一种文本摘要的生成方法、装置和电子设备与流程
本发明涉及自然语言处理领域,特别是指一种文本摘要的生成方法、装置和电子设备。
背景技术:
1、随着互联网技术的快速发展,新闻平台与网络用户每天都在向互联网中输送大量的新闻信息,人们在日常生活和工作生活总是能接受到大量的新闻信息。在此背景下,能从大量的新闻文字中,归纳总结每一篇新闻的主要内容,可以帮助人们快速地了解新闻包含的主要内容,减少消耗在阅读上的时间,提升阅读的效率。
2、现有生成文本摘要的方式主要有两种方式,第一种方式为生成式摘要生成方式,生成式摘要生成方式基于深度学习模型,对全文信息深度理解、训练,再生成一定长度的摘要文本,但在实际的工程应用中,生成的文本长度不足,不能够完整的概括全新信息,且句子中容易出现异常词语,影响句子的可读性;其次,生成式摘要的模型需要大量的语料进行训练,虽然这一点可以使用大规模预训练模型得到缓解,但对于特定领域,仍然需要使用大量的语料来进行下游任务的训练,这是一项耗费人力物力的工作。即生成式摘要生成方式输出摘要的精确度较高,但生成的摘要不符合人们的阅读习惯,可读性较差。
3、第二种方式为抽取式摘要生成方式,抽取式摘要生成方式分为有监督抽取式方法和无监督抽取式方法。有监督抽取式方法,使用分类模型对文中的每个句子进行分类,这与其他监督式方法相同,需要足够多的训练集进行训练,因此也需要重新标注数据;无监督式抽取方法无需借助其他的语料进行训练,即可挑选出合适的句子作为摘要,但该方法使用句子-句子或词语-词语之间的关系进行建模,忽略了文本句子-词语之间的联系,导致一些关键词与句子之间的关系无法嵌入到模型中进行训练。即抽取式摘要生成方式,该种方式生成的摘要冗余,并且由于利用的特征较少,输出摘要的精确度较低,不能准确代表文档的含义。
技术实现思路
1、本发明的目的是提供一种文本摘要的生成方法、装置及设备,该方法通过利用文档词语之间以及句子和词语之间的关系更好地评估句子和词语的重要性,能够同时为文档生成更好的摘要和关键词。
2、为达到上述目的,本发明的实施例提供一种文本摘要的生成方法,包括:
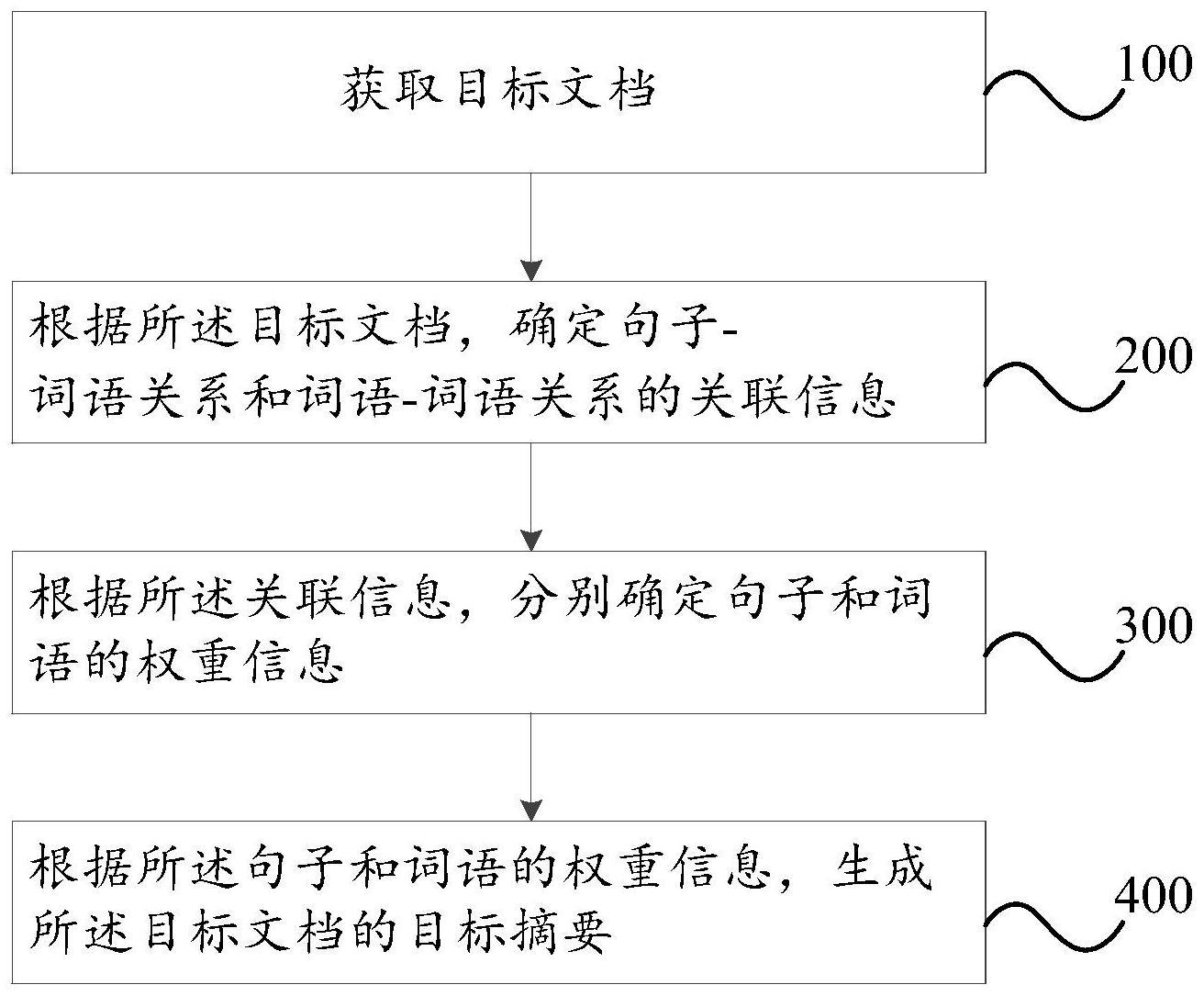
3、获取目标文档;
4、根据所述目标文档,确定句子-词语关系和词语-词语关系的关联信息;
5、根据所述关联信息,分别确定句子和词语的权重信息;
6、根据所述句子和词语的权重信息,生成所述目标文档的目标摘要。
7、可选地,所述的资源分配方法,其中,所述确定句子-词语关系和词语-词语关系的关联信息,包括:
8、根据所述目标文档,得到第一数量的句子节点集合s1和第二数量的词语节点集合s2;
9、根据s1和s2,构建包括句子-词语关系和词语-词语关系的权重矩阵和相似度矩阵。
10、可选地,所述的资源分配方法,其中,根据所述关联信息,分别确定句子和词语的权重信息,包括:
11、根据如下公式进行迭代计算:tr(i+1)=(1-d)+d*tri*m;
12、当任一句子或词语的当前权重与上次循环中计算得到的权重相差小于第一预设阈值时,确定句子和词语的权重;
13、其中,tr表示初始权重矩阵;d表示阻尼系数,m表示相似度矩阵;i表示第i次迭代计算。
14、可选地,所述的资源分配方法,其中,所述s1和s2,构建包括句子-词语关系和词语-词语关系的相似度矩阵,包括:
15、根据所述s1和所述s2,确定元素个数;所述元素个数为第三数量*第三数量,所述第三数量为所述第一数量和所述第二数量之和;
16、根据所述元素个数中第一元素对应的第一节点和第二节点,确定所述第一元素的具体值;所述第一元素为所述元素个数中的每个元素;
17、根据所述第一元素的具体值,确定包括句子-词语关系和词语-词语关系的相似度矩阵。
18、可选地,所述的资源分配方法,其中,所述根据所述元素个数中第一元素对应的第一节点和第二节点,确定所述第一元素的具体值,包括:
19、若所述第一节点和所述第二节点均为句子节点或者均为词语节点,则根据余弦公式确定所述第一元素的具体值;所述余弦公式为cos<vi,vj>,vi表示所述第一节点和所述第二节点中一个节点对应的向量,vj表示所述第一节点和所述第二节点中另一个节点对应的向量;
20、或者,
21、若所述第一节点为句子节点,且所述第二节点为词语节点,且所述词语节点不属于所述句子节点时,确定所述第一元素的具体值为0;
22、或者,
23、若所述第一节点为句子节点,且所述第二节点为词语节点,且所述词语节点属于所述句子节点时,则根据预设公式确定所述第一元素的具体值;所述预设公式为position(i,j)*p(i,j),position(i,j)表示所述词语节点和所述句子节点的位置函数,p(i,j)表示所述词语节点在所述句子节点中出现的概率。
24、可选地,所述的资源分配方法,其中,所述词语节点和所述句子节点的位置函数,具体为:position(i,j)=1-sigmoid(x);
25、其中,sigmoid(x)表示将x转化到(0,1)范围内,x为预设值。
26、可选地,所述的资源分配方法,其中,所述词语节点在所述句子节点中出现的概率具体为:
27、
28、其中,count(nodei,nodej)表示所述词语节点在所述句子节点中出现的次数,count(nodei)表示所述词语节点在所述目标文档中出现的次数。
29、可选地,所述的资源分配方法,其中,所述获取目标文档,包括:
30、对所述目标文档进行分词、去重的预处理,获得句子集合;以及,
31、提取所述目标文档中的关键词,获得词语集合;
32、基于所述句子集合和所述词语集合,确定每个句子和每个词语的向量。
33、为达到上述目的,本发明的实施例还提供一种电子设备,包括处理器和收发机,所述处理器用于:
34、所述处理器用于,获取目标文档;
35、所述处理器还用于,根据所述目标文档,确定句子-词语关系和词语-词语关系的关联信息;
36、所述处理器还用于,根据所述关联信息,分别确定句子和词语的权重信息;
37、所述处理器还用于,根据所述句子和词语的权重信息,生成所述目标文档的目标摘要。
38、可选地,所述的电子设备,其中,所述处理器具体用于:
39、根据所述目标文档,得到第一数量的句子节点集合s1和第二数量的词语节点集合s2;
40、根据s1和s2,构建包括句子-词语关系和词语-词语关系的初始权重矩阵;
41、以及,
42、根据所述s1和所述s2,构建包括句子-词语关系和词语-词语关系的相似度矩阵。
43、可选地,所述的电子设备,其中,所述处理器具体用于:
44、根据如下公式进行迭代计算:tr(i+1)=(1-d)+d*tri*m;
45、当任一句子或词语的当前权重与上次循环中计算得到的权重相差小于第一预设阈值时,确定句子和词语的权重;
46、其中,tr表示初始权重矩阵;d表示阻尼系数,m表示相似度矩阵;i表示第i次迭代计算。
47、可选地,所述的电子设备,其中,所述处理器具体用于:
48、根据所述s1和所述s2,确定元素个数;所述元素个数为第三数量*第三数量,所述第三数量为所述第一数量和所述第二数量之和;
49、根据所述元素个数中第一元素对应的第一节点和第二节点,确定所述第一元素的具体值;所述第一元素为所述元素个数中的每个元素;
50、根据所述第一元素的具体值,确定包括句子-词语关系和词语-词语关系的相似度矩阵。
51、可选地,所述的电子设备,其中,所述处理器具体用于:
52、若所述第一节点和所述第二节点均为句子节点或者均为词语节点,则根据余弦公式确定所述第一元素的具体值;所述余弦公式为cos<vi,vj>,vi表示所述第一节点和所述第二节点中一个节点对应的向量,vj表示所述第一节点和所述第二节点中另一个节点对应的向量;
53、或者,
54、若所述第一节点为句子节点,且所述第二节点为词语节点,且所述词语节点不属于所述句子节点时,确定所述第一元素的具体值为0;
55、或者,
56、若所述第一节点为句子节点,且所述第二节点为词语节点,且所述词语节点属于所述句子节点时,则根据预设公式确定所述第一元素的具体值;所述预设公式为position(i,j)*p(i,j),position(i,j)表示所述词语节点和所述句子节点的位置函数,p(i,j)表示所述词语节点在所述句子节点中出现的概率。
57、可选的,所述词语节点和所述句子节点的位置函数,具体为:position(i,j)=1-sigmoid(x);
58、其中,sigmoid(x)表示将x转化到(0,1)范围内,x为预设值。
59、可选的,所述词语节点在所述句子节点中出现的概率具体为:
60、
61、其中,count(nodei,nodej)表示所述词语节点在所述句子节点中出现的次数,count(nodei)表示所述词语节点在所述目标文档中出现的次数。
62、可选地,所述的电子设备,其中,所述处理器具体用于:
63、对所述目标文档进行分词、去重的预处理,获得句子集合;以及,
64、提取所述目标文档中的关键词,获得词语集合;
65、基于所述句子集合和所述词语集合,确定每个句子和每个词语的向量。
66、为达到上述目的,本发明的实施例还提供一种文本摘要的生成装置,包括:
67、处理模块,用于获取目标文档;
68、构建模块,用于根据所述目标文档,确定句子-词语关系和词语-词语关系的关联信息;
69、确定模块,用于根据所述关联信息,分别确定句子和词语的权重信息;
70、生成模块,用于根据所述句子和词语的权重信息,生成所述目标文档的目标摘要。
71、可选的,所述构建模块,包括:
72、第一确定单元,用于根据所述目标文档,得到第一数量的句子节点集合s1和第二数量的词语节点集合s2;
73、第一构建单元,用于根据s1和s2,构建包括句子-词语关系和词语-词语关系的初始权重矩阵;
74、以及,
75、根据所述s1和所述s2,构建包括句子-词语关系和词语-词语关系的相似度矩阵。
76、可选的,所述确定模块,包括:
77、第二确定单元,用于根据如下公式进行迭代计算:tr(i+1)=(1-d)+d*tri*m;
78、当任一句子或词语的当前权重与上次循环中计算得到的权重相差小于第一预设阈值时,确定句子和词语的权重;
79、其中,tr表示初始权重矩阵;d表示阻尼系数,m表示相似度矩阵;i表示第i次迭代计算。
80、可选的,所述第一构建单元,包括:
81、第一确定子单元,用于根据所述s1和所述s2,确定元素个数;所述元素个数为第三数量*第三数量,所述第三数量为所述第一数量和所述第二数量之和;
82、第二确定子单元,用于根据所述元素个数中第一元素对应的第一节点和第二节点,确定所述第一元素的具体值;所述第一元素为所述元素个数中的每个元素;
83、第三确定子单元,用于根据所述第一元素的具体值,确定包括句子-词语关系和词语-词语关系的相似度矩阵。
84、可选的,所述第二确定子单元,具体用于:
85、若所述第一节点和所述第二节点均为句子节点或者均为词语节点,则根据余弦公式确定所述第一元素的具体值;所述余弦公式为cos<vi,vj>,vi表示所述第一节点和所述第二节点中一个节点对应的向量,vj表示所述第一节点和所述第二节点中另一个节点对应的向量;
86、或者,
87、若所述第一节点为句子节点,且所述第二节点为词语节点,且所述词语节点不属于所述句子节点时,确定所述第一元素的具体值为0;
88、或者,
89、若所述第一节点为句子节点,且所述第二节点为词语节点,且所述词语节点属于所述句子节点时,则根据预设公式确定所述第一元素的具体值;所述预设公式为position(i,j)*p(i,j),position(i,j)表示所述词语节点和所述句子节点的位置函数,p(i,j)表示所述词语节点在所述句子节点中出现的概率。
90、可选的,所述词语节点和所述句子节点的位置函数,具体为:position(i,j)=1-sigmoid(x);
91、其中,sigmoid(x)表示将x转化到(0,1)范围内,x为预设值。
92、可选的,所述词语节点在所述句子节点中出现的概率具体为:
93、
94、其中,count(nodei,nodej)表示所述词语节点在所述句子节点中出现的次数,count(nodei)表示所述词语节点在所述目标文档中出现的次数。
95、可选的,所述处理模块,包括:
96、第三确定单元,用于对所述目标文档进行分词、去重的预处理,获得句子集合;以及,
97、提取所述目标文档中的关键词,获得词语集合;
98、第四确定单元,用于基于所述句子集合和所述词语集合,确定每个句子和每个词语的向量。
99、为达到上述目的,本发明的实施例还提供一种电子设备,包括:收发器、处理器、存储器及存储在所述存储器上并可在所述处理器上运行的程序或指令;所述处理器执行所述程序或指令时实现如上任一项所述的文本摘要的生成方法。
100、为达到上述目的,本发明的实施例还提供一种可读存储介质,其上存储有程序或指令,所述程序或指令被处理器执行时实现如上任一项所述的文本摘要的生成方法。
101、本发明的上述技术方案的有益效果如下:
102、上述技术方案中,通过获取目标文档;根据所述目标文档,确定句子-词语关系和词语-词语关系的关联信息,能够更好地建立全文信息之间的关系,生成更能概括全文的摘要,根据所述关联信息,分别确定句子和词语的权重信息;根据所述句子和词语的权重信息,生成所述目标文档的目标摘要。采用本发明所述的方法,一方面能够同时提取文本摘要和关键词,另一方面能够取得更好的摘要与关键词抽取效果。
- 还没有人留言评论。精彩留言会获得点赞!