过根据不同金融场景增加不同附加特征数据的方式,结合模型算法对特定金融场景完成自动化客户分级,从而辅助业务部门完成
对客户进行针对性的营销分析。
39.需要说明的是,rfm指标数据包括最近一次动账间隔(r)、近30日动账频次(f)以及近30天日均结算存款(m)。
40.还需要说明的是,针对不同金融场景添加不同场景特征,即为rfm+表示;以借贷场景为例,除了通用定义的rfm所代表的三个基础特征,可以通过增加逾期数、借款金额等其他特征作为场景特征。
41.为了更好的实现对样本数据的标注处理,所述交叉标注包括:
42.随机打乱需要标注的样本数据,通过多数原则标明抽取的客户级别。
43.在本实施例中,从采样客户数据中随机抽取优选为10%的样本数据(若采样数据为45000条,则随机抽取数据为4500条),包含rfm指标数据以及针对特定场景包含附加特征数据(如图2中的借贷场景,包含逾期数和借款金额等),之后,通过业务人员或机器设备识别等方式对样本数据进行交叉标注,并且由于不同业务人员标注的数据可能相同,随机打乱需要标注的样本数据,采取多数原则,快速实现对客户级别的标明。
44.需要说明的是,金融类客户包括但不局限于以下8个级别:1.重要价值用户;2.重要发展客户;3.重要保护客户;4.重要潜力客户;5.一般价值用户;6.一般发展客户;7.一般保护客户;8.一般挽留客户;分别用数字1-8表示。
45.为了实现对标记数据在模型训练前的预处理,所述对标记数据进行特征处理包括:
46.对已经标注的数据进行归一化处理,使每个特征的数据范围收敛到相同数量级。
47.为了实现模型训练,所述机器学习模型训练包括:
48.将训练数据输入至分类算法供模型拟合训练,并将得到模型通过随机抽取数据验证模型分类是否准确,其中,标注数据包括训练数据和随机抽取数据。
49.在本实施例中,通过将已经标记后的数据进行归一化处理后,作为模型训练的训练数据以及验证模型准确性的随机抽取数据,其中,模型训练数据的数据量优选大于随机随机抽取数据量。
50.值得注意的是,该分类模型优选为deepforest算法(森林算法),但也不局限于该类算法,例如逻辑回归、xgboost等均可代替deepforest算法实现本发明。
51.为了更为合理的实现模型训练以及准确性验证,所述训练数据和随机抽取数据的数据量比优选为7:3。
52.例如,结合上述实施内容,将已经标注的数据进行归一化处理,使每个特征的数据范围收敛到相同数量级,同时随机抽取30%的标注且归一化完成的数据作为模型准确性验证测试数据,70%作为模型训练数据,将训练数据输入deepforest算法进行模型拟合训练,得出模型后通过测试数据验证模型分类的准确性。
53.为了更好的实现对特定金融场所的客户分级处理,所述在机器学习模型中对全量客户数据进行特定金融场所的分析处理包括:
54.判断分类准确度是否达到业务期望阈值,若未达到期望阈值,提升分类准确度。
55.在本实施例中,在分类准确度达到业务期望阈值时,优选通过投喂rfm+数据的方式自动判别不同金融场景下客户的分级。
56.需要补充的是,该业务期望阈值优选为95%的准确率。
57.为了实现对分类准确度的处理,所述提升分类准确度包括:
58.重新定义rfm模型,并增加新特征,再次进行数据处理和模型训练,使分类准确度终值达到期望阈值。
59.在本实施例中,通过增加新特征的方式进行客户数据的再次处理和训练,从而实现分类准确度逐渐区域期望阈值,直至达到期望阈值,完成基于金融场景的客户精准分级。
60.上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1