一种基于色彩-参数迁移的遥感建筑物震害信息提取方法
1.本发明涉及遥感建筑物震害信息提取技术领域,特别涉及一种基于深度学习和迁移学习的遥感建筑物震害信息提取方法。
背景技术:
2.地震具有突发性强、破坏性大的特点,往往给建筑物造成毁灭性的破坏,给人民生命财产安全带来极大的威胁。灾区建筑物震害信息的快速准确提取,对降低地震灾害损失、保障人民生命财产安全和社会经济可持续发展具有重要意义。传统的建筑物震害信息遥感提取方法包括面向对象方法和变化检测方法,面向对象方法需要选择恰当的分割参数,其分类效率和精度相对较低。而变化检测方法需要获得震前的高分影像,需要严格震害前后影像配准,配准误差不能大于1/3像元大小,且检测结果中仍包含许多非地震震害引起的地表变化信息,影响到了其提取性能。新提出的基于深度学习的建筑物震害信息遥感提取方法,需要通过目视标绘对样本数据进行人工震害信息处理,大量训练样本消耗掉巨大的人工和时间成本,无法满足震后建筑物震害快速提取的需求。如何精确快速提取震害建筑物的损毁情况和数量信息,并将已有建筑物震害提取知识应用到更多的地震灾区影像处理中,同时提升知识迁移学习的能力、模型迁移的性能,以此提高遥感在震害提取中的快速应用性能,需要一种高效和性能更好的建筑物震害信息提取方法。
3.本发明的主要特点在于结合待迁移的源域模型的参数和少量的目标域样本训练目标域模型,以此减少训练网络模型的人工和时间成本,并采用图像色彩迁移算法,将源域数据的色彩统计特征迁移至目标域数据,增加目标域数据和源域数据之间的相似性,从而提高建筑物震害信息的提取精度,同时解决建筑物震害信息深度卷积神经网络训练时间和人工样本制作成本较大的问题。
技术实现要素:
4.本发明的目的是提供一种基于深度学习和迁移学习的遥感建筑物震害信息提取方法,能有效减少震害信息提取深度学习模型训练的人工和时间成本。
5.具体步骤为:
6.(1)源域震害遥感影像获取:从防震减灾部门或遥感数据网站获取某一地区震后高分辨率历史遥感影像,作为迁移学习的源域影像数据。
7.(2)源域样本集创建划分和扩充增强:采用目视解译的方式,利用labelme图像标绘工具对源域影像中的“完整建筑物”和“损毁建筑物”分别进行标绘,生成对应的语义标签数据,由影像与对应的两类震害语义标签构成深度学习样本集;将样本集划分为训练集和测试集,对样本进行随机裁剪数量扩充,采用虚拟样本增强技术对深度学习样本进行数据增强。
8.(3)网络层深结构设计:设计提取震后完整建筑物、损毁建筑物的层深增长卷积神经网络结构。
9.(4)源域模型训练:设置模型训练参数,在深度学习框架下完成模型训练,保存训练好的模型与参数。
10.(5)获取最优层深结构模型和参数:针对步骤(2)中扩充的源域样本集,按照步骤(3)中设计的层深增长网络结构对模型的层深结构进行调整,分别训练不同层深结构下的网络模型。结合源域测试集比较不同层深结构模型对建筑物震害信息的提取性能,并保存提取精度和模型训练时间最佳的网络层深结构和模型参数。
11.(6)目标域震害遥感影像获取:从防震减灾部门或遥感数据网站获取另一地区的地震后高分辨率遥感影像,作为迁移学习的目标域影像数据。
12.(7)影像色彩迁移处理:利用步骤(1)中获取的源域震害影像数据,提取源域影像的色彩统计特征对目标域震害影像进行色彩迁移处理,使处理后的目标域影像具有与源域影像相近的色彩统计特征。
13.(8)目标域样本集创建划分和扩充增强:利用labelme图像标绘工具将目标域数据进行“完整建筑物”和“损毁建筑物”语义信息的标注,生成标签数据。影像和对应标签构成样本集,将样本集划分为训练集和测试集。采用随机方式对样本图像及其标签进行裁减处理,采用虚拟样本增强技术对目标域样本进行扩充。
14.(9)目标域模型训练:采用步骤(4)中获取的最优源域模型,以该模型参数作为初始值结合目标域样本集训练目标域深度学习模型。
15.(10)目标域影像建筑物震害信息提取与精度评价:利用目标域步骤(9)中模型进行目标域影像建筑物震害信息的提取,完成目标域影像建筑物震害信息提取结果精度效率评价。
16.进一步地,所述步骤(1)、(6)中获取的源域和目标域震害遥感影像对应的地震事件、震区、遥感器高度类型、成像时间不同,既可包括源域高空间分辨率卫星影像到目标域高空间分辨率航空影像的色彩-参数迁移处理,也可包括源域为高空间分辨率航空影像到目标域高分卫星影像的色彩-参数迁移处理。
17.进一步地,所述步骤(3)中网络层深结构设计中采用了层深增长网络结构优化震害信息提取性能和效率。层深增长网络结构中网络输入层可输入rgb三波段震害样本集数据,通过层深调节、逐层对称增加编码器和解码器的层深结构,包括逐层对称增加卷积层、池化层和上采样层。
18.进一步地,所述步骤(5)中为了实现网络层深结构优化,采用步骤(3)中设计的层深增长网络结构进行优化,获取最优层深结构模型,记录下最优模型权重与偏置量,同时记录训练该模型的参数,包括学习率、冲量、权重衰减值作为待迁移参数。
19.进一步地,所述步骤(9)中目标域模型训练采用与源域完全相同的网络层深结构和模型训练参数,网络层深结构包括网络输入输出层、卷积层层深及对应的卷积核大小数量,池化层池化核和上采样层上采样核大小,卷积滑动步长、填充方式。训练参数包括学习率、冲量、权重衰减值。目标域模型参数的初始值使用步骤(5)中获取的源域模型最优参数;源域参数包括模型权重与偏置量参数。为了减少目标域模型的训练时间,仅调少训练的迭代次数。损失函数、激活函数、批次大小等其他模型训练参数与步骤(4)中源域模型训练完全相同。
20.进一步地,所述步骤(7)中图像色彩迁移处理,先将原始图像由rgb色彩空间变换
至ιαβ色彩空间,在ιαβ色彩空间中采用reinhard算法将源域色彩统计特征迁移至目标域图像,进而能保障目标域图像和源域图像具有相近的色彩统计特征。
21.进一步地,所述步骤(10)中目标域影像建筑物震害信息提取结果精度评价,对完整建筑物和损毁建筑物提取结果计算综合精确率和综合召回率,micro-f1由综合精确率和综合召回率综合计算得到。
22.本发明充分考虑了不同层深网络结构对震害信息提取性能和效率的影响和源域数据、目标域数据的色彩接近性,提出了色彩-参数迁移的遥感建筑物震害信息提取方法,采用层深增长网络结构优化方法,以深度卷积神经网络的最优的源域模型参数作为目标域模型训练的初始模型参数值,降低了深度学习的样本制作成本和模型训练时间,克服了深度学习方法需要较大成本的不足,使得不断积累的震害遥感影像从无用数据变成了数据宝地,为震后快速应急救援和灾后重建提供了有效的震害信息提取方法
附图说明
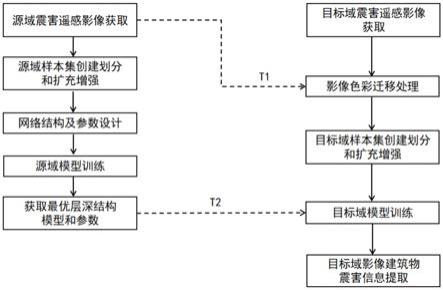
23.图1为本发明基于色彩-参数迁移的遥感建筑物震害信息提取方法的技术流程图
24.图2为本发明实施例采用的层深增长网络结构优化源域卷积网络模型示意图
25.图3为本发明实施例中采用的层深增长网络结构图
26.图4为本发明实施例层深增长卷积网络模型震害信息提取精度kappa系数指标变化
27.图5为本发明实施例层深增长卷积网络模型震害信息提取精度micro-f1指标变化
28.图6为本发明实施例层深增长卷积网络模型训练时间变化
29.图7为本发明实施例色彩统计特征迁移原理图
30.图8为本发明实施例模型层深结构与参数迁移原理图
31.图9为本发明方法提取结果空间误差分布与无迁移cnn方法的对比图
具体实施方式
32.为了更清楚地说明本发明的技术方案,下面结合具体实施例对本发明做详细说明,以下实施例有助于本领域的技术人员更好地理解本发明。应当指出的是,本领域内的其他技术人员在不脱离于本发明和实例的基础上演变而来的其他实例,都属于本发明的保护范围。
33.实施例:
34.图1所示一种基于色彩-参数迁移的遥感建筑物震害信息提取方法的技术流程图,图中t1为源域色彩统计特征,t2为源域最优模型和参数,具体步骤包括:
35.(1)源域震害遥感影像获取:本例中获取的是2010年4月14日青海玉树地震的谷歌地球遥感影像,作为迁移学习的源域数据。影像地面分辨率为1米,包含rgb(红绿蓝)三个波段,包括9幅1000行
×
1000列像元大小的影像。
36.(2)源域样本集创建划分和扩充增强:采用目视解译的方式,利用labelme图像标绘工具对源域影像中的“完整建筑物”和“损毁建筑物”分别进行标绘,生成对应的语义标签,源域深度学习样本集由9幅影像与对应的两类震害语义标签构成;将样本集按2:1的比例划分为训练集和测试集,训练集包括6幅影像,测试集包括3幅影像。利用opencv函数对样
本数据集进行扩充,采用随机裁剪的方式将样本图像及其对应标签裁剪为256*256像元大小,将源域样本数量扩充到30000张。分别采用opencv函数库中的旋转、镜像、伽马转换、模糊处理、添加噪声等5种函数对扩充后的源域样本集图像进行数据增强,形成虚拟样本,包括按照90
°
、180
°
和270
°
对样本图像进行旋转变换,通过在图像上随机散播像元值为0(黑点)和255(白点)的像元点随机添加椒盐噪声。将图像像元矩阵中每行像元值的排列顺序进行颠倒,生成镜像图像,通过“伽马转换”提升图像的暗部细节,通过“模糊处理”产生模糊效果。
37.(3)网络层深结构设计:设计提取震后完整建筑物、损毁建筑物的层深增长卷积神经网络结构。为了实现端到端提取,实施例以segnet全卷积神经网络结构为基础设计网络模型和结构参数,网络输入层(input)可输入256*256像元大小的rgb三波段震害样本集数据,设计层深增长网络结构优化震害信息提取精度和效率,在编码器(encoder)中进行卷积和最大池化操作,在解码器(decoder)中进行卷积和上采样操作,如图2所示,虚线框k中为层深增长结构调节变化部分。图3虚线框k中显示了层深增长网络结构的具体调节方式,通过调节编码器和解码器的层深结构,从编码器和解码器的第5层开始逐层增加对称的网络结构,包括逐层对称增加卷积层、池化层和上采样层。其中,m为编码器和解码器同时对称向层中间增长的网络层数,5≤m≤13。编码器卷积层表示为conv a
m-bm,卷积层中卷积核大小表示为am*am,卷积核个数设计为bm;解码器卷积层表示为dconv a
m-bm,卷积层中卷积核大小表示为am*am,卷积核个数设计为bm。maxpool2表示编码器池化层的池化核大小为2*2,upsample2表示解码器上采样层的上采样核大小为2*2。卷积填充方式采用same,滑动步长为1个像元。
38.网络输出层(output)为soft-max分类层,采用soft-max分类器提取两类震害语义信息,其公式如下:
[0039][0040]
式中,sk(i,j)为图像(i,j)处像元输出为第k类的概率值;k、l取值包括0、1、2,分别代表完整建筑物、损毁建筑物和背景地物;xk(i,j)表示第k类在(i,j)处像元的特征值。
[0041]
(4)源域模型训练:输入步骤(2)中创建的源域样本集,采用步骤(3)中设计的网络层深结构和参数,随机生成网络模型初始参数。模型训练参数包括初始学习率设置为0.01,冲量设置为0.9,权重衰减值为0.0005,迭代次数(epochs)设置为10,批次大小(batch size)设置为6。训练过程使用交叉熵函数计算损失函数,如下:
[0042][0043]
其中,l为损失函数,n为训练样本数目,yi为第i个像元的真实值,ai为预测值。采用用随机梯度下降法(sgd)调整网络的权重参数,通过反向传播使得损失函数l达到最小。使用relu函数作为激活函数:
[0044]
y=max(0,x)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0045]
y=f(x)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0046]
式中,x为输入信号,y为激活的输出信号,其中f(x)为输入信号x的激活函数。在
tensorflow框架下完成模型训练,保存训练好的模型与参数。
[0047]
(5)获取最优层深结构模型和参数:针对(2)中扩充的源域样本集,对模型的层深结构进行调整,分别训练不同层深下的网络模型。结合源域测试集比较不同层深模型对建筑物震害信息的提取精度和效率,并保存提取精度和模型训练时间最佳的网络层深结构和模型参数。其中,层深增长网络结构按照编码和解码的层深对称结构,从第5层开始逐层增加网络结构,按照步骤(3)中所述层深增长的网络结构逐层训练网络模型,本实施例中层深增长网络结构参数如下,当m=5时,a5=3,b5=256;m=6时,a6=3,b6=256;m=7时,a7=3,b7=256;m=8时,a8=3,b8=512;m=9时,a9=3,b9=512;m=10时,a
10
=3,b
10
=512;m=11时,a
11
=3,b
11
=512;m=12时,a
12
=3,b
13
=512;m=13时,a
13
=3,b
13
=512。分别训练10层、12层、14层、16层、18层、20层、22层、24层、26层9种层深网络,对应编码器、解码器各5层、6层、7层、8层、9层、10层、11层、12层、13层卷积对称式网络结构。由于网络结构中卷积层数目较少时,本例中层数少于10层,震害信息提取精度较低且训练出的模型容易过拟合。
[0048]
结合步骤(2)中源域测试集计算不同层深网络模型下的kappa系数、micro-f1精度和模型训练时间,如图4、图5、图6所示。当网络层深大于14层时,模型对建筑物震害信息的提取精度开始下降,模型训练时间增加。本例中获取的最优层深结构为14层网络模型,记录下模型参数,模型权重(图8中t21)与偏置量(t22),作为待迁移参数(如图1中t2)。
[0049]
同时记录该模型的训练参数,包括学习率(图8中的t23)、冲量(图8中的t24)、权重衰减值(图8中的t25)。
[0050]
(6)目标域震害遥感影像获取:本例中获取的是2008年5月12日四川汶川地震后中国科学院对地观测与数字地球科学中心的航空遥感影像图,作为迁移学习的目标域影像数据。数据地面分辨率为0.3米,包含rgb三个波段,包括8幅500行
×
500列像元大小的影像。
[0051]
(7)影像色彩迁移处理:利用步骤(1)中获取的玉树地震源域影像数据,结合reinhard色彩迁移算法提取源域影像的色彩统计特征(为图1中t1)对步骤(6)中获取的汶川地震目标域影像进行色彩迁移处理,使处理后的目标域影像与源域影像具有相近的色彩统计特征。
[0052]
具体包括:
[0053]
将源域和目标域影像由rgb色彩空间转换到ιαβ空间。
[0054]
首先将源域影像和目标域影像数据由rgb色彩空间转换到cie xyz色彩空间,再由cie xyz色彩空间转换到lms色彩空间,最后由lms色彩空间转换到ιαβ空间。rgb空间到lms空间转换的计算公式:
[0055][0056][0057]
式中,r、g、b分别表示rgb色彩空间中的红、绿、蓝三通道像元灰度值,x、y、z分别表示ciexyz色彩空间中的三色刺激值,l、m、s分别表示lms空间中三种人眼锥体在长波长、中
波长和短波长处的响应度(灵敏度)峰值。为保证转换后空间尺度的合理性,进行对数级的尺度变换,计算公式如(7)所示:
[0058][0059]
式中,l、m、s分别表示lms空间中人眼三种锥体在长波长、中波长和短波长处的响应度(灵敏度)峰值,l'、m'、s'分别表示l、m、s的对数值。
[0060]
从lms空间转换到ιαβ空间如式(8)所示:
[0061][0062]
式中,l'、m'、s'分别表示lms空间中对应通道l、m、s的对数值,ι表示ιαβ空间的亮度通道值,α、β分别表示ιαβ空间的颜色通道值。
[0063]
本例中reinhard色彩迁移算法利用源域玉树地区影像的标准差、均值信息来对目标域汶川地区的影像进行色彩校正,通过线性变换使目标域与源域影像的色彩统计量相一致,从而使目标域影像在视觉上达到与源域影像相近的色彩特征,其像元关系表达如式(9)所示:
[0064][0065]
式中l、a、b分别表示目标域结果影像对应通道的空间像元值,ι、α、β分别表示目标域影像对应通道的空间像元值,m
ι
、m
α
、m
β
和m
ι'
、m
α'
、m
β'
分别表示目标域影像和源域影像对应通道的均值,n
ι
、n
α
、n
β
和n
ι'
、n
α'
、n
β'
分别表示目标域影像和源域影像对应通道的标准方差。
[0066]
(8)目标域样本集创建划分和扩充增强:采用目视解译的方式,利用labelme图像标绘工具对目标域影像中的“完整建筑物”和“损毁建筑物”分别进行标绘,生成对应的语义标签,目标域深度学习样本集由8幅影像与对应的两类震害语义标签构成;将样本集按5:3的比例划分为训练集和测试集,训练集包括5幅影像,测试集包括3幅影像。利用opencv函数采用随机方式将样本图像及其对应标签随机裁剪为3000张256*256像元大小的样本,对样本集进行扩充。分别采用opencv函数库中的旋转、镜像、伽马转换、模糊处理、添加噪声等5种函数对扩充后的目标域样本集图像进行数据增强,形成虚拟样本,包括按照90
°
、180
°
和270
°
对样本图像进行旋转变换,通过在图像上随机散播像元值为0(黑点)和255(白点)的像元点随机添加椒盐噪声。将图像像元矩阵中每行像元值的排列顺序进行颠倒,生成镜像图像,通过“伽马转换”提升图像的暗部细节,通过“模糊处理”产生模糊效果。
[0067]
(9)目标域模型训练:
[0068]
结合目标域样本集训练震害信息提取模型,训练步骤为:
[0069]
a)输入目标域样本数据,采用与源域完全相同的网络层深结构(图8中源域同构网络)和模型训练参数,网络层深结构包括网络输入输出层、卷积层层深及对应的卷积核大小
数量,池化层池化核和上采样层上采样核大小,卷积滑动步长、填充方式。训练参数包括学习率(图8中的t23)、冲量(图8中的t24)、权重衰减值(图8中的t25)。目标域模型参数的初始值使用步骤(5)中获取图1中源域模型最优参数(t2);t2包括图8中的模型权重(t21)与偏置量(t22)参数。
[0070]
b)在编码器中进行卷积和最大池化,然后在解码器中进行卷积和上采样操作,最后将特征图送到soft-max分类器进行震害信息识别;
[0071]
c)通过迭代更新网络参数,保存最终训练好的模型参数,并输出训练精度损失曲线图。
[0072]
为了减少目标域模型的训练时间,与源域相比本实施例目标域训练迭代次数(epochs)减少5次,设置为5,损失函数、激活函数、批次大小等其他模型训练参数与步骤(4)中源域模型训练完全相同。
[0073]
(10)目标域影像建筑物震害信息提取与精度评价:利用步骤(9)中训练好的模型进行步骤(8)中目标域测试集影像建筑物震害信息的提取,结合目标域测试集标签数据评价目标域模型对建筑物震害信息提取的精度和效率,选用kappa系数和micro-f1评分作为精度评价指标。为了获得micro-f1精度,对完整建筑物和损毁建筑物提取结果计算综合精确率p
micro
(式10)和综合召回率r
micro
(式11),由综合精确率p
micro
和综合召回率r
micro
计算得到micro-f1(式12)。
[0074][0075][0076][0077]
其中,p
micro
为两类震害建筑物的综合精确率,r
micro
为两类震害建筑物的综合召回率,tp1为完整建筑物真阳性检验的像元数,fp1为完整建筑物假阳性的像元数,fn1为完整建筑物假阴性的像元数;tp2为损毁建筑物真阳性的像元数,fp2为损毁建筑物假阳性的像元数,fn2为损毁建筑物假阴性的像元数。
[0078]
图9为本发明方法提取结果空间误差分布与无迁移cnn方法的对比图,其中a、b、c为目标域测试影像,d、e、f为无迁移cnn方法提取结果空间误差分布,g、h、i为本发明方法提取结果空间误差分布。s1为完整建筑物正确分类吗,s2为其错误分类,s3为其遗漏分类;s4为损毁建筑物正确分类,s5为损毁建筑物错误分类,s6为损毁建筑物遗漏分类,空间误差分布对比显示本发明方法建筑物震害信息提取结果中错分和漏分像元减少显著,提取精度增加。
[0079]
本发明提取结果精度显示kappa系数及micro-f1评分平均达到了69.56%和74.14%,相对无迁移卷积神经网络(无迁移cnn)提高了33.17%和32.29%,对比随机森林法(rf)提高了42.73%和31.79%,比支持向量机(svm)提高了34.83%和24.08%,如表1所示。在耗时与样本量制作方面,无迁移cnn模型(30000样本)训练耗时219分钟,本发明方法(3000样本)训练耗时11分钟,模型分类精度接近的情况下,本发明方法的目标域模型训练
耗时更少,样本量更小。
[0080]
表1本发明与rf、svm、无迁移cnn方法震害信息提取精度比较
[0081][0082]
以上所述是本发明的具体实施例及所运用的技术原理,若以本发明的构想所作的改变,其所产生的功能作用仍未超出说明书及附图所涵盖的内容时,仍应属本发明的保护范围。。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1