使用块划分的神经网络模型压缩的制作方法
使用块划分的神经网络模型压缩
1.援引并入
2.本公开要求于2021年4月15日提交的美国专利申请号17/232,069、题为“使用块划分的神经网络模型压缩”的优先权,该美国专利申请要求于2020年4月24日提交的美国临时申请号63/015,213、题为“用于神经网络模型压缩的块定义和用途”的优先权、要求于2020年6月22日提交的美国临时申请号63/042,303、题为“用于神经网络模型压缩的3d金字塔编码方法”的优先权、要求于2020年9月16日提交的美国临时申请号63/079,310、题为“用于神经网络模型压缩的基于统一的编码方法”的优先权、以及要求于2020年9月17日提交的美国临时申请号63/079,706、题为“用于神经网络模型压缩的基于统一的编码方法”的优先权。这些在先申请的公开内容通过引用整体并入本文中。
技术领域
3.本公开描述了总体上与神经网络模型压缩/解压缩相关的实施例。
背景技术:
4.本文所提供的背景描述旨在总体上呈现本公开的环境。在该背景部分中描述的范围内,目前命名的发明人的作品以及提交之时不符合现有技术的描述的各方面既未明确、亦未默示地承认为本公开的现有技术。
5.计算机视觉领域、图像识别领域和语音识别领域的各种应用依赖于神经网络来实现性能改进。神经网络基于连接的节点(还称为神经元)的集合,连接的节点松散地模拟生物大脑中的神经元。神经元可组织成多个层。一层的神经元可连接到紧挨着的前一层和紧挨着的后一层的神经元。
6.两个神经元之间的连接,如生物大脑中的突触,可将信号从一个神经元传递到另一个神经元。然后,接收信号的神经元处理该信号,且可以向其它连接的神经元发送信号。在一些示例中,为了找到神经元的输出,通过从输入到神经元的连接的权重来对神经元的输入进行加权,且对加权的输入求和,以生成加权和。偏置可与加权和相加。此外,加权和随后经过激活函数以产生输出。
技术实现要素:
7.本发明的各方面提供神经网络模型压缩/解压缩的方法和装置。在一些示例中,一种神经网络模型解压缩的装置包括处理电路。该处理电路可配置成从神经网络的压缩的神经网络表示(nnr)的比特流中接收压缩的nnr聚合单元的nnr聚合单元报头中的第一语法元素。第一语法元素可指示用于处理nnr聚合单元中的张量的编码树单元(ctu,coding tree unit)扫描顺序。可基于由第一语法元素指示的ctu扫描顺序,重建nnr聚合单元中的张量。
8.在一个实施例中,第一语法元素的第一值可指示ctu扫描顺序是沿着水平方向的第一光栅扫描顺序,且第一语法元素的第二值指示ctu扫描顺序是沿着竖直方向的第二光栅扫描顺序。在一个实施例中,可从比特流中接收nnr聚合单元的nnr聚合单元报头中的第
二语法元素。第二语法元素可指示nnr聚合单元中的张量的量化系数的最大位深度。
9.在一个实施例中,可接收第三语法元素,第三语法元素指示是否对nnr聚合单元中的张量启用ctu块划分。第三语法元素可以是与模型相关的语法元素或者与张量相关的语法元素,与模型相关的语法元素用于指定是否对神经网络的层启用ctu块划分,与张量相关的语法元素用于指定是否对nnr聚合单元中的张量启用ctu块划分。
10.在一个实施例中,可接收与模型相关或与张量相关的第四语法元素,第四语法元素指示nnr聚合单元中的张量的ctu维度。在一个实施例中,可以在接收任意nnr聚合单元之前接收nnr单元。nnr单元可包括第五语法元素,第五语法元素指示是否启用ctu划分。
11.在一些示例中,另一神经网络模型解压缩的装置包括处理电路。该处理电路可配置成从压缩的神经网络表示的比特流中接收一个或多个第一语法元素,该第一语法元素与从第一三维编码树单元(ctu3d,3-dimensional coding tree unit)划分的三维编码单元(cu3d,3-dimensional coding unit)相关联。第一ctu3d可从神经网络中的张量划分得到。一个或多个第一语法元素可指示cu3d基于包括多个深度的3d金字塔结构来划分。每个深度对应于一个或多个节点。每个节点具有节点值。可以以用于扫描3d金字塔结构中的节点的广度优先扫描顺序从比特流中接收与3d金字塔结构中的节点的节点值对应的第二语法元素。可基于所接收的与3d金字塔结构中的各节点的节点值对应的第二语法元素重建张量的模型参数。在各种实施例中,3d金字塔结构是八叉树结构、单叉树结构、标签树结构和单叉标签树结构中的一种。
12.在一个实施例中,从3d金字塔结构的深度中的起始深度开始接收第二语法元素。起始深度可以在比特流中指示或在解码器处推断得到。在一个实施例中,可接收第三语法元素,第三语法元素指示用于接收第二语法元素的起始深度,第二语法元素指示3d金字塔结构中的节点的节点值。当起始深度是3d金字塔结构的最后一个深度时,可使用基于非3d金字塔树的解码方法从比特流中解码得到张量的模型参数。
13.在一个实施例中,可接收第三语法元素,第三语法元素指示用于接收第二语法元素的起始深度,第二语法元素指示3d金字塔结构中的各节点的节点值。当起始深度是3d金字塔结构的最后一个深度时,从3d金字塔结构的深度中的倒数第二深度开始接收第二语法元素。
14.在另一实施例中,可接收第三语法元素,第三语法元素指示用于接收第二语法元素的起始深度,第二语法元素指示3d金字塔结构中的节点的节点值。当起始深度是3d金字塔结构的最后一个深度且3d金字塔结构是与单叉树部分编码和标签树部分编码相关联的单叉标签树结构时,对于单叉树部分编码,从3d金字塔结构的深度中的倒数第二深度开始接收第二语法元素;以及对于标签树部分编码,从3d金字塔结构的深度中的最后一个深度开始接收第二语法元素。
15.在一个实施例中,当一个或多个第一语法元素指示cu3d基于3d金字塔结构来划分时,禁用依赖量化。在一个实施例中,当一个或多个第一语法元素指示cu3d基于3d金字塔结构来划分时,可执行依赖量化构造过程。在基于3d金字塔结构的编码过程期间跳过的张量的模型参数从依赖量化构造过程中排除。
16.在一个实施例中,可接收与cu3d相关联的第四语法元素,第四语法元素指示cu3d的所有模型参数是否统一。在一个实施例中,可使用零值作为张量的内核中的第一系数的
前向邻居的值,来确定用于对内核中的第一系数进行熵解码的上下文模型。在一个实施例中,可以在比特流中接收一个或多个第五语法元素,第五语法元素指示张量的第二ctu3d的宽度或高度。当宽度、高度、或者宽度和高度两者是一个模型参数时,可确定基于基线编码方法对第二ctu3d的模型参数进行解码。
17.在一些示例中,另一神经网络模型解压缩的装置包括处理电路。该处理电路可配置成在神经网络的压缩的神经网络表示的比特流中接收第一语法元素,第一语法元素与从神经网络的层中的张量划分得到的ctu3d相关联。第一语法元素可指示与ctu3d相关联的金字塔树结构的底部深度处的所有子节点是否统一。当第一语法元素指示与ctu3d相关联的金字塔树结构的底部深度处的所有子节点统一时,可基于三维单叉树(3d单叉树)编码方法对ctu3d进行解码。
18.在一个实施例中,可以在比特流中接收与神经网络的层相关联的第二语法元素。第二语法元素可指示是否使用基于金字塔树结构的编码方法对该层进行编码。在一个实施例中,在底部深度处不共享相同父节点的子节点具有不同的统一值。
19.在一个实施例中,可推断3d单叉树编码方法的起始深度为金字塔树结构的底部深度。在一个实施例中,不在比特流中对金字塔树结构的底部深度处的节点的统一标志进行编码。在一个实施例中,可接收在比特流中针对在底部深度处共享相同父节点的所有子节点编码的统一值。可接收在底部深度处共享相同父节点的所有子节点的符号位。在比特流中该符号位跟在统一值之后。
20.在一个实施例中,可从比特流中接收在底部深度处共享相同父节点的每一组子节点的统一值。可接收在底部深度处共享相同父节点的每一组子节点中的子节点的符号位。
21.在一个实施例中,响应于第一语法元素指示与ctu3d相关联的金字塔树结构的底部深度处的所有子节点并非全部统一,可基于三维标签树(3d标签树)编码方法对ctu3d进行解码。在一个实施例中,可推断3d标签树编码方法的起始深度为金字塔树结构的底部深度。
22.在一个实施例中,可根据以下之一对金字塔树结构的底部深度处的节点的值进行解码:接收金字塔树结构的底部深度处的节点的值,在比特流中每个节点的值基于预定扫描顺序进行编码;在比特流中基于预定扫描顺序接收金字塔树结构的底部深度处的每一个节点的绝对值,然后如果绝对值不是零,接收每一个节点的符号,或者在比特流中基于预定扫描顺序接收金字塔树结构的底部深度处的每一个节点的绝对值,然后如果节点具有非零值,则在比特流中基于预定扫描顺序接收金字塔树结构的底部深度处的每一个节点的符号。
23.本公开的各方面还提供一种非暂时性计算机可读介质,非暂时性计算机可读介质存储指令,该指令在由用于神经网络模型解压缩的计算机运行时,使得计算机执行神经网络模型解压缩的方法。
附图说明
24.根据以下详细描述和附图,所公开的主题的其他特征、性质和各种优点将更加明显。附图中:
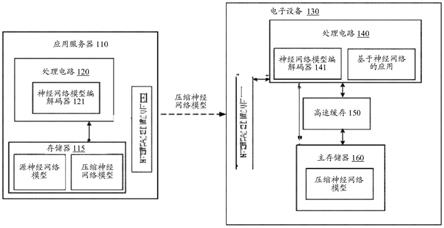
25.图1示出了根据本公开的一个实施例的电子设备(130)的框图。
26.图2示出了示例性压缩神经网络表示(nnr)单元(200)。
27.图3示出了示例性聚合nnr单元(300)。
28.图4示出了示例性nnr比特流(400)。
29.图5示出了示例性nnr单元语法。
30.图6示出了示例性nnr单元报头语法。
31.图7示出了示例性nnr聚合单元报头语法。
32.图8示出了示例性nnr单元有效负载语法。
33.图9示出了示例性nnr模型参数集有效负载语法。
34.图10示出了模型参数集的示例性语法。
35.图11示出了聚合单元报头的示例性语法,其包括用于一个或多个权重张量的编码树单元(ctu)扫描顺序的信令。
36.图12示出了扫描权重张量中的权重系数的语法示例。
37.图13示出了根据本公开的一些实施例的用于对量化的权重系数的绝对值进行解码的示例。
38.图14示出了使用沿着竖直方向的光栅扫描的自适应三维ctu(ctu3d)/三维编码单元(cu3d)划分的两个示例。
39.图15示出了基于3d金字塔结构的示例性划分过程。
40.图16示出了根据本公开的实施例的两个标量量化器。
41.图17示出了根据本公开的一个实施例的ctu划分的解码过程(1700)。
42.图18示出了根据本公开的一个实施例的3d金字塔编码的解码过程(1800)。
43.图19示出了根据本公开的一个实施例的基于统一编码的解码过程(1900)。
44.图20是根据本公开的一个实施例的计算机系统的示意图。
具体实施方式
45.本公开的各方面提供用于神经网络模型压缩/解压缩的各种技术。这些技术涉及编码树单元(ctu)块划分、基于3d金字塔结构的编码以及基于统一的编码。
46.人工神经网络可用于多媒体分析和处理、媒体编码、数据分析和许多其它领域中范围广泛的任务。使用人工神经网络的成功是基于与过去相比处理大得多和复杂的神经网络(深度神经网络,dnn)的可行性以及大规模训练数据集的可用性。因此,已训练的神经网络可包含大量的模型参数,导致相当大的容量(例如,数百mb)。模型参数可包括已训练的神经网络的系数,例如权重、偏差、缩放因子、批归一化(批范数,batchnorm)参数等。这些模型参数可组织成模型参数张量。模型参数张量用于指代将神经网络的相关模型参数组合在一起的多维结构(例如,阵列或矩阵)。例如,当可用时,神经网络中的层的系数可分为权重张量、偏置张量、缩放因子张量、批范数张量等。
47.许多应用需要将特定训练的网络实例潜在地部署到更大数量的设备,这些设备可能在处理能力和存储(例如,移动设备或智能相机)方面存在限制以及在通信带宽方面存在限制。这些应用可受益于本文公开的神经网络压缩/解压缩技术。
48.i.基于神经网络的设备和应用
49.图1示出了根据本公开的一个实施例的电子设备(130)的框图。电子设备(130)可
配置成运行基于神经网络的应用。在一些实施例中,电子设备(130)接收并存储压缩(编码的)神经网络模型(例如,比特流形式的神经网络的压缩表示)。电子设备(130)可对压缩神经网络模型进行解压缩(或解码)以恢复神经网络模型,且可运行基于神经网络模型的应用。在一些实施例中,从诸如应用服务器(110)之类的服务器提供压缩神经网络模型。
50.在图1的示例中,应用服务器(110)包括耦接在一起的处理电路(120)、存储器(115)和接口电路(111)。在一些示例中,适当地生成、训练或更新神经网络。神经网络可作为源神经网络模型存储在存储器(115)中。处理电路(120)包括神经网络模型编解码器(121)。神经网络模型编解码器(121)包括编码器,该编码器可压缩源神经网络模型并生成压缩神经网络模型(神经网络的压缩表示)。在一些示例中,压缩神经网络模型采用比特流的形式。压缩神经网络模型可存储在存储器(115)中。应用服务器(110)可通过接口电路(111)以比特流的形式将压缩神经网络模型提供给其它设备,例如电子设备(130)。
51.应注意,电子设备(130)可以是任何合适的设备,例如智能手机、相机、平板电脑、膝上型计算机、台式计算机、游戏耳机等。
52.在图1的示例中,电子设备(130)包括耦接在一起的处理电路(140)、高速缓存(150)、主存储器(160)和接口电路(131)。在一些示例中,压缩神经网络模型例如以比特流的形式通过接口电路(131)由电子设备(130)接收。压缩神经网络模型存储在主存储器(160)中。
53.处理电路(140)包括任何合适的处理硬件,例如中央处理单元(cpu)、图形处理单元(gpu)等。处理电路(140)包括适合于执行基于神经网络的应用的组件,并包括适合于配置成神经网络模型编解码器(141)的组件。神经网络模型编解码器(141)包括可对例如从应用服务器(110)接收的压缩神经网络模型进行解码的解码器。在一个示例中,处理电路(140)包括单个芯片(例如,集成电路),一个或多个处理器设置在该单个芯片上。在另一示例中,处理电路(140)包括多个芯片,每个芯片可包括一个或多个处理器。
54.在一些实施例中,主存储器(160)具有相对大的存储空间,且可存储各种信息,例如软件代码、媒体数据(例如,视频、音频、图像等)、压缩神经网络模型等。高速缓存(150)具有相对较小的存储空间,但是与主存储器(160)相比具有快得多的存取速度。在一些示例中,主存储器(160)可包括硬盘驱动器、固态驱动器等,高速缓存(150)可包括静态随机存取存储器(sram)等。在一个示例中,高速缓存(150)可以是设置在例如处理器芯片上的片上存储器。在另一示例中,高速缓存(150)可以是设置在与处理器芯片分离的一个或多个存储器芯片上的芯片外存储器。通常,片上存储器相比于芯片外存储器具有更快的存取速度。
55.在一些实施例中,当处理电路(140)执行使用神经网络模型的应用时,神经网络模型编解码器(141)可对压缩神经网络模型进行解压缩以恢复神经网络模型。在一些示例中,高速缓存(150)足够大,因此可将已恢复的神经网络模型缓冲在高速缓存(150)中。然后,处理电路(140)可访问高速缓存(150)以在应用中使用已恢复的神经网络模型。在另一示例中,高速缓存(150)具有有限的存储器空间(例如,片上存储器),压缩神经网络模型可逐层或逐块解压缩,且高速缓存(150)可逐层或逐块缓冲已恢复的神经网络模型。
56.应注意,神经网络模型编解码器(121)和神经网络模型编解码器(141)可通过任何合适的技术来实现。在一些实施例中,编码器和/或解码器可由集成电路实现。在一些实施例中,编码器和解码器可实现为执行存储在非暂时性计算机可读介质中的程序的一个或多
个处理器。神经网络模型编解码器(121)和神经网络模型编解码器(141)可根据下面描述的编码和解码特征来实现。
57.本公开提供用于压缩神经网络表示(nnr)的技术,可用于对神经网络模型例如深度神经网络(dnn)模型进行编码和解码,以节省存储和计算。深度神经网络(dnn)可以在大范围的视频应用中使用,此类视频应用例如语义分类、目标检测/识别、目标跟踪、视频质量增强等。
58.神经网络(或人工神经网络)通常包括输入层和输出层之间的多个层。在一些示例中,神经网络中的一层对应于将该层的输入转换成该层的输出的数学变换。数学变换可以是线性关系或非线性关系。神经网络可移动经过各层,以计算每个输出的概率。这样,每个数学变换被认为是一层,且复数dnn可具有多个层。在一些示例中,层的数学变换可由一个或多个张量(例如,权重张量,偏置张量,缩放因子张量,批范数张量等)表示。
59.ii.神经网络模型压缩的块定义和用途
60.1.高级语法
61.在一些实施例中,可基于nnr单元的概念来定义在压缩或编码表示中携带神经网络(模型)的比特流的高级语法。nnr单元是用于携带神经网络数据和相关元数据的数据结构。nnr单元携带与神经网络元数据、拓扑信息、全部或部分层数据、滤波器、内核、偏差、量化权重、张量等相关的压缩或未压缩信息。
62.图2示出了示例性nnr单元(200)。如图所示,nnr单元(200)可包括以下数据元素:
[0063]-nnr单元大小:该数据元素用信号表示包括nnr单元大小本身的nnr单元总字节大小。
[0064]-nnr单元报头:该数据元素包含与nnr单元类型和相关元数据相关的信息。
[0065]-nnr单元有效负载:该数据元素包含与神经网络相关的压缩或未压缩数据。
[0066]
图3示出了示例性聚合nnr单元(300)。聚合nnr单元(300)是可以在其有效负载中携带多个nnr单元的nnr单元。聚合nnr单元提供数个nnr单元的分组机制,这些nnr单元彼此相关且受益于在单个nnr单元下的聚合。图4示出了示例性nnr比特流(400)。nnr比特流(400)可包括nnr单元的序列。nnr比特流中的第一nnr单元可以是nnr开始单元(即,类型为nnr_str的nnr单元)。
[0067]
图5示出了示例性nnr单元语法。图6示出了示例性nnr单元报头语法。图7示出了示例性nnr聚合单元报头语法。图8示出了示例性nnr单元有效负载语法。图9示出了示例性nnr模型参数集有效负载语法。
[0068]
2.重新成形和扫描顺序
[0069]
在一些示例中,权重张量的维度大于2(例如在卷积层中,维度是4),且权重张量可重新成形为二维(2d)张量。在一个示例中,如果权重张量的维度不超过2(例如完全连接层或偏置层),则不执行重新成形。为了对权重张量进行编码,按照一定顺序对权重张量中的权重系数进行扫描。在一些示例中,权重张量中的权重系数可例如以行优先的方式对每一行从左到右进行扫描以及从顶部行到底部行进行扫描。
[0070]
3.块划分标志
[0071]
在一些实施例中,权重张量可重新成形为2d张量,2d张量随后划分成被称为编码树单元(ctu)的块。然后,可基于所得到的ctu块对2d张量的系数进行编码。例如,可基于这
些ctu块来定义扫描顺序,且可根据扫描顺序来执行编码。在一些其它实施例中,权重张量可重新成形为3d张量,例如,分别使输入通道和输出通道的数量作为第一维度和第二维度,且使内核(滤波器)中的元素的数量作为第三维度。然后,可沿着第一维度和第二维度的平面执行块划分,得到被称为ctu3d的3d块。因此,张量的编码可基于这些ctu3d的扫描顺序来执行。在一些示例中,ctu块或ctu3d块可以是大小相等的块。
[0072]
在一些实施例中,使用与模型相关的语法元素ctu_partition_flag来指定是否对神经网络的每一层的权重张量启用块划分(ctu划分)。例如,语法元素的第一值(例如,值0)指示禁用块划分,且语法元素的第二值(例如,值1)指示启用块划分。在一个实施例中,语法元素是1位标志。在另一实施例中,语法元素可由多个位表示。语法元素的一个值指示是否执行块划分。例如,零值可指示不执行划分。语法元素的其它值可用于指示ctu或ctu3d块的大小。
[0073]
图10示出了模型参数集的示例性语法。模型参数集包括ctu_partition_flag。ctu_parition_flag可用于启动或关闭由模型参数集控制的神经网络模型的块划分。
[0074]
在一些实施例中,与张量相关的语法元素ctu_partition_flag可用于指定是否对神经网络的一个或多个单独权重张量启用块划分(ctu划分)。例如,语法元素的第一值(例如,值0)指示对相应的一个或多个张量禁用块划分,且语法元素的第二值(例如,值1)指示对相应的一个或多个张量启用块划分。在一个实施例中,语法元素是1位标志。在另一实施例中,语法元素可由多个位表示。语法元素的一个值指示是否对相应的一个或多个张量执行块划分。例如,零值可指示不对相应的一个或多个张量执行划分。语法元素的其它值可用于指示从相应的一个或多个张量划分的ctu或ctu3d块的大小。
[0075]
在一个示例中,与张量相关的语法元素ctu_partition_flag包括在压缩数据单元报头中。在一个示例中,与张量相关的语法元素ctu_partition_flag包括在聚合单元报头中。
[0076]
4.ctu维度的信号表示
[0077]
在一个实施例中,当与模型相关的标志ctu_partition_flag具有指示启用块划分的值时,与模型相关的2位max_ctu_dim_flag可用于指定神经网络的权重张量的与模型相关的最大ctu维度(表示为gctu_dim)。例如,gctu可根据下式确定:
[0078]
gctu_dim=(64》》max_ctu_dim_flag)。
[0079]
例如,对应于值为0,1,2或3的max_ctu_dim_flag,gctu_dim可具有值64,32,16和8。
[0080]
在一个实施例中,对于2d重新成形的张量,与张量相关的最大ctu宽度可与每个卷积张量的内核大小成比例地缩放,如下:
[0081]
max_ctu_height=gctu_dim,
[0082]
max_ctu_width=gctu_dim*kernel_size。
[0083]
右侧/底部ctu的高度/宽度可小于max_ctu_height/max_ctu_width。应注意,max_ctu_dim_flag的位数可改变成其它值(例如,大于2位)。可使用涉及max_ctu_dim_flag的其它映射函数来计算gctu_dim。max_ctu_width可以不与kernel_size成比例地缩放(例如,用于划分ctu3d块)。或者,max_ctu_width可与任何任意值成比例地缩放,以形成具有各种大小的合适的2d或3d块。
[0084]
在另一实施例中,当与模型相关或张量相关的标志ctu_partition_flag具有指示启用块划分的值时,与张量相关的2位max_ctu_dim_flag可用于根据下式指定神经网络的相应权重张量的与张量相关的最大ctu维度:
[0085]
gctu_dim=(64》》max_ctu_dim_flag)。
[0086]
在一个实施例中,与张量相关的最大ctu宽度可与每个卷积张量的内核大小成比例地缩放,如下:
[0087]
max_ctu_height=gctu_dim,
[0088]
max_ctu_width=gctu_dim*kernel_size。
[0089]
类似地,右侧/底部ctu的高度/宽度可小于max_ctu_height/max_ctu_width。与张量相关的max_ctu_dim_flag的位数可改变成其它值(例如,大于2位)。可使用涉及与张量相关的max_ctu_dim_flag的其它映射函数来计算gctu_dim。max_ctu_width可以不与kernel_size成比例地缩放(例如,用于划分ctu3d块)。max_ctu_width可与任意值成比例地缩放,以形成具有各种大小的合适的2d或3d块。
[0090]
5.ctu扫描顺序
[0091]
在一些实施例中,与张量相关的语法元素ctu_scan_order用于指定相应的一个或多个张量的与ctu相关的(或ctu3d)扫描顺序。例如,与张量相关的语法元素ctu_scan_order的第一值(例如,值0)指示与ctu相关的扫描顺序是沿着水平方向的光栅扫描顺序。与张量相关的语法元素ctu_scan_order的第二值(例如,值1)指示与ctu相关的扫描顺序是沿着竖直方向的光栅扫描顺序。在一个示例中,与张量相关的语法元素ctu_scan_order包括在压缩数据单元报头中。在一个示例中,与张量相关的语法元素ctu_scan_order包括在聚合单元报头中。
[0092]
在一个实施例中,当与模型相关的语法元素标志ctu_partition_flag具有指示启用块(ctu)划分的值时,与张量相关的语法元素ctu_scan_order包括在语法表中。
[0093]
图11示出了聚合单元报头的示例性语法,其包括用于一个或多个权重张量的ctu扫描顺序的信令。在行(1101),对多个nnr单元执行for循环。多个nnr单元中的每一个可包括例如权重张量。对于多个nnr单元中的每一个,当ctu_partition_flag具有指示启用ctu划分的值(行(1102))时,可接收ctu_scan_order[i],其中i可以是多个nnr单元中的每一个的索引。ctu_partition_flag可以是与模型相关的语法元素。
[0094]
另外,在行(1102),可以为一个或多个nnr单元中的每一个接收语法元素quant_bitdepth[i]。quant_bitdepth[i]可指定nnr聚合单元中的每个张量的量化系数的最大位深度。
[0095]
在另一实施例中,当与张量相关的语法元素标志ctu_partition_flag具有指示对相应的一个或多个张量启用块(ctu)划分的值时,与张量相关的语法元素ctu_scan_order包括在语法表中。
[0096]
6.标志依赖性
[0097]
在一个示例中,ctu_partition_flag定义成与模型相关的标志。ctu_scan_order标志放置在nnr_aggregate_unit_header部分(例如,在图11的示例中)。ctu_partition_flag放置在nnr_aggregate_unit内的nnr_model_parameter_set_payload部分。nnr_aggregate_unit_header可以在nnr_model_parameter_set_payload之前序列化,这使得不
可能对ctu_scan_order进行解码。
[0098]
为了解决该问题,在一个示例中,可以在任意nnr_aggregate_unit之前串行地布置与模型相关的nnr_unit。ctu_partition_flag和max_ctu_dim_flag可包括在该nnr_unit中。因此,跟在nnr_unit之后的nnr聚合单元可使用在nnr_unit中定义的任意信息。
[0099]
iii.用于神经网络模型压缩的3d金字塔编码
[0100]
1.扫描顺序
[0101]
图12示出了扫描权重张量中的权重系数的语法示例。例如,权重张量的维度大于2(例如在卷积层中,维度是4),且权重张量可重新成形为二维张量。在一个示例中,如果权重张量的维度不超过2(例如完全连接层或偏置层),则不执行重新成形。为了对权重张量进行编码,按照一定顺序对权重张量中的权重系数进行扫描。在一些示例中,权重张量中的权重系数可例如以行优先的方式对每一行从左到右进行扫描以及从顶部行到底部行进行扫描。
[0102]
在图12的示例中,2d整数阵列statetranstab[][]指定用于依赖标量量化的状态转换表,且可如下配置:
[0103]
statetranstab[][]={{0,2},{7,5},{1,3},{6,4},{2,0},{5,7},{3,1},{4,6}}。
[0104]
2.量化
[0105]
在各种实施例中,可使用三种类型的量化方法:基线量化方法、基于码本的量化方法以及依赖标量量化(dependent scalar quantization)方法。
[0106]
在基线量化方法中,均匀量化可使用固定步长来应用于模型参数张量(或参数张量)。在一个示例中,固定步长可由参数qpdensity和qp表示。表示为dq_flag的标志可用于启用均匀量化(例如,dq_flag等于0)。解码张量中的重建值可以是步长的整数倍。
[0107]
在基于码本的方法中,模型参数张量可表示为索引的张量和码本,索引的张量具有与原始张量相同的形状。码本的大小可以在编码器处选择并作为元数据参数发送。索引具有整数值,且可进一步被熵编码。在一个示例中,码本由浮点32位值组成。解码张量中的重建值是由这些解码张量的索引值指代的码本元素的值。
[0108]
在依赖标量量化方法中,依赖标量量化可使用固定步长和大小为8的状态转换表来应用于参数张量,固定步长例如由参数qpdensity和qp表示。表示为dq_flag的标志等于1,则可用于启用依赖标量量化。解码张量中的重建值是步长的整数倍。
[0109]
3.熵编码
[0110]
为了对量化的权重系数进行编码,可使用熵编码技术。在一些实施例中,量化的权重系数的绝对值在包括一元序列的序列中编码,该一元序列可跟随有固定长度序列。
[0111]
在一些示例中,权重系数在层中的分布通常遵循高斯分布,且具有大值的权重系数的比例非常小,但是权重系数的最大值可以非常大。在一些实施例中,可使用一元编码对非常小的值进行编码,且可基于golomb编码对较大值进行编码。例如,当不使用golomb编码时,使用被称为maxnumnorem的整数参数来指示最大数。当量化的权重系数不大于(例如,等于或小于)maxnumnorem时,量化的权重系数可通过一元编码来编码。当量化的权重系数大于maxnumnorem时,量化的权重系数的、等于maxnumnorem的部分通过一元编码来编码,且量化的权重系数的其余部分通过golomb编码来编码。因此,一元序列包括一元编码的第一部分和用于对指数golomb剩余位进行编码的第二部分。
[0112]
在一些实施例中,量化的权重系数可通过以下两个步骤来编码。
[0113]
在第一步骤中,对于量化的权重系数,对二进制语法元素sig_flag进行编码。二进制语法元素sig_flag指定量化的权重系数是否等于0。如果sig_flag等于1(表示量化的权重系数不等于0),则进一步对二进制语法元素sign_flag进行编码。二进制语法元素sign_flag指示量化的权重系数是正还是负。
[0114]
在第二步骤中,量化的权重系数的绝对值可编码成包括一元序列的序列,该一元序列可跟随有固定长度序列。当量化的权重系数的绝对值等于或小于maxnumnorem时,该序列包括量化的权重系数的绝对值的一元编码。当量化的权重系数的绝对值大于maxnumnorem时,一元序列可包括用于使用一元编码对maxnumnorem进行编码的第一部分和用于对指数golomb剩余位进行编码的第二部分,且固定长度序列用于对固定长度余数进行编码。
[0115]
在一些示例中,首先应用一元编码。例如,诸如j的变量初始化为0,且另一变量x设置为j+1。对语法元素abs_level_greater_x进行编码。在一个示例中,当量化的权重水平的绝对值大于变量x时,abs_level_greater_x设置为1,一元编码继续;否则,abs_level_greater_x设置为0,一元编码完成。当abs_level_greater_x等于1且变量j小于maxnumnorem时,变量j加1,且变量x也加1。然后,对另一语法元素abs_level_greater_x进行编码。该过程继续,直到abs_level_greater_x等于0或变量j等于maxnumnorem。当变量j等于maxnumnorem时,编码位是一元序列的第一部分。
[0116]
当abs_level_greater_x等于1且j等于maxnumnorem时,继续以golomb编码来进行编码。具体地,变量j重置为0,且x设置为1《《j。可根据量化的权重系数的绝对值减去maxnumnorem来计算一元编码余数。对语法元素abs_level_greater_thanx进行编码。在一个示例中,当一元编码余数大于变量x时,abs_level_greater_x设置为1;否则,abs_level_greater_x设置为0。如果abs_level_greater_x等于1,则变量j加1,1《《j与x相加,且对另一abs_level_greater_x进行编码。该过程继续,直到abs_level_greater_x等于0,因此对一元序列的第二部分进行编码。当abs_level_greater_x等于0时,一元编码余数可以是这些值(x,x-1,
…
x-(1《《j)+1)之一。长度j的代码可用于对指向(x,x-1,
…
x-(1《《j)+1)中的一个值的索引进行编码,该代码可称为固定长度余数。
[0117]
图13示出了根据本公开的一些实施例的用于对量化的权重系数的绝对值进行解码的示例。在图13的示例中,quantweight[i]表示阵列中第i个位置处的量化的权重系数;sig_flag指定量化的权重系数quantweight[i]是否不为0(例如,sig_flag为0指示quantweight[i]为0);sign_flag指定量化的权重系quantweight[i]是正还是负(例如sign_flag为1指示quantweight[i]为负);abs_level_greater_x[j]指示quantweight[i]的绝对水平(absolute level)是否大于j+1(例如,一元序列的第一部分);abs_level_greater_x2[j]包括指数golomb余数的一元部分(例如,一元序列的第二部分);以及abs_remainder指示固定长度余数。
[0118]
根据本公开的一方面,上下文建模(context modeling)方法可用于对三个标志sig_flag、sign_flag和abs_level_greater_x进行编码。因此,具有相似统计行为的标志可与相同的上下文模型相关联,使得概率估计器(在上下文模型内部)可适应于基本统计。
[0119]
在一个示例中,根据左侧相邻的量化的权重系数是0、小于0还是大于0,上下文建
模方法对sig_flag使用三个上下文模型。
[0120]
在另一示例中,根据左侧相邻的量化的权重系数是0、小于0还是大于0,上下文模型方法对sign_flag使用三个其它上下文模型。
[0121]
在另一示例中,对于abs_level_greater_x个标志中的每一个,上下文建模方法使用一个或两个单独的上下文模型。在一个示例中,当x≤maxnumnorem时,根据sign_flag使用两个上下文模型。在一个示例中,当x》maxnumnorem时,仅使用一个上下文模型。
[0122]
4.ctu3d和递归cu3d块划分
[0123]
在一些实施例中,模型参数张量可划分成ctu3d块,每个块进一步划分成3d编码单元(cu3d)块。cu3d可进一步基于金字塔结构进行划分和编码。例如,金字塔结构可以是3d八叉树、3d单叉树、3d标签树或3d单叉标签树结构。在特定训练/重新训练操作之后,权重系数可具有局部结构。利用3d八叉树、3d单叉树、3d标签树和/或3d单叉标签树结构的编码方法可通过使用ctu3d/cu3d块的局部分布来生成更有效的表示。这些基于金字塔结构的方法可与基线方法(即,基于非金字塔结构的编码方法)协调。
[0124]
典型地,对于布局为[r][s][c][k]的卷积层,权重张量(或模型参数张量)的维度可以是4;对于布局为[c][k]的完全连接层,维度可以是2;以及对于偏置和批范数层,维度可以是1。r和s表示卷积内核大小(宽度和高度),c表示输入特征大小,k表示输出特征大小。
[0125]
在一个实施例中,对于卷积层,2d[r][s]维度可重新成形为1d[rs]维度,使得4d张量[r][s][c][k]重新成形为3d张量[rs][c][k]。完全连接层被视为其中r=s=1的3d张量的特例。
[0126]
在一个实施例中,可沿着[c][k]平面通过不重叠的较小块(ctu3d)划分3d张量[rs][c][k]。每个ctu3d具有[rs][ctu3d_height][ctu3d_width]的形状,其中,在一个示例中,ctu3d_height=max_ctu3d_height且ctu3d_width=max_ctu3d_width。对于位于张量右侧和/或底部的ctu3d,其ctu3d_height是c/max_ctu3d_height的余数,其ctu3d_width是k/max_ctu3d_width的余数。
[0127]
在一个实施例中,max_ctu3d_height和max_ctu3d_width的值可以在比特流中显式地用信号表示,或者可以隐式地推断得到。在一个示例中,当max_ctu3d_height=c且max_ctu3d_width=k时,禁用块划分。
[0128]
在一个实施例中,可使用四叉树结构来执行简化块结构,其中ctu3d/cu3d递归地划分成更小的cu3d,直到达到最大递归深度。从ctu3d节点开始,可使用深度优先的四叉树扫描顺序来扫描和处理cu3d块的这个四叉树。使用沿着水平方向或竖直方向的光栅扫描顺序来扫描和处理相同父节点下的子节点。
[0129]
图14示出了使用沿着竖直方向的光栅扫描的自适应ctu3d/cu3d划分的两个示例。
[0130]
在一个实施例中,对于给定四叉树深度的cu3d,使用以下公式计算这些cu3d的max_cu3d_height/max_cu3d_width。
[0131]
max_cu3d_height=max_ctu3d_height》》depth
[0132]
max_cu3d_width=max_ctu3d_width》》depth
[0133]
当max_cu3d_height和max_cu3d_width均小于或等于预定阈值时,达到最大递归深度。该阈值可显式地包括在比特流中,或者可以是可由解码器隐式地推断得到的预定数(例如8)。当预定阈值是ctu3d的大小时,禁用该递归划分。
[0134]
在一个实施例中,基于率失真(rd,rate-distortion)的编码算法决定是否将父cu3d拆分成多个较小的子cu3d。如果这些较小的子cu3d的组合rd小于来自父cu3d的rd,则将父cu3d拆分成多个较小的子cu3d。否则,不会进一步拆分该父cu3d。定义拆分标志以记录相应的拆分决定。可以在cu划分的最后一个深度跳过该标志。
[0135]
在一个实施例中,基于四叉树结构执行递归cu3d块划分操作,以将ctu3d划分成cu3d块,且定义拆分标志以记录四叉树结构中的节点处的每个拆分决定。
[0136]
在另一实施例中,在ctu3d块中不执行递归cu3d块划分操作,且不定义用于记录拆分决定的拆分标志。在这种情况下,cu3d块与ctu3d块相同。
[0137]
5.3d金字塔结构
[0138]
在各种实施例中,金字塔结构(或3d金字塔结构)可以是树数据结构,其中每个内部节点可具有8个子节点。3d金字塔结构可用于通过沿着z、y和x轴递归地将3d张量(或诸如ctu3d或cu3d之类的子块)细分成8个八分体,来划分3d张量。
[0139]
图15示出了基于3d金字塔结构的示例性划分过程。如图15所示,3d八叉树(1505)是树数据结构,其中每个内部节点(1510)恰好具有8个子节点(1515)。3d八叉树(1505)用于通过沿着z、y和x轴递归地将三维张量(1520)细分成8个八分体(1525),来划分三维张量(1520)。在3d八叉树(1505)的最后一个深度处的节点可以是具有2
×2×
2个系数的大小的块。
[0140]
在各种实施例中,可采用不同的方法来构造3d金字塔结构,以表示在编码器侧或解码器侧的cu3d中的系数。
[0141]
在一个实施例中,可如下构造用于cu3d的3d八叉树。在最后一个深度处的3d八叉树位置的节点值1指示对应节点中的码本索引(在使用码本编码方法的情况下)或系数(在使用直接量化编码方法的情况下)不为0。在底部深度处的3d八叉树位置的节点值0指示对应节点中的码本索引或系数为0。在其它深度处的3d八叉树位置的节点值定义为其8个子节点的最大值。
[0142]
在一个实施例中,可如下构造用于cu3d的3d单叉树。在除了最后一个深度之外的深度处的3d单叉树位置的节点值1指示其子节点(及子节点的子节点,包括在最后一个深度处的节点)具有不统一(不同)的值;在除了最后一个深度之外的深度处的3d单叉树位置的节点值0指示其所有子节点(及子节点的子节点,包括在最后一个深度处的节点)具有统一(相同)的值。
[0143]
在一个实施例中,可如下构造用于cu3d的3d标签树。在最后一个深度处的3d标签树位置的节点值指示对应cu3d中的码本索引(在使用码本编码方法的情况下)或绝对系数(在使用直接量化编码方法的情况下)的绝对值不为0。在其它深度处的3d标签树位置的节点值定义为其8个子节点的最小值。在另一实施例中,在其它深度处的3d标签树位置的节点值可定义为其8个子节点的最大值。
[0144]
在一个实施例中,通过组合3d标签树和3d单叉树来构造cu3d的3d单叉标签树。
[0145]
应注意,对于具有不同深度/高度/宽度的一些cu3d块,可存在不足以构造完整3d金字塔的系数,在完整3d金字塔中所有父节点的全部8个子节点都可用。如果父节点不具有全部8个子节点,则可跳过这些不存在的子节点的扫描和编码。
[0146]
6.3d金字塔扫描顺序
[0147]
在构造3d金字塔之后,可使用预定扫描顺序行经所有节点,以在编码器侧对节点值进行编码或者在解码器侧对节点值进行解码。
[0148]
在一个实施例中,从顶部节点开始,可采用深度优先搜索扫描顺序行经所有节点。可任意定义共享相同父节点的子节点的扫描顺序,例如(0,0,0)-》(0,0,1)-》(0,1,0)-》(0,1,1)-》(1,0,0)-》(1,0,1)-》(1,1,0)-》(1,1,1)。
[0149]
在另一实施例中,从顶部节点开始,可采用广度优先搜索行经所有节点。因为每个金字塔深度是3d形状,所以可任意定义每个深度中的扫描顺序。在一个实施例中,使用以下伪代码定义扫描顺序,以与金字塔编码方法对齐:
[0150][0151][0152]
在另一实施例中,可采用encoding_start_depth语法元素来指示参与编码或解码过程的第一深度。当使用预定扫描顺序行经所有节点时,如果该节点的深度大于encoding_start_depth,则跳过当前节点值的编码。多个cu3d、ctu3d、层或模型可共享一个encoding_start_depth。该语法元素可以在比特流中显式地用信号表示,或者预定义且隐式地推断得到。
[0153]
在一个实施例中,encoding_start_depth在比特流中显式地用信号表示。在另一实施例中,encoding_start_depth预定义且隐式地推断得到。在另一实施例中,encoding_start_depth设置为3d金字塔结构的最后一个深度且隐式地推断得到。
[0154]
7.3d金字塔编码方法
[0155]
在解码器侧,在构造3d金字塔结构之后,可执行相应的编码方法以行经所有节点并对由不同3d树表示的系数进行编码。在解码器侧,对应于不同的编码方法,可相应地对已编码的系数进行解码。
[0156]
对于3d八叉树,如果父节点的值为0,则跳过其子节点(及子节点的子节点)的扫描和编码,原因是子节点的值应该总是为0。如果父节点的值是1,且除了最后一个子节点之外的所有子节点的值都是0,则可扫描最后一个子节点,但是可跳过对最后一个子节点的值的编码,原因是最后一个子节点的值应该总是为1。如果当前深度是金字塔的最后一个深度且如果当前节点值是1,则在不使用码本方法时对地图值的符号进行编码,然后对地图值(量化值)本身进行编码。
[0157]
对于3d单叉树,在一个实施例中,可对给定节点的值进行编码。如果节点值为0,则可对相应的统一值进行编码,且可跳过其子节点(及子节点的子节点)的编码,原因是子节点的绝对值应该总是等于该统一值。可扫描子节点,直到到达底部深度,其中如果节点值不为0,则可对每个子节点的符号位进行编码。
[0158]
对于3d单叉树,在另一实施例中,可对给定节点的值进行编码。如果节点值为0,则
可对与之对应的统一值进行编码,且可跳过其子节点(及子节点的子节点)的编码,原因是子节点的绝对值应该总是等于该统一值。且在处理该cu3d中的所有节点之后,可再次扫描金字塔结构,如果节点值不为0,则可对底部深度处的每个子节点的符号位进行编码。
[0159]
对于3d标签树,如果节点是不具有父节点的顶部节点,则可对该节点的值进行编码。对于任何子节点,可对父节点和该子节点之间的差值进行编码。如果父节点的值是x且除了最后一个子节点之外的所有子节点的值大于x,则可扫描最后一个子节点,但是可跳过对最后一个子节点的值的编码,原因是最后一个子节点的值应该总是为x。
[0160]
对于3d单叉标签树,首先可对来自单叉树的给定节点的值进行编码。然后,如果节点是不具有父节点的顶部节点,则可使用标签树编码方法来对标签树值进行编码,或者对父节点和该子节点之间的标签树值之差进行编码。还采用在标签树编码部分中引入的节点跳过方法。如果单叉树节点值为0,则可跳过其子节点(及子节点的子节点)的扫描和编码,原因是子节点的值应该总是等于统一值。
[0161]
在一个实施例中,当encoding_start_depth是最后一个深度时,可禁用本文描述的这些系数跳过方法,以对所有系数进行编码。在一个示例中,可以在解码器侧的比特流中接收语法元素,该语法元素指示3d金字塔结构中的起始深度。当起始深度是3d金字塔结构的最后一个深度时,可使用基于非3d金字塔树的解码方法从比特流中解码模型参数张量的模型参数。
[0162]
在另一实施例中,当encoding_start_depth是最后一个深度时,为了利用本文描述的这些系数跳过方法,可通过调节起始深度使得起始深度是倒数第二深度,来对3d金字塔树进行编码。在一个示例中,可以在解码器处的比特流中接收指示3d金字塔结构中的起始深度的语法元素。当起始深度是3d金字塔结构的最后一个深度时,解码处理可以在解码器处从3d金字塔结构的深度中的倒数第二深度开始。
[0163]
在另一实施例中,当encoding_start_depth是最后一个深度时,对于3d单叉标签树,可通过调节encoding_start_depth使得encoding_start_depth是倒数第二深度,来对3d金字塔树的单叉树部分进行编码。3d金字塔树的标签树部分可以在不调节encoding_start_depth的情况下编码。在一个示例中,可以在解码器的比特流中接收指示3d金字塔结构中的起始深度的语法元素。当起始深度是3d金字塔结构的最后一个深度且3d金字塔结构是与单叉树部分编码和标签树部分编码相关联的单叉标签树结构时,可以如下在解码器处执行解码处理。对于单叉树部分编码,解码处理可从3d金字塔结构的深度中的倒数第二深度开始。对于标签树部分编码,解码处理可从3d金字塔结构的深度中的最后一个深度开始。
[0164]
8.依赖量化
[0165]
在一些实施例中,依赖标量量化方法用于神经网络参数近似。相关的熵编码方法可用于与量化方法协作。该方法引入量化的参数值之间的依赖性,这减少了参数近似过程中的失真。另外,可以在熵编码阶段利用依赖性。
[0166]
在依赖量化中,神经网络参数(例如,权重参数)的容许重建值取决于按照重建顺序在前的神经网络参数的所选量化索引。该方法的主要效果是:与传统标量量化相比,容许重建向量(由层的所有重建的神经网络参数给出)在n维向量空间中更密集地聚集(n表示层中的参数的数量)。这意味着,对于每n维单位体积下的容许重建向量的给定平均数,输入向量和最接近的重建向量之间的平均距离(例如,均方误差(mse,mean squared error)或平
均绝对误差(mae,mean absolute error)失真)减小(对于输入向量的典型分布而言)。
[0167]
在依赖量化处理中,由于重建值之间的依赖性,使得可以以扫描顺序重建参数(扫描顺序与对参数进行熵解码的顺序相同)。然后,可通过定义具有不同重建水平的两个标量量化器以及定义用于在两个标量量化器之间进行切换的过程,来实现依赖标量量化的方法。因此,对于每个参数,可存在两个可用的标量量化器,如图16所示。
[0168]
图16示出了根据本公开的实施例使用的两个标量量化器。第一量化器q0将神经网络参数水平(从点下方-4至4的数字)映射成量化步长δ的偶数倍。第二量化器q1将神经网络参数水平(从-5至5的数字)映射成量化步长δ的奇数倍或映射成0。
[0169]
对于量化器q0和q1,可用的重建水平的位置由量化步长δ唯一指定。两个标量量化器q0和q1的特征如下:
[0170]
q0:第一量化器q0的重建水平由量化步长δ的偶数倍给出。当使用该量化器时,根据下式计算重建的神经网络参数t
′
:
[0171]
t
′
=2
·k·
δ,
[0172]
其中k表示相关联的参数水平(发送的量化索引)。
[0173]
q1:第二量化器q1的重建水平由量化步长δ的奇数倍和等于零的重建水平给出。神经网络参数水平k到重建参数t
′
的映射由下式指定:
[0174]
t
′
=(2
·
k-sgn(k))
·
δ,
[0175]
其中sgn(
·
)表示符号函数
[0176][0177]
代替在比特流中显式地用信号表示当前权重参数所使用的量化器(q0或q1),量化器由按照编码/重建顺序在当前权重参数之前的权重参数水平的奇偶性确定。量化器之间的切换通过由表1表示的状态机来实现。状态具有8个可能的值(0,1,2,3,4,5,6,7),且由按照编码/重建顺序在当前权重参数之前的权重参数水平的奇偶性唯一确定。对于每一层,状态变量初始设置为0。当重建权重参数时,随后根据表1更新状态,其中k表示变换系数水平的值。下一个状态取决于当前状态和当前权重参数水平k的奇偶性(k&1)。因此,可通过下式获得状态更新:
[0178]
state=sttab[state][k&1]
[0179]
其中sttab表示表1。
[0180]
表1示出了用于确定用于神经网络参数的标量量化器的状态转换表,其中k表示神经网络参数的值:
[0181]
表1
[0182][0183]
状态唯一指定所使用的标量量化器。如果当前权重参数的状态值是偶数(0,2,4,6),则使用标量量化器q0。否则,如果状态值是奇数(1,3,5,7),则使用标量量化器q1。
[0184]
在一些实施例中,可采用基线编码方法(其中不使用基于3d金字塔结构的编码/解码方法)。在基线编码方法中,可根据扫描顺序扫描模型参数张量的所有系数并对所有系数进行熵编码。对于与基线编码方法组合使用的依赖量化处理,可以以扫描顺序重构系数(扫描顺序与对系数进行熵解码的顺序相同)。
[0185]
由于本文描述的3d金字塔编码方法的性质,可从熵编码过程中跳过模型参数张量中的某些系数。因此,在一个实施例中,当使用3d金字塔编码方法时,可禁用依赖量化处理(依赖量化处理在模型参数张量中的所有系数上操作)。
[0186]
在另一实施例中,当使用3d金字塔编码方法时,可启用依赖量化处理。例如,可修改依赖量化构造过程,使得如果从熵编码处理跳过这些系数,则这些系数可从依赖量化系数的构造过程中排除。在一个示例中,当一个或多个语法元素指示基于3d金字塔结构划分cu3d时,可以对cu3d执行依赖量化构造过程。在基于3d金字塔结构的编码过程期间跳过的cu3d的模型参数从依赖量化构造过程中排除。
[0187]
在另一实施例中,在依赖量化中使用系数的绝对值。
[0188]
9.熵编码的上下文
[0189]
在一些实施例中,当不使用依赖量化时,可以如下执行上下文建模。
[0190]
对于基于3d八叉树的编码方法中表示为oct_flag的八叉树节点值和表示为sign的符号,表示为ctx的上下文模型索引可根据下式确定:
[0191]
oct_flag:
[0192]
int p0=(z》=1)?oct[d][z-1][y][x]:0;
[0193]
int p1=(z》=2)?oct[d][z-2][y][x]:0;
[0194]
int ctx=(p0==p1)?!!p0:2;
[0195]
sign:
[0196]
int p0=(z》=1)?map[z-1][y][x]:0;
[0197]
int ctx=(p0==0)?0:(p0《0)?1:2。
[0198]
在上述计算中,oct[d][z][y][x]表示在深度d处在位置[z][y][x]处的节点值;map[z][y][x]表示在位置[z][y][x]处的量化值。
[0199]
对于基于3d单叉树的编码方法中表示为nz_flag的非零标志和表示为sign的符号,表示为ctx的上下文模型索引可根据下式确定:
[0200]
nz_flag:
[0201]
int p0=(last_depth&&map_z》=1)?std::abs(map[map_z-1][map_y][map_x]):0;
[0202]
int ctx=(p0==0)?0:1;
[0203]
sign:
[0204]
int p0=(z》=1)?map[z-1][y][x]:0;
[0205]
int ctx=(p0==0)?0:(p0《0)?1:2。
[0206]
对于基于3d标签树的编码方法,表示为nz_flag的非零标志和表示为sign的符号的、表示为ctx的上下文模型索引可根据下式确定:
[0207]
nz_flag:
[0208]
int p0=(z》=1)?tgt[d][z-1][y][x]:0;
[0209]
int p1=(z》=2)?tgt[d][z-2][y][x]:0;
[0210]
int ctx=(p0==p1)?!!p0:2;
[0211]
sign:
[0212]
int p0=(z》=1)?tgt[d][z-1][y][x]:0;
[0213]
int ctx=(p0==0)?0:(p0《0)?1:2。
[0214]
其中tgt[d][z][y][x]表示在深度d处在位置[z][y][x]处的节点值。
[0215]
对于3d单叉标签树,表示为nz_flag的非零标志和表示为sign的符号的、表示为ctx的上下文模型索引可根据下式确定:
[0216]
nz_flag:
[0217]
int p0=(z》=1)?tgt[d][z-1][y][x]:0;
[0218]
int p1=(z》=2)?tgt[d][z-2][y][x]:0;
[0219]
int ctx=(p0==p1)?!!p0:2;
[0220]
sign:
[0221]
int p0=(z》=1)?map[z-1][y][x]:0;
[0222]
int ctx=(p0==0)?0:(p0《0)?1:2。
[0223]
在一个示例中,当使用依赖量化时,可调节nz_flag的上下文建模,使得ctx=ctx+3*state_id。
[0224]
10.语法清理
[0225]
可以使cu3d中的所有系数统一。在一个实施例中,可以在cu3d报头中定义uaflag以指示cu3d中的所有系数是否统一。在一个示例中,uaflag的值=1指示该cu3d中的所有系数统一。
[0226]
在一个实施例中,可定义ctu3d_map_mode_flag以指示ctu3d中的所有cu3d块是否共享相同map_mode。如果ctu3d_map_mode_flag=1,则用信号表示map_mode。应注意,还可隐式地推断该标志(为0)。
[0227]
在一个实施例中,可定义enable_start_depth以指示cu3d编码是否可从除了底部深度之外的深度开始。如果enable_start_depth=1,则用信号表示start_depth(或encoding_start_depth)。应注意,还可隐式地推断该标志(为1)。
[0228]
在一个实施例中,可定义enable_zdep_reorder标志以指示是否允许zdep_array重新排序。应注意,还可隐式地推断该标志(为0)。
[0229]
11.基线编码方法与金字塔编码方法的协调
[0230]
在基线方法中,权重张量可重新成形为具有[output_channel][input_channel*内核大小]的形状的2d矩阵。同一内核中的系数存储在连续的存储器位置中。当计算sig_flag和sign_flag的上下文时,相邻系数定义为在当前系数之前处理的最后一个系数。例如,一个内核中的第一系数的相邻系数是前一个内核中的最后一个系数。
[0231]
在一个实施例中,为了计算上下文模型索引,对于一个内核中的第一系数,其相邻系数的值设置为0,而不是前一个内核中的最后一个系数的值设置为0。
[0232]
在一个实施例中,在3d金字塔编码处理期间,如果量化模式不是码本模式,且如果start_depth是最后一个金字塔深度,则选择基线编码方法,计算其rd并与其它模式(例如,基于3d金字塔结构的编码方法)进行比较。
[0233]
在一个实施例中,如果ctu3d_width和/或ctu3d_height是1,则自动选择基线编码方法。
[0234]
12.3d金字塔编码的语法表
[0235]
在本公开的附录b中,列出语法表表2至表17,作为本文公开的基于3d金字塔结构的编码方法的示例。在所列出的语法表中引入的语法元素在每个相应语法表的末尾处定义。
[0236]
13.用于神经网络模型压缩的基于统一的编码方法
[0237]
在一些实施例中,可采用基于统一的编码方法。可对卷积和完全连接层定义layer_uniform_flag标志,以指示是否使用基于3d金字塔结构的编码方法对该层进行编码。在一个示例中,如果layer_uniform_flag标志等于第一值(例如,0),则使用基线方法对该层进行编码。
[0238]
如果layer_uniform_flag等于第二值(例如,1),则可使用基于3d金字塔结构的编码方法。例如,该层可重新成形为ctu3d布局。对于每个ctu3d,可定义ctu3d_uniform_flag标志,以指示在底部深度处共享相同父节点的所有子节点是否统一(不共享相同父节点的节点可具有不同的统一值)。
[0239]
如果对于该ctu3d,ctu3d_uniform_flag标志等于第一值(例如,1),则在底部深度处共享相同父节点的所有子节点统一(不共享相同父节点的节点可具有不同的统一值),在一个实施例中,3d单叉树编码方法可用于对该ctu3d进行编码。encoding_start_depth设置为3d金字塔结构(例如,与cu3d或ctu3d相关联)的最后一个深度且隐式地推断得到。可跳过节点的统一值的编码,原因是该节点的统一值应该总是为0。
[0240]
在一个实施例中,对于在底部深度处共享相同父节点的所有子节点,可对一个统一值进行编码,如果节点值不为0,则随后对这些子节点的符号位进行编码。在另一实施例中,对于在底部深度处共享相同父节点的所有子节点,可对一个统一值进行编码。且在处理该cu3d中的所有节点之后,如果节点值不为0,则可再次扫描金字塔(金字塔结构)以对底部
深度处的每个子节点的符号位进行编码。
[0241]
在一个实施例中,如果ctu3d_uniform_flag标志等于第二值(例如,0),则可使用3d标签树编码方法对该ctu3d进行编码。encoding_start_depth设置为3d金字塔结构(例如,与cu3d或ctu3d相关联)的最后一个深度且隐式地推断得到。
[0242]
在一个实施例中,可基于预定扫描顺序对每个子节点的值进行编码。在另一个实施例中,可基于预定扫描顺序对每个子节点的绝对值进行编码,然后对每个子节点的符号位进行编码。在另一实施例中,可基于预定扫描顺序对所有子节点的绝对值进行编码。且在处理该cu3d中的所有节点之后,如果节点值不为0,则可对所有子节点的符号位进行编码。
[0243]
14.基于统一的编码的语法表
[0244]
在本公开的附录c中,列出语法表表18至表21,作为本文公开的基于统一的编码方法的示例。在所列出的语法表中引入的语法元素在每个相应语法表的末尾处定义。
[0245]
iv.编码过程的示例
[0246]
图17示出了根据本公开的一个实施例的ctu划分的解码过程(1700)。过程(1700)可从(s1701)开始并前进到(s1710)。
[0247]
在(s1710),可以从比特流中接收nnr聚合单元的nnr聚合单元报头中的第一语法元素。第一语法元素可指示用于处理nnr聚合单元中传输的模型参数张量的ctu扫描顺序。例如,第一语法元素的第一值可指示ctu扫描顺序是沿着水平方向的第一光栅扫描顺序。第一语法元素的第二值可指示ctu扫描顺序是沿着竖直方向的第二光栅扫描顺序。
[0248]
在一个示例中,可预先接收另一语法元素,以控制是否对nnr聚合单元中的张量启用ctu块划分。例如,该另一语法元素可以是与模型相关的语法元素或者与张量相关的语法元素,与模型相关的语法元素用于指定是否对神经网络的层启用ctu块划分,与张量相关的语法元素用于指定是否对nnr聚合单元中的张量启用ctu块划分。
[0249]
在(s1720),可基于ctu扫描顺序重建nnr聚合单元中的张量。当对nnr聚合单元中的张量启用ctu块划分时,在编码器侧,张量可划分成ctu。可根据由第一语法元素指示的扫描顺序对ctu进行扫描和编码。在解码器侧,基于所指示的扫描顺序,解码器可理解对ctu进行编码的顺序,并因此将解码的ctu组织成张量。过程(1700)可前进到(s1799)并在(s1799)处终止。
[0250]
图18示出了根据本公开的一个实施例的3d金字塔编码的解码过程(1800)。过程(1800)可从(s1801)开始并前进到(s1810)。
[0251]
在(s1810),可从压缩神经网络表示的比特流中接收一个或多个第一语法元素。一个或多个第一语法元素可与从ctu3d划分的cu3d相关联。ctu3d可从神经网络中的张量划分得到。一个或多个第一语法元素可指示cu3d基于对应于3d金字塔结构的编码模式来划分。3d金字塔结构可包括多个深度。每个深度对应于一个或多个节点。每个节点具有节点值。例如,3d金字塔结构可以是八叉树结构、单叉树结构、标签树结构、单叉标签树结构等中的一种。
[0252]
在(s1820),可以以用于扫描3d金字塔结构中的节点的广度优先扫描顺序从比特流中接收与3d金字塔结构中的各节点的节点值对应的第二语法元素序列。因此,在解码器侧,可基于深度优先扫描顺序来接收节点值(由语法元素表示)。在其它实施例(未实现过程(1800))中,可以在编码器侧根据深度优先扫描顺序来扫描3d金字塔结构。
[0253]
在(s1830),可基于所接收的与3d金字塔结构中的节点的节点值对应的第二语法元素来重建张量的模型参数。如上所述,在解码器处,对应于八叉树结构、单叉树结构、标签树结构或单叉标签树结构,可采用3d金字塔编码方法来对3d金字塔结构的节点值和使用3d金字塔结构划分的cu3d的系数值进行编码。在解码器处,对应于所采用的3d金字塔编码方法,可相应地重建节点值和系数值。该过程可前进到(s1899)并在(s1899)处终止。
[0254]
图19示出了根据本公开的一个实施例的基于统一的编码的解码过程(1900)。过程(1900)可从(s1901)开始并前进到(s1910)。
[0255]
在(s1910),可接收与ctu3d相关联的语法元素。该ctu3d可以在神经网络的压缩神经网络表示的比特流中从神经网络的层中的张量划分得到。语法元素可指示与ctu3d相关联的金字塔树结构的底部深度处的所有子节点是否统一。在底部深度处不共享相同父节点的子节点可具有不同的统一值。
[0256]
在(s1920),响应于语法元素指示与ctu3d相关联的金字塔树结构的底部深度处的所有子节点统一,可基于3d单叉树编码方法对ctu3d进行解码。在一个示例中,可推断3d单叉树编码方法的起始深度为金字塔树结构的底部深度。在一个实施例中,不在比特流中对金字塔树结构的底部深度处的节点的统一标志进行编码。
[0257]
在一个实施例中,可接收在比特流中针对在底部深度处共享相同父节点的所有子节点编码的统一值。可接收在底部深度处共享相同父节点的所有子节点的符号位。在比特流中符号位跟在统一值之后。
[0258]
在一个实施例中,可接收在底部深度处共享相同父节点的每一组子节点的统一值。然后可接收在底部深度处共享相同父节点的每一组子节点中的子节点的符号位。
[0259]
在(s1930),响应于语法元素指示与ctu3d相关联的金字塔树结构的底部深度处的所有子节点并非全部统一,可基于3d标签树编码方法对ctu3d进行解码。在一个示例中,可推断3d标签树编码方法的起始深度为金字塔树结构的底部深度。
[0260]
在各种实施例中,可根据以下方法之一对金字塔树结构的底部深度处的节点的值进行解码。在第一方法中,可接收金字塔树结构的底部深度处的节点的值,在比特流中基于预定扫描顺序对每个节点的值进行编码。
[0261]
在第二方法中,可以在比特流中基于预定扫描顺序接收金字塔树结构的底部深度处的每一个节点的绝对值,然后(如果该绝对值不为0)接收每一个节点的符号。在第三方法中,可以在比特流中基于预定扫描顺序接收金字塔树结构的底部深度处的每一个节点的绝对值,然后(如果节点具有非零值)在比特流中基于预定扫描顺序接收金字塔树结构的底部深度处的每一个节点的符号。过程(1900)可前进到(s1999)并在(s1999)处终止。
[0262]
v.计算机系统
[0263]
可将上述技术实现为计算机软件,该计算机软件使用计算机可读指令,且物理地存储在一个或多个计算机可读介质中。例如,图20示出了适于实施所公开的主题的某些实施例的计算机系统(2000)。
[0264]
可使用任何合适的机器代码或计算机语言对计算机软件进行编码,任何合适的机器代码或计算机语言可经受汇编、编译、链接或类似的机制以创建包括指令的代码,该指令可由一个或多个计算机中央处理单元(cpu)、图形处理单元(gpu)等直接执行或通过解释、微代码执行等执行。
[0265]
指令可在各种类型的计算机或其组件上执行,计算机或其组件包括例如个人计算机、平板计算机、服务器、智能手机、游戏设备、物联网设备等。
[0266]
图20所示的计算机系统(2000)的组件本质上是示例性的,并不旨在对实施本公开的实施例的计算机软件的使用范围或功能提出任何限制。组件的配置也不应被解释为具有与计算机系统(2000)的示例性实施例中所示的组件中的任何一个组件或组件的组合相关的任何依赖或要求。
[0267]
计算机系统(2000)可包括某些人机接口输入设备。此类人机接口输入设备可响应于一个或多个人类用户通过例如下述的输入:触觉输入(例如:击键、划动,数据手套移动)、音频输入(例如:语音、拍手)、视觉输入(例如:手势)、嗅觉输入(未描绘)。人机接口设备还可用于捕获不一定与人的意识输入直接相关的某些媒介,例如音频(例如:语音、音乐、环境声音)、图像(例如:扫描的图像、从静止图像相机获取摄影图像)、视频(例如2d视频、包括立体视频的3d视频)。
[0268]
输入人机接口设备可包括下述中的一项或多项(每种中仅示出一个):键盘(2001)、鼠标(2002)、触控板(2003)、触摸屏(2010)、数据手套(未示出)、操纵杆(2005)、麦克风(2006)、扫描仪(2007)、相机(2008)。
[0269]
计算机系统(2000)还可包括某些人机接口输出设备。此类人机接口输出设备可通过例如触觉输出、声音、光和气味/味道来刺激一个或多个人类用户的感官。此类人机接口输出设备可包括触觉输出设备(例如触摸屏(2010)的触觉反馈、数据手套(未示出)或操纵杆(2005),但也可以是不作为输入设备的触觉反馈设备)、音频输出设备(例如扬声器(2009)、耳机(未描绘))、视觉输出设备(例如包括crt屏幕、lcd屏幕、等离子屏幕、oled屏幕的屏幕(2010),每种屏幕都有或没有触摸屏输入功能,每种屏幕都有或没有触觉反馈功能-其中的一些屏幕能够通过诸如立体图像输出之类的装置、虚拟现实眼镜(未描绘)、全息显示器和烟箱(未描绘)来输出2d视觉输出或超过3d的输出)以及打印机(未描绘)。
[0270]
计算机系统(2000)还可包括人类可访问存储设备及其关联介质,例如,包括具有cd/dvd等介质(2021)的cd/dvd rom/rw(2020)的光学介质、指状驱动器(2022)、可拆卸硬盘驱动器或固态驱动器(2023)、诸如磁带和软盘之类的传统磁性介质(未描绘)、诸如安全软件狗之类的基于专用rom/asic/pld的设备(未描绘)等。
[0271]
本领域技术人员还应该理解,结合当前公开的主题使用的术语“计算机可读介质”不涵盖传输介质、载波或其它暂时性信号。
[0272]
计算机系统(2000)还可包括通到一个或多个通信网络的接口。网络可以例如是无线网络、有线网络、光网络。网络可进一步是本地网络、广域网络、城域网络、车辆和工业网络、实时网络、延迟容忍网络等。网络的示例包括诸如以太网之类的局域网、无线lan、包括gsm、3g、4g、5g、lte等的蜂窝网络、包括有线电视、卫星电视和地面广播电视的电视有线或无线广域数字网络、包括canbus的车辆和工业用网络等。某些网络通常需要连接到某些通用数据端口或外围总线(2049)的外部网络接口适配器(例如,计算机系统(2000)的usb端口);如下所述,其它网络接口通常通过附接到系统总线而集成到计算机系统(2000)的内核中(例如,pc计算机系统中的以太网接口或智能手机计算机系统中的蜂窝网络接口)。计算机系统(2000)可使用这些网络中的任何一个网络与其它实体通信。此类通信可以是仅单向接收的(例如,广播电视)、仅单向发送的(例如,连接到某些canbus设备的canbus)或双向
的,例如,使用局域网或广域网数字网络连接到其它计算机系统。如上所述,可在这些网络和网络接口中的每一个上使用某些协议和协议栈。
[0273]
上述人机接口设备、人机可访问的存储设备和网络接口可附接到计算机系统(2000)的内核(2040)。
[0274]
内核(2040)可包括一个或多个中央处理单元(cpu)(2041),图形处理单元(gpu)(2042),现场可编程门区域(fpga)(2043)形式的专用可编程处理单元、用于某些任务的硬件加速器(2044)等。这些设备以及只读存储器(rom)(2045)、随机存取存储器(2046)、诸如内部非用户可访问的硬盘驱动器、ssd等之类的内部大容量存储器(2047)可通过系统总线(2048)连接。在一些计算机系统中,可以以一个或多个物理插头的形式访问系统总线(2048),以能够通过附加的cpu、gpu等进行扩展。外围设备可直接附接到内核的系统总线(2048)或通过外围总线(2049)附接到内核的系统总线(2048)。外围总线的体系结构包括pci、usb等。
[0275]
cpu(2041)、gpu(2042)、fpga(2043)和加速器(2044)可执行某些指令,这些指令可以组合来构成上述计算机代码。该计算机代码可存储在rom(2045)或ram(2046)中。过渡数据也可存储在ram(2046)中,而永久数据可例如存储在内部大容量存储器(2047)中。可通过使用高速缓存来进行到任何存储设备的快速存储及检索,该高速缓存可与下述紧密关联:一个或多个cpu(2041)、gpu(2042)、大容量存储器(2047)、rom(2045)、ram(2046)等。
[0276]
计算机可读介质可在其上具有用于执行各种由计算机实现的操作的计算机代码。介质和计算机代码可以是出于本公开的目的而专门设计和构造的介质和计算机代码,或者介质和计算机代码可以是计算机软件领域的技术人员公知且可用的类型。
[0277]
作为非限制性示例,可由于一个或多个处理器(包括cpu、gpu、fpga、加速器等)执行包含在一种或多种有形的计算机可读介质中的软件而使得具有架构(2000),特别是内核(2040)的计算机系统提供功能。此类计算机可读介质可以是与如上所述的用户可访问的大容量存储相关联的介质,以及某些非暂时性的内核(2040)的存储器,例如内核内部大容量存储器(2047)或rom(2045)。可将实施本公开的各实施例的软件存储在此类设备中并由内核(2040)执行。根据特定需要,计算机可读介质可包括一个或多个存储设备或芯片。软件可使得内核(2040),特别是其中的处理器(包括cpu、gpu、fpga等)执行本文所描述的特定过程或特定过程的特定部分,包括定义存储在ram(2046)中的数据结构以及根据由软件定义的过程来修改此类数据结构。附加地或替换地,可由于硬连线或以其它方式体现在电路(例如,加速器(2044))中的逻辑而使得计算机系统提供功能,该电路可替换软件或与软件一起运行以执行本文描述的特定过程或特定过程的特定部分。在适当的情况下,提及软件的部分可包含逻辑,反之亦然。在适当的情况下,提及计算机可读介质的部分可包括存储用于执行的软件的电路(例如集成电路(ic))、体现用于执行的逻辑的电路或包括两者。本公开包括硬件和软件的任何合适的组合。
[0278]
虽然本公开已经描述了多个示例性实施例,但是存在落入本公开的范围内的更改、置换和各种替换等效物。因此,应当理解,本领域技术人员将能够设计出许多虽然未在本文中明确示出或描述,但是体现了本公开的原理,因此落入本公开的精神和范围内的系统和方法。
[0279]
附录a:缩略词
[0280]
dnn:深度神经网络
[0281]
nnr:压缩的神经网络表示;神经网络的编码表示
[0282]
ctu:编码树单元
[0283]
ctu3d:三维编码树单元
[0284]
cu:编码单元
[0285]
cu3d:三维编码单元
[0286]
rd:率失真
[0287]
附录b:金字塔编码方法的语法表
[0288]
表2
[0289]
[0290][0291]
表3
[0292][0293][0294]
表4
[0295]
[0296][0297]
[0298][0299]
表5
[0300][0301]
nzflag
ꢀꢀꢀꢀꢀꢀ
量化系数的非零标志
[0302]
sign
ꢀꢀꢀꢀꢀꢀꢀꢀ
量化系数的符号位
[0303]
表6
[0304][0305]
表7
[0306]
[0307][0308]
表8
[0309][0310]
sign
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
predicted_size-prev_predicted_size的符号位
[0311]
predicted_flag
ꢀꢀꢀ
0指示位置n不是预测条目,1指示位置n是预测条目
[0312]
表9
[0313]
[0314][0315][0316]
表10
[0317][0318][0319]
nzflag
ꢀꢀꢀꢀꢀꢀ
量化系数的非零标志
[0320]
sign
ꢀꢀꢀꢀꢀꢀꢀꢀ
量化系数的符号位
[0321]
表11
[0322]
[0323][0324]
uni_flag
ꢀꢀꢀꢀ
单叉树节点值
[0325]
nzflag
ꢀꢀꢀꢀꢀꢀ
量化系数的非零标志
[0326]
sign
ꢀꢀꢀꢀꢀꢀꢀꢀ
量化系数的符号位
[0327]
表12
[0328]
[0329]
[0330][0331]
oct_flag
ꢀꢀꢀꢀ
八叉树结点值
[0332]
sign
ꢀꢀꢀꢀꢀꢀꢀꢀ
量化系数的符号位
[0333]
表13
[0334]
[0335][0336]
nz_flag
ꢀꢀꢀꢀꢀ
节点值的非零标志
[0337]
sign
ꢀꢀꢀꢀꢀꢀꢀꢀ
量化系数的符号位
[0338]
表14
[0339]
[0340][0341]
uni_flag
ꢀꢀꢀꢀ
单叉树节点值
[0342]
nz_flag
ꢀꢀꢀꢀꢀ
节点值的非零标志
[0343]
sign
ꢀꢀꢀꢀꢀꢀꢀꢀ
量化系数的符号位
[0344]
表15
[0345][0346]
nz_flag
ꢀꢀꢀꢀꢀ
节点值的非零标志
[0347]
sign
ꢀꢀꢀꢀꢀꢀꢀꢀ
量化系数的符号位
[0348]
表16
[0349]
[0350][0351][0352]
表17
[0353]
[0354][0355]
nzflag
ꢀꢀꢀꢀꢀꢀ
非零标志
[0356]
uibit
ꢀꢀꢀꢀꢀꢀꢀ
指数golomb余数的一元部分
[0357]
uibits
ꢀꢀꢀꢀꢀꢀ
固定长度余数
[0358]
附录c:基于统一的编码的语法表
[0359]
表18
[0360][0361]
ndim(arrayname[])返回arrayname[]的维数。
[0362]
scan_order根据下表指定具有多于一个维度的参数的块扫描顺序:
[0363]
0:不扫描块
[0364]
1:8
×
8块
[0365]
2:16
×
16块
[0366]
3:32
×
32块
[0367]
4:64
×
64块
[0368]
layer_uniform_flag指定是否使用均匀方法对量化权重quantparam[]进行编码。layer_uniform_flag等于1指示使用均匀方法对quantparam[]进行编码。
[0369]
表19
[0370][0371]
2d整数阵列statetranstab[][]指定用于依赖标量量化的状态转移表,如下:
[0372]
statetranstab[][]={{0,2},{7,5},{1,3},{6,4},{2,0},{5,7},{3,1},{4,6}}
[0373]
表20
[0374]
[0375][0376]
ctu3d_uniform_flag指定是否使用均匀方法对量化的ctu3d权重quantparam[]进行编码。ctu3d_uniform_flag等于1指示使用均匀方法对quantparam[]进行编码。
[0377]
sign_flag指定量化权重quantparam[i]是正还是负。sign_flag等于1指示quantparam[i]为负。
[0378]
表21
[0379][0380]
sig_flag指定量化权重quantparam[i]是否不为零。sig_flag等于0指示quantparam[i]为零。
[0381]
sign_flag指定量化权重quantparam[i]是正还是负。sign_flag等于1指示quantparam[i]为负。
[0382]
abs_level_greater_x[j]指示quantparam[i]的绝对水平是否大于j+1。
[0383]
abs_level_greater_x2[j]包括指数golomb余数的一元部分。
[0384]
abs_remainder指示固定长度余数。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1