分布式存储系统内的数据迁移方法及分布式存储系统
1.本说明书一个或多个实施例涉及分布式存储技术领域,尤其涉及一种分布式存储系统内的数据迁移方法及分布式存储系统。
背景技术:
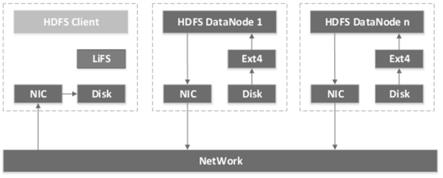
2.客户端使用的传统的本地文件系统拥有很强大的功能和复杂的索引逻辑,如ext4。参见图1,现有技术中在分布式存储系统hdfs集群的客户端和数据节点之间进行数据传输时,例如,数据从数据节点的磁盘导入到客户端磁盘的过程中,需要数据节点的本地文件系统ext4将其磁盘disk上的数据通过网卡nic、网络、客户端的网卡nic后,进入客户端,进而利用客户端的本地文件系统存储到磁盘中。
3.但是在分布式存储系统之间进行数据迁移的过程中仅用到文件系统中的一部分功能,例如,读取、写入等简单操作,这就使得本地文件系统会产生一些不必要的索引开销对数据的读写性能产生影响。
技术实现要素:
4.本说明书一个或多个实施例描述了一种分布式存储系统内的数据迁移方法及分布式存储系统。
5.根据第一方面,提供了一种分布式存储系统内的数据迁移方法,分布式存储系统包括客户端、元数据节点和多个数据节点,所述客户端上安装有第一文件系统;所述方法包括:迁移方向为从所述数据节点到所述客户端的第一数据迁移过程;其中,所述第一数据迁移过程包括:
6.所述客户端向所述元数据节点发送请求以获取第一元数据信息,所述第一元数据信息包括待迁移文件的标识、组成所述待迁移文件的各个数据块文件的标识所形成的第一列表以及各个数据块文件当前所在的数据节点的标识;
7.所述客户端根据接收到的所述第一元数据信息对所述第一文件系统中的数据相关信息进行更新,并根据更新后的数据相关信息计算出所述第一列表中各个数据块文件在所述客户端对应的写入位置信息;
8.所述客户端将所述第一列表中的每一个数据块文件的标识和对应的写入位置信息发送给该数据块文件当前所在的数据节点,以使所述数据节点根据所述写入位置信息将该数据块文件写入到所述客户端磁盘的对应位置中,并在写入完成后向所述客户端返回写入完成的消息。
9.根据第二方面,提供了一种分布式存储系统,包括客户端、元数据节点和多个数据节点,所述客户端上安装有第一文件系统;所述客户端用于执行:迁移方向为从所述数据节点到所述客户端的第一数据迁移过程;
10.其中,所述客户端具体包括:
11.第一信息获取模块,用于向所述元数据节点发送请求以获取第一元数据信息,所
述第一元数据信息包括待迁移文件的标识、组成所述待迁移文件的各个数据块文件的标识所形成的第一列表以及各个数据块文件当前所在的数据节点的标识;
12.第一位置计算模块,用于根据接收到的所述第一元数据信息对所述第一文件系统中的数据相关信息进行更新,并根据更新后的数据相关信息计算出所述第一列表中各个数据块文件在所述客户端对应的写入位置信息;
13.第一信息发送模块,用于将所述第一列表中的每一个数据块文件的标识和对应的写入位置信息发送给该数据块文件当前所在的数据节点,以使所述数据节点根据所述写入位置信息将该数据块文件写入到所述客户端磁盘的对应位置中,并在写入完成后向所述客户端返回写入完成的消息。
14.本发明实施例提供的分布式存储系统内的数据迁移方法及分布式存储系统,客户端向元数据节点发送请求,这样元数据节点在接收到该请求时会返回客户端第一元数据信息,而第一元数据信息中包含待迁移文件的标识、组成待迁移文件所需的各个数据块文件的标识以及各个数据块文件目前所在的数据节点的标识,这样客户端就会得知需要对哪个或哪些文件进行迁移,而文件中包含哪些数据块文件,以及这些数据块文件目前存储在哪个数据节点上。客户端根据第一元数据信息对第一文件系统进行信息更新,而第一文件系统中存储的是客户端磁盘上的数据块文件的相关信息,对这些相关信息进行更新后,得到的是完成写入操作之后的相关信息。即先对相关信息进行更新,然后再进行数据块的写入。在进行信息更新之后,可以计算出每一个数据块文件应该被写入的位置,即一个数据块文件应该被写入在客户端磁盘上的位置的起始偏移量,将起始偏移量作为写入位置信息。根据每一个数据块文件当前所在的数据节点的标识,客户端将该数据块文件对应的写入位置信息和写入请求发送至该数据节点,该数据节点在接收到写入请求后,会根据写入位置信息将自身节点中存储的该数据块文件写入到客户端磁盘上的对应位置,该数据节点在写入完成后,会告知客户端已经写入完成的消息。由于该过程可以实现多个数据节点同时进行数据写入操作,而且在写入过程中不需要再经过第一文件系统,而是直接写入到客户端的磁盘上,因此可以大大减少不必要的开销,提高数据迁移的速度,实现高效数据迁移。
附图说明
15.为了更清楚地说明本说明书实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本说明书的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
16.图1是现有技术中在分布式存储系统hdfs集群的客户端和数据节点之间进行数据传输时的流程示意图;
17.图2是本发明实施例中数据迁移方法对应的系统架构图;
18.图3是本发明实施例中将数据从hdfs集群的数据节点导出至客户端的大致流程图;
19.图4是本发明实施例中将数据从hdfs集群的数据节点导出至客户端的具体流程图;
20.图5是本发明实施例中将数据从客户端磁盘导入数据节点的大致流程图;
21.图6是本发明实施例中将数据从客户端磁盘导入数据节点的具体流程图;
22.图7是本发明实施例中第一文件系统所管理的信息的布局示意图。
具体实施方式
23.下面结合附图,对本说明书提供的方案进行描述。
24.第一方面,本发明实施例提供一种分布式存储系统内的数据迁移方法,分布式存储系统包括客户端、元数据节点和多个数据节点,所述客户端上安装有第一文件系统;所述方法包括:迁移方向为从所述数据节点到所述客户端的第一数据迁移过程;
25.其中,所述第一数据迁移过程包括:
26.s1、所述客户端向所述元数据节点发送请求以获取第一元数据信息,所述第一元数据信息包括待迁移文件的标识、组成所述待迁移文件的各个数据块文件的标识所形成的第一列表以及各个数据块文件当前所在的数据节点的标识;
27.s2、所述客户端根据接收到的所述第一元数据信息对所述第一文件系统中的数据相关信息进行更新,并根据更新后的数据相关信息计算出所述第一列表中各个数据块文件在所述客户端对应的写入位置信息;
28.s3、所述客户端将所述第一列表中的每一个数据块文件的标识和对应的写入位置信息发送给该数据块文件当前所在的数据节点,以使所述数据节点根据所述写入位置信息将该数据块文件写入到所述客户端磁盘的对应位置中,并在写入完成后向所述客户端返回写入完成的消息。
29.也就是说,客户端向元数据节点发送请求,这样元数据节点在接收到该请求时会返回客户端第一元数据信息,而第一元数据信息中包含待迁移文件的标识、组成待迁移文件所需的各个数据块文件的标识以及各个数据块文件目前所在的数据节点的标识,这样客户端就会得知需要对哪个或哪些文件进行迁移,而文件中包含哪些数据块文件,以及这些数据块文件目前存储在哪个数据节点上。客户端根据第一元数据信息对第一文件系统进行信息更新,而第一文件系统中存储的是客户端磁盘上的数据块文件的相关信息,对这些相关信息进行更新后,得到的是完成写入操作之后的相关信息。即先对相关信息进行更新,然后再进行数据块的写入。在进行信息更新之后,可以计算出每一个数据块文件应该被写入的位置,即一个数据块文件应该被写入在客户端磁盘上的位置的起始偏移量,将起始偏移量作为写入位置信息。根据每一个数据块文件当前所在的数据节点的标识,客户端将该数据块文件对应的写入位置信息和写入请求发送至该数据节点,该数据节点在接收到写入请求后,会根据写入位置信息将自身节点中存储的该数据块文件写入到客户端磁盘上的对应位置,该数据节点在写入完成后,会告知客户端已经写入完成的消息。由于该过程可以实现多个数据节点同时进行数据写入操作,而且在写入过程中不需要经过第一文件系统,而是直接写入到客户端的磁盘上,因此可以大大提高数据迁移的速度,实现高效数据迁移。
30.参见图2,本发明实施例中,客户端上安装有第一文件系统lifs,数据节点上安装有第二文件系统ext4,图2示出的是数据从datanode到客户端的过程。在向客户端的磁盘写入数据块文件时,客户端会从元数据节点中获取到第一元数据信息,然后计算出每一个数据块文件的写入地址信息,将写入地址信息发送给对应的数据节点,这样数据节点就会通过本地的第二文件系统将其磁盘中的数据块文件通过网络写入到客户端磁盘中,写入过程
不需要经过客户端的第一文件系统。
31.参见图3,为本发明实施例中的数据从hdfs集群的数据节点导出至客户端的大致流程图,hdfs集群底层使用支持nvme over fabric技术的存储介质,客户端上安装有第一文件系统lifs。第一文件系统会计算出各个数据块文件应该被写入到客户端磁盘中的位置的起始偏移量。客户端和datanode进行通信时,将数据块文件对应的写入位置信息发送给对应的datanode,datanode会使用nvme over fabric技术将数据块文件直接写入客户端中的存储介质中,即客户端磁盘中。
32.如图4所示,为本发明实施例中将数据从hdfs集群的数据节点导出至客户端的具体流程图。具体的顺序如下:
33.(1)客户端与namenode进行通信,发送需要获取数据的请求。namenode对客户端发来的请求进行分析,返回客户端需要的第一元数据信息;
34.(2)客户端本地的第一文件系统lifs根据接收到的第一元数据信息后,对第一文件系统中的数据相关信息(例如,block info、bitmap、file info,具体见下文)进行更新,并计算出组成待迁移文件的每一个数据块的写入位置信息;
35.(3)客户端将数据块文件的标识及其写入位置信息发送至存储该数据块文件的datanode;
36.(4)datanode收到客户端发送的数据块文件的标识和写入位置信息后,使用nvme over fabric技术将本地存储的该标识对应的数据块文件写入到客户端磁盘中的对应位置上,每个datanode写完数据之后都需要向客户端发送数据已写完的确认信息。直到客户端接收到所有的数据节点返回的数据已写完的确认信息后,数据导出工作完成。
37.在具体实施时,本发明实施例提供的方法还可以包括:迁移方向为所述客户端到所述数据节点的第二数据迁移过程。
38.其中,所述第二数据迁移过程包括:
39.s4、所述客户端计算待迁移文件中各个数据块文件的读取位置信息,将所述待迁移文件对应的第二元数据信息发送至所述元数据节点,所述第二元数据信息包括待迁移文件的标识以及组成待迁移文件的各个数据块文件的标识;
40.s5、所述元数据节点根据所述第二元数据信息对所述元数据节点中元数据进行更新,根据更新后的元数据生成第二列表,并将所述第二列表发送至所述客户端;所述第二列表包括针对所述待迁移文件为各个数据节点分配的各个数据块文件的标识;
41.s6、所述客户端在接收到所述第二列表后,将每一个数据块对应的读取位置信息发送至对应的数据节点,以使所述数据节点根据所述读取位置信息将该数据块文件读取至自身节点中,并在读取完成后向所述客户端返回读取完成的消息。
42.也就是说,在第二数据迁移过程中,数据块文件是存储在客户端磁盘上的,因此客户端的第一文件系统中存储有这些数据块文件的相关信息,利用这些相关信息可以计算出待迁移文件中每一个数据块的位置,即每一个数据块在客户端磁盘中位置的起始偏移量,将该起始偏移量作为读取位置信息。然后客户端将待迁移文件的标识以及组成该待迁移文件中的各个数据块文件的标识发送给元数据节点。元数据节点在接收到这些信息后,会对元数据节点中的元数据进行更新。在更新前,元数据节点中的元数据为每一个数据节点中目前已经存储的各个数据块文件的标识,也就是说每一个数据节点中目前存储有哪些数据
块文件。在更新后,元数据节点中的元数据为每一个数据节点在读取操作后应该存储的各个数据块文件的标识,即在读取操作后每一个数据节点应该会存储有哪些数据块文件。元数据节点在进行信息更新后,便可以生成第二列表,第二列表中包含组成待迁移文件中的各个数据块文件对应的数据节点的标识,也就是说,根据第二列表可以得知,待迁移文件中的每一个数据块文件应该被存储到哪一个数据节点上。当客户端接收到元数据节点发送来的第二列表后,将每一个数据块文件对应的读取位置信息发送给对应的数据节点,这样该数据节点就会根据读取位置信息从客户端磁盘上进行数据块文件的读取,在读取之后存储在自身节点中。
43.如图5所示,为本发明实施例中将数据从客户端磁盘导入数据节点磁盘的大致流程图。客户端本地的第一文件系统lifs中存放着每个数据块文件的信息,例如、数据块文件的大小、数据块文件的个数以及具体的标识id等信息,客户端在与namenode进行通信时将待迁移文件中的各个数据块文件的相关信息发送给namenode,namenode获取信息后更新自身节点上的元数据,然后根据更新后的元数据生成第二列表发送给客户端,客户端通过本地的第一文件系统lifs计算每一个数据块文件在磁盘中的起始偏移量作为读取位置信息。客户端与对应的datanode通信,将需要获取的每个数据块文件对应的读取位置信息发送给datanode,datanode使用nvme over fabric技术直接从client的磁盘中获取数据块文件。
44.如图6所示,为本发明实施例中将数据从客户端磁盘中导入数据节点中的具体流程图,具体过程如下:
45.(1)客户端从本地的第一文件系统lifs获取相关信息,进而根据这些信息计算出每一个数据块文件的起始偏移量作为读取位置信息;
46.(2)客户端与namenode建立通信,将待迁移文件中各个数据块文件的相关信息发送给namenode;
47.(3)namenode接收到客户端发来的数据后,对自身节点上的元数据metadata进行更新,并返回第二列表给客户端;
48.(4)客户端在接收到第二列表后,将数据块文件的标识和对应的读取位置信息发送给对应的datanodes;
49.(5)datanodes使用nvme over fabric技术直接从客户端磁盘中相应的位置上读取数据块文件,并存储到自身节点的存储介质中。
50.(6)每个datanode读取完数据块文件后,向客户端发送确认导入完成信息,直至所有datanode都发送完确认信息,数据导入完成。
51.下面对客户端上的第一文件系统进行介绍:
52.所述第一文件系统用于管理所述数据相关部分,数据相关部分用于存储所述数据相关信息;所述数据相关部分包括超级块、数据块信息、位图和文件信息;其中:所述超级块中用于存储客户端的磁盘信息,所述磁盘信息中包括磁盘的大小、存储的数据块文件的总数量和第一个数据块文件的偏移地址;所述位图中用于存储客户端的磁盘的可用空间信息和已用空间信息;所述数据块信息中用于存储每一个数据块的标识、长度、创建时间和更新时间;所述文件信息中用于存储文件和数据块文件之间的对应关系。
53.也就是说,第一文件系统可以用于对一些相关信息进行管理,例如,对客户端的磁盘信息、磁盘的可用空间信息和已用空间信息、对各个数据块的信息、文件和数据块之间的
关系等进行管理。
54.除此之外,本发明实施例中第一文件系统还可以用于管理数据部分,所述数据部分包含多个块,每一个块用于存储一个数据块文件,每一个数据块文件包含元数据和数据。
55.也就是说,第一文件系统还可以存储多个数据块文件,而每一个数据块文件中包括元数据和数据本身。
56.如图7所示,本发明实施例中第一文件系统所管理的数据相关信息和数据信息的示意图。第一文件系统lifs可以更加高效的存储和读写数据节点中的数据块文件。而数据块文件中包含两部分:一种是数据本身,其命名blk加数字的形式,另一种是元数据,具体为数据块长度、校验和以及时间戳等信息,其命名特点是有mate后缀。数据块文件存储在数据部分,而数据相关信息存储在数据相关部分,数据相关部分分为四部分:超级块(即super block,缩写为sb)、位图(即bitmap)、数据块信息(即block info,缩写为bi)、文件信息(即file info)。其中:
57.超级块(即super block)中存放了客户端磁盘的基本信息,包括磁盘大小、数据块文件的大小、块的总数量、第一个数据块文件的偏移地址等信息。
58.位图(即bitmap)是用来记录磁盘中可用空间和已用空间的信息,通过位图可以获得的两个列表,一个列表中存放的是磁盘中已被占用的数据块文件的信息,另一个列表中存放的是磁盘中可用的数据块文件的信息,列表中的数据块data_block_id是数据块文件在磁盘中的编号。
59.数据块信息(即block info)中存储着每个数据块文件的标识(即block_id)、磁盘中存储的数据块文件的长度,数据块文件的创建时间和更新时间等信息,在每次写入新的数据块文件或者修改数据块文件时block info中的信息也会被修改。图7中的csm是指元数据。
60.文件信息(即file info)中记录着文件和数据块文件的对应关系,通常一个文件对应许多个数据块文件。
61.数据部分包含多个块,每一个块中存放一个数据块文件,而一个数据块文件中包含数据本身和后缀有meta的元数据,由于数据本身和元数据的后缀是不同的,可以通过后缀区分出是数据本身还是元数据。
62.在具体实施时,为了在第一文件系统中更加便捷、简单的获取相关信息,可以设置一个结构体。具体的,在第一文件系统lifs挂载之后,会在内存中建立一个file结构体,即下文中的预设结构体。file结构体用来记录已经写入到客户端磁盘中的数据块文件的信息,例如,数据块文件的名称、标识、在客户端磁盘中的起始偏移量、长度等信息,减少第一文件系统在读写时候对磁盘的操作次数,可以提高索引效率。
63.也就是说,在本发明实施例中所述第一文件系统可以用于载挂载之后在内存中建立一个预设结构体,所述预设结构体用于存储写入所述客户端的磁盘的各个数据块文件的信息,所述信息包括每一个数据块文件的名称、标识、在客户端磁盘上的起始偏移量以及长度。
64.在建立预设结构体的基础上,s4中所述客户端计算待迁移文件中各个数据块文件的读取位置信息,可以包括:所述客户端从所述预设结构体中获取每一个数据块文件的起始偏移量,将所述起始偏移量作为该数据块文件对应的读取位置信息。
65.也就是说,如果建立了预设结构体,就不必在第一文件系统中获取相关的信息来计算读取位置信息,而是可以从预设结构体中直接获取数据块文件的起始偏移量,将起始偏移量作为读取位置信息即可,这样可以减少对磁盘的操作次数,提高效率。
66.可理解的是,本发明实施例提供的方法应用在分布式存储系统的内部进行数据迁移的场景中。分布式存储系统具有高性能、高可用性和高可扩展等特性,已成为大数据时代主流的底层存储系统。可以将实际产生的大量数据导入到分布式存储系统中,例如,大型科学仪器(例如,风洞实验)或车载系统产生的海量数据需要一次性导入分布式存储系统。风洞实验一次产生的数据量可达tb级,车载系统累计的数据也在数百gb。也可以将分布式存储系统中的数据导出至系统外部,例如,互联网企业通过爬虫、日志分析等方法累积的数据,数据产生速度较慢,但积累的数据量大。这些数据需要导出至其他系统用于备份或分析时速度很慢。即使现在网速已提高很多,城市间的数据传输仍需耗费较长时间。以4tb数据为例,传输速率达到5mb/s时,仍需要将近10天才能传输完成。
67.本发明实施例提供的数据迁移方法适用于分布式存储系统内部的高速数据导入和导出方法,是一种新的数据传输机制,数据节点在读取或写入客户端磁盘中的数据时,例如,写入操作,客户端在获取元数据信息后,根据第一文件系统中的数据布局方式,通知各个数据节点直接将自身节点中的数据块文件写入到客户端磁盘中,在写入过程中不必再经过第一文件系统,可以大大提高数据迁移的效率。
68.其中,第一文件系统在本发明实施例中的命名为lifs(即li filesystem),lifs的存储逻辑是专门为了存储分布式存储系统的数据块文件所设计,其通过用户空间文件系统fuse(即filesystem in userspace)提供的接口来实现所需要的功能。与ext4相比,第一文件系统没有冗余的功能和索引逻辑,只针对分布式存储系统中数据块文件的高效存储和读取。第一文件系统是一个只用于存储数据块文件的文件系统,其不能存储数据块文件以外的文件或者目录。在对客户端磁盘进行格式化时根据lifs设计的索引关系,对磁盘进行逻辑分区并将磁盘信息存储在超级块中。
69.可理解是,fuse在读取或写入文件时,可以将数据块文件切分成小块进行操作的。客户端在写入或读取数据块文件时会先判断该文件是否已经存在,如写入的时候已经存在可以追加写,读取的时候已经存在就直接读取数据。
70.本发明实施例在数据迁移的过程中,使用数据节点直接写入客户端磁盘的方法(如使用nvme over fabric技术)减少不必要的开销,具体应用于数据在客户端的磁盘和数据节点间的传输。数据在客户端和datanode间进行传输的时候,datanode可以使用nvme over fabric技术直接将数据写入磁盘中的相应位置,或者将数据从磁盘的相应位置读取出来,来实现数据的导入和导出。其中,数据在磁盘的位置可以由上述的第一文件系统lifs根据数据块的信息计算得出。
71.第二方面,本发明实施例提供一种分布式存储系统,该系统包括客户端、元数据节点和多个数据节点,所述客户端上安装有第一文件系统;所述客户端用于执行:迁移方向为从所述数据节点到所述客户端的第一数据迁移过程;
72.其中,所述客户端具体包括:
73.第一信息获取模块,用于向所述元数据节点发送请求以获取第一元数据信息,所述第一元数据信息包括待迁移文件的标识、组成所述待迁移文件的各个数据块文件的标识
所形成的第一列表以及各个数据块文件当前所在的数据节点的标识;
74.第一位置计算模块,用于根据接收到的所述第一元数据信息对所述第一文件系统中的数据相关信息进行更新,并根据更新后的数据相关信息计算出所述第一列表中各个数据块文件在所述客户端对应的写入位置信息;
75.第一信息发送模块,用于将所述第一列表中的每一个数据块文件的标识和对应的写入位置信息发送给该数据块文件当前所在的数据节点,以使所述数据节点根据所述写入位置信息将该数据块文件写入到所述客户端磁盘的对应位置中,并在写入完成后向所述客户端返回写入完成的消息。
76.在一些实施例中,所述客户端还用于执行:迁移方向为所述客户端到所述数据节点的第二数据迁移过程;其中,所述客户端还具体包括:
77.第二位置计算模块,用于计算待迁移文件中各个数据块文件的读取位置信息,将所述待迁移文件对应的第二元数据信息发送至所述元数据节点,以使所述元数据节点根据所述第二元数据信息对所述元数据节点中元数据进行更新,根据更新后的元数据生成第二列表,并将所述第二列表发送至所述客户端;所述第二元数据信息包括待迁移文件的标识以及组成待迁移文件的各个数据块文件的标识;所述第二列表包括针对所述待迁移文件为各个数据节点分配的各个数据块文件的标识;
78.第二信息发送模块,用于在接收到所述第二列表后,将每一个数据块对应的读取位置信息发送至对应的数据节点,以使所述数据节点根据所述读取位置信息将该数据块文件读取至自身节点中,并在读取完成后向所述客户端返回读取完成的消息。
79.在一些实施例中,所述第一文件系统用于管理所述数据相关部分,数据相关部分用于存储所述数据相关信息;所述数据相关部分包括超级块、数据块信息、位图和文件信息;其中:所述超级块中用于存储客户端的磁盘信息,所述磁盘信息中包括磁盘的大小、存储的数据块文件的总数量和第一个数据块文件的偏移地址;所述位图中用于存储客户端的磁盘的可用空间信息和已用空间信息;所述数据块信息中用于存储每一个数据块的标识、长度、创建时间和更新时间;所述文件信息中用于存储文件和数据块文件之间的对应关系。
80.在一些实施例中,所述第一文件系统还用于管理数据部分,所述数据部分包含多个块,每一个块用于存储一个数据块文件,每一个数据块文件包含元数据和数据。
81.可理解的是,本发明实施例提供的分布式存储系统和上述迁移方法是相对应的,第二方面提供的分布式存储系统中的有关内容的解释、举例、有益效果等内容可以参考第一方面中的相关内容,此处不再赘述。
82.本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于装置实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
83.本领域技术人员应该可以意识到,在上述一个或至少一个示例中,本发明所描述的功能可以用硬件、软件、挂件或它们的任意组合来实现。当使用软件实现时,可以将这些功能存储在计算机可读介质中或者作为计算机可读介质上的一个或至少一个指令或代码进行传输。
84.以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步
详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的技术方案的基础之上,所做的任何修改、等同替换、改进等,均应包括在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1