一种基于改进Transformer的运动员能力预测方法
一种基于改进transformer的运动员能力预测方法
技术领域
1.本发明涉及运动员能力预测领域,尤其涉及一种基于改进transformer的运动员能力预测方法。
背景技术:
2.近年来,中国体育发展迅速。全民体育,全民健身的热潮不断掀起,竞技体育逐渐创新发展,大众对体育的认知也在不断加深与更新,体育产业迎来了一个飞速发展的时代。回顾中国体育事业的发展,体育科技借助大数据,为我国制定体育政策,建立科研机构,培养人才以及取得科技成果发挥着不可替代的作用。通过科学的运动能力预测手段来发现运动人才,是从根本上提高我国竞技体育水平的重要途径。除此之外,运动员能力预测使运动科学家、教练和运动员能够客观地分析运动员的实际工作能力,在规划训练和调整比赛策略中具有至关重要的作用。
3.国内外学者针对运动员能力预测的研究主要包括预测模型的选择与改进。anderson t w等以一组高年级女生的运动能力预测为例提出一种静态计算模型,为了确定预测运动能力的最佳组合和权重,通过对现有的、不同的运动指标加权平均来进行计算。然而指标筛选较为麻烦且静态模型不能很好地学习指标之间相对关系,从而对下一次成绩作出预测。孙毅等结合实例介绍灰色多变量预测模型在运动员竞技能力系统发展中的建模、预测方法,并通过与单因素模型的实际对比,阐述灰色多变量预测模型的实用价值和应用前提。实验结果表明,相比只考虑某一特征参数的单因素模型,灰色多变量模型预测精度明显要高。然而灰色多变量模型的使用前提是各因素之间必须存在较强的耦合关系,因此在进行预测时,如果所选变量不当,会导致参数失真,影响实验效果。vroonen r等以篮球运动员和棒球运动员能力预测为例,开发出预测系统来预测球员未来的能力,比如美国职业棒球大联盟的pecota系统和美国国家篮球协会的carmelo系统,通过搜索历史数据库来识别与目标球员年龄相似的其他球员,从而预测目标球员的潜力。再根据观察到的识别出的相似玩家的能力变化来预测目标玩家的能力变化。然而这些系统使用的模型都存在冷启动问题,即如果系统中不存在和目标球员相似球员的成绩,而导致模型无法预测的问题。yijie z等以中国篮球运动员能力预测为例,采用em(最大期望算法)学习各队的球员能力,根据综合比赛结果评估球员的能力值。此模型是基于团队中运动员相互影响,描述的不是球员的运动能力,而是球员在目前环境下所展现的球场作用,但一场比赛中阵容轮换纷繁复杂,使得很多对阵的回合数少之又少,很难获得符合模型条件的输入数据。
技术实现要素:
4.为了解决上述现有技术中存在的问题,本发明提供一种基于改进transformer的运动员能力预测方法,在现有运动员能力数据稀疏的约束情况下,提出改进transformer模型能够得到准确的运动员能力预测值,使该预测方法能够很好地适用于稀疏数据预测模型。
5.技术方案如下:
6.一种基于改进transformer的运动员能力预测方法,其中,运动员能力数据集包括该运动员成绩及取得该成绩的时间,其特征在于,包括以下步骤:
7.步骤1:运用滑动窗口平移方法将原始数据处理成适用于监督学习的时序数据;
8.步骤2:将预处理完的运动员成绩集合随机等分成5份,抽取其中3份形成训练集,1份作为验证集,剩下1份作为测试集;
9.步骤3:将训练集输入改进transformer模型;
10.步骤4:将训练集上的均方误差为损失函数进行优化,并进行迭代,使用早停函数在验证集上均方误差的损失验证防止过拟合,然后在测试集上检测模型预测效果,若满足早停函数条件则跳出循环。
11.进一步的,步骤1中,采用移动拼接的方法将原始运动员数据改为适用于监督学习的数据。
12.进一步的,步骤1包括以下具体步骤:
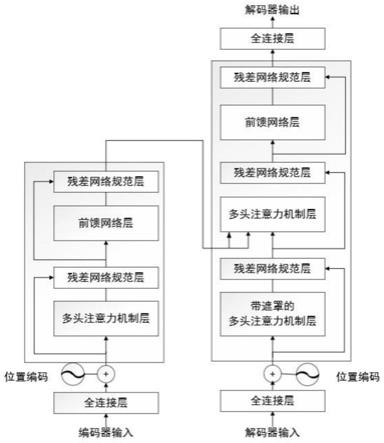
13.(1)每一个运动员的n次成绩在滑动窗口平移后可以得到f个l
×
(n-f)维的横向特征向量,其中l表示运动员成绩特征数量;
14.(2)拼接得到横向特征向量的集合,即运动员成绩矩阵
15.进一步的,其中步骤2包括以下具体步骤:
16.将滑动窗口平移产生的数据集随机划分成5等份,抽取其中3份形成训练集tri用以训练模型,1份形成验证集vai用来作为早停函数的损失验证以防止模型过拟合,剩下1份形成测试集tei以检测模型预测效果。
17.进一步的,步骤3中,对transformer结构进行再设计,第一个改进是编码层的嵌入层:输入层通过一个全连接层将输入的nba运动员能力的时间序列数据映射到向量;第二个改进是输出层:设置一个输出层,映射解码器的输出到目标时间序列。
18.进一步的,步骤3包括以下具体步骤:
19.(1)将训练集tri首先输入全连接层将数据映射成符合模型的输入,然后将其输入编码器层,进行位置编码pe得到各个成绩之间的相对位置关系:
[0020][0021]
其中pe表示二维矩阵的位置编码,每行表示运动员成绩,每列表示运动员各成绩指标;pos表示运动员数据在序列中的位置,i表示指标位置,dmodel表示运动员成绩指标个数;
[0022]
(2)对于得到的位置编码信息和原始特征向量进行连接,然后再通过多头注意力机制层multi-head attention在不同位置共同注意来自不同表征子空间的信息:
[0023]
[0024][0025][0026]
其中multihead表示多头注意力,q表示查询矩阵,k表示键矩阵,v表示值矩阵,headi表示第i个不同注意力头,concat(.)表示将不同的注意力头的输出进行拼接,wo表示附加的权重矩阵,attention(.)表示计算注意力,w
iq
表示查询矩阵q投影到低维空间上的权重矩阵,w
ik
表示键矩阵k投影到低维空间上的权重矩阵,w
iv
表示值矩阵v投影到低维空间上的权重矩阵,softmax(.)表示归一化指数函数,k
t
表示对键矩阵k进行转置,dk表示键矩阵的维度,zi表示矩阵中行向量;
[0027]
(3)然后输入残差网络规范层进行残差连接,将上一层输入结果和输入值相加和层归一化:
[0028]
layernorm(x+sublayer(x))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0029]
其中layernorm(.)表示层归一化,x表示输入值,sublayer(.)表得到上一层的输出结果;
[0030]
(4)将上述输出结果输入前馈网络层进行前馈连接:
[0031]
ffn(x)=max(0,xw1+b1)w2+b2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0032]
其中ffn(.)表示进行前馈连接,max(.)表示取最大值的函数,w1表示第一层的权重矩阵,b1表示第一层的偏置向量,w2表示第二层的权重矩阵,b2表示第二层的偏置向量;
[0033]
(5)将其进行残差连接并输出为查询矩阵q和键矩阵k,然后输入解码器层,解码器层中:增加了一个子层,将编码器层的输出当做输入;修改编码器栈的自注意力层,来防止预测时当前位置关注后续位置的值,从而造成信息泄露。
[0034]
进一步的,步骤4包括以下具体步骤:
[0035]
将训练集上的均方误差为损失函数进行优化,使用早停函数在验证集上vai均方误差的损失验证防止过拟合,然后在测试集tei上检测模型预测效果;
[0036][0037]
其中mse(.)表示求均方误差,y表示真实值,y'表示预测值,n表示n个数据,yi表示第个真实值,yi'表示第i个预测值。
[0038]
本发明的有益效果是:
[0039]
本发明所述的基于改进transformer的运动员能力预测方法将运动员能力的时序数值移动拼接解决了运动员能力的次数不一致,神经网络无法有效预测的问题;经过改进的全连接层将运动员能力的时序数值映射到向量进行下一步操作,然后设置的输出层将经过处理的输出映射到目标时间序列,提高了处理效率。
附图说明
[0040]
以下通过附图及具体实施例对本发明进行详细说明:
[0041]
图1是本发明实验流程示意图;
[0042]
图2是本发明提出的改进transformer结构图;
[0043]
图3是本发明在nba篮球运动员能力预测的mse比较图。
具体实施方式
[0044]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。下面结合附图1-3对基于改进transformer的运动员能力预测方法做进一步说明。
[0045]
实施例1
[0046]
步骤1:运用滑动窗口平移方法将原始数据处理成适用于监督学习的横向特征向量拼接的集合;
[0047]
步骤2:基于步骤1,将预处理完的运动员成绩集合随机等分成5份,抽取其中3份形成训练集tri,1份作为验证集vai,剩下1份作为测试集tei;
[0048]
步骤3:基于步骤2,将训练集tri输入改进transformer模型,进行模型训练:
[0049]
步骤4:基于步骤3,将训练集在上述模型的均方误差(mse)为损失函数进行梯度优化,并进行迭代,使用早停函数在验证集vai上的均方误差的损失验证防止过拟合,然后在测试集tei上检测模型预测效果,若满足早停函数条件则跳出循环。
[0050]
其中步骤1中,为了将数据适用于模型输入,采用移动拼接的方法将原始运动员数据改为适用于监督学习的数据。包括以下具体步骤:
[0051]
(1)每一个运动员的n次成绩在经过滑动窗口f平移后,可以得到f个l
×
(n-f)维的横向特征向量;其中l表示运动员成绩特征数量,l在本例中数值是8。
[0052]
(2)拼接得到的集合,即第i个运动员成绩矩阵
[0053]
其中步骤2包括以下具体步骤:
[0054]
(1)将滑动窗口平移产生的数据集随机划分成5等份抽取其中3份形成训练集tri用以训练模型,1份形成验证集vai用来作为早停函数的损失验证以防止模型过拟合,剩下1份形成测试集tei以检测模型预测效果。
[0055]
为了将transformer结构用于时序数据预测,本发明对transformer结构进行再设计。第一个改进是编码层的嵌入层。在传统模型中,嵌入层把输入的文本编码成长度一致的向量,方便后续处理。而在做预测时,nba运动员的能力已经用数值表示,输入层只需通过一个全连接层将输入的nba运动员能力的时间序列数据映射到向量。第二个改进是输出层。在传统模型中,使用softmax来产生下一个token时给定词汇表中每个单词的概率,这意味着传统的transformer结构只能用作分类工具。因此,在nba运动员能力预测时,最后设置一个输出层,映射解码器的输出到目标时间序列。
[0056]
其中步骤3包括以下具体步骤
[0057]
(1)将上述产生的训练集tri首先输入全连接层将数据映射成符合模型的输入,然后将其输入编码器层,进行位置编码pe得到各个成绩之间的相对位置关系:
[0058][0059]
其中pe表示二维矩阵的位置编码,大小跟输入的矩阵的维度一样,每行表示运动员成绩,每列表示运动员各成绩指标;pos表示运动员数据在序列中的位置,i表示指标位置,dmodel表示运动员成绩指标个数。
[0060]
(2)对于得到的位置编码信息和原始特征向量进行连接,然后再通过多头注意力机制层multi-head attention在不同位置共同注意来自不同表征子空间的信息:
[0061][0062][0063][0064]
其中multihead表示多头注意力,q表示查询矩阵,k表示键矩阵,v表示值矩阵,headi表示第i个不同注意力头,concat(.)表示将不同的注意力头的输出进行拼接,wo表示附加的权重矩阵,attention(.)表示计算注意力,w
iq
表示查询矩阵q投影到低维空间上的权重矩阵,w
ik
表示键矩阵k投影到低维空间上的权重矩阵,w
iv
表示值矩阵v投影到低维空间上的权重矩阵,softmax(.)表示归一化指数函数,k
t
表示对键矩阵k进行转置,dk表示键矩阵的维度,zi表示矩阵中行向量;
[0065]
(3)然后输入残差网络规范层进行残差连接,将上一层输入结果和输入值相加和层归一化:
[0066]
layernorm(x+sublayer(x))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0067]
其中layernorm(.)表示层归一化,x表示输入值,sublayer(.)表得到上一层的输出结果。
[0068]
(4)将上述输出结果输入前馈网络层进行前馈连接:
[0069]
ffn(x)=max(0,xw1+b1)w2+b2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0070]
其中ffn(.)表示进行前馈连接,max(.)表示取最大值的函数,w1表示第一层的权重矩阵,b1表示第一层的偏置向量,w2表示第二层的权重矩阵,b2表示第二层的偏置向量;
[0071]
(5)将其进行残差连接并输出为查询矩阵q和键矩阵k,然后输入解码器层,解码器层和编码器层最主要有两个区别:增加了一个子层,将编码器层的输出当做输入;修改了编码器栈的自注意力层,来防止预测时当前位置关注后续位置的值,从而造成信息泄露。
[0072]
其中步骤4包括以下具体步骤:
[0073]
(1)将训练集上的均方误差(mse)为损失函数进行优化,使用早停函数在验证集上vai均方误差的损失验证防止过拟合,然后在测试集tei上检测模型预测效果;
[0074][0075]
其中mse(.)表示求均方误差,y表示真实值,y'表示预测值,n表示n个数据,yi表示第个真实值,yi'表示第i个预测值;
[0076]
为了将transformer结构用于时序数据预测,对transformer结构进行再设计。第一个改进是编码层的嵌入层。在传统模型中,嵌入层把输入的文本编码成长度一致的向量,方便后续处理。而在做预测时,运动员的能力已经用数值表示,输入层只需通过一个全连接层将输入的运动员能力的时间序列数据映射到向量。第二个改进是输出层。在传统模型中,使用softmax来产生下一个token时给定词汇表中每个单词的概率,这意味着传统的transformer结构只能用作分类工具。因此,在运动员能力预测时,最后设置一个输出层,映射解码器的输出到目标时间序列。
[0077]
实施例2
[0078]
参见图1,为本发明的流程图。为实现本发明的基于改进transformer的运动员能力预测的目的:首先,获取nba篮球运动员数据库,将所有数据输入滑动窗口平移然后进行拼接:其次,将滑动窗口平移处理过的数据集进行随机划分处理;然后,将得到的训练集输入改进transformer模型进行迭代训练;最后根据模型产生的预测值在早停函数上的表现决定要不要终止迭代。
[0079]
以下结合实施例和附图对本发明做详细的说明:
[0080]
本发明的实验数据来自lee richardson收集的nba数据集。此数据集其中有每个赛季每个球员的50个个人统计数据,这个数据集中有7139个比赛。在篮球参考网站获得更先进的统计数据,例如广泛使用的玩家效率评级(per),相比之下,espn提供的只是box scores(盒装得分)的统计数据。使用的最后一个来源是jeremias engleman整理的正则化修正正负值(rapm)数据。从上述三个网站共获得包含3682个运动员在内的22800条数据,每条数据由58个指标组成。
[0081]
本发明采用的改进transformer模型,它是用传统用于nlp(自然语言处理)领域的transformer做改进,共有2层,用以运动员能力数值趋势。
[0082]
本发明实验的具体实施过程如下:
[0083]
步骤一:首先排除指标构成上述58个指标中前8个与运动员成绩无直接关联的指标,然后将剩下的50个指标作为预测指标,由步骤一得知,我们获取移动拼接层预处理完的适用于监督学习的数据。
[0084]
步骤二:移动拼接层预处理得到的数据大小都为(n-3)
×3×
50,其中n表示运动员成绩次数(每个运动成绩不一致)的所有横向特征矩阵作为输入样本,生成训练集、测试集、验证集,由步骤二可知,数据集等分成5份,随机3份形成训练集tri,1份作为验证集vai,剩下1份作为验证集tei,随机抽取10次,由此在运动员运动成绩子集中形成10组训练集、测试集和验证集,并产生10次预测结果。
[0085]
步骤三:将训练集tri分别输入改进transformer,如图2所示,mlp(多层感知机)pr(多项式回归)如公式8所示,由步骤三可知,三个模型同时处理运动员成绩输入:
[0086]
pr=β0+β1x+β2x2+β3x3+
…
+βnxn+ε
ꢀꢀꢀ
(8)
[0087]
其中pr表示多项式回归结果,β表示系数,x表示输入,n表示多项式次数,ε表示偏差;
[0088]
步骤四:根据步骤二和三将训练集上的均方误差(mse)为损失函数进行梯度优化,并进行迭代,使用早停函数在验证集vai上均方误差的损失验证防止过拟合,然后在测试集tei上检测模型预测效果,若满足早停函数条件则跳出循环。比较上述三个模型的预测结果如图3所示。
[0089]
综上所述,本发明提出的基于改进transformer的运动员能力预测方法具有很好的预测效果。首先,移动平移方法使能力预测转化为监督学习问题,方便transformer模型学习预测,解决了传统模型冷启动问题,其次,transformer输入层的处理使其适用于时序数据预测,另外,加入的位置编码使得模型能够利用序列的顺序,可以并行处理提高了效率。
[0090]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1