基于邻域相似关系的图像相似性的计算方法与流程
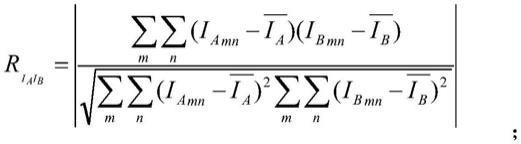
1.本发明涉及图像处理的技术领域,特别涉及一种基于邻域相似关系的图像相似性的计算方法。
背景技术:
2.图像指纹技术广泛应用于图像追踪溯源、图像检索以及图像拷贝检测中,其一般策略是从图像中抽取少量特征组成能够表彰原始图像内容的特征向量,作为与其他图像进行比对的依据。典型的特征提取方案包括平均哈希算法(ahash)、感知哈希算法(phash)、改进的感知哈希算法(whash)、差分哈希算法(dhash)、sift特征以及神经网络法等。这些方法,尤其是感知哈希算法,在各种以图识图引擎中起到重要的作用。同样的,有一些不是基于图像指纹技术的图像追溯算法,比如图像明水印技术以及盲水印(隐水印)技术。在特征提取方案中,ahash、phash、whash以及dhash在面对图像旋转、裁剪攻击时鲁棒性较差;sift方法在能够有效抵抗图像旋转,但是易受噪声影响;神经网络法虽然对旋转裁剪攻击有一定的抵抗能力,但由于神经网络是有监督的做法,所以受到网络模型、训练集影响较大,结果不稳定,而且通常检测速度较慢。明水印技术能够显式地给图像加上标记,其所有权一目了然,但是大量使用明水印技术会影响图像观感,有时甚至会遮挡重要信息。盲水印技术虽然是明水印技术的改进,但是对图像压缩即尺寸变化的抵抗能力较差,同时由于盲水印是利用傅里叶变换将水印信息嵌入原图像,所以水印提取结果不稳定,通常含有大量噪声。
技术实现要素:
3.本发明所要解决的技术问题是克服现有技术的缺陷,提供一种基于邻域相似关系的图像相似性的计算方法,它通过邻域关系确定相似性,不易受到椒盐噪声、局部光照不均的影响,能够最大程度地保证图像的相似关系在局部结构上的稳定。
4.为了解决上述技术问题,本发明的技术方案是:一种基于邻域相似关系的图像相似性的计算方法,方法步骤中包含:
5.将目标图像切分为大小一致的多个图像块;
6.基于四邻域计算目标图像与数据库中图像的结构相似性s
structure
;
7.将结构相似性s
structure
与阈值ts比较;其中,
8.如果s
structure
≥ts,基于四邻域计算目标图像与数据库中图像的特性相似性s
feature
,计算结构相似性s
structure
和特性相似性s
feature
的加权平均数,得到目标图像与数据库中图像的整体相似性s;
9.如果s
structure
<ts,目标图像与数据库中的图像无相似性。
10.进一步,在将目标图像切分为多个图像块前,还包括对目标图像进行处理,所述处理过程包含:
11.先去除目标图像边界上的纯色区域;再对目标图像进行灰度化处理;后将目标图像归一化至m
×
m像素大小;其中,
12.将目标图像均切成n
×
n个图像块,n≥3,m为n的整数倍。
13.进一步,基于四邻域计算目标图像与数据库中图像的结构相似性s
structure
的方法步骤中包含:
14.定义相邻图像块之间的相似系数的计算方式;
15.计算目标图像除边界外的每一个图像块与其四邻域图像块之间的相似系数,目标图像除边界外的每一个图像块与其四邻域图像块之间的相似系数构成一个1
×
4的相似系数数组;
16.在每个相似系数数组中,以四个相似系数的均值为衡量系数,相似系数大于或等于衡量系数,置1,小于衡量系数,置0,每个相似系数数组得到一个1
×
4的相关系数数组;
17.对于每一个1
×
4的相关系数数组,与数据库中图像的对应位置的相关系数数组进行比对,其结果diff为:
[0018][0019]
其中,i代表数组中第i个元素,为异或运算,ai为目标图像的某个相关系数数组中第i个元素,bi为数据库中图像对应位置的相关系数数组的第i个元素;
[0020]
将(n-2)2个diff累加,得到diff;
[0021]
由得到s
structure
。
[0022]
进一步,相邻图像块之间的相似系数的计算方式为:
[0023][0024]
其中,m
×
n为图像块ia和图像块ib的大小,为图像块ia的像素均值,为图像块ib的像素均值,为图像块ia和图像块ib的相似系数。
[0025]
进一步,基于四邻域计算目标图像与数据库中图像的特性相似性s
feature
的方法步骤中包含:
[0026]
对于每个图像块,以2
×
2大小的卷积核,步长为2求取中位数,得到特征矩阵h,将特征矩阵h的灰度压缩到8级,得到特征矩阵h,将特征矩阵h压缩到一维,则得到一个一维数组;
[0027]
将目标图像除边界外的每一个图像块的四邻域图像块所对应的一维数组与数据库中图像相对应图像块的四邻域图像块所对应的一维数组做对比,当对应位置数值相同时,置为0,反之置为1,得到对比后的数组v;其中,
[0028]
某个图像块的一个邻域图像块与数据库中图像相对应图像块的相对应邻域图像块的相似度s
feature
为:
[0029][0030]
采用四邻域均值代表某个图像块与数据库中图像对应图像块的相似度,之后从左向右,从上到下对目标图像除边界外的图像块进行遍历,求取均值作为目标图像与数据库中图像的特征相似度s
feature
。
[0031]
进一步,将特征矩阵h的灰度压缩到8级,得到特征矩阵h的计算公式为:
[0032][0033]
其中,max(h)代表特征矩阵h的最大值,min(h)代表特征矩阵h的最小值,代表向下取整。
[0034]
进一步,计算结构相似性s
structure
和特性相似性s
feature
的加权平均数,得到目标图像与数据库中图像的整体相似性s的计算公式为:
[0035]
s=0.3
×sstructure
+0.7
×sfeature
。。。
[0036]
进一步,ts=0.7。
[0037]
进一步,m=512,n=16,每个图像块的像素大小为32
×
32。
[0038]
采用了上述技术方案后,本发明通过邻域关系确定图像的结构相似性,在满足结构相似性阈值的前提下计算特征相似性,结合结构相似性和特征相似性作为最终的图像相似性,采用邻域关系的好处在于不易受到椒盐噪声、局部光照不均的影响,能够最大程度地保证图像的相似关系在局部结构上的稳定,特征相似性是计算图像特征值,对特征值进行比对,特征值差异越小代表图像越相似,综合结构相似性和特征相似性得到整体相似性,使得整体精度更高。
具体实施方式
[0039]
为了使本发明的内容更容易被清楚地理解,下面根据具体实施例,对本发明作进一步详细的说明。
[0040]
一种基于邻域相似关系的图像相似性的计算方法,方法步骤中包含:
[0041]
将目标图像切分为大小一致的多个图像块;
[0042]
基于四邻域计算目标图像与数据库中图像的结构相似性s
structure
;
[0043]
将结构相似性s
structure
与阈值ts比较;其中,
[0044]
如果s
structure
≥ts,基于四邻域计算目标图像与数据库中图像的特性相似性s
feature
,计算结构相似性s
structure
和特性相似性s
feature
的加权平均数,得到目标图像与数据库中图像的整体相似性s;
[0045]
如果s
structure
<ts,目标图像与数据库中的图像无相似性。
[0046]
在本实施例中,由于s
structure
代表全图像邻域的结构相似性,考虑到四邻域内可能存在的噪声偏差、光照偏差以及图像裁剪的问题,所以我们认为阈值应不大于0.75,即平均一个图像块的四邻域内有三个图像块结构一致,于是,为了提高容错能力,本发明中,ts取
值为0.7。在比对过程中可以人为设置阈值,当需要比对的是包含缺失区域的目标图像,可以适当降低阈值标准。
[0047]
在本实施例中,在本实施例中,计算结构相似性s
structure
和特性相似性s
feature
的加权平均数,得到目标图像与数据库中图像的整体相似性s的计算公式为:
[0048]
s=0.3
×sstructure
+0.7
×sfeature
。。。
[0049]
在本实施例中,在将目标图像切分为多个图像块前,还包括对目标图像进行处理,所述处理过程包含:
[0050]
先去除目标图像边界上的纯色区域;再对目标图像进行灰度化处理;后将目标图像归一化至m
×
m像素大小;其中,
[0051]
将目标图像均切成n
×
n个图像块,n≥3,m为n的整数倍。、
[0052]
在本实施例中,m=512,n=16,每个图像块的像素大小为32
×
32。
[0053]
纯色区域的定义是某个矩形区域内,图像rgb像素值各处相同,这些边界对目标图像本身没有任何意义,可能是目标图像在复制过程中人为加入的用于混淆目标图像溯源算法的区域。
[0054]
在本实施例中,基于四邻域计算目标图像与数据库中图像的结构相似性s
structure
的方法步骤中包含:
[0055]
定义相邻图像块之间的相似系数的计算方式;
[0056]
计算目标图像除边界外的每一个图像块与其四邻域图像块之间的相似系数,目标图像除边界外的每一个图像块与其四邻域图像块之间的相似系数构成一个1
×
4的相似系数数组;
[0057]
在每个相似系数数组中,以四个相似系数的均值为衡量系数,相似系数大于或等于衡量系数,置1,小于衡量系数,置0,每个相似系数数组得到一个1
×
4的相关系数数组;
[0058]
对于每一个1
×
4的相关系数数组,与数据库中图像的对应位置的相关系数数组进行比对,其结果diff为:
[0059][0060]
其中,i代表数组中第i个元素,为异或运算,ai为目标图像的某个相关系数数组中第i个元素,bi为数据库中图像对应位置的相关系数数组的第i个元素;
[0061]
目标图像与数据库中图像的差异程度是(n-2)2个diff的总和,将(n-2)2个diff累加,得到diff;
[0062]
由得到s
structure
。
[0063]
其中,被切分为n
×
n块图像块的目标图像,总共可以得到(n-2)2个1
×
4的相关系数数组,我们将关系简化为[0,1]值域的数组,是因为相信,相同或者相似的图像在邻域范围内的相似关系的结构是一致的。
[0064]
在本实施例中,diff的取值为[0,1,2,3,4]。diff为0代表两者在四邻域的相关性结构一致,diff为4代表两者在四邻域相关性结构完全不同。于是,本发明中,目标图像与数据库中图像的差异程度diff的值域为[0,784]。
[0065]
在本实施例中,定义相邻图像块之间的相似系数的计算方式为:
[0066][0067]
其中,m
×
n为图像块ia和图像块ib的大小,为图像块ia的像素均值,为图像块ib的像素均值,为图像块ia和图像块ib的相似系数。
[0068]
在本实施例中,基于四邻域计算目标图像与数据库中图像的特性相似性s
feature
的方法步骤中包含:
[0069]
对于每个图像块,以2
×
2大小的卷积核,步长为2求取中位数,得到特征矩阵h,采用中位数是为了防止噪声影响,将特征矩阵h的灰度压缩到8级,得到特征矩阵h,将特征矩阵h压缩到一维,则得到一个一维数组;
[0070]
由于考察的是四邻域的图像块关系,所以在与数据库图像比对的时候也是按照四邻域同时比对,即一个图像块需要同时比对4个1
×
256的一维数组的差异程度,将目标图像除边界外的每一个图像块的四邻域图像块所对应的一维数组与数据库中图像相对应图像块的四邻域图像块所对应的一维数组做对比,当对应位置数值相同时,置为0,反之置为1,得到对比后的数组v;其中,
[0071]
某个图像块的一个邻域图像块与数据库中图像相对应图像块的相对应邻域图像块的相似度s
feature
为:
[0072][0073]
采用四邻域均值代表某个图像块与数据库中图像对应图像块的相似度,之后从左向右,从上到下对目标图像除边界外的图像块进行遍历,求取均值作为目标图像与数据库中图像的特征相似度s
feature
。如此,可以有效规避局部裁剪造成的目标图像缺失。
[0074]
在本实施例中,将特征矩阵h的灰度压缩到8级,得到特征矩阵h的计算公式为:
[0075][0076]
其中,max(h)代表特征矩阵h的最大值,min(h)代表特征矩阵h的最小值,代表向下取整。如此,即可将图像块灰度级压缩到[0-7]这八个数量级。
[0077]
按特征矩阵h的最大值和最小值压缩图像块的像素等级,一是为了降低比对复杂度,二是在比对时可以减少光照不均的影响。
[0078]
以上所述的具体实施例,对本发明解决的技术问题、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1