在多用户环境中使用手势来控制设备的方法和系统与流程
在多用户环境中使用手势来控制设备的方法和系统
1.相关申请数据
2.本技术要求于2020年4月7日提交的申请号为16/842,717、发明名称为“在多用户环境中使用手势来控制设备的方法和系统(methods and systems for controlling a device using hand gestures in multi-user environment)”的美国非临时申请的权益,该在先申请要求于2020年3月20日提交的申请号为pct/cn2020/080416的国际申请的权益,要求于2020年3月23日提交的申请号为pct/cn2020/080562的国际申请的权益,其全部内容通过引用结合在本技术中。
技术领域
3.本发明涉及在多用户环境中使用手势来控制设备(例如电视)的方法和系统。
背景技术:
4.为了便于控制一组用户共用的设备(例如,视频会议系统、电视、视频游戏系统等),人们一直对使用手势远程控制设备感兴趣。然而,在多用户环境中,手势识别系统可能需要处理一个以上用户执行手势的数字图像(例如帧),这样存在困难。手势识别系统可能需要更多的计算资源来识别包括多个用户而不是单个用户的数字图像中的手势,并且可能在识别多个用户执行的手势时产生混淆。另外,在同时识别多个手势的情况下,手势识别系统可能需要选择对哪个手势或哪些手势进行操作。
5.因此,提供在多用户环境中对设备进行手势控制的改进方法和系统技术将是有用的,这些技术能够高效使用计算资源,最大限度地减少混淆,并解决一个以上用户执行的手势之间的交互。
技术实现要素:
6.在各种示例中,本发明描述了在多用户环境中使用手势来控制设备的方法和系统。所述公开的方法和系统支持设备(以下称为手势控制设备)和执行空中手势的两个或两个以上用户之间的实时交互。本发明提供的方法和系统执行手势识别,以识别多个用户执行的手势并根据分配给所述识别到的手势的优先级控制所述手势控制设备。
7.在一些示例中,本发明描述了一种在多用户环境中使用手势来控制设备的方法。所述方法包括:接收视频的帧;处理所述帧的至少一部分来检测在所述帧中的第一位置上可见的第一用户;处理所述帧的至少一部分来检测在所述帧中的第二位置上可见的第二用户;使用虚拟手势空间生成子系统来限定与所述帧的靠近所述第一位置的第一区域对应的第一虚拟手势空间;使用手势识别子系统来处理所述帧的第一区域,以识别第一手势并生成表示所述识别到的第一手势的手势类别的标签;应用优先级规则集来确定所述第一手势具有优先级;响应于确定所述第一手势具有优先级,启动计算机的与所述第一手势对应的第一动作。
8.在一些示例中,本发明描述了一种在多用户环境中使用手势来控制设备的装置。
所述装置包括耦合到存储机器可执行指令的存储器的处理设备。所述指令在由所述处理设备执行时使得所述装置:接收视频的帧;处理所述帧的至少一部分来检测在所述帧中的第一位置上可见的第一用户;检测在所述帧中的第二位置上可见的第二用户;使用虚拟手势空间生成子系统来限定与所述帧的靠近所述第一位置的第一区域对应的第一虚拟手势空间;使用手势识别子系统来处理所述第一区域,以识别第一手势并生成表示所述识别到的第一手势的手势类别的标签;应用优先级规则集来确定所述第一手势具有优先级;响应于确定所述第一手势具有优先级,启动所述装置的与所述第一手势对应的第一动作。
9.在上述示例中,所述装置包括用于捕获多个视频帧的至少一个相机和用于将反馈信息提供给所述第一用户和所述第二用户的显示器。
10.在任一上述示例中,所述方法还包括:将反馈信息提供给输出设备,其中,所述反馈信息用于呈现给所述第一用户,所述反馈信息表示所述第一手势具有优先级。
11.在任一上述示例中,所述方法还包括:使用所述虚拟手势空间生成子系统来限定与所述帧的靠近所述第二位置的第二区域对应的第二虚拟手势空间;使用所述手势识别子系统来处理所述第二区域,其中,所述优先级规则集是时间上第一的用户规则集,所述规则集确定所述第一手势具有优先级,因为所述手势识别子系统不识别所述第二区域内的手势。
12.在任一上述示例中,所述方法还包括:接收所述视频的下一帧;处理所述下一帧的至少一部分来检测在所述下一帧中的第一位置上可见的第一用户;使用所述虚拟手势空间生成子系统来限定与所述下一帧的靠近所述下一帧中的第一位置的第一区域对应的下一虚拟手势空间;使用所述手势识别子系统只处理所述下一帧的第一区域。
13.在任一上述示例中,所述方法还包括:将反馈信息提供给输出设备,其中,所述反馈信息用于呈现给所述第一用户,所述反馈信息表示所述第一手势具有优先级;所述计算机是以下之一:电视、视频会议系统、视频游戏系统、车载设备、物联网设备、增强现实设备或虚拟现实设备。
14.在任一上述示例中,所述方法还包括:使用所述虚拟手势空间生成子系统来限定与所述帧的靠近所述第二位置的第二区域对应的第二虚拟手势空间;使用所述手势识别子系统来处理所述第二区域,以识别第二手势并生成表示所述识别到的第二手势的手势类别的标签,其中,所述第二手势对应于所述计算机的第二动作,所述优先级规则集是动作层次结构规则集,所述规则集确定所述第一手势具有优先级,因为所述第一动作在所述动作层次结构规则集的动作层次结构中高于所述第二动作。
15.在任一上述示例中,所述方法还包括:应用所述优先级规则集来确定所述第一动作与所述第二动作不冲突;响应于确定所述第一动作和所述第二动作不冲突,启动所述第二动作。
16.在任一上述示例中,所述动作层次结构包括以下一个或多个动作:调大音频音量、调小音频音量、静音音频和关闭电源。
17.在任一上述示例中,所述方法还包括:将反馈信息提供给输出设备,其中,所述反馈信息用于呈现给所述第一用户,所述反馈信息表示所述第一手势具有优先级;所述计算机是以下之一:电视、视频会议系统、视频游戏系统、车载设备、物联网设备、增强现实设备或虚拟现实设备。
18.在任一上述示例中,所述方法还包括:将反馈信息提供给输出设备,其中,所述反馈信息用于呈现给所述第一用户,所述反馈信息表示所述第一手势具有优先级;所述计算机是以下之一:电视、视频会议系统、视频游戏系统、车载设备、物联网设备、增强现实设备或虚拟现实设备;所述动作层次结构包括以下一个或多个动作:调大音频音量、调小音频音量、静音音频和关闭电源。
19.在任一上述示例中,所述优先级规则集是指定主用户规则集,所述规则集确定所述第一手势具有优先级,因为已经指定所述第一用户为主用户。
20.在任一上述示例中,所述第一动作是用于指定新主用户的动作。所述方法还包括,在启动所述第一动作之后,将新主用户选择信息提供给输出设备,其中,所述新主用户选择信息用于呈现给所述第一用户,所述新主用户选择信息表示用于指定新主用户的一个或多个选项,每个选项对应于所述帧中可见的用户;接收所述视频的下一帧;处理所述下一帧的至少一部分来检测在所述下一帧中的第一位置上可见的第一用户;使用所述虚拟手势空间生成子系统来限定与所述下一帧的靠近所述下一帧中的第一位置的第一区域对应的下一虚拟手势空间;使用所述手势识别子系统来处理所述下一帧的第一区域,以识别其它手势并生成表示所述识别到的其它手势的手势类别的标签,所述其它手势对应于所述用于指定新主用户的一个或多个选项中的第一选项的指定;将与所述第一选项对应的用户指定为所述主用户。
21.在任一上述示例中,所述方法还包括:接收所述视频的下一帧;处理所述下一帧的至少一部分来检测在所述下一帧中的第一位置上可见的第一用户;使用所述虚拟手势空间生成子系统来限定与所述下一帧的靠近所述下一帧中的第一位置的第一区域对应的下一虚拟手势空间;使用所述手势识别子系统只处理所述下一帧的第一区域。
22.在任一上述示例中,所述方法还包括:接收所述视频的下一帧;处理所述下一帧的至少一部分来检测在所述下一帧中的第一位置上可见的第一用户;使用所述虚拟手势空间生成子系统来限定与所述下一帧的靠近所述下一帧中的第一位置的第一区域对应的下一虚拟手势空间;使用所述手势识别子系统只处理所述下一帧的第一区域;将反馈信息提供给输出设备,其中,所述反馈信息用于呈现给所述第一用户,所述反馈信息表示所述第一手势具有优先级;所述计算机是以下之一:电视、视频会议系统、视频游戏系统、车载设备、物联网设备、增强现实设备或虚拟现实设备。
23.在一些示例中,本发明描述了一种存储有机器可执行指令的计算机可读介质。所述指令在由装置中的处理设备执行时使得所述装置执行任一上述方法。
24.本文中公开的示例可以对在多用户环境中执行的多个同时手势进行更加高效和清晰的管理。通过提供明确的规则集对同时手势进行优先级排序,计算资源可以集中跟踪和识别单个用户执行的手势。可以将反馈提供给识别优先手势的用户或执行优先手势的用户,从而使执行手势的其它用户清晰。潜在冲突的同时手势可以通过系统和清晰的方式解决冲突,防止用户混淆并提供一致的用户界面行为。
附图说明
25.现在将通过示例参考示出本技术示例性实施例的附图,其中:
26.图1是用户与示例性手势控制设备交互的框图;
27.图2是示例性手势控制设备中的一些组件的框图;
28.图3a至图3h示出了示例性手势控制设备可以检测和识别的一些示例性手势类别;
29.图4a至图4c示出了示例性手势控制设备可以检测和识别的一些示例性动态手势;
30.图5是可以示例性手势控制设备中实现的示例性自适应手势感应系统的一些细节的框图;
31.图6是使用虚拟手势空间进行手部检测的示例性方法的流程图;
32.图7示出了包括用于实现虚拟鼠标的限定子空间的虚拟手势空间的一个示例;
33.图8a和图8b示出了2d和3d虚拟手势空间的示例;
34.图9是用于手部检测和根据检测到的手重新限定虚拟手势空间的示例性方法的流程图;
35.图10a和图10b示出了图9中的方法的一种示例性实现方式;
36.图11a是使用虚拟手势空间进行手部检测的示例性方法的流程图,其中,实现了用于多用户优先级的用户列表和时间上第一的用户规则集;
37.图11b是使用虚拟手势空间进行手部检测的示例性方法的流程图,其中,实现了用于多用户优先级的用户列表和动作层次结构规则集;
38.图11c是使用虚拟手势空间进行手部检测的示例性方法的流程图,其中,实现了用于多用户优先级的用户列表和指定主用户规则集;
39.图12是使用自适应roi执行检测的示例性方法的流程图;
40.图13示出了可以在图12的方法中使用的示例性roi序列;
41.图14是可以用于手势识别的示例联合网络的框图;
42.图15和图16示出了可以用于训练图14中的联合网络的一些示例性训练数据样本;
43.图17是用于手势识别的示例性方法的流程图;
44.图18是基于状态的手势识别的示例的状态图;
45.图19a是使用激活区域进行手势控制的第一示例性方法的流程图;
46.图19b是使用激活区域进行手势控制的第二示例性方法的流程图;
47.图20a是相对于用户限定的虚拟手势空间和激活区域的简化表示;
48.图20b是相对于用户限定的虚拟手势空间、手部边界框和激活区域的简化表示;
49.图20c是示例性手势控制设备的显示提示用户将手势移进激活区域的反馈的显示器的示例性屏幕;
50.图21是示例性手势控制设备的显示表示多用户环境中的当前主要用户的反馈的显示器的示例性屏幕;
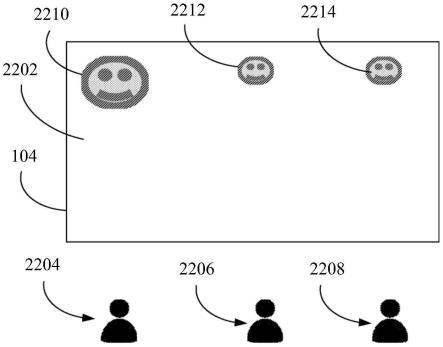
51.图22a是示例性手势控制设备的在主用户执行指定新主用户的手势之前显示表示多用户环境中当前主要用户的反馈的显示器的简化示例性屏幕的示意图;
52.图22b是示例性手势控制设备的在主用户执行指定新主用户的手势之后显示表示多用户环境中当前主要用户的反馈的显示器的简化示例性屏幕的示意图;
53.图22c是主用户执行指定新主用户的手势的若干时刻的简化前视图。
54.不同的附图中使用了相似的附图标记来表示相似的组件。
具体实施方式
55.在各种示例中,本发明描述了在多用户环境中使用手势来控制手势控制设备的方法和系统。手势控制设备可以是电视(例如智能电视)、桌面设备、视频会议系统、视频游戏系统、车载设备(例如仪表盘设备)或智能扬声器,等等。本文中描述的方法和系统可以用于实现用户与手势控制设备提供的任何用户界面进行交互,包括在手势控制设备的显示设备上呈现的用户界面、在与手势控制设备进行通信的显示设备上呈现的用户界面。本发明提供的方法和系统的示例还可以用于增强现实(augmented reality,ar)应用或虚拟现实(virtual reality,vr)应用,等等。
56.为了简单起见,本发明描述了在包括显示器(例如与视频会议系统进行通信的智能电视(television,tv)或显示设备)的手势控制设备的背景下的示例,并且描述了用于控制上述设备进行交互的方法和系统,例如用于播放视频。然而,应当理解,本发明并不限于这些实施例,本文中描述的方法和系统可以用于控制各种应用中的各种手势控制设备。例如,本文中描述的方法和系统的一些实施例可以使用其它输出设备(例如音频扬声器),以将反馈信息提供给用户。一些实施例可以实现用户使用手势与其它类型的内容或其它软件应用交互,例如音乐播放器、视频会议应用、视频游戏或多用户虚拟现实(virtual reality,vr)或增强现实(augmented reality,ar)环境,等等。
57.使用手势来控制手势控制设备可能比控制这类设备的其它输入模式具有优势。使用手势来控制这类设备不需要用户手持这类设备与之交互。而且,由于用户不需要触摸手势控制设备的表面与之交互,因此使用手势控制这类设备会更卫生。
58.图1示出了用户10与手势控制设备100交互的一个示例。在这一简化图中,手势控制设备100包括捕获视场角(field-of-view,fov)20的相机102。fov 20可以包括用户10的至少一部分,特别是用户10的脸和手。值得注意的是,现实生活中(例如实验室环境之外)的fov 20通常不仅仅包括用户10。例如,fov 20还可以包括其它对象、背景场面或可能存在的其它人。手势控制设备100可以代替相机102包括能够感测用户10的手势的其它传感器,例如任何图像捕获设备/传感器(例如红外图像传感器)。手势控制设备100还包括显示设备104(以下称为显示器104),用于在其上呈现视觉信息,例如视频。图2是手势控制设备100中的一些组件的框图。虽然下文示出和描述了手势控制设备100的一个示例性实施例,但其它实施例可以用于实现本文中公开的示例,可以包括与所示的组件不同的组件。虽然图2示出了每个组件的单个实例,但显示的每个组件可以有多个实例。
59.手势控制设备100包括一个或多个处理设备202,例如处理器、微处理器、专用集成电路(application-specific integrated circuit,asic)、现场可编程门阵列(field-programmable gate array,fpga)、专用逻辑电路、专用人工智能处理器单元或其组合。手势控制设备100还包括一个或多个输入/输出(input/output,i/o)接口204,用于连接相机102等输入设备和显示器104等输出设备。手势控制设备100可以包括其它输入设备(例如,按钮、麦克风、触摸屏、键盘等)和其它输出设备(例如,扬声器、振动单元等)。相机102(或其它输入设备)可以具备捕获实时手势输入作为视频帧序列的能力。捕获到的帧可以由一个或多个i/o接口204存储并提供给一个或多个处理设备202,以实时或近实时(例如在10ms内)处理。
60.手势控制设备100可以包括一个或多个可选的网络接口206,用于与网络(例如内
网、互联网、p2p网络、wan和/或lan)或其它节点进行有线或无线通信。一个或多个网络接口206可以包括用于进行内网通信和/或网外通信的有线链路(例如以太网线)和/或无线链路(例如一个或多个天线)。
61.手势控制设备100包括一个或多个存储器208,可以包括易失性或非易失性存储器(例如,闪存、随机存取存储器(random access memory,ram)和/或只读存储器(read-only memory,rom))。一个或多个非瞬时性存储器208可以存储由一个或多个处理设备202执行的指令,例如,以执行本发明中描述的示例。例如,一个或多个存储器208可以包括用于执行自适应手势感应系统300的指令。一个或多个存储器208可以包括其它软件指令,例如用于实现操作系统和其它应用/功能。一个或多个存储器208还可以包括数据210,例如可以通过显示器104呈现给用户的视频内容文件。
62.在一些示例中,手势控制设备100还可以包括一个或多个电子存储单元(未示出),例如,固态硬盘、硬式磁盘驱动器、磁盘驱动器和/或光盘驱动器。在一些示例中,一个或多个数据集和/或模块可以由外部存储器(例如与手势控制设备100进行有线或无线通信的外置驱动器)提供,也可以由瞬时性或非瞬时性计算机可读介质提供。非瞬时性计算机可读介质的示例包括ram、rom、可擦除可编程rom(erasable programmable rom,eprom)、电可擦除可编程rom(electrically erasable programmable rom,eeprom)、闪存、cd-rom或其它便携式存储器。手势控制设备100中的组件可以通过总线等互相通信。
63.在一些实施例中,分布式系统可以包括多个手势控制设备100,可选地包括一个或多个其它组件。分布式系统可以包括通过网络相互通信的多个手势控制设备100。例如,视频会议系统可以包括每个远程参与用户对应的手势控制设备100,可选地包括中心服务器。手势识别和对用户手势进行优先级排序以控制在每个手势控制设备100上运行的视频会议应用,可以通过本地处理(即在每个用户的手势控制设备100上)和远程处理或集中处理(即在中心服务器上)的某种组合来执行。在一些实施例中,第一手势控制设备100可以用于识别本地用户执行的手势,其中,中心服务器应用优先级规则集对不同手势控制设备100的用户同时执行的手势进行优先级排序。在一些实施例中,每个手势控制设备100可以向中心服务器发送手势控制设备100中的相机捕获到的帧,中心服务器将优先级规则集应用于帧集合,以集中对手势控制进行优先级排序。在一些实施例中,每个手势控制设备100用于根据本地捕获到的帧(例如手势控制设备100中的相机捕获到的帧)和从系统中的其它手势控制设备100接收到的信息的组合对手势进行优先级排序。在一些实施例中,分布式系统是增强现实系统,包括单个手势控制设备100和多个相机(例如位于物理空间周围的相机阵列)和/或多个显示器。在本实施例中,单个手势控制设备100用于识别手势控制设备100中的相机102和/或系统中的多个相机捕获到的帧中的手势,然后,手势控制设备使用识别到的手势来控制多个显示器,以在显示器上呈现信息。应当理解,这些系统作为示例提供,还可以使用其它分布式系统。
64.应当理解,不同的实施例可以包括代替或补充相机102和显示器104的输入设备和输出设备的不同组合。在vr或ar系统的背景下,可以使用多个头戴式显示器代替单个大型共享显示器104,其中,一个或多个相机102用于捕获用于输入的视频,如本文中所述。在每个用户的相应头戴式显示器上呈现给这种vr或ar系统的用户的反馈信息可以类似于本文中描述的在单个共享显示器104上呈现的反馈。在一些实施例中,针对单个用户的反馈信息
可以仅在目标用户的头戴式显示器上呈现。
65.在一些实施例中,多个相机102可以用于捕获用户的手势。例如,vr或ar系统可以包括安装在每个用户的耳机或其它vr或ar设备上的单独相机,其中,每个用户的相机用于捕获该用户的手势。类似地,多个用户相距遥远情况下的示例性视频会议、vr或ar系统可以使用每个用户本地的相机来捕获该用户的身体和环境,以便识别该用户的手势。在这样的示例性多相机实施例中,本文中描述的方法和系统可以用于通过组合每个相机捕获到的视频帧来检测、跟踪和识别每个用户的手势。来自多个相机的帧的这种组合可以在一些实施例中在时间上完成(例如,依次处理用于手势识别的每个帧),在一些实施例中在空间上完成(例如,创建包括来自每个相机的当前帧的组合视频帧,并处理用于手势识别的组合帧),或者通过组合来自多个相机的视频帧输入的一些其它方法来完成。
66.为了帮助理解本发明,首先描述手势。在本发明中,手势通常定义为可以由手势控制设备100识别为特定命令输入的不同手形。手势可以有不同的形状和动作。例如,手势控制设备100可以将手势识别为属于图3a至图3h所示的类别之一。虽然下文的示例是在手势的背景下描述的,但在一些实施例中,手势可以涉及除手以外的身体部位,例如脸或手臂,或者可以涉及除人体部位以外的实体元素,例如相机可见的持有物。
67.图3a示出了“张开(open hand)”手势30,图3b示出了“握拳(fist/closed hand)”手势32,图3c示出了“放大(pinch open)”手势34,图3d示出了“缩小(pinch closed)”手势36,图3e示出了“静音(mute/silence)”手势38,图3f示出了“点赞(like/approve)”手势40,图3g示出了“其它(others)”(或“下一个(next)”)手势42,图3h示出了“指向(touch)”(或“选择(select)”)手势44。手势控制设备100可以识别其它手势类别。
68.根据这些手势类别,手势可以分为静态手势或动态手势。静态手势定义为单个手势类别,在通常固定的位置上(例如在允许存在某一误差幅度的特定区域内)保持至少一段限定时间(例如1秒)或至少限定数量的连续捕获到的视频帧(例如100个帧)。例如,手势控制设备100可以识别静态张开手势30,在视频播放的背景下可以解释为暂停命令输入。手势控制设备100可以识别静态握拳手势32,在视频播放的背景下可以解释为停止命令输入。
69.动态手势定义为一个或多个手势类别、位置和/或动作的组合。例如,动态手势可以是位置随着时间变化的单个手势类别(例如,在捕获到的帧序列(即视频中的数字图像)中的不同位置上检测到)。手势控制设备100可以识别位置变化的张开手势30,解释为拖拽或移动界面对象(例如显示图标)的命令。
70.图4a示出了另一种类型的动态手势,可以是手势类别的组合。在图4a中,动态手势包括指向手势44和握拳手势32的组合。手势控制设备100可以识别这种动态手势,解释为相当于使用鼠标设备选择并然后单击界面对象的命令输入。又如,放大手势34和随后的缩小手势36可以一起识别为“捏合(pinching)”动态手势,手势控制设备100可以识别这一手势,解释为缩小命令输入。
71.更复杂的动态手势可能涉及手势类别组合和位置变化。例如,在图4a中,如果在位置随时间变化时检测到指向手势44(例如,在捕获到的视频帧序列中的不同位置上检测到),接着检测到握拳手势32,则手势控制设备100可以将手势解释为移动显示光标的命令,以反映指向手势44的位置变化,然后在检测到握拳手势32时解释为点击命令。
72.又如,手势控制设备100可以将放大手势34、随后的缩小手势36、随后的缩小手势
36的位置变化和随后再次的放大手势34一起识别为动态“捏合-拖拽-释放(pinch-drag-release)”手势。需要说明的是,包括位置变化的动态手势可以根据位置的特定变化解释为不同的输入。例如,如图4b所示,缩小手势36的位置46存在垂直变化(或垂直“拖拽”)的捏合-拖拽-释放手势可以在视频播放的背景下解释为调节音量的命令输入。相反,如图4c所示,缩小手势36的位置48存在水平变化的捏合-拖拽-释放手势可以在视频播放的背景下解释为向前或向后拖拽视频的命令输入。这种捏合-拖拽-释放动态手势可以使用户直观、便捷地与手势控制设备100交互,而且还可以使手势控制设备100相对准确地检测和识别手势。具体地,可以通过将动态手势分解为静态手势分量(例如,放大手势34、随后的缩小手势36、随后的另一放大手势34)来检测和识别捏合-拖拽-释放动态手势。
73.手势分割和识别的计算成本通常很高;在多用户环境中执行这些任务会进一步增加需要的计算资源。此外,当fov中有多人时,检测和识别手势(无论是静态的还是动态的)通常比较困难。另外,现有系统没有明确的、有条理的规则来解决多用户环境中一个以上用户同时执行手势的情况。
74.在各种示例中,本发明描述了能够解决多个用户执行多个同时手势的技术方案,以控制多用户环境中的手势控制设备,以及实现手势控制设备在多用户环境中高效识别手势。本发明描述了一种根据预定优先级规则集对检测到的用户或识别到的手势进行优先级排序的系统和方法。本发明描述了3个示例性优先级规则集。第一描述了时间上第一的用户规则集,即根据用户在相机fov中开始执行手势的时间对这些手势进行优先级排序。第二描述了动作层次结构规则集,即根据手势对应的动作以及这些动作在动作层次结构中的相对位置对这些手势进行优先级排序。第三描述了指定主用户规则集,即对明确指定的主用户执行的手势进行优先级排序。本发明还描述了指定新主用户的方法。在一些示例中,本发明还描述了用于执行本文中描述的方法的计算机可读介质。应当理解,本发明包括其它方面和特征。
75.本发明描述了虚拟手势空间的使用,至少最初限定为用户的脸周围的空间,用于检测手势。虚拟手势空间应该小于相机102捕获到的fov。只有在虚拟手势空间内检测和识别到的手势才视为有效手势。虚拟手势空间的使用可以减少手势检测中的误报(例如,特别是在复杂背景下),更易于将手势与特定用户相关联,而且可以更高效地处理帧来识别手势。
76.图5是自适应手势感应系统300中的一些示例性子系统的框图。在本示例中,自适应手势感应系统300可以使用虚拟手势空间子系统310、手势解析子系统320、多用户优先级子系统350和显示子系统360来实现。以下示例描述了自适应手势感应系统300包括所有4个子系统310、320、350、360或提供所有4个子系统310、320、350、360的功能。然而,在其它示例中,自适应手势感应系统300可以只包括虚拟手势空间子系统310或手势解析子系统320中的一个(或提供其功能),或者可以省略显示子系统360。例如,自适应手势感应系统300可以(例如,使用虚拟手势空间子系统310)只提供虚拟手势空间的自适应生成和虚拟手势空间内的手势检测,而手势识别和解析可以由手势控制设备100中的另一组件(例如,使用任何合适的现有手势识别技术)执行。又如,自适应手势感应系统300可以(例如,使用手势解析子系统320)只提供多个用户的手势识别和管理,而手部检测可以由手势控制设备100中的另一组件(例如,使用任何合适的现有手部检测技术)执行。
77.在一些示例中,自适应手势感应系统300可以不包括不同的子系统310、320、350、360。相反,子系统310、320、350、360中的子块可以视为自适应手势感应系统300自身的子块。因此,可选地使用不同的子系统310、320、350、360来实现自适应手势感应系统300。
78.自适应手势感应系统300包括脸部检测和跟踪子系统312、虚拟手势空间生成子系统314、激活区域生成子系统315、手部检测和跟踪子系统316、手势识别子系统322、优先级规则集352、用户列表354和用户反馈子系统362。脸部检测和跟踪子系统312、虚拟手势空间生成子系统314、激活区域生成子系统315和手部检测和跟踪子系统316可以是虚拟手势空间子系统310的一部分,手势识别子系统322可以是手势解析子系统320的一部分,优先级规则集352和用户列表354可以是多用户优先级子系统350的一部分,用户反馈子系统362可以是显示子系统360的一部分。
79.在一些示例中,替代或补充脸部检测和跟踪子系统312,另一子系统(未示出)可以用于检测和跟踪区别性解剖特征(例如,整个人体或人体躯干)。如下文进一步所述,可以使用区别性解剖特征替代或补充脸,以作为生成虚拟手势空间的基础。为了简单起见,本发明重点描述使用脸部检测和跟踪,但应当理解,本发明并不限于此。
80.自适应手势感应系统300接收捕获到的帧(即数字图像)作为输入帧。脸部检测和跟踪子系统312对输入帧执行脸部检测。脸部检测和跟踪子系统312可以使用任何合适的脸部检测技术来检测输入帧中的脸,并为检测到的脸生成边界框(bounding box)。边界框可以是二维(two-dimension,2d)边界框或三维(three-dimension,3d)边界框。
81.虚拟手势空间生成子系统314使用为检测到的脸生成的边界框来限定虚拟手势空间。在本发明中,虚拟手势空间(或简称为手势空间)是指在输入帧中限定并映射到用户10的真实环境中的虚拟空间的2d空间或3d空间,其中的手势可以检测为有效手势。换句话说,用户10可以在虚拟限定的2d虚拟手势空间或3d虚拟手势空间内做手势,以将输入提供给手势控制设备100。在虚拟手势空间之外执行的手势可能检测不到,而且也不会由手势控制设备100识别为有效手势。虚拟手势空间的维度可以匹配脸的边界框的维度,也可以不匹配(例如,脸的边界框可以是2d,而虚拟手势空间可以是3d)。
82.手部检测和跟踪子系统316使用虚拟手势空间生成子系统314限定的虚拟手势空间来执行手部检测。具体地,手部检测和跟踪子系统316可以只分析在输入帧内限定的虚拟手势空间。手部检测和跟踪子系统316可以使用任何合适的手部检测技术来检测输入帧中的手,并为检测到的手生成2d边界框或3d边界框。
83.在一些实施例中,激活区域生成子系统315使用为检测到的脸生成的边界框来限定激活区域。在本发明中,激活区域是指在输入帧中限定并映射到用户10的真实环境中的虚拟空间的2d空间或3d空间,必须检测其中的手写输入以便由手势控制设备100进行操作。换句话说,用户10可以在虚拟手势空间内做手势,但直到手势移进激活区域,才会将该手势识别为手势控制设备100的有效输入。一些实施例可以不使用激活区域;在这种实施例中,将在虚拟手势空间内检测和识别到的所有手势都识别为手势控制设备100的有效输入。在确实使用激活区域的实施例中,激活区域的尺寸可以不同于虚拟手势空间的尺寸。在一些示例中,激活区域小于虚拟手势空间,并且更靠近用户的脸或更靠近另一检测到的用户的解剖特征,如上所述。
84.在一些示例中,脸部检测和跟踪子系统312可以使用经训练的神经网络来执行脸
部检测。类似地,手部检测和跟踪子系统316可以使用另一经训练的神经网络来执行手部检测。例如,用于脸部检测或手部检测的合适神经网络可以是经训练的对象检测器,例如使用基于残差神经网络(residual neural network,resnet)架构(例如resnet34(例如,如he,kaiming等人在2016年的ieee计算机视觉与模式识别会议记录上发表的“deep residual learning for image recognition(用于图像识别的深度残差学习)”所述))的yolov3(例如,如redmon等人在2018年的预印本文献库:1804.02767中发表的“yolov3:an incremental improvement(yolov3:增量式改进)”所述)。另一示例可以是经训练的单发检测器(single shot detector,ssd),例如基于卷积神经网络(convolutional neural network,cnn)架构(例如mobilenetv2(例如,如sandler等人在2018年的ieee计算机视觉与模式识别会议记录上发表的“mobilenetv2:inverted residuals and linear bottlenecks(mobilenetv2:反向残差和线性瓶颈)”所述))的多框ssd(例如,如liu等人在2016年的springer,cham的欧洲计算机视觉会议上发表的“ssd:single shot multibox detector(ssd:单发多框检测器)”所述)。脸部检测和跟踪子系统312和手部检测和跟踪子系统316可以使用卢卡斯-卡纳德光流技术(如lucas等人在1981年的成像理解研讨会记录中发表的“an iterative image registration technique with an application to stereo vision(一种迭代图像配准技术及其在立体视觉中的应用)”所述)分别执行脸部跟踪和手部跟踪。
85.手势识别子系统322使用为检测到的手生成的边界框来识手形并将手形分类为手势类别。手势识别子系统322可以使用任何合适的手势分类技术将检测到的手形分类为特定的手势类别。例如,手势识别子系统322可以使用经训练的神经网络(例如cnn)以根据预定义的手势类别集合对手势进行分类。手势识别子系统322输出标识手势类别的标签。通过仅限于对虚拟手势空间内执行的手势进行手部检测和手势识别,可以提高手部检测和跟踪子系统316和/或手势识别子系统322的性能。
86.手势控制设备100的软件应用(例如操作系统)可以将自适应手势感应系统300输出的手势类别转换为命令输入。将手势类别转换为命令输入可以取决于应用。例如,某种手势类别可以在第一应用处于激活状态时转换为第一命令输入,但在第二应用处于激活状态时转换为第二命令输入(或者视为无效)。
87.多用户优先级子系统350用于对识别到的手势进行优先级排序,并在多用户环境中分配计算资源。例如,可以在相机102的fov中捕获多个人。因此,脸部检测和跟踪子系统312可以检测和跟踪多张脸。每个检测到的脸可以属于将输入提供给手势控制设备100的用户。因此,即使检测到的人当前不提供识别到的输入,每个检测到的人也可以视为用户(或潜在用户)。在一些示例中,多用户优先级子系统350可以在某一帧的背景下确定脸部检测和跟踪子系统312跟踪哪些用户,虚拟手势空间生成子系统314生成哪些用户的虚拟手势空间,手部检测和跟踪子系统316跟踪哪些用户的手,以及处理哪些用户的手势以供手势识别子系统322识别。因此,可以预留自适应手势感应系统300的计算资源来跟踪和识别当前由多用户优先级子系统350进行优先级排序的用户的手势。
88.多用户优先级子系统350用于多用户环境中,以确定脸部检测和跟踪子系统312、虚拟手势空间生成子系统314和手部检测和跟踪子系统316检测和跟踪哪些用户,处理哪些手势以供手势识别子系统322识别,以及将哪些识别到的手势类别转换为命令输入。在相机
fov中的一个以上用户执行手势而相机fov中的另一用户也在执行手势的情况下,多用户优先级子系统350应用预定优先级规则集352来确定应该处理哪个手势以供手势识别子系统322识别并转换为命令输入。在一些实施例中,优先级规则集352可以用于将更多的计算资源用于确定具有优先级的用户。例如,一些实施例可以使用优先级规则集来标识具有优先级的用户,称为主要用户或主用户,从而导致脸部检测和跟踪子系统312、虚拟手势空间生成子系统314和手部检测和跟踪子系统316只检测和跟踪该用户,直到优先级转移到不同用户。一些实施例可以在第一用户具有优先级时继续检测和跟踪非主要用户,但是用于检测和跟踪非主要用户的计算资源可以比用于检测和跟踪主要用户的资源少。下文结合图11a至图11c描述和示出了多用户优先级子系统350的操作。
89.用户反馈子系统362通过一个或多个输入/输出(input/output,i/o)接口204和输出设备(例如显示器104)将反馈提供给用户。在一些实施例中,用户反馈子系统362向用户呈现的用户反馈信息可以包括提示用户将其手势移进虚拟手势空间和/或激活区域的反馈信息,和/或标识当前主要用户的反馈信息。虽然描述和示出了用户反馈子系统362是显示子系统360的一部分,但是在一些实施例中,用户反馈子系统362还可以通过其它输出设备(例如扬声器)提供用户反馈。下文结合图21、图22a和图22b描述和示出了用户反馈子系统362的操作。
90.自适应手势感应系统300存储和维护在多用户环境中使用的用户列表354。用户列表354跟踪所有检测到的用户,并根据优先级规则集352对检测到的用户进行排名。用户列表354中排名最高的用户可以视为主要用户。在帧中识别到的对应于检测到的主要用户的手势可以优先于为在帧中检测到的用户识别到的任何其它手势。在一些示例中,用户列表354可以只包括授权或预注册的用户。例如,用户配置文件可以与授权或预注册的用户相关联,而且用户配置文件可以包括使手势控制设备100(例如,使用合适的脸部识别技术)能够识别到授权或预注册用户的数据(例如生物特征数据)。自适应手势感应系统300或手势控制设备100中的单独脸部识别系统可以执行这种授权或预注册的用户的脸部识别。通过限制用户列表354只包括授权或预注册的用户,可以避免未经授权地控制手势控制设备100。此外,可以减少手势的误报识别。在一些实施例中,用户列表354中的用户排名确定了用于在帧序列中跟踪该用户并识别该用户在帧序列中的手势的处理资源或计算资源的数量。例如,在帧序列中识别排名低的用户手势之前,可以跟踪排名高的用户并在帧序列中识别他们的手势,从而在一些实施例中(例如,当为排名高的用户识别手势时),可能不需要处理帧序列来跟踪和识别排名低的用户的手势。
91.虽然示出了自适应手势感应系统300包括不同的子块(或子系统),但应当理解,本发明并不限于此。例如,自适应手势感应系统300可以使用更多或更少的子块(或子系统)来实现,也可以不需要任何子块(或子系统)。此外,本文中描述的由特定子块(或子系统)执行的功能可以由另一子块(或子系统)执行。
92.通常情况下,自适应手势感应系统300的功能可以通过各种合适的方式来实现,都属于本发明保护的范围。
93.下文描述了自适应手势感应系统300的操作的示例。
94.图6是自适应手势感应系统300可以使用虚拟手势空间子系统310(和子系统312、314和316)等执行的示例性方法600的流程图。自适应手势感应系统300可以是包括计算机
可读代码(或计算机可读指令)的软件。手势控制设备100中的处理设备202能够执行计算机可读代码,以执行方法600。根据本发明,自适应手势感应系统300中的软件的编码完全在本领域技术人员的范围内。方法600包括的过程可以比示出和描述的过程多或少,而且可以按照不同的顺序执行。计算机可读代码可以存储在存储器208或计算机可读介质中。
95.在602中,接收相机102捕获到的输入帧。输入帧通常是实时或近实时接收的。输入帧可以是相机102捕获到的原始未处理帧(即数字图像),也可以是最少处理(例如归一化)帧。
96.在604中,自适应手势感应系统300检测输入帧中的区别性解剖特征。可以在步骤604中处理整个输入帧。区别性解剖特征可以是用户身体的任何部位,这些部分容易检测且与背景区分开的。一个示例是脸部检测(例如,使用脸部检测和跟踪子系统312)。在一些情况下,可能难以检测到脸,在这种情况下,改为检测区别性解剖特征(例如,整个人体或人体躯干)。如上所述,可以使用任何合适的方法(包括使用基于机器学习的技术)来检测解剖特征。检测区别性解剖特征可以包括:确定解剖特征的位置(例如,表示为坐标)以及为区别性解剖特征生成边界框。
97.在606中,根据检测到的区别性解剖特征(例如检测到的脸)(例如,使用虚拟手势空间生成子系统314)生成虚拟手势空间。在一些实施例中,可以检测到区别性解剖特征的多个实例(例如,如果相机102的fov内有多个人,则可以检测到多张脸),在这种情况下,可以为区别性解剖特征的每个相应检测到的实例生成一个虚拟手势空间。如下文进一步所述,在一些实施例中,在检测到区别性解剖特征的多个实例时只能生成一个虚拟手势空间,或者可以根据检测到的区别性解剖特征的实例的排名或优先级生成一个或多个虚拟手势空间。
98.虚拟手势空间可以使用与相应检测到的区别性解剖特征的位置相关的预定义等式来生成。例如,虚拟手势空间可以通过计算相对于为检测到的区别性解剖特征(例如检测到的脸)生成的边界框的矩形空间来生成。下文进一步提供了一些示例性等式。
99.可选地,在608中,自适应手势感应系统300可以提供关于生成的虚拟手势空间的信息,以使手势控制设备100能够将关于生成的虚拟手势空间的反馈提供给用户10。例如,自适应手势感应系统300可以提供虚拟手势空间的坐标或其它参数,以使手势控制设备100能够在显示器104上向用户10呈现虚拟手势空间的表示,例如作为相机102捕获到的实时图像之上的叠加。又如,虚拟手势空间可以具有手势控制设备100显示的内嵌或辅助窗口,以仅显示对应于虚拟手势空间的fov,以此显示给用户10。将反馈提供给用户10的其它方式也适用。
100.在610中,在每个生成的虚拟手势空间中(例如,使用手部检测和跟踪子系统316)检测手。检测到的手可以与检测到手的相应虚拟手势空间相关联。如果生成多个虚拟手势空间,则可以尝试在每个生成的虚拟手势空间中检测手。如果在指定的虚拟手势空间中没有检测到手,则可以忽略或丢弃该指定的虚拟手势空间。
101.如果在生成的一个或多个虚拟手势空间中都没有检测到手,则可以确定在接收到的输入帧中没有检测到有效手势,然后方法600可以返回步骤602,即接收相机102捕获到的下一输入帧。假设在至少一个虚拟手势空间中检测到至少一只手,则方法600前进到可选步骤612。
102.可选地,在612中,如果在指定的虚拟手势空间中检测到的手不止一只,则可以在该指定的虚拟手势空间中识别一只主要手。可以根据以下内容识别主要手:例如,在指定的虚拟手势空间中检测到的一只最大手,检测到的最靠近在指定的虚拟手势空间中检测到的区别性解剖特征(例如脸)的手,或者检测到的照明度和/或色调最接近在指定的虚拟手势空间中检测到的区别性解剖特征(例如脸)的手。在一些实施例中,步骤612可以由多用户优先级子系统350执行。如果在指定的虚拟手势空间中只检测到一只手,则可以假设这一只手是主要手。
103.在614中,在相应的虚拟手势空间中(例如,使用手部检测和跟踪子系统316)跟踪检测到的手。提供检测和跟踪手(或主要手)的信息,以进一步解析手势。例如,可以生成检测到的手对应的边界框和可选的唯一标识符,以便跟踪检测到的手。然后,可以提供边界框(和可选的唯一标识符)(例如,给手势识别子系统322或其它手部分类器)。
104.在一些实施例中,方法600可以由自适应手势感应系统300只使用虚拟手势空间子系统310来实现。自适应手势感应系统300可以将关于跟踪到的手的信息(例如,检测到的手对应的边界框和唯一标识符)而不是手势类别(如图5所示)输出到传统的基于视频的手势识别系统,而传统的基于视频的手势识别系统可以执行手部分类和手势识别。
105.上述示例不直接检测用户的手,而是先检测区别性解剖特征(例如用户的脸),并根据检测到的特征生成虚拟手势空间(小于在输入帧中捕获到的fov)。然后,仅在虚拟手势空间中执行手部检测。用户的脸可以用作生成虚拟手势空间的区别性解剖特征,因为脸部检测通常比手部检测准确和可靠。通过将手部检测限制在虚拟手势空间,可以简化手部检测需要的处理,减少误报,而且更易于识别主要手。
106.在一些示例中,方法600可以用于处理相机102捕获到的每个帧。在其它示例中,方法600只能在预计手势时使用。例如,可以在响应命令输入(例如,通过键盘输入、鼠标输入或语音输入)时启动方法600。在一些示例中,可以在检测到人注意力时启动方法600。例如,注意力检测技术(例如,使用眼动跟踪软件)可以用于确定人是否正在直视手势控制设备100,而且可以只在检测到人直视设备100时才启动方法600。在检测到人注意力时启动方法600有助于避免手势的误报或错误解释。
107.在一些示例中,检测用户、为用户生成虚拟手势空间、检测和跟踪虚拟手势空间内用户的手以及在虚拟手势空间内对用户的手势进行分类的步骤可以统称为用户的“手势识别”或“识别手势”。
108.图7示出了方法600的一种示例性实现方式。在这种实现方式中,根据检测到的脸生成虚拟手势空间。在本示例中,假设(例如,在步骤604中)已经检测到主要用户的脸12,而且脸12用作区别性解剖特征,作为虚拟手势空间的基础。
109.可以使用任何合适的脸部检测技术(包括如上所述的基于机器学习的技术)为脸12生成边界框702。在本示例中,生成的边界框702由一组值{xf,yf,wf,hf}限定,其中,xf和yf分别表示边界框702的锚点(例如中心)的x和v坐标(在自适应手势感应系统300限定的参考帧中),wf和hf分别表示边界框702的宽度和高度。根据边界框702,(例如,在步骤606中)生成虚拟手势空间704,虚拟手势空间704由一组值{xg,yg,wghg}限定,其中,xg和yg分别表示虚拟手势空间704的锚点(例如中心)的x和y坐标(在自适应手势感应系统300限定的参考帧中),wg和hg分别表示虚拟手势空间704的宽度和高度。例如,以下等式可以用于生成虚拟手势空
间704:
[0110][0111][0112][0113]
hg=β
·
hf[0114]
其中,(δ
x
,δy)是预定义的相对位置参数,是预定义的尺度参数。参数(δ
x
,δy)和可以根据虚拟手势空间704的期望大小和边界框702在虚拟手势空间704内的期望位置(例如,由用户10或手势控制设备100的制造商)预定义。需要说明的是,在一些示例中,可以生成虚拟手势空间704,使得脸12的边界框702部分或全部在虚拟手势空间704之外。也就是说,虽然脸12可以用于生成虚拟手势空间704的基础,但虚拟手势空间704不一定包括脸12。
[0115]
在图7的示例中,虚拟手势空间704生成为2d矩形区域。然而,应当理解,虚拟手势空间704可以生成为2d空间或3d空间,而且可以生成为任何几何形状(例如,正方形、矩形、圆形等)、规则形状或不规则形状。
[0116]
在一些示例中,虚拟手势空间704还可以限定一个或多个子空间706、708,这些子空间可以用于实现特定的输入功能。一个或多个子空间706、708可以根据检测到的脸12的特征(例如由虚拟手势空间生成子系统314)限定。例如,根据检测到的眼睛和鼻子在脸12上的位置,左子空间706和右子空间708可以限定在虚拟手势空间中、与检测到的脸12的左下部分和右下部分对应。在左子空间706中检测指向(touch/point)手势可以解释为鼠标左键点击输入。类似地,在右子空间708中检测指向手势可以解释为鼠标右键点击输入。这样,包括限定的子空间706、708的虚拟手势空间704可以用于实现虚拟鼠标。在一些实施例中,图4a所示的动态手势可以检测用于实现虚拟光标。虚拟光标可以随着指向手势44的跟踪而移动(且可以通过显示给用户10的视觉叠加来表示),而且当检测到握拳手势32时,可以检测到鼠标点击输入。这样,可以实现虚拟鼠标。
[0117]
图8a和图8b示出了根据检测到的用户10的脸12生成的虚拟手势空间704的另一个示例。在图8a中,虚拟手势空间704是2d矩形区域,包括用户10的脸12和手14(例如,类似于图7中的示例)。在图8b中,虚拟手势空间704是3d空间,包括用户10的脸12和手14。当深度信息可用时,虚拟手势空间704可以生成为3d空间。例如,深度信息可以根据相机102捕获到的多个帧(例如数字图像)使用视频分析技术计算出。例如,手势控制设备100可以使用两个相机102来计算深度信息(例如,使用计算机立体视觉技术),或者相机102可以是能够生成深度信息(还生成传统rgb图像信息)的rgb深度(rgb-depth,rgbd)相机,或者手势控制设备可以包括飞行时间(time of flight,tof)相机(还包括传统相机102)来获取rgb图像信息和其它对应的深度信息。在一些示例中,除了相机102之外,还可以使用能够捕获深度信息的传感器(例如红外传感器)来捕获深度信息。使用3d虚拟手势空间704可以有助于将用于控制手势控制设备100(例如,将手移近或远离手势控制设备100)的基于深度的手势检测和识别为命令输入。
[0118]
在一些示例中,虚拟手势空间最初是根据检测到的区别性解剖特征(例如脸)生成的,随后根据检测到的手重新限定或更新。这样,即使手远离区别性解剖特征,虚拟手势空间也可以根据检测到的手的位置来确定。
[0119]
图9是自适应手势感应系统300可以使用虚拟手势空间子系统310(和子系统312、314和316)等执行的示例性方法900的流程图。方法900包括的步骤可以与上述方法600描述的步骤类似,因此不再赘述。
[0120]
在902中,接收相机102捕获到的输入帧。这一步骤可以与上述步骤602类似。
[0121]
在904中,自适应手势感应系统300检测输入帧中的区别性解剖特征。这一步骤可以与上述步骤604类似。
[0122]
在906中,根据检测到的区别性解剖特征(例如检测到的脸)(例如,使用虚拟手势空间生成子系统314)生成虚拟手势空间。这一步骤可以与上述步骤606类似。可选地,可以提供表示虚拟手势空间的信息(例如,使得反馈可以提供给用户10)。为了简单起见,在以下对方法900的描述中,假设只生成一个虚拟手势空间。然而,应当理解,方法900可以适用于(例如,根据区别性解剖特征的多个检测到的实例)生成多个虚拟手势空间的情况。
[0123]
在908中,在虚拟手势空间中(例如,使用手部检测和跟踪子系统316)检测手,并将手与检测到手的虚拟手势空间相关联。这一步骤可以与上述步骤610类似。可选地,可以识别主要手并将主要手与虚拟手势空间相关联。
[0124]
在910中,根据检测到的手重新限定虚拟手势空间。重新限定虚拟手势空间可以包括:使用与检测到的手相关(而不是与检测到的解剖特征相关)的预定义等式重新计算虚拟手势空间的位置和/或尺寸。例如,可以重新限定虚拟手势空间,使得虚拟手势空间以检测到的手的边界框为中心。下文进一步描述一些示例性等式。
[0125]
在912中,存储重新限定的虚拟手势空间。这样可以使用重新限定的虚拟手势空间(根据检测到的手重新限定)作为手部检测和跟踪的基础,而不使用最初生成的虚拟手势空间(最初是根据检测到的区别性解剖特征(例如检测到的脸)生成的)。
[0126]
在914中,在重新限定的虚拟手势空间中(例如,使用手部检测和跟踪子系统316)跟踪检测到的手(或主要手)。这一步骤可以与上述步骤614类似。可以提供边界框(和与检测到的手相关联的可选的唯一标识符)(例如,给手势识别子系统322或其它手部分类器)。
[0127]
方法900能够根据检测到的手重新限定虚拟手势空间,使得即使手远离区别性解剖特征,也可以继续跟踪和检测手。在根据检测到的手重新限定虚拟手势空间之后,可以使用重新限定的虚拟手势空间处理后续输入帧。重新限定的虚拟手势空间可以随着手的空间位置变化连续不断地重新限定,使得虚拟手势空间随着手的移动继续以检测到的手为中心。例如,后续输入帧可以使用方法900的省略步骤904和906的变体来处理。
[0128]
在一些示例中,如果在重新限定的虚拟手势空间中不再检测到手,则虚拟手势空间可以根据检测到的区别性解剖特征重新生成。也就是说,区别性解剖特征可以用作限定虚拟手势空间的锚点或默认基础。在一些示例中,仅当在重新限定的虚拟手势空间中无法在预定义数量以上的输入帧(例如至少10个输入帧)中检测到手时,恢复使用区别性解剖特征作为虚拟手势空间的默认基础。
[0129]
图10a和图10b示出了方法900的一种示例性实现方式,在这种实现方式中,虚拟手势空间704最初是根据检测到的用户10的脸12生成的,随后根据检测到的用户10的手14重
新限定。在图10a中,虚拟手势空间704是2d矩形区域,这个区域是根据检测到的脸12的边界框702生成的(例如,类似于图7中的示例)。在虚拟手势空间704中检测到手14,并为手14生成边界框706。在图10b中,根据手14的边界框706重新限定虚拟手势空间704b。
[0130]
例如,为手生成的边界框706可以由一组值{xh,yh,wh,hh}限定,其中,xh和yh分别表示边界框706的锚点(例如中心)的x和y坐标(在自适应手势感应系统300限定的参考帧中),wh和hh分别表示边界框706的宽度和高度。根据边界框706,(例如,在步骤910中)重新限定虚拟手势空间704b。例如,以下等式可以用于重新限定虚拟手势空间704b:
[0131][0132][0133][0134]
hg=βh·hh
[0135]
其中,{xg,yg,wg,hg}是限定如上所述的虚拟手势空间704b的参数,(δ
xh
,δ
yh
)是预定义的相对位置参数,是相对于检测到的手的预定义尺度参数。参数(δ
xh
,δ
yh
)和可以根据重新限定的虚拟手势空间704b的期望大小和边界框706在重新限定的虚拟手势空间704b内的期望位置(例如,由用户10或手势控制设备100的制造商)预定义。值得注意的是,如图10b的示例所示,脸12可以部分或全部从重新限定的虚拟手势空间704b中移除。
[0136]
在一些示例中,当检测到多人(例如,脸部检测和跟踪子系统312检测到多张脸)时,自适应手势感应系统300可以实现优先级规则集352来生成用户列表354,以将一个人识别为主要用户(或主控制器)。在一些实施例中,可以只为主要用户生成虚拟手势空间。在一些实施例中,与非主要用户相比,为主要用户生成和监控虚拟手势空间可以需要更多的计算资源。
[0137]
图11a是自适应手势感应系统300可以使用虚拟手势空间子系统310、手势解析子系统320和多用户优先级子系统350(和子系统312、314、316、322、352、354)等执行的示例性方法1100的流程图。方法1100使用时间上第一的用户规则集作为其优先级规则集352,以解析多个用户执行的多个同时手势。方法1100包括的步骤可以与上述方法600描述的步骤类似,因此不再赘述。
[0138]
在方法1100中,优先级规则集352是时间上第一的用户规则集。在相机fov内执行有效手势的第一用户视为主要用户,直到第一用户的手势由于完成、中止或在手势超时定时器达到预定超时时间时仍然未完成而解析出。当第一用户在超时时间内执行手势并因此被指定为主要用户时,脸部检测和跟踪子系统312、虚拟手势空间生成子系统314、激活区域生成子系统315、手部检测和跟踪子系统316或手势识别子系统322不跟踪或监控其它用户。因此,一旦第一用户已经启动有效手势,系统300就会忽略第二用户做的手势,直到第一用户完成手势、停止做手势或达到完成手势的时间限制。因此,在方法1100中将时间上第一的用户规则集作为优先级规则集决定了方法1100中关于如何生成和处理用户列表354(特别是关于如何相对于非主要用户处理主要用户)的各种步骤之间的关系。
[0139]
在1102中,接收相机102捕获到的帧作为输入帧。这一步骤可以与上述步骤602类似。
[0140]
在1104中,确定是否已经识别到和选择好主要用户。例如,主要用户可以通过分析前一输入帧已经识别到和选择好。如果已经选择好主要用户,则方法1100前进到步骤1106;否则,方法1100前进到步骤1108。
[0141]
在1106中,通过处理帧的至少一部分来检测在帧中的第一位置上可见的主要用户,(例如,使用脸部检测和跟踪子系统312)检测和跟踪主要用户的区别性解剖特征(例如脸),如结合上文图6所述。如果在前一输入帧中识别到主要用户,则已经为主要用户限定虚拟手势空间。在这种情况下,解剖特征可以通过只分析已经限定的虚拟手势空间来检测和跟踪。解剖特征可以在每个帧中跟踪,但检测以较低的频率(例如跳过一个或多个帧)执行。执行检测可以纠正跟踪错误(例如,当在多个帧中跟踪时,跟踪错误会累积)。需要说明的是,虽然这里描述的是检测和跟踪主要用户的区别性解剖特征(例如脸),但是在根据检测到的手重新限定虚拟手势空间(例如,如上文结合图10a和图10b所述)的情况下,可以修改步骤1106来检测和跟踪主要用户的手。
[0142]
在1108中,如果先前没有选择好主要用户,则可以处理整个输入帧来使用脸部检测和跟踪子系统312等检测区别性解剖特征的实例(例如脸的所有实例)。处理输入帧的至少一部分来检测在帧中的第一位置上可见的第一用户,以及处理帧的至少一部分来检测在帧中的第二位置上可见的第二用户。可以为每个检测到的解剖特征生成边界框和标识符。如果在输入帧中没有检测到区别性解剖特征的实例,则方法1100可以返回步骤1102,即处理下一输入帧。
[0143]
在1109中,根据检测到的解剖特征的实例生成排名的用户列表354。每个检测到的实例可以与相应的检测到的用户相关联。
[0144]
由于没有用户启动手势,因此优先级规则集352没有指定主要用户,在这种情况下,多用户优先级子系统350可以使用一组默认用户排名规则从相机fov内的可见用户中选择默认主要用户。在一些实施例中,默认用户排名规则可以包括在优先级规则集352中。可以根据预定义排名标准通过进一步分析检测到的解剖特征(例如,使用任何眼动跟踪技术等任何合适的脸部分析技术)对用户列表354进行排名。例如,如果解剖特征是脸,则排名标准可以指定较大的脸(假设脸更靠近手势控制设备100)的排名高于较小的脸;面向手势控制设备100的脸的排名高于远离手势控制设备的脸;或者眼睛盯着手势控制设备100的脸的排名高于目光移开手势控制设备100的脸。可以使用其它排名标准。如果只检测到区别性解剖特征的一个实例,则这个实例在列表中默认排名最高。
[0145]
在1112中,将排名的用户列表354中的排名最高的用户选择为主要用户。如果用户列表354中只有一个用户,则默认将该用户选择为主要用户。然后,方法1100前进到步骤1106,即跟踪主要用户的解剖特征。
[0146]
在1114中,为主要用户生成虚拟手势空间。如果(根据对前一输入帧的分析)先前已经限定虚拟手势空间,则可以使用已经限定的虚拟手势空间而不是生成虚拟手势空间。否则,根据检测到的主要用户的区别性解剖特征(例如脸)生成虚拟手势空间(例如,与上文描述的步骤606类似)。因此,虚拟手势空间生成子系统用于限定与帧的靠近主要用户在帧中的位置的第一区域对应的第一虚拟手势空间。可选地,可以将表示虚拟手势空间的信息
提供给显示器104等输出设备(例如,使得反馈可以提供给主要用户)。
[0147]
在1116中,在虚拟手势空间中(例如,使用手部检测和跟踪子系统316)检测手。这一步骤可以与上述步骤610类似。可选地,如果在虚拟手势空间中检测到不止一只手,则可以(例如,根据手的大小等一些预定义标准)识别主要手,并将主要手与虚拟手势空间相关联。可选地,可以根据检测到的手重新限定虚拟手势空间(类似于上文对图9的描述)。如果已经根据检测和跟踪的手重新限定虚拟手势空间,则在步骤1106中已经执行手部检测和跟踪,因此可以不需要这一步骤。
[0148]
在1118中,对检测到的手(例如,由边界框限定)(例如,使用手势识别子系统322)执行手势识别。因此,使用手势识别子系统322来处理帧的与虚拟手势空间对应的第一区域,以识别主要用户执行的手势并生成表示识别到的手势的手势类别的标签,如上文结合图6所述。标签可以是标识手势类别的信息或数据。如果识别到有效手势,则输出与识别到的手势的手势类别对应的标签,以将标签转换为软件应用的命令输入,等等。丢弃用户列表354中的任何非主要用户(即,只保留主要用户),然后,方法1100返回步骤1102,即接收和处理下一输入帧。
[0149]
因此,在方法1100中将时间上第一的用户规则集用作优先级规则集确定主要用户执行的手势具有优先级,因为将主要用户识别为在时间上第一做出由手势识别子系统322识别到的手势的用户。换句话说,由于手势识别子系统322不识别用户列表354中的每个其它排名较高的用户的虚拟手势空间内的手势,因此如此识别主要用户。响应于确定主要用户的手势具有优先级,启动手势控制设备的动作(例如,软件应用的对应于命令输入的动作),其中,该动作对应于主要用户的手势。
[0150]
时间上第一的用户规则集还保留计算资源,用于跟踪和识别主要用户的手势。当在步骤1102的新迭代中接收到视频的下一帧时,在步骤1104中识别主要用户,步骤1106、1114、1116和1118仅对主要用户重复。如果主要用户仍在执行有效手势,如手势识别子系统322在步骤1118中确定,则方法1100不将任何计算资源用于对在帧中可见的任何其它用户执行步骤1106、1114、1116或1118。
[0151]
在使用激活区域的一些实施例中,可以将在第一用户的虚拟手势空间内执行有效手势的第一用户指定为主要用户,而不管手势是否在激活区域内执行。下文结合图19a和图19b以及图20a至图20c描述了一种使用激活区域进行手势控制的方法的详细示例。在本示例性方法1100中,在使用激活区域的示例中,一旦在步骤1118中确定第一用户正在虚拟手势空间内但不在激活区域内执行有效手势,方法1100就返回步骤1102,其中,将第一用户指定为主要用户,但是不输出第一用户执行的手势来转换为软件应用的命令输入。第一用户在确定用户正在虚拟手势空间内执行有效手势的每个下一帧中仍然是主要用户,直到超时定时器结束或用户停止在虚拟手势空间内执行手势。然而,不输出与手势的手势类别对应的标签来转换为软件应用的命令输入,直到在激活区域内执行手势。
[0152]
如果手势识别无法识别有效手势(例如无法将手形分类为任何预定义的手势类别),或者如果手势不是当前激活软件应用的有效手势(例如,软件应用向自适应手势感应系统300报告无效输入),则方法1100前进到步骤1120。
[0153]
在1120中,从用户列表354中丢弃当前选择的主要用户。
[0154]
在1122中,确定用户列表354中是否存在任何其它用户。如果用户列表354中存在
至少一个剩余用户,则在步骤1112中,将用户列表354中排名最高的剩余用户选择为主要用户,然后方法1100前进到上述步骤1106。如果用户列表354中没有剩余用户,则方法1100返回步骤1102,即接收和处理下一输入帧。
[0155]
即使当相机102的fov内有多个人时,用户列表354也使得自适应手势感应系统300能够在减少误报的情况下分析和处理手势。用户列表354可以是适应多人存在的相对高效方式,然而,可以使用其它技术来代替或补充上述用户列表354。在上述一些实施例中,可以通过处理整个输入帧来检测区别性解剖特征(例如脸)。在下文描述的其它示例中,区别性解剖特征可以通过只处理输入帧内的感兴趣区域(region of interest,roi)来检测。例如,在上述步骤1108中,可以使用自适应roi方法(例如,由脸部检测和跟踪子系统312进行脸部检测)。
[0156]
在上文描述的一些实施例中,可以使用用户反馈子系统362将反馈信息提供给显示器104等输出设备。反馈信息可以在显示器104上或通过其它输出设备呈现给至少主要用户和潜在的其它用户(例如通过扬声器呈现的音频反馈)。反馈信息表示主要用户正在执行的手势具有优先级。这种反馈信息可以减少用户之间的混淆,并澄清哪些用户的手势正用于控制手势控制设备。下文结合图21描述了这种反馈信息的详细示例。
[0157]
图11b是自适应手势感应系统300可以使用虚拟手势空间子系统310、手势解析子系统320和多用户优先级子系统350(和子系统312、314、316、322、352、354)等执行的示例性方法1101的流程图。方法1101使用动作层次结构规则集作为其优先级规则集352,以解析多个用户执行的多个同时手势。方法1101包括的步骤可以与上述方法600描述的步骤类似或与上述方法1100描述的步骤相同,因此不再赘述。
[0158]
在方法1101中,优先级规则集352是动作层次结构规则集。对应于各种手势类别的各种动作在动作层次结构中进行排名和设置,其中,占据动作层次结构中较高位置的动作比位于动作层次结构中较低位置的动作具有更高的优先级。在将视频内容呈现在智能电视上的示例性实施例中,动作层次结构可以预定义为以下从高优先级到低优先级的动作顺序:关闭电视》静音音频》切换频道》导航视频》调节音量。在一些实施例中,可以允许用户根据用户偏好配置动作层次结构。
[0159]
在不同的实施例中,动作层次结构规则集可以使用简单的解析过程或复杂的解析过程来解析同时手势。当执行与位于动作层次结构中较高位置的动作对应的手势时,使用简单解析过程的实施例忽略了与位于动作层次结构中较低位置的动作对应的手势。因此,考虑到上述示例性预定动作层次结构,如果第一用户正在执行对应于“导航视频”动作的手势(例如,将视频流向前跳过10秒),而第二用户同时执行对应于“音频静音”动作的手势,则忽略第一用户的手势,静音音频且不向前跳过视频流。相反,使用复杂解析过程的实施例会考虑两个同时手势是否对应于冲突动作或非冲突动作。如果动作冲突(例如,两个用户想要调节音量,或者一个用户想要切换频道,而另一个用户想要关闭电视),则根据动作层次结构中两个动作的相对位置(例如,“关闭电视”比“切换频道”的优先级高)和用户列表354中用户的排名(例如,当两个用户都想要调节音量时,用户列表354中排名较高的用户启动与自己的手势对应的动作)的某种组合,只启动优先级较高的动作。另一方面,如果动作不冲突,复杂解析过程将启动这两个动作(例如,如果一个用户想要切换频道,而另一个用户想要调节音量,则这两个动作都可以启动)。在一些实施例中,可以使用复杂解析过程,其中,
可以聚合性质相似的一些冲突动作:例如,想要调节音频音量或在视频中导航的多个用户可以根据预定的聚合方案聚合与他们的手势对应的动作,例如累加多个用户想要的音量变化。
[0160]
因此,在方法1101中使用动作层次结构规则集作为优先级规则集352决定了方法1101中关于如何生成和处理用户列表354以及关于如何相对于非主要用户处理主要用户的各种步骤之间的关系。
[0161]
步骤1102、1104和1108与在方法1100中一样继续执行。
[0162]
在步骤1111中,如果还没有生成用户列表354(例如,根据步骤1110的前一迭代,如下所述),则生成用户列表354,其中,用户根据上文结合图11a的步骤1109描述的默认排名规则和标准进行排名。如果用户列表354已经存在,或者在使用默认排名规则生成用户列表354之后,方法1101前进到步骤1112。
[0163]
步骤1112、1106、1114、1116和1118与在方法1100中一样继续执行。
[0164]
在步骤1118之后,无论在步骤1118是否识别到有效手势,方法1101都前进到步骤1124。
[0165]
在1124中,如果识别到有效手势,则将与识别到的手势的手势类别对应的标签添加到手势队列中。在一些实施例中,手势队列可以存储在存储器208中作为手势类别阵列,其中,每个标签与执行手势的用户相关联。
[0166]
步骤1120与在方法1100中一样继续执行。
[0167]
在1122中,确定用户列表354中是否存在任何其它用户。如果用户列表354中存在至少一个剩余用户,则在步骤1112中,将用户列表354中排名最高的剩余用户选择为主要用户,然后方法1101前进到上述步骤1106。如果用户列表354中没有剩余用户,则方法1101前进到步骤1126。
[0168]
在步骤1126中,使用优先级规则集352处理手势队列,以识别与存储在手势队列中的手势类别对应的动作,并通过应用优先级规则集352选择要进行操作的一个或多个排队标签。本方法1101中的优先级规则集352是动作层次结构规则集,如上文详述。输出选择的一个或多个标签,以转换为软件应用等的命令输入。在使用复杂解析过程的实施例中,如上所述,可以选择两个或两个以上动作执行,或者可以在输出两个或两个以上动作执行之前聚合这些动作。在使用激活区域的实施例中,如参考方法1100所述,在激活区域内执行手势之前,可以不输出选择的一个或多个动作执行。
[0169]
在步骤1110中,重新生成用户列表。将主要用户指定为执行当前排队标签的用户,该标签对应于在动作层次结构中比任何其它当前排队标签位于更高位置的动作。根据任何其它用户当前是否正在执行排队标签,他们在用户列表354中的排名可能低于主用户,其中,他们的相对排名基于他们排队标签在动作层次结构中的位置。当前不执行对应标签包括在手势队列的手势的用户可以使用上文结合方法1100描述的默认排名标准在用户列表354中进行排名。在多个用户执行与在动作层次结构中占据相同位置的动作对应的手势的情况下,默认排名标准可以用于对这些用户进行相对排名。
[0170]
由于没有用户启动手势,因此优先级规则集352没有指定主要用户,在这种情况下,在步骤1111生成的默认用户列表354可以保持不变。
[0171]
在步骤1110中生成用户列表354之后,方法1101然后返回步骤1102,即接收和处理
下一输入帧。
[0172]
图11c是自适应手势感应系统300可以使用虚拟手势空间子系统310、手势解析子系统320和多用户优先级子系统350(和子系统312、314、316、322、352、354)等执行的示例性方法1103的流程图。方法1103使用指定主用户规则集作为其优先级规则集352,以解析多个用户执行的多个同时手势。方法1103包括的步骤可以与上述方法600描述的步骤类似或与上述方法1100描述的步骤相同,因此不再赘述。
[0173]
在方法1103中,优先级规则集352是指定主用户规则集。指定主用户规则集的操作如下:识别单个主要用户,称为主用户,监控或跟踪单个主用户进行手势控制。在一些实施例中,主用户可以执行手势以将主用户状态转移到不同用户。下文结合图22a至图22c详述了这种过程的一个示例。
[0174]
步骤1102、1104、1108和1109与在方法1100中一样继续执行。将在步骤1109中通过默认排名规则和标准确定的主要用户指定为主用户。该用户仍然是主用户,除非离开相机fov或指定另一个用户为主用户,如下文结合图22a至图22c详述。
[0175]
步骤1112、1106、1114、1116和1118与在方法1100中一样继续执行。
[0176]
在步骤1118之后,如果识别到有效手势,则输出对应手势类别的标签,以转换为软件应用等的命令输入。无论在步骤1118是否识别到有效手势,这时都丢弃用户列表354中的任何非主要用户(即,只保留主要用户作为主用户),然后,方法1103返回1102,即接收和处理下一输入帧。在使用激活区域的实施例中,如参考方法1100所述,在激活区域内执行手势之前,可以不输出选择的一个或多个动作执行。
[0177]
在上述一些示例中,区别性解剖特征(例如脸)可以通过处理整个输入帧来检测。在下文描述的其它示例中,区别性解剖特征可以通过只处理输入帧内的感兴趣区域(region of interest,roi)来检测。例如,在上述步骤1108中,可以使用自适应roi方法(例如,由脸部检测和跟踪子系统312进行脸部检测)。
[0178]
在本发明中,由于roi的大小和/或位置可以根据脸部检测器的需求、输入帧的分辨率或处理效率等调整,因此自适应roi可以视为“自适应的”。例如,基于机器学习的脸部和手部检测器通常训练用于处理正方形输入图像。因此,为了提高脸部和手部检测的性能,用于执行检测的roi应该是正方形。考虑到类似的原因,用于手部检测的虚拟手势空间可以限定为正方形。
[0179]
图12是使用自适应roi来检测相机102捕获到的输入帧中的区别性解剖特征的示例性方法1200的流程图。方法1200可以是上述步骤1108的一部分。例如,方法1200可以由脸部检测和跟踪子系统312实现。应当理解,方法1100可以使用步骤1108对应的其它技术来实现,可以使用也可以不使用自适应roi。
[0180]
在1202中,检测是否在相机102捕获到的前一输入帧中检测到解剖特征。如果是,则在1204中,选择在相机102捕获到的当前输入帧中再次使用在相机102捕获到的前一输入帧中检测解剖特征(例如脸)使用的roi。通常情况下,用于检测解剖特征的roi应该小于相机102捕获到的整个输入帧,可以是正方形(根据检测算法的训练或设计方式)。
[0181]
如果在相机102捕获到的前一输入帧中没有检测到解剖特征(或者相机102没有捕获到前一输入帧),则在1206中,从roi序列中选择roi。如果在相机102捕获到的前一输入帧中使用roi序列中的一个roi,则可以选择roi序列中的下一roi在相机102捕获到的当前输
入帧中使用。可以预定义(例如在脸部检测和跟踪子系统312中预定义)roi序列。roi序列定义待用于处理相机102捕获到的顺序输入帧的一系列不同roi。例如,如果roi序列是8个不同roi的序列(例如具有不同位置和/或大小),则依次选择序列中的每个roi用于在相机102捕获到的8个输入帧的序列中检测解剖特征。然后,roi序列可以循环回序列中的第一个roi。
[0182]
图13示出了包括8个不同roi 1302、1304、1306、1308、1310、1312、1314、1316的示例性roi序列。这8个roi 1302至1316可以在相机102捕获到的8个不同输入帧的序列中循环,可以应用于不同分辨率的输入帧。例如,6个roi 1302至1312可以应用于相机102捕获到的输入帧的原始分辨率1300,可以设计成能够检测较小的解剖特征(例如,如果用户10远离手势控制设备100)。两个roi 1314、1316可以应用于输入帧的缩小版本1350(输入帧的较低分辨率的版本),可以设计成能够检测较大的解剖特征(例如,如果用户10靠近手势控制设备100)。对于一些roi 1314、1316,使用输入帧的缩小版本有助于减少处理输入帧的较大区域的计算成本。
[0183]
需要说明的是,roi序列在相机102捕获到的输入帧序列中循环,使得每个输入帧只使用一个选定的roi进行处理(而不是使用两个或两个以上roi来处理相同的输入帧)。由于相机102捕获到的视频的输入帧通常以高频捕获,因此相邻帧之间的时间差可以足够小,使得通过这种方式使用roi序列处理相机102捕获到的输入帧序列不会丢失信息(或丢失的信息非常少)。
[0184]
可以存在预定义的不同roi序列(例如存储在脸部检测和跟踪子系统312中)。所使用的roi序列可以由用户10选择,或者可以存在循环使用不同roi序列的预定义顺序(即,待使用的roi序列可以存在预定义顺序)。此外,虽然图13中的示例示出了roi序列中的每个roi在序列中使用一次,但是在一些示例中,可以限定roi序列,指定的roi在roi序列中使用两次或两次以上。可以使用其它此类变型。
[0185]
在1208中,使用选择的roi(在步骤1204中在相机102捕获到的前一输入帧中选择的roi或在步骤1206中从roi序列中选择的roi)检测区别性解剖特征。
[0186]
使用自适应roi来检测区别性解剖特征(例如脸)可以减少计算成本和/或提高经训练的脸部检测和跟踪子系统312的性能。
[0187]
在一些示例中,当激活手势检测时(或当默认使用手势检测时),自适应roi技术可以用于处理相机102捕获到的每个输入帧。在其它示例中,自适应roi技术可以用于处理相机102捕获到的每n(其中,n》1)个输入帧。
[0188]
如上所述,在一些实施例中,手部检测和跟踪子系统316可以输出手势识别子系统322进行手势识别而要使用的手部图像(即,输入帧的与边界框对应的一部分)。在一些实施例中,手势识别子系统322可以通过使用机器学习技术构建的模型来实现。在一些实施例中,手势识别子系统322包括经训练的手势分类神经网络,用于对手部图像(例如,输入帧的与手部检测和跟踪子系统316输出的边界框对应的一部分)执行手势分类。
[0189]
通常情况下,随着手部图像的裁剪(例如,当边界框与地面真值存在很大偏移时),经训练的手势分类神经网络的准确性会下降。边界框调整的一个示例在于2019年3月15日提交的申请号为16/355,665、发明名称为“用于脸部识别的自适应图像裁剪(adaptive image cropping for face recognition)”的美国专利申请中描述,其全部内容通过引用
结合在本技术中。本文描述了一种类似的边界框调整方法,以帮助改进手势识别。
[0190]
图14是可以用于通过手势识别子系统322进行手势识别的手势分类神经网络的一种示例性实现方式的框图。手势分类网络1400可以与边界框修正网络1450的旁分支一起实现。手势分类网络1400对手部图像(例如,输入帧的与手部检测和跟踪子系统316输出的边界框对应的一部分)执行手势分类,边界框修正网络1450对用于生成手势分类神经网络1400使用的手部图像的边界框执行修正。
[0191]
接收手部图像作为手势分类神经网络1400的输入数据。手部图像可以是输入帧的裁剪版本(例如,输入帧的与为检测到的手生成的边界框对应的一部分)。在一些实施例中,输入数据可以是一批手部图像,例如用于网络1400、1450的分批训练,或根据帧序列实现手势分类。手势分类网络1400包括一系列卷积块1402(例如使用resnet设计来实现)。为了简单起见,示出了3个这样的卷积块1402,但手势分类网络1400中可以包括更多或更少的卷积块1402。这些卷积块1402向手势分类全连接网络(fully connected network,fcn)1404输出,该网络输出确定的手势类别。手势分类fcn 1404接收从一系列卷积块1402中的最后一个卷积块1402输出的向量作为输入。手势分类fcn 1404使用特征嵌入(embedding)来确定在手部图像中识别到的手势的手势类别,并输出确定的手势类别作为标签。标签是为识别到的手势标识确定的手势类别的数据或信息。在一些实施例中,手势分类fcn 1404输出包括可能手势类别的概率分布的向量。也就是说,手势分类网络1400的输出可以是不同手势类别的概率,而不是一个确定的手势类别。在一些实施例中,手势分类fcn 1404在最后一个输出层中包括softmax函数,用于对可能手势类别的输出概率分布进行归一化。
[0192]
每个卷积块1402还向属于边界框修正网络1450的旁分支1452输出。每个旁分支1452向边界框修正fcn 1454输出。每个旁分支1452可以单独包括可选的最大池化层、可选的调整大小层和卷积块。将旁分支1452的输出级联成组合输出向量,组合输出向量在输入到边界框修正fcn 1454之前,可以由1
×
1卷积块(未示出)进行扁平化。边界框修正fcn 1454的输出是调整或修正用于裁剪输入帧以生成输入帧的裁剪版本(例如手部图像)的边界框的大小和位置的信息(例如,以边界框的坐标信息为形式)。
[0193]
下文描述联合网络1400、1450的训练。如上所述,手势分类fcn 1404可以包括softmax层。手势分类fcn 1404可以进一步计算和输出交叉熵损失,可以认为交叉熵损失是模型中的输出概率分布和原始概率分布之差的度量。这种交叉熵损失可以用作softmax层的损失函数,因此也可以称为softmax损失。类似地,边界框损失可以从边界框修正fcn 1454输出。softmax损失和边界框损失可以组合为总损失函数,总损失函数可以用于训练1456联合网络1400、1450。softmax损失、边界框损失和使用总损失函数的训练1456可以只在训练网络1400、1450的过程中使用,在推理过程中不需要。
[0194]
在训练网络1400、1450的过程中,训练数据样本可以使用基于地面真值手部边界框的输入帧(例如手部图像)的随机裁剪版本来生成。
[0195]
图15示出了一些示例,其中,地面真值1502限定用于生成输入帧的裁剪版本(例如手部图像)的优化边界框,输入帧的其它随机裁剪版本(例如手部图像)生成为训练数据样本1504。需要说明的是,训练数据样本1504不仅可以移动边界框的位置,而且还可以改变边界框的大小(使得手部图像中的手看起来更大或更小)。每个训练数据样本1504相对于地面真值1502的边界框偏移用作训练边界框修正的标签。
[0196]
联合网络1400、1450通过最小化总损失函数来训练,在本示例中,总损失函数是分类损失函数(softmax损失)和边界框损失函数的线性组合。下文描述边界框损失函数的一个示例。
[0197]
考虑到图16中的简化示例,示出了围绕对象限定的地面真值边界框1802和裁剪的训练数据样本边界框1804。假设{(x1,y1),(x1,y2),(x2,y1),(x2,y2)}是限定训练数据样本边界框1804的位置(本示例中的4个角)的坐标,假设是限定对应地面真值边界框1802的位置的坐标。边界框修正网络1450估计训练数据样本边界框1804和地面真值边界框1802之间的相对旋转θ和相对位移{z1,z2,z3,z4},其中,
[0198][0199]
边界框损失函数可以定义为:
[0200][0201]
其中,λ是正则化参数。
[0202]
在推理过程中,可以迭代地校正用于裁剪输入帧以生成手部图像的边界框,直到边界框修正网络1450预测的偏移接近于0。可以通过组合每次迭代获得的所有手势分类得分来计算最终手势分类得分,如下所示:
[0203][0204]
其中,sm是第m次迭代的分类得分(例如softmax输出),是第m个边界框和最终修正边界框的对应权重(例如检测评价函数(intersection over union,iou))。
[0205]
在推理过程中,使用手势分类网络1400对手部图像执行迭代分类。在每次迭代中,使用通过前一次迭代的输出边界框修正参数校正的边界框来裁剪前一输入帧,得到输入给手势分类网络1400的手部图像。
[0206]
因此,边界框修正网络1450和手势分类网络1400一起提供反馈,所述反馈用于修正为相机102捕获到的输入帧中的手部图像生成的边界框,这样有助于提高手势分类网络1400的性能。
[0207]
图17是使用边界框修正(例如,使用上述联合网络1400、1450)执行手势识别的示例性方法1700的流程图。方法1700可以是上述步骤1118的一部分。例如,方法1700可以由手势识别子系统322实现。应该理解,方法1100可以使用步骤1118对应的其它技术来实现,可以使用也可以不使用边界框修正。
[0208]
在1702中,接收相机102捕获到的输入帧以及为检测到的手生成的边界框(例如,由手部检测和跟踪子系统316输出),并且使用生成的边界框裁剪输入帧,以此生成输入帧的裁剪版本(例如手部图像)。
[0209]
在1704中,手势分类网络和联合边界框修正网络(如上所述)可以用于通过上述边界框修正执行手势分类。
[0210]
可选地,在1706中,可以在相机102捕获到的多个输入帧中执行手势识别。例如,手势识别子系统322可以存储相机102捕获到的先前输入帧所在的存储空间(buffer),并通过
考虑相机102捕获到的先前输入帧来执行手势识别。
[0211]
存储空间(例如在自适应手势感应系统300中实现)可以用于存储相机102捕获到的预定数量的先前输入帧。相机102捕获到的存储在存储空间中的先前输入帧可以相对较少(例如,10个至30个先前输入帧),以便更高效地利用内存资源。在一些示例中,存储空间可以另外或替代地存储对相机102捕获到的少量先前输入帧执行的手势分析的结果。
[0212]
对于要识别的单个静态手势,手势识别子系统322可以要求表示手势类别的相同标签在相机102捕获到的预定义数量(n)的先前输入帧中输出预定义最少次数(k),其中,k≥1且k≤n。这种要求可以有助于提高检测准确性且减少误报。在一些示例中,在相机102捕获到的n个先前输入帧内,可能需要在相机102捕获到的k个连续输入帧中检测到相同的手势类别。可以选择预定义的最小k为相对较小的数字(例如10),以实现更好检测,而且仍然实现近实时手势识别。使用这种方法可以检测到的静态手势可以包括静音手势(例如用于静音或取消静音命令)或张开手势(例如用于播放或暂停命令)等。n个先前输入帧可以存储在存储空间中,并可以用作检测手势的滑动窗口,从而帮助减少误报。
[0213]
手势识别子系统322可以根据两个或两个以上静态手势的组合识别动态手势。例如,完成的动态手势可以解耦成不同的状态,其中,状态切换是静态手势的检测结果。手势识别子系统322可以实现一组预定义的状态切换规则,这些规则用于进行基于状态的动态手势识别。
[0214]
图18是基于状态的动态手势识别的一个示例的状态图,基于状态的动态手势识别可以由手势识别子系统322实现。当第一次激活手势识别子系统322时,或者当未检测到当前有效手势时,中性状态1802可以默认是初始状态。
[0215]
当首先检测到第一手势切换到滑动就绪状态1804,然后检测到张开手势切换到滑动状态1806时,可以检测到滑动动态手势。在进入滑动状态1806时,手势识别子系统322将手势识别为动态滑动手势。因此,识别静态握拳手势和随后的静态张开手势(按照适当的顺序)导致识别动态滑动手势。此外,明确检测动态滑动手势(例如将滑动手势与不涉及位置变化的另一动态手势区分开)需要检测到的握拳手势和检测到的张开手势之间的位置变化。检测到的手势的位置变化可以根据为检测到的手生成的边界框的坐标的变化来计算。在进入滑动状态1806时,手势识别子系统322可以生成表示识别到的手势(例如手势类别标签)的输出,还可以提供表示滑动就绪状态1804和滑动状态1806的检测之间位置变化的输出。
[0216]
垂直或水平动态拖拽手势可以是放大手势、缩小手势和放大静态手势的组合。例如,在检测到放大静态手势之后,从中性状态1802切换到捏合就绪状态1808。缩小静态手势的检测导致捏合就绪状态1808切换到捏合激活状态1810。保持缩小静态手势的同时改变垂直位置(例如大于预定义阈值)导致捏合激活状态1810切换到垂直拖拽状态1812。类似地,保持缩小静态手势的同时改变水平位置(例如大于预定义阈值)导致捏合激活状态1810切换到水平拖拽状态1814。如果位置变化是垂直变化和水平变化的组合(例如位置的对角线变化),则幅度较大的变化可以用于确定状态切换。可选地,如果位置变化是垂直变化和水平变化的组合,则可能没有识别到状态切换。在进入垂直拖拽状态1812或水平拖拽状态1814时,手势识别子系统322可以生成表示识别到的手势(例如手势类别标签)的输出,还可以提供表示垂直位置变化或水平位置变化的输出。例如,手势识别子系统322可以(例如根
据在输入帧中限定的坐标)计算距离并输出这个值。距离值可以用于将动态拖拽手势映射到拖拽命令输入。放大静态手势的检测导致垂直拖拽状态1812或水平拖拽状态1814切换到捏合就绪状态1808。返回到捏合就绪状态1808可以识别为结束动态拖拽手势。
[0217]
对于涉及位置变化的动态手势,手势识别子系统322可以根据物理定律和/或预期的人运动实现预定义规则,以进一步排除可能的误报。例如,预定义规则可以是,检测到的手不应该在连续输入帧之间表现出大于预定义阈值的位置变化(例如超过100个像素的变化)。
[0218]
使用基于状态的手势识别比基于运动的手势分类和识别有优势。例如,与检测静态手势相比,检测和处理手势运动需要更多处理资源。此外,基于状态的手势识别可能不容易出现误报。
[0219]
在一些实施例中,系统300可以使用扩展的虚拟手势空间来识别有效手势,并且使用激活区域,必须在激活区域启动手势以便转换为命令输入。在虚拟手势空间内但在激活区域之外启动的手势可以识别为有效手势,但在手势在激活区域内执行之前,手势控制设备100不启动动作。
[0220]
激活区域可以提供区分用户10执行的意外手势和有意手势的方法。在一些情况下,用户10可以在激活区域之外执行有效手势。手势识别子系统322可以检测、识别和分类手势,但在一些实施例中,系统300可以将这种手势视为用户10是否真的想要与系统交互的模糊动作。在使用激活区域的实施例中,手势识别子系统322可以确定用户10已经在激活区域之外在一定数量的输入帧中执行有效手势或有效手势序列。作为响应,用户反馈子系统362可以显示激活区域反馈,如下文结合图20c所述。在一些实施例中,激活区域反馈可以包括表示人体并显示激活区域和当前手部位置的图像。激活区域反馈可以显示用户的手与激活区域和用户10正在执行的手势之间的距离和角度位置。在一些实施例中,激活区域反馈可以包括附加信息,例如文字指令,提示用户将手移进激活区域,以便手势控制设备100启动对应动作。
[0221]
图19a是使用激活区域对手势控制设备100进行手势控制的第一示例性方法1900的流程图。图19b是使用激活区域对手势控制设备100进行手势控制的第二示例性方法1901(即方法1900的变体)的流程图。结合图20a至图20c描述了方法1900和1901的各种步骤。图20a示出了相对于用户限定的虚拟手势空间和激活区域的简化表示。图20b示出了虚拟手势空间、为检测到的手生成的边界框和相对于图20a中的用户限定的激活区域的简化表示。图20c示出了在显示器104上显示的示例性激活区域反馈屏幕,以提示用户将手势移进激活区域。
[0222]
返回图19a,方法1900在(例如,在步骤1114中由虚拟手势空间生成子系统314)限定虚拟手势空间之后开始。在本实施例中,虚拟手势空间相对于检测到的用户头部位置限定。图19b示出了相对于用户头部1934的位置限定的示例性虚拟手势空间1932。在一些实施例中,虚拟手势空间可以相对于用户的另一身体部位限定,例如已经由手部检测和跟踪子系统316检测到的手。
[0223]
在步骤1902中,在虚拟手势空间内检测用户的手,手势识别子系统322识别手在执行的手势。在图20a中,示出了用户的手1938在虚拟手势空间1932内执行“张开”手势。
[0224]
在步骤1904中,手部检测和跟踪子系统316确定用户的手是否正在激活区域
(activation region,ar)内执行手势。在图20a中,示出了激活区域1936小于虚拟手势空间1932且位置相对于用户的头部1934。在其它实施例中,激活区域的大小或形状可以不同,其位置可以相对于用户的不同身体部位。
[0225]
如果在步骤1904中确定手势在激活区域内,则方法1900前进到步骤1910。在步骤1910中,虚拟手势空间生成子系统314相对于用户的手重新限定虚拟手势空间,如上文结合图9所述(方法900的步骤910)。在一些示例中,重新限定的虚拟手势空间可以以手为中心,但大于通过手的尺寸限定的手部边界框。图20b示出了以用户的手1938为中心的示例性重新限定的虚拟手势空间1932和尺寸通过手1938的尺寸限定的手部边界框1940。手部检测和跟踪子系统316可以使用重新限定的虚拟手势空间1932。根据步骤1902、1904和1910,重新限定的虚拟手势空间1932可以在每个下一帧中重新限定,从而随手移动,而且即使移出激活区域,也能跟踪。只要用户正在执行识别到的手势,重新限定的虚拟手势空间1932会随用户的手移动,可以识别该手的手势并转换为命令输入。在步骤1912中,识别和分类手势,输出相应的手势类别(例如,标识手势类别的标签)以转换为命令输入,如上结合图11a中的方法1100等所述。
[0226]
如果在步骤1904中确定手势不在激活区域内,则方法1900前进到步骤1906。
[0227]
在步骤1906中,查询超时定时器以确定在激活区域之外执行的手势是否因为在激活区域之外停留超过预定时间段而超时。如果在步骤1906中确定手势已经超时,则手势识别子系统322忽略该手势,直到检测到重置条件。在一些示例中,重置条件可以是手势识别子系统322检测到手势不再由用户的手执行。一旦已经触发重置条件,则在步骤1902中,手势识别子系统322可以再次识别到手势。
[0228]
如果在步骤1906中确定在激活区域之外执行的手势没有超时,则方法1900前进到步骤1908。在步骤1908中,启动未运行的超时定时器。
[0229]
在步骤1909中,用户反馈子系统362向用户呈现激活区域反馈。图20c示出了示例性激活区域反馈屏幕1950。当在步骤1908中检测到用户正在激活区域之外执行手势时,在显示器104上呈现激活区域反馈屏幕1950,以将反馈信息提供给用户,提示用户将手势移进激活区域。激活区域反馈屏幕1950将激活区域反馈信息1954叠加到在显示器104上呈现的其它内容(在这种情况下是视频内容1952)之上。在本示例中,激活区域反馈信息1954包括用户身体1960的风格化表示,示出了激活区域1958相对于用户身体1960的大小、形状和位置。激活区域反馈信息1954还包括执行手势的用户手1956的表示,示出了手1956相对于激活区域1958的位置,从而提示用户将执行手势的手移进激活区域。在本示例中,激活区域反馈信息1954还包括提示用户将手移进激活区域的文字提示(在这种情况下是文字“将手移近”)。
[0230]
图19b是使用激活区域对手势控制设备100进行手势控制的第二示例性方法1901的流程图。这些步骤与方法1900的步骤相同,但彼此位置不同。值得注意的是,如果在步骤1906中确定手势在激活区域内,则方法1901直接前进到步骤1912,即识别和分类手势,然后前进到步骤1910,即相对于手重新限定虚拟手势空间。此外,在步骤1908中确定在激活区域之外执行的手势没有超时之后的分支中,在步骤1909(呈现激活区域反馈)之后执行步骤1910(重新限定虚拟手势空间)。这表示,尽管方法1900只在激活区域中检测到手(如图20b所示)之后才相对于手重新限定虚拟手势空间,但在方法1901中,一旦在初始虚拟手势空间
内检测到做手势的手,就相对于手重新限定虚拟手势空间。在另一种方法(未示出)中,一旦在初始虚拟手势空间内检测到手,就可以相对于用户的手重新限定虚拟手势空间,而不管是否检测到有效手势。可以认为这一步骤是方法1900或方法1901的初始条件:在步骤1902之前初始限定虚拟手势空间可以是响应于手部检测和跟踪子系统316检测手而相对于用户的手限定虚拟手势空间,如上文参考图9(方法900的步骤908至910)所述。
[0231]
应当理解,这些步骤中的许多步骤可以按照不同的顺序执行,而不会实质性地影响方法1900或1901的操作方式。例如,在步骤1908中启动超时定时器和在步骤1909中呈现激活反馈数据可以相对于彼此以任何顺序执行。
[0232]
图21示出了向多用户环境中的用户呈现反馈的示例性图形用户界面2102。图形用户界面2102在显示器104上呈现,使得它对多用户环境中的至少一些用户可见。在本示例中,显示器104用于在图形用户界面2102中呈现视频内容2104。当脸部检测和跟踪子系统312、虚拟手势空间生成子系统314、手部检测和跟踪子系统316和/或手势识别子系统322检测到用户执行的有效手势时,并且优先级规则集352确定该手势具有优先级时,用户反馈子系统362呈现表示检测到的手势具有优先级的反馈信息。在本实施例中,反馈信息包括表示正在执行有效手势并且该手势具有优先级(即,如果手势完成,系统300会启动对应动作)的“手部”图标2108以及表示做手势的用户的标识符的“脸部”图标2106。在本实施例中,脸部图标2106根据相机102捕获到的当前视频帧、根据相机102捕获到的不同最近视频帧或根据存储在存储器208中的先前保存的用户脸部图像数据显示当前主要用户的脸部图像。根据系统300使用的优先级规则集352,可以识别到脸部图标2106示出的主要用户,主要用户可以是时间上第一的用户(使用时间上第一的用户规则集)、执行与优先级高于任何其它执行的手势的动作对应的手势(使用动作层次结构规则集)或者是指定的主用户(使用指定主用户规则集)。因此,反馈信息表示脸部图标2106示出的用户当前正在执行的手势是有效手势,并且优先级比其它用户当前正在执行的任何其它手势高。
[0233]
在一些实施例中,例如,如果自适应手势感应系统300正在使用动作层次结构规则集,并且同时执行的两个有效输入手势不冲突或可以聚合,则反馈信息可以表示正在执行两个或两个以上有效手势。在这些实施例中,反馈信息可以包括两个或两个以上脸部图标2106,以表示所有用户正在做同时有效的且对应动作不冲突的手势。
[0234]
在一些实施例中,脸部图标2106可以是风格化图标,而不是主要用户的脸部图像。风格化图标可以根据用户偏好设置,可以是相机102捕获到的用户的脸部图像的风格化表示,或者可以通过某种其它方式确定。在一些实施例中,脸部图标2106和/或手部图标2108的位置可以与图21所示的示例不同。例如,脸部图标2106可以显示在显示器104的左边缘、右边缘或下边缘附近,而不是靠近上边缘,或者脸部图标2106可以根据主要用户在相机102的fov内与相机fov内的其它用户绝对或相对的位置显示在上边缘或下边缘的水平位置上。
[0235]
图22a至图22c示出了根据上文结合图11c描述的方法1103和2240指定新主用户的示例性方法。图22a和图22b示出了在执行指定新主用户的动态手势的过程中在显示器104上呈现的示例性图形用户界面。图22c示出了执行动态手势,在所描述的示例中,动态手势是当前主用户指定新主用户的动态手势。总体而言,图22a至图22c提供了执行上文结合图11c描述的方法1103的一个示例。
[0236]
图22a示出了显示器104用于呈现第一图形用户界面2202,第一图形用户界面2202
包括标识当前主用户的反馈信息。用户反馈子系统362可以在显示器104上呈现第一图形用户界面2202,以响应手势识别子系统322识别当前主用户正在执行的“新主用户手势”。第一图形用户界面2202包括以在相机102的fov内可见的每个用户的风格化表示为形式的反馈信息。主用户示为站在显示器104前面的第一用户2204,在图形用户界面2202中由第一用户图标2210表示,而第二用户2206和第三用户2208在图形用户界面2202中分别由第二用户图标2212和第三用户图标2214表示。在各种实施例中,第一用户图标2210可以通过各种区别性特征与第二用户图标2212和第三用户图标2214区分开。例如,如图22a所示,第一用户图标2210大于第二用户图标2212和第三用户图标2214。在一些实施例中,第一用户图标2210与第二用户图标2212和第三用户图标2214具有不同的颜色或者具有不同的形状或风格。在一些实施例中,3个用户图标2210、2212、2214可以包含表示或标识它们各自用户的信息,而不是它们在图形用户界面2202上的相对位置。例如,这3个用户图标可以基于每个用户的脸部图像,如上文结合图21描述的示例性脸部图标2106。
[0237]
图22b示出了第二用户图形用户界面2222,包括表示实际指定或待指定第二用户2206为新主用户的反馈信息。这里,第二用户图标2212通过上文结合图22a描述的一个或多个区别性特征与其它用户图标2210、2214区分开。
[0238]
当使用指定主用户规则集执行上文结合图11c描述的方法1103时,系统300使用优先级规则集352来指定新主用户,以响应于图22c所示的当前主用户执行动态手势。图22c示出了主用户2240执行动态手势以指定新主用户的5个步骤2261至2265。虽然在图22c中执行的动态手势是用于指定新主用户的动态手势的一个示例,但应当理解,描述和示出的动态手势可以在一些实施例中用于执行其它控制命令。示出的动态手势包括以下手势序列:放大、缩小、左移或右移、缩小、放大。在一些实施例中,这种动态手势或其变体(例如上移或下移用户的手而不是左移或右移)可以用于在取值范围内改变变量,例如,向上或向下调节音频音量或从内容源范围(例如频道或视频文件)中选择。
[0239]
在步骤2261中,主用户2240使用手执行放大手势34。由于放大手势34是在主用户的虚拟手势空间2246内执行的,因此手部检测和跟踪子系统316检测到。虚拟手势空间2246示为靠近脸部检测和跟踪子系统312检测到的主用户的脸的边界框。然而,放大手势34在激活区域2244之外执行,激活区域2244示为靠近主用户的脸的较小边界框。因此,虽然放大手势34在步骤2261中由手部检测和跟踪子系统316检测到并由手势识别子系统322识别,但在激活区域2244内执行之前,可能不会转换为命令输入,如上文结合方法1900和1901所述。在一些实施例中,放大手势34必须在预定时间段内移进激活区域2244,或者手势超时并被忽略,直到满足重置条件,也如上文结合方法1900和1901所述。
[0240]
在步骤2262中,将执行放大手势34的主用户的手移进激活区域2244。现在,手势识别子系统322输出放大手势并将其转换为命令输入。
[0241]
在步骤2263中,主用户的手在激活区域2244内执行手势识别子系统322识别到的缩小手势36。在本实施例中,在激活区域2244内执行放大到缩小手势构成“新主用户手势”。作为响应,手部检测和跟踪子系统316相对于主用户2240的手重新限定虚拟手势空间2246。手部检测和跟踪子系统316和手势识别子系统322针对其它手势跟踪和监控重新限定的虚拟手势空间2246。将放大到缩小动态手势识别为新主用户手势,从而启动指定新主用户的动作。
[0242]
用户反馈子系统362在显示器104上呈现新主用户选择信息,例如图22a中的第一用户反馈屏幕2202。主用户2240对应于图22a中的第一用户2204。第一用户图标2210显示在屏幕2202上,表示第一用户2204用作主用户2240。第二用户图标2212和第三用户图标2214构成指定新主用户的选项。
[0243]
在步骤2264中,主用户2240相对于其在激活区域2244内的起始位置将手右移(即移到图22c的左侧)。在移动过程中保持缩小手势36。响应于右移,用户反馈子系统362可以显示反馈信息,例如图22b中的第二用户反馈屏幕2222,显示主用户2240已经暂定地将第二用户(即右边的下一个用户)指定为新主用户。
[0244]
然而,直到主用户2240通过执行放大手势34完成动态手势之前,才最终确定这个新指定。只要主用户2240保持缩小手势36,手就可以继续左移或右移(在一些实施例中,上移或下移)来改变指定新主用户的选项的暂定选择,以突出或识别与显示器104上的不同用户图标对应的另一用户。
[0245]
在步骤2265中,主用户2240执行放大手势34。在这个阶段,基于显示器104上的选定用户图标,当前指定为新主用户的任何用户都指定为新主用户。
[0246]
图22c中所示的步骤与使用激活区域进行手势控制的方法1900一致。具体地,方法1900仅在用户将手移进激活区域2244之后,相对于用户的手重新限定虚拟手势空间2246。应当理解,可以使用替代的通过激活区域进行手势控制的方法,例如方法1901,即只要在初始虚拟手势空间2246内检测到用户的手,就相对于用户的手重新限定虚拟手势空间2246。如果在图22c所示的步骤中使用方法1901代替方法1900,则唯一的区别是在步骤2261和2262中,相对于用户的手限定虚拟手势空间2246的边界框,与在步骤2263至2265中一样。
[0247]
在各种示例中,本发明描述了有助于提高手势检测和识别的准确性和效率的系统和方法。本发明可以用于在复杂多用户环境中检测和识别手势和/或用于长距离检测手势。
[0248]
即使在复杂现实场景中,使用上述方法中的一个或多个方法(例如,自适应roi技术、边界框修正联合网络、虚拟手势空间、多用户优先级规则集、激活区域)也可以实现更鲁棒的手势检测和识别。提高手势检测的准确性可以更高效地处理捕获到的输入帧。在一些示例中,输入帧可以按照低于图像捕获速率的频率处理。例如,为了检测和跟踪脸(或其它区别性解剖特征)和手,处理每n个帧(其中,n》1),而不是处理每个输入帧。n可以是用户选择的参数,可以是预编程参数,或者可以是手势控制设备100自动选择的参数(例如,当图像以低于预定义阈值的速率捕获时,n可以为1;当图像以超过预定义阈值捕获时,n可以为2或以上;当图像质量差或分辨率低时,n可以为1;当图像分辨率高时,n可以为2或以上)。通过处理每n个(n》1)帧,仍然可以非常准确地近实时地执行手势检测和识别,且可以减少手势控制设备所需的处理资源。
[0249]
本发明描述了使用神经网络进行脸部和手部检测的示例性实现方式。本发明描述了一种示例性联合神经网络,能够修正手部边界框,以帮助提高手势分类和识别的准确性。
[0250]
在一些示例中,本发明描述了虚拟手势空间,可以根据检测到的脸(或其它区别性解剖特征)限定虚拟手势空间。通过使用限定的虚拟手势空间来检测手,可以实现更准确和/或更高效的手势检测。在一些实施例中,虚拟手势空间还可以包括子空间,特定子空间中的手势可以映射为鼠标输入。因此,虚拟手势空间可以用作虚拟鼠标。
[0251]
虽然已经在包括显示器和相机(例如,智能电视、视频会议系统、vr或ar系统、智能
手机或平板电脑)的手势控制设备中描述了一些示例,但本发明可以与包括或不包括显示器和/或相机的其它手势控制设备相关。例如,本发明可以与智能扬声器、智能电器、物联网(internet of things,iot)设备、仪表盘设备(例如安装在车辆中)或具有低计算资源的设备相关。手势控制设备可以具有嵌入式和/或外置相机和/或显示器。
[0252]
本文中描述的示例可以适用于增强现实(augmented reality,ar)、虚拟现实(virtual reality,vr)和/或视频游戏应用。
[0253]
尽管本发明通过按照一定的顺序执行的步骤描述方法和过程,但是可以适当地省略或改变方法和过程中的一个或多个步骤。在适当情况下,一个或多个步骤可以按所描述的顺序以外的顺序执行。
[0254]
尽管本发明在方法方面至少部分地进行了描述,但本领域普通技术人员将理解,本发明也针对用于执行所述方法的至少一些方面和特征的各种组件,无论是通过硬件组件、软件还是其任意组合。相应地,本发明的技术方案可以通过软件产品的形式体现。合适的软件产品可以存储在预先记录的存储设备或其它类似的非易失性或非瞬时性计算机可读介质中,包括dvd、cd-rom、usb闪存盘、可移动硬盘或其它存储介质等。软件产品包括有形地存储在其上的指令,所述指令使得处理设备(例如,个人计算机、服务器或网络设备)能够执行本文中公开的方法的示例。
[0255]
在不脱离权利要求书的主题的前提下,本发明可以通过其它特定形式实施。所描述的示例性实施例在各方面都仅仅是说明性的而非限制性的。可以组合从一个或多个上述实施例中选择的特征,以创建非显式描述的可选实施例,在本发明的范围内可以理解适合于此类组合的特征。
[0256]
还公开了所公开范围内的所有值和子范围。而且,尽管本文公开和示出的系统、设备和过程可以包括特定数量的元件/组件,但是所述系统、设备和组件还可以被修改为包括更多或更少的这类元件/组件。例如,尽管所公开的任何元件/组件可以作为单数引用,但是本文公开的实施例可以被修改为包括多个的这类元件/组件。本文中描述的主题旨在涵盖和包括技术上的所有适当变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1