一种异常用电识别方法和异常用电识别系统
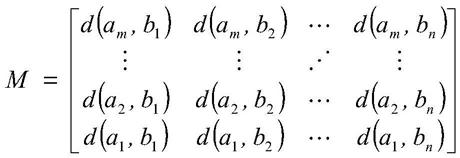
1.本发明涉及用电数据处理技术领域,具体涉及一种异常用电识别方法和异常用电识别系统。
背景技术:
2.异常用电识别是用电稽查、计量装置运行状态辨识的重要内容,对维护电网的安全运行和保障正常用户权益有重要意义。现有人工排查方法难以应对不同异常用电原因所呈现的多样性、随机性等特点,导致识别结果往往准确率不高,且效率较低。随着人工智能算法的发展,基于回归模型、分类模型与聚类模型的集中式计算方法被广泛应用。但是为了识别用户多元用电模式,这些方法在保证识别准确性的基础上容易造成计算过于复杂,而考虑效率的简单计算方法又难以准确度量不同用电模式的相似性,因此难以兼顾计算效率与准确性;此外,将用电数据上传至云端集中计算会占用大量网络带宽和计算资源,进一步限制了异常辨识的应用。因此迫切需要一种分布式的异常识别方法以平衡准确性和计算效率。
技术实现要素:
3.本发明的目的在于提供一种异常用电识别方法和异常用电识别系统,以解决现有异常用电识别受限的问题。
4.本发明解决上述技术问题的技术方案如下:
5.本发明提供一种异常用电识别方法,所述异常用电识别方法包括:
6.采集历史用电数据;
7.对所述历史用电数据进行数据压缩处理,得到压缩后的用电数据;
8.根据所述压缩后的用电数据,利用基于密度的聚类算法,对所述历史用电数据中的异常用电进行识别,得到识别结果。
9.本发明还提供一种异常用电识别方法,其应用于边缘端,所述异常用电识别方法包括:
10.对历史用电数据进行数据处理操作,得到新的用电数据,其中,所述历史用电数据包括多个历史用电子数据,所述新的用电数据包括多个与所述历史用电子数据一一对应的新的用电子数据;
11.计算每个所述历史用电子数据的阈值;
12.根据多个所述历史用电子数据的阈值和多个所述新的用电子数据,对所述历史用电数据进行分段处理,得到分段处理结果;
13.计算每段处理结果的平均值,得到计算结果;
14.根据所述计算结果,得到压缩数据序列;
15.根据所述压缩数据序列,得到所述压缩后的历史用电数据。
16.可选择地,所述对所述历史用电数据进行数据处理操作包括:
17.对所述历史用电数据中的每个历史用电子数据进行差分运算操作,得到差分运算后的用电数据;
18.取所述差分运算后的用电数据的绝对值,得到所述新的用电数据。
19.可选择地,所述计算每个所述历史用电子数据的阈值包括:
20.将目标历史用电子数据的目标范围内的值作为所述目标用电子数据的阈值的计算窗口;
21.根据所述目标用电子数据的阈值的计算窗口,得到所述目标历史用电子数据的阈值。
22.可选择地,所述目标历史用电子数据的阈值的计算方式为:
[0023][0024]
其中,thj表示x
j+1
相对于xj允许的最大变化量,μ表示计算窗口中数据的平均值,σ表示计算窗口中数据的标准差,pj为能量比率,且ej和e
t
分别为计算窗口中信号的能量和整个信号的总能量,且的能量和整个信号的总能量,且cnt表示常数,xj表示历史数据中第j个历史子数据。
[0025]
可选择地,所述根据多个所述历史用电子数据的阈值和多个所述新的用电子数据,对所述历史用电数据进行分段处理,得到分段处理结果包括:
[0026]
若当前所述新的用电子数据大于与当前所述新的用电子数据对应的历史用电子数据的阈值,则将该历史用电子数据作为分段点;
[0027]
利用所述分段点对所述历史用电数据进行分段,得到多段历史用电数据;
[0028]
将多段所述历史用电数据作为分段处理结果输出。
[0029]
本发明还提供一种异常用电识别方法,其应用于云端,所述异常用电识别方法包括:
[0030]
获取压缩后的用电数据中的压缩数据序列;
[0031]
计算多个所述压缩数据序列间的分段加权dtw距离和滑动欧式距离,得到第一距离计算结果和第二距离计算结果;
[0032]
根据所述第一距离计算结果和所述第二距离计算结果,得到综合相似度;
[0033]
根据所述综合相似度,利用基于密度的聚类算法,对所述历史用电数据中的异常用电进行识别,得到识别结果。
[0034]
可选择地,所述分段加权dtw距离为:
[0035]
dtw(a,b)=d(m,n)
[0036]
其中,dtw(a,b)表示压缩数据序列a和压缩数据序列b之间的分段加权dtw距离;a和b分别表示压缩数据序列a和压缩数据序列b,d(m,n)表示累积距离矩阵的第m行n列的值,d是m
×
n的距离矩阵;
[0037]
所述滑动欧式距离为:
[0038][0039]
其中,ed(a,b)表示压缩数据序列a和压缩数据序列b之间的滑动欧式距离,ak和bk分别表示压缩数据序列a和压缩数据序列b中第k个元素ak和第k个元素bk。
[0040]
所述综合相似度为:
[0041]
s(a,b)=α
·
dtw(a,b)+β
·
ed(a,b)
[0042]
其中,s(a,b)表示综合相似度,α和β分别为加权dtw距离和滑动欧式距离的权重,dtw(a,b)表示压缩数据序列a和压缩数据序列b之间的分段加权dtw距离,ed(a,b)表示压缩数据序列a和压缩数据序列b之间的滑动欧式距离。
[0043]
可选择地,所述根据所述综合相似度,利用基于密度的聚类算法,对所述历史用电数据中的异常用电进行识别,得到识别结果包括:
[0044]
根据所述综合相似度,得到综合相似度矩阵;
[0045]
根据所述综合相似度矩阵的行数,得到最小聚类点数;
[0046]
对所述综合相似度矩阵中每行元素进行排序,得到排序后的每行元素;
[0047]
取排序后的每行元素中所述最小聚类点数值所在列的所有数据,并对其进行最大最小值归一化处理,得到处理结果;
[0048]
根据所述处理结果绘制曲线;
[0049]
若所述曲线中目标点与其相邻点间的变化量大于预设阈值,则将满足该条件的第一个所述目标点处理之前的值作为邻域半径;
[0050]
将所述邻域半径、所述最小聚类点数和所述相似度矩阵输入所述基于密度的聚类算法中进行识别,得到识别结果。
[0051]
基于上述技术方案,本发明还提供一种异常用电识别系统,所述异常用电识别系统利用上述的异常用电识别方法,并且,所述异常用电识别系统包括:
[0052]
数据采集模块,所述数据采集模块用于采集历史用电数据;
[0053]
数据压缩模块,所述数据压缩模块用于对所述历史用电数据进行数据压缩处理,得到压缩后的用电数据;
[0054]
数据传输模块,所述数据传输模块用于将所述压缩后的用电数据传输至数据识别处理模块;
[0055]
数据识别处理模块,所述数据识别处理模块用于根据所述压缩后的用电数据,利用基于密度的聚类算法,对所述历史用电数据中的异常用电进行识别,得到识别结果。
[0056]
本发明具有以下有益效果:
[0057]
1.本发明基于云边协同计算架构,相比于集中式计算降低了数据传输的带宽占用,缓解了云端服务器的计算压力,提高了计算架构的整体性能。
[0058]
2.本发明采用分段加权dtw距离和滑动欧式距离对压缩数据的综合相似性进行度量,考虑了压缩数据整体和局部的特征,为异常识别准确性奠定了基础。
[0059]
3.本发明根据用电数据的特点,采用其统计特征和熵等多种判据作为分段依据,使数据的平稳段和波动段得到了不同压缩率的处理,保证了压缩数据的准确性。
附图说明
[0060]
图1为本发明所提供的异常用电识别系统的结构示意图。
具体实施方式
[0061]
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
[0062]
实施例1
[0063]
本发明提供一种异常用电识别方法,所述异常用电识别方法包括:
[0064]
采集历史用电数据;
[0065]
对所述历史用电数据进行数据压缩处理,得到压缩后的用电数据;
[0066]
根据所述压缩后的用电数据,利用基于密度的聚类算法,对所述历史用电数据中的异常用电进行识别,得到识别结果。
[0067]
本发明还提供一种异常用电识别方法,其应用于边缘端,所述异常用电识别方法包括:
[0068]
对历史用电数据进行数据处理操作,得到新的用电数据,其中,所述历史用电数据包括多个历史用电子数据,所述新的用电数据包括多个与所述历史用电子数据一一对应的新的用电子数据;
[0069]
计算每个所述历史用电子数据的阈值;
[0070]
根据多个所述历史用电子数据的阈值和多个所述新的用电子数据,对所述历史用电数据进行分段处理,得到分段处理结果;
[0071]
计算每段处理结果的平均值,得到计算结果;
[0072]
根据所述计算结果,得到压缩数据序列;
[0073]
根据所述压缩数据序列,得到所述压缩后的历史用电数据。
[0074]
可选择地,所述对所述历史用电数据进行数据处理操作包括:
[0075]
对所述历史用电数据中的每个历史用电子数据进行差分运算操作,得到差分运算后的用电数据;
[0076]
取所述差分运算后的用电数据的绝对值,得到所述新的用电数据。
[0077]
可选择地,所述计算每个所述历史用电子数据的阈值包括:
[0078]
将目标历史用电子数据的目标范围内的值作为所述目标用电子数据的阈值的计算窗口;
[0079]
根据所述目标用电子数据的阈值的计算窗口,得到所述目标历史用电子数据的阈值。
[0080]
可选择地,所述目标历史用电子数据的阈值的计算方式为:
[0081][0082]
其中,thj表示x
j+1
相对于xj允许的最大变化量,μ表示计算窗口中数据的平均值,σ表示计算窗口中数据的标准差,pj为能量比率,且ej和e
t
分别为计算窗口中信号
的能量和整个信号的总能量,且的能量和整个信号的总能量,且cnt表示常数,xj表示历史数据中第j个历史子数据。
[0083]
可选择地,所述根据多个所述历史用电子数据的阈值和多个所述新的用电子数据,对所述历史用电数据进行分段处理,得到分段处理结果包括:
[0084]
若当前所述新的用电子数据大于与当前所述新的用电子数据对应的历史用电子数据的阈值,则将该历史用电子数据作为分段点;
[0085]
利用所述分段点对所述历史用电数据进行分段,得到多段历史用电数据;
[0086]
将多段所述历史用电数据作为分段处理结果输出。
[0087]
本发明还提供一种异常用电识别方法,其应用于云端,所述异常用电识别方法包括:
[0088]
获取压缩后的用电数据中的压缩数据序列;
[0089]
计算多个所述压缩数据序列间的分段加权dtw距离和滑动欧式距离,得到第一距离计算结果和第二距离计算结果;
[0090]
根据所述第一距离计算结果和所述第二距离计算结果,得到综合相似度;
[0091]
根据所述综合相似度,利用基于密度的聚类算法,对所述历史用电数据中的异常用电进行识别,得到识别结果。
[0092]
可选择地,所述分段加权dtw距离为:
[0093]
dtw(a,b)=d(m,n)
[0094]
其中,dtw(a,b)表示压缩数据序列a和压缩数据序列b之间的分段加权dtw距离;a和b分别表示压缩数据序列a和压缩数据序列b,d(m,n)表示累积距离矩阵的第m行n列的值,d是m
×
n的距离矩阵;
[0095]
所述滑动欧式距离为:
[0096][0097]
其中,ed(a,b)表示压缩数据序列a和压缩数据序列b之间的滑动欧式距离,ak和bk分别表示压缩数据序列a和压缩数据序列b中第k个元素ak和第k个元素bk,m表示压缩数据序列和压缩数据序列中长度更短的那一个。
[0098]
所述综合相似度为:
[0099]
s(a,b)=α
·
dtw(a,b)+β
·
ed(a,b)
[0100]
其中,s(a,b)表示综合相似度,α和β分别为加权dtw距离和滑动欧式距离的权重,dtw(a,b)表示压缩数据序列a和压缩数据序列b之间的分段加权dtw距离,ed(a,b)表示压缩数据序列a和压缩数据序列b之间的滑动欧式距离。
[0101]
可选择地,所述根据所述综合相似度,利用基于密度的聚类算法,对所述历史用电数据中的异常用电进行识别,得到识别结果包括:
[0102]
根据所述综合相似度,得到综合相似度矩阵;
[0103]
根据所述综合相似度矩阵的行数,得到最小聚类点数;
[0104]
对所述综合相似度矩阵中每行元素进行排序,得到排序后的每行元素;
[0105]
取排序后的每行元素中所述最小聚类点数值所在列的所有数据,并对其进行最大最小值归一化处理,得到处理结果;
[0106]
根据所述处理结果绘制曲线;
[0107]
若所述曲线中目标点与其相邻点间的变化量大于预设阈值,则将满足该条件的第一个所述目标点处理之前的值作为邻域半径;
[0108]
将所述邻域半径、所述最小聚类点数和所述相似度矩阵输入所述基于密度的聚类算法中进行识别,得到识别结果。
[0109]
基于上述技术方案,本发明还提供一种异常用电识别系统,所述异常用电识别系统利用上述的异常用电识别方法,并且,所述异常用电识别系统包括:
[0110]
数据采集模块,所述数据采集模块用于采集历史用电数据;
[0111]
数据压缩模块,所述数据压缩模块用于对所述历史用电数据进行数据压缩处理,得到压缩后的用电数据;
[0112]
数据传输模块,所述数据传输模块用于将所述压缩后的用电数据传输至数据识别处理模块;
[0113]
数据识别处理模块,所述数据识别处理模块用于根据所述压缩后的用电数据,利用基于密度的聚类算法,对所述历史用电数据中的异常用电进行识别,得到识别结果。
[0114]
本发明具有以下技术效果:
[0115]
1、本发明考虑了高采样率的用电数据对集中式的异常用电识别方法计算效率和传输带宽上的负面影响,为此,基于本发明所提供的异常用电识别系统,根据边缘端和云端的算力差异和传输限制,本发明将计算量较小的数据压缩模块部署在边缘端,且边缘端仅将压缩后的数据上传至云端,这将极大地减少带宽占用。而云端则根据压缩数据的相似度识别异常,由于数据长度减小,这也将释放云端的部分算力,提高协同计算架构整体的性能。
[0116]
2、本发明考虑了传统数据压缩方法固定压缩率对信息准确性造成的影响。由于用电曲线中大部分波形较为平稳,反而是少部分波动较大的信号段包含较多信息,因此对其中波动剧烈的数据段,如果直接进行等压缩率的处理会丢失许多重要的特征信息,无法实现用电信息的动态表达,这将直接影响后续云端的异常识别结果。本发明对压缩方法的分段策略进行改进,让其依据数据自身的统计特征选取分段窗口长度,动态调整压缩率,如平稳段的压缩率变大,而波动段的压缩率变小,甚至直接将其保留,使用电数据的信息得到动态的表达。
[0117]
3、本发明考虑了异常识别算法对相似性度量准确性的依赖,为此,基于分段加权dtw距离和滑动欧式距离计算数据的综合相似度,考虑了压缩数据的整体和局部特征,提高了相似性度量的准确性。
[0118]
实施例2
[0119]
由于电网中各种仪表的采样率不断提高,使得电力企业能掌握到的用户用电数据更为精细,然而这些高精度的数据对算力提出了更高的要求。为了节约计算资源,需要先对数据进行压缩。
[0120]
对于历史用电数据x={x1,x2,
…
,xn},先对其作差分运算并取绝对值得到新的用电数据x'={x'1,x'2,
…
,x'
n-1
},其中,x'
n-1
=|x
n-x
n-1
|。
[0121]
历史用电数据x中的每个值xj,取其前k个和后k个值作为一个该值的阈值计算窗口,阈值计算方式为:
[0122][0123]
其中,thj表示x
j+1
相对于xj允许的最大变化量,μ表示计算窗口中数据的平均值,σ表示计算窗口中数据的标准差,pj为能量比率,且ej和e
t
分别为计算窗口中信号的能量和整个信号的总能量,且的能量和整个信号的总能量,且cnt表示常数,xj表示历史数据中第j个历史子数据。
[0124]
由于和pj都没有量纲,因此引入常数cnt,用以校正th的数量级,使之与x'j相匹配。同时也可以通过控制这个参数的大小,来得到最匹配边缘服务器算力的数据量。
[0125]
在进行分段加权dtw距离的计算过程中:
[0126]
首先,设两个经过压缩的压缩数据序列a={a1,a2,
…
,am}和压缩数据序列b={b1,b2,
…
,bn},其中的元素ai和bj实际上是两个分段的数据取平均得来的,且式中a
is
和b
jt
分别为ai和bj所对应的数据分段元素。ai和bj代表了分段的信息,相当于分段内的点取相同的权值得到的综合数据点,其包含了曲线的局部特征信息。
[0127]
他们的长度分别为m和n,先构造一个m
×
n的初始距离矩阵m:
[0128][0129]
式中d(ai,bj)表示ai和bj两个点之间的距离,通常采用欧式距离,即
[0130]
其次,在初始距离矩阵m中找到一条满足边界条件和单调性的压缩数据序列a和压缩数据序列b之间的对齐路径p={p1,p2,
…
,pk},式中p1=(1,1),pk=(m,n),pk为路径中第k个点的坐标,且max(m,n)≤k≤m+n-1;若p
t
=(i,j),则p
t+1
只能是(i+1,j),(i,j+1),(i+1,j+1)这三种情况之一。
[0131]
之后,根据初始距离矩阵m和上述的路径形成规则,通过递归法计算累积距离矩阵d的元素
[0132][0133]
式中d(i,j)表示矩阵m中的d(a1,b1)到d(ai,bj)的最小累积距离。
[0134]
最后,压缩数据序列a和压缩数据序列b之间的分段加权dtw距离为:
[0135]
dtw(a,b)=d(m,n)
[0136]
其中,dtw(a,b)表示压缩数据序列a和压缩数据序列b之间的分段加权dtw距离;a和b分别表示压缩数据序列a和压缩数据序列b,d(m,n)表示累积距离矩阵的第m行n列的值,d是m
×
n的距离矩阵;
[0137]
将压缩数据序列a的第一个数据和压缩数据序列b第一个数据对齐后计算欧式距离,假设压缩数据序列a的长度小于压缩数据序列b的长度,则其两者间的滑动欧式距离为:
[0138][0139]
其中,ed(a,b)表示压缩数据序列a和压缩数据序列b之间的滑动欧式距离,ak和bk分别表示压缩数据序列a和压缩数据序列b中第k个元素ak和第k个元素bk,m表示压缩数据序列和压缩数据序列中长度更短的那一个。
[0140]
之后将压缩数据序列a的第一个数据和压缩数据序列b第一个数据对齐后计算对应的欧式距离,直到压缩数据序列a的所有数据和压缩数据序列b的所有数据均计算过欧式距离,则输出所有数值中的最小值,作为两条数据之间的滑动欧式距离。
[0141]
结合分段加权dtw距离和滑动欧式距离计算综合相似度矩阵,则综合相似度为:
[0142]
s(a,b)=α
·
dtw(a,b)+β
·
ed(a,b)
[0143]
其中,s(a,b)表示综合相似度,α和β分别为加权dtw距离和滑动欧式距离的权重,dtw(a,b)表示压缩数据序列a和压缩数据序列b之间的分段加权dtw距离,ed(a,b)表示压缩数据序列a和压缩数据序列b之间的滑动欧式距离。
[0144]
之后,利用综合相似度矩阵,利用dbscan算法,对历史用电数据中的异常用电数据进行识别,具体包括:
[0145]
①
若输入算法的样本数,即综合相似度矩阵s的行数为n,那么最小聚类点数一般取
[0146]
②
将相似度矩阵s的每行按照升序排序后取出第minpts列,先将该列进行最大最小值归一化,然后按照升序绘制曲线。
[0147]
③
若曲线相邻两点间的变化量δ》0.1,则将该第一个满足条件的点归一化前的值作为邻域半径eps。
[0148]
④
将两个参数和相似度矩阵输入dbscan算法中,dbscan识别的异常点即为本发明识别出的异常用电数据。
[0149]
基于上述技术方案,同时鉴于如今用电数据的采样率普遍较高,采用集中式的异常识别方法势必给数据传输带宽和服务器算力造成巨大的压力,而云边协同的方式能利用大量的边缘服务器预处理冗余数据,节约了数据传输带宽和云端服务器算力,可极大地提升系统性能。因此本发明的异常用电识别系统包括数据采集模块、数据压缩模块、数据传输模块和数据处理识别模块,具体参考图1,数据采集模块选择较为常见的智能电表,数据压缩模块采用边缘节点,数据传输模块选用通信传输线,数据处理识别模块包括云端的相似性度量和云端的异常识别组成。
[0150]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和
原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1