用于广播视频的端到端相机校准的制作方法
用于广播视频的端到端相机校准
1.相关申请的交叉引用
2.本技术要求于2020年4月10日提交的美国临时申请序列no.63/008,184的优先权,该申请的全部内容通过引用并入本文。
技术领域
3.本公开总体上涉及用于基于例如跟踪数据的广播视频动作和参与者的端到端相机校准的系统和方法。
背景技术:
4.被部署在生产中的越来越多的基于视觉的跟踪系统需要快速、稳健的相机校准。例如,在体育运动领域,当前的大部分工作集中于易于提取线条和交叉点以及跨场地的外观相对一致的体育运动上。
技术实现要素:
5.在一些实施例中,本文公开了一种校准广播视频源的方法。计算系统检索多个运动事件的多个广播视频源。每个广播视频源包括多个视频帧。通过将广播视频源划分为多个帧来生成基于广播视频源的多个训练数据集以及通过神经网络来学习以为多个帧中的每一帧生成单应矩阵,计算系统生成训练的神经网络。计算系统接收目标运动事件的目标广播视频源。计算系统将目标广播视频源划分成多个目标帧。计算系统经由神经网络为多个目标帧中的每个目标帧生成目标单应矩阵。计算系统通过由相应的目标单应矩阵扭曲每个目标帧来校准目标广播视频源。
6.在一些实施例中,本文公开了一种系统。该系统包括处理器和存储器。存储器具有存储在其上的编程指令,当编程指令由处理器执行时,执行一个或更多个操作。一个或更多个操作包括检索多个运动事件的多个广播视频源。每个广播视频源包括多个视频帧。一个或更多个操作还包括通过由将广播视频源划分为多个帧来生成基于广播视频源的多个训练数据集以及通过神经网络学习为多个帧中的每一帧生成单应矩阵,生成训练的神经网络。一个或更多个操作还包括接收目标运动事件的目标广播视频源。一个或更多个操作还包括将目标广播视频源划分成多个目标帧。一个或更多个操作还包括通过神经网络为多个目标帧中的每个目标帧生成目标单应矩阵。一个或更多个操作还包括通过由相应的目标单应矩阵扭曲每个目标帧来校准目标广播视频源。
7.在一些实施例中,本文公开了一种非暂时性计算机可读介质。非暂时性计算机可读介质包括一个或更多个指令序列,一个或更多个指令序列在由一个或更多个处理器执行时,使得计算系统执行一个或更多个操作。计算系统检索多个运动事件的多个广播视频源。每个广播视频源包括多个视频帧。通过将广播视频源划分为多个帧来生成基于广播视频源的多个训练数据集以及通过神经网络学习为多个帧中的每一帧生成单应矩阵,计算系统生成训练的神经网络。计算系统接收目标运动事件的目标广播视频源。计算系统将目标广播
视频源划分成多个目标帧。计算系统经由神经网络为多个目标帧中的每个目标帧生成目标单应矩阵。计算系统通过由相应的目标单应矩阵扭曲每个目标帧来校准目标广播视频源。
附图说明
8.为了能够详细理解本公开的上述特征,可以通过参考实施例对以上简要概括的本公开进行更具体的描述,其中一些实施例在附图中被示出。然而,要注意,附图仅示出了本公开的典型实施例,因此不应被视为对本公开范围的限制,因为本公开可以允许其他同等有效的实施例。
9.图1是示出根据示例实施例的计算环境的框图。
10.图2a-图2b是示出根据示例实施例的相机校准器的神经网络架构的框图。
11.图3是示出根据示例实施例的比赛场地的一个或更多个图像的框图。
12.图4是示出根据示例实施例的生成完全训练的校准模型的方法的流程图。
13.图5是示出根据示例实施例的校准广播相机的方法的流程图。
14.图6a是示出根据示例实施例的计算设备的框图。
15.图6b是示出根据示例实施例的计算设备的框图。
16.为了便于理解,在可能的情况下,已使用相同的参考数字来表示附图中共同的相同元件。在一个实施例中公开的元件可以有益地被用于其他实施例而无需具体叙述是可预期的。
具体实施方式
17.相机校准是计算机视觉应用的一项重要任务,例如跟踪系统、即时定位与地图构建(simultaneous localization and mapping,slam)以及增强现实(ar)。最近,许多职业体育运动联盟已经部署了一些基于视觉的跟踪系统版本。此外,在视频广播期间使用的以用于提高观众参与度的ar应用(例如中的virtual 3、中的first down line)已变得不足为奇。所有这些应用都需要高质量的相机校准系统。目前,这些应用的大多数依赖于多个预先校准的固定相机或直接来自相机的云台变焦(pan-tilt-zoom,ptz)参数的实时馈送。然而,由于体育运动领域中最广泛可用的数据源是广播视频,所以从具有未知的和变化的相机参数的单个移动相机进行校准的能力将大大扩展选手跟踪数据和粉丝参与度解决方案的范围。单个移动相机的校准仍然是一项具有挑战性的任务,因为该方法应该是准确的、快速的且可推广到各种视图和外观。本文描述的一种或更多种技术允许计算系统在给定帧和运动的情况下确定单个移动相机的相机单应性。
18.相机校准的当前方法主要遵循基于场配准、模板匹配(即,相机姿态初始化)和单应性细化的框架。这些方法的大多数集中于语义信息(例如,关键球场标记)易于提取、跨体育场(例如,绿草和白线)的场外观一致、以及相机的移动相对缓慢且平稳的运动上。然而,这些假设不适用于更具动态性的体育运动,例如篮球,其中选手遮挡场标记,场外观因场地而异,并且相机快速移动。
19.此外,大多数现有工作成果由多个独立模型组成,这些独立模型分别被训练或调整。因此,他们不能为此类优化任务实现全局最优。这个问题还限制了这些方法在更具挑战性的场景中的性能,因为误差通过系统进行模块到模块的传播。
20.本文所述的一种或更多种技术涉及用于相机校准的全新的端到端神经网络。通过端到端神经网络的使用,本系统能够处理涉及移动模糊、遮挡和大变换的更具挑战性的场景—现有系统根本不能解释或解决的场景。在一些实施例中,本系统实施基于区域的语义而不是用于相机校准的线,从而为动态环境和具有高度可变外观特征的那些环境提供更稳健的方法。在一些实施例中,本系统结合了用于大变换学习的空间变换网络,这有助于减少用于校准目的所需模板的数量。在一些实施例中,本系统实施用于相机校准的端到端架构,这允许更有效地联合训练和推理单应性。
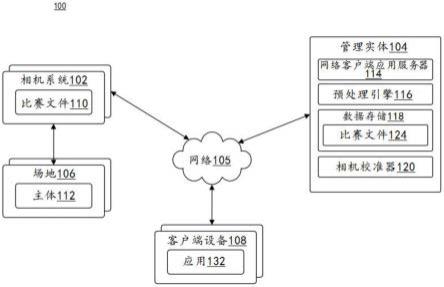
21.图1是示出根据示例实施例的计算环境100的框图。计算环境100可以包括:经由网络105通信的相机系统102、组织计算系统104以及一个或更多个客户端设备108。
22.网络105可以是包括经由互联网(例如,蜂窝或wi-fi网络)的单独连接的任何合适的类型。在一些实施例中,网络105可以使用直接连接(例如,射频识别(rfid)、近场通信(nfc)、蓝牙
tm
、低能耗蓝牙
tm
(ble)、wi-fi
tm
、zigbee
tm
、环境反向散射通信(abc)协议、usb、wan或lan)来连接终端、服务和移动设备。因为传输的信息可能是个人的或机密的,出于安全考虑可能要求对这些类型的连接中的一种或更多种进行加密或以其他方式保护。然而,在一些实施例中,正在传输的信息可能不太个人化,因此,为了方便而不是安全,可以选择网络连接。
23.网络105可以包括用于交换数据或信息的任何类型的计算机网络布置。例如,网络105可以是互联网、专用数据网络、使用公共网络的虚拟专用网络和/或使计算环境100中的部件能够在环境100的部件之间发送和接收信息的其他合适的连接。
24.相机系统102可以位于场地106中。例如,场地106可以被配置为举办包括一个或更多个主体112的运动事件。相机系统102可以被配置为捕获比赛场地上的所有主体(即,选手)的移动,以及一个或更多个其他相关对象(例如,球、裁判等)的移动。在一些实施例中,相机系统102可以是使用诸如多个固定相机的基于光学的系统。例如,可以使用由六个固定的校准相机组成的系统,该系统将选手和球的三维位置投影到球场的二维俯视图上。在另一示例中,静止相机和非静止相机的混合可用于捕获比赛场地上的所有主体以及一个或更多个相关对象的移动。如本领域技术人员所认识到的,利用这种相机系统(例如,相机系统102)可能生成球场的许多不同相机视图(例如,高边线视图、罚球线视图、队员靠拢(huddle)视图、争球(face-off)视图、球门区(end zone)视图等)。通常,相机系统102可用于给定比赛的广播源(broadcast feed)。广播源的每一帧可以存储在比赛文件110中。
25.相机系统102可以被配置为经由网络105与组织计算系统104通信。组织计算系统104可以被配置为管理和分析由相机系统102捕获的广播源。组织计算系统104可以至少包括网络客户端应用服务器114、预处理引擎116、数据存储118和相机校准器120。预处理引擎116和相机校准器120均可以包括一个或更多个软件模块。一个或更多个软件模块可以是存储在介质(例如,组织计算系统104的存储器)上的代码或指令的集合,这些代码或指令的集合表示实施一个或更多个算法步骤的一系列机器指令(例如,程序代码)。这样的机器指令可以是组织计算系统104的处理器解释以实施指令的实际计算机代码,或者,可以是被解释以获得实际计算机代码的指令的更高级别的编码。一个或更多个软件模块还可以包括一个或更多个硬件部件。示例算法的一个或更多个方面可以由硬件部件(例如,电路)本身执行,而不是作为指令的结果。
26.数据存储118可以被配置为存储一个或更多个比赛文件124。每个比赛文件124可以包括给定比赛的广播数据。例如,广播数据可以是由相机系统102捕获的多个视频帧。
27.相机校准器120可以被配置为校准相机系统102的相机。例如,相机校准器120可以被配置为将在可跟踪帧中检测到的选手投影到真实世界坐标以供进一步分析。因为相机系统102中的相机不断地移动以便集中于球或关键比赛,所以这样的相机不能被预先校准。相机校准器120可以被配置为生成单应矩阵,该单应矩阵可以将来自广播视频的任何帧的目标地平面场地与俯视场模型配准。例如,相机校准器120可以实施单个神经网络以找出可以将来自广播视频的任何帧i的目标地平面场地与俯视场模型m配准的单应矩阵h。在一些实施例中,用于计算具有点对应的单应性的标准目标函数可以是:
[0028][0029]
其中xi表示在广播图像i中像素i的位置(x,y),x'i是模型“图像”m上对应的像素位置,χ表示两个图像i和m之间的点对应集。
[0030]
客户端设备108可以经由网络105与组织计算系统104通信。客户端设备108可以由用户操作。例如,客户端设备108可以是移动设备、平板电脑、台式计算机或具有本文所述能力的任何计算系统。用户可以包括但不限于个人,例如订阅者、客户、潜在客户或与组织计算系统104相关联的实体的消费者,例如已经获得、将要获得或可能获得来自与组织计算系统104相关联的实体的产品、服务或咨询的个人。
[0031]
客户端设备108可以至少包括应用132。应用132可以表示独立应用或允许访问网站的网络浏览器。客户端设备108可以访问应用132以访问组织计算系统104的一个或更多个功能。客户端设备108可以通过网络105进行通信以请求诸如来自组织计算系统104的网络客户端应用服务器114的网页。例如,客户端设备108可以被配置为执行应用132以访问由网络客户端应用服务器114管理的内容。显示给客户端设备108的内容可以从网络客户端应用服务器114传输到客户端设备108,并且随后由应用132处理以通过客户端设备108的图形用户界面(gui)显示。
[0032]
图2a-图2b是示出根据示例实施例的相机校准器120的神经网络架构200的框图。如所讨论的,相机校准器120可以利用单个神经网络,单个神经网络将视频帧作为输入,并输出该帧的单应矩阵。例如,相机校准器120可以利用单个神经网络进行给定跨各种运动(例如,篮球、足球、橄榄球、曲棍球等)的未知相机内部参数的单个移动相机校准。神经网络架构200可以包括三个模块:语义分割模块202、相机姿态初始化模块204和单应性细化模块206。三个模块202-206中的每一个都被集成到单个神经网络架构中,例如神经网络架构200所示。因为所有三个模块202-206均已被连接,所以神经网络架构200能够进行端到端训练。
[0033]
语义分割模块202可以被配置为识别比赛场地(例如,篮球场、足球场等)的特征。例如,语义分割模块202可以被配置为从输入图像i(参考数字220)中提取关键特征并去除不相关信息。这样的输出可导致可用于确定点对应的场地不可知外观(参考数字222)。因此,来自上述的目标函数h可以被重写为:
[0034]
[0035]
其中θh表示八个单应性参数的向量,w(;θ)表示具有变换参数θ的扭曲函数,l()表示测量两个图像(在这种情况下是预测的语义图和扭曲的开销(overhead)模型m)之间的差异的任何损失函数。
[0036]
语义分割模块202可以通过将比赛场地划分为一个或更多个区域来对比赛场地进行基于区域的分割。通过将比赛场地划分为一个或更多个区域,语义分割模块202可以将开销场模型m变换为多通道图像。考虑到多通道图像,语义分割模块202可以将i中的每个像素分类到一个或更多个区域中的一个区域中。为了生成每个图像的基于区域的语义标签,语义分割模块202可以利用相关联的地面实况单应性扭曲开销模型,从而为训练提供地面实况语义标签。
[0037]
图3是示出根据示例实施例的篮球比赛场地的一个或更多个图像302-306的框图。如图所示,图像302可以对应于篮球比赛场地的俯视的视场模型。语义分割模块202可以将篮球比赛场地划分成四个区域,从而产生4通道图像。例如,区域308可以对应于第一通道,区域310可以对应于第二通道,区域312可以对应于第三通道,以及区域314可以对应于第四通道。在操作中,语义分割模块202可以利用图像302将输入图像(例如,在i中)中的每个像素分类到区域308-314中的一个。
[0038]
图像304可以阐明应用于传入图像的语义标签。语义分割模块202可以通过使用地面实况单应性扭曲场模型m(例如,图像302)来生成图像304。然后这些图像(例如,图像302和图像304)可以被用于训练语义分割模块202。
[0039]
图像306可以从俯视透视图阐明示出相机视图中的场模型的比例(fraction)的图像304的多边形区域。
[0040]
返回参考图2a和图2b,对于分割任务,语义分割模块202可以实施unet样式的自动编码器214(以下简称为“unet 214”)。unet 214可以将图像i220作为输入,并输出θh所需的语义图222。在一些实施例中,可以使用交叉熵损失来训练unet 214。例如:
[0041][0042]
其中c可以表示类别集,可以表示地面实况标签,可以表示像素i属于类别c的似然度。
[0043]
相机姿态初始化模块204可以被配置为使用语义图从模板集中选择适当的模板。相机姿态初始化模块204可以使用孪生网络来确定每个输入语义图像的最佳模板。孪生网络可以是卷积编码器,该卷积编码器计算语义图像的隐藏表示,该语义图像可以是unet 214的输出或任何语义模板图像。在一些实施例中,两个图像之间的相似度可以是它们的隐藏表示之间的范数l2。在一些实施例中,可以将每个图像编码为128长度的向量用于相似度计算。
[0044]
对于ptz相机,投影矩阵p可以表示为:
[0045]
p=kr[i|-c]=kqs[i|-c]
[0046]
其中q和s是由旋转矩阵r分解而成的,k是相机系统102中相机的固有参数,i是3
×
3单位矩阵,c是相机平移。矩阵s可以描述从世界坐标到ptz相机底部的旋转,以及q表示由
于平移(pan)和倾斜(tilt)导致的相机旋转。例如,s可以被限定为围绕世界x轴旋转约90
°
,使得相机沿世界平面中的y轴观看。换句话说,相机是水平的,它的投影与地面平行。
[0047]
在一些实施例中,对于每个图像,相机校准器120可以假设中心原理点、方形像素以及无镜头畸变。在一些实施例中,可以识别六个参数。例如,这六个参数可以是焦距、三维相机位置、平移和倾斜角。
[0048]
在一些实施例中,预处理引擎116可以初始化固有相机矩阵k、相机位置c和旋转矩阵r。通过该初始化,预处理引擎116可以识别最优焦距、三维相机位置和旋转角度。例如,预处理引擎116可以使用列文伯格-马夸尔特(levenberg-marquardt)算法来找出最优焦距、三维相机位置和旋转角度。一旦预处理引擎116确定k、c、r和s,预处理引擎116就可以生成q。在一些实施例中,预处理引擎116可以生成给定q的平移和倾斜角。例如,预处理引擎116可以通过将罗德里格斯公式应用于q来生成平移和倾斜角。因此,根据以上所述,相机姿态初始化模块204可以生成6维相机配置λ(平移、倾斜、缩放和三维相机位置)。
[0049]
在预处理引擎116估计每个训练图像的相机配置λ之后,预处理引擎116可以生成可能的相机姿态λ的字典。
[0050]
在一些实施例中,预处理引擎116可以通过从可能的相机姿态的范围内均匀地采样来生成可能的相机姿态λ的字典。例如,预处理引擎116可以从训练数据确定平移、倾斜、焦距和相机位置的范围,并从6维网格中对姿态进行均匀采样。即使训练集很小,这种方法能够覆盖所有相机姿态。此外,使用较小的网格可以简化单应性细化,因为所需的变换的最大尺度在网格大小的尺度上。
[0051]
在一些实施例中,预处理引擎116可以使用聚类直接从训练数据中学习可能的相机姿态λ。例如,当训练集具有足够的多样性时,这样的过程可能是有益的。例如,预处理引擎116可以将λ视为多变量正态分布,并应用高斯混合模型(gmm)来构建相机姿态集。在一些实施例中,对于每个分量,混合权重π可以被固定为相等。在一些实施例中,对于每个分布,协方差矩阵σ可以是固定的。在这样的实施例中,σ的特征尺度可以设置由单应性细化模块206处理的变换的尺度。与传统的gmm相比,由预处理引擎116实施的gmm学习算法可以在给定混合权重π和协方差矩阵σ的情况下找出分量k的数量和每个分布的平均值μk,而不是设置分量k的数量。每个分量的相同的σ和π可以确保从训练数据的流形中对gmm分量均匀地采样。
[0052]
在一些实施例中,gmm学习算法可以是:
[0053][0054]
因为预处理引擎116可以确定σ,所以相机姿态初始化模块可以在最大化步骤期间仅更新μ。预处理引擎116可以逐渐增加k直到满足停止准则。停止准则可能旨在生成足够的分量,使得每个训练示例都接近混合中一个分量的平均值。预处理引擎116可以利用所有分量[μ1,...,μk]生成相机姿态字典λ。
[0055]
考虑到相机姿态字典λ,相机姿态初始化模块204可以计算每个姿态的单应性并使用λ来扭曲开销场模型m。因此,图像模板集及其对应的单应矩阵可以被确定并被相机姿态初始化模块204使用。
[0056]
考虑到语义分割图像和模板图像集相机姿态初始化模块204可以使用孪生网络来计算每个输入和模板对之间的距离。在一些实施例中,每对的目标/标签可以是相似的或不同的。例如,对于网格采样的相机姿态字典,如果模板tk的姿态参数是网格中的最近邻,则模板tk可能与图像相似。对于基于gmm的相机姿态字典,如果模板的对应分布给出输入图像的姿态参数λ的最高似然度,则可以将模板tk标记为与图像相似。这个过程可以为训练集中的每个图像生成模板相似度标签。
[0057]
一旦(在fc1之后)输入语义图像和模板图像被编码,相机姿态初始化模块204可以使用潜在表示来计算输入图像和每个模板之间的l2距离。选择模块210可以找出目标相机姿态索引并且可以根据以下公式检索其模板图像和单应性作为输出:
[0058][0059]
其中f()可以表示孪生网络的编码函数。
[0060]
在一些实施例中,相机姿态初始化模块204可以使用对比损失来训练孪生网络。例如,
[0061][0062]
其中a可以表示图像对的二进制相似性标签,m可以表示对比损失的边界。
[0063]
单应性分割模块206可以被配置为通过识别所选模板和输入图像之间的相对变换来细化单应性。例如,单应性分割模块206可以实施空间变换网络(spatial transformer network,stn),stn允许大型非仿射变换的处理和较小的相机姿态字典的使用。例如,在给定输入图像和所选模板时,这两个图像可以被堆栈并作为输入被提供给stn。stn可用于回归几何变换参数。在一些实施例中,可以在卷积编码器中使用残差块来保护用于变形预测的显著特征。在一些实施例中,relu可用于所有隐藏层,而stn的输出层可使用线性激活。
[0064]
为了计算输入语义图像和所选模板图像之间的相对变换,单应性分割模块206可以将图像堆栈成n通道图像(例如,8通道图像),形成stn定位层的输入。在一些实施例中,定位层的输出可以是将语义图像映射到模板tk的相对单应性的参数(例如,8个参数)。
[0065]
在一些实施例中,单应性分割模块206可以初始化定位层中的最后一层(例如,fc3),使得内核中的所有元素都为零并且偏向于扁平单位矩阵的前n个值(例如,8个值)。因此,在训练开始时,可以假设输入与模板相同,为stn优化提供初始化。因此,最终的单应性可能是
[0066]
一旦h被计算,单应性细化模块206的变换器212可以将开销模型m扭曲到相机视角,反之亦然,这允许相机校准器120计算损失函数。例如,单应性细化模块206可以使用骰子系数损失:
[0067][0068]
其中u、v可以表示语义图像,c可以表示通道数,
°
可以表示逐元素乘法,||
·
||可以表示图像中像素强度的总和。此处,例如,每个通道的强度可以是像素属于通道c的似然度。与基于线的分割相反,使用基于区域的分割的主要优点之一是它对遮挡具有鲁棒性,并且可以更好地使用(即更有效地使用)网络容量,因为图像像素的更大比例可能属于有意义的类别。
[0069]
然而,基于交并比(intersection-of-union,iou)的损失的限制是,随着图像中视场的比例减小,iou损失可能变得对分割误差敏感。例如,如果比赛场地占据了图像的一小部分,那么小的变换可以显著降低iou。因此,单应性细化模块206在两个视角中的扭曲的比赛场地上都使用了骰子损失—高占用视角可以实现粗略的配准,而低占用视角可以对微调提供有力的约束。因此,损失函数可以被定义为:
[0070][0071]
其中y可以表示地面实况语义图像,m'可以表示掩蔽开销场模型,以便仅针对图像中示出的区域计算损失。来自两个视角的损失可以通过δ加权,其中较低占用比例视角的权重总是较高。
[0072]
因为每个模块202-206可以使用其他模块的输出作为输入,所以这三个模块202-206可以连接成单个神经网络(即,神经网络架构200)。因此,网络的总损失可以变为:
[0073][0074]
其中α,β∈[0,1)。
[0075]
相机校准器120可以逐个模块递增地训练整个神经网络架构200,使得孪生网络和stn可以合理的输入开始训练。例如,训练可以从对unet进行20次epoch的预热开始;孪生网络训练可以从α=0.1和β=0.9开启。例如,在又过10次epoch后,stn可以从α=0.05和β=0.05开启。神经网络架构可能会继续进行联合训练,直到收敛。
[0076]
图4是示出根据示例实施例的生成完全训练的校准模型的方法400的流程图。方法400可以开始于步骤402。
[0077]
在步骤402,组织计算系统104可以检索一个或更多个数据集以用于训练。每个数据集可以包括在比赛过程期间由相机系统102捕获的多个图像。
[0078]
在一些实施例中,数据集可以从十三场篮球比赛中创建。本领域技术人员认识到,多于十三场的比赛或少于十三场的比赛可用于训练目的。例如,十场比赛可用于训练,剩余三场比赛可用于测试。本领域技术人员认识到,多于十场的比赛或少于十场的比赛可用于训练,多于三场的比赛或少于三场的比赛可用于测试。上述用于训练目的的比赛数量仅是示例性的,并不意味着限制上述讨论。不同的比赛可以有不同的相机位置,每场比赛都在一个独特的场地中进行。因此,每场比赛的比赛场地外观可能因比赛而异。对于每场比赛,可以为具有高相机姿态多样性的每个注释选择30-60帧。专业注释者可能已经点击了每个图像中的四到六个点对应来计算地面实况单应性。这些注释可能已经产生了526个用于训练的图像和114个用于测试的图像。在一些实施例中,可以通过水平翻转图像来进一步丰富训练数据,这样可以总共生成1052个训练示例。
[0079]
在一些实施例中,数据集可以从二十场足球比赛中创建。例如,二十场足球比赛在白天和晚上在九个不同的体育场举行,图像可能由不同的视角和照明条件组成。因此,该数据集可能包括从10场比赛中收集的209个训练图像和从其他10场比赛中收集的186个测试图像。
[0080]
在步骤404,组织计算系统104可以根据一个或更多个数据集生成多个相机姿态模板。例如,基于检索的用于训练的一个或更多个数据集,相机校准器120可以生成用于训练的相机姿态模板。在一些实施例中,只要一个或更多个数据集足够大且多样化,相机校准器120就可以使用上面讨论的基于gmm的方法生成相机姿态模板。在一些实施例中,当获得完整且相对干净的开销比赛场地图像时,可以认为一个或更多个数据集足够大且多样化。在这样的实施例中,相机校准器120可以设置平移、倾斜、焦距和相机位置(x,y,z)的标准偏差。在一些实施例中,相机校准器120还可以设置用于停止准则和扭曲损失的阈值。
[0081]
继续参考上面的第一示例,使用篮球数据集,相机校准器120可以使用基于gmm的方法以生成来自1052个训练图像的相机姿态模板。在这样的示例中,相机校准器120可以将平移、倾斜、焦距和相机位置(x,y,z)的标准偏差分别设置为5
°
、5
°
、1000像素和15英尺。非对角元素可以被设置为零,因为相机校准器120假定那些相机配置是彼此独立的。停止准则的阈值可以被设置为0.6,且聚类算法可以生成210个分量。对于扭曲损失可以被设
置为0.8,因为相机视角可能具有比俯视视角更低的场占用率。
[0082]
在一些实施例中,如果例如一个或更多个数据集具有不足的示例数量,则相机校准器120可以使用高网格分辨率生成相机姿态模板。在这样的实施例中,相机校准器120可以设置平移、倾斜和焦距的分辨率。
[0083]
继续参考上面的第二个示例,使用足球数据集,相机校准器120可以使用高网格分辨率方法来生成相机姿态模板。在这样的示例中,相机校准器120可以将平移、倾斜和焦距的分辨率分别设置为5
°
、2.5
°
和500像素。在一些实施例中,相机位置可以固定在例如相对于场左上角的560、1150和186码处。因为足球数据集具有不足的示例数量来使用基于gmm的相机姿态估计,所以相机校准器120可以使用具有估计的平移、倾斜和焦距范围(分别为[-35
°
,35
°
]、[5
°
,15
°
]、[1500,4500]像素)的该数据集的均匀采样,从而生成450个用于相机姿态初始化的模板。
[0084]
正如本领域技术人员所认识到的,尽管在当前示例中讨论了篮球和足球,但是这种方法可以扩展到任何运动的视频广播。
[0085]
在步骤406,组织计算系统104可以基于一个或更多个训练数据集学习如何校准单个移动相机。例如,相机校准器120的神经网络可以学习如何基于一个或更多个训练数据集来校准单个移动相机。在一些实施例中,可以同时训练神经网络架构200的每个模块。例如,因为神经网络架构200的每个模块202-206使用其他模块的输出作为输入,所以这三个模块202-206可以连接成单个神经网络。因此,网络的总损失可以变为:
[0086][0087]
其中α,β∈[0,1)。
[0088]
相机校准器120可以逐个模块递增地训练整个神经网络架构200,使得孪生网络和stn可以合理的输入开始训练。例如,训练可以从对unet进行20次epoch的预热开始;孪生网络训练可以从α=0.1和β=0.9开启。例如,在又过10次epoch后,stn可以从α=0.05和β=0.05开启。神经网络架构可能会继续进行联合训练,直到收敛。
[0089]
在一些实施例中,模块202-206中的一个或更多个模块可以用合成数据“预热”。例如,由于以上参考的足球数据集中的少量训练示例,相机校准器120可以使用合成数据来预热相机姿态初始化模块204和单应性细化模块206。除了语义分割模块202中的unet之外,神经网络架构200的其余部分使用语义图像作为输入,使得相机校准器120可以合成任意数量的语义图像来预训练网络的部分。使用特定示例,可以通过对平移、倾斜和焦距参数进行均匀采样来生成2000个语义图像。对于每个合成图像,它们的地面实况单应性是已知的,并且可以通过对网格进行下采样轻松找出模板分配。因此,相机姿态初始化模块204和stn可以被单独预训练。一旦相机姿态初始化模块204和单应性细化模块206被预热,相机校准器120就可以利用真实数据来训练神经网络。
[0090]
在步骤408,组织计算系统104可以输出完全训练的预测模型。例如,在训练和测试过程结束时,相机校准器120可以具有完全训练的神经网络架构200。
[0091]
图5是示出根据示例实施例的校准广播相机的方法500的流程图。方法500可以开始于步骤502。
[0092]
在步骤502,组织计算系统104可以接收(或检索)事件的广播源。在一些实施例中,广播源可以是从相机系统102实时(或接近实时)接收的实况源。在一些实施例中,广播源可
以是已经结束的比赛的广播源。通常,广播源可以包括多个视频数据帧。每一帧可以捕获不同的相机视角。
[0093]
在步骤504,组织计算系统104可以将每一帧输入到神经网络架构200中。例如,相机校准器120可以识别接收的广播源中的第一帧并将该帧提供给神经网络架构200。
[0094]
在步骤506,组织计算系统104可以生成每一帧的单应矩阵h。例如,语义分割模块202可以识别每一帧中的球场特征y。来自语义分割模块202的输出可以是由unet生成的语义图语义图可以作为输入被提供给相机姿态初始化模块204。相机姿态初始化模块204可以使用语义图从模板集中选择适当的模板相机姿态初始化模块204还可以识别目标相机姿态索引并使用选择模块210检索其模板图像和单应性相机校准器120可以将和串联在一起作为输入传递给单应性细化模块206。然后单应性细化模块206可以通过将串联项和传递给stn来预测模板和语义图之间的相对单应性然后单应性细化模块206可以使用矩阵乘法(即),生成基于相对单应性和的单应矩阵h。
[0095]
在步骤508,组织计算系统104可以通过每一帧相应的单应矩阵h来扭曲每一帧。
[0096]
图6a示出了根据示例实施例的系统总线计算系统架构600。系统600可以表示组织计算系统104的至少一部分。系统600的一个或更多个部件可以使用总线605彼此电通信。系统600可以包括处理单元(cpu或处理器)610和将各种系统部件耦接到处理器610的系统总线605,各种系统部件包括系统存储器615,例如只读存储器(rom)620和随机存取存储器(ram)625。系统600可以包括直接连接处理器610、紧邻处理器610或集成为处理器610的一部分的高速存储器的高速缓存。系统600可以将数据从存储器615和/或存储设备630复制到高速缓存612以供处理器610快速访问。以此方式,高速缓存612可提供避免处理器610在等待数据时延迟的性能提升。这些模块和其他模块可以控制或被配置为控制处理器610以执行各种动作。也可以使用其他系统存储器615。存储器615可以包括具有不同性能特征的多种不同类型的存储器。处理器610可以包括被配置为控制处理器610的任何通用处理器或硬件模块或软件模块(例如存储在存储设备630中的服务1632、服务2634和服务3636)以及软件指令被整合到实际处理器设计中的专用处理器。处理器610本质上可以是完全独立的计算系统,包含多个核或处理器、总线、存储器控制器、高速缓存等。多核处理器可以是对称的或不对称的。
[0097]
为了能够使用户与计算设备600交互,输入设备645可以表示任何数量的输入机构,例如用于语音的麦克风、用于手势或图形输入的触敏屏幕、键盘、鼠标、移动输入、语音等等。输出设备635也可以是本领域技术人员已知的多种输出机构中的一种或更多种。在一些情况下,多模式系统可以使得用户能够提供多种类型的输入以与计算设备600进行通信。通信接口640通常可以支配和管理用户输入和系统输出。对在任何特定硬件装置上的操作没有限制,因此在开发过程中,此处的基本特征可以很容易地被替换为改进的硬件或固件装置。
[0098]
存储设备630可以是非易失性存储器并且可以是硬盘或是可以存储由计算机访问的数据的其他类型的计算机可读介质,例如盒式磁带、闪存卡、固态存储设备、数字多功能
磁盘、暗盒、随机存取存储器(ram)625、只读存储器(rom)620及其混合。
[0099]
存储设备630可以包括用于控制处理器610的服务632、634和636。其他硬件或软件模块是可预期的。存储设备630可以连接到系统总线605。一方面,执行特定功能的硬件模块可以包括存储在计算机可读介质中的软件部件,该软件部件与诸如处理器610、总线605、显示器635等必要的硬件部件连接,以执行该功能。
[0100]
图6b示出了具有可以表示组织计算系统104的至少一部分的芯片组架构的计算机系统650。计算机系统650可以是可用于实施所公开技术的计算机硬件、软件和固件的示例。系统650可以包括表示能够执行被配置为执行识别的计算的软件、固件和硬件的任意数量的物理和/或逻辑上的不同的资源的处理器655。处理器655可以与芯片组660通信,芯片组660可以控制对处理器655的输入和来自处理器655的输出。在该示例中,芯片组660将信息输出到输出665(例如,显示器),并且芯片组660可以读取信息并将信息写入到存储设备670,存储设备670可以包括例如磁介质和固态介质。芯片组660还可以从ram 675读取数据并向ram 675写入数据。可以提供用于与各种用户接口部件685连接的桥680,以用于与芯片组660连接。这样的用户接口部件685可以包括键盘、麦克风、触摸检测和处理电路、诸如鼠标的定点设备等等。通常,对系统650的输入可以来自机器生成的和/或人工生成的各种源中的任何一种。
[0101]
芯片组660还可以与可能具有不同物理接口的一个或更多个通信接口690连接。这样的通信接口可以包括用于有线和无线局域网、宽带无线网络以及个人局域网的接口。本文公开的用于生成、显示和使用gui的方法的一些应用可以包括通过物理接口接收有序数据集,或者可以由机器本身通过处理器655分析存储在存储器670或675中的数据来生成用于生成、显示和使用本文公开的gui的方法的一些应用。此外,机器可以通过用户接口部件685接收来自用户的输入并通过使用处理器655解释这些输入来执行适当的功能,例如浏览功能。
[0102]
可以理解,示例系统600和650可以具有多于一个处理器610或者是联网在一起以提供更大处理能力的计算设备组或集群的一部分。
[0103]
虽然前述内容是针对本文描述的实施例,但是在不背离其基本范围的情况下,可以设计其他和进一步的实施例。例如,本公开的各方面可以硬件或软件或硬件和软件的组合来实施。本文描述的实施例可以被实施为与计算机系统一起使用的程序产品。程序产品的程序限定了实施例的功能(包括本文描述的方法)并且可以被包含在各种计算机可读存储介质上。说明性的计算机可读存储介质包括但不限于:(i)永久存储信息的不可写存储介质(例如,计算机内的只读存储器(rom)设备,诸如可由cd-rom驱动器读取的cd-rom磁盘、闪存、rom芯片或任何类型的固态非易失性存储器);以及(ii)存储可变信息的可写存储介质(例如,软盘驱动器中的软盘或硬盘驱动器或任何类型的固态随机存取存储器)。当承载指导所公开实施例的功能的计算机可读指令时,这样的计算机可读存储介质是本公开的实施例。
[0104]
本领域技术人员将理解,前述示例是示例性的而非限制性的。在阅读说明书和研究附图后,所有置换、增强、等效和改进对于本领域技术人员而言是显而易见的,都被包括在本公开的真实本质和范围内。因此,以下所附权利要求旨在包括落入这些教导的真实本质和范围内的所有这样的修改、置换和等效。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1