一种基于时间增强的图神经网络会话推荐方法
1.本发明涉及互联网大数据技术领域,具体涉及一种基于时间增强的图神经网络会话推荐方法。
背景技术:
2.基于会话的推荐是一种针对匿名用户或未登录用户的推荐模式,其在如今的各大电商平台(淘宝、京东等)或流媒体平台(抖音,youtobe等)发挥着重要作用。实际场景中,某些时候只能获取到用户的短期历史交互,比如:新用户或未登录用户。此时,依赖于用户长期历史交互的推荐算法在会话推荐中的表现会收到限制,例如基于协同过滤或马尔可夫链的方法。因此,基于会话的推荐成为一个研究热点,其目标是根据用户在会话中的行为序列来推荐用户感兴趣的下一个项目(或商品)。
3.针对现有会话推荐方法的项目推荐准确性不高的问题,公开号为cn112035746a的中国专利公开了《一种基于时空序列图卷积网络的会话推荐方法》,其包括:将所有会话序列建模为有向会话图;以会话中共有的商品为链接,构建全局图;将arma过滤器嵌入到门控图神经网络中,提取图模型中随时间变化的拓扑图信号,并得到会话图中涉及的各个节点的特征向量;采用注意力机制从用户历史会话中得到全局偏好信息;从用户点击的最后一个会话中获取用户的局部偏好信息,并结合全局偏好信息得到用户最终偏好信息;预测每个会话中下一点击商品可能出现的概率,并给出top-k推荐商品。
4.上述现有方案中的会话推荐方法从全局图中捕获丰富的会话表示(上下文关系),通过注意力机制学习用户的全局和局部偏好,进而提供准确的商品预测。但是现有会话推荐方法在探索项目间过渡关系中用户兴趣变化方面所做的努力有限,其一般是平等地对待项目之间的每个转换关系,忽略了转换关系中丰富的用户兴趣漂移信息,进而只能捕获连续动作之间的顺序转换,而不能有效地建模非相邻动作之间的复杂转换,使得项目嵌入的质量偏低,导致会话推荐的准确性仍然不高。因此,如何设计一种能够基于用户兴趣漂移程度提升项目嵌入质量的会话推荐方法是亟需解决的技术问题。
技术实现要素:
5.针对上述现有技术的不足,本发明所要解决的技术问题是:如何提供一种基于时间增强的图神经网络会话推荐方法,以能够基于用户兴趣漂移程度提升项目嵌入质量,从而提升会话推荐的准确性。
6.为了解决上述技术问题,本发明采用了如下的技术方案:
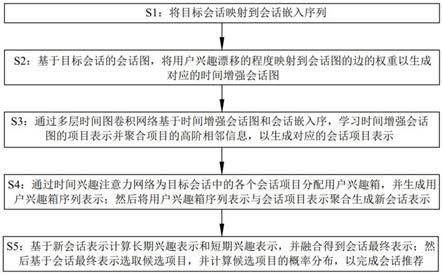
7.一种基于时间增强的图神经网络会话推荐方法,将目标会话输入经过训练的时间增强图神经网络模型中;所述时间增强图神经网络模型通过会话项目转换发生的时间间隔生成用户兴趣漂移程度,并构造能够根据用户兴趣漂移程度对应处理会话项目间转换关系的时间增强会话图,然后基于时间增强会话图学习项目嵌入并生成新会话表示,最后基于新会话表示计算候选项目的概率分布,以完成会话推荐。
8.优选的,时间增强图神经网络模型通过如下步骤完成会话推荐:
9.s1:将目标会话s=(v1,v2,
…
,vn)映射到会话嵌入序列h=(h1,h2,
…
,hn);
10.s2:基于目标会话的会话图,将用户兴趣漂移的程度映射到会话图的边的权重以生成对应的时间增强会话图;
11.s3:通过多层时间图卷积网络基于时间增强会话图和会话嵌入序,学习时间增强会话图的项目表示并聚合项目的高阶相邻信息,以生成对应的会话项目表示;
12.s4:通过时间兴趣注意力网络为目标会话中的各个会话项目分配用户兴趣箱,并生成用户兴趣箱序列表示;然后将用户兴趣箱序列表示与会话项目表示聚合生成新会话表示;
13.s5:基于新会话表示计算长期兴趣表示和短期兴趣表示,并融合得到会话最终表示;然后基于会话最终表示选取候选项目,并计算候选项目的概率分布,以完成会话推荐。
14.优选的,步骤s2中,时间增强会话图的定义为:对于目标会话s=(v1,v2,
…
,vn),其时间增强会话图为gs=(vs,εs,ws),其中,εs代表边的集合,ws表示边的权重矩阵;
15.每个节点vi∈vs和边(v
i-1
,vi)∈εs表示两个连续的项目v
i-1
和vi邻接关系,其矩阵表达形式为入边矩阵ai和出边矩阵ao;每条边(v
i-1
,vi)都对应着一个权重w
i-1,i
∈ws;每个节点vi∈vs添加了自连边,其矩阵表示为自连接矩阵as。
16.优选的,步骤s3中,通过如下步骤生成会话项目表示:
17.s301:通过多层时间图卷积网络的第l层输出嵌入表示
18.s302:将多层时间图卷积网络输出的嵌入表示h
il
作为会话项目vi∈s的嵌入表示;
19.s303:通过高速公路网络将多层时间图卷积网络输出的嵌入表示与其初始嵌入的表示进行合并得到会话项目vi∈s的项目表示并生成会话项目表示
20.优选的,通过公式计算嵌入表示
21.通过公式计算项目表示
22.其中,
23.上述式中:和分别表示时间增强会话图入边矩阵ai、入边矩阵ao和自连接矩阵as的第i行;l、l均表示多层时间图卷积网络的层数;表示可训练参数;σ表示函数sigmoid。
24.优选的,步骤s4中,通过如下步骤生成新会话表示:
25.s401:基于目标会话s中每个会话项目的点击时间戳t=(t1,t2,
…
,tn)计算每个项目距离最后一个项目的时间间隔序列q=(q1,q2,
…
,qn);
26.s402:将时间间隔序列q映射为兴趣敏感序列γ=(γ1,γ2,
…
,γn),并计算自适应时间跨度μ;
27.s403:通过时间兴趣注意力网络基于自适应时间跨度μ为目标会话s中的各个会话项目分配用户兴趣箱bini,并生成用户兴趣箱序列b=(bin1,bin2,
…
,binn);
28.s404:将用户兴趣箱序列b=(bin1,bin2,
…
,binn)中的各个用户兴趣箱bini映射到低维稠密向量ei,并生成对应的用户兴趣箱表示e=(e1,e2,
…
,en);
29.s405:通过非对称门控循环神经网络对用户兴趣箱表示的前向上下文信息和后向上下文信息进行不对称处理,生成对应的用户兴趣箱序列增强表示
30.s406:通过注意力机制聚合用户兴趣箱序列增强表示和会话项目表示生成捕获了项目顺序结构信息和用户时间兴趣特征的新会话表示c=(c1,c2,
…
,cn)。
31.优选的,通过公式计算兴趣敏感序列γ=(γ1,γ2,
…
,γn);
32.其中,m=t
n-t1;
33.通过公式计算自适应时间跨度μ;
34.通过公式bini=k,whereγi∈(μ
×
(k-1),μ
×
k]计算用户兴趣箱bini;
35.非对称门控循环神经网络通过如下公式生成用户兴趣箱序列增强表示非对称门控循环神经网络通过如下公式生成用户兴趣箱序列增强表示
36.通过公式计算新会话表示c=(c1,c2,
…
,cn);
37.其中,
38.上述式中:和l
p
分别表示衰减常数和左偏移量;d
init
和d
final
表示两个预先指定的常数设置d
init
=0.98,d
final
=0.01;e表示自然常数;n表示用户兴趣箱的个数;μ表示目标会话s所需要的自适应时间间隔;k∈(1,2,
…
,n);表示可训练参数。
39.优选的,步骤s5中,通过如下步骤生成候选项目的概率分布:
40.s501:基于新会话表示c=(c1,c2,
…
,cn)结合加和池化,生成长期兴趣表示z
long
;
41.s502:通过gru从新会话表示c中获取短期兴趣表示z
short
;
42.s503:结合门控机制融合长期兴趣表示z
long
和短期兴趣表示z
short
,生成会话最终表示z
final
;
43.s504:基于会话最终表示z
final
从候选项目集合v=(v1,v2,
…
,v
|v|
)中选取前k个候选项目vi∈v进行推荐,并计算各个候选项目vi∈v的分数;
44.s505:基于各个候选项目vi∈v的分数应用softmax函数,生成候选项目的概率分布。
45.优选的,通过公式计算长期兴趣表示z
long
;
46.通过公式计算短期兴趣表示z
short
,其中,代表在时间步长i-1处的会话项目表示,将最后一个会话项目表示作为会话短期表示
47.通过公式z
final
=f
⊙zlong
+(1-f)
⊙zshort
计算会话最终表示z
final
;
48.其中,
49.通过公式计算候选项目vi∈v的分数
50.通过公式计算候选项目vi∈v的概率,进而生成候选项目的概率分布;
51.上述式中:表示候选项目vi∈v的初始化嵌入表示;表示可训练参数。
52.优选的,通过时间反向传播算法训练时间增强图神经网络模型,并采用交叉熵作为损失函数;
53.其中,交叉熵损失函数表示为
54.上述式中:yi表示真实标签。
55.本发明的会话推荐方法与现有技术相比,具有如下有益效果:
56.本发明通过项目转换发生的时间间隔生成用户兴趣漂移程度,并根据用户兴趣漂移的程度对应处理会话项目间转换关系,使得能够关注转换关系中丰富的用户兴趣漂移信息,捕获非相邻动作之间的复杂转换关系,生成捕获了项目顺序结构信息和用户时间兴趣特征的新会话表示,即能够基于用户兴趣漂移程度提升项目嵌入的质量,从而能够提升会话推荐的准确性。同时,多层时间图卷积网络能够有效获取时间增强会话图的结构信息,使得能够准确的学习项目的嵌入,从而能够更好的提升项目嵌入的质量。此外,时间兴趣注意力网络能够捕获具有共同用户兴趣的项目的复杂转换模式,使得能够对在时间维度上具有相似用户兴趣的项目进行建模,进而能够关注项目之间的局部共性,生成捕获了项目顺序结构信息和用户时间兴趣特征的新会话表示,从而能够进一步提升会话推荐的准确性。
附图说明
57.为了使发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步的详细描述,其中:
58.图1为会话推荐方法的逻辑框图;
59.图2为时间增强图神经网络模型的网络结构图;
60.图3为实际实例的示意图;
61.图4为时间图卷积网络层数的变化的实验结果图;
62.图5为时间兴趣箱数量变化的实验结果图。
具体实施方式
63.下面通过具体实施方式进一步详细的说明:
64.实施例:
65.本实施例中公开了一种基于时间增强的图神经网络会话推荐方法。
66.基于时间增强的图神经网络会话推荐方法,将目标会话输入经过训练的时间增强图神经网络模型中;所述时间增强图神经网络模型通过会话项目转换发生的时间间隔生成用户兴趣漂移程度,并构造能够根据用户兴趣漂移程度对应处理会话项目间转换关系的时间增强会话图,然后基于时间增强会话图学习项目嵌入并生成新会话表示,最后基于新会话表示计算候选项目的概率分布,以完成会话推荐。
67.如图1和图2所示,时间增强图神经网络模型通过如下步骤完成会话推荐:
68.s1:将目标会话s=(v1,v2,
…
,vn)映射到会话嵌入序列h=(h1,h2,
…
,hn);
69.s2:基于目标会话的会话图,将用户兴趣漂移的程度映射到会话图的边的权重以生成对应的时间增强会话图(tes graph);
70.s3:通过多层时间图卷积网络(t-gcn)基于时间增强会话图和会话嵌入序,学习时间增强会话图的项目表示并聚合项目的高阶相邻信息,以生成对应的会话项目表示;
71.s4:通过时间兴趣注意力网络(temporal interest attention network,tian)为目标会话中的各个会话项目分配用户兴趣箱,并生成用户兴趣箱序列表示;然后将用户兴趣箱序列表示与会话项目表示聚合生成新会话表示;
72.s5:基于新会话表示计算长期兴趣表示和短期兴趣表示,并融合得到会话最终表示;然后基于会话最终表示选取候选项目,并计算候选项目的概率分布,以完成会话推荐。
73.本发明通过项目转换发生的时间间隔生成用户兴趣漂移程度,并根据用户兴趣漂移的程度对应处理会话项目间转换关系,使得能够关注转换关系中丰富的用户兴趣漂移信息,捕获非相邻动作之间的复杂转换关系,生成捕获了项目顺序结构信息和用户时间兴趣特征的新会话表示,即能够基于用户兴趣漂移程度提升项目嵌入的质量,从而能够提升会话推荐的准确性。同时,多层时间图卷积网络能够有效获取时间增强会话图的结构信息,使得能够准确的学习项目的嵌入,从而能够更好的提升项目嵌入的质量。此外,时间兴趣注意力网络能够捕获具有共同用户兴趣的项目的复杂转换模式,使得能够对在时间维度上具有相似用户兴趣的项目进行建模,进而能够关注项目之间的局部共性,生成捕获了项目顺序结构信息和用户时间兴趣特征的新会话表示,从而能够进一步提升会话推荐的准确性。
74.具体实施过程中,时间增强会话图的定义为:对于目标会话s=(v1,v2,
…
,vn),其时间增强会话图为gs=(vs,εs,ws),其中,εs代表边的集合,ws表示边的权重矩阵;每个节点vi∈vs和边(v
i-1
,vi)∈εs表示两个连续的项目v
i-1
和vi邻接关系,其矩阵表达形式为入边矩阵ai和出边矩阵ao;每条边(v
i-1
,vi)都对应着一个权重w
i-1,i
∈ws;每个节点vi∈vs添加了自连边,其矩阵表示为自连接矩阵as。
75.用户兴趣漂移与正在进行的会话中的两个连续项目之间的时间间隔密切相关,即两个连续项目之间的时间间隔越长,用户兴趣漂移越大,反之亦然。结合图3所示,我们可以观察到:(1)“sweater”和“iphone”之间的转换关系弱于“iphone”和“airpods”之间的转换关系,因为前者的用户兴趣漂移远大于后者;(2)用户兴趣漂移与时间间隔密切相关,即两个连续项目之间的时间间隔越大,表示用户兴趣漂移的程度越高;(3)短时间间隔内的物品(如“shirt”、“overcoat”和“sweater”)通常具有相似的用户兴趣而只有较小的兴趣偏移。
76.图3中,会话包含了5个项目(衬衫8
′
大衣7
′
毛衣405
′
手机15
′
耳机),其中毛衣和手机的时间间隔是405分钟,该时间间隔远远大于了手机和耳机15分钟的时间间隔,同时我们也能看出从毛衣到手机用户的兴趣发生了偏移,根据这一观察,我们按照如下方式进行边的权重计算:对于每个会话s=(v1,v2,
…
,vn),我们首先获取其项目的点击时间t=(t1,t2,
…
,tn),并基于用户兴趣漂移程度来测量时间增强会话图中每条边的权重,该程度基于对应于该边的时间间隔来计算。
77.利用牛顿冷却定律来计算边缘重量。目标会话s中两个相邻项目会话vi∈s和vj∈s之间的边的权重τ(
i,j)
计算公式为:
[0078][0079][0080][0081]
m=t
n-t1;
[0082]
式中:d
init
和d
final
表示两个预先指定的常数,其用于衰减的初始和最终边的权重,设置d
init
=0.98,d
final
=0.01;e表示自然常数;ti、tj表示项目会话vi∈s和vj∈s的点击时间戳;tn、t1示会话项目v1∈s和会话项目vn∈s的点击时间戳;和l
p
分别表示衰减常数和左偏移量,l
p
用于使τ
(i,j)
适应不同的会话。
[0083]
本发明将用户兴趣漂移程度映射到会话图的边的权重以生成时间增强会话图,能够实现根据用户兴趣漂移的程度对应处理会话项目间转换关系,使得能够关注转换关系中丰富的用户兴趣漂移信息,捕获非相邻动作之间的复杂转换关系,生成捕获了项目顺序结构信息和用户时间兴趣特征的新会话表示,即能够基于用户兴趣漂移程度提升项目嵌入的质量,从而能够提升会话推荐的准确性。
[0084]
具体实施过程中,通过如下步骤生成会话项目表示:
[0085]
s301:通过多层时间图卷积网络的第l层输出嵌入表示
[0086]
s302:将多层时间图卷积网络输出的嵌入表示作为会话项目vi∈s的嵌入表示;
[0087]
s303:通过高速公路网络将多层时间图卷积网络输出的嵌入表示与其初始嵌入的表示进行合并得到会话项目vi∈s的项目表示并生成会话项目表示
[0088]
单层时间图卷积网络(t-gcn)将聚合项目本身及其一阶邻居的信息。在t-gcn中,我们放弃了现有图神经网络(gcn)中最常用的两种机制(即线性转化和非线性激活)。为了捕获远距离项目之间的转移关系,我们堆叠了多层t-gcn来聚合项目的高阶相邻信息。
[0089]
通过公式计算嵌入表示
[0090]
通过公式计算项目表示
[0091]
其中,
[0092]
上述式中:和分别表示时间增强会话图入边矩阵ai、入边矩阵ao和自连接矩阵as的第i行;l、l均表示多层时间图卷积网络的层数;表示可训练参数;σ表示函数sigmoid。
[0093]
本发明通过多层时间图卷积网络能够有效获取时间增强会话图的结构信息,使得能够准确的学习项目的嵌入,从而能够更好的提升项目嵌入的质量。同时,能够通过高速公路网络解决项目表示过度平滑的问题。
[0094]
具体实施过程中,通过如下步骤生成新会话表示:
[0095]
s401:基于目标会话s中每个会话项目的点击时间戳t=(t1,t2,
…
,tn)计算每个项目距离最后一个项目的时间间隔序列q=(q1,q2,
…
,qn);
[0096]
s402:将时间间隔序列q映射为兴趣敏感序列γ=(γ1,γ2,
…
,γn),并计算自适应时间跨度μ;
[0097]
s403:通过时间兴趣注意力网络基于自适应时间跨度μ为目标会话s中的各个会话项目分配用户兴趣箱bini,并生成用户兴趣箱序列b=(bin1,bin2,
…
,binn);
[0098]
s404:将用户兴趣箱序列b=(bin1,bin2,
…
,binn)中的各个用户兴趣箱bini映射到低维稠密向量ei,并生成对应的用户兴趣箱表示e=(e1,e2,
…
,en);
[0099]
s405:通过非对称门控循环神经网络(asym-bigru)对用户兴趣箱表示的前向上下文信息和后向上下文信息进行不对称处理,生成对应的用户兴趣箱序列增强表示
[0100]
s406:通过注意力机制聚合用户兴趣箱序列增强表示和会话项目表示生成捕获了项目顺序结构信息和用户时间兴趣特征的新会话表示c=(c1,c2,
…
,cn)。
[0101]
具体的,我们将时间间隔较短的项目被分隔到同一个用户兴趣箱中。然后将每个箱子映射到一个嵌入,并将其与其对应的项目嵌入拼接起来。接下来,一种非对称的双向门控循环神经网络被用于对会话中的用户兴趣箱序列,并获得增强的用户兴趣箱序列表示。最后,利用注意力网络将增强后的用户兴趣箱表示形成对于项目的重要性系数,为相应的项目进行加权形成新的项目表示。
[0102]
通过公式计算兴趣敏感序列г=(γ1,γ2,
…
,γn);
[0103]
其中,m=t
n-t1;
[0104]
通过公式计算自适应时间跨度μ;
[0105]
通过公式bini=k,whereγi∈(μ
×
(k-1),μ
×
k]计算用户兴趣箱bini;
[0106]
非对称门控循环神经网络通过如下公式生成用户兴趣箱序列增强表示
[0107][0108]
通过公式计算新会话表示c=(c1,c2,
…
,cn);
[0109]
其中,
[0110]
上述式中:和l
p
分别表示衰减常数和左偏移量;d
init
和d
final
表示两个预先指定的常数设置d
init
=0.98,d
final
=0.01;e表示自然常数;n表示用户兴趣箱的个数;μ表示目标会话s所需要的自适应时间间隔;k∈(1,2,
…
,n);表示可训练参数。
[0111]
本发明通过时间兴趣注意力网络能够捕获具有共同用户兴趣的项目的复杂转换
模式,使得能够对在时间维度上具有相似用户兴趣的项目进行建模,进而能够关注项目之间的局部共性,生成捕获了项目顺序结构信息和用户时间兴趣特征的新会话表示,从而能够进一步提升会话推荐的准确性。
[0112]
具体实施过程中,通过如下步骤生成候选项目的概率分布:
[0113]
s501:基于新会话表示c=(c1,c2,
…
,cn)结合加和池化,生成长期兴趣表示z
long
;
[0114]
s502:通过gru从新会话表示c中获取短期兴趣表示z
short
;
[0115]
s503:结合门控机制融合长期兴趣表示z
long
和短期兴趣表示z
short
,生成会话最终表示z
final
;
[0116]
s504:基于会话最终表示z
final
从候选项目集合v=(v1,v2,
…
,v
|v|
)中选取前k个候选项目vi∈v进行推荐,并计算各个候选项目vi∈v的分数;
[0117]
s505:基于各个候选项目vi∈v的分数应用softmax函数,生成候选项目的概率分布。
[0118]
通过公式计算长期兴趣表示z
long
;
[0119]
通过公式计算短期兴趣表示z
short
,其中,代表在时间步长i-1处的会话项目表示,将最后一个会话项目表示作为会话短期表示
[0120]
通过公式z
final
=f
⊙zlong
+(1-f)
⊙zshort
计算会话最终表示z
final
;
[0121]
其中,
[0122]
通过公式计算候选项目vi∈v的分数
[0123]
通过公式计算候选项目vi∈v的概率,进而生成候选项目的概率分布;
[0124]
上述式中:表示候选项目vi∈v的初始化嵌入表示;表示可训练参数。
[0125]
本发明基于长期兴趣表示和短期兴趣表示计算会话最终表示,并基于会话最终表示计算生成候选项目的概率分布,使得能够有效的保证会话推荐的准确性。
[0126]
具体实施过程中,通过时间反向传播算法训练时间增强图神经网络模型,并采用交叉熵作为损失函数;其中,交叉熵损失函数表示为
[0127]
上述式中:yi表示真实标签。
[0128]
本发明通过时间反向传播算法和交叉熵损失函数,能够有效的训练时间增强图神经网络模型,进而能够提升模型的会话推荐效果。
[0129]
为了更好的说明本发明会话推荐方法的优势,本实施例公开了如下实验。
[0130]
一、数据集
[0131]
本实验在三个广泛使用的基准数据集(diginetica,tmall,nowplaying,retailrocket)上测试了本发明的时间增强图神经网络模型(后称为te-gnn)和一系列基线模型的性能。
[0132]
diginetica:该数据来自于2016年cikm cup挑战赛。由于其包含商品交易类型的数据,所以经常被用于会话推荐任务,我们提取其最后一周的数据作为测试数据。
[0133]
tmall:该数据来自于2015年ijcai竞赛,其由匿名用户在天猫网上购物平台上的
购物日志组成。由于项目数量太多,我们选择会话最近的1/64部分作为数据集,其中最后一天的会话用作测试数据,其余会话用于训练。
[0134]
nowplaying:该数据集由twitter构建,其描述了用户的音乐收听习惯。我们将数据分为训练和测试两部分,其中最近两个月的数据用于测试,剩余的历史数据作为训练集。
[0135]
retailrocket:该数据来自于2016年的kaggle竞赛,其包含了用户在电子商务网站上4.5个月的行为数据。我们提取最近的1/4数据作为训练集,最后15天的数据作为测试集。
[0136]
在三个数据集中,将会话长度小于2的会话和项目出现次数小于5的项目进行过滤。
[0137]
我们同样进行了数据增强,例如:对于会话s=(v1,v2,
…
,vn),可以产生样本和标签:([v1],v2),([v1,v2],v3),
…
,([v1,v2,
…
,v
n-1
],vn)。
[0138]
二、评测指标
[0139]
我们使用2个广泛使用的评测指标p@20和mrr@20来评估所有模型的性能。p@k和mrr@k的值越高,代表模型性能越好。
[0140]
p@k(precision):它衡量目标项目在top-k推荐中排名时的数量比例,是评估未排名结果的指标。
[0141]
其中n是测试集数量,n
hit
是目标项目在预测的top-k列表中的样本数量。
[0142]
mrr@k(mean reciprocal rank):它是目标项在推荐列表中的倒数排名的平均值。此指标考虑正确推荐项目在排名列表中的位置。
[0143]
其中n是测试集数量,ranki是第i个目标项目在推荐列表中的位置。若目标项目未在top-k推荐列表中,则mrr@k为0。
[0144]
三、基线模型
[0145]
为了全面评估我们模型的性能,我们将其与11种基线方法进行了比较,这些方法大致可分为三类,即:传统推荐方法,基于循环神经网络rnn和注意力机制的方法,基于图神经网络gnn的方法。所有基线的详细信息简要描述如下。
[0146]
传统推荐方法:
[0147]
pop:是推荐系统中常用的一种基线方法,它推荐训练集中前n个出现频率最高的项目。
[0148]
item-knn:是一种基于协同过滤的方法,其通过向用户推荐与当前会话最相似的项目。
[0149]
fpmc:该方法将矩阵分解和马尔科夫链结合起来,其中序列数据由转移矩阵建模,所有转移矩阵都是用户特定的。它引入了一个因子分解模型,该模型给出了转换立方体的低秩近似值,其中每一个部分都是用户历史点击在马尔科夫链下的转移矩阵。
[0150]
基于循环神经网络和注意力机制的方法:
[0151]
gru4rec:该方法利用门控循环神经网络gru模拟用户的顺序行为并采用并行小批次训练方案进行模型训练。
[0152]
narm:该方法使用循环神经网络rnn来建模用户的顺序行为并结合注意力机制来捕获用户的主要偏好。同时,它结合双线性匹配机制为每个候选项目生成推荐概率。
[0153]
stamp:该模型通过捕获用户的长期偏好和短期兴趣来缓解用户的偏好转移的问题。
[0154]
csrm:该方法提出利用协作邻域信息进行基于会话的推荐。它利用内部编码器捕获当前会话的信息,同时它也利用外部编码器捕获邻域会话的协作信息。
[0155]
sr-iem:该方法利用改进的注意机制生成项目的重要性得分,并根据用户的全局偏好和当前兴趣生成会话表示。
[0156]
基于图神经网络的方法:
[0157]
sr-gnn:sr-gnn通过将会话序列建模为会话图来捕获项目在会话中复杂的转换关系。同时,它还结合门控图神经网络和自注意力机制来生成会话表示。
[0158]
tagnn:该方法通过会话序列建模为会话图并通过图神经网络获取项目的嵌入表示,它还引入了目标感知模块,以揭示给定目标项目与所有候选项目的相关性,从而提升会话表示质量。
[0159]
gce-gnn:是目前性能最好的模型,它通过2个不同的视角学习项目的表示,例如:会话视角和全局视角。会话视角旨在通过会话内项目的转换关系学习项目的表示,全局视角旨在通过项目在所有会话中的转换关系学习项目的表示。
[0160]
四、实验参数设置
[0161]
在te-gnn的所有实验中,我们设置训练批次大小为256,项目嵌入的向量维度为256。用户兴趣箱的数量n为6,t-gcn的层数为2。
[0162]
在实验中的模型参数初始化按照均值为0,方差为0.1进行初始化。我们使用adam优化器并配备0.001的学习率,该学习率会每训练3轮衰减为之前的0.1倍,dropout的随机丢弃率设置为0.3。另一方面,我们利用l2正则化来避免过拟合,其值设定为1e-4。te-gnn由pytorch实现并在gpu geforce gtx 2080ti上部署。同时,我们根据基线模型的论文来设置它们对应的参数。
[0163]
五、整体实验
[0164]
为了验证te-gnn的有效性,在表1中报告了te-gnn与最先进基线之间的性能比较。
[0165]
表1 te-gnn与基线模型的性能比较
[0166][0167]
从表1中,可以观察到传统的推荐方法pop在所有数据集的两个指标上表现最差。这主要是因为它只关注出现频率高的项目,而忽略了会话内有用的序列信息。fpmc表现出比pop更好的性能,因为它应用了一阶马尔可夫链和矩阵分解来捕获用户的偏好。在所有传
统的推荐方法中,item-knn在所有数据集上都取得了最好的性能。这是因为用户的潜在偏好对推荐效果的影响更大
[0168]
与传统的推荐方法相比,基于循环神经网络rnn和注意力机制的方法表现出更好的性能。其中gru4rec是第一个基于rnn的会话推荐方法,它在大部分数据集上都优于传统的推荐方法,这表明了通过rnn对与建模序列信息的实用性。narm和stamp的性能均优于gru4rec,因为它们进一步结合了注意力机制来动态捕获会话中项目的重要性。csrm通过融合来自其他会话的辅助信息来增强当前会话表示,并在所有数据集上表示出比narm和stamp更好的性能。sr-iem是最近提出的一个模型,该方法修改了自注意力机制,从而更精准的获得会话中每个项目的重要性来捕获用户的长期偏好,同时,该方法基于用户的长期偏好和会话中最后一个项目生成的短期偏好进行推荐。
[0169]
在所有基线模型的实验报告来看,基于图神经网络的方法体现了其优越性。其原因也许是图神经网络gnn放松了连续项目之间的时间依赖性假设并将复杂项目转换关系建模为成对关系(例如:有向图)。例如:sr-gnn通过将会话序列建模为图形结构,以此来捕获项目之间更多的隐式连接。tagnn在sr-gnn的基础上结合目标感知注意力机制进一步考虑了用户偏好。在所有基于gnn的方法中,gce-gnn在所有数据集上的性能最好。这是因为gce-gnn有效地从全局上下文(其他会话)和当前会话来同时学习项目的表示。
[0170]
我们提出的方法te-gnn在所有数据集上都优于所有最先进的基线方法。具体而言,te-gnn在diginetica、tmall、nowplaying、retairocket上的p@20上分别高出最先进的基线模型1.03%、16.73%、6.62%、2.73。在mrr@20上也能看到类似的性能改进。实验结果表明,对复杂用户兴趣漂移和用户共同兴趣进行建模至关重要,te-gnn通过引入时间图卷积网络和时态兴趣注意力网络,可以有效地对这两种模式信息进行建模。
[0171]
六、时间图卷积网络(t-gcn)的影响
[0172]
为了探究时间图卷积网络(t-gcn)对模型性能的影响,我们将其与几种变体模型进行比较,变体模型的简要描述如下:
[0173]
te-gnn-mlp:利用多层感知器(mlp)代替te-gnn中的t-gcn模块。
[0174]
te-gnn-ggnn:该变体使用门控图神经网络(ggnn)取代te-gnn中的t-gcn。
[0175]
te-gnn-gat:将te-gnn中的t-gcn替换为图形注意网络(gat)。
[0176]
表2变体模型的性能实验结果
[0177][0178]
表2报告了所有变体模型的性能实验结果。从表2可以观察到三个变体模型的性能在两个指标上都有较大程度的下降。更准确地说,用mlp替换t-gcn表现出最差的性能,因为它缺乏捕获复杂项目转换关系的能力。te-gnn-ggcn和te-gnn-gat均显示出优于te-gnn-mlp的性能,因为它们基于图形神经网络有效地对项目之间丰富的结构信息进行了建模。其中,te-gnn-gat的表现优于te-gnn-ggcn,这是因为它通过图注意力网络考虑了相邻项目的重要性。我们提出的方法te-gnn比所有三种变体都具有更高的性能,这表明了在我们的模
型中加入时间图卷积网络的有效性。
[0179]
七、时间兴趣注意力网络(tian)的影响
[0180]
我们比较了时间兴趣注意力网络(tian)与sasrec和sgnn中分别使用的自注意力网络和位置感知注意力网络的性能。与自注意力网络和位置感知注意力网络不同的是,本发明的时间兴趣注意网络(tian)对时间信息进行了细粒度的挖掘。此外,我们通过丢弃aasym-bigru组件或用传统bigru替换它,进一步研究了tian中提出的组件非对称双向门控循环神经网络(asym-bigru)的有效性。所有变体的简要说明如下所示:
[0181]
w/o tian:删除te-gnn中的时间兴趣注意网络(tian)。
[0182]
te-gnn-sa:将te-gnn中的时间兴趣注意网络(tian)替换为自注意力网络。
[0183]
te-gnn-pa:采用sgnn中的位置感知注意力网络,而不是te-gnn中的时间兴趣注意网络(tian)。
[0184]
tian-w/o gru:我们丢弃tian中的asym-bigru,并且不考虑会话中的用户兴趣箱的顺序关系。
[0185]
tian-bigru:我们将asym bigru替换为常规bigru,该bigru将平等地处理用户兴趣箱前向和后向的上下文信息。
[0186]
通过实验可以看出,配备时间兴趣注意网络将实现显著的性能改进,这表明了时间兴趣注意网络的有效性。te-gnn-w/o tian显示出显著的性能下降,因为它不能对用户的时间兴趣信息进行建模。与te-gnn-w/o tian相比,te-gnn-sa和te-gnn-pa都没有表现出显著的性能改进,这是由于te-gnn-sa只捕获项目之间的语义关系,而te-gnn-pa只关注项目的位置信息,因此两者都不能捕获用户的时间兴趣信息。与这些变体不同,tian-w/o gru使用多粒度兴趣分离策略来显式地建模用户的时间兴趣信息,因此获得了优异的性能。tian-bigru通过进一步考虑会话中每个用户兴趣箱的上下文信息来提高性能。然而,优于bigru的一个主要局限性是它平等地对待一个兴趣点前向和后向的上下文信息。然而,在基于会话的推荐场景中,前向上下文信息比后向上下文信息发挥更重要的作用。与所有变体相比,我们提出的方法te-gnn通过引入了非对称双向门控循环神经网络(asym bigru)实现了最佳性能,该网络对用户兴趣箱上下文信息的两侧进行了不同的建模。
[0187]
八、时间图卷积网络层数的影响
[0188]
为了验证探索图增强的注意力网络(gea)对推荐性能的影响,我们设计了以下三种变体模型:为了检验te-gnn中t-gnn层数的影响,我们研究了te-gnn分别配备1到6层t-gnn的性能变化。由于在我们的模型中利用了高速公路网络来缓解过度平滑问题,我们还比较了我们的方法与其相应的变体te-gnn-w/o hn的性能,该变体在不同数量的t-gnn层上丢弃了高速公路网络。所有四个数据集上的实验结果如图4所示。从图4中,我们可以观察到,在diginetica数据集上,我们的方法te-gnn的性能首先上升,并在t-gnn层数l=2时达到峰值,然后开始下降并变大。在tmall数据集上,随着t-gnn层数不断增多,
[0189]
te-gnn的性能逐渐提高,并在t-gnn层数l=4时达到峰值。如果我们进一步扩大层的数量,将导致te-gnn大幅度的性能下降。在其他两个数据集(nowplaying和retailrocket)上也可以观察到类似的结果。这一趋势表明,当我们增加t-gnn层的数量时,我们的模型可以有效地捕获远处项目之间的转换关系。然而,如果tgnn层的数量过大,则会向模型中注入更多不相关或噪声高阶的相邻项,从而导致模型次优性能。我们还可以在图4
中观察到,我们的模型te-gnn始终比其相应的变体te-gnn-w/o hn表现更好。此外,随着t-gnn层数的增加,te-gnn-w/o hn与我们的方法te-gnn相比,性能退化更大。结果表明,高速公路网络可以有效地缓解由这些多层gcn结构引起的过度平滑问题。
[0190]
九、时间兴趣箱数量的影响
[0191]
为了探索te-gnn中时间兴趣箱的数量n的影响,我们在diginetica和tmall数据集上将时间兴趣箱的数量从1变为10。实验结果如图5所示。从图5中,我们可以看到用户兴趣箱的数量对te-gnn的性能影响很大。更准确地说,在diginetica数据集上,te-gnn的性能首先提高,并在n=6时达到峰值,在n为7-10时,模型性能逐渐下降。模型在tmall数据集的性能变化趋势与diginetica数据集上的性能变化趋势相似。具体来说,随着时间兴趣箱数量的增加,te-gnn的性能先是不断上升,直到达到峰值(等于8),然后开始快速下降。这种变化趋势是合理的,因为当它很小时,它不能捕获细粒度的用户兴趣以及时间维度。当规模过大时,会话中的共同用户兴趣将被忽略,从而导致推荐性能低下。
[0192]
需要说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管通过参照本发明的优选实施例已经对本发明进行了描述,但本领域的普通技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离所附权利要求书所限定的本发明的精神和范围。同时,实施例中公知的具体结构及特性等常识在此未作过多描述。最后,本发明要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1