时空域信息融合随机森林的微表情检测方法
1.本发明属于图像处理及人工智能技术领域,具体涉及一种时空域信息融合随机森林的微表情检测方法。
背景技术:
2.面部微表情是内心真实情绪的外延折射,区别于宏表情,其不受意识控制,通常持续时间非常短暂,仅在1/5秒到1/25秒之间,在脸部特定位置发生。所以微表情识别在测谎监测等多种领域场合有着较重要的应用。过去微表情分析技术仅适用于经验丰富的心理学专家,随着人工智能技术的发展,及其在机器学习、表情识别领域不断的突破和应用,为微表情检测识别技术提供了动力支撑,近年来关于微表情识别领域的研究成果一直在逐年递增。
3.微表情识别过程一般分为以下几个步骤:图像采集、图像预处理、微表情检测、特征提取、微表情分类。其中微表情特征提取目前方法主要有传统分析方法及深度学习方法。传统分析方法中主要包含局部二值模式(lbp,local binary patterns)的方法、基于光流场特征的方法、基于张量变化分析的方法。深度学习方法中主要包括基于卷积神经网络(cnn, convolutional neural networks)的方法、基于循环神经网络(rnn,recurrent neural networks) 的方法、基于3d-cnn的方法。微表情分类方法主要是通过提取类似光流或光强等细微表情非刚性的运动变化,或者使用面部动态图(fdm,facial dynamic map)对面部组件进行运动建模,结合多尺度滑动窗口的微表情检测结果与数据集样本进行比对,进而完成微表情的分类。
4.微表情实验数据集较为稀缺,代表性数据集有casme、casmeii、smic、cas(me)2。影响数据集质量的重要属性参数主要有制作数据集包含的参与者数量、采集的总样本数量、数据集表情分类数量、采集图像的分辨率以及帧率等。
5.微表情检测指的是从一段视频流中检测出是否包含有微表情,并标记微表情的起点 (onset),峰值(apex)和终点(offset)。起点指的是微表情开始出现的时间,峰值指的是微表情发生幅度最大的时间,终点指的是微表情彻底消失的时间。微表情识别指的是针对已经检测完成的微表情序列,通过一定算法对视频序列的微表情进行分类。以casmeii微表情数据集为例,分为:蔑视(contempt)、厌恶(disgust)、恐惧(fear)、高兴(happiness)、压抑(repression)、悲伤(sadness)、惊讶(surprise)及紧张(tense)。
6.由于微表情运动幅度小,变化特征不明显,通常难于跟踪提取。此外,标准微表情数据集较为匮乏,造成微表情训练资源短缺,且由于有限数据集中微表情样本分类极度不均衡,造成不同类别微表情的分类鲁棒性不理想。
技术实现要素:
7.为解决上述问题,本发明提供了一种有效性高,识别率高,性能较高的时空域信息融合随机森林的微表情检测方法。
8.为达到上述目的,本发明的技术方案如下:
9.一种时空域信息融合随机森林的微表情检测方法,包括以下步骤:
10.s1:通过人脸跟踪检测,完成输入视频序列预处理;
11.s2:使用所提出的特征空间表示整个视频序列,由呈现为金字塔式层级的二维子区域表征的统一局部二进制模式来表示;
12.s3:采用改进的增强方式融合时空域信息作为随机森林源对象;
13.s4:使用基于随机森林的嵌入式特征选择方法来选择最具区别性的特征;
14.s5:基于时空域信息融合随机森林算法构建微表情分类器。
15.进一步的,所述步骤s1包括如下子步骤:
16.s11:将微表情数据库进行空域和时域分割;随后通过人脸跟踪检测,针对空域部分通过 fac接口实现人脸定位、通过dlib工具进行人脸配准、并对图像帧序列进行roi裁剪;同时进行降噪处理;
17.s12:对所有图像帧序列进行归一化处理,并对时域区间的时间标尺运用时域插值模型 tim进行标准化处理;通过归一化和标准化处理,将全部图像帧序列整合处理后再作为训练网络的输入;
18.s13:进行tvl光流计算,获取到微表情的光流序列,以此作为网络的二次输入;对光流进行水平和垂直分量表示,光流向量表示形式为:k=[m,n]
t
,其中m与n分别为水平和垂直光流分量,dv和dw表示沿着水平和垂直维度的像素渐变情况,dt为时域长度的跨度情况。
[0019]
进一步的,所述步骤s2包括如下子步骤:
[0020]
s21:将每一个视频序列分解为子区域,并且按照金字塔式层级分解为不同尺寸;引入以视频序列帧为符号的三维像素矩阵的金字塔式表征,其中在空间向量中包括了金字塔式指征的指标水平;
[0021]
s22:通过二维子区域表征方式将三维矩阵降维为二维图像,通过抽取每一帧的第一行并给它打上二维标签,继而以此为标准对后续视频帧做二维化处理;
[0022]
s23:计算每一张二维图像的二维子区域lbp特征值,并且需要进行水平最终端点x和垂直最终端点y的同步调节,表达式为以及其中,height和length分别表示视频序列帧的高度和宽度;
[0023]
s24:将每一个水平的二维子区域lbp直方图建立起联系,按照金字塔式水平决定lbp特征空间尺寸的优先级。
[0024]
进一步的,所述步骤s23中,计算每一张二维图像的二维子区域lbp特征值的过程中设定领域像素每一次的单位跳转值和跳转半径单位值。
[0025]
进一步的,所述步骤s3包括如下子步骤:
[0026]
s31:对象参数初始化及参数定义,其中,s:改进增强后的源对象;is:空域对象信息; i
t
:时域对象信息;h
s1
:空域对象一次融合处理;h
s2
:空域对象二次融合处理;h
t1
:时域对象一次融合处理;h
t2
:时域对象二次融合处理;mf:融合微表情信息帧;f:微表情信息帧;
一次融合微表情信息帧m
fs1
、m
ft1
;二次融合微表情信息帧m
fs2
、m
ft2
;
[0027]
s=is∪i
t
[0028]hs1
={m
fs1
,fs1}
[0029]hs2
={m
fs2
,fs2}
[0030]ht1
={m
ft1
,ft1}
[0031]ht2
={m
ft2
,ft2}
[0032]
s32:以改进的增强方式融合时空域信息作为随机森林源对象处理,对时域对象及空域对象进行一次融合处理及二次融合处理,如果时域与空域信息在指定帧相交向量大于帧向量本身,则对处理结果进行增强融合处理,具体包括:
[0033]
当时域与空域信息在指定帧相交向量大于第i帧指定的帧向量ii本身,且帧向量本身不为0时,则通过以下公式对第i帧信息的时空域对象进行一次信息提取及二次信息提取均值的融合处理:
[0034]
mix fi=(fi1+fi2)/2
[0035]
当第i帧信息的融合处理结果与其第一次提取信息之差的绝对值大于与其第二次提取信息之差的绝对值,则通过以下公式进行融合处理和增强融合处理:
[0036]
handle(h
s1
,h
s2
)
[0037]
handle(h
t1
,h
t2
)
[0038][0039]
其中,融合处理及增强融合处理定义如下:
[0040][0041][0042]
进一步的,所述步骤s4包括如下子步骤:
[0043]
s41:通过二叉树方式产生一个分类森林,并对嵌入式对象相应的特征矩阵进行设置,从每一个分离的节点中随机选择数量不等的特征创建树节点;
[0044]
s42:以s32中获得的基于改进的增强方式融合的时空域信息作为s41建立的分类森林的源输入对象,并为每一个特征计算重要性权值,对每一棵树都假设相应特征矩阵的预测错误;同时对特征矩阵的首行进行随机的序列改变,假设预测错误会在修改过的特征矩阵中再现;序列改变操作在二叉树分类过程中重复直至所有特征行均被逐一处理,并按照获得的重要性权值组成随机森林的嵌入式特征序列;
[0045]
s43:选取关联的由最优随机森林分类器产生的鉴别特征;首先定义一个二叉分类树,它与以下特征相关联:具备首要最高重要权值的特征,以及具备次要高权值的特征;首要权重特征与次要权重特征相互关联,再与第三级权重特征相连接,以此类推;由此为每一个训练视频序列所关联的特征建立并产生了一个随机森林分类器;采用最佳关联最大准确率和最小准确率特征,这种关联代表了序列和节点的选择。
[0046]
进一步的,所述步骤s5包括以下子步骤:
[0047]
s51:通过标准随机森林算法建立随机森林分类器,准确地算出森林中每一个训练
视频序列树的索引叶节点,由此得出一个叶节点矩阵;
[0048]
s52:针对测试视频序列,算出森林中每棵树的索引叶节点,由此得到一个待测森林节点向量组;
[0049]
s53:计算待测视频序列与标准训练视频序列之间的近似测量偏差值,该偏差值作为预测训练视频序列和测试视频序列分类所共用的树叶节点的数量;
[0050]
s54:基于向量近似测量值预测测试视频序列分类,如果相应的近似测量值与向量计算得到的最大值接近,则一个测试视频序列被认为与训练视频序列相类似;测试视频序列作为具有最大权值的分类;过程中如果发现存在面部表情具有最大权值,将其视作随机产生;用面部表情权值代替面部表情数量。
[0051]
进一步的,所述步骤s53中使用kronecker delta函数等式定义待测视频序列与训练视频序列之间的近似测量偏差值。
[0052]
本发明的有益效果为:
[0053]
1.本发明利用微表情视频序列在时域和空域上的双重信息通道及随机森林分类器的天然多元处理能力,通过识别面部正面低维外观特征空间分类微表情。基于本发明方法,人脸微表情识别率有较大幅度提升,且对基础数据库依赖降低。
[0054]
2.本发明引入基于随机森林的嵌入式特征选择方法来选择最具区别性的特征。由于森林中的每一棵树都是一个分类器,对于微表情序列批量输入的情况,随机森林可以做到一对一的分类设计,有效的解决了微表情特征尺度小对象多的难于跟踪提取的问题。
[0055]
3.本发明通过将待测微表情序列对象进行空域和时域分割,空域维度由rgb单帧构成,仅作为空间信息载体,而时域维度由光流图像构成,刻画待测对象运动轨迹。由于实质上起到了深度降维的效果,所以这种分割方式大大减少了对训练样本集的依赖,屏蔽了标准样本集不足对领域研究形成的障碍。同时通过随机森林的不平衡分类特性,平衡分类样本不均造成的误差。
附图说明
[0056]
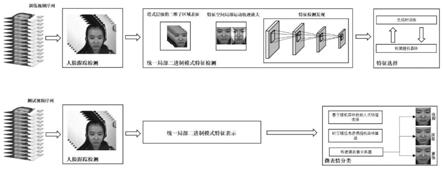
图1为本发明提供的时空域信息融合随机森林的微表情检测方法的主框架流程图。
[0057]
图2为采用本发明方法进行的微表情分类、标注及分类概率可视化统计图。
具体实施方式
[0058]
以下将结合具体实施例对本发明提供的技术方案进行详细说明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。另外,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
[0059]
附图仅用于示例性说明,是本发明的示意或示例,不能以此限定本发明的保护范围;为了突出发明重点,附图有关部件进行了删减,示例图不代表产品实际的完备尺寸;对于本领域研究技术人员而言,附图中基于业内常识内容的删减是默认可以接受的。
[0060]
本发明提供的时空域信息融合随机森林的微表情检测方法,其主框架流程如图1所示,包括以下步骤:
[0061]
s1:通过人脸跟踪检测,完成输入视频序列预处理,包括以下子步骤:
[0062]
s11:将微表情数据库进行空域和时域分割;随后通过人脸跟踪检测,针对空域部分通过fac接口实现人脸定位、通过dlib工具(一种深度学习开源工具)进行人脸配准、并对图像帧序列进行roi(region ofinterest感兴趣区域)裁剪。同时进行降噪处理,排除无关信息,为特征提取做好铺垫。
[0063]
s12:对所有图像帧序列进行归一化处理,并对时域区间的时间标尺运用时域插值模型 tim进行标准化处理。通过归一化和标准化处理,将全部图像帧序列整合处理后再作为训练网络的输入。通过将图像帧序列的时间长度归一后进行光流计算,获取到微表情的光流序列,以此作为网络的二次输入。
[0064]
s13:通过tvl光流计算提升抗噪鲁棒性,有效阻断因光流颠簸引起的运动编码紊乱。对光流进行水平和垂直分量表示,光流向量表示形式为:k=[m,n]
t
,m与 n分别为水平和垂直光流分量,dv和dw表示沿着水平和垂直维度的像素渐变情况,dt为时域长度的跨度情况。
[0065]
s2:使用所提出的特征空间表示整个视频序列,由呈现为金字塔式层级的二维子区域表征的统一局部二进制模式来表示。这里提到的金字塔式层级指空间金字塔池化层,它是获得一个时间步的图像层次表征。解决了卷积神经网络输入图像大小必须固定的问题,从而使得输入图像高宽比和大小可以任意。具体包括以下子步骤:
[0066]
s21:将每一个视频序列分解为子区域,并且按照金字塔式层级分解为不同尺寸。引入以视频序列帧为符号的三维像素矩阵的金字塔式表征,其中在空间向量中包括了金字塔式指征的指标水平。
[0067]
s22:通过二维子区域表征方式将三维矩阵降维为二维图像,通过抽取每一帧的第一行并给它打上二维标签,继而以此为标准对后续视频帧做二维化处理。
[0068]
s23:计算每一张二维图像的二维子区域lbp(local binary pattern局部二值模式)特征值,并在计算过程中设定领域像素每一次的单位跳转值及跳转半径单位值。本例中单位跳转值为8像素,跳转半径单位值设置为1,均为经验值,可以根据需要修改。并且需要进行水平最终端点x和垂直最终端点y的同步调节,表达式为以及height和length分别表示视频序列帧的高度和宽度,radius表示跳转半径。
[0069]
s24:将每一个水平的二维子区域lbp直方图之间建立起联系,按照金字塔式水平决定 lbp特征空间尺寸的优先级。
[0070]
s3:采用一种改进的增强方式融合时空域信息作为随机森林源对象,具体包括以下子步骤:
[0071]
s31:对象参数初始化及参数定义,其中,s:改进增强后的源对象;is:空域对象信息; i
t
:时域对象信息;h
s1
:空域对象一次融合处理;h
s2
:空域对象二次融合处理;h
t1
:时域对象一次融合处理;h
t2
:时域对象二次融合处理;mf:融合微表情信息帧;f:微表情信息帧;一次融合微表情信息帧m
fs1
、m
ft1
;二次融合微表情信息帧m
fs2
、m
ft2
等。其中t1, t2,s1,s2分别为时域及空域对象第一次及第二次处理对象。
[0072]
s=is∪i
t
[0073]hs1
={m
fs1
,fs1}
[0074]hs2
={m
fs2
,fs2}
[0075]ht1
={m
ft1
,ft1}
[0076]ht2
={m
ft2
,ft2}
[0077]
s32:以改进的增强方式融合时空域信息作为随机森林源对象处理,对时域对象及空域对象进行一次融合处理及二次融合处理,如果时域与空域信息在指定帧相交向量大于帧向量本身,则对处理结果进行增强融合处理。具体的:
[0078]
当is∧i
t
>ii且i≥0时,即时域与空域信息在指定帧相交向量大于第i帧指定的帧向量ii本身,且帧向量本身不为0时,则通过以下公式对第i帧信息的时空域对象进行一次信息提取及二次信息提取均值的融合处理:
[0079]
mix fi=(fi1+fi2)/2
[0080]
当|fi-fi1|>|fi-fi2|时,即如果第i帧信息的融合处理结果与其第一次提取信息之差的绝对值大于与其第二次提取信息之差的绝对值,则通过以下公式进行融合处理和增强融合处理:
[0081]
handle(h
s1
,h
s2
)
[0082]
handle(h
t1
,h
t2
)
[0083][0084]
其中,融合处理及增强融合处理定义如下:
[0085][0086][0087]
s4:使用基于随机森林的嵌入式特征选择方法来选择最具区别性的特征,具体包括以下子步骤:
[0088]
s41:通过二叉树方式产生一个分类森林,并对嵌入式对象相应的特征矩阵进行设置,从每一个分离的节点中随机选择数量不等的特征创建树节点。
[0089]
s42:以s32中获得的基于改进的增强方式融合的时空域信息作为s41建立的分类森林的源输入对象,并为每一个特征计算重要性权值,对每一棵树都假设相应特征矩阵的预测错误。同时对特征矩阵的首行进行随机的序列改变,假设预测错误会在修改过的特征矩阵中再现。序列改变操作在二叉树分类过程中重复直至所有特征行均被逐一处理,并按照获得的重要性权值组成随机森林的嵌入式特征序列。
[0090]
s43:选取关联的由最优随机森林分类器产生的鉴别特征。首先定义一个二叉分类树,它与以下特征相关联:具备首要最高重要权值的特征,以及具备次要高权值的特征。首要权重特征与次要权重特征相互关联,再与第三级权重特征相连接,以此类推。由此为每一个训练视频序列所关联的特征建立并产生了一个随机森林分类器。采用最佳关联最大准确率和最小准确率特征,这种关联代表了序列和节点的选择。
[0091]
s5:基于所提出的时空域信息融合随机森林算法构建微表情分类器,具体包括以下子步骤:
[0092]
s51:通过标准随机森林算法建立随机森林分类器。准确地算出森林中每一个训练视频序列树的索引叶节点,由此得出一个叶节点矩阵。
[0093]
s52:针对测试视频序列,算出森林中每棵树的索引叶节点,由此得到一个待测森林节点向量组。
[0094]
s53:计算待测视频序列与标准训练视频序列之间的近似测量值(偏差值)。使用 kronecker delta函数等式定义待测视频序列与训练视频序列之间的近似测量偏差值,该偏差值作为预测训练视频序列和测试视频序列分类所共用的树叶节点的数量。
[0095]
s54:基于向量近似测量值预测测试视频序列分类,如果相应的近似测量值与向量计算得到的最大值接近,则一个测试视频序列可以被认为与训练视频序列相类似。测试视频序列类别只是面部表情集合之一,通过具有最大权值的向量类表示,测试视频序列可作为具有最大权值的分类。过程中如果发现存在面部表情具有最大权值,可以将其视作随机产生。用面部表情权值代替面部表情数量以避免不同面部表情分类之间不平衡所造成的影响。
[0096]
图2为基于时空域信息融合随机森林的微表情检测方法开发的微表情分析工具(该工具包括预处理模块、特征提取模块、增强融合模块、随机森林选择模块、分类模块,分别用于实现上述步骤s1-s5的功能),在定位人脸框、检测微表情、时空域分割及随机森林分类后进行微表情分类及标注,并针对分类概率进行了可视化统计。该应用示例仅为澄清方案要点及展示方案效果而用,不应以此限定本发明的保护范围。
[0097]
需要说明的是,以上内容仅仅说明了本发明的技术思想,不能以此限定本发明的保护范围,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰均落入本发明权利要求书的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1