基于MASK训练的辱骂识别方法与流程
基于mask训练的辱骂识别方法
技术领域
1.本发明涉及数据挖掘技术领域,尤其涉及一种基于mask训练的辱骂识别方法。
背景技术:
2.客户服务(customer service),主要体现了一种以客户满意为导向的价值观,它整合及管理在预先设定的最优成本——服务组合中的客户界面的所有要素。广义而言,任何能提高客户满意度的内容都属于客户服务的范围。
3.在客服的业务中,涉及大量的销售(客服)与客户的对话,严格控制销售及客服人员的言行规范、文明不仅有利于成单,更关系到公司的外在形象,辱骂是一种性质极为严重的不文明行为,应该被杜绝。传统的辱骂检测方案有关键词匹配、基于深度学习方法,这些方法存在如下一些不足:
4.(1)关键词匹配误伤率高,例如关键词“下流”,在“你提个审批,走下流程”会被当做辱骂,在我们的实验中,关键词匹配的准确率仅仅为0.065,远远不能满足生产需要。
5.(2)基于深度学习方法,比如训练语料中“你妈的xx”是辱骂文本,则训练完成后,很可能退化成关键词模型,对于“你妈的手机”也判定为辱骂文本,解决方法是补足对抗样本,例如将“你妈的手机”作为非辱骂文本放入训练集中,但这样依然会出现问题,首先容易过拟合到xx上;第二需要补足的文本随着辱骂的词成指数级增长。
6.(3)对于字面无辱骂的文本,但语义上是辱骂性质的文本,例如“长的真后现代。”这种判定更加难,且可能暗含的文本无限多,收集类似的数据成本高,且不一定能有很好的效果。
7.(4)另外就是辱骂文本在字面上的多样性,例如转换成火星文、转换成拼音、字形拆分等等。这种情况下更是让传统方法不好识别,单靠增加相应数据,成本依旧很高,且覆盖率不一定全。
8.为了解决上述问题和不足之处:我们提出了种基于mask训练的辱骂识别方法。
技术实现要素:
9.基于背景技术中提出的关键词匹配误伤率高,例如关键词“下流”,在“你提个审批,走下流程”会被当做辱骂,在我们的实验中,关键词匹配的准确率仅仅为0.065,远远不能满足生产需要的技术问题,本发明提出一种基于mask训练的辱骂识别方法。
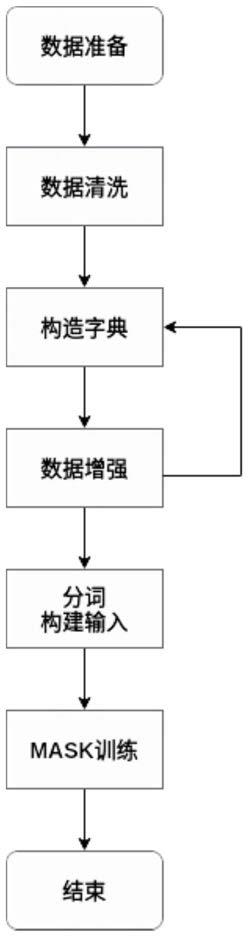
10.本发明提出的基于mask训练的辱骂识别方法,包括dusbert训练模型,具体包括以下步骤:
11.s1:数据准备;
12.s2:数据清洗;
13.s3:构造字典;
14.s4:数据增强;
15.s5:分词构建输入;
16.s6:mask训练;
17.s7:结束。
18.优选地,所述s1的步骤中,从网络上收集脏话数据,为了实验,我们收集了在明显脏词的文本约1180条,另外收集不带脏词但语义上是辱骂的的文本约300条,该文本实验中不作为训练数据,而仅仅作为特殊测试数据,非辱骂文本来自于之前各种任务的随机抽样,约7000条,并通过人工筛选和增加400条存在脏字脏词但非辱骂文本,例如“你妈的手机号码”,加入特殊测试集,所述s2的步骤中,通过人工筛选的通过一些预处理手段对这些文本清洗,所述s3的步骤中,基于收集到的语料,将预料中的脏词按字的粒度构成一个字典;
19.样本数量多,并且随机形强,将所有收集到的文本构成字典,可以有效的提高字典的准确率。
20.优选地,所述s4的步骤中,基于上述的字典数据随机做一些增强,增强的手段如转换成拼音、转换成火星文、将字进行一些拆分、随机加入一些噪音字符,将这些增强后的字符也同样加入到字典中,这里的增强仅仅对相应字典脏字脏词的数据进行增强,随后将数据按7:2:1的比例分成训练集、验证集、测试集;
21.从特殊测试集上来看,不需要额外准备数据,大大节省成本且达到较高水平,在未使用特殊测试集训练的情况下,能够区分包含脏字脏词但非辱骂语义以及暗喻辱骂文本,足可见模型方法的泛华能力。
22.优选地,所述s5的步骤中,经过数据增强后,我们对文本进行词性标注pos,考虑到对于收集文本的特点,分词采用的是ltp,然后将pos后的词以及词性一起作为bert的输入,形式如:是对应文本进行pos的第i个词,是第i个词对应的词性,这里的词性种类我们仅仅保留了训练语料中词性个数大于500的词性类别,如果某个词的词性类别小于500,则该词两边不加词性。
23.优选地,所述s6步骤中,训练过程中,当某个文本中存在上述步骤中字典包含的字,则我们以0.98的概率将改字替换成dusbert(bert)预训练任务的特殊token——[mask],而对于不在该字典的词则以0.05的概率随机替换成[mask],所以最后输入到dusbert的形式可能是[cls][p0][mask][p0][p1][w1][p1][mask]...[sep]。我们取除了[cls]、[sep]的所有token的编码进行平均池化,再接ffn做2分类任务,采用梯度传播更新网络参数,测试时,不对文本进行mask训练中的替换,而是采用分词构建输入的输入形式进行预测,当ffn输出的sigmoid值大于0.5时是辱骂,反之,不是。
[0024]
本发明中的有益效果为:
[0025]
1、该基于mask训练的辱骂识别方法,该方法最后在测试集的上非辱骂语句的f1为0.99+,辱骂文本为0.94+,marco f1为0.97,在特殊测试集上的准确率为0.93。
[0026]
2、该基于mask训练的辱骂识别方法,从特殊测试集上来看,不需要额外准备数据,大大节省成本且达到较高水平,在未使用特殊测试集训练的情况下,能够区分包含脏字脏词但非辱骂语义以及暗喻辱骂文本,足可见模型方法的泛华能力。
[0027]
3、该基于mask训练的辱骂识别方法,整个训练过程成本小且能够兼容拼音、火星文等辱骂文本的转换。
[0028]
该装置中未涉及部分均与现有技术相同或可采用现有技术加以实现。
附图说明
[0029]
图1为本发明提出的基于mask训练的辱骂识别方法的结构示意图。
具体实施方式
[0030]
下面结合具体实施方式对本专利的技术方案作进一步详细地说明。
[0031]
下面详细描述本专利的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本专利,而不能理解为对本专利的限制。
[0032]
参照图1,基于mask训练的辱骂识别方法,包括dusbert训练模型,具体包括以下步骤:
[0033]
s1:数据准备;
[0034]
s2:数据清洗;
[0035]
s3:构造字典;
[0036]
s4:数据增强;
[0037]
s5:分词构建输入;
[0038]
s6:mask训练;
[0039]
s7:结束。
[0040]
参照图1,本发明中,所述s1的步骤中,从网络上收集脏话数据,为了实验,我们收集了在明显脏词的文本约1180条,另外收集不带脏词但语义上是辱骂的的文本约300条,该文本实验中不作为训练数据,而仅仅作为特殊测试数据,非辱骂文本来自于之前各种任务的随机抽样,约7000条,并通过人工筛选和增加400条存在脏字脏词但非辱骂文本,例如“你妈的手机号码”,加入特殊测试集;
[0041]
从特殊测试集上来看,不需要额外准备数据,大大节省成本且达到较高水平,在未使用特殊测试集训练的情况下,能够区分包含脏字脏词但非辱骂语义以及暗喻辱骂文本,足可见模型方法的泛华能力。
[0042]
参照图1,本发明中,所述s2的步骤中,通过人工筛选的通过一些预处理手段对这些文本清洗,清洗后的文本更加具备随机性,可提高字典的准确度。
[0043]
参照图1,本发明中,所述s3的步骤中,基于收集到的语料,将预料中的脏词按字的粒度构成一个字典。
[0044]
参照图1,本发明中,所述s4的步骤中,基于上述的字典数据随机做一些增强,增强的手段如转换成拼音、转换成火星文、将字进行一些拆分、随机加入一些噪音字符,将这些增强后的字符也同样加入到字典中,这里的增强仅仅对相应字典脏字脏词的数据进行增强,随后将数据按7:2:1的比例分成训练集、验证集、测试集。
[0045]
参照图1,本发明中,所述s5的步骤中,经过数据增强后,我们对文本进行词性标注pos,考虑到对于收集文本的特点,分词采用的是ltp,然后将pos后的词以及词性一起作为bert的输入,形式如:是对应文本进行pos的第i个词,是第i个词对应的词性,这里的词性种类我们仅仅保留了训练语料中词性个数大于500的词性类别,如果某个词的词性类别小于500,则该词两边不加词性。
[0046]
参照图1,本发明中,所述s6步骤中,训练过程中,当某个文本中存在上述步骤中字
典包含的字,则我们以0.98的概率将改字替换成dusbert(bert)预训练任务的特殊token——[mask],而对于不在该字典的词则以0.05的概率随机替换成[mask],所以最后输入到dusbert的形式可能是[cls][p0][mask][p0][p1][w1][p1][mask]...[sep]。我们取除了[cls]、[sep]的所有token的编码进行平均池化,再接ffn做2分类任务,采用梯度传播更新网络参数;
[0047]
整个训练过程成本小且能够兼容拼音、火星文等辱骂文本的转换。
[0048]
参照图1,本发明中,测试时,不对文本进行mask训练中的替换,而是采用分词构建输入的输入形式进行预测,当ffn输出的sigmoid值大于0.5时是辱骂,反之,不是。
[0049]
本发明的关键点在于构建脏字字典(包含数据增强添加)、将词性和词进行联合输入dusbert的形式和思路、并在训练过程利用[mask]标记替换用作分类任务从而提升辱骂识别精度的方法。
[0050]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1