容器集群环境下容器gpu资源监控系统
技术领域
1.本发明涉及容器集群,gpu设备,集群资源监控技术领域,具体地,涉及一种容器集群环境下全局同步的细粒度多级(主机级,容器级)实时gpu资源监控系统,尤其涉及一种容器集群环境下容器gpu资源监控系统。
背景技术:
2.随着近年来深度学习在诸如图像识别、自然语言处理等领域的广泛应用,对于云服务商和集群用户而言深度学习模型的训练任务正在成为集群批处理任务的热点问题。因为深度学习模型训练需要迭代运行大量的浮点计算以求解百万级甚至千万级的模型参数的梯度并进行参数更新,因此深度学习模型训练任务需要耗费大量的gpu资源。随着云原生概念的普及,使用诸如kubernetes,openshift等容器编排引擎组织管理的容器集群正在广泛应用,大量先前的研究诸如kubeflow,optimus,slaq等都致力于将深度学习模型训练任务进行容器化的分布式部署,以充分利用集群中的gpu资源。然而在容器集群中深度学习任务的gpu资源监控成为了生产系统中亟需的系统工具。
3.当前,容器集群的资源监控系统主要关注于从容器资源分配的底层原理角度进行资源监控的设计。例如,prometheus和kubelet自带的metric server从kubernetes的资源聚合接口cadvisor中读取实时的资源数据,cadvisor本质上是对容器集群中运行容器的cgroup进行的资源封装。prometheus作为当前业内容器集群资源监控的主流平台,允许用户进行大量的扩展,常见的扩展工具包括主机监控平台node-exporter,该工具平台以daemonset的方式在每个主机上部署代理容器,汇总所在主机上的cgroup信息。但是对于gpu资源等未包括在cgroup中的计算资源,实时监控的集成仍然需要提升。
4.prometheus通过扩展部署pod-gpu-metrics-exporter和dcgm-exporter这两个监控工具,实现了gpu资源的识别和以gpu卡为单位的容器集群gpu资源监控,但是该监控仍然存在以下问题:(1)该监控无法实现深度学习训练任务中的多级gpu细粒度监控,未包括细化到每个容器的gpu资源监控;(2)该监控在主机级别的资源监控时缺少一个master节点来实现各主机间gpu资源监控的同步性和各主机中gpu资源配置信息的全局一致性管理。
5.公开号为cn111552556a的发明专利,公开了一种gpu集群服务管理系统及方法,包括:资源监控模块,用于监控gpu集群资源,生成集群资源数据,发送集群资源数据;资源分配模块,用于获取任务信息和所述集群资源数据,根据所述任务信息和集群资源数据,分配任务资源;检查模块,用于获取资源监控模块发送的集群资源数据,根据所述集群资源数据检查gpu集群资源状态,生成检查结果,发送所述检查结果;隔离模块,用于获取所述检查结果,根据所述检查结果对异常资源进行隔离。
技术实现要素:
6.针对现有技术中的缺陷,本发明提供一种容器集群环境下容器gpu资源监控系统。
7.根据本发明提供的一种容器集群环境下容器gpu资源监控系统,所述方案如下:
8.第一方面,提供了一种容器集群环境下容器gpu资源监控系统,所述系统包括:
9.主机级gpu资源监控子系统:用以对集群中的各gpu卡进行全局唯一识别,并对主机中的gpu资源进行全局同步监控;
10.容器级gpu资源监控子系统:在每个容器中通过调用api的方式启动新的进程来对容器占据的gpu卡进行实时资源监控。
11.优选地,所述主机级gpu资源监控子系统包括:对于集群中各主机内的各gpu卡进行全局同步的监控,采用master-workers的布局方式,部署时,存在一个master节点来管理集群中gpu的配置信息。
12.优选地,所述gpu的配置信息包括:(1)该集群中各主机的配置信息,(2)各主机中各gpu卡的配置信息;
13.其中,各gpu卡的配置信息包括:1)全局唯一的uuid;2)gpu在主机内部的编号id;3)gpu卡的显存容量。
14.优选地,所述master-workers的布局方式中,master节点的主要特征:
15.a.全局同步的配置信息维护,通过注册集群中的主机配置信息来维护集群主机表,通过与各worker通信获取各主机的各gpu卡的配置信息,利用uuid这一全局唯一标识作为键来维护全局gpu配置信息表;
16.b.全局同步的采样控制,通过master定期产生全局同步的时间戳,并发送时间戳触发各worker的信息采集。
17.优选地,所述master-workers的布局方式中,worker节点的主要特征:采用daemonset的部署方式,即在集群内每个节点上部署worker,worker实时检测主机内的gpu配置信息,并在检测到更新时与master进行交互。
18.优选地,所述主机级gpu资源监控子系统还包括:集群中的每个主机运行一个worker;在接收到时间戳信息后,worker进行数据采集,包括gpu的实时利用率和实时占用显存量,并估算显存利用率。
19.优选地,所述主机级gpu资源监控子系统还包括:各worker定期检测所在主机的gpu配置信息,包括:a.是否新增或移除gpu卡;b.主机内全部gpu卡的uuid和id信息;c.当前主机的空闲gpu卡;
20.发现gpu配置信息修改时,将向master发送配置更新信息,master接收更新信息后进行配置更新。
21.优选地,所述容器级gpu资源监控子系统包括:
22.在镜像中添加容器gpu监控agent的代码,并设置环境变量;
23.在深度学习任务的代码中,通过调用api修改环境变量启动和管理gpu监控agent;
24.在开启容器gpu监控后,容器内通过新的进程启动gpu容器监控agent,该agent在确认深度学习任务已启动后开始进行数据采集,并实时读取容器占据的gpu卡的uuid信息。
25.优选地,所述容器级gpu资源监控子系统还包括:容器监控agent通过与主机gpu监控系统的master通信后获得当前使用的gpu卡的配置信息,uuid在集群中全局唯一地识别容器使用的gpu卡;
26.在采集信息时,用户指定采样间隔,实时采集容器使用的gpu卡的利用率与占用的显存量,并估算显存利用率。
27.优选地,所述容器级gpu资源监控子系统还包括:
28.对于每个深度学习任务,通过封装代码包和环境变量的方式,实现深度学习任务仅调用api实现gpu资源监控的启动,对于每个容器内的资源监控agent,该agent运行的进程不影响深度学习任务运行的同时,感知深度学习任务的状态,在有深度学习任务占用gpu时进行数据采集;
29.容器监控agent通过与主机级gpu资源监控子系统中的master节点交互,利用gpu卡的uuid进行全局唯一地gpu识别。
30.与现有技术相比,本发明具有如下的有益效果:
31.1、本发明提出的主机级别的gpu监控引入了master节点,维护了全局gpu配置信息的一致性;
32.2、本发明实现了各容器粒度的gpu资源监控,且容器的gpu资源监控可以通过用户调用api启动,并且可以与主机gpu监控系统的master节点交互以实现gpu资源配置的一致性。此外每个容器的gpu监控agent可以感知该容器的深度学习任务状态与配置信息,例如该容器在一个分布式深度学习任务中的状态、角色,该容器使用gpu的进程pid等。
附图说明
33.通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
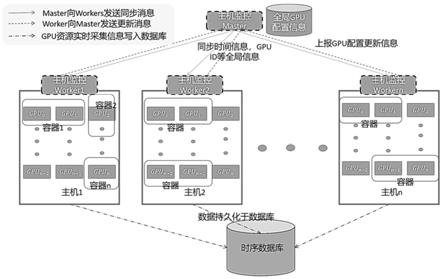
34.图1为本发明主机gpu资源监控系统的逻辑框架图;
35.图2为本发明容器gpu资源监控系统的逻辑框架图;
36.图3为本发明的可视化效果图。
具体实施方式
37.下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
38.本发明实施例提供了一种容器集群环境下容器gpu资源监控系统,克服现有容器集群中gpu计算资源的多级监控问题,具体来说,实现了各主机和各容器的gpu资源的细粒度采集。在容器级、主机级的gpu监控中实现了gpu资源配置信息的全局同步,并实现了主机级别gpu资源数据的全局同步采集。
39.为实现集群中各主机的gpu资源的全局同步监控,并实现各运行深度学习任务的容器的gpu资源的监控。针对prometheus中以gpu卡为单位的容器集群gpu资源监控工具dcgm-exporter的局限性,本发明进行了两个主要优化:首先,在主机的gpu资源监控中,本发明在以daemonset的方式部署workers的基础上(daeonset部署即在集群中每个主机上都部署一个容器副本的部署方式),引入了master-workers的部署方式。使用master实现了gpu配置信息的全局一致性存储和实时更新,并利用master实现了gpu资源数据采集时的全局同步性。其次,针对容器级别gpu资源的监控,本发明对每个容器设计并封装了资源监控agent。该agent可以实现对深度学习训练容器的无干扰gpu监控的同时感知深度学习任务
的运行状态,且通过与主机gpu监控的master节点交互实现gpu资源配置信息的全局一致性。
40.具体地,参照图1和图2所示,该系统包括:主机级gpu资源监控子系统和容器级gpu资源监控子系统;
41.其中,主机级gpu资源监控子系统:用以对集群中的各gpu卡进行全局唯一识别,并对主机中的gpu资源进行全局同步监控。
42.对于集群中各主机内的各gpu卡进行全局同步的监控,采用master-workers的布局方式,部署时,存在一个master节点来管理集群中gpu的配置信息,gpu的配置信息包括:(1)该集群中各主机的配置信息,(2)各主机中各gpu卡的配置信息。
43.其中,各gpu卡的配置信息包括:1)全局唯一的uuid;2)gpu在主机内部的编号id;3)gpu卡的显存容量。这一全局同步的配置保存方式保证了集群中各gpu卡的全局唯一识别。在采集数据时,master向各工作节点(worker)发送同步的时间戳,保证全局同步的采样。本实施例中的uuid是通用唯一识别码(universally unique identifier)的缩写,是一种软件建构的标准,亦为开放软件基金会组织在分布式计算环境领域的一部分,在gpu中,uuid则具体gpu厂家生产时给定当前gpu卡的通用唯一识别码。
44.对于工作节点(worker),集群中的每个主机运行一个worker;在接收到时间戳信息后,worker进行数据采集,包括gpu的实时利用率和实时占用显存量,并估算显存利用率。各worker定期检测所在主机的gpu配置信息,包括:a.是否新增或移除gpu卡;b.主机内全部gpu卡的uuid和id信息;c.当前主机的空闲gpu卡(无深度学习进程运行);发现gpu配置信息修改时,将向master发送配置更新信息,master接收更新信息后进行配置更新。
45.在master-workers的布局方式中,master节点的主要特征:
46.a.全局同步的配置信息维护,通过注册集群中的主机配置信息来维护集群主机表,通过与各worker通信获取各主机的各gpu卡的配置信息,利用uuid这一全局唯一标识作为键来维护全局gpu配置信息表。
47.b.全局同步的采样控制,通过master定期产生全局同步的时间戳,并发送时间戳触发各worker的信息采集。
48.worker节点的主要特征:采用daemonset的部署方式,即在集群内每个节点上部署worker,worker实时检测主机内的gpu配置信息,并在检测到更新时与master进行交互。worker通过和master的交互实现了全局同步的数据采集。
49.容器级gpu资源监控子系统:在每个容器中通过调用api的方式启动新的进程来对容器占据的gpu卡进行实时资源监控。
50.在集群中的每个深度学习容器中,本发明在镜像中添加了容器gpu监控agent的代码,并设置环境变量;在深度学习任务的代码中,通过调用api修改环境变量启动和管理gpu监控agent。在开启容器gpu监控后,容器内通过新的进程启动gpu容器监控agent,该进程不会影响深度学习任务的运行,该agent在确认深度学习任务已启动后开始进行数据采集,并实时读取容器占据的gpu卡的uuid信息。
51.容器监控agent通过与主机gpu监控系统的master通信后获得当前使用的gpu卡的配置信息,由于uuid是全局唯一的标识,因此可以在集群中全局唯一地识别容器使用的gpu卡。在采集信息时,用户指定采样间隔,实时采集容器使用的gpu卡的利用率与占用的显存
量,并估算显存利用率。
52.对于每个深度学习任务,通过封装代码包和环境变量的方式,实现深度学习任务仅调用api即可实现gpu资源监控的启动,对于每个容器内的资源监控agent,该agent运行的进程不影响深度学习任务的运行,同时可以感知深度学习任务的状态,保证在有深度学习任务占用gpu时进行数据采集;容器监控agent可以通过与主机级gpu资源监控子系统中的master节点交互,利用gpu卡的uuid进行全局唯一地gpu识别。
53.接下来,对本发明进行更为具体的说明。
54.1、框架结构:
55.图1和图2分别显示了本发明提出的主机级gpu资源监控子系统和容器级gpu资源监控子系统的逻辑框架图。主机级的gpu资源监控系统由一个master和多个worker组成,每个主机运行一个worker副本,worker副本负责具体和gpu生产厂家nvidia提供的counters进行交互。master定时生成全局同步的时间戳并发送采集指令给各工作节点workers,workers获取主机上gpu的配置信息和gpu的实时资源使用情况后,gpu实时资源情况存入时序数据库,配置信息则由各worker节点发送给master节点,master节点探测到gpu配置变化后将更新键值数据库中的配置信息。
56.对于容器级gpu资源监控子系统,该子系统在每个运行的容器中添加一个数据采集的agent,该agent以python代码包的形式写入容器镜像,对于常用的深度学习框架诸如tensorflow和pytorch等,用户在代码中通过api调用该监控agent,通过api修改环境变量的方式启动该监控agent,则一个新的进程会启动并运行,用户可以在代码中通过api停止负责监控的agent进程。agent进程会读取容器中可用gpu的uuid通过与主机级监控系统的master节点交互,通过在全局gpu配置信息中的uuid字段中进行检索,获取一致的gpu配置信息,并全局唯一地识别gpu卡。agent会根据用户在代码中指定地采样间隔采集gpu的实时利用率,显存占用量,温度等信息,存入时序数据库中。
57.如图1所示,我们给出主机级gpu资源监控子系统中master和worker的基本组成设计和基本任务。(1)master作为独立的进程,通过定时器触发同步地gpu数据采集和配置更新服务。(2)master中维护全局gpu配置信息表,不同主机分别维护一张gpu配置信息表,每张表内部以uuid唯一标识gpu卡。(3)各worker独立运行于集群中的各主机中,通过与master进行通信保证全局的一致性,worker的数据采集由master发送的同步时间戳触发,读取的配置信息将反馈回master用于gpu的全局配置更新,读取的实时资源信息将写入时序数据库。(4)上述过程中的数据源来自于nvidia的相关api,具体从nvidia-smi中进行读取。
58.如图2所示,我们给出容器级gpu资源监控子系统中agent的基本组成设计和基本任务。(1)agent作为独立的进程,通过python代码包的方式可以在常用的深度学习框架,诸如tensorflow和pytorch中调用,用户可以通过api启动gpu监控agent。(2)agent的采样间隔,持久化数据使用的数据库等信息可以在用户调用时指定。(3)agent通过nvidia-smi读取gpu的uuid和实时使用信息,包括gpu利用率,gpu显存占用量,gpu温度等,并通过uuid与主机gpu监控系统中维护的全局gpu配置信息关联,获取gpu的显存容量,估计gpu显存的实时占用率。(4)agent可以实时获取容器中占用gpu的进程id,以及该容器在分布式训练任务中的角色(主训练节点或从训练节点及其副本编号),以感知深度学习训练任务的运行状
态。
59.接下来,我们描述qore-gpu-monitor技术方案的工作流程。从gpu服务器作为主机加入集群开始,主机gpu监控系统的工作流程如下:
60.(1)集群管理员需要在master中注册新引入的gpu服务器信息,包括gpu服务器在集群中的主机名与ip地址。master通过主机注册信息,在该主机上启动主机gpu监控工作节点worker。
61.(2)启动的工作节点worker将通过nviadia-smi获取当前主机的gpu列表,包括当前主机各gpu卡的uuid,各gpu卡的显存容量等静态配置信息,并将相关信息发送至master节点,master节点更新相应主机中的gpu卡的配置,初始化worker完成。
62.(3)master中保留定时器,用户可根据需要配置定时器中的采样时间间隔,在每一采样间隔到时后,master会生成全局同步的时间戳,将时间戳并发发送给所有worker,worker获得信息后通过nvidia-smi采集实时gpu信息:1)gpu配置信息:gpu的uuid,在本主机上的编号id和gpu显存容量等静态信息。2)gpu实时资源信息:包括gpu的实时利用率,gpu显存占用量,gpu温度,gpu功率等。
63.(4)worker将gpu配置信息发送给master,如果master发现gpu配置信息发生变化则更新gpu全局配置键值表,每个主机的gpu信息分别存在一张表中,同一张表中以gpu卡的uuid作为主键,以此实现每张gpu卡的全局唯一标识。worker将gpu实时资源信息存入时序数据库中,以从master中获得的同步时间戳作为该数据的时间键。用户可以根据需要直接从时序数据库中获取gpu实时资源信息,从master维护的全局配置表中获取gpu配置信息。
64.对于每个运行深度学习训练任务的容器而言,其监控agent的工作流程如下:
65.(1)容器在kubernetes等编排引起启动时增加了gpu_monitor_start环境变量,用户在代码中通过引用pod_gpu_monitor包中的api将gpu_monitor_start设置为true,agent进程启动并开始工作。
66.(2)agent在初始化阶段实时探测事件包括:1)该容器使用的gpu的配置信息是否已写入主机gpu监控系统的master节点中的gpu全局信息表;2)该容器中运行的深度学习训练任务是否已完成初始化。当agent探测到上述两个事件已就绪后,agent将开始gpu监控。
67.(3)agent根据用户启动该进程时指定的采样间隔和数据持久化数据库,进行gpu数据采集,包括:1)gpu配置信息:容器中可用gpu的uuid,容器所在主机;2)gpu实时资源数据:gpu的利用率,gpu实时显存占用量,gpu温度,功率等;3)深度学习任务配置信息:包括运行在各gpu上的进程pid,该深度学习容器名,该深度学习任务节点在分布式深度学习训练任务中的角色(例如主节点,从节点,以及编号等信息)。之后agent通过容器所在主机信息和gpu的uuid获取各gpu的配置信息,通过各gpu的显存容量实时估算gpu显存占用率。gpu的实时资源数据,uuid,所在节点,深度学习任务配置信息均写入时序数据库,用户可通过深度学习容器名等进行检索。
68.2、系统创新:
69.(1)该系统实现了在主机级gpu监控中实现了全局同步的采样与全局一致的gpu静态配置信息统计、更新。
70.(2)该系统实现了多级细粒度gpu监控,可以实现容器级的gpu监控,并感知容器中相应深度学习任务的配置与状态。
71.(3)该系统综合利用主机级监控系统与容器级监控系统,实现了容器级监控系统中的gpu标识一致性。
72.3、系统实现:
73.该系统的实现目前基于kubernetes编排引擎组织的容器集群中,需要容器集群中的gpu主机安装cuda环境,且深度学习训练任务在使用时需要引入封装监控agent的python代码包并配置环境变量,目前实现时,代码包需要封装于任务镜像内,环境变量可以通过kubernetes集群在运行时进行配置。对于主机监控系统而言,worker需要进行daemonset方式的部署,master节点可单独部署,目前时序数据库选用influxdb。经实验,本发明采样率可以达到亚秒级(实验中采样间隔可以细化至0.8s)。关于数据可视化,当前集群中gpu监控的可视化效果如图3所示。
74.本发明实施例提供了一种容器集群环境下容器gpu资源监控系统,以master-workers的部署方式保证了各主机采集的同步运行,并保证了集群中各张gpu卡配置信息的全局统一标识、管理和更新。此外,本发明针对运行每个深度学习训练任务的容器,设计了容器内部的gpu资源监控agent,该agent封装为代码包的形式,可以通过设置环境变量和调用api的方式启动,且不会影响深度学习训练任务的运行,并可以通过和主机监控系统的master节点进行交互以实现gpu配置信息的同步。这两种方案的共同不属于集群中,并且可以进行相互通信,从而实现了容器集群中gpu资源的主机级、容器级的多级资源监控系统,其次,本发明实现了主机级全局同步监控,并在多级gpu监控系统中,保证了gpu配置全局一致性。最后,本系统可以实现细粒度的gpu资源监控,包括每个容器级的gpu资源监控以及在避免干扰容器深度学习任务的前提下实现了亚秒级的数据采集。
75.本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统及其各个装置、模块、单元以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统及其各个装置、模块、单元以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同功能。所以,本发明提供的系统及其各项装置、模块、单元可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置、模块、单元也可以视为硬件部件内的结构;也可以将用于实现各种功能的装置、模块、单元视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
76.以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本技术的实施例和实施例中的特征可以任意相互组合。
- 该技术已申请专利。仅供学习研究,如用于商业用途,请联系技术所有人。
- 技术研发人员:钱诗友 华勤 曹健 汤敬华 方楠 张宗振
- 技术所有人:上海交通大学
- 我是此专利的发明人
- 该领域下的技术专家
- 如您需求助技术专家,请点此查看客服电话进行咨询。
- 1、李老师:1.计算力学 2.无损检测
- 2、毕老师:机构动力学与控制
- 3、袁老师:1.计算机视觉 2.无线网络及物联网
- 4、王老师:1.计算机网络安全 2.计算机仿真技术
- 5、王老师:1.网络安全;物联网安全 、大数据安全 2.安全态势感知、舆情分析和控制 3.区块链及应用
- 如您是高校老师,可以点此联系我们加入专家库。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
精彩留言,会给你点赞!
专利分类正在加载中....