一种基于工业流数据的设备故障诊断方法
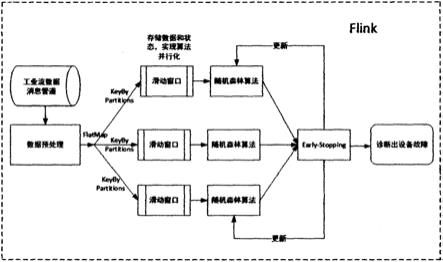
1.本发明涉及一种基于大数据和机器学习的工业设备故障诊断模型的构建方法,具体来说,将flink大数据技术和机器学习中的随机森林算法相结合,并针对随机森林的缺点加以改进引入early stopping技术,对工业设备进行诊断。
背景技术:
2.现在人类进入工业大数据时代,设备故障诊断在工业系统中显得愈发重要。提前诊断出工业设备问题,并根据其使用情况进行规划和安排,能够大大降低突发情况的出现,同时也能够降低运营成本,提高企业自身的竞争力。工业系统中数据量大,且包含较多噪声因素,传统的故障诊断模型random forest对工业大数据并不“友好”,且故障诊断率、准确率都较低,同时会出现过拟合现象,具有一定的局限性。因此应采用多种模型形成的故障诊断方法,并和大数据技术相结合来克服单种方法的缺点。因此,结合多种模型和大数据技术形成的方法将成为工业系统中设备故障诊断的方向。
技术实现要素:
3.发明目的:针对当前工业大数据规模大、类型杂、噪声多的特点,且传统单一设备诊断方法不具有针对性、预测精确度低的缺点,利用flink对工业大数据进行预处理并实现算法的并行化,且采用随机森林模型和early stopping相结合的方法对设备故障进行诊断,提高设备故障诊断的准确性。
4.技术方案:一种基于random forest-early stopping的设备故障诊断方法,利用java作为编程语言构建三个模块,分别是flink预处理模块、random forest建模模块、early stopping去过拟合模块。因为工业大数据噪声多、无效数据多,所以先用flink对工业大数据进行预处理,并通过flink的滚动窗口实现random forest算法的并行化,提高方法的效率;接着构建随机森林模型,对正常数据和已知异常数据进行分类,根据异常数据分布特征判断故障数据。然后采用early stopping方法解决随机森林可能会出现的过拟合现象,并更新随机森林模型。最终利用训练集进行测试验证,计算出故障诊断算法的精度。包括如下步骤:
5.步骤1:利用flink将测试数据传入到kafka工业流数据消息管道中,kafka保证数据传输的局部有序性,同时起到一定的削峰作用。
6.步骤2:flink消费kafka中的数据并利用自带的rocksdb状态后端去重方式对测试数据去重。然后利用flink datastream api的evictor()方法去除和预期差异较大的无效数据;同时flink具有滚动窗口机制,处理器在每个窗口中运行一个随机森林检测算法,窗口中会保存活动点和其元数据,实现算法的并行化。
7.步骤3:构建单个决策树。当前节点预处理后的数据集为d,从根节点开始,计算数据集d的基尼系数,公式如下:
[0008][0009]
其中k为类别个数,pk为第k个类别的概率,gini指数可用来确定某个特征的最优切分点。如果样本个数小于阈值或者基尼系数小于阈值,则返回决策树子树,当前节点停止递归。若满足上述条件,在计算出来的基尼系数中,选择基尼系数最小的特征a和对应的特征值a。根据最优特征和最优特征值,把数据集d划分成两部分d1和d2,同时建立当前节点的左右节点,左节点的数据集d为d1,右节点的数据集d为d2。对左右的子节点递归的调用以上步骤,生成单个决策树。
[0010]
步骤4:针对数据集d抽样b次并放回,当b小于等于数据集d的个数m时得到一个子集,该子集作为新的训练集。重复上述方式抽样c次,得到c个随机采样集。
[0011]
步骤5:根据c个随机采样集,分别构建步骤3的决策树。增加随机抽取属性的步骤,在当前节点包含的d个属性中随机抽取c个属性,当c不大于d时,从含有c个属性的属性子集中选取最优属性进行划分,在建立决策树时,不对决策树进行剪枝加工处理。
[0012]
步骤6:针对c棵决策树输出各自结果,根据相对多数投票法原理,对所有决策树模型的输出结果进行投票,选择出票数最多的输出结果作为随机森林模型的输出结果,即故障数据。
[0013]
步骤7:采用early stopping(早停法),在每一轮训练数据遍历结束(epoch)时计算验证数据集的准确率,采用“no-improvement-in-n”策略,当连续10次epoch(或者更多次)没达到最佳准确率时,则可认为准确率不再提高了。此时便可以停止迭代了,并更新步骤3-6中的模型。
[0014]
步骤8:将上述训练出来的结果与实际数据比对,计算出识别的设备故障的精度。
[0015]
优选地,在所述步骤1中,利用kafka消息管道存储工业流数据,其副本机制和isr机制保证了数据发送的可靠性和高可用性,即使机器出现宕机情况,数据也不会丢失。同时kafka具有高吞吐量、低延迟的特点,即使再多的数据也能够轻松应对。
[0016]
优选地,在所述步骤2中,利用大数据技术flink对工业大数据进行预处理,清除掉无效数据、重复数据等,减少了噪声数据对实验的影响。同时将大数据和机器学习相结合,实现了上述方法的并行化,提高了方法的应用效率。
[0017]
优选地,在所述步骤3-6中,采用随机森林算法对故障进行诊断,由于特征子集是随机选择的,所以它能够处理工业背景下的高维度数据。同时训练数据时,决策树之间是独立的,所以训练速度较快。再者即使缺失值数据较多,也能维持训练速度和准确度。
[0018]
优选地,在所述步骤7中,采用early stopping方法解决了随机森林模型面对噪声较大的工业大数据易产生的过拟合化的问题。
[0019]
本发明采用上述技术方案,具有以下有益效果:对于工业大数据设备故障诊断的方法,引入了一种新的组合模型,该方法综合了大数据技术flink、kafka以及随机森林模型和深度学习的early stopping方法,充分利用两种模型的优点,提高了设备故障诊断的灵敏度;两个模型的并行分工能够快速诊断出故障数据,同时也解决了随机森林模型可能带来的过拟合问题,提高了随机森林模型的准确性和有效性;组合模型同时和大数据技术相结合,能够更好地应对工业数据量大而导致的处理速度慢的问题,同时可实现算法的并行
化,提高设备故障诊断的效率。
附图说明
[0020]
图1为本发明实施例的体系结构和方法流程图
具体实施方式
[0021]
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本技术所附权利要求所限定的范围。
[0022]
一种基于工业流数据的设备故障诊断的构建方法,主要实现步骤如下:
[0023]
步骤1:采用的数据集为xxx企业工业现场的轧钢数据集,flink作为生产者将采集到的轧钢数据集发送至kafka消息队列中,暂存数据;
[0024]
步骤2:flink从kafka消息管道中获取数据,并用自带的rocksdb状态后端去重方式对工业大数据集去重。然后利用flink流数据api的evictor()方法去除和预期差异较大的无效数据;同时用flink的滚动窗口机制实现随机森林算法的并行化。
[0025]
步骤3:构建单个决策树。当前节点经过步骤2得到的工业大数据集为d,从根节点开始,计算数据集d的基尼系数。如果样本个数小于阈值或者基尼系数小于阈值,则返回决策树子树,当前节点停止递归。若满足条件,在计算出来的对数据集d的基尼系数中,选择基尼系数最小的特征a和对应的特征值a。根据这个最优特征和最优特征值,把数据集划分成两部分d1和d2,同时建立当前节点的左右节点,左节点的数据集d为d1,右节点的数据集d为d2。对左右的子节点递归的调用以上步骤,生成单个决策树。
[0026]
步骤4:针对轧钢数据集d抽样b次并放回,当b小于等于数据集d的个数m时得到一个子集,该子集作为新的训练集。重复上述方式抽样c次,得到c个随机采样集。
[0027]
步骤5:根据步骤4中的c个随机采样集,分别构建步骤3的决策树。增加随机抽取属性的步骤,在当前节点包含的d个属性中随机抽取c个属性(c≤d),从含有c个属性的属性子集中选取最优属性进行划分,在建立决策树时,不对决策树进行剪枝加工处理。
[0028]
步骤6:针对c棵决策树输出各自结果,根据相对多数投票法原理,对所有决策树模型的输出结果进行投票,选择出票数最多的输出结果作为随机森林模型的输出结果,即出现故障的数据。
[0029]
步骤7:采用early stopping模型,在每一轮遍历随机森林模型结束时计算验证轧钢数据集的准确率,当连续10次没达到最佳准确率时,则可以认为准确率不再提高了。此时便可以停止迭代了并更新步骤3-6中的模型。
[0030]
步骤8:将上述训练出来的结果与实际数据比对,计算出识别的设备故障的精度。
[0031]
方法比较
[0032]
通过将本方法与单一模型作对比,在效率和精确度方面分别有5.6%和1.3%的提升,并且不会出现过拟合的现象。随着数据量的增大,其方法的优势更加明显。从中我们可以发现组合模型提高了设备故障诊断的效率和精确度,具有实际的应用价值。
[0033]
最后应说明的是:以上实例仅用以说明本发明的技术方法,而非对其限制;尽管参照前述实例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对
前述各实例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1