无源域无监督域自适应车辆再识别方法
1.本发明属于机器学习、车辆再识别技术领域,尤其涉及一种无源域无监督域自适应车辆再识别方法。
背景技术:
2.目前大多数基于监督学习的车辆再识别方法都实现了较高的精度,但代价是极度依赖于有效的监督标签,无法很好拓展到无监督领域。为此,一些基于无监督的车辆再识别方法应运而生,这里着重强调一下无监督再识别任务与目前受关注的无监督预训练(unsupervised pre-training)任务存在的主要区别:(1)无监督预训练任务从网络随机初始化开始,而无监督再识别任务是从预训练好的网络开始;(2)无监督预训练的网络需要经过fine-tune才可以应用在下游任务上,而无监督再识别任务本身可以看作一个无监督的下游任务,经过训练好的网络可直接部署。无监督车辆再识别又分为无监督域自适应和完全无监督两个方向。
3.对于无监督域自适应任务和完全无监督任务来说,本质上是十分相似的,区别在于无监督域自适应方法额外需要一个具有标签的源域数据集,先利用源域数据对模型进行预训练,预训练完成后,不再使用源域数据,只使用无标签的目标域数据进行再次训练得到最终模型;而完全无监督的方法只需要用无标签的目标域数据进行训练即可。
4.目前在无监督车辆再识别任务中,无监督域自适应任务是当前最受关注的,而不依赖于源域数据的完全无监督任务则较少被研究。
5.目前,基于无监督域自适应的车辆再识别算法通常需要源域模型,然后再利用到有标签的源域数据和无标签的目标域数据进行一系列的微调,使得模型可以在目标域上也可以有着良好的表现。但是由于数据隐私性和安全性被科研工作人员日益重视,源域数据的获取变得不是那么容易,而源域模型的获取相对而言是容易。
6.在以往基于图片生成的无监督域自适应方法中,通常需要利用源域数据作为内容与风格指导,来促进目标域数据的风格向源域数据的风格进行迁移。
技术实现要素:
7.考虑到近年来,大多数基于监督学习的车辆再识别方法都实现了较高的精度,但却极度依赖于有效的监督标签,如何将一个车辆再识别模型部署到无标签的数据集上并实现较好的效果是一个巨大的难题。此外,由于数据安全性及私密性的限制,在实际应用当中源域数据的获取也存在较大的难度。
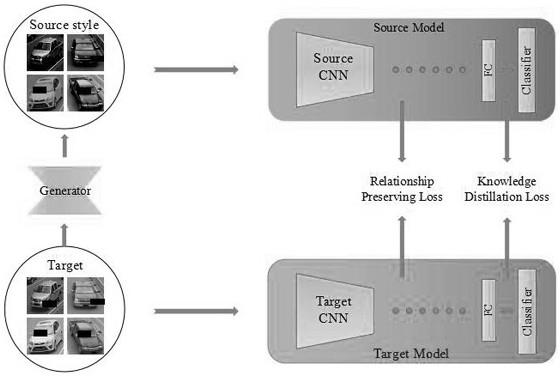
8.为了弥补现有技术的空白和不足,本发明提出一种无源域无监督域自适应车辆再识别方法。通过源域模型和目标域数据,利用关系保持一致损失和知识蒸馏损失训练一个生成器,目的是生成具有源域风格的伪目标样本,然后利用伪目标样本对模型进行微调,从而提升模型性能。其不再使用源域数据,而是利用隐含在源域模型中学习到的源域知识来作为指导,从而促进目标域数据的风格向源域数据的风格进行迁移。
9.与其他基于域迁移的无监督域自适应方法相比,本发明方法最大的优势是无需访问源域数据。
10.本发明具体采用以下技术方案:
11.一种无源域无监督域自适应车辆再识别方法,其特征在于:在车辆再识别过程中,通过源域模型和目标域数据,利用关系保持一致损失和知识蒸馏损失训练一个生成器,目的是生成具有源域风格的伪目标样本,然后利用伪目标样本对模型进行微调,从而提升模型性能。
12.进一步地,不使用源域数据,而是利用隐含在源域模型中学习到的源域知识来作为指导,从而促进目标域数据的风格向源域数据的风格进行迁移。
13.进一步地,运用合成图像,将合成图像通过spgan生成伪目标样本进行预训练,同时能够接收源域数据与目标域数据联合进行再次训练,进而完成无监督域自适应任务。
14.进一步地,通过合成图像设计两个网络模型用来学习车辆的方向相似度和背景相似度,再利用车辆id相似度减去方向相似度和相机相似度,以此来减小相似的方向和背景的对模型的干扰。
15.进一步地,源域模型通过公开的预训练模型或者利用公开的数据集以交叉熵损失和三元组损失预训练获取;目标域模型通过加载已获取的源域模型参数,在利用目标域数据微调获得。
16.进一步地,假设只有源模型中的特征提取器才适应于目标域;给定一个源模型fs(
·
)和一个目标模型f
t
(
·
),为无源知识迁移模块训练一个生成器;将目标图像设为x,给定生成的图像源模型输出所有源域数据的特征映射和概率分布为了描述生成的图像中所适应的知识,除了知识蒸馏损失外,还引入一种新的关系保持损失,其保持了目标图像目标模型特征图f
t
(x)与生成的图像源模型特征图之间的相对通道关系;
17.所述知识蒸馏损失为:在无源知识迁移模块中,将利用源模型和生成器的组合fs(g(
·
))描述目标模型f
t
(
·
)中适应的知识看做知识蒸馏的一种特殊情况;将源域数据和目标域数据之间的知识差异提取到生成器中;利用生成图像喂入源模型的输出和目标图像喂入目标模型的输出p(f
t
(x))构成知识蒸馏损失:
[0018][0019]
所述关系保持损失为:在经过成功的知识蒸馏之后,目标图像据通过目标模型所得到的全局特征和生成的源域风格图像通过源模型所得到的全局特征应当是相似的,因此利用关系保持损失进行约束;
[0020]
给定源域特征图和目标域特征图f
t
(x),首先对其进行重塑为特征向量fs和f
t
,
[0021][0022][0023]
其中,d、h、w分别为特征图深度(通道数)、高度和宽度;之后,计算它们的通道级自相关性,或格拉姆矩阵,
[0024][0025]
其中,gs,g
t
∈rd×d,并应用行l2归一化:
[0026][0027]
其中,[i,:]表示矩阵中的第i行;最后,将保持损失的关系定义为归一化格兰氏矩阵之间的均方误差mse:
[0028][0029]
总损失为:
[0030][0031]
通过这两个损失的约束,能够从目标图像中生成源风格的图像,以此用于模型的进一步微调,提升模型辨别能力。
[0032]
本发明及其优选方案提供了一种新的无源知识迁移的无监督域自适应车辆再识别框架。与其他基于域迁移的无监督域自适应方法相比,其最大的优势是无需访问源域数据。只需要获取源域数据训练的模型,之后利用无源知识迁移模块,就能够将隐含在源域模型当中的知识具象迁移到目标域数据上。
[0033]
与现有技术相比,本发明及其优选方案具有以下技术优势:
[0034]
1、现有的方法通常直接利用源域数据对模型进行预训练,在预训练之后不再使用源域数据,只使用目标域进行训练,这使得源域数据中的真实标签无法得到合理利用。
[0035]
本发明及其优选方案在车辆再识别领域运用合成图像,将合成图像通过spgan生成伪目标样本进行预训练,同时能够接收源域数据与目标域数据联合进行再次训练,进而完成无监督域自适应任务。
[0036]
2、现有的方法由于目标图像没有标注信息,对于一些因车辆方向或视角变化造成的干扰,都可能导致模型不能准确的进行辨别。
[0037]
本发明及其优选方案通过合成图像设计了两个网络模型用来学习车辆的方向相似度和背景相似度,再利用车辆id相似度减去方向相似度和相机相似度,以此来减小相似的方向和背景的对模型的干扰。
附图说明
[0038]
图1为本发明实施例整体方法流程示意图。
具体实施方式
[0039]
为让本专利的特征和优点能更明显易懂,下文特举实施例,作详细说明如下:
[0040]
如图1所示,本实施例提出的无源域无监督域自适应车辆再识别方法具体包括以下设计细节:
[0041]
(1)源域模型和目标域模型获取:源域模型可以通过下载公开的预训练模型或者利用公开的数据集以交叉熵损失和三元组损失预训练获取,而目标域模型通过加载已获取的源域模型参数,在利用目标域数据微调即可。
[0042]
(2)源域风格图像生成:根据现有的无监督域自适应工作原理,本实施例假设只有
源模型中的特征提取器才适应于目标域。给定一个源模型fs(
·
)和一个目标模型f
t
(
·
),本实施例为无源知识迁移模块训练一个生成器g(
·
)。由于训练过程是无源的,所以为了简单起见,本实施例在下面的内容中将目标图像称为x。
[0043]
给定生成的图像源模型输出所有源域数据的特征映射和概率分布为了描述生成的图像中所适应的知识,除了传统的知识蒸馏损失外,本实施例还引入了一种新的关系保持损失,它保持了目标图像目标模型特征图f
t
(x)与生成的图像源模型特征图之间的相对通道关系。
[0044]
知识蒸馏损失:在本实施例所提出的无源知识迁移模块中,利用源模型和生成器的组合fs(g(
·
))来描述目标模型f
t
(
·
)中适应的知识可以看做是知识蒸馏的一种特殊情况。本实施例的目的是将源域数据和目标域数据之间的知识差异提取到生成器中。在这种情况下,本实施例利用生成图像喂入源模型的输出和目标图像喂入目标模型的输出p(f
t
(x))构成知识蒸馏损失。
[0045][0046]
关系保持损失:在经过成功的知识蒸馏之后,本实施例可以想到目标图像据通过目标模型所得到的全局特征和生成的源域风格图像通过源模型所得到的全局特征应当是相似的,因此本实施例利用关系保持损失来进行约束。在特征图f
t
(x)和之间促进类似的通道级关系有助于实现这一目标。
[0047]
在以往的知识蒸馏工作通常是以保持批级或是像素级的关系来进行约束。然而种约束的方式并不适用于当前任务。首先,批级的关系无法很好地监督到每一张图像的生成任务,这将对生成的效果造成损害。而像素级的关系的有效性在经过全局池化之后也会大打折扣。与两者相比,通道级的关系是以每张图像作为基础来进行计算的,并且不会受到全局池化的影响。因此,通道级关系是更加适合用来计算关系保持损失。
[0048]
给定源域特征图和目标域特征图f
t
(x),本实施例首先需要对它进行重塑为特征向量fs和f
t
,
[0049][0050][0051]
其中,d、h、w分别为特征图深度(通道数)、高度和宽度。接下来,本实施例计算它们的通道级自相关性,或格拉姆矩阵,
[0052][0053]
其中,gs,g
t
∈rd×d。像其他知识蒸馏的相似性保持损失一样,本实施例应用行l2归一化,
[0054][0055]
其中,[i,:]表示矩阵中的第i行。最后,本实施例将保持损失的关系定义为归一化格兰氏矩阵之间的均方误差(mse),
[0056]
[0057]
总损失为:
[0058][0059]
通过这两个损失的约束,本实施例能够从目标图像中生成源风格的图像,以此用于模型的进一步微调,提升模型辨别能力。
[0060]
本专利不局限于上述最佳实施方式,任何人在本专利的启示下都可以得出其它各种形式的无源域无监督域自适应车辆再识别方法,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本专利的涵盖范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1