同时使用多个处理器来处理矩阵的系统的制作方法
1.本发明涉及数字表示的数的矩阵的乘法,尤其涉及由专用硬件加速器辅助以用于矩阵运算的处理器。
背景技术:
2.人工智能技术,尤其是深度学习,在大矩阵的乘法方面要求特别高,其中大矩阵可以有几百行和几百列。因此,专用于矩阵乘法的硬件加速器应运而生。
3.大矩阵的乘法通常是分块进行的,即,通过将矩阵分解成大小适合计算资源的子矩阵。因此,加速器被设计以有效地计算这些子矩阵的乘积。
4.专用于矩阵乘法的硬件加速器面临若干挑战,这些挑战与向加速器的计算单元提供被存储在共享存储器中的矩阵数据而不导致计算单元饥饿或利用不足有关。例如,存储器中的数据存储格式可能与计算单元所需的格式不匹配,以使得可能引入延迟和数据缓冲器以对数据重排序。
5.kalray的专利申请us2020/0201642公开了一种处理器架构,该处理器架构包含紧密耦合的协处理器,该协处理器包括它自己的寄存器文件并实现用于在存储器与协处理器寄存器之间传递数据的特殊机制。由于专用指令集,因此,处理器能够在对要相乘的两个矩阵的整个处理中以最佳方式使用存储器带宽。
6.然而,当寻求处理的并行化时,即并行使用多个处理器来处理同一个矩阵乘法,在存储器带宽优化方面将出现挑战。
技术实现要素:
7.一般地,提供一种用于使用多个处理元件对被存储在同一共享存储器中的两个矩阵进行块处理的方法,其中一个矩阵被按行存储,另一个矩阵被按列存储,其中,每个处理元件通过相应的n位访问被连接到共享存储器,并通过双向n位点对点链路被连接到第一相邻处理元件。该方法包括在一个处理器指令周期中执行的以下步骤:在处理元件中,通过相应的存储器访问来接收两个矩阵中的同一个矩阵的相应的不同n位段;以及借助于对应的点对点链路,与第一相邻处理元件交换两个矩阵中的第一矩阵的n位段,该第一矩阵的n位段是在前一指令周期中在相邻的处理元件中被接收的。
8.根据实施例,每个处理元件通过相应的双向n位点对点链路被连接到第二相邻处理元件。该方法包括在后续的指令周期中执行的以下步骤:在处理元件中通过相应的存储器访问来接收两个矩阵中的同一个矩阵的相应的不同n位段;以及借助于点对点链路,与第二相邻处理元件交换两个矩阵中的第二矩阵的n位段,该第二矩阵的n位段是在前一指令周期中在相邻的处理元件中被接收的。
9.每个所接收的n位段可包含分别属于m个n位子矩阵的m行或列,每个子矩阵具有偶数r个行或列,其中,r可被m整除。该方法则包括以下步骤:重复接收或交换步骤r次,以及将所得到的r个所接收的段存储在n位寄存器的r个相应的元组中,由此,r个元组中的每个元
组包含分别属于m个子矩阵的m行或列;对r个元组的内容进行转置,以使得m个子矩阵中的每个子矩阵被完全包含在一组r/m个元组中;以及对每个子矩阵单独使用包含它的r/m个元组作为执行单元的操作数来进行操作。
10.还提供了一种处理器,其包括:多个超长指令字处理元件;通过相应的端口被连接到每个处理元件的共享存储器;连接两个相邻的处理元件的双向点对点链路。每个处理元件具有存储器访问管理单元和能够同时执行在vliw指令包中包含的相应指令的两个算术逻辑单元。第一算术逻辑单元被配置为通过在由参数标识的本地寄存器中存储在点对点链路的输入通道上存在的数据来对数据接收指令进行响应。第二算术逻辑单元被配置为通过将由参数标识的本地寄存器的内容写入点对点链路的输出通道来对数据发送指令进行响应。
11.处理器可以包括用于点对点链路的每个通道的fifo缓冲器,处理元件的第一算术逻辑单元被配置为响应于接收指令,从输入通道的fifo存储器中取回当前数据;以及处理元件的第二算术逻辑单元被配置为响应于发送指令,在输出通道的fifo存储器中堆叠本地寄存器的内容。
附图说明
12.将关于附图在仅为示例性目的提供的以下描述中公开实施例,在附图中:
13.图1是集成与中央处理单元强耦合的协处理器的处理器的框图。
14.图2是在执行子矩阵乘积中提供计算能力增加四倍的处理器架构的实施例的框图。
15.图3a至图3c示出图2的结构中的完整数据交换周期。
16.图4示出处理元件在两个处理阶段期间的寄存器内容。
17.图5示出作为在处理元件中执行的vliw指令周期的图3a至图3c的三个阶段。
具体实施方式
18.图1是在前面提到的专利申请us2020/0201642中公开的处理器架构的框图。它包括与协处理器12强耦合的通用中央处理单元(cpu)10,协处理器12集成了专用于矩阵乘积计算的硬件运算符。“强耦合”应被理解为协处理器遵守在cpu中执行的并由硬件执行单元14实施的循环机器指令。
19.更具体地,处理器指令集中的一些机器指令包含专用于协处理器的命令。当这些指令到达cpu的对应执行单元14时,执行单元通过控制线ctrl来配置协处理器操作。协处理器被连线以立即遵守在这些控制线上存在的信号。事实上,协处理器是cpu的执行单元14的扩展,其遵守处理器的通用指令集的扩展。因此,除了使执行单元适应协处理器控制之外,cpu 10可以是通用类型的,特别是允许执行操作系统或从通用编程语言编译的程序。
20.协处理器12包括代数计算单元16,其包括专用于矩阵乘法计算的硬件运算符。独立于cpu 10的常规寄存器文件20,协处理器还集成了它自己的工作寄存器集合或寄存器文件18。
21.寄存器文件18和20通过n位数据总线d被连接到共享存储器22。遵从常规cpu执行单元的地址和存储器控制总线没有被示出。协处理器的寄存器18具有与数据总线相同的大
小n,并被配置为遵守来自cpu的执行单元14的命令。
22.要相乘的两个矩阵[a]和[b]最初被存储在共享存储器22中。取决于所使用的编程语言,矩阵被默认以行优先格式存储(即,同一行的元素位于连续的地址)或者以列优先格式存储(即,同一列的元素位于连续的地址)。c编程语言使用第一种格式,而fortran使用第二种格式。在任何情况下,这些编程语言所使用的标准线性代数库(blas)提供转置参数,以在计算需要时将矩阵从一种格式转换为另一种格式。
[0023]
针对本架构的需要,要相乘的两个矩阵被以互补的格式存储,例如,第一矩阵[a]被以行优先格式存储,第二矩阵[b]被以列优先格式存储。因此,矩阵[b]被以转置形式存储。图1示出x+1行和y+1列的矩阵[a]以及y+1行和z+1列的矩阵[b]的存储器内容。行数等于矩阵[a]的列数的矩阵[b]可以与矩阵[a]相乘。
[0024]
在具有x+1行和z+1列的结果矩阵[c]中,每个元素c[i,j]是矩阵[a]的第i行和矩阵[b]的第j列的点积,其中,行和列被认为是y+1个分量的向量,即:
[0025]
c[i,j]=a[i,0..y]-b[0..y,j]
[0026]
协处理器12被设计为以全硬件方式将源矩阵的两个子矩阵相乘,第一子矩阵[a]具有固定行数r,第二子矩阵[b]具有固定列数q。子矩阵的剩余维度p(在下文中将被称为“深度”)可根据矩阵的元素的格式和被分配给硬件操作器的面积或功率预算来配置。因此,这些子矩阵的乘法产生r
×
q个元素的结果子矩阵[c]。
[0027]
暂时假设r等于q,该数字与p一起确定执行乘法所需的硬件资源。对于人工智能应用,值p=16提供一个有趣的折衷方案,并将在下面被用作示例。实际上,人工智能计算倾向于使用混合精度矩阵乘法,其中,要相乘的矩阵的元素适合8或16位,很少适合32位,而结果矩阵的元素适合以浮点、小数或整数表示的32或64位。要相乘的矩阵的小精度降低了运算符的复杂性,并且允许的深度p比处理在通用cpu中通常使用且分别以32和64位编码的“单精度”和“双精度”浮点数所需的深度更大。
[0028]
此外,每个要相乘的子矩阵被认为具有n位的整体大小倍数,其中,n是数据总线d的大小,作为示例,其在下面将被假设为256位。这导致子矩阵具有r=4行或列并且深度为64位或64位的倍数的实际情况。取决于应用,该深度被16到64位的字节或字占据。这些可以是整数或定点数或浮点数。
[0029]
如果期望并行处理若干个子矩阵乘积,则自然会使用若干个图1所示类型的处理器。然而,计算能力并没有系统地乘以并行处理器的数量,这是因为存储器带宽由于矩阵相乘的某些特性也增加了,这意味着每个处理器与其邻居处理器处理相同的数据。
[0030]
更具体地,各自计算结果矩阵的同一行组中的子矩阵的两个处理器各自使用也被另一个处理器使用的源子矩阵。换句话说,同一个子矩阵被使用两次,每个处理器使用一次,这可能涉及从存储器中对每个子矩阵的两次读取。当两个处理器在同一列组上计算时也是如此。在最好的情况下,针对r
×
p矩阵与p
×
q矩阵的乘积的存储器读取总量与处理器数量的平方根成正比地增加:对于一个处理器是r
×
p+p
×
q,对于四个处理器是4
×
(r/2
×
p+p
×
q/2),对于十六个处理器是16
×
(r/4
×
p+p
×
q/4)等。
[0031]
图2是处理器架构的实施例的框图,该架构允许针对计算子矩阵乘积增加四倍功率,同时仅增加四倍存储器带宽,而常规优化的实施例会需要将该带宽乘以八。
[0032]
处理器包括四个处理元件pe0至pe3,每个处理元件可以具有图1的处理器的结构。
每个处理元件通过相应的n=256位的独立数据总线d0-d3被连接到共享存储器22。存储器22不需要具有全四重存取结构,即其中总线d0-d3中的每条总线提供对整个存储器的访问。实际上,如在下文将看到的,没有处理元件将需要访问存储器以获取由另一个处理元件使用的数据。因此,存储器22可以是四体(4-bank)结构的,其实现比全四重存取存储器明显更简单。
[0033]
此外,处理元件经由n=256位的双向点对点链路被连接成环,即,元件pe0与pe1之间的链路x01、元件pe0与pe2之间的链路x02、元件pe1与pe3之间的链路x13、以及原件pe2与pe3之间的x23。
[0034]
每个点对点链路被连接到它的两个相邻的处理元件,更具体地,被连接到那些处理元件的寄存器文件18,以使得处理元件可以将其任何一个寄存器18中的内容传送到相邻的处理元件之一的任意寄存器18。
[0035]
这种传送可以通过在一个处理元件中执行被标记为“send.pe$v”的发送指令来协调,其中,pe指定目标处理元件(实际上是要使用的x链路),$v指定其内容(实际上是向量)要被发送的本地寄存器。目标处理元件执行被标记为“recv.pe$v”的互补接收指令,其中,pe指定源处理元件(实际上是要使用的x链路),$v指定所传送的数据将要被存储在其中的本地寄存器。
[0036]
send和recv指令可以与通常被用来管理fifo缓冲器的“push”和“pop”指令类似地实现。点对点链路的每个通道则被提供有fifo存储器。在这种情况下,recv指令使得当前数据从输入通道的fifo存储器中读取,send指令使得数据被堆叠在输出通道的fifo存储器中。在这种情况下,取决于fifo的大小,在相邻的处理元件上执行的send和recv指令可以相隔几个周期被执行,而不会触发这些处理元件之间的等待。如果过早地执行recv指令(当输入通道的fifo存储器为空时),则处理元件被暂停。如果在输出通道fifo已满时执行send指令,则处理元件也被暂停。
[0037]
图3a至图3c示出在处理矩阵[a]的16个256位行段和矩阵[b]的16个256位列段中图2的结构中的完整数据交换周期。每一段中的256位被按编号为[0..31]的字节分组。
[0038]
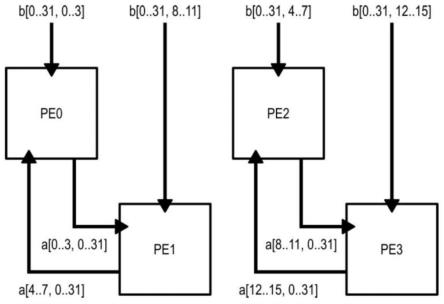
在图3a中,在第一阶段,每一个处理元件pe0至pe3从存储器并行接收包含四个段的块,分别为a[0..3,0..31]、a[4..7,0..31]、a[8..11,0..31]和a[12..15,0..31]。由于每个段是数据总线的大小,因此,这个阶段实际上需要四个存储器读取周期。
[0039]
在图3b中,在可以紧跟第一阶段的第二阶段中,每一个处理元件pe0到pe3从存储器并行接收包含四个段的块,分别为b[0..31,0..3]、b[0..31,8..11]、b[0..31,4..7]和b[0..31,12..15]。由于每个段是数据总线的大小,因此,这个阶段也需要四个存储器读取周期。
[0040]
在第二阶段期间,垂直相邻的处理元件通过它们对应的点对点链路来交换在前一阶段中接收到的矩阵[a]的段。具体地,处理元件pe0和pe1交换段a[0..3,0..31]和a[4..7,0..31],而处理元件pe2和pe3交换段a[8..11,0..31]和a[12..15,0..31]。给定256位大小的点对点链路,则这些段交换也需要四个周期。
[0041]
因此,在这个阶段期间,在每个处理元件中发生四个段读取周期和四个段交换周期。然而,由于读取周期和交换周期不会在相同的通信通道上发生,因此,交换周期可以与读取周期同时发生。这可以通过使用可同时执行多个操作的处理元件架构(诸如vliw(超长
指令字)核心架构)来实现,其中,读取操作和交换操作可以由两个独立的执行单元实现,每个执行单元对于专用指令并行地进行响应。因此,第二阶段可以只需要四个周期。
[0042]
在该第二阶段,由其他vliw指令并行控制的其他独立执行单元也可以参与执行涉及在处理元件中存在的矩阵数据的计算,如后面将说明的,以使得在存储器总线的占用中没有死时间,并且无需多次从存储器中读取相同的数据。
[0043]
在图3c中,在紧接第二阶段的第三阶段中,水平相邻的处理元件通过它们对应的点对点链路交换在前一阶段中接收到的矩阵段[b]。具体地,处理元件pe0和pe2交换段b[0..31,0..3]和b[0..31,4..7],而处理元件pe1和pe3交换段b[0..31,8..11]和b[0..31,12..15]。这些段交换需要四个周期。
[0044]
另外,在该第三阶段期间,开始处理包含矩阵[a]的16个段和矩阵[b]的16个段的新系列。因此,每一个处理元件pe0至pe3从存储器并行接收新的一组四个段,分别为a[0..3,32..63]、a[4..7,32..63]、a[8..11,32..63]和a[12..15,32..63]。
[0045]
图4示出在上述前两个阶段期间的处理元件pe0的寄存器内容$v(向量)。在下文使用的示例的上下文中,假设每个处理元件能够在一个指令周期中执行4
×
16和16
×
4字节的两个子矩阵[a]和[b](子矩阵具有16字节的“深度”)的乘法以及累加在4
×
4的32位字的子矩阵[c]中。
[0046]
在前四个读取周期(指令被标记为lv“加载向量”)期间,连续的段a[0,0..31]至a[3,0..31]被分别存储在寄存器$v0至$v3中。由于处理元件被设计为使具有16字节的深度的子矩阵相乘,因此,每个寄存器实际上包含属于源矩阵[a]中的两个相邻的子矩阵的两个16字节的行或向量,这两个相邻的子矩阵被标记为a0a和a0b。
[0047]
在随后的四个交换周期(指令被标记为recv.pe1,用于从处理元件pe1接收)期间,连续的段a[4,0..31]至a[7,0..31]被分别存储在寄存器$v4至$v7中。因此,这些寄存器中的每一个寄存器实际上包含属于源矩阵[a]中的另外两个相邻的子矩阵的两个16字节的向量,这两个相邻的子矩阵被标记为a1a和a1b。
[0048]
源矩阵[b]的子矩阵b0a、b0b和b2a、b2b被类似地组织在寄存器$v8至$v11和$v12至$v15中。
[0049]
由于字节在寄存器中的该组织方式,寄存器不适合于用作期望来自单个子矩阵的数据用于每个操作数的执行单元的操作数。
[0050]
为了在每个寄存器中找到来自单个子矩阵的数据,通过将寄存器的内容视为矩阵的r个连续行(或q列)来对寄存器$v0至$v3和$v4至$v7中的数据进行转置。例如,通过被标记为mt44d(“矩阵转置4
×
4双精度”)的指令来执行转置,该指令对4
×
4双精度矩阵(64位或8字节)进行操作。所讨论的4
×
4矩阵的四行是在mt44d指令参数中标识的四个寄存器的内容。图4所示的寄存器被切分成64位的块,如mt44d指令所使用的。该转置中的元素的64位大小是从段大小n(256位)除以r(4)而得到的。
[0051]
作为转置的结果,如图4所示,每个子矩阵a0a、a0b、a1a和a1b被完全包含在相应的寄存器对($v0,$v1)、($v2,$v3)、($v4,$v5)和($v6,$v7)中。因此,子矩阵的字节在寄存器对中的组织方式是使得每个寄存器包含四(r=4)行八(n/r=8)字节的子矩阵,在这种情况下,每列一个字节,但是该组织方式不是必需的,因为对于任何选定的组织方式,字节在被提供给硬件运算符时被固定的接线结构重排序。对于优化处理重要的是,每个寄存器包含
属于单个子矩阵的数据。
[0052]
图5示出图3a至图3c的三个阶段,作为在处理元件pe0中执行的vliw指令周期。五个列对应于处理元件pe0的独立执行单元,每个执行单元可以并行地执行vliw“包”的相应指令。lsu(加载/存储单元)管理对共享存储器的访问(lv指令)。两个算术逻辑执行单元alu0、alu1被设计为并行执行相同类型的两个指令,通常是计算指令。在此,其中一个单元alu0被进一步设计为处理通过点对点链路从相邻的处理元件接收数据(recv.pe指令),另一个单元alu1被设计为处理通过点对点链路向相邻的处理元件发送数据(send.pe指令)。分支控制单元(bcu)被用于管理比较、分支和环路。该bcu被扩展为还处理包括转置(mt44d指令)的数据移动。
[0053]
采用对alu和bcu执行单元的这些扩展,可以在vliw包中并行执行矩阵处理所涉及的多个指令,其顺序不会引入任何关于共享存储器访问的空周期。
[0054]
最后,协处理器被设计为执行特定于矩阵处理的指令,诸如在所考虑的示例的上下文中,4
×
16字节和16
×
4字节的子矩阵的乘法并累加在4
×
4的32位字子矩阵中,其指令被标记为mma4164。这种子矩阵的大小为512位,即每个子矩阵被包含在两个连续的$v寄存器中。然后,对应的硬件运算符被连线以针对每个操作数接收两个$v寄存器的适当重排序的内容。
[0055]“cyc.”列指示指令周期,“op.”列指示对子矩阵执行的操作。
[0056]
在周期1到4中,lsu执行从存储器中读取矩阵[a]的四个256位段的指令,这些段被分别加载到寄存器$v0至$v3中。在周期4中,寄存器$v0至$v3以交错形式包含子矩阵a0a和a0b,这在“op”列中被标记为a0ab。
[0057]
在周期5到8中,可以在执行单元lsu、alu0和alu1上并行地进行若干操作。通过lsu,从存储器中读取矩阵[b]的四段以被加载到寄存器$v8至$v11中,以交错形式形成矩阵b0a和b0b(b0ab)。假设相邻的处理元件pe1已经在前四个周期将子矩阵a1a和a1b加载到它的寄存器中,则通过在周期5到8中在alu0单元中执行recv.pe1指令,这些子矩阵可以通过对应的点对点链路被接收,并且也以交错形式(a1ab)被加载到寄存器$v4至$v7中。类似地,在接收到子矩阵a0a和a0b后,通过在alu1中执行四个连续的send.pe1指令以及recv.pe1和lv指令,这些子矩阵可以被发送到相邻的处理元件。
[0058]
在周期9到12中,使用寄存器$v12-$v15和$v8-$v11,通过执行对应的recv.pe2和send.pe2指令,与处理元件pe2交换交错的子矩阵b0ab和b2ab。
[0059]
同时,可以接收源矩阵[a]的新的一对4
×
16子矩阵,例如a[0..3,32..63]。
[0060]
在周期13到16中,要对其进行操作的所有子矩阵在寄存器$v0至$v15中以交错形式a0ab、a1ab、b0ab和b2ab可用。然后,在bcu中执行四个转置(mt44d)以在相应的寄存器对中隔离子矩阵a0a、a0b、b0a、b0b、a1a、a1b、b2a和b2b。
[0061]
同时,可以从源矩阵[b]接收新的一对16
×
4子矩阵,例如b[32..63,0..4],并且可以交换在周期9到周期12中接收到的子矩阵。
[0062]
因此,四个处理元件pe0-pe3被馈送来自源矩阵[a]和[b]的数据,以便以32字节的步长扫描矩阵[a]的同一16行组的所有列以及矩阵[b]的同一16列组的所有行,然后切换到两个不同的16行组和16列组,直到扫描了源矩阵的所有行和列位置。
[0063]
在所示的示例中,四个处理元件一起在第0行到第15行和第0列到第15列中以32字
节[0..31]的第一步长进行操作。处理元件被组织为计算点积:
[0064]
c[i,j]=a[i,0..31]
·
b[0..31,j],其中,i和j每个的范围是从0到15。
[0065]
处理元件pe0被设置以执行部分计算:
[0066]
c[i0,j0]=a[i0,0..31]
·
b[0..31,j0],其中,i0和j0每个的范围是从0到7,使用:
[0067]
a0a=a[0..3,0..15],b0a=b[0..15,0..3],
[0068]
a0b=a[0..3,16..31],b0b=b[16..31,0..3],
[0069]
a1a=a[4..7,0..15],b2a=b[0..15,4..7],
[0070]
a1b=a[4..7,16..31],b2b=b[16..31,4..7]。
[0071]
为此,在周期17到24中,已被隔离在寄存器对$v中的4
×
16和16
×
4子矩阵相乘并累加(mma4164),以计算它们对结果矩阵[c]的4
×
4的32位字贡献,即:
[0072]
c[0..3,0..3]+=a0a*b0a+a0b*b0b,
[0073]
c[0..3,4..7]+=a0a*b2a+a0b*b2b,
[0074]
c[4..7,0..3]+=a1a*b0a+a1b*b0b,
[0075]
c[4..7,4..7]+=a1a*b2a+a1b*b2b。
[0076]
每个mma4164指令采用三个参数,即,接收累加结果的子矩阵的寄存器元组(在此是寄存器对)和包含操作数子矩阵的两个寄存器对。根据该配置,处理元件pe0进行计算的结果是被存储在寄存器$v40至$v47中的8
×
8的32位整数的子矩阵c0[0..7,0..7]。
[0077]
在相同的周期17到24期间,剩余的执行单元(lsu,alu0,alu1,bcu)可用以对准备用于下一步长的数据所需的操作进行排序,而没有空周期。
[0078]
类似地,元件pe1至pe3被组织为并行地执行相应的部分计算:
[0079]
c1[i0,j1]=a[i0,0..31]
·
b[0..31,j1],其中,i0的范围是从0到7,j1的范围是从8到15,
[0080]
c2[i1,j0]=a[i1,0..31]
·
b[0..31,j0],其中,i1的范围是从8到15,j0的范围是从0到7,以及
[0081]
c3[i1,j1]=a[i1,0..31]
·
b[0..31,j1],其中,i1和j1每个的范围是从8到15。
[0082]
在周期25中,每个处理元件已在其寄存器$v40至$v47中计算出当前步长对个体8
×
8数据子矩阵的贡献,该8
×
8数据子矩阵构成由四个处理元件联合计算的16
×
16结果数据子矩阵c[0..15,0..15]的四象限之一。
[0083]
一旦所有的步长已被完成,在四个处理元件的寄存器$v40至$v47中共同保存的结果子矩阵c[0..15,0..15]就是完整的,并且可被写入存储器。然后,可以启动新的不相交的16
×
16结果子矩阵的计算,例如c[16..31,0..15]。
[0084]
图5中的指令序列只是为了清楚说明不同阶段的示例。实际上,每个指令可以在它使用的数据可用时被立即执行。例如,只要相关的$v寄存器包含更新值,就可以执行send.pe1指令。因此,所示的send.pe1指令序列可以早在周期2就开始。由于recv.pe指令旨在与相邻的处理元件的send.pe指令准同步,因此,recv.pe指令序列也可以在周期2开始。
[0085]
四个mt44d指令中的每一个可以在相应的send.pe1$v3、recv.pe1$v7、send.pe1$v11和recv.pe1$v15指令之后被立即执行。
[0086]
此外,在图示的序列中,在相邻的处理元件之间交换的数据是尚未被转置的数据,
由此,该数据在交换之后被转置。转置可以在交换之前发生,或者与交换操作相结合地发生。
[0087]
在专利申请us2020/0201642中,提供了被称为“加载分散”的特定指令,其允许在读取存储器时执行转置。通过使用这些指令代替lv指令,可以省略所有的mt44d转置指令,尽管这不会影响存储器带宽,其无论如何都会被完全占用。
[0088]
已经在将4
×
16字节和16
×
4字节子矩阵相乘的上下文中描述了使用四个环形连接的处理元件的示例性应用。类似的示例有4
×
8和8
×
4的16位子矩阵的乘法(mma484指令),4
×
4和4
×
4的32位子矩阵的乘法(mma444指令),或者4
×
2和2
×
4的64位子矩阵的乘法(mma424指令)。在所有这些情况下,应用相同的计算方案,唯一的调整是结果矩阵[c]的元素的大小。因此,当结果矩阵具有64位元素时,mma4《p》4指令的累加操作数是寄存器四元组。
[0089]
在此描述的处理系统可以被解释为基于以超立方体拓扑结构(对于两个元件是段,对于四个元件是环形,对于八个元件是立方体,对于16个元件是由对应的顶点连接的两个立方体等)组织的处理元件之间的点对点链路设备的矩阵乘法的并行化。然而,先前关于这一类型的并行化的工作并没有解决矩阵根据行优先或列优先布局被存储在所有处理元件可访问的共享存储器中的限制。在此描述的用于四个处理元件之间的环形拓扑(维度为二的超立方体)的处理系统直接推广到更高维度的超立方体系统。
[0090]
此外,已经描述了实现的示例,其中,存储器总线的宽度和点对点链路的宽度(n=256位)使得被读取或交换的每个段包含分别属于存储器中的两个相邻子矩阵的m=2行。结果,在八个读取周期(lv)和八个交换周期(recv)的阶段之后,每个处理元件接收通过八个乘法与累加(mma4164)进行处理的八个子矩阵。对阶段进行排序,而在存储器带宽使用方面没有任何死时间,因为乘法的数量最多等于读取和交换的数量。
[0091]
通过将总线的宽度和点对点链路的宽度加倍(n=512),或者通过将要被mma运算符处理的子矩阵的深度减半(4
×
8,8
×
4),每个所读取或交换的段包含分别属于存储器中的四个相邻子矩阵的m=4行。结果,在八个读取周期(lv)和八个交换周期(recv)的阶段之后,每个处理元件接收十六个子矩阵,这些子矩阵可通过十六个乘法与累加进行处理。在这种情况下,由于乘法的数量是读取和交换的数量的两倍,因此,阶段会被排序,而在存储器带宽的使用方面有八个周期的死时间。这种安排的优点在于减少了对从共享存储器中读取的带宽要求,该共享存储器则可以被诸如dma单元之类的另一个总线主控器同时使用。
[0092]
为了获得没有死时间的序列,mma运算符可以被配置为处理两倍深度的操作数矩阵,其中,每个操作数矩阵接收两个子矩阵的并置。因此,对于n=512,mma运算符被配置为处理4
×
32和32
×
4操作数矩阵,每个操作数矩阵接收两个4
×
16或16
×
4的子矩阵。适合于其中增加深度p不可行的情况(如在32位或64位浮点算术中)的替代方案是在处理元件的每个指令包中实施两个mma4164操作。
[0093]
转置(mt)会被配置为对适当大小的块(对于n=512是128位)进行操作。
[0094]
该结构可以推广到是2的幂的任何整数m。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1