学习模型计算资源的动态分配和重新分配的制作方法
学习模型计算资源的动态分配和重新分配
1.相关申请
2.本技术要求于2020年3月13日提交的美国专利申请第16/818,955号的优先权,其全部内容通过引用并入本文。
技术领域
3.本公开总体上涉及对神经网络计算的动态监测以及相应的对计算资源的分配。
背景技术:
4.当前的机器学习模型在被一个或多个处理器执行以计算一个或多个机器学习任务(例如,机器学习模型的训练或计算一个或多个数据集)的过程中引发大量的计算开销。越来越多地,机器学习任务计算通常所需的规模的计算资源可以被托管在大规模计算系统处(例如,数据中心、云计算系统或其组合)。大规模计算系统可以聚集许多分布式计算节点,这些分布式计算节点托管物理处理器或虚拟处理器(例如,中央处理单元(“cpu”))或加速器(例如图形处理单元(“gpu”))。
5.物理处理器或虚拟处理器可以包括任何数量的核心,并且诸如机器学习任务之类的大规模计算任务可以由跨多个节点的多个处理器的多个核心、以及多个集群来计算。此外,模型的许多副本可以跨多个计算节点分布,用于在不同副本处进行相同任务的缩放并发处理。随着机器学习日益成为商业决策、智能和研究的支柱,由于通常由机器学习任务引发的计算负载的规模,托管和提供大规模计算系统能够远程访问的这种计算资源对于大多数现代工业是重要的服务。
6.虽然期望所托管的计算资源的可用性能够针对客户的个性化计算需求进行缩放,但在实践中,这些计算需求的实际规模通常不容易提前查明。所托管的计算资源的大多数用户不一定是机器学习或机器学习模型实施的领域的技术人员,并且因此可能没有能力在执行计算任务之前确定所需的计算资源的规模。即使对于本领域的技术人员来说,由于当今通常实施的多层人工神经网络(“ann”)模型的复杂性,机器学习模型在训练和计算期间的行为也是意想不到的。
7.因此,需要更好地为大规模计算任务分配计算资源。
附图说明
8.下面参照附图进行详细描述。在这些图中,附图标记的最左侧的(一个或多个)数字标识了该附图标记首次出现的图。在不同的图中使用相同的附图标记表示相似或相同的项。附图中描绘的系统不是按比例绘制的,并且图中的组件可以彼此不按比例绘制。
9.图1a示出了机器学习任务模型的副本的密集互连相邻层的示例。图1b示出了机器学习任务模型的副本的稀疏互连相邻层的示例。
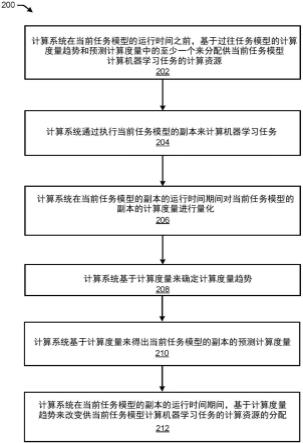
10.图2示出了根据本公开的示例实施例的计算资源分配方法。
11.图3示出了任务模型的副本随时间的学习斜率的示例。
12.图4a示出了根据本公开的示例实施例的被配置为计算机器学习任务的计算系统的示例系统架构。图4b示出了根据本公开的示例实施例的(一个或多个)专用处理器的示例。
13.图5示出了根据本公开的示例实施例的托管计算资源和模型的大规模计算系统的架构图。
具体实施方式
14.概述
15.本公开描述了用于改进向机器学习任务的计算分配计算资源的技术,包括在托管机器学习模型的大规模计算系统上。一种方法包括:计算系统在当前任务模型的运行时间之前,基于过往任务模型的计算度量趋势和预测计算度量中的至少一个来分配供当前任务模型计算机器学习任务的计算资源。该方法还包括:计算系统通过执行当前任务模型的副本来计算机器学习任务。该方法还包括:计算系统在当前任务模型的副本的运行时间期间对当前任务模型的副本的计算度量进行量化。该方法还包括:计算系统基于计算度量来确定计算度量趋势。该方法还包括:计算系统基于计算度量来得出当前任务模型的副本的预测计算度量。该方法还包括:计算系统在当前任务模型的副本的运行时间期间,基于计算度量趋势来改变供当前任务模型计算机器学习任务的计算资源的分配。
16.另外,本文所描述的技术可以由具有存储计算机可执行指令的非暂时性计算机可读介质的系统来执行,所述计算机可执行指令在由一个或多个处理器执行时执行上文所描述的方法。
17.另外,本文所描述的技术可以由大规模计算系统来执行,该大规模计算系统包括任何数量的节点和/或边缘节点,这些节点和/或边缘节点托管如上所述的物理系统或虚拟系统,其中,上述方法的步骤可以分布在这些节点和/或边缘节点中以用于执行。
18.示例实施例
19.诸如人工神经网络(“ann”)模型之类的机器学习模型通常由单元(例如神经元)组成,这些单元互连在多个层中。分层模型可以通过模型之内和之间、及其组合的一些结构互连,这些结构为例如完全连接结构、前馈结构、反向传播结构、反馈环路和它们的任何组合。模型的单元可以各自构成被存储在计算机可读存储介质上的计算机可读指令,每个指令可以由处理器执行以使得处理器执行由该单元指定的特定计算(例如求解等式)。模型可以通过分布式计算框架来实现,该分布式计算框架实现线程化、并发性和异步计算,例如,tensorflow等。
20.模型可以包括预定架构并且可以包括经训练架构。预定架构可以包括例如由人操作员或研究员设置以控制要由模型的每个单元求解的等式的模型单元的等式变量。其他预定架构可以包括例如单元的运行时间设定,例如学习率或世代数(number of epoch)。学习率可以是控制在模型训练期间模型参数被更新的速率的数值。世代数可以是确定训练数据集被模型完全计算的次数的数值。通常,这些可以被称为“超参数”,以将它们与随后将描述的其他参数区分开。
21.经训练架构可以包括例如不是由人操作员或研究员设置,而是通过在训练模型期间通过计算标记训练数据集来更新变量值而设置的模型单元的等式变量。在本公开通篇,
这些变量可以被称为“参数”(与“超参数”不同)或“权重”。
22.在诸如训练之类的机器学习任务的计算期间执行模型(为清楚起见,下文中可以被称为“任务模型”)的大规模计算系统可以被配置为向其计算分配一定量的各种计算资源。例如,可以为任务的计算分配一定数量的处理器核心。所分配的核心可以是也可以不是同一物理处理器的核心,并且还可以是大规模计算系统的任何数量的物理处理器或虚拟处理器的物理核心或虚拟核心。核心可以根据大规模计算系统的物理节点或虚拟节点的数量、物理或虚拟节点的数量、以及这些物理节点或虚拟节点的物理集群或虚拟集群的数量来分配。核心可以各自连接到一个或多个公共数据总线,这些公共数据总线可以在核心、存储装置和计算系统的其他元件之间传输数据。数据总线可以是例如外围组件互连快速(“pcie”)连接等。
23.向计算任务分配计算资源可以通过计算系统发送根据应用编程接口(“api”)的指令来执行。根据本公开的示例实施例,api可以定义协议,计算系统可以通过这些协议对计算资源进行分组并且为计算一个或多个机器学习任务分配这些计算资源,这些任务可以被api定义为线程、上下文、进程等,以用于多任务、并发处理、上下文切换、调度以及计算系统的操作系统的这些功能。
24.例如,根据本公开的示例实施例,api可以是来自加利福尼亚州圣克拉拉的英伟达公司的统一计算设备架构(“cuda”)接口。cuda可以提供api,以将任何数量的核心、节点和其中的核心、和/或集群以及其中的核心和节点配置为与计算系统的计算资源管理组件集成,以使计算系统能够监测计算资源使用等。因此,计算系统可以能够指定计算资源,例如由诸如cuda_visible_devices之类的api元件初始化和配置的核心。如上所述的分布式计算框架可以具有与用于分配计算资源以将线程、进程等分配给特定核心的api相兼容的api。
25.此外,在机器学习任务的计算期间执行任务模型的大规模计算系统可以被配置为在计算机可读存储介质上分配存储空间(如随后在本公开中定义的),以存储用于任务模型的计算的任务模型的附加副本。所分配的存储空间可以是大规模计算系统的任何数量的物理节点或虚拟节点的物理存储装置或虚拟存储装置。空间可以根据要被存储以供执行的任务模型的副本的数量来分配。
26.机器学习模型的训练通常是计算密集和大规模的,因此在计算核心方面和在存储空间方面分配不足的计算资源和分配过度的计算资源的结果两者都是不期望的。由于大规模的机器学习模型计算,用不足的计算资源处理计算可能导致计算受到有限计算资源的制约,并且计算时间自然会变得拖延(这种计算时间会延长数周或数月)。此外,由于大规模计算系统中的大规模资源分配(其中例如分配可以以节点集群为单位),过度分配的影响可能在多个用户或多个任务上变得系统性地加剧,导致所分配的计算资源大规模地变得空闲,剥夺其他用户和其他任务受到空闲资源的益处。
27.在某种程度上,机器学习模型的计算开销可以在将资源分配给模型的副本之前在某种程度上被估计,但是对计算工作量和计算开销的估计(尤其是基于关于模型架构的先验知识)可能缺乏精度。例如,关于模型的先验知识可以包括该模型的大小的知识,其可以以单元、层、互连以及该模型的其他这样的可量化特征来测量。理论上,可以假设计算工作量和开销随着单元的数量、层的数量、互连的数量以及架构规模的其他这样的可量化方面
而增加。因此,自然地,资源分配可以与模型架构的规模成比例。
28.然而,在实践中,由于预训练模型和经训练模型之间的差异(通过使用标记训练数据集来训练模型副本而学习),架构规模可能不直接与使用模型副本的计算的计算工作量和开销相关。训练通常是指迭代过程,其中在每个世代期间,标记训练数据集通过模型(或其副本)被循环,模型基于训练数据集的特征来计算诸如分类和标签等之类的结果并且学习权重集的值(即,模型的参数)。根据标记训练数据集,基于计算的结果来定义代价函数以最大化偏离正确结果的错误结果的代价。通过诸如梯度算法等之类的优化算法,可以基于对模型副本的训练的每次迭代来在每个世代中迭代地求解代价函数,将学习的权重集反馈回模型副本中以用于训练的下一次迭代,直到学习权重收敛于一组值为止(即,学习权重的最后一次迭代的值与前一次迭代没有显著不同)。
29.模型副本的学习权重集可以包括针对模型的每个单元的学习参数。学习参数可以对应于模型的不同单元之间的互连,其中,来自第一单元处的计算的变量输出可以通过学习参数进行加权,并且作为用于第二单元处的计算的变量被转发到第二单元。学习参数可以被记录为一个或多个矩阵的系数,每个系数表示模型的每个单元之间的可能互连。具有非零值的系数(即,学习参数)可以表示模型的两个单元之间的互连。具有零值的系数(即,学习参数)可以表示模型的两个单元中没有互连(即,来自一个单元的输出在与另一单元的互连处被加权为零,并且因此不作为因子引入到该另一单元的计算中)。
30.模型副本的单元之间的互连可以具有不同的密集或稀疏程度。在模型中,较密集的互连可以由大多具有非零值的系数(即,学习参数)来反映,这使得大多数单元的输出在与其他单元的大多数互连处被加权为非零,并且因此作为因子引入到这些其他单元的计算中。在模型中,较稀疏的互连可以由大多具有零值的系数(即,学习参数)来反映,使得大多数单元的输出在与其他单元的大多数互连处被加权为零,并且因此不作为因子引入到这些其他单元的计算中。因此,可以使用根据程度的描述(例如,稀疏互连、密集互连或完全互连)来描述模型副本的相邻层。
31.图1a示出了机器学习任务模型的副本的密集互连相邻层的示例。图1b示出机器学习任务模型的副本的稀疏互连相邻层的示例。这里,第一层的单元表示为102,并且第二层的单元表示为104。
32.机器学习领域的技术人员将理解,机器学习模型的高度互连性对于实现各种目的而言往往是不期望的。例如,在模型高度互连或密集的情况下,这可能倾向于指示该模型是过拟合的,这意味着该模型在计算训练数据集时具有高准确率,但同时在计算其他数据集时具有次优或不合格的准确率。因此,可能希望通过例如在训练期间或之后修剪模型中的互连,或者通过在模型架构上强加各种规则以引起稀疏互连的训练,来增强模型的经训练副本中的稀疏性。
33.另外,在不考虑模型的副本是否高度互连的情况下,在训练之前预定的模型的单元的实质数量可能对通过执行模型的经训练副本而执行的计算没有显著贡献。例如,模型训练的常见结果是某些单元可能最终对经训练模型的输出贡献不足(即使没有将它们相应的输出加权为零)。然而,通常只有在训练完成之后才能观察到特定单元或单元路径的不足贡献,因此这种观察不能用作分配计算资源的基础。此外,训练可能会由于梯度消失现象而过早地实质停止,其中,诸如梯度算法之类的优化算法由于达到局部最小值而不能进一步
通过模型训练的后续迭代来调整权重。因此,可能期望对模型的经训练副本利用正则化过程(例如,丢弃(dropout)),以便例如在模型训练的至少一定次数的迭代之后从模型中消除单元(在这之后,训练可以基于模型的正则化副本而恢复运行或重新开始)。
34.本领域技术人员已知的这些和其他技术可能导致单元的数量、层的数量以及模型的其他这样的预定架构是训练后的模型的副本的计算工作量和开销的不准确预测因子,因为模型的预定架构可能显著不同于模型的经训练副本,尤其是在实施稀疏性、应用丢弃和其他这样的技术时。例如,实施了稀疏性的经训练模型可能比密集的经训练模型更不可能过早地在局部最小值处下降到为0的收敛速率,并且因此更可能的是随着计算的进行,仅模型的经训练副本的单元的有限子集会在计算上密集地参与。因此,基于模型的预定架构的对计算资源的分配可能由于计算资源的过度分配或不足分配而变得过时和低效。
35.本公开的示例实施例提供了为在大规模计算系统上运行的任务模型的副本动态分配和重新分配计算资源的方法。图2示出了根据本公开的示例实施例的计算资源分配方法200。
36.在步骤202,计算系统在当前任务模型的运行时间之前,基于过往任务模型的计算度量趋势和预测计算度量中的至少一个来分配供当前任务模型计算机器学习任务的计算资源。
37.根据本公开的示例实施例,可以通过如下所述的类似方式从在计算其他机器学习任务的其他任务模型上执行的计算资源分配方法200的先前迭代中学习任何数量的计算度量趋势和预测计算度量。基于这样的计算度量趋势和预测计算度量(其可以包括例如:如下所述的随时间的稀疏性和随时间的学习斜率、如下所述的由具有相应的特定预定架构的过往任务模型先前计算的机器学习任务的预期完成时间、或者如下所述的具有相应的特定预定架构的过往任务模型的每个副本之间的计算工作量和开销的预期分布),计算系统可以将各种过往任务模型的预定架构与当前任务模型的预定架构进行比较。基于具有与当前任务模型的预定架构相似的预定架构的任何过往任务模型的计算度量趋势和预测计算度量,计算系统可以向当前任务模型分配计算资源。
38.例如,在当前任务模型具有与随时间趋向于稀疏的过往任务模型相似的预定架构的情况下,计算系统可以根据分配会随时间被减少的预期来向当前任务模型分配计算资源。分配会随时间被减少的预期可能意味着例如被分配给当前任务模型的核心、节点和/或集群可能不被长期保留。因此,计算系统的与计算资源分配有关的其他组件(例如,调度器或负载均衡器)可以在向其他计算任务分配计算资源时参考分配会随时间被减少的该预期。
39.在当前任务模型具有与随时间不趋向于稀疏(或者甚至随时间趋向于密集)的过往任务模型相似的预定架构的情况下,计算系统可以根据分配会随时间被保留的预期来向当前任务模型分配计算资源。因此,计算系统的与计算资源分配有关的其他组件(例如,调度器或负载均衡器)可以在向其他计算任务分配计算资源时参考分配会被长期保留的该预期。
40.在步骤204,计算系统通过执行当前任务模型的副本来计算机器学习任务。计算系统可以是例如如上所述的大规模计算系统。
41.在步骤206,计算系统在当前任务模型的副本的运行时间期间对当前任务模型的
副本的计算度量进行量化。根据本公开的示例实施例,由执行当前任务模型的副本的大规模计算系统的处理器计算机器学习任务的期间的当前任务模型的副本的一个或多个计算度量可以以周期性间隔被量化。
42.在步骤208,计算系统基于计算度量来确定计算度量趋势。可以随着时间的推移在计算度量中观察到趋势,并且基于该趋势,可以将大规模计算系统的处理器分配用于计算机器学习任务或将其分配为远离计算机器学习任务。
43.根据本公开的示例实施例,当前任务模型的副本的计算度量可以是层间稀疏性测量。稀疏性可以是从当前任务模型的输出层开始,在当前任务模型的相邻层之间连续地采取的比较测量。在当前任务模型的每一层,可以通过将由当前层的单元接收到的非零加权输入的数量与当前任务模型的前一层中的前馈单元的数量在比例上进行比较来确定稀疏性测量。不管前一层的单元如何与当前层的单元互连,对输入的加权可能导致一些互连不能对当前层的计算有贡献。因此例如如果在当前层接收到的加权输入对于前一层的前馈单元在比例上数量很少,则可以在当前层和前一层之间测量到高稀疏性(即,低互连性)。
44.根据本公开的示例实施例,当前任务模型的副本的层间稀疏性测量可以进一步通过各种运算而被聚集,以确定当前任务模型的副本的整体稀疏性测量。聚合运算可以是例如对当前任务模型的层间稀疏性测量的求和运算、对当前任务模型的层间稀疏性测量的乘积运算、或对当前任务模型的层间稀疏性测量的求平均运算。可以对当前任务模型的每个聚集的层间稀疏性测量执行归一化,以便标准化每对相邻层之间的层间稀疏性测量的影响。聚合运算可以是例如对当前任务模型的层间稀疏性测量的矩阵运算,其中,稀疏性测量可以被聚合为矩阵的系数。可以对这样的聚集矩阵执行正则化,以便标准化每对相邻层之间的层间稀疏性测量的影响。
45.根据本公开的示例实施例,预期当前任务模型的总体更稀疏副本的各个互连比当前任务模型的总体更密集副本的各个互连更可能被更高地加权。与数量较大的较低加权的互连相比,数量较少的较高加权的互连预期在计算工作量和开销方面更密集,这是因为较高加权的互连可能导致在这些互连上传递的变量在量级上更大,并且跨当前任务模型中的多对层的较高加权的互连可能加剧该放大效果。其中稀疏互连被向上加权(up-weighted)以产生大量级的变量的当前任务模型的副本可以相应地比其中密集互连没有被类似地向上加权的同一当前任务模型的副本更长地保持参与计算,而当前任务模型的具有密集互连的那些副本可能由于上述缺点而过早地停止。因此,即使可以预期密集互连的任务模型可能总体上比稀疏互连的任务模型具有更密集的计算工作量和开销,但是反过来,可以预当前任务模型的期稀疏互连的副本比当前任务模型的密集互连的副本占用计算资源的时间更长。
46.因此,根据本公开的示例实施例,计算度量趋势可以是如下的确定:被执行以计算机器学习任务的当前任务模型的一些副本随时间趋向于稀疏。这可以表明针对那些随时间趋向于密集互连的副本,向当前任务模型的副本的对计算资源的分配可以随着时间被减少(但由于那些随时间趋向于稀疏互连的副本而没有被大幅度减少),或者由于当前任务模型的更多副本随时间趋向于密集互连或过早地下降到收敛速率为0而存储装置应当被解除分配。
47.根据本公开的示例实施例,当前任务模型的副本的计算度量可以是当前任务模型
的副本的学习斜率。经过当前任务模型的副本的多次迭代计算,通过诸如梯度下降之类的优化算法,当前任务模型的副本的参数可以随时间接近一组稳定的非零值,其中,每次迭代之间的差异变得可以忽略。因此,学习斜率可以描述在训练期间当前任务模型的任何副本随时间向结束状态收敛的速率,其中,结束状态表示当前任务模型的副本的收敛。
48.学习斜率可以通过随时间测量到的各种其他计算度量的导数(斜率)来量化。根据本公开的示例实施例,学习斜率可以通过当前任务模型的副本随时间的准确度的斜率来量化。准确度可以通过在训练的迭代之后当前任务模型对标记训练数据集的输出与训练数据集的标记相匹配的程度来测量。根据本公开的示例实施例,学习斜率可以通过当前任务模型的副本随时间的损失的斜率来量化。损失可以是如上所述的当前任务模型的每次迭代的代价函数的输出。根据本公开的示例实施例,学习斜率可以由当前任务模型的副本随时间的混淆矩阵来量化。混淆矩阵可以包含表示每次迭代的当前任务模型的输出的真肯定、假肯定、真否定和假否定的系数。学习斜率因此可以描述这些混淆矩阵系数中的一个或多个随时间的变化。
49.在学习模型的副本的参数收敛后,由于计算机器学习任务的迭代中参数值的稳定性,可能需要浮点算术(例如浮点乘法运算)中的较少有效数字来维持机器学习任务的每次迭代的准确度,因为收敛的权重值不太可能在量级上波动,从而导致需要更多有效数字。因此,在学习模型的副本的参数收敛后,被分配给学习模型的副本的存储空间可以在存储器方面减少,并且计算系统可以减少在计算机器学习任务中涉及的有效数字的数量,从而基于参数值的收敛增加了准确度的置信度而降低浮点算术运算的精度。
50.图3示出了任务模型的副本随时间的学习斜率的示例(其中,x轴是时间,y轴可以是如上所述的计算度量,从该计算度量可以得出学习斜率导数,但不限于此)。两个导数(学习斜率302和304)大致以虚线示出。这里,可以观察到学习斜率302最初是陡峭的,因为任务模型的副本的参数最初在任务模型的副本的不同单元之间是不同的。随着时间的推移,参数在任务模型的副本的单元之间交换,并且逐渐学习到用于这些参数的新值,这些新值收敛(在非零值处)。可以观察到收敛发生在学习斜率304进入平稳期的地方。
51.在步骤210,计算系统基于计算度量来得出当前任务模型的副本的预测计算度量。根据本公开的示例实施例,计算系统可以将当前任务模型的副本的计算度量输入到学习斜率进展学习模型中。根据本公开的示例实施例,随时间的学习斜率可以被输入到学习斜率进展学习模型中,该学习斜率进展学习模型可以是第二单独的学习模型。在将学习斜率随时间的值作为模型输入时,学习斜率进展学习模型可以通过诸如回归之类的方法来学习描述学习斜率随时间的进展的趋势、或将趋势拟合到学习斜率随时间的进展。基于以这种方式学习的或拟合的趋势,学习斜率进展学习模型可以由一个或多个处理器执行,以预测在已输入学习斜率的时间段之后的未来学习斜率,并且由此可以推断和输出当前任务模型的预测计算度量。预测计算度量可以包括例如正在由当前任务模型计算的机器学习任务的预期完成时间、或当前任务模型的每个副本之间的计算工作量和开销的预期分布。
52.根据本公开的示例实施例,学习斜率进展学习模型可以是构成被存储在计算机可读存储介质上的计算机可读指令的任何合适的计算模型,该计算模型能够进行操作以基于当前任务模型的计算度量来学习趋势,并且基于该趋势来推断当前任务模型的预测计算度量。例如,学习斜率进展学习模型可以是统计模型,例如根据贝叶斯或其他统计分布的回归
模型。根据本公开的示例实施例,学习斜率进展学习模型可以是结合诸如长期短期存储器(“lstm”)架构之类的递归神经网络(“rnn”)架构的模型,以使得学习斜率进展学习模型能够拟合较早的计算度量如何影响分开时间跨度的较晚的计算度量。因此通常学习斜率进展学习模型可以通过推断、预测、拟合、建模或任何其他这样的适当计算来从当前任务模型的已知计算度量得出当前任务模型的预测计算度量。
53.在步骤212,计算系统在当前任务模型的副本的运行时间期间,基于计算度量趋势来改变供当前任务模型计算机器学习任务的计算资源的分配。根据本公开的示例实施例,基于作为计算度量的稀疏性测量,在稀疏性测量(例如,模型的副本的整体稀疏性测量)指示当前任务模型的副本随时间趋向于稀疏的情况下,计算系统可以确定向当前任务模型的副本的对计算资源(例如,核心、节点或集群)的分配随后应随时间被减少(但不大幅度减少),如上所述。在稀疏性测量指示当前任务模型的副本不随时间趋向于稀疏的情况下,计算系统可以确定向当前任务模型的副本的对计算资源的分配随后不应随时间被减少。在稀疏性测量指示当前任务模型的副本随时间趋向于密集的情况下,计算系统可以确定向当前任务模型的副本的对计算资源的分配随后应随时间被增加。
54.根据本公开的示例实施例,基于作为计算度量的学习斜率,在学习斜率指示随时间相对较快收敛的情况下(例如,准确度随时间相对较快地增加,损失随时间相对较快地减小,或者混淆矩阵中的真肯定和/或真否定随时间相对较快地增加、和/或假肯定和/或假否定随时间相对较快地减少),计算系统可以确定向当前任务模型的对计算资源(例如,核心、节点或集群等)的分配应随时间被减少,并且进一步地,确定被分配给当前任务模型的副本的存储空间应随时间被减少,直到当前训练世代结束为止,并且当前任务模型的收敛副本应相应地从存储装置中删除,从而在训练迭代结束时只留下经训练的参数。
55.此外,先前利用分配会随时间被减少的预期根据步骤202而被分配的那些计算资源可以比先前利用分配会随时间被保留的预期而被分配那些计算资源相对更早地被分配离开当前任务模型的副本。
56.在学习斜率指示随时间相对较慢的收敛(例如,准确度随时间缓慢增加或不增加,损失随时间缓慢减少或不减少,或混淆矩阵中的真肯定和/或真否定随时间缓慢增加或不增加、和/或假肯定和/或假否定随时间缓慢减少或不减少)的情况下,计算系统可以确定向当前任务模型的副本的对计算资源(例如,核心、节点、或集群)的分配应不随时间被减少或应随时间被增加,并且进一步地,确定被分配给当前任务模型的副本的存储空间不应随时间减少,因为当前任务模型的副本不太可能已收敛并且因此不应在世代结束之前从存储装置中删除。
57.此外,先前利用分配会随时间被减少的预期根据步骤202而被分配给其他任务的那些计算资源可以被分配给当前任务模型的副本,而非先前利用分配会随时间被保留的预期而被分配给其他任务的那些计算资源。
58.因此,本公开的示例实施例提供了一种方法,通过该方法,可以使用由相似任务模型计算的过往机器学习任务的趋势和预测度量来将计算资源预测性地分配给当前任务模型的机器学习任务。此外,在当前任务模型的副本的运行时间期间,机器学习任务的计算的计算度量(随时间而被量化)可以被用来得出计算度量趋势和预测计算度量。在当前任务模型的运行时间期间,可以参考随时间的计算度量来重新分配计算资源以用于由当前任务模
型的副本来计算机器学习任务。
59.图4a示出了根据本公开的示例实施例的被配置为计算机器学习任务的计算系统400的示例系统架构。
60.根据本公开的示例实施例,计算系统400可以包括任何数量的(一个或多个)通用处理器402和任何数量的(一个或多个)专用处理器404。(一个或多个)通用处理器402和(一个或多个)专用处理器404可以是物理处理器和/或可以是虚拟处理器,并且可以包括任何数量的物理核心和/或虚拟核心,并且可以分布在任何数量的物理节点和/或虚拟节点和任何数量的物理集群和/或虚拟集群中。(一个或多个)通用处理器402和(一个或多个)专用处理器404可以各自被配置为执行被存储在计算机可读存储介质上的一个或多个指令(例如,如上所述的模型),以使得(一个或多个)通用处理器402或(一个或多个)专用处理器404计算诸如机器学习任务之类的任务。(一个或多个)专用处理器404可以是具有便于诸如训练和推断计算之类的机器学习任务的计算的硬件或软件的计算设备。例如,(一个或多个)专用处理器404可以是(一个或多个)加速器,例如如上所述的gpu等。为了便于诸如训练和推断之类的任务的计算,(一个或多个)专用处理器404例如可以实现用于计算诸如矩阵运算之类的数学运算的引擎。
61.(一个或多个)通用处理器402和(一个或多个)专用处理器404可以通过操纵在一个分立的物理状态和下一个物理状态之间进行区分并改变这些状态的开关元件而从该一个分立的物理状态转换到该下一个物理状态来执行操作。开关元件通常包括维持两个二进制状态之一的电子电路(例如触发器)、以及基于一个或多个其他开关元件的状态的逻辑组合而提供输出状态的电子电路(例如逻辑门)。这些基本开关元件可以被组合以创建更复杂的逻辑电路,包括寄存器、加法器-减法器、算术逻辑单元和浮点单元等。
62.计算系统400还可以包括通过数据总线408通信地耦合到如上所述的(一个或多个)通用处理器402和(一个或多个)专用处理器404的系统存储器。系统存储器406可以是物理的或虚拟的,并且可以分布在任何数量的节点和/或集群中。系统存储器406可以是易失性的(例如ram)、非易失性的(例如rom、闪存、微型硬盘驱动器、存储卡等)、或它们的某种组合。
63.数据总线408提供(一个或多个)通用处理器402、(一个或多个)专用处理器404以及计算系统400的其余组件和设备之间的接口。数据总线408可以提供到用作计算系统400中的主存储器的ram的接口。数据总线408还可以提供到计算机可读存储介质的接口,该计算机可读存储介质为例如只读存储器(“rom”)或非易失性ram(“nvram”)等,用于存储有助于启动计算系统400并在各种组件和设备之间传送信息的基本例程。rom或nvram还可以存储根据本文所述的配置的计算系统400的操作所需的其他软件组件。
64.计算系统400可以使用通过网络到远程计算设备和计算机系统的逻辑连接来在联网环境中操作。数据总线408可以包括用于通过nic 412(例如千兆以太网适配器)提供网络连接性的功能性。nic 412能够通过网络将计算系统400连接到其他计算设备。应当理解,计算系统400中可以存在多个nic 412,将计算系统400连接到其他类型的网络和远程计算机系统。
65.计算系统400可以连接到为计算系统400提供非易失性存储装置的存储设备414。存储设备414可以存储操作系统416、程序418、bios和已经在本文中进行了更详细的描述的
数据。存储设备414可以通过连接到数据总线408的存储控制器420而连接到计算系统400。存储设备414可以由一个或多个物理存储单元组成。存储控制器420可以通过串行连接scsi(“sas”)接口、串行高级技术连接(“sata”)接口、光纤信道(“fc”)接口、或用于在计算机和物理存储单元之间进行物理连接和传送数据的其他类型的接口来与物理存储单元接口连接。
66.计算系统400可以通过转换物理存储单元的物理状态以反映正在被存储的信息,来将数据存储在存储设备414上。在本说明书的不同实施例中,物理状态的特定转换可以取决于各种因素。这些因素的示例可以包括但不限于:用于实现物理存储单元的技术、存储设备414被表征为主存储装置还是辅存储装置等。
67.例如,计算系统400可以通过经由存储控制器420发出指令以改变磁盘驱动单元内的特定位置的磁特性、光学存储单元中的特定位置的反射或折射特性、或者固态存储单元中的特定电容器、晶体管或其他分立组件的电气特性,来将信息存储到存储设备414。在不脱离本说明书的范围和精神的情况下,物理介质的其他变换也是可能的,提供前述示例仅是为了便于说明。计算系统400还可以通过检测物理存储单元内的一个或多个特定位置的物理状态或特性,来从存储设备414读取信息。
68.除了上述存储设备414之外,计算系统400还可以访问其他计算机可读存储介质以存储和检索信息,例如,程序模块、数据结构或其他数据。本领域技术人员应当理解,计算机可读存储介质是提供对数据的非暂时性存储并且可以由计算系统400访问的任何可用介质。在一些示例中,由网络覆盖的路由器节点和/或其中所包括的任何组件执行的操作可以由类似于计算系统400的一个或多个设备支持。换句话说,为计算机机器学习任务而执行的操作中的一部分或全部可以由在一个或多个网络上的一个或多个逻辑结构平面上以联网的、分布式的布置操作的一个或多个计算系统400来执行,如随后参考图5进一步详细描述的。
69.作为示例而非限制,计算机可读存储介质可以包括以任何方法或技术实现的易失性和非易失性、可移除和不可移除介质。计算机可读存储介质包括但不限于ram、rom、可擦除可编程rom(“eprom”)、电可擦除可编程rom(“eeprom”)、闪存或其他固态存储技术、光盘rom(“cd-rom”)、数字多功能盘(“dvd”)、高清dvd(“hd-dvd”)、blu-ray或其他光学存储装置、磁盒、磁带、磁盘存储装置或其他磁存储设备、或任何其他可用于以非暂时性方式存储所需信息的介质。
70.如上所简述的,存储设备414可以存储用于控制计算系统400的操作的操作系统416。根据一个实施例,操作系统包括linux操作系统及其衍生物。根据另一个实施例,操作系统包括来自华盛顿州雷德蒙德的微软公司的windows操作系统。应该理解,也可以使用其他操作系统。存储设备414可以存储计算系统400使用的其他系统或应用程序和数据。
71.在一个实施例中,存储设备414或其他计算机可读存储介质被编码有计算机可执行指令,这些指令在被加载到计算机中时,将计算机从通用计算系统转换成能够实现本文所述实施例的专用计算机。这些计算机可执行指令通过指定(一个或多个)通用处理器402和(一个或多个)专用处理器404如何在状态之间转换来转换计算系统400,如上所述。根据一个实施例,计算系统400可以访问存储计算机可执行指令的计算机可读存储介质,所述计算机可执行指令在由计算系统400执行时执行以上关于图1至图3描述的各种过程。计算系
统400还可以包括其上存储有用于执行本文所述的任何其他计算机实现的操作的指令的计算机可读存储介质。
72.图4b示出了根据本公开的示例实施例的(一个或多个)专用处理器404的示例。(一个或多个)专用处理器404可以包括任何数量的(一个或多个)核心422。(一个或多个)专用处理器404的处理能力可以分布在(一个或多个)核心422中。每个核心422可以包括本地存储器424,其可以包含用于执行计算机器学习任务的初始化数据,例如,参数和超参数。每个核心422还可以被配置为执行在核心422的本地存储装置428上初始化的一个或多个模型单元集合426,每个模型单元集合426可以由(一个或多个)核心422执行,包括由多个核心422并发执行,以执行例如用于机器学习任务的诸如矩阵运算等之类的算术运算。
73.图5示出了根据本公开的示例实施例的托管计算资源和模型的大规模计算系统500的架构图。这里示出了用于托管如上所述的计算资源的可能的架构实施例。
74.大规模计算系统500可以在物理节点或虚拟节点504(1)、504(2)、
……
、504(n)(其中任何非特定节点可以称为节点504)的网络502上实现,这些节点由物理网络连接或虚拟网络连接进行连接。网络502还可以终止于位于网络502的物理边缘和/或逻辑边缘的物理边缘节点或虚拟边缘节点506(1)、506(2)、
……
、506(n)(其中任何非特定边缘节点可以被称为边缘节点506)。
75.在本公开的示例实施例中描述的模型508可以具有分布在任何数量的节点504和边缘节点506上的单元,其中,这些单元可以被存储在任何数量的节点504的物理存储装置或虚拟存储装置(“节点存储装置510”)和/或任何数量的边缘节点506的物理存储装置或虚拟存储装置(“边缘存储装置512”)上,并且可以被加载到任何数量的节点504的物理存储器或虚拟存储器(“节点存储器514”)和/或任何数量的边缘节点506的物理存储器或虚拟存储器(“边缘存储器516”)中,以便用于任何数量的节点504的任何数量的(一个或多个)物理或虚拟处理器(“(一个或多个)节点处理器518”)和/或任何数量的边缘节点506的任何数量的(一个或多个)物理或虚拟处理器(“(一个或多个)边缘处理器520”)通过执行模型508的单元来执行计算,以计算本文所述的机器学习任务。(一个或多个)节点处理器518和(一个或多个)边缘处理器520可以是执行计算所需的算术和逻辑运算的标准可编程处理器,并且可以是促进对机器学习任务的计算的专用计算设备,例如,如上所述的任何数量的(一个或多个)专用处理器404,包括诸如gpu等之类的(一个或多个)加速器。
76.根据本公开的示例实施例,如上所述的方法200的步骤可以通过根据需要在节点504和边缘节点506之间传送数据而分布在(一个或多个)节点处理器518和/或(一个或多个)边缘处理器520中;通常,机器学习任务的计算可以分布到节点504,其中可以集中在(一个或多个)专用处理器404处发现的大量计算能力。因此,通常可以在节点504处执行计算资源的分配,其中机器学习任务的大部分计算通常可以发生。在某种程度上,对计算度量的量化和计算度量趋势的确定可以分布到边缘节点506,边缘节点506通常可以具有相对较小的计算能力并且可以主要拥有(一个或多个)通用处理器402而不是(一个或多个)专用处理器404。得出预测计算度量通常可以被分布到节点504,因为执行学习斜率进展学习模型通常需要更大的计算能力。
77.虽然本发明是针对具体实施例进行描述的,但应理解本发明的范围不限于这些具体实施例。由于为适合特定操作要求和环境而改变的其他修改和改变对于本领域技术人员
来说将是显而易见的,因此本发明不被认为限于为公开目的而选择的示例,并且涵盖不构成背离本发明的真正精神和范围的所有改变和修改。
78.尽管本技术描述了具有特定结构特征和/或方法动作的实施例,但是应当理解,权利要求不一定限于所描述的特定特征或动作。相反,特定特征和动作仅仅是落入本技术的权利要求范围内的一些说明性实施例。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1