人工智能模型的处理方法、装置、设备及可读存储介质与流程
1.本技术涉及处理器技术领域,尤其涉及一种人工智能模型的处理方法、人工智能模型的处理装置、人工智能模型的处理设备、计算机可读存储介质以及计算机程序。
背景技术:
2.人工智能(artificial intelligence,ai)是利用数字计算机或者由数字计算机控制的机器,模拟、延伸和扩展人类的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术和应用系统。ai是当前热门的科学和世界发展的前沿技术,应用到生活中各种各样的场景中。
3.自动驾驶系统有大量的场景需要用到ai模型推理,ai模型基本上都是深度神经网络,神经网络是矩阵和矢量计算密集型,对算力要求很高(t级)。普通的cpu一般不能满足深度神经网络,也就是ai模型的海量计算的算力需求,因此需要用到专用的加速器来执行ai模型,比如专门定制的图形处理器(graphics processing unit,gpu)或神经网络处理器(network process unit,npu)等。
4.应用程序将ai模型加载到ai加速器,通过ai加速器对ai模型进行训练或推理(执行)。现有技术中的ai加速器遇到存在条件分支判断算子和循环算子的时候,由于ai加速器只能执行当前算子,不能根据当前算子的执行结果控制后面算子的执行;那么ai加速器需要将部分控制功能回落到主处理器上执行。因此,在对ai模型进行训练或推理的过程中,需要主处理器和ai加速器相互之间进行频繁的交互才能完成,造成模型推理或模型训练的性能不高。
技术实现要素:
5.本技术实施例提供一种人工智能模型的处理方法、人工智能模型的处理装置、人工智能模型的处理设备、计算机可读存储介质以及计算机程序,以提升模型推理或模型训练的性能。
6.第一方面,本技术实施例提供了一种人工智能模型的处理方法,应用于人工智能处理单元,该人工智能处理单元包括控制单元、运算逻辑单元以及存储单元,该方法包括:
7.该人工智能处理单元获取由处理器侧基于用户态接口(application programming interface,api)下发的ai模型;其中,该ai模型包括控制算子和计算算子,该api包括第一api,该第一api用于下发该控制算子;
8.该人工智能处理单元在训练或推理该ai模型的过程中,通过该运算逻辑单元执行该计算算子,并且该运算逻辑单元在执行该计算算子后,会将执行后的数据存储在该存储单元中;
9.该人工智能处理单元通过该控制单元基于该存储单元中的数据来执行该控制算子。
10.本技术实施例,通过设置用于下发控制算子的api,基于该api即可实现向人工智
能处理单元下发包括控制算子的ai模型,以使该人工智能处理单元在训练或推理该ai模型的过程中,通过在人工智能处理单元中设置存储单元,运算逻辑单元可以将执行算子或任务后的数据存储在该存储单元中,以便于控制单元可直接基于该存储单元中的数据来执行控制算子,从而实现了该控制单元可根据当前算子的执行结果控制后面算子的执行。实现了整个ai模型都在控制器和运算逻辑单元内执行,无需将部分控制功能返回主处理器处理;解决了现有技术中在对ai模型进行训练或推理的过程中,需要主处理器和ai加速器相互之间进行频繁的交互才能完成,造成模型推理或模型训练的性能不高的技术问题;提升了模型推理或模型训练的性能。
11.在一种可能的实现方式中,该存储单元包括第一存储单元和第二存储单元;上述将执行该计算算子后的数据存储在该存储单元中包括:将执行该计算算子后的数据存储在该第二存储单元中;
12.上述通过控制单元基于存储单元中的数据执行控制算子包括:通过控制单元读取该第二存储单元中的数据,然后将该第二存储单元中的数据写入该第一存储单元;那么在执行控制算子的时候,可以读取并基于该第一存储单元中的数据来执行该控制算子。
13.本技术实施例,通过在人工智能处理单元中设置第一存储单元和第二存储单元,该第二存储单元用于存储运算逻辑单元执行完算子或任务后的数据,并供控制单元读取到该第一存储单元,那么在执行控制算子的时候可直接基于该第一存储单元中的数据来执行控制算子,从而实现了该控制单元可根据当前算子的执行结果控制后面算子的执行。
14.在一种可能的实现方式中,该第一存储单元可集成在控制单元中,也就是说可以在控制单元中增加该第一存储单元,该第一存储单元可以为该控制单元的专用寄存器。该第二存储单元可集成在运算逻辑单元中,也就是说可以在运算逻辑单元中增加该第二存储单元,该第二存储单元可以为该运算逻辑单元的专用寄存器。可以进一步实现控制单元快速高效地读取到运算逻辑单元执行完算子或任务后的数据,从而可根据当前算子的执行结果控制后面算子的执行。实现了整个ai模型都在控制器和运算逻辑单元内执行,无需将部分控制功能返回主处理器处理。
15.其中,人工智能处理单元中每个运算逻辑单元都可增加第二存储单元(自身专用的寄存器),使得每一个运算逻辑单元都可用于配合控制单元来执行控制算子,从而可再进一步提高人工智能处理单元模型推理或模型训练的性能。
16.在一种可能的实现方式中,ai模型对应有至少一个执行序列,每个第一存储单元对应不同的执行序列。
17.本技术实施例中,处理器可以根据处理ai模型的数量,以及每个ai模型对应的执行序列的数量,实现定制化地设置控制单元中第一存储单元的数量。
18.在一种可能的实现方式中,该控制算子包括分支判断算子,其中该分支判断算子用于判断执行第一分支算子或第二分支算子;
19.上述读取并基于该第一存储单元中的数据执行该控制算子,包括:
20.读取该第一存储单元中的数据;
21.基于该第一存储单元中数据和该分支判断算子中的参数判断是否执行该第一分支算子;
22.若判断为是,则执行该第一分支算子;若判断为否,则执行该第二分支算子。
23.本技术实施例中控制算子可以包括分支判断算子,也就是说控制单元在执行下发的分支判断算子时可直接读取到分支判断需用到的数据,然后进一步下一算子或任务(第一分支算子或第二分支算子)。实现了整个ai模型都在控制单元和运算逻辑单元内执行,无需将部分控制功能返回主处理器处理。
24.在一种可能的实现方式中,该控制算子还包括循环算子,该循环算子用于循环执行所述ai模型的第一计算算子;上述执行该第一分支算子之后,还包括:执行该循环算子,以通过该运算逻辑单元跳转到ai模型的该第一计算算子的地方,从而循环执行该第一计算算子,以此循环迭代,直到下次基于该第一存储单元中数据和该分支判断算子中的参数判断是否执行该第一分支算子的判断结果为否时,结束该循环迭代,执行该第二分支算子。
25.本技术实施例中的ai模型还可以包括循环算子,执行该循环算子可以控制运算逻辑单元跳转到ai模型的该第一计算算子的地方,以循环执行该第一计算算子,从而实现了可以在控制单元内部可以直接执行ai模型中的分支判断算子和循环算子,无需与主处理器进行频繁的交互才能完成,解决了模型推理或模型训练的性能不高的技术问题;提升了模型推理或模型训练的性能。
26.在一种可能的实现方式中,该api还包括第二api和第三api,该第二api用于创建标签;该第三api用于设置标签在该ai模型中的位置;该ai模型还包括用于跳转的第一标签和第二标签;其中该第一标签放置在与该ai模型的第一计算算子相邻的上一个算子中,该第二标签放置在与该第二分支算子相邻的上一个算子中;
27.上述通过控制单元读取并基于该第一存储单元中的数据执行该控制算子之前,还包括:通过该运算逻辑单元执行该第一计算算子;
28.那么上述执行该循环算子,以通过该运算逻辑单元迭代执行该ai模型的计算算子,包括:执行该循环算子,跳转到该第一标签所在的位置,以通过该运算逻辑单元循环执行该第一计算算子;
29.上述若判断为否,则执行该第二分支算子,包括:若判断为否,则跳转到该第二标签所在的位置,以执行该第二分支算子。
30.本技术实施例中的ai模型还可以包括第一标签和第二标签,及其分别在ai模型中放置的位置;通过第一标签和第二标签的跳转,高效地实现分支判断算子后的算子,例如执行循环算子时的跳转。从而实现了可以在控制单元内部直接执行ai模型中的分支判断算子和循环算子,无需与主处理器进行频繁的交互才能完成,解决了模型推理或模型训练的性能不高的技术问题;提升了模型推理或模型训练的性能。
31.在一种可能的实现方式中,上述通过控制单元读取该第二存储单元中的数据之前,还包括:将该第二存储单元设置为无效值;
32.那么上述将该第二存储单元中的数据写入该第一存储单元,包括:在判断出读取的该第二存储单元的数据为有效值的情况下,将该第二存储单元的数据写入该第一存储单元中;若判断读取的该第二存储单元的数据为无效值,那么不将该第二存储单元的数据写入该第一存储单元中。
33.本技术实施例中,控制单元先设置运算逻辑单元的第二存储单元为无效值,后在判断读取的该第二存储单元的数据为有效值的情况下,才将该数据写入第一存储单元中,可很好地确保训练或推理ai模型的准确性。
34.第二方面,本技术提供一种人工智能模型的处理方法,该方法包括:
35.处理器(或称为主处理器)创建人工智能ai模型;该ai模型包括控制算子和计算算子;
36.基于api将该ai模型下发给人工智能处理单元;
37.其中,该api包括第一api,该第一api用于下发该控制算子;该人工智能处理单元用于在训练或推理该ai模型的过程中,执行该控制算子和该计算算子。
38.本技术实施例,通过设置用于下发控制算子的api,基于该api即可实现向人工智能处理单元下发包括控制算子的ai模型,以使该人工智能处理单元在训练或推理该ai模型的过程中,可独立执行该整个ai模型,无需将部分控制功能返回主处理器处理。解决了现有技术中在对ai模型进行训练或推理的过程中,需要主处理器和ai加速器相互之间进行频繁的交互才能完成,造成模型推理或模型训练的性能不高的技术问题;提升了模型推理或模型训练的性能。
39.在一种可能的实现方式中,该控制算子包括分支判断算子,该分支判断算子用于判断执行第一分支算子或第二分支算子。
40.本技术实施例,可以设置用于下发分支判断算子的api,那么向人工智能处理单元下发的ai模型,可以使得该人工智能处理单元在训练或推理该ai模型的过程中,可独立完成该分支判断算子的执行,无需与主处理器来回交互。
41.在一种可能的实现方式中,该控制算子还包括循环算子,该循环算子用于循环执行所述ai模型的第一计算算子;该api还包括第二api和第三api,该第二api用于创建标签;该第三api用于设置标签在所述ai模型中的位置。
42.在一种可能的实现方式中,该人工智能处理单元包括控制单元、运算逻辑单元以及存储单元。该ai模型中的计算算子是由人工智能处理单元中的控制单元调度给该运算逻辑单元来执行,并且每次执行完计算算子后,将执行后的数据存储在该存储单元中。以便该人工智能处理单元通过该控制单元基于该存储单元中的数据来执行该控制算子。
43.本技术实施例,还可以设置用于下发循环算子的api,那么向人工智能处理单元下发的ai模型,可以使得该人工智能处理单元在训练或推理该ai模型的过程中,可独立完成该循环算子的执行。并且该人工智能处理单元在执行循环算子的过程中,可通过用于创建标签的api以及用于设置标签在该ai模型中的位置的api进行相关跳转,从而可进一步快速高效地完成循环算子的执行。
44.第三方面,本技术提供一种人工智能模型的处理装置,该装置为人工智能处理单元,包括:
45.获取单元,用于获取由处理器侧基于api下发的ai模型;其中,该ai模型包括控制算子和计算算子,该ai模型为处理器基于api下发的ai模型;该api包括第一api,该第一api用于下发该控制算子;
46.第一执行单元,用于在训练或推理该ai模型的过程中,通过该人工智能处理单元的运算逻辑单元执行该计算算子;
47.存储处理单元,用于在该第一执行单元执行该计算算子后,将执行后的数据存储在该人工智能处理单元的存储单元中;
48.第二执行单元,用于通过该人工智能处理单元的控制单元,基于该存储单元中的
数据执行该控制算子。
49.在一种可能的实现方式中,该存储单元包括第一存储单元和第二存储单元;
50.该存储处理单元具体用于:将执行该计算算子后的数据存储在该第二存储单元中;
51.该第二执行单元包括:
52.第一读取单元,用于读取该第二存储单元中的数据;
53.第一写入单元,用于将该第二存储单元中的数据写入该第一存储单元;
54.读取执行单元,用于读取并基于该第一存储单元中的数据执行该控制算子。
55.在一种可能的实现方式中,该控制算子包括分支判断算子,其中该分支判断算子用于判断执行第一分支算子或第二分支算子;该读取执行单元包括:
56.第二读取单元,用于读取该第一存储单元中的数据;
57.判断单元,用于基于该第一存储单元中数据和该分支判断算子中的参数判断是否执行该第一分支算子;
58.判断处理单元,用于若该判断单元判断为是,则执行该第一分支算子;若该判断单元判断为否,则执行该第二分支算子。
59.在一种可能的实现方式中,该控制算子还包括循环算子,该循环算子用于循环执行该ai模型的第一计算算子;该处理装置还包括:
60.第三执行单元,用于在该判断处理单元执行该第一分支算子之后,执行该循环算子,以通过该运算逻辑单元跳转到ai模型的该第一计算算子的地方,从而循环执行该第一计算算子,以此循环迭代,直到下次判断单元基于该第一存储单元中数据和该分支判断算子中的参数判断是否执行该第一分支算子的判断结果为否时,结束该循环迭代,由该判断处理单元执行该第二分支算子。
61.在一种可能的实现方式中,该api还包括第二api和第三api,该第二api用于创建标签;该第三api用于设置标签在该ai模型中的位置;该ai模型还包括用于跳转的第一标签和第二标签;其中该第一标签放置在与该ai模型的第一计算算子相邻的上一个算子中,该第二标签放置在与该第二分支算子相邻的上一个算子中;该处理装置还包括:
62.第四执行单元,用于在该读取执行单元读取并基于该第一存储单元中的数据执行该控制算子之前,通过该运算逻辑单元执行该第一计算算子;
63.该第三执行单元具体用于:在该判断处理单元执行该第一分支算子之后,执行该循环算子,跳转到该第一标签所在的位置,以通过该运算逻辑单元循环执行该第一计算算子;
64.若该判断单元判断为否,该判断处理单元具体用于,跳转到该第二标签所在的位置,以执行该第二分支算子。
65.在一种可能的实现方式中,ai模型对应有至少一个执行序列,每个该第一存储单元对应不同的执行序列。
66.在一种可能的实现方式中,该处理装置还包括:
67.设置单元,用于在该第一读取单元读取该第二存储单元中的数据之前,将该第二存储单元设置为无效值;
68.该第一写入单元具体用于:在判断出读取的该第二存储单元的数据为有效值的情
况下,将该第二存储单元的数据写入该第一存储单元中;若判断读取的该第二存储单元的数据为无效值,那么不将该第二存储单元的数据写入该第一存储单元中。
69.第四方面,本技术提供一种人工智能模型的处理装置,该处理装置包括:
70.创建单元,用于创建ai模型;该ai模型包括控制算子和计算算子;
71.下发单元,用于基于api将该ai模型下发给人工智能处理单元;
72.其中,该api包括第一api,该第一api用于下发该控制算子;该人工智能处理单元用于在训练或推理该ai模型的过程中,执行该控制算子和该计算算子。
73.在一种可能的实现方式中,该控制算子包括分支判断算子,该分支判断算子用于判断执行第一分支算子或第二分支算子。
74.在一种可能的实现方式中,该控制算子还包括循环算子,该循环算子用于循环执行所述ai模型的第一计算算子;该api还包括第二api和第三api,该第二api用于创建标签;该第三api用于设置标签在所述ai模型中的位置。
75.第五方面,本技术提供了一种人工智能模型的处理设备,包括该人工智能处理单元和存储器;其中,该存储器用于存储程序代码,该人工智能处理单元调用该存储器存储的程序代码使得该人工智能模型的处理设备执行上述第一方面及其各种可能的实现方式中的方法。
76.第六方面,本技术提供了一种人工智能模型的处理设备,包括处理器和存储器;其中,该存储器用于存储程序代码,该处理器调用该存储器存储的程序代码使得该人工智能模型的处理设备执行上述第二方面及其各种可能的实现方式中的方法。
77.第七方面,本技术提供了一种人工智能模型的处理设备,包括处理器、人工智能处理单元和存储器;其中,该存储器可以包括多个,用于存储程序代码;该处理器与该人工智能处理单元耦合;该人工智能处理单元可以调用与自身耦合的存储器或调用自身内部的存储器存储的程序代码使得该人工智能模型的处理设备执行上述第一方面及其各种可能的实现方式中的方法。该处理器可以调用与自身耦合的存储器存储的程序代码使得该人工智能模型的处理设备执行上述第二方面及其各种可能的实现方式中的方法。
78.第八方面,本技术提供了一种计算机可读存储介质,该计算机可读存储介质存储有计算机程序,该计算机程序被处理器执行时实现上述第一方面或第二方面及其各个可能的实现方式的方法。
79.第九方面,本技术提供了一种计算机程序,该计算机可读程序包括指令,当该计算机程序被处理器执行时,使得该主处理器执行上述第一方面或第二方面及其各个可能的实现方式的方法。
附图说明
80.图1为本技术实施例提供的车辆100的功能框图。
81.图2为本技术实施例提供的ai计算架构的结构示意图。
82.图3为本技术实施例提供的人工智能模型的处理设备的结构示意图。
83.图4为本技术提供的另一实施例的人工智能模型的处理设备的结构示意图。
84.图5为本技术提供的另一实施例的人工智能模型的处理设备的结构示意图。
85.图6为本技术实施例提供的ai模型的循环语句的示意图。
86.图7为本技术实施例提供的ai模型中stream1的执行序列的示意图。
87.图8为本技术实施例提供的控制单元执行流程的示意图。
88.图9为本技术实施例提供的人工智能处理单元执行的原理示意图。
89.图10为本技术实施例提供的一种人工智能模型的处理装置的结构示意图。
90.图11为本技术提供的另一实施例的人工智能模型的处理装置的结构示意图。
91.图12为本技术实施例提供的一种人工智能模型的处理方法的流程示意图。
92.图13为本技术提供的另一种实施例的人工智能模型的处理方法的流程示意图。
93.图14为本技术实施例提供的计算机程序或计算机程序产品的概念性局部视图。
具体实施方式
94.下面将结合本技术实施例中的附图,对本技术实施例进行描述。本技术的说明书和权利要求书及该附图中的术语“第一”、“第二”、“第三”和“第四”等是用于区别不同对象,而不是用于描述特定顺序。此外,术语“包括”和“具有”以及它们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。在本文中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本技术的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本文所描述的实施例可以与其它实施例相结合。
95.在本说明书中使用的术语“部件”、“模块”、“系统”等用于表示计算机相关的实体、硬件、固件、硬件和软件的组合、软件、或执行中的软件。例如,部件可以是但不限于,在处理器上运行的进程、处理器、对象、可执行文件、执行线程、程序和/或计算机。通过图示,在计算设备上运行的应用和计算设备都可以是部件。一个或多个部件可驻留在进程和/或执行线程中,部件可位于一个计算机上和/或分布在2个或更多个计算机之间。此外,这些部件可从在上面存储有各种数据结构的各种计算机可读介质执行。部件可例如根据具有一个或多个数据分组(例如来自与本地系统、分布式系统和/或网络间的另一部件交互的二个部件的数据,例如通过信号与其它系统交互的互联网)的信号通过本地和/或远程进程来通信。
96.首先,对本技术中的部分用语进行解释说明,以便于本领域技术人员理解。
97.(1)寄存器,是中央处理器内的组成部份,它跟cpu有关。寄存器是有限存贮容量的高速存贮部件,它们可用来暂存指令、数据和位址。在中央处理器的控制部件中,包含的寄存器有指令寄存器(ir)和程序计数器(pc)。在中央处理器的算术及逻辑部件中,包含的寄存器有累加器(acc)。
98.(2)ai加速器,是一类专门的硬件加速器或计算机系统,旨在加速人工智能的应用,尤其是人工神经网络、机器视觉和机器学习。典型应用包括机器人技术,物联网和其他数据密集型或传感器驱动任务的算法。ai加速器作为一类专用于专用任务的硬件加速器,往往是对计算机系统中的主处理器的协助或补充,例如包括但不限于用于执行ai模型的专门定制的gpu或npu等。
99.(3)api,是一些预先定义的接口(如函数、http接口),或指软件系统不同组成部分
衔接的约定。用来提供应用程序与开发人员基于某软件或硬件得以访问的一组例程,而又无需访问源码,或理解内部工作机制的细节。
100.(4)runtime,是指一个程序在运行(cc或者在被执行)的状态,也就是说程序运行的时候。runtime库就是程序运行的时候所需要依赖的库。在一些编程语言中,把某些可以重用的程序或者实例打包或者重建成为runtime库。这些实例可以在它们运行的时候被链接或者被任何程序调用。本技术实施例的runtime库中提供了人工智能处理单元(例如gpu或npu)的api,例如包括用于生成并下发控制算子的api。
101.(5)执行序列,一个ai模型一般会拆分出多个stream,该stream即相当于执行序列。每个执行序列下有多个task(或称为算子,或task封装了一个算子),stream之间会有event进行同步。多个stream之间的task可以在人工智能处理单元上并行执行,stream内的task一般只能串行执行。本技术实施例中的算子或任务可以包括计算算子和控制算子等等,该计算算子可以用于数据计算,该控制算子可以用于控制执行序列的执行顺序。该算子或任务实质为ai模型中的代码,例如ai模型中的卷积代码就是一个算子或任务。也就是说,本技术实施例中的计算算子即为实现或完成数据计算的代码,通常在人工智能处理单元中的运算逻辑单元上运行,以完成数据计算任务。本技术实施例中的控制算子即为控制执行序列执行顺序的代码,可以通过人工智能处理单元中的控制单元来执行。
102.本技术实施例提供的人工智能模型的处理方法、人工智能模型的处理装置、人工智能模型的处理设备,可以针对需要用到ai加速器的所有应用场景,包括使用的卷积神经网络(convolutionalneuralnetworks,cnn)模型、或掩膜基于区域的卷积神经网络(mask region
‑
based cnn,mask rcnn)模型对摄像头的图片进行ai处理的场景,例如智能车场景中的自动驾驶领域,驾驶员监控、泊车、自动驾驶等场景。也可以包括使用循环神经网络(recurrent neural network,rnn)模型对数据进行ai处理的场景,例如智能车场景中汽车和驾驶员、车内乘客的语音交互的场景。
103.为了便于理解本技术实施例,进一步分析并提出本技术所具体要解决的技术问题。下面以车辆的自动驾驶场景为例进行说明:
104.首先结合图1示出的本技术实施例提供的车辆100的功能框图。在一个实施例中,将车辆100配置为完全或部分地自动驾驶模式。例如,车辆100可以在处于自动驾驶模式中的同时控制自身,并且可通过人为操作来确定车辆及其周边环境的当前状态,确定周边环境中的至少一个其他车辆的可能行为,并确定该其他车辆执行可能行为的可能性相对应的置信水平,基于所确定的信息来控制车辆100。在车辆100处于自动驾驶模式中时,可以将车辆100置为在没有和人交互的情况下操作。
105.车辆100可以为轿车、卡车、摩托车、公共汽车、船、飞机、直升飞机、割草机、娱乐车、游乐场车辆、施工设备、电车、高尔夫球车、火车、和手推车等,本技术实施例不做特别的限定。
106.车辆100可包括各种子系统,例如行进系统102、传感系统104、控制系统106、一个或多个外围设备108以及电源110、计算机系统112和用户接口116。可选地,车辆100可包括更多或更少的子系统,并且每个子系统可包括多个元件。另外,车辆100的每个子系统和元件可以通过有线或者无线互连。
107.行进系统102可包括为车辆100提供动力运动的组件。在一个实施例中,行进系统
102可包括引擎118、能量源119、传动装置120和车轮/轮胎121。引擎118可以是内燃引擎、电动机、空气压缩引擎或其他类型的引擎组合,例如汽油发动机和电动机组成的混动引擎,内燃引擎和空气压缩引擎组成的混动引擎。引擎118将能量源119转换成机械能量。
108.能量源119的示例包括汽油、柴油、其他基于石油的燃料、丙烷、其他基于压缩气体的燃料、乙醇、太阳能电池板、电池和其他电力来源。能量源119也可以为车辆100的其他系统提供能量。
109.传动装置120可以将来自引擎118的机械动力传送到车轮121。传动装置120可包括变速箱、差速器和驱动轴。在一个实施例中,传动装置120还可以包括其他器件,比如离合器。其中,驱动轴可包括可耦合到一个或多个车轮121的一个或多个轴。
110.传感系统104可包括感测关于车辆100周边的环境的信息的若干个传感器。例如,传感系统104可包括全球定位系统122(全球定位系统可以是gps系统,也可以是北斗系统或者其他定位系统)、惯性测量单元(inertialmeasurementunit,imu)124、雷达126、激光测距仪128以及相机130。传感系统104还可包括被监视车辆100的内部系统的传感器(例如,车内空气质量监测器、燃油量表、机油温度表等)。来自这些传感器中的一个或多个的传感器数据可用于检测对象及其相应特性(位置、形状、方向、速度等)。这种检测和识别是自主车辆100的安全操作的关键功能。
111.全球定位系统122可用于估计车辆100的地理位置。imu124用于基于惯性加速度来感测车辆100的位置和朝向变化。在一个实施例中,imu124可以是加速度计和陀螺仪的组合。
112.雷达126可利用无线电信号来感测车辆100的周边环境内的物体。在一些实施例中,除了感测物体以外,雷达126还可用于感测物体的速度和/或前进方向。
113.激光测距仪128可利用激光来感测车辆100所位于的环境中的物体。在一些实施例中,激光测距仪128可包括一个或多个激光源、激光扫描器以及一个或多个检测器,以及其他系统组件。
114.相机130可用于捕捉车辆100的周边环境的多个图像。相机130可以是静态相机或视频相机。
115.控制系统106为控制车辆100及其组件的操作。控制系统106可包括各种元件,其中包括转向系统132、油门134、制动单元136、传感器融合算法138、计算机视觉系统140、路线控制系统142以及障碍规避系统144。
116.转向系统132可操作来调整车辆100的前进方向。例如在一个实施例中可以为方向盘系统。
117.油门134用于控制引擎118的操作速度并进而控制车辆100的速度。
118.制动单元136用于控制车辆100减速。制动单元136可使用摩擦力来减慢车轮121。在其他实施例中,制动单元136可将车轮121的动能转换为电流。制动单元136也可采取其他形式来减慢车轮121转速从而控制车辆100的速度。
119.计算机视觉系统140可以操作来处理和分析由相机130捕捉的图像以便识别车辆100周边环境中的物体和/或特征。该物体和/或特征可包括交通信号、道路边界和障碍物。计算机视觉系统140可使用物体识别算法、运动中恢复结构(structurefrommotion,sfm)算法、视频跟踪和其他计算机视觉技术。在一些实施例中,计算机视觉系统140可以用于为环
境绘制地图、跟踪物体、估计物体的速度等等。
120.路线控制系统142用于确定车辆100的行驶路线。在一些实施例中,路线控制系统142可结合来自传感器融合算法138、gps122和一个或多个预定地图的数据以为车辆100确定行驶路线。
121.障碍规避系统144用于识别、评估和避免或者以其他方式越过车辆100的环境中的潜在障碍物。
122.当然,在一个实例中,控制系统106可以增加或替换地包括除了所示出和描述的那些以外的组件。或者也可以减少一部分上述示出的组件。
123.车辆100通过外围设备108与外部传感器、其他车辆、其他计算机系统或用户之间进行交互。外围设备108可包括无线通信系统146、车载电脑148、麦克风150和/或扬声器152。
124.在一些实施例中,外围设备108提供车辆100的用户与用户接口116交互的手段。例如,车载电脑148可向车辆100的用户提供信息。用户接口116还可操作车载电脑148来接收用户的输入。车载电脑148可以通过触摸屏进行操作。在其他情况中,外围设备108可提供用于车辆100与位于车内的其它设备通信的手段。例如,麦克风150可从车辆100的用户接收音频(例如,语音命令或其他音频输入)。类似地,扬声器152可向车辆100的用户输出音频。
125.无线通信系统146可以直接地或者经由通信网络来与一个或多个设备无线通信。例如,无线通信系统146可使用3g蜂窝通信,例如cdma、evd0、gsm/gprs,或者4g蜂窝通信,例如lte。或者5g蜂窝通信。无线通信系统146可利用wifi与无线局域网(wirelesslocalareanetwork,wlan)通信。在一些实施例中,无线通信系统146可利用红外链路、蓝牙或zigbee与设备直接通信。其他无线协议,例如各种车辆通信系统,例如,无线通信系统146可包括一个或多个专用短程通信(dedicatedshortrangecommunications,dsrc)设备,这些设备可包括车辆和/或路边台站之间的公共和/或私有数据通信。
126.电源110可向车辆100的各种组件提供电力。在一个实施例中,电源110可以为可再充电锂离子或铅酸电池。这种电池的一个或多个电池组可被配置为电源为车辆100的各种组件提供电力。在一些实施例中,电源110和能量源119可一起实现,例如一些全电动车中那样。
127.车辆100的部分或所有功能受计算机系统112控制。计算机系统112可包括至少一个处理器113,处理器113执行存储在例如数据存储装置114这样的非暂态计算机可读介质中的指令115。计算机系统112还可以是采用分布式方式控制车辆100的个体组件或子系统的多个计算设备。
128.处理器113可以是任何常规的处理器,诸如商业可获得的cpu。替选地,该处理器可以是诸如asic或其它基于硬件的处理器的专用设备。尽管图1功能性地图示了处理器、存储器、和在相同块中的计算机110的其它元件,但是本领域的普通技术人员应该理解该处理器、计算机、或存储器实际上可以包括可以或者可以不存储在相同的物理外壳内的多个处理器、计算机、或存储器。例如,存储器可以是硬盘驱动器或位于不同于计算机110的外壳内的其它存储介质。因此,对处理器或计算机的引用将被理解为包括对可以或者可以不并行操作的处理器或计算机或存储器的集合的引用。不同于使用单一的处理器来执行此处所描述的步骤,诸如转向组件和减速组件的一些组件每个都可以具有其自己的处理器,该处理
器只执行与特定于组件的功能相关的计算。
129.在此处所描述的各个方面中,处理器可以位于远离该车辆并且与该车辆进行无线通信。在其它方面中,此处所描述的过程中的一些在布置于车辆内的处理器上执行而其它则由远程处理器执行,包括采取执行单一操纵的必要步骤。
130.在一些实施例中,数据存储装置114可包含指令115(例如,程序逻辑),指令115可被处理器113执行来执行车辆100的各种功能,包括以上描述的那些功能。数据存储装置114也可包含额外的指令,包括向行进系统102、传感系统104、控制系统106和外围设备108中的一个或多个发送数据、从其接收数据、与其交互和/或对其进行控制的指令。
131.除了指令115以外,数据存储装置114还可存储数据,例如道路地图、路线信息,车辆的位置、方向、速度以及其它这样的车辆数据,以及其他信息。这种信息可在车辆100在自主、半自主和/或手动模式中操作期间被车辆100和计算机系统112使用。
132.用户接口116,用于向车辆100的用户提供信息或从其接收信息。可选地,用户接口116可包括在外围设备108的集合内的一个或多个输入/输出设备,例如无线通信系统146、车车在电脑148、麦克风150和扬声器152。
133.计算机系统112可基于从各种子系统(例如,行进系统102、传感系统104和控制系统106)以及从用户接口116接收的输入来控制车辆100的功能。例如,计算机系统112可利用来自控制系统106的输入以便控制转向单元132来避免由传感系统104和障碍规避系统144检测到的障碍物。在一些实施例中,计算机系统112可操作来对车辆100及其子系统的许多方面提供控制。
134.可选地,上述这些组件中的一个或多个可与车辆100分开安装或关联。例如,数据存储装置114可以部分或完全地与车辆100分开存在。上述组件可以按有线和/或无线方式来通信地耦合在一起。
135.可选地,上述组件只是一个示例,实际应用中,上述各个模块中的组件有可能根据实际需要增添或者删除,图1不应理解为对本发明实施例的限制。
136.在道路行进的自动驾驶汽车,如上面的车辆100,可以识别其周围环境内的物体以确定对当前速度的调整。该物体可以是其它车辆、交通控制设备、或者其它类型的物体。在一些示例中,可以独立地考虑每个识别的物体,并且基于物体的各自的特性,诸如它的当前速度、加速度、与车辆的间距等,可以用来确定自动驾驶汽车所要调整的速度。
137.可选地,自动驾驶汽车车辆100或者与自动驾驶车辆100相关联的计算设备(如图1的计算机系统112、计算机视觉系统140、数据存储装置114)可以基于所识别的物体的特性和周围环境的状态(例如,交通、雨、道路上的冰、等等)来预测该识别的物体的行为。可选地,每一个所识别的物体都依赖于彼此的行为,因此还可以将所识别的所有物体全部一起考虑来预测单个识别的物体的行为。车辆100能够基于预测的该识别的物体的行为来调整它的速度。换句话说,自动驾驶汽车能够基于所预测的物体的行为来确定车辆将需要调整到(例如,加速、减速、或者停止)什么稳定状态。在这个过程中,也可以考虑其它因素来确定车辆100的速度,诸如,车辆100在行驶的道路中的横向位置、道路的曲率、静态和动态物体的接近度等等。
138.除了提供调整自动驾驶汽车的速度的指令之外,计算设备还可以提供修改车辆100的转向角的指令,以使得自动驾驶汽车遵循给定的轨迹和/或维持与自动驾驶汽车附近
的物体(例如,道路上的相邻车道中的轿车)的安全横向和纵向距离。
139.进一步地,计算机系统112中的数据存储装置114可以包括系统内存,运行在系统内存的数据可以包括计算机的操作系统和应用程序app等。计算机系统112中的处理器113可以通过系统总线与该系统内存连接,读取该系统内存的数据并进行处理。
140.操作系统包括shell和内核(kernel)。shell是介于使用者和操作系统之内核(kernel)间的一个接口。shell是操作系统最外面的一层。shell管理使用者与操作系统之间的交互:等待使用者的输入,向操作系统解释使用者的输入,并且处理各种各样的操作系统的输出结果。
141.内核由操作系统中用于管理存储器、文件、外设和系统资源的那些部分组成。直接与硬件交互,操作系统内核通常运行进程,并提供进程间的通信,提供cpu时间片管理、中断、内存管理、io管理等等。
142.应用程序包括控制汽车自动驾驶相关的程序,比如,管理自动驾驶的汽车和路上障碍物交互的程序,控制自动驾驶汽车路线或者速度的程序,控制自动驾驶汽车和路上其他自动驾驶汽车交互的程序。应用程序也存在于软件部署服务器deploying server的系统上。在一个实施例中,在需要执行应用程序时,计算机系统112可以从deploying server下载应用程序。
143.那么,本技术实施例提供一种人工智能模型的处理方法可以具体应用在图1的计算机系统112上,应用在该计算机系统112的处理器113使用cnn模型或mask rcnn模型等ai模型对摄像头获取的图像进行ai处理的场景,以识别的物体的特性和周围环境的状态(例如,交通、雨、道路上的冰、等等)来预测该识别的物体的行为,从而确定车辆将需要调整到(例如,加速、减速、或者停止)什么稳定状态。本技术实施提供的人工智能模型的处理装置、人工智能模型的处理设备,具体即可以相当于图1的计算机系统112。
144.下面结合图2示出的本技术实施例提供的ai计算架构的结构示意图,说明计算机系统112的处理器训练或推理ai的过程。ai计算架构可以相当于计算机系统112中的处理器113,其可以具体包括主处理器(host cpu)以及人工智能处理单元,其中:
145.host cpu可以包括人工智能处理单元驱动(driver)、运行时单元或运行时层或用户态驱动层(runtime)以及库(library),也就是说host cpu可以读取系统内存或存储器中的上述数据。其中,人工智能处理单元driver可以提供人工智能处理单元的驱动功能。runtime可以提供人工智能处理单元的用户态接口(application programming interface,api),部署在应用程序app中。library可以提供人工智能处理单元的运算逻辑单元上可以直接执行的算子库功能,方便app开发业务功能。
146.人工智能处理单元也可以称为ai加速器,可以包括gpu或npu等ai处理器,其中npu可以为专用的或定制的神经网络处理器。人工智能处理单元可以包括控制单元(或控制器)和运算逻辑单元。
147.在一种实现方式中,针对人工智能处理单元的runtime,可以提供模型(model)、数据流(stream)、任务(task)、事件(event)等api。上层业务(如app)将ai计算图(即ai模型)进行分拆,转换成人工智能处理单元能够处理的stream、task、event等,通过调用这些api将ai模型下发给人工智能处理单元处理。人工智能处理单元的控制单元可以用于接收host cpu下发的ai模型,调度ai模型进行训练或推理,给host cpu上报执行结果。运算逻辑单元
可以执行控制单元下发的ai模型中的task,给控制单元返回每个task的结果(一个ai模型可以包含多个task)。
148.为提高模型执行效率,app将ai模型加载到人工智能处理单元,人工智能处理单元保存该ai模型。模型只需要加载一次,后续便可以多次执行,app退出或业务结束时,先通知人工智能处理单元卸载之前加载的模型。在人工智能处理单元侧,ai模型也是按照stream、task、event类似的结构方式,保存了加载的ai模型。
149.针对存在控制算子(如分支判断算子)和循环算子的神经网络模型,例如maskrcnn类型的网络模型以及循环神经网络(recurrent neural network,rnn)类型的网络模型,ai加速器不支持分支判断算子和循环算子时,在模型训练或模型执行的过程中,部分计算需要回落到host cpu上执行,降低模型的推理性能。
150.也就是说,针对ai模型中的某一个分支判断算子和循环算子,在运算逻辑单元执行本次算子后,并不能控制后面算子的执行,只能通过控制单元将数据返回给host cpu侧,由host cpu执行分支判断算子以及循环算子,以触发控制单元再次给运算逻辑单元调度算子或任务。以此与host cpu多次交互,将部分计算需要回落到host cpu上执行,来完成整个ai模型中的分支判断算子和循环算子。造成模型的推理或训练性能不高。
151.下面结合图3示出的本技术实施例提供的人工智能模型的处理设备的结构示意图,来说明本技术提供的ai计算架构如何提升模型推理或模型训练的性能。人工智能模型的处理设备30包括处理器300和人工智能处理单元301,其中:
152.处理器300用于创建人工智能ai模型;其中,该ai模型包括控制算子和计算算子;然后基于用户态接口api将该ai模型下发给人工智能处理单元301;该api包括第一api,该第一api用于下发该控制算子;该处理器300可相当于主处理器。
153.具体地,app里设置有ai模型的程序代码,可用于对输入的数据进行ai处理。处理器300读取到app的数据,并运行里面的关于ai模型的程序代码的过程,即为创建该ai模型。
154.本技术实施例中的ai模型包括控制算子,该控制算子可以为实现控制逻辑的代码或函数。本技术实施例中在runtime层可设有用于下发该控制算子的api;处理器300可以通过调用该runtime层的api将该ai模型下发给人工智能处理单元301。
155.人工智能处理单元301用于在获取到该人工智能ai模型,在训练或推理该ai模型的过程中,执行该控制算子和该计算算子。
156.可理解的是,本技术实施例的处理器300可以包括自身的控制器和运算器等,用于解释计算机指令以及处理计算机软件中的数据。处理器300是人工智能模型的处理设备30的中核心硬件单元,主要负责计算和整体协调,包括对人工智能模型的处理设备30的所有硬件资源(如存储器、输入输出单元以及本技术实施例的人工智能处理单元301)进行控制调配以及执行通用运算。
157.本技术实施例的人工智能处理单元301实际上可以为处理器或处理芯片,例如为专用或定制的gpu或npu等,可以作为协处理器挂载到处理器300上,或与处理器300耦合,由处理器300分配任务。
158.以npu为例,人工智能处理单元301的核心部件为运算逻辑单元,通过控制单元控制该运算逻辑单元提取矩阵数据并进行运算。运算逻辑单元内部可以包括多个处理单元(process engine,pe)。在一些实现中,运算逻辑单元是二维脉动阵列。运算逻辑单元还可
以是一维脉动阵列或者能够执行例如乘法和加法这样的数学运算的其它电子线路。在一些实现中,运算逻辑单元是通用的矩阵处理器。人工智能处理单元301还可以包括统一存储器、存储单元访问控制器(direct memory access controller,dmac)、权重存储器、总线接口单元、向量计算单元、取指存储器(instruction fetch buffer)等。其中:
159.该统一存储器可以用于存放输入数据以及输出数据。权重数据可以直接通过dmac被搬运到权重存储器中。输入数据也可以通过dmac被搬运到统一存储器。
160.总线接口单元可以用于axi总线与dmac和取指存储器的交互。具体可以用于取指存储器从外部存储器获取指令,以及用于dmac从外部存储器获取输入矩阵a或者权重矩阵b的原数据。
161.dmac主要用于将外部存储器中的输入数据搬运到统一存储器或将权重数据搬运到权重存储器中或将输入数据数据搬运到输入存储器中。
162.向量计算单元可以包括多个运算处理单元,在需要的情况下,对运算逻辑单元的输出做进一步处理,如向量乘,向量加,指数运算,对数运算,大小比较等等。主要用于神经网络中非卷积/fc层网络计算,如pooling(池化),batch normalization(批归一化),local response normalization(局部响应归一化)等。
163.在一些实现种,向量计算单元能将经处理的输出的向量存储到统一缓存器。例如,向量计算单元可以将非线性函数应用到运算逻辑单元的输出,例如累加值的向量,用以生成激活值。在一些实现中,向量计算单元生成归一化的值、合并值,或二者均有。在一些实现中,处理过的输出的向量能够用作到运算逻辑单元的激活输入,例如用于在神经网络中的后续层中的使用。
164.控制单元连接的取指存储器可以用于存储控制单元使用或执行的指令。
165.本技术实施例,通过设置用于下发控制算子的api,基于该api即可实现向人工智能处理单元下发包括控制算子的ai模型,以使该人工智能处理单元在训练或推理该ai模型的过程中,可独立执行该整个ai模型,无需将部分控制功能返回主处理器处理。解决了现有技术中在对ai模型进行训练或推理的过程中,需要主处理器和ai加速器相互之间进行频繁的交互才能完成,造成模型推理或模型训练的性能不高的技术问题;提升了模型推理或模型训练的性能。
166.在一种可能的实现方式中,本技术实施例的控制算子可以包括分支判断算子,该分支判断算子用于判断执行第一分支算子或第二分支算子。
167.在一种可能的实现方式中,该控制算子还包括循环算子,该循环算子用于循环执行所述ai模型的第一计算算子;该api还包括第二api和第三api,该第二api用于创建标签;该第三api用于设置标签在所述ai模型中的位置。
168.也就是说,用于下发该控制算子的api(即第一api)可以包括下发分支判断算子的api以及下发循环算子的api。具体地:
169.处理器300可以在runtime层创建或增加4个用于下发ai模型的api:
170.1、第二api,创建标签(createlabel):用于跳转时的定位;
171.2、第三api,标签设置(labelset)(涉及label,stream):在stream的当前位置放置label;也就是说针对放置有label的任务,设置其在执行序列或数据流中的位置;
172.3、分支判断(switch)(涉及value,condition,false_label,stream):将条件寄存
器中的数据(或值)与value条件比较,如果为false,则跳转到false_label后的task执行。条件支持“>”、“<”、“==”、“!=”、“<=”、“>=”等无符号整形数值比较;
173.4、循环(goto)(涉及label,stream):无条件跳转到label后的task执行。
174.那么在开发应用程序app的过程中,开发人员可基于该runtime层提供的上述api进行开发,根据开发需求将ai计算图进行分拆,转换成人工智能处理单元301能够处理的stream、task、event等。然后通过调用上述相应的api,将控制算子(如分支判断算子和循环算子)下发到人工智能处理单元301执行。
175.本技术实施例,还可以设置用于下发循环算子的api,那么向人工智能处理单元下发的ai模型,可以使得该人工智能处理单元在训练或推理该ai模型的过程中,可独立完成该循环算子的执行。并且该人工智能处理单元在执行循环算子的过程中,可通过用于创建标签的api以及用于设置标签在该ai模型中的位置的api进行相关跳转,从而可进一步快速高效地完成循环算子的执行。
176.进一步地,下面结合图4示出的本技术提供的另一实施例的人工智能模型的处理设备的结构示意图,说明本技术提供的人工智能处理单元的其中一种具体结构,以及如何提升模型推理或模型训练的性能。
177.图4的人工智能模型的处理设备40可以包括控制单元(或控制器)400和运算逻辑单元402。如上述所描述,人工智能模型的处理设备40还可以包括其他单元或模块,如统一存储器、dmac、权重存储器、总线接口单元等等,只是本实施例图4中没有画出。如图4所示,人工智能模型的处理设备40往往可以包括多个运算逻辑单元402。控制单元400可以包括多个第一存储单元(可称为第一寄存器或条件寄存器(condition,cond)),控制单元400在训练或推理ai模型的过程中,一个第一存储单元可以对应该ai模型的一个执行序列,同步并行的不同执行序列对应不同的第一存储单元;运算逻辑单元402包括第二存储单元(可称为第二寄存器或专用条件寄存器(condition special purpose register,cond_spr))。其中,控制单元400用于调度ai模型执行,也就是将模型的算子或任务调度到运算逻辑单元402执行(如计算类型算子),或控制单元400自己执行(如event类型的任务)。运算逻辑单元执行单个的计算类型算子。具体地:
178.控制单元400用于获取或读取ai模型,该ai模型包括控制算子和计算算子;ai模型为主处理器基于api下发的ai模型;该api包括第一api,该第一api用于下发该控制算子;
179.第二存储单元用于存储运算逻辑单元402执行计算算子后的数据。
180.控制单元400还用于读取该第二存储单元的数据。其中,运算逻辑单元402执行该任务后,将执行后的数据写入自身的第二存储单元,并可以通知控制单元400执行完毕,以触发控制单元400读取该第二存储单元的数据。控制单元400读取到该第二存储单元的数据后,将该数据写入该执行序列对应的第一存储单元中。然后控制单元400可以基于第一存储单元中存储的该数据以及控制算子中的参数来执行该执行序列的下一任务;
181.本技术实施例的控制算子为控制单元400需要依据从该402运算逻辑单元读取的数据来执行的控制任务。在一种可能的实现方式中,控制算子可以包括分支判断算子,该分支判断算子用于判断执行第一分支算子或第二分支算子;
182.那么控制单元400在基于该数据和该控制算子中的参数执行该执行序列的下一任务时,可以具体地,基于该数据和该分支判断算子中的参数判断是否执行第一分支算子;
183.由于该分支判断算子是用于判断执行第一分支算子还是执行第二分支算子,故若判断为是,则执行该第一分支算子;若判断为否,则执行该第二分支算子。
184.进一步地,本技术实施例的ai模型还可以包括循环算子,该循环算子用于循环执行所述ai模型的第一计算算子。控制单元400在判断出执行第一分支算子后,可执行该循环算子;以调度该运算逻辑单元402循环执行该执行序列的第一计算算子,直到控制单元400基于该数据和该分支判断算子中的参数判断不执行第一分支算子。
185.需要说明的是,控制单元400在执行该分支判断算子的时候,往往是基于该数据和该分支判断算子中的参数,通过具体的判断逻辑或判断条件来判断是真(ture)还是假(false),例如可以在判断为ture时,则执行该第一分支算子,在判断为false时,则执行该第二分支算子;也可以在判断为false时,则执行该第一分支算子,在判断为ture时,则执行该第二分支算子。而本技术实施例通过判断是否执行第一分支算子,来对应判断是真(ture)还是假(false)。由于在判断执行第一分支算子后,会执行该循环算子,也就是说,本技术实施例可以是在执行该分支判断算子的时候,基于该数据和该分支判断算子中的参数通过具体的判断逻辑或判断条件判断为ture时,执行该循环算子,也可以是判断为false时,执行该循环算子。
186.例如,在该ai模型的执行序列中,在控制单元400基于该数据和该分支判断算子中的参数判断是否执行第一分支算子之前,该运算逻辑单元402被该控制单元400调用执行某个计算算子(如本技术的第一计算算子)。那么控制单元400在执行该循环算子,可触发控制单元400调用运算逻辑单元402再次执行该某个计算算子,从而跳转到该第一计算算子,以进行循环执行。直到控制单元400基于该数据和该分支判断算子中的参数判断不执行第一分支算子。
187.在一种可能的实现方式中,上述在执行分支判断算子和循环算子的过程中,具体地可以通过以下方式实现:
188.本技术实施例的ai模型还可以包括用于跳转的第一标签和第二标签,及其分别在该执行序列中放置的位置;其中该第一标签放置在与该执行序列的第一计算算子相邻的上一个任务中,该第二标签放置在与该第二分支算子相邻的上一个任务中;
189.假设在该ai模型的执行序列中,控制单元400在基于该数据和该控制算子中的参数执行该执行序列的下一任务之前,包括控制单元400将该第一计算算子调度给该运算逻辑单元执行的任务;
190.那么控制单元400在判断出执行第一分支算子后,可执行该循环算子,跳转到该第一标签所在的位置,那么下一个任务即回到该执行序列的第一计算算子,即该控制单元400调度该运算逻辑单元402再次执行该第一计算算子,以进行迭代;
191.控制单元400在执行第二分支算子时,即跳转到该第二标签所在的位置,那么下一个任务即为该第二分支算子,以执行该第二分支算子。
192.控制单元400还用于在执行完毕该执行序列的情况下,输出执行完毕的指示信息。
193.本技术实施例,通过在控制单元中设置多个第一存储单元,以及在运算逻辑单元中设置第二存储单元,运算逻辑单元可以将执行任务后的数据写入该第二存储单元,那么控制单元可以读取该第二存储单元的数据,并将数据写入执行序列对应的第一存储单元。也就是说,控制单元可以读取到当前算子执行后的数据,实现了根据当前算子的执行结果
device,mid)、可穿戴设备,虚拟现实(virtual reality,vr)设备、增强现实(augmented reality,ar)设备、工业控制(industrial control)中的无线终端、无人驾驶(self driving)中的无线终端、远程手术(remote medical surgery)中的无线终端、智能电网(smart grid)中的无线终端、运输安全(transportation safety)中的无线终端、智慧城市(smart city)中的无线终端、智慧家庭(smart home)中的无线终端、智能机器人、车载系统或含有驾驶舱域控制器的车辆等。
203.可理解的是,人工智能模型的处理设备50还可以包括其他处理器、存储模块、通信模块、显示屏、电池、电池管理模块、基于不同功能的多个传感器等单元中的至少一个。只是图5中的人工智能模型的处理设备50没有画出。
204.下面结合图6示出的本技术实施例提供的ai模型的循环语句的示意图,举例进行说明。假设model1(即ai模型1)的循环语句的执行逻辑是:
205.i初始值为0,当i<10时,循环执行i+1操作。图6中计算图入口为输入(enter)算子,enter透传输入张量0,融合(merge)算子收到0后启动执行,将0传递给switch算子,同时输出0和10进行比较,比较结果(true)作为switch的控制输入(p),switch算子将输入0转发到true分支,增加(add)算子收到输入0后启动0+1计算,计算结果1输出给循环或迭代(nextiteration)算子,nextiteration算子将输入1传递给merge,如此循环,直至merge的输出>=10,switch算子将输入传递给false分支,退出(exit)循环。
206.那么结合上述在runtime层创建或增加的4个api,即包括第一api(生成分支判断算子的api和生成循环算子的api)、第二api和第三api,编码可以如下:
207.create model1
208.create stream1
209.create label1
210.create label2
211.model1.add(stream 1)
212.launch(stream1,enter,
…
)
213.labelset(label1,stream1)
214.launch(stream1,merge,
…
)
215.switch(10,“<”,label2,stream1)
216.launch(stream1,add,
…
)
217.goto(label1,stream1)
218.labelset(label2,stream1)
219.launch(stream1,exit,
…
)
220.也就是说,创建了用于跳转的第一标签label1和第二标签label2,以及第一标签label1和第二标签label2分布在数据流stream1中的位置。label1的位置(也即放置了label1这个标签的执行任务的位置)与merge算子相邻,在该merge算子之前。label2的位置(也即放置了label2这个标签的执行任务的位置)与exit算子相邻,在该exit算子之前。可对应参考图7示出的本技术实施例提供的ai模型中stream1的执行序列的示意图,关于ai模型中stream1的执行序列可包括8个任务,例如,如图中enter即对应任务1、label1即对应任务2、merge即对应任务3、switch即对应任务4、add即对应任务5、goto即对应任务6、label2
即对应任务7、exit即对应任务8。该stream1的执行序列对应有图7中的第一存储单元。
221.应用程序(例如app1)将上述编码通过runtime层,经过npu driver下发给控制单元500后,也就是说将需要训练或推理的model1下发给控制单元500后,触发控制单元500在调度ai模型的执行序列的计算算子给运算逻辑单元502执行。控制单元500在执行循环goto算子时,基于label1跳转到label1在ai模型的执行序列所在的位置(即放置了label1这个标签的执行任务的位置),触发运算逻辑单元502迭代执行该执行序列的任务。控制单元500执行分支判断算子(switch),判断为否时,即基于label2跳转到第二标签label2在ai模型的执行序列所在的位置(即放置了label2这个标签的执行任务的位置),然后调度退出任务(即exit算子)给运算逻辑单元502;在接收到运算逻辑单元502执行完该退出任务的通知后,输出执行完毕的指示信息。
222.具体结合图8示出的本技术实施例提供的控制单元执行流程的示意图,以及图9示出的本技术实施例提供的人工智能处理单元执行的原理示意图,说明控制单元的执行流程:
223.步骤s800:控制单元将enter task调度给运算逻辑单元执行;
224.步骤s802:运算逻辑单元执行该enter task;
225.步骤s804:运算逻辑单元执行完毕后,通知控制单元执行完成;
226.具体地,运算逻辑单元执行完后,可将执行任务后的结果或数据存储在其第二存储单元中。
227.步骤s806:控制单元接收到通知后,针对该第一标签的任务或算子(label1 task),可直接跳过,执行后面的task;
228.具体地,控制单元获知运算逻辑单元执行完毕enter task后,可以读取该第二存储单元中的数据,并将数据保存(或写入)到该执行序列对应的第一存储单元cond中;并且执行label1 task,针对该label1 task,控制单元是直接跳过的,即执行步骤s808。
229.步骤s808:控制单元将merge task调度给运算逻辑单元执行;本技术实施例中,该merge task即可以相当于第一计算算子。
230.步骤s810:运算逻辑单元执行该merge task,并将i写入到自身的第二存储单元cond_spr中;
231.具体地,运算逻辑单元第一次执行该merge task时,i值是由该enter task直接透传给该merge task的。在后续迭代执行该merge task时,i值是由循环算子传递给merge task。
232.步骤s812:运算逻辑单元执行完成后,通知控制单元执行完成;
233.步骤s814:控制单元接收到通知后,读取该cond_spr的值(也就是i),并将读取的数据写入到stream1对应的第一存储单元cond中;
234.具体地,控制单元获知运算逻辑单元执行完毕merge task后,可以读取该第二存储单元中的数据(也就是i),并将数据写入该执行序列对应的第一存储单元cond中。可理解的是,若该第一存储单元cond已存储有数据,那么本次写入相当于刷新第一存储单元cond中的数据。
235.步骤s816:控制单元执行switch task,根据读取的数据以及switch task中的参数进行判断处理(例如,将i和value进行比较,判断是否i小于value),如果是true,继续执
行下面的task(即执行步骤s818),如果是false,跳转到label2(即跳转到步骤s824);
236.具体地,例如value为10,那么若判断当前的i小于10,则执行步骤s818;若不小于10,则跳转到步骤s824。
237.步骤s818:控制单元将增加任务add task(相当于下一任务,例如第一分支算子)调度给运算逻辑单元执行;也就是说,本技术实施例是举例在步骤s816中判断为ture时,才执行后续步骤s822的循环算子。实际上如上述图4实施例中所描述,本技术实施例并不限定。
238.步骤s820:运算逻辑单元执行完成,通知控制单元;
239.例如,运算逻辑单元可以执行add task(第一分支算子),例如将i值加1,将当前i值存储在自身的第二存储单元中,并在执行完毕后通知控制单元。
240.步骤s822:控制单元执行循环算子(goto task),然后无条件跳转到label1开始执行(即跳转到步骤s806开始执行,并接着再次触发执行第一计算算子merge task);
241.具体地,控制单元获知运算逻辑单元执行完毕goto task后,可以读取该第二存储单元中的数据(也就是当前i值),并将数据写入该执行序列对应的第一存储单元cond中。然后在执行该goto task时将当前第一存储单元cond中的数据(即当前i值),传递给merge task。本技术实施例的控制单元支持从逻辑运算单元的第二存储单元中读取数据,从而可在控制单元内部来完成分支判断算子的执行,无需与host cpu反复交互。
242.步骤s824:控制单元对于lable2 task(可以相当于另一个下一任务,例如第二分支算子),可跳过lable2 task,调度exit task给运算逻辑单元执行;
243.步骤s826:运算逻辑单元执行完成,通知控制单元;
244.步骤s828:控制单元接收到通知后,判断执行序列完成,然后输出执行完毕的指示信息。
245.具体的,可以向该npu driver输出执行完毕的指示信息。
246.在一种可能的实现方式中,本技术实施例的控制单元500,还可以用于在读取第二存储单元的数据之前,将运算逻辑单元502的第二存储单元设置为无效值;然后控制单元500后续在判断出读取的第二存储单元的数据为有效值的情况下,再将该读取的数据写入该执行序列对应的第一存储单元中。若判断为无效值,则不将该读取的数据写入该执行序列对应的第一存储单元中。
247.可理解的是,上述图6
‑
图8的实施例描述仅仅是本技术的一个实施例,本技术的第一分支算子不限定为上述的add task,第二分支算子不限定为lable2 task或exit task。
248.相应的,本技术还提供了人工智能模型的处理装置以及人工智能模型的处理方法,下面将结合图10至图13进行说明。
249.如图10示出的本技术实施例提供的一种人工智能模型的处理装置的结构示意图,人工智能模型的处理装置16可以为图3实施例中人工智能模型的处理设备30的处理器300或图5实施例中人工智能模型的处理设备50的主处理器504。其中,人工智能模型的处理装置16可以包括创建单元160和下发单元162,其中:
250.创建单元160用于创建人工智能ai模型;该ai模型包括控制算子和计算算子;
251.具体地,该创建单元160可以相当于处理器300或主处理器504中执行的用于创建人工智能ai模型的程序代码。
252.下发单元162用于基于用户态接口api将该ai模型下发给人工智能处理单元;其中,该api包括第一api,该第一api用于下发该控制算子;该人工智能处理单元用于在训练或推理该ai模型的过程中,执行该控制算子和该计算算子。
253.具体地,该下发单元162可以相当于在处理器300或主处理器504中执行的用于基于用户态接口api将该ai模型下发给人工智能处理单元的程序代码。
254.在其中一种实现方式中,该控制算子包括分支判断算子,该分支判断算子用于判断执行第一分支算子或第二分支算子。
255.在其中一种实现方式中,该控制算子还包括循环算子,该循环算子用于循环执行该ai模型的第一计算算子;该api还包括第二api和第三api,该第二api用于创建标签;该第三api用于设置标签在该ai模型中的位置。
256.该创建单元160和下发单元162的具体实现方式可以参考上述图3至图8实施例中关于处理器300或主处理器504进行ai模型处理的过程,这里不再赘述。
257.如图11示出的本技术提供的另一实施例的人工智能模型的处理装置的结构示意图,人工智能模型的处理装置17可以为图3实施例中人工智能模型的处理设备30的人工智能处理单元301、或图4的人工智能模型的处理设备40、或图5实施例的人工智能模型的处理设备50的人工智能处理单元。其中,人工智能模型的处理装置17可以包括获取单元170和执行算子单元172,其中:
258.获取单元170用于获取人工智能ai模型;该ai模型包括控制算子和计算算子,该ai模型为处理器基于用户态接口api下发的ai模型;该api包括第一api,该第一api用于下发该控制算子;
259.执行算子单元172用于在训练或推理该ai模型的过程中,执行该控制算子和该计算算子。
260.具体地,该获取单元170可以相当于在人工智能处理单元301或人工智能模型的处理设备40或人工智能模型的处理设备50的人工智能处理单元中的控制单元中执行的用于获取人工智能ai模型的程序代码。
261.该执行算子单元172可以相当于在人工智能处理单元301或人工智能模型的处理设备40或人工智能模型的处理设备50的人工智能处理单元中的控制单元和运算逻辑单元中共同或相互配合执行的用于在训练或推理该ai模型的过程中执行该控制算子的程序代码。
262.在其中一种实现方式中,执行算子单元172可以包括第一执行单元1720、存储处理单元1721和第二执行单元1722,其中:
263.第一执行单元1720用于在训练或推理该ai模型的过程中,通过该人工智能处理单元的运算逻辑单元执行该ai模型中的计算算子;也就是说,该第一执行单元1720可以相当于在运算逻辑单元上用于执行该ai模型中的计算算子的程序代码。
264.存储处理单元1721用于将执行该计算算子后的数据存储在该人工智能处理单元的存储单元中;具体地,该存储处理单元1721可以相当于在运算逻辑单元上用于将执行该计算算子后的数据存储在该人工智能处理单元的存储单元中的程序代码。
265.第二执行单元1722用于通过该人工智能处理单元的控制单元,基于该存储单元中的数据执行该控制算子。具体地,该第二执行单元1722可以相当于在控制单元上用于基于
该存储单元中的数据执行该控制算子的程序代码。
266.在其中一种实现方式中,人工智能处理单元中的存储单元可以包括第一存储单元和第二存储单元;
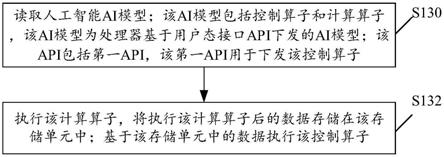
267.那么存储处理单元1721可以具体用于:将执行该计算算子后的数据存储在该第二存储单元中;
268.第二执行单元1722可以具体包括:
269.第一读取单元,用于读取该第二存储单元中的数据;
270.第一写入单元,用于将该第二存储单元中的数据写入该第一存储单元;
271.读取执行单元,用于读取并基于该第一存储单元中的数据执行该控制算子。
272.在其中一种实现方式中,该读取执行单元可以具体包括:
273.第二读取单元,用于读取该第一存储单元中的数据;
274.判断单元,用于基于该第一存储单元中数据和该分支判断算子中的参数判断是否执行该第一分支算子;
275.判断处理单元,用于若该判断单元判断为是,则执行该第一分支算子;若该判断单元判断为否,则执行该第二分支算子。
276.在其中一种实现方式中,该控制算子还可以包括循环算子,该循环算子用于循环执行该ai模型的第一计算算子;该人工智能模型的处理装置17还可以包括第三执行单元174,用于在该判断处理单元执行该第一分支算子之后,执行该循环算子,以通过该运算逻辑单元循环执行该第一计算算子,直到该判断为否。具体地,该第三执行单元174可以相当于在控制单元上用于执行该循环算子的程序代码。
277.在其中一种实现方式中,该api还包括第二api和第三api,该第二api用于创建标签;该第三api用于设置标签在所述ai模型中的位置;该ai模型包括用于跳转的第一标签和第二标签;其中该第一标签放置在与该ai模型的第一计算算子相邻的上一个算子中,该第二标签放置在与该第二分支算子相邻的上一个算子中;该人工智能模型的处理装置17还可以包括第四执行单元176,用于在该读取执行单元读取并基于该第一存储单元中的数据执行该控制算子之前,通过该运算逻辑单元执行该第一计算算子;也就是说,该第四执行单元176可以相当于在运算逻辑单元上用于执行该第一计算算子的程序代码。
278.该第三执行单元174具体用于:在该判断处理单元执行该第一分支算子之后,执行该循环算子,跳转到该第一标签所在的位置,以通过该运算逻辑单元循环执行该第一计算算子;
279.若该判断单元判断为否,该判断处理单元具体用于,跳转到该第二标签所在的位置,以执行该第二分支算子。
280.在其中一种实现方式中,该人工智能模型的处理装置17还可以包括设置单元178,用于在该第一读取单元读取该第二存储单元中的数据之前,将该第二存储单元设置为无效值;具体地,该设置单元178可以相当于在控制单元上用于将该第二存储单元设置为无效值的程序代码。
281.该第一写入单元具体用于:在判断出读取的该第二存储单元的数据为有效值的情况下,将该第二存储单元的数据写入该第一存储单元中。
282.需要说明的是,该人工智能模型的处理装置17的具体实现方式可以参考上述图3
至图8实施例中关于人工智能模型的处理设备30的人工智能处理单元301、或图4的人工智能模型的处理设备40、或图5实施例的人工智能模型的处理设备50的人工智能处理单元进行ai模型处理的过程,这里不再赘述。
283.如图12示出的本技术实施例提供的一种人工智能模型的处理方法的流程示意图,应用于图3实施例中人工智能模型的处理设备30的处理器300或图5实施例中人工智能模型的处理设备50的主处理器504,可以包括以下步骤:
284.步骤s120:处理器(或称为主处理器)创建人工智能ai模型;该ai模型包括控制算子和计算算子;
285.步骤s122:基于用户态接口api将该ai模型下发给人工智能处理单元。
286.其中,该api包括第一api,该第一api用于下发该控制算子;该人工智能处理单元用于在训练或推理该ai模型的过程中,执行该控制算子和该计算算子。
287.本实施例该人工智能模型的处理方法的具体实现方式可以参考上述图3至图8实施例中关于处理器300或主处理器504进行ai模型处理的过程,这里不再赘述。
288.如图13示出的本技术提供的另一种实施例的人工智能模型的处理方法的流程示意图,应用于图3实施例中人工智能模型的处理设备30的人工智能处理单元301、或图4的人工智能模型的处理设备40、或图5实施例的人工智能模型的处理设备50的人工智能处理单元,该人工智能处理单元可以包括控制单元、运算逻辑单元以及存储单元,该人工智能处理单元可以执行以下步骤:
289.步骤s130:读取人工智能ai模型;该ai模型包括控制算子和计算算子,该ai模型为处理器基于用户态接口api下发的ai模型;该api包括第一api,该第一api用于下发该控制算子;
290.步骤s132:执行该计算算子,将执行该计算算子后的数据存储在该存储单元中;基于该存储单元中的数据执行该控制算子。
291.其中,该人工智能处理单元在训练或推理该ai模型的过程中,可以通过该运算逻辑单元执行该ai模型中的计算算子,该运算逻辑单元将执行该计算算子后的数据存储在该存储单元中;然后该控制单元可以基于该存储单元中的数据执行该控制算子。
292.在一种可能的实现方式中,该存储单元可以包括第一存储单元和第二存储单元;那么该将执行该计算算子后的数据存储在该存储单元中可以包括:将执行该计算算子后的数据存储在该第二存储单元中;
293.该基于该存储单元中的数据执行该控制算子课可以包括:读取该第二存储单元中的数据,将该第二存储单元中的数据写入该第一存储单元;读取并基于该第一存储单元中的数据执行该控制算子。
294.在一种可能的实现方式中,该第一存储单元可集成在控制单元中,也就是说可以在控制单元中增加该第一存储单元,该第一存储单元可以为该控制单元的专用寄存器。该第二存储单元可集成在运算逻辑单元中,也就是说可以在运算逻辑单元中增加该第二存储单元,该第二存储单元可以为该运算逻辑单元的专用寄存器。可以进一步实现控制单元快速高效地读取到运算逻辑单元执行完算子或任务后的数据,从而可根据当前算子的执行结果控制后面算子的执行。实现了整个ai模型都在控制器和运算逻辑单元内执行,无需将部分控制功能返回主处理器处理。
295.其中,人工智能处理单元中每个运算逻辑单元都可增加第二存储单元(自身专用的寄存器),使得每一个运算逻辑单元都可用于配合控制单元来执行控制算子,从而可再进一步提高人工智能处理单元模型推理或模型训练的性能。
296.在一种可能的实现方式中,ai模型对应有至少一个执行序列,每个该第一存储单元对应不同的执行序列。
297.本技术实施例中,处理器可以根据处理ai模型的数量,以及每个ai模型对应的执行序列的数量,实现定制化地设置控制单元中第一存储单元的数量。
298.在一种可能的实现方式中,该控制算子可以包括分支判断算子和循环算子,其中该分支判断算子用于判断执行第一分支算子或第二分支算子;
299.那么该读取并基于该第一存储单元中的数据执行该控制算子,可以包括:读取该第一存储单元中的数据;基于该第一存储单元中数据和该分支判断算子中的参数判断是否执行该第一分支算子;若判断为是,则执行该第一分支算子;若判断为否,则执行该第二分支算子。
300.在一种可能的实现方式中,该控制算子还可以包括循环算子,那么在该执行该第一分支算子之后,还可以包括:执行该循环算子,以通过该运算逻辑单元迭代执行该ai模型的计算算子,直到该判断为否。
301.在一种可能的实现方式中,该ai模型可以包括用于跳转的第一标签和第二标签;其中该第一标签放置在与该ai模型的第一计算算子相邻的上一个算子中,该第二标签放置在与该第二分支算子相邻的上一个算子中;那么在该读取并基于该第一存储单元中的数据执行该控制算子之前,还可以包括:通过该运算逻辑单元执行该第一计算算子;
302.该执行该循环算子,以通过该运算逻辑单元迭代执行该ai模型的计算算子,可以包括:执行该循环算子,跳转到该第一标签所在的位置,以通过该运算逻辑单元迭代执行该ai模型的该第一计算算子;该若判断为否,则执行该第二分支算子,包括:若判断为否,则跳转到该第二标签所在的位置,以执行该第二分支算子。
303.在一种可能的实现方式中,在该读取该第二存储单元中的数据之前,还可以包括:将该第二存储单元设置为无效值;那么该将该第二存储单元中的数据写入该第一存储单元,可以包括:在判断出读取的该第二存储单元的数据为有效值的情况下,将该第二存储单元的数据写入该第一存储单元中。
304.本实施例该人工智能模型的处理方法的具体实现方式可以参考上述图3至图8实施例中关于人工智能模型的处理设备30的人工智能处理单元301、或图4的人工智能模型的处理设备40、或图5实施例的人工智能模型的处理设备50的人工智能处理单元进行ai模型处理的过程,这里不再赘述。
305.本技术实施例还提供一种计算机可读存储介质,其中,该计算机可读存储介质可存储有程序,该程序被本技术实施例的处理器执行时包括上述方法实施例中记载的任意一种人工智能模型的处理方法的部分或全部步骤。
306.例如,该程序被处理器执行时,可以创建人工智能ai模型;该ai模型包括控制算子;然后基于用户态接口api将该ai模型下发给人工智能处理单元。其中,该api包括用于下发该控制算子的api;该人工智能处理单元用于在训练或推理该ai模型的过程中,执行该控制算子。其具体实现方式可以参考上述图3至图8实施例中关于处理器300或主处理器504进
行ai模型处理的过程,这里不再赘述。
307.又如,该程序被处理器执行时,可以获取或读取人工智能ai模型;该ai模型包括控制算子,该ai模型为处理器通过创建ai模型,基于用户态接口api下发的ai模型;该api包括用于下发该控制算子的api;然后在训练或推理该ai模型的过程中,执行该控制算子。其具体实现方式可以参考上述图3至图8实施例中关于人工智能模型的处理设备30的人工智能处理单元301、或图4的人工智能模型的处理设备40、或图5实施例的人工智能模型的处理设备50的人工智能处理单元进行ai模型处理的过程,这里不再赘述。
308.本技术实施例还提供一种计算机程序,该计算机程序包括指令,当该计算机程序被多核处理器执行时,使得该本技术实施例的处理器可以执行任意一种人工智能模型的处理方法的部分或全部步骤。
309.在一些实施例中,所公开的方法可以实施为以机器可读格式被编码在计算机可读存储介质上的或者被编码在其它非瞬时性介质或者制品上的计算机程序指令。图14示意性地示出根据这里展示的至少一些实施例而布置的示例计算机程序或计算机程序产品的概念性局部视图,该示例计算机程序产品包括用于在计算设备上执行计算机进程的计算机程序。在一个实施例中,示例计算机程序产品1400是使用信号承载介质1401来提供的。该信号承载介质1401可以包括一个或多个程序指令1402,其当被一个或多个处理器运行时可以提供以上针对图3至图8实施例中关于处理器300或主处理器504、或人工智能模型的处理设备30的人工智能处理单元301、或图4的人工智能模型的处理设备40、或图5实施例的人工智能模型的处理设备50的人工智能处理单元描述的功能或者部分功能。
310.在一些示例中,信号承载介质1401可以包含计算机可读介质1403,诸如但不限于,硬盘驱动器、紧密盘(cd)、数字视频光盘(dvd)、数字磁带、存储器、只读存储记忆体(read
‑
only memory,rom)或随机存储记忆体(random access memory,ram)等等。在一些实施方式中,信号承载介质1401可以包含计算机可记录介质1404,诸如但不限于,存储器、读/写(r/w)cd、r/w dvd、等等。在一些实施方式中,信号承载介质1401可以包含通信介质1405,诸如但不限于,数字和/或模拟通信介质(例如,光纤电缆、波导、有线通信链路、无线通信链路、等等)。因此,例如,信号承载介质1401可以由无线形式的通信介质1405(例如,遵守ieee 802.11标准或者其它传输协议的无线通信介质)来传达。一个或多个程序指令1402可以是,例如,计算机可执行指令或者逻辑实施指令。在一些示例中,诸如针对图3至图8实施例中关于处理器300或主处理器504、或人工智能模型的处理设备30的人工智能处理单元301、或图4的人工智能模型的处理设备40、或图5实施例的人工智能模型的处理设备50的人工智能处理单元可以被配置为,响应于通过计算机可读介质1403、计算机可记录介质1404、和/或通信介质1405中的一个或多个传达到计算设备的程序指令1402,提供各种操作、功能、或者动作。应该理解,这里描述的布置仅仅是用于示例的目的。因而,本领域技术人员将理解,其它布置和其它元素(例如,机器、接口、功能、顺序、和功能组等等)能够被取而代之地使用,并且一些元素可以根据所期望的结果而一并省略。另外,所描述的元素中的许多是可以被实现为离散的或者分布式的组件的、或者以任何适当的组合和位置来结合其它组件实施的功能实体。
311.在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其它实施例的相关描述。
312.需要说明的是,对于前述的各方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本技术并不受所描述的动作顺序的限制,因为依据本技术,某些步骤可能可以采用其它顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和模块并不一定是本技术所必须的。
313.在本技术所提供的几个实施例中,应该理解到,所揭露的装置,可通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如上述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性或其它的形式。
314.上述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
315.另外,在本技术各实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
316.上述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以为个人计算机、服务器或者网络设备等,具体可以是计算机设备中的处理器)执行本技术各个实施例上述方法的全部或部分步骤。其中,而前述的存储介质可包括:u盘、移动硬盘、磁碟、光盘、只读存储器(read
‑
only memory,缩写:rom)或者随机存取存储器(random access memory,缩写:ram)等各种可以存储程序代码的介质。
317.以上实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1