一种基于逆向强化学习的智能空战奖励函数生成方法与流程
1.本发明涉及一种基于逆向强化学习的智能空战奖励函数生成方法。
背景技术:
2.强化学习在空战中的应用目前已经被某些国家的研究机构探索,典型的包括美国deepmind公司,洛克希德-马丁公司等。根据已公开的材料,这些强化学习算法均使用了人工设计的奖励函数。在实际的空对空或类似的对抗中,任务的目标各异,难以人工设计出合理的奖励函数。
3.现有的基于强化学习的空战算法均采用了人工设计的奖励函数。人工设计的奖励函数主要考虑如下因素:
4.1.对方武器的损失数量,损失程度;
5.2.己方武器的损失数量,损失程度;
6.奖励函数综合考虑对方和己方的损失,通常采用线性加权平均的方式作为最终的奖励函数值。
7.这类奖励函数存在如下问题:
8.1.函数难以确定,包括损失函数的各项,以及各项的权重值;
9.2.不具有通用性,对于每个任务都要重新设计奖励函数;
10.3.不合适的奖励函数将导致强化学习不收敛,或者收敛到一个不好的策略。
技术实现要素:
11.本发明的目的在于提供了一种基于逆向强化学习的智能空战奖励函数生成方法,从而解决人工设计的奖励函数存在的各种弊端。
12.为了解决上述技术问题,本发明提供一种基于逆向强化学习的智能空战奖励函数生成方法,该方法包括如下步骤:
13.s1:神经网络的设计:采用有2个隐含层的全连接神经网络结构,用从传感器获取的环境数据提取特征,状态空间设计如下:
14.1)自身战机通道以经纬度表示自身位置的坐标,当前位置标记为1,其余位置标记为0;
15.2)我方其他战机通道以经纬度表示我方其他战机位置的坐标,当前位置标记为1,其余位置标记为0;
16.3)敌方战机通道以经纬度表示敌方战机位置的坐标,当前位置标记为1,其余位置标记为0;
17.4)未探索区域通道将未探索区域标记为1,已探索区域标记为0;
18.5)已探索区域通道将已探索区域标记未1,未探索区域标记为0;
19.s2:奖励函数的生成:学习奖励函数的目标是使得专家决策序列的奖励函数值优于强化学习算法生成的所有决策序列的奖励函数值,即:
[0020][0021]
其中r是要学习得到的奖励函数,τ1,...,τn是强化学习算法生成的决策序列,是专家生成的决策序列;实现时,采用最大熵模型;优化的目标为
[0022][0023]
即,使得专家的决策序列的对数概率值最大化;
[0024]
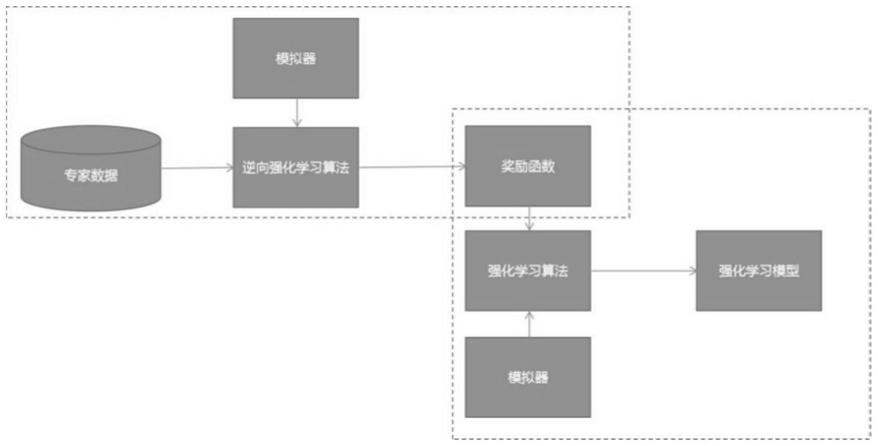
s3:使用强化学习算法根据该奖励函数搜索出最优策略:
[0025]
①
收集专家决策序列,由专家与模拟器对抗生成;
[0026]
②
使用逆向强化学习算法,确定奖励函数;
[0027]
③
使用强化学习算法,与模拟器交互,随机执行动作,生成决策序列,最大化奖励函数,从而得到强化学习模型。
[0028]
进一步,s1中的所述传感器为雷达。
[0029]
进一步,s1中输入层的神经元数量与状态数相同;第1个隐含层有256个神经元,第2个隐含层有128个神经元;输出层神经元数量与动作空间的动作数量相同。
[0030]
本发明采用模仿学习训练空对空对抗算法,采用逆向强化学习算法确定奖励函数;能够确保算法设计出一个合理的奖励函数,保证强化学习算法的收敛与模型的效果;此外,该方法具有通用性,针对不同任务都可以自动设计出一个奖励函数,无需人工设计。
附图说明
[0031]
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单的介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0032]
图1为本发明中使用强化学习算法根据该奖励函数搜索出最优策略的流程图。
具体实施方式
[0033]
以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
[0034]
本发明方案的具体实现和技术细节如下:
[0035]
步骤一:神经网络的设计:采用有2个隐含层的全连接神经网络结构,用从雷达等传感器获取的环境数据提取特征,状态空间设计如下:
[0036]
1)自身战机通道以经纬度表示自身位置的坐标,当前位置标记为1,其余位置标记为0;
[0037]
2)我方其他战机通道以经纬度表示我方其他战机位置的坐标,当前位置标记为1,其余位置标记为0;
[0038]
3)敌方战机通道以经纬度表示敌方战机位置的坐标,当前位置标记为1,其余位置标记为0;
[0039]
4)未探索区域通道将未探索区域标记为1,已探索区域标记为0(战机所在坐标(我方+已发现的敌方)默认为已探索区域);
[0040]
5)已探索区域通道将已探索区域标记未1,未探索区域标记为0;
[0041]
输入层的神经元数量与状态数相同;第1个隐含层有256个神经元,第2个隐含层有128个神经元;输出层神经元数量与动作空间的动作数量相同。
[0042]
步骤二:奖励函数的生成:学习奖励函数的目标是使得专家决策序列的奖励函数值优于强化学习算法生成的所有决策序列的奖励函数值,即:
[0043][0044]
其中r是要学习得到的奖励函数,τ1,...,τn是强化学习算法生成的决策序列,是专家生成的决策序列;实现时,采用最大熵模型;优化的目标为
[0045][0046]
即,使得专家的决策序列的对数概率值最大化。
[0047]
步骤三:结合图1所述,使用强化学习算法根据该奖励函数搜索出最优策略:逆向强化学习首先根据样本数据学习一个奖励函数,然后用这个奖励函数学习得到最优策略;具体算法如下:
[0048]
①
收集专家决策序列,由专家与模拟器对抗生成;
[0049]
②
使用逆向强化学习算法,确定奖励函数;
[0050]
③
使用强化学习算法,与模拟器交互,随机执行动作,生成决策序列,最大化奖励函数,从而得到强化学习模型。
[0051]
本发明能够确保算法设计出一个合理的奖励函数,保证强化学习算法的收敛与模型的效果。该方法具有通用性,针对不同任务都可以自动设计出一个奖励函数,无需人工设计。
[0052]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1