包括由具有三个操作数引用的指令可驱动的双乘双加运算符的处理器的制作方法
1.本发明涉及处理器核的数字处理硬件运算符的实现,特别是通过乘法和加法运算组合几个数的运算符。
背景技术:
2.被操纵的数可以以不同的格式被编码,诸如定点或浮点、单精度或双精度、整数和伽罗瓦域(galois field)元素表示。组合运算可以包括例如多项式求值运算、复数算术运算、以及矩阵或向量乘法运算。
3.许多应用涉及数的乘积之和。例如,对于矩阵乘法或者诸如三角函数和对数函数的超越函数,就是这种情况,它们通过多项式来逼近。诸如深度学习的人工智能技术使用可能有数百个行和列的矩阵乘法以及线性组合计算。
4.在主要的通用处理器核中,通过依赖执行融合乘加(fma)的硬件运算符来执行数的乘积之和。具体地,该运算符通过以下方式来执行具有三个操作数a、b、c(其可以是浮点数)的a
·
b+c运算:首先计算操作数a和b的乘积,然后将乘积与操作数c相加。加法的结果被四舍五入为可以浮点格式表示的数。该数可被存储在寄存器中,以用于使用该结果作为新的fma运算的加法操作数的目的。
5.通常,处理器核指令集中的指令接受采用处理器核寄存器标识符形式的不超过三个的显式操作数,即,两个源寄存器标识符包含操作数的值,目的地寄存器标识符旨在接收运算的结果。
6.为了性能的原因,期望实现具有组合多个乘法和加法的硬件运算符的处理器核,并对处理器核的指令集添加激活该硬件运算符的指令。
7.因此,期望提供一种处理器核指令集,该指令集包括可以组合超过三个操作数而不使用超过三个寄存器标识符的指令,以便使用最少数量的指令来对例如多项式、复数乘法或矩阵乘法求值。
技术实现要素:
8.实施例涉及一种由处理器处理数据的方法,该方法包括以下步骤:由处理器接收包括与三个寄存器引用相关联的运算符代码的指令,该三个寄存器引用指定被配置为包含乘法操作数对和加法操作数的寄存器以及被配置为接收运算符结果的结果寄存器,运算符代码指定被配置为计算乘法操作数对的乘积并将乘积与加法操作数相加的运算符;由处理器的指令解码器对指令进行解码,以确定要被执行的运算符以及包含要被提供给运算符的操作数和运算符的结果的寄存器;由处理器的算术电路使用在由寄存器引用指定的寄存器中的操作数来驱动运算符;以及将运算符的结果存储在所指定的结果寄存器中。
9.根据实施例,寄存器引用包括分别指定以下项的两个寄存器引用:寄存器组的两对连续寄存器,其被配置为包含乘法操作数;或者寄存器组的两组n个连续寄存器,其被配
置为包含乘法操作数,其中,运算符被配置为通过将两组中的一组中的寄存器与两组中的另一组中的相应寄存器相关联来从n对寄存器中计算n个乘积。
10.根据实施例,寄存器引用包括:指定被配置为包含加法操作数并接收由运算符提供的结果的相同寄存器的寄存器引用;或者指定寄存器组的两个连续寄存器的寄存器引用,该两个连续寄存器分别被配置为包含加法操作数和接收由运算符提供的结果;或者指定被配置为包含加法操作数的寄存器的寄存器引用,以及指定被配置为接收由运算符提供的结果的寄存器的寄存器引用。
11.根据实施例,乘积被同时计算,并且加法被同时执行。
12.根据实施例,寄存器引用指定多个操作数集,并且每个所指定的寄存器包括每个操作数集中的一个操作数,同时在每个操作数集上执行运算符,所指定的结果寄存器包含使用操作数集的运算符的结果。
13.根据实施例,该方法包括以下步骤:由处理器接收用于对多项式求值的指令系列,其中,该指令系列中的指令指定运算符和五个操作数,每个指令被配置为对二次多项式的涉及变量的两个项求值,其中该二次多项式是从要被求值的多项式的分解中产生的,并且每个指令被配置为计算两个项与二次多项式的第三项之和;将该指令系列中的指令的结果寄存器在该指令系列的后续指令中指定为要与变量的平方相乘的乘积操作数寄存器;以及由处理器连续地执行指令系列中的指令,以计算要被求值的多项式的涉及变量的值。
14.根据实施例,要被求值的多项式被预先分解为两个多项式,该两个多项式分别将包含被升到偶数次幂的变量的项和包含被升到奇数次幂的变量的项分组,该指令系列包括分别用于计算两个多项式的两个指令系列。
15.根据实施例,该方法包括以下步骤:由处理器接收用于对两个向量的点积求值的指令系列,该指令系列包括指定运算符的指令,该指令被配置为每一个计算乘积的两个项并将它们与通过执行指定运算符的指令系列中的前一指令而获得的结果相加;以及由处理器连续地执行指令系列中的指令。
16.根据实施例,指令包括选择性地指示在计算和之前要反转每一个乘积的符号的参数。
17.根据实施例,指令包括选择性地指示由寄存器引用之一指定的指定乘法操作数的寄存器在计算乘积之前要被成对交换的参数。
18.根据实施例,该方法包括以下步骤:由处理器接收用于对两个复数的乘积求值的指令系列,该指令系列包括指定运算符和分别包含两个复数的实部和虚部的寄存器对的两个指令,两个指令中的一个指令被配置为计算乘积的实部,两个指令中的另一个指令被配置为计算乘积的虚部;以及由处理器执行指令系列中的指令。
19.根据实施例,操作数以下列格式之一被编码:单精度或双精度浮点,定点,整数,以及属于伽罗瓦域的数。
20.根据实施例,处理器的算术计算电路被配置为通过舍入运算来计算乘积以及和,而不损失精度。
21.实施例还可以涉及被配置为实现先前定义的方法的处理器。
22.根据实施例,处理器包括多个处理单元,该多个处理单元用于并行地驱动用于计算乘积并将乘积与加法操作数相加多个运算符。
23.根据实施例,处理器包括运算符,该运算符包括多个乘法器和加法器,每个乘法器计算操作数对的乘积,加法器将乘积一起与加法操作数相加。
附图说明
24.将在下面与附图相结合地描述本发明的实施例的示例,其中:
25.图1是双乘双加运算符的示意图。
26.图2示出可用作本发明的基础的处理器核架构的示例。
27.图3是融合双乘双加运算符的示例的示意图。
28.图4是融合双乘双加运算符的另一个示例的示意图。
具体实施方式
29.本公开提供一种处理器核,在它的指令集中具有用于驱动组合两个乘法和两个加法的fdmda运算符以执行a1
·
b1+a2
·
b2+c运算的指令。该运算符执行等效于两个fma运算。在实施例中,fdmda运算符与三个寄存器引用相组合,以指定运算符的五个操作数并指定接收运算的结果的寄存器。
30.图1示出融合乘加运算符fdmda。该运算符与两个乘法操作数对或者被乘数(a1,b1)和(a2,b2)以及加法操作数c相关联。被乘数对(a1,b1)和(a2,b2)被提供给相应的乘法器。所产生的两个乘积p1、p2(被称为“部分乘积”)和加法操作数c被加法器树addt同时相加。被乘数和加法运算符可以采用相同或不同精度的浮点格式,或者采用诸如定点或整数的不同格式。加法的结果被归一化和舍入电路nmrd处理以被转换成原始的浮点格式,以使得它可被重用作加法操作数c。
31.根据实施例,fdmda运算符的一个寄存器引用指定包含操作数c的值并被用于提供运算的结果的寄存器。
32.根据另一个实施例,两个操作数对(a1,b1)和(a2,b2)由两个寄存器引用来指定,其中每个寄存器引用指定寄存器组的两个连续寄存器。
33.根据示例性实施例,处理器核指令集包括指令ffdmdaw,该指令指定fdmda运算符并与寄存器引用相关联,如下所示:
34.ffdmdaw$r
x
=$r
yry+1
,$r
zrz+1
,或者
35.ffdmdaw$r
x
=$ry,$rz。
36.在该表示中,“$r
x”指定包含操作数c的寄存器r
x
,其旨在接收运算的结果,“$r
yry+1
,$r
zrz+1”或者“$ry,$r
z”指定寄存器组中的两对连续寄存器(ry,r
y+1
)和(rz,r
z+1
)。因此,所指定的每对连续寄存器包含两个操作数。该指令执行运算:r
x
=r
x
+ry·rz
+r
y+1
·rz+1
。
37.根据实施例,ffmdaw运算符可以被应用于采用单精度或双精度格式的浮点数、定点数、整数、或者属于伽罗瓦域的数的表示。
38.根据实施例,对次数为n的多项式pn求值一般被表述为:
[0039][0040]
该多项式pn被分解成次数为2的嵌套多项式,其形式如下:
[0041]
pn(x)=x2q
n-2
(x)+a1x+a0,当n是偶数时,
ꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0042]
pn(x)=xq
n-1
(x)+a0,当n是奇数时,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0043]
其中qj(x)=x2q
j-2
(x)+a
n-j+1
x+a
n-j
,当n是偶数时,j=2,4,6,...n-2(或者,当n是奇数时,j是2,4,6,...n-1)。例如,次数为6(n=6)的多项式可以被表示为以下形式:
[0044]
p6(x)=((a6x2+a5x+a4)x2+a3x+a2)x2+a1x+a0[0045]
次数为7(n=7)的多项式可以被表示为以下形式:
[0046]
p7(x)=(((a7x2+a6x+a5)x2+a4x+a3)x2+a2x+a1)x+a0[0047]
可以例如通过以下指令序列来执行多项式p6(x)的计算:
[0048]
lw$r8=x#将x载入寄存器r8中
[0049]
fmulw$r9=$r8,$r8#在寄存器r9中计算x2[0050]
lw$r7=a6#将a6载入寄存器r7中
[0051]
lw$r6=a5#将a5载入寄存器r6中
[0052]
lw$r5=a4#将a4载入寄存器r5中
[0053]
lw$r4=a3#将a3载入寄存器r4中
[0054]
lw$r3=a2#将a2载入寄存器r3中
[0055]
lw$r2=a1#将a1载入寄存器r2中
[0056]
lw$r1=a0#将a0载入寄存器r1中
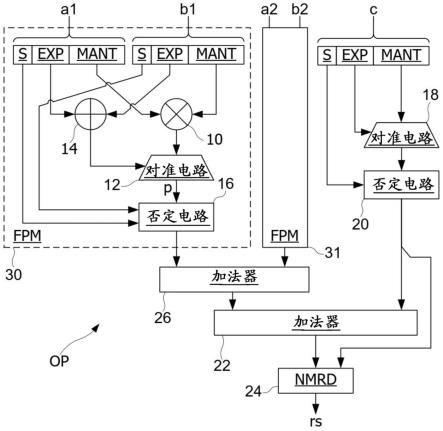
[0057]
ffdmdaw$r5=$r6r7,$r8r9#计算r5=q2(x)=a6x2+a5x+a4[0058]
fdmdaw$r3=$r4r5,$r8r9#计算r3=q4(x)=x2q2(x)a3x+a2[0059]
fdmdaw$r1=$r2r3,$r8r9#计算r1=p6(x)=x2q4(x)a1x+a0在字符“#”后面的文本是对在前的指令的解释性注释。
[0060]
可以观察到,可以仅通过三个连续的ffdmdaw指令来对多项式p6(x)求值,而不必执行中间结果传递到另一个寄存器。通常,如果n是偶数,则次数为n的多项式可以通过n/2个ffdmdaw指令来求值,而如果n是奇数,则可以通过(n+1)/2个ffdmdaw指令来求值。
[0061]
根据另一个实施例,多项式pn被分解成两个多项式p
2k
和p
2k+1
或p
2k-1
,以使得当n是偶数(n=2k)时,pn(x)=p
2k
(x)+x
·
p
2k-1
(x),当n是奇数(n=2k+1)时,pn(x)=x
·
p
2k+1
(x2)+p
2k
(x2)。通过设定x=x2,多项式p
2k
和p
2k+1
具有以下形式:
[0062][0063]
因此,两个独立的多项式被处理,其中由方程(2)和(3)定义的分解可以独立的方式被应用于这两个独立的多项式。如果处理器核允许,尤其是在simd(“单指令多数据”)处理器核的情况下,可以并行地对两个多项式p
2k
(x)和p
2k-1
(x)(或者p
2k+1
(x))求值。
[0064]
ffdmdaw指令还可以被用于计算具有以下类型的一个或多个运算的矩阵乘积或点积:
[0065][0066]
其中,v1是分量(a0,a1,a2,...,an)的向量,v2是分量(b0,b1,b2,...,bn)的向量。根
据实施例,向量v1、v2的点积可以通过以下指令序列来执行:
[0067]
lw$r1=0#初始化寄存器r1
[0068]
lw$r2=a0#将a0载入寄存器r2中
[0069]
lw$r3=a1#将a1载入寄存器r3中
[0070]
lw$r8=b0#将b0载入寄存器r8中
[0071]
lw$r9=b1#将b1载入寄存器r9中
[0072]
ffdmdaw$r1=$r2r3,$r8r9#计算r1=r1+a0·
b0+a1·
b1[0073]
lw$r2=a2#将a2载入寄存器r2中
[0074]
lw$r3=a3#将a3载入寄存器r3中
[0075]
lw$r8=b2#将b2载入寄存器r8中
[0076]
lw$r9=b3#将b3载入寄存器r9中
[0077]
ffdmdaw$r1=$r2r3,$r8r9#计算r1=r1+a2·
b2+a3·
b3[0078]
…
[0079]
因此,上面的每个ffdmdaw指令计算两个连续乘积ai·bi
和a
i+1
·bi+1
,并将它们与在寄存器r1中存储的先前结果相加。
[0080]
根据实施例,ffmdaw指令可以与附加参数相关联,该附加参数例如由可以采用以下值的后缀来定义:“.np”、“.pn”和“.nn”,并且指定第一乘积(r2
·
r4)的符号或者第二乘积(r3
·
r5)的符号是否应当在由ffdmdaw运算符执行的计算r1=r1+r2
·
r4+r3
·
r5中被反转。因此:
[0081]
ffdmdaw.np$r1=$r2r3,$r4r5
[0082]
执行运算r1=r1-r2
·
r4+r3
·
r5,
[0083]
ffdmdaw.pn$r1=$r2r3,$r4r5
[0084]
执行运算r1=r1+r2
·
r4-r3
·
r5,
[0085]
ffdmdaw.nn$r1=$r2r3,$r4r5
[0086]
执行运算r1=r1-r2
·
r4-r3
·
r5。
[0087]
根据实施例,ffdmdaw指令可以与附加参数相关联,该附加参数例如由后缀“.x”定义以指定在执行计算之前应当交换第二对寄存器中的两个值。
[0088]
因此,ffdmdaw.x$r1=$r2r3,$r4r5
[0089]
执行运算r1=r1+r2
·
r5+r3
·
r4。
[0090]
符号反转和交换参数的组合可以例如对于计算复数z1=a+b
·
i与z2=c+d
·
i(其中i2=-1)的乘积有用。因此,可以通过以下指令获得乘积z1·
z2=a
·c–b·
d+i(a
·
d+b
·
c):
[0091]
lw$r0=0#将寄存器r0初始化为0
[0092]
lw$r1=0#将寄存器r1初始化为0
[0093]
lw$r2=a#将a载入寄存器r2中
[0094]
lw$r3=b#将b载入寄存器r3中
[0095]
lw$r4=c#将c载入寄存器r4中
[0096]
lw$r5=d#将d载入寄存器r5中
[0097]
ffdmdaw.pn$r0=$r2r3,$r4r5#r0=r2
·
r4-r3
·
r5=a
·c–b·d[0098]
ffdmdaw.x$r1=$r2r3,$r4r5#r1=r2
·
r5+r3
·
r4=a
·
d+b
·
c,寄存器r0、r1分别接收复数z1、z2的乘积的实部(a
·c–b·
d)和虚部(a
·
d+b
·
c)。
[0099]
类似地,可以通过另一个复数的共轭来计算复数的乘积:
[0100][0101]
可以通过以下两个指令获得乘积
[0102]
ffdmdaw$r0=$r2r3,$r4r5#r0=r2
·
r4+r3
·
r5=a
·
c+b
·
d,以及
[0103]
ffdmdaw.np.x$r1=$r2r3,$r4r5#r1=-r2
·
r5+r3
·
r4=-a
·
d+b
·
c。
[0104]
可以观察到,这些指令允许单独指定接收乘积的实部和虚部的寄存器。如果处理器核允许,特别是在具有simd指令的处理器核的情况下,因此,可以在单个运算中或并行地计算复数的向量的点积,乘积的实部和虚部可在指令中所指定的各个向量中获得。
[0105]
还应当注意,可以以各种其他方式在ffdmdaw指令中指定被乘数对(a1,b1)、(a2,b2)。例如,指令ffdmdaw$r1=$r2r3,$r4r5可以指定运算r1=r2
·
r3+r4
·
r5+r1。在这种情况下,“.x”参数被用于交换寄存器r3和r5。
[0106]
根据实施例,ffdmdaw指令包括第四寄存器引用以指定分别包含加法操作数c和运算的结果的两个不同的寄存器。因此,例如,指定fdmda运算符的指令可以被表述如下:
[0107]
ffdmdaw$r0=$r2r3,$r4r5,$r1#r0=r2
·
r4+r3
·
r5+r1。
[0108]
根据另一个实施例,指定该指令的被乘数的ffdmdaw寄存器引用的每一个指定处理器核寄存器文件的一组n个连续寄存器。出于硬件的原因,n可被限制为2的幂(n=2n,n=1,2,3,...)。因此,例如,指定n=4的fnmna运算符的指令可以被表述如下:
[0109]
ffnmnaw$r1=$r4r5r6r7,$r8r9r10r11
[0110]
#r1=r1+r4
·
r8+r5
·
r9+r6r
·
10+r7
·
r11,或者
[0111]
ffnmnaw$r1=$r4,$r8
[0112]
#r1=r1+r4
·
r8+r5
·
r9+r6
·
r10+r7
·
r11。
[0113]
关系式(2)和(3)可以被一般化并适合于其中ffnmnaw指令可以执行四个或更多乘法并将所获得的所有乘积与加法操作数相加的情况。因此,取决于在ffnmnaw指令中指定的被乘数对的数量,要被求值的多项式可被分解为次数为4或更多的多项式。在这种情况下,可以在ffnmnaw指令中使用“.x”参数以规定在所指定的两组n个寄存器中的一组中的每对寄存器中的寄存器要被交换。另外,该指令可以与用于在所指定的两组n个寄存器中的一组中的每个寄存器的“.n”/“.p”参数相关联。
[0114]
更一般地,ffmddaw(或ffnmnaw)指令可以被扩展为simd指令以同时处理操作数集(每个操作数集包括q个元素)以同时对q个fdmda(或ffnmnaw)运算求值。例如,在指令ffdmdawq$r0=$r2r3,$r4r5中,寄存器ri(i=1,2,...5)每一个包括q=4个操作数ri[j],j=1,2,3,4,并且通过执行四个运算来执行该指令:
[0115]
r0[j]=r2[j]
·
r4[j]+r3[j]
·
r5[j],其中j=1,2,3,4。
[0116]
因此,在ffdmdawq指令中指定的寄存器是在ffdmdaw指令中指定的寄存器的四倍。
[0117]
图2示出在其指令集中可以具有ffdmdaw指令的处理器核prc的示例。该处理器核具有深度为7级(stage)的流水线,包括指令预取级pf、指令解码级id、寄存器读取级rr和四个指令执行级e1至e4。
[0118]
pf级在本质上包括缓冲器pfb,其存储从指令高速缓存ich馈送的预加载指令。id级包括控制形成级rr的寄存器文件rf的指令解码单元dec。解码单元被配置为对ffmdaw指令进行解码。寄存器组rf管理通用寄存器gpr,在该示例中是64个64位寄存器r0至r63。取决于被解码的指令,所选择的寄存器被读取或写入到形成执行级e1至e4的多个并行处理单元之一。这些处理单元可以包括访问数据高速缓存dch的加载/存储单元lsu、浮点单元fpu、被连接并被配置为根据来自解码器dec的输入来处理专用于它的指令的分支和比较单元bcu、一个或多个算术逻辑单元alu0、alu1、以及可以包括一个或多个fnmna类型的运算符(n=2n)的乘法单元mau。mau可以与fpu合并。
[0119]
处理器核具有vliw(超长指令字)架构。因此,解码单元dec处理可包含要被同时执行的多个指令的分组,在此,该核可最多同时执行5个指令,在e1-e4执行级的每个处理单元上执行一个,在如下所述的bcu单元中执行一个。
[0120]
bcu单元被设计为支持分支管理,并包括一组系统功能寄存器,该组sfr包括被配置为保存当前被执行的指令的地址(或在vliw分组中的第一个指令的地址)的程序计数器pc、以及定义在其中执行当前指令的特权环、关联权限和被屏蔽的异常等的处理器核状态寄存器ps。还提供了存储库spc和sps以用于保存程序计数器和处理器核状态寄存器。
[0121]
处理器核还包括各种外围单元,其包括基于外部事件而生成对bcu的中断的中断控制器itc、与地址转换表tlb相关联的存储器管理单元mmu、输入/输出接口if、性能监视器pm、高速缓存存储器dch等。
[0122]
图3表示混合精度结构fdmda(fp16/fp32)的示例性运算符op。没有描述处理标准化的浮点数的细节通常所需的一些元素,诸如非规格化数、未定义数(nan)、无穷大数等。
[0123]
运算符op包括多个浮点乘法单元fpm30、31,其中每个单元提供定点结果。每个fpm单元接收例如采用格式fp16(或二进制16)或fp31(或二进制32)的被乘数对(a1,b1)、(a2,b2)。每个被乘数包括符号位s、指数exp和尾数mant。两个尾数被提供给乘法器10,乘法器10计算尾数mant的乘积作为整数。尾数乘积被提供给对准电路12,对准电路12由产生被乘数a1和b1(或a2和b2)的指数exp之和的加法器14控制。对准电路12被配置为考虑指数之和来执行尾数乘积的转换,以将被乘数a1、b1(或a2、b2)的乘积p作为定点数提供。
[0124]
对准电路12的输出被传递到否定电路16,否定电路16被配置为当被乘数的符号相反时将绝对值的符号反转。因此,否定电路16产生的数构成乘法单元30、31之一的输出。因此,每个部分乘积a1
·
b1、a2
·
b2由相应的乘法单元30、31计算。部分乘积被提供给加法器26。
[0125]
此外,例如采用fp32(或二进制32)格式被提供给运算符op的加法操作数c包括符号位s、指数exp和尾数mant。尾数mant被提供给由操作数c的指数控制的对准电路18。电路18被配置为执行浮点操作数c到定点数的转换。
[0126]
由对准电路18提供的数被传递经过由操作数c的符号位控制的否定电路20。替代地,可以省略否定电路20,并且在否定电路16处,如果乘积的符号不等于操作数c的符号,则可以将乘积的符号反转。
[0127]
因此,由加法器26提供的定点数将与被转换为定点的加法操作数c相加。因此,对准电路18执行向定点数的转换,并且相应地调整下游处理。特别地,操作数c的高阶位被提供给加法器22。在部分乘积之和一侧,由加法器26提供的80+o位在左右被补充24个固定值
位(对于正结果是0,或者对于负结果是1)。
[0128]
加法器22接收加法器26的输出和由否定电路20提供的有符号数的高阶位。否定电路20的输出的低阶位在下游舍入计算中使用。
[0129]
加法器22的输出被归一化和舍入电路24处理,该归一化和舍入电路用于将加法的定点结果转换为采用fp32格式的浮点数rs。乘法单元30、31和加法器22、26的大小可调整以执行无损或舍入计算。另外,可以正确地计算电路24所执行的舍入。
[0130]
因此,图3的运算符op结构在将最终加法结果转换为浮点数时只执行一次舍入,并且该单次舍入可以在任何情况下被正确地计算。
[0131]
当然,乘法单元fpm的数量可以被扩展到超过两个,以执行具有多于个被乘数对的ffnmnaw指令。实际上,可以观察到,乘法单元fpm彼此独立,因为没有必要比较部分乘积的指数以执行部分乘积的尾数的相对对准。每个fpm单元转换到对所有数共同的相同定点格式。因此,在设计上特别容易根据需要改变乘法单元fpm的数量,因为在乘法单元之间没有相互依赖性。根据操作数的数量来调整多加法器26的结构也很容易,因为它是根据系统规则进行的。因此,运算符的复杂度可以保持与乘法单元的数量成正比。
[0132]
根据图4所示的实施例,fdmda运算符op1进一步包括接收操作数b1、b2的反相器电路35,用于根据控制信号xc交换这些操作数。因此,在信号xc的给定状态下,操作数b1被提供给乘法单元31而不是单元30,并且操作数b2被提供给乘法单元30而不是单元31。取决于在ffdmdaw指令中参数“.x”的存在,可以由指令解码器dec控制信号xc的状态。
[0133]
运算符op1进一步包括两个否定电路36、37,其分别由两个信号n1、n2控制,以在在乘法单元30的输出处的乘积和在乘法单元31的输出处的乘积在加法器26中被加在一起之前分别反转在乘法单元30的输出处的乘积和在乘法单元31的输出处的乘积的符号。根据与指令ffdmdaw相关联的任何一个参数“.np”、“.pn”、“.nn”的存在来定义信号n1、n2的状态。
[0134]
对于本领域技术人员,显然,本发明能够有各种替代方案和应用。特别地,在图3和图4中示出的运算符已经被描述为组合逻辑电路。在时钟频率相对较快的处理器核中,组合逻辑电路的反应时间可能太慢。在这种情况下,通过提供用于存储中间结果(例如,存储对准电路12、18和/或电路30、31和20的输出数)的寄存器,运算符可以具有流水线结构。参考图3和图4描述的运算符可以容易地被适配于其他精度格式,无论是标准化的还是非标准化的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1