AI实现的早期-PET采集的制作方法
ai实现的早期-pet采集
技术领域
1.本发明涉及用于核医学成像的数据处理系统、涉及用于基于训练数据来训练用于核成像的机器学习模块的训练系统、相关的方法、涉及计算机程序单元以及计算机可读介质。
背景技术:
2.发射成像允许功能性成像,而不是诸如x射线成像(例如ct(计算机断层摄影)成像)的结构性成像。功能性成像包括pet(位置发射断层摄影)或spect(单光子发射计算机断层摄影)成像模态。功能性影像表示器官做什么,而不是结构性影像所表示的其形态。功能性成像和结构性成像都能够结合使用。
3.更详细地,pet是一种已确立的核医学成像模态,临床上用于可视化人体的功能的过程。患者被施用正电子发射放射性药物,所述药物直接参与靶向代谢过程或与特定受体结合。
4.在同位素衰变期间,由带有局部电子的质子湮灭(在相反的空间方向上)所发射的光子,通常由身体外部的环形探测器设备来探测。随时间收集这些检测事件,并通过从随机或分散事件中分离出真实的符合事件来预处理数据,允许对表示身体内的示踪剂分布的发射影像的(三维)重建。通常,与(例如由ct或mri(磁共振成像)提供的)额外的解剖信息结合/叠加,可以观察到与预期的/典型的示踪剂分布的偏差。这些变化与生理代谢模式的变化相关联。因此,发射影像可以帮助识别恶性过程,如肿瘤形成。
5.pet图像质量和相应的诊断值取决于特定因素,包括示踪剂的结合/积累亲和力、其生理清除特性、以及扫描器的灵敏度、施用的示踪剂数量和同位素的正电子产量。
6.当前的临床工作流程设置通过已确立的剂量施用方案、患者等待时间以及标准图像采集持续时间来解释这些影响因素。在患者等待时间期间,允许示踪剂在目标区域积聚。由于(基于同位素衰变的)采集过程的统计性质,为了实现所想要的图像质量和诊断值所需的图像采集持续时间(也称为“扫描时间”)也可能取决于一个或多个上述因素。
7.鉴于可施用的示踪剂数量是有限的(主要出于辐射安全,但也出于成本降低的原因),为了实现对于后续诊断所需的特定图像质量水平,使用扫描时间以及(在可能的法律范围内)个体示踪剂量调整。
8.鉴于检测过程中固有变化引起的局部图像强度变化(聚集“噪声”),为了充分支持对某些空间扩展和定量变化范围的空间示踪剂密度变化的检测,主要由必须收集的信息的数量来确定扫描时间。简单地说:采集时间段越长(每一种床的位置),最终图像越接近理想的、无噪声的、“真实的”图像。
9.在临床实践中,不仅是由于工作流程,而且由于患者只能忍受有限的扫描程序持续时间,扫描时间必须是固定的。此外,对于给定患者,从示踪剂施用到扫描能够开始进行(采集开始时间)的患者等待时间可能达到60分钟或更长。
技术实现要素:
10.可能需要改进核医学成像,具体地,需要缩短核医学成像中所涉及的特定时间段。
11.本发明的目的通过独立权利要求的主题来解决,其他实施例合并在从属权利要求中。应当注意,本发明的下述方面同样适用于用于核医学成像的数据处理系统、用于训练在核成像中使用的机器学习模块的训练系统、相关方法、计算机程序单元和计算机可读介质。
12.根据本发明的第一方面,提供一种用于核医学成像的数据处理系统,包括:
[0013]-输入接口,用于接收第一投影数据或可根据第一投影数据重建的第一图像,并且,第一投影数据与第一等待期相关联,所述第一等待期指示从示踪剂的施用到核医学成像设备开始采集投影数据的时间段;以及
[0014]-预先训练过的(“预训练”)的机器学习模块,其被配置为基于第一投影数据或第一图像来预测或估计可与比第一等待期长的第二等待期相关联的第二投影数据或第二图像。
[0015]
一种用于核医学成像的数据处理系统,包括:
[0016]-输入接口,用于接收第一投影数据或可根据第一投影数据重建的第一图像,并且,第一投影数据与用于由核医学成像设备采集关于掺入了示踪剂的患者的投影数据的第一采集时间段相关联;以及
[0017]-训练过的机器学习模块,其被配置为基于第一投影数据或第一图像预测或估计可与比第一采集时间段长的第二采集时间段相关联的第二投影数据或第二图像。在实施例中,第二等待期或第二采集时间段由示踪剂的类型规定。
[0018]
在另一方面,提供一种用于核医学成像的数据处理系统,包括:
[0019]-迭代图像重建器,用于根据由核医学成像设备采集的投影数据在给定迭代步骤(i)中重建第一图像;以及
[0020]-训练过的机器学习模块,其被配置为基于第一图像预测或估计第二图像,迭代重建器随后基于第二图像在下一个迭代步骤中重建下一个图像。根据上述系统中的任一个或两个,在缩短的扫描或等待时间中可以已经获得了用于机器学习模块的这种内部重建应用的投影数据,每个系统可以使用分别训练过的机器学习模块。
[0021]
在实施例中,上述实施例或方面中的任何一个中的系统包括采样器,所述第一图像或投影数据是由采样器从相应超集采样的相应图像或投影数据的超集的一部分,和/或其中,所述预测的第二图像或第二投影数据形成可由图像汇编器(assembler)汇编的相应超集的部分。
[0022]
在实施例中,核医学成像设备被配置为用于pet和spect成像中的任何一个。
[0023]
在另一方面,设想了一种训练系统,其被配置为基于训练数据来训练用于核成像的机器学习模块,以获得在上述系统中的任何一个中使用的预训练的机器学习模块。
[0024]
一种用于核成像的数据处理方法,包括:
[0025]-接收第一投影数据或可根据第一投影数据重建的第一图像,并且第一投影数据与第一等待期相关联,所述第一等待期指示从示踪剂的施用到核医学成像设备开始采集投影数据的时间段;并且
[0026]-由训练过的机器学习模块处理第一投影数据或第一图像,以预测或估计可与比第一等待期长的第二等待期相关联的第二投影数据或第二图像。
[0027]
在另一方面,提供一种用于核成像的数据处理方法,包括:
[0028]-接收第一投影数据或可根据第一投影数据重建的第一图像,并且第一投影数据与用于由核医学成像设备采集关于掺入了示踪剂的患者的投影数据的第一采集时间段相关联;并且
[0029]-由训练过的机器学习模块处理第一投影数据或第一图像,以预测或估计可与比第一采集时间段长的第二采集时间段相关联的第二投影数据或第二图像。
[0030]
在又一方面,提供一种用于核成像的数据处理方法,包括:
[0031]-根据由核医学成像设备采集的投影数据在给定迭代步骤中重建第一图像;
[0032]-由训练过的机器学习模块处理第一图像,以预测或估计第二图像;并且
[0033]-基于第二图像在下一个迭代步骤中重建下一个图像。
[0034]
在另一方面,提供一种训练方法,用于基于训练数据来训练用于核成像的机器学习模块,以获得在上述方法中的任何一种中使用的预训练的机器学习模块。
[0035]
在另一方面,提供了一种获取(procuring)用于训练用于核成像的机器学习模块的训练数据的方法,训练数据是基于i)历史动态pet投影数据,或ii)下采样的历史投影数据。
[0036]
在又一方面,提供一种成像装置,包括如上述实施例或方面中的任一个所述的核成像设备和系统。
[0037]
所提出的系统和方法允许显著缩短涉及核医学成像的时间段,具体地显著缩短扫描时间和/或prost示踪剂施用等待时间,以改善患者舒适度和成像吞吐量。这对于需要应对人口老龄化和不健康生活方式增加的世界范围内的繁忙且紧张的国家卫生设施尤其有益。还能够减少重建时间。
[0038]
换言之,所提出的机器学习模块允许实施加速的核医学协议。所提出的机器学习模块允许从早期影像或早期投影数据估计后期影像或后期投影数据,从而消除了对于传统上较长时间段的需要。所估计的影像允许临床医生确定如果较长的患者等待期或采集期已经耗尽,图像会是什么样子。此外,或者替代地,能够缩短重建时间段。能够避免迭代重建算法陷入局部极小值的可能性,从而改善图像质量。
[0039]
在另一方面,提供一种计算机程序单元,当由至少一个处理单元执行时,所述计算机程序元素适于使处理单元执行根据上述实施例中的任何一个的方法。
[0040]
在又一方面,提供一种其上存储有程序元素的计算机可读介质。
[0041]
定义
[0042]“用户”是指操作成像装置或监督成像过程的人员,如医务人员或其他人员。换言之,用户通常不是患者。
[0043]
总体上,“机器学习模块”是一种计算机化的装置,它实施被配置为执行任务的机器学习(“ml”)算法。机器学习算法可以基于机器学习“模型”。在ml算法中,在已经提供了具有更多(新的)训练数据或足够的方差的装置后,任务性能显著改善。当向系统馈送测试数据时,可以通过客观测试来测量性能。性能可以根据给定测试数据要达到的特定错误率来定义。参见例如t.m.mitchell的“machine learning”(mcgraw-hill,1997年,第2页,第1.1节)。
[0044]
本文使用的“投影数据”是在pet检测器(投影域)处检测到的(原始)数据,其能够
通过重建算法转换为图像域中的发射影像。投影数据可以以列表模式或正弦图模式表示。列表模式能够转换为正弦图模式,例如通过重新分箱(rebinning)程序。
[0045]
本文使用的“早期数据”和“后期数据”包括以下内容:早期数据包括早期发射投影数据或早期发射影像。早期发射影像是可从早期发射投影数据重建的图像域中的影像。早期发射投影数据是在缩短的示踪剂施用后等待时间之后采集的,或者利用缩短的采集时间段采集的投影数据。缩短的时间段短于“后期”数据中使用的较长时间段。
[0046]
具体地,与早期数据相反的后期数据包括后期发射投影数据和/或可根据后期发射投影图像数据重建的后期发射影像。
[0047]
早期/后期数据还包括迭代重建期间产生的(中间)影像,其中,“早期”/“后期”与可获得相应(中间)图像的重建周期/步骤有关。重建周期/步骤可以表示收敛状态。
附图说明
[0048]
现在将参考以下附图描述本发明的范例性实施例,除非另有说明,否则这些附图并非按比例绘制的,其中:
[0049]
现在将参考以下附图描述本发明的范例性实施例,其中:
[0050]
图1a示出了包括核成像设备的核成像装置的框图;
[0051]
图1b示出了核成像协议中涉及的时间段的时间线;
[0052]
图2-9示出了不同实施例中用于支持核成像的系统的框图;
[0053]
图10示出了机器学习模型的框图;
[0054]
图11示出了用于训练机器学习模型的训练系统;
[0055]
图12-14示出了根据不同实施例的用于支持核成像的方法的流程图;以及
[0056]
图15示出了用于训练机器学习模型的方法的流程图。
具体实施方式
[0057]
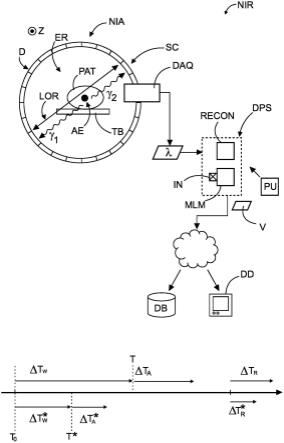
参考图1a,示出了核医学成像装置nir的示意性框图。
[0058]
装置nir包括核成像设备nia和数据处理部分dps。广义地说,核成像设备nia将能够在数据处理部分dps中处理的发射投影数据λ输出到能够存储在his(医院信息系统)或任何其他存储器db中的诸如pacs(图片存档和通信系统)的数据库中的发射图像v中。发射影像可以在显示设备dd上可视化或能够其他方式被处理。发射投影数据λ能够通过从成像设备mia到数据处理部分dps的有线或无线连接来提供。
[0059]
广义地说,本文提出一种新颖的数据处理部分dps,其允许缩短核成像(本文也称为发射成像)中涉及的某些时间段。数据处理部分因此被配置为用于加速后的核成像。数据处理部分dps包括实施pet/spect重建算法的重建器组件recon。重建算法允许根据投影原始数据λ计算期望的发射影像。为了实现加速后的发射成像协议,重建器recon与对历史或合成的训练数据进行过预训练的机器学习模块mlm协同操作。机器学习模块mlm是被布置在硬件或软件中或者部分布置在硬件和软件中的计算实体,其将预先训练过的机器学习模型应用于输入数据。新颖的处理部分dps的操作,具体地是重建器recon与机器学习模块mlm之间的协同操作将在下文中进行更全面的探讨。
[0060]
现在首先更详细地解释核成像设备nia的操作,现在参考pet成像器。然而,本文中
还设想了诸如spect或平面闪烁成像的其他核成像或发射成像模式,并且本文中要描述的原理也适用于此类其他发射成像模式。
[0061]
pet成像器nia通常(但不一定)与mri成像器或计算机断层摄影扫描器ct串联布置。mri或ct提供有关解剖结构的结构性信息,而pet成像器提供功能性信息,包括例如器官活动。
[0062]
广义地说,pet成像器nia包括机架,在机架中,围绕中空检查区域er布置环形检测器单元d。环形检测器单元d形成成像器nia的孔。环形探测器单元d包括环形闪烁体sc。在成像之前,向患者pat施用放射性示踪物质(示踪剂)。该物质包括适当的放射性核素。所施用的物质分布在患者体内。患者被要求躺在检查台tb上。如图1a中的侧视图所示,有患者pat在上面的工作台tb滑入检查区域er,以便至少感兴趣解剖结构(roi)现在部分或完全被闪烁体sc环所包围。患者pat的纵轴延伸到孔中,并与成像轴z对齐。成像轴z垂直延伸到图1a的绘图平面中。闪烁体环sc(其中可以有多个闪烁体环沿着z轴一个接一个地布置)本质上是伽马照相机。
[0063]
在全身(“tb”)配置中,孔可以具有沿成像轴z的长度,以同时环绕整个患者。然而,在所有实施例中,不一定需要全身配置,还设想了一次仅覆盖患者的纵向截面的标准孔长度。在具有标准孔长度的成像器中,为了仍然执行全身采集协议,在成像期间可能存在于闪烁体环sc和检查台之间的沿z轴的相对平移运动。tb型配置中不需要这种运动。在使用中,在“扫描”期间(本文也称为采集期),闪烁体环sc能够检测由示踪剂引起的伽马辐射。伽马辐射被检测单元d检测为发射预测数据。发射预测数据可以由重建器recon重建为3d发射影像。在扫描期间,如由不同协议和成像目标所要求的,可能存在或不存在所述平移运动。
[0064]
更详细地说,施用和累积的放射性核素在一定时间后解体,以产生衰变事件。这种衰变事件导致正电子发射。正电子产生后,通常短距离行进,然后与周围的患者组织相互作用。更具体地,正电子在某个位置处与遇到的患者组织中的电子发生碰撞。这种碰撞导致所述患者内位置处的湮灭事件ae。两个相互碰撞的基本粒子(正电子和电子)的湮灭继而产生了一对γ光子,在本文中称为γ1、γ2或“伽马”,或其中一个的“伽马”。已知这些γ光子的能量值为511kev。每对γ光子以180
°
的相反方向,从产生位置ae向闪烁体环sc的不同(直径位置的)部分行进,然后入射到闪烁体环上。
[0065]
闪烁体环sc包括在环中连续布置的晶体块。闪烁体sc的晶体块被耦合到一组光电二极管,并形成成像器的数据采集系统daq的部分。
[0066]
晶体块被耦合到相应的光电二极管。每个晶体元件与其空间上关联的一个或多个光电二极管一起形成相应的检测器元件。检测器元件的光电二极管被耦合到其他电路,例如位置解算器pr电路和定时电路tc,这两个电路将在下面进一步详细讨论。
[0067]
现在首先回去更详细地谈谈γ光子,如上所述,这些光子入射到闪烁体环sc的直径相对的晶体块上,并引起光线光子释放。光学光子由被耦合到受影响的晶体元件的光电二极管配准。
[0068]
光电二极管通过输出相关电信号(例如电压或电流)来响应光线光子。
[0069]
闪烁体环sc中的每个晶体块能够由唯一的位置指示器x来索引。这种位置指示器x随后也是检测器元件之一,具体地被耦合到相应晶体的光电二极管之一。
[0070]
由伽马激活的探测器元件的相应组因此可以由用于每个伽马的指数(xj)的列表
来表征。对于每对伽马都有两个这样的列表。
[0071]
现在更详细地说说位置解算器电路,这可以包括anger逻辑或单个处理单元或其他。位置解算器电路pr接收由激活的光电二极管检测到的电信号。位置解算器电路pr基于激活的光电二极管的列表提供出现第一次事件时索引p的估计值x。位置解算器为一对伽马光子γ1、γ2中的每一个分配针对激活的晶体块的相应位置估计值x1、x2。估计的位置x1、x2大致沿直径位于闪烁体环sc的区域er上。
[0072]
如从上文可理解的,一对两个伽马光子γ1、γ2中的每一个都将产生相应的检测事件。检测事件包括由相应的响应光电二极管phd产生的电信号。这两个探测事件需要相互关联,以便两个伽马光子γ1、γ2能够被识别为构成由同一湮灭事件引起的一对。这种关联是基于时间的,并且由定时电路tc完成。大致相同时间出现达到特定时间限额的检测事件由定时电路tc配准为针对单个湮灭事件的一对光子的定时电路光子γ1、γ2的共同伴随和组成检测事件。一旦被定时电路tc识别为一对,由位置解算器pr提供的它们相应的估计的碰撞位置x1、x2就构成了每对响应线lor。lor形成连接第一次相互作用的两个位置x1、x2的几何线。两个位置x1、x2还确定了撞击的方向,该方向能够通过在仰角和方位角上的针对每个伽马的角度坐标ф、θ来量化。
[0073]
总之,由数据采集部分daq提供的发射投影(原始)数据λ表示重合事件。每个这样的事件是由闪烁体环sc的一对相对的晶体块部分对光子伽马1、伽马2的近乎同时的(在大约6-12纳秒的适用时间窗口内)检测。每个这样的重合事件因此定义相应的lor。
[0074]
本文设想了测量出的投影原始数据λ的不同表示,包括列表模式和正弦图模式。然而,列表模式格式是优选的,因为正弦图模式数据能够通过重新分箱从列表模式数据转换而来。在列表模式中,所采集的原始数据被组织为列表中的条目,每个条目包括数据部分,所述数据部分可以指定在给定检测器部分处的窗口内检测到的计数的数量、检测到计数的检测器sc环的部分的坐标、角度数据、时间戳等。通过重新分箱,即,通过组织列表模式数据获得每个lor角度的空间分辨数据,从列表模式数据获得正弦图数据。
[0075]
继续参考图1a,新颖的数据处理部分dps的重建器recon能够理解为从投影域到图像域的映射。投影域位于定义投影数据的检测器单元d处。相反,图像域位于检查区域er中,并且能够由体素位置的空间3d网格来定义。重建器recon是被布置在硬件或软件中或部分布置在硬件和软件中的实施重建算法的计算模块,利用基于投影数据λ的图像值充满体素位置,从而构建发射图像。重建器recon能够分析地实施,也能够迭代地实施,这将在下面进行更充分的探讨。还设想了基于机器学习的重建器recon。
[0076]
现在参考图1b,图1b示出了时间图,以说明在发射成像中,具体地在pet或spect中涉及的三个时间段。所提出的机器学习模块mlm被配置为帮助减少所述时间段中的任意一个、任意两个或全部三个,从而加速从采集投影数据到对于用户(例如,临床医生)可用于诊断、治疗、教育或任何其他目的准备查看发射影像的时间点所需的总时间。
[0077]
广义上说,在发射成像中,人们可以在时间上以这种顺序区分以下三个阶段:准备阶段、采集阶段和重建阶段。准备阶段开始于患者pat被施用示踪剂的时间点t0,所述示踪剂供应随后可由检测器检测的辐射源。本文设想了一系列示踪剂。这些示踪剂中的每一种都具有不同的性质,并且可以用于不同的成像目的。示踪剂是放射性核素和感兴趣器官使用的化合物(如糖或其他物质)的组合。示踪剂的范例包括氟脱氧葡萄糖
fluorodeoxyglucose[
18
f]fdg或其他种类的示踪剂。就目前的目的而言,示踪剂还包括放射性配体,其是包括被放射性标记过的配体的生化物质。放射性配体被设计为与特定受体结合,从而能够对生化途径的特定功能方面进行成像。备选地,放射性配体可以设计成在感兴趣代谢过程中替代(非放射性标记的)化合物/分子。
[0078]
在时间t0处施用后,随后(通常是立即,不一定是之后)有一个等待期δtw,其中患者被要求等待,以便示踪剂能够随着患者体内的血流分布累积在目标器官或一组感兴趣器官处。该等待时间能够是相当长的,例如60分钟或更长。
[0079]
总体上,等待期是示踪剂在总体上的平均动力学的函数。示踪剂分布的动力学大致如下。在向患者的血液池中施用预定类型和预定量的示踪剂(这可以取决于患者的生物特征和感兴趣器官)之后,示踪剂随着血流行进并开始在感兴趣器官处累积。示踪剂开始从血池中清除,并以一定的摄取率灌注到感兴趣器官中。理想情况下,这种摄取率高于血液和周围组织以及不感兴趣器官。灌注以及因此在感兴趣器官中的示踪剂浓度,在倾斜上升相位上增加,并且在某一点上趋于平稳,然后最终下降。常规上,等待期是与在感兴趣器官中开始示踪剂的灌注一样长。为了获得最佳结果,一旦在灌注阶段感兴趣器官中的示踪剂的浓度趋于稳定,等待期到期。这种稳定阶段本文中可称为饱和期。在某些情况下,可能存在定义最佳扫描点的稳定之外的其他因素。例如,如果放射性配体是受体结合的,那么能够通过用放射性示踪剂充满血液很快地占据有限数量的可用受体。假设这些结合体不再被释放,通常优选等待开始采集,洗出的进度足以为背景对比提供足够的特征。
[0080]
等待期δtw结束后,跟进采集时间段δta,但不一定在开始时间t(时间点)立即跟进。在采集时间段δta期间,患者位于检查区域,并且检测器d的读出电路能够收集计数数据,即投影数据λ。在这段时间之后,可以立即跟进,也可以不立即跟进,能够由重建器recon重建如此收集的投影数据λ。重建操作(计算任务)可能消耗时间段δtr,在时间段δtr结束时,发射影像是可用的,然后能够显示、存储或以其他方式处理发射影像。
[0081]
可以看出,上述时间驱动协议产生了与时间段相关联的各种数据。例如,投影数据能够被认为是与采集时间段相关联。不同长度的采集时间段dta将产生不同质量的投影数据。更具体地,采集时间段越长,所收集的投影数据中的噪声水平总体上越低。总体上,投影数据λ能够被认为是由叠加了噪声贡献的地面实况(ground truth)信号构成的。采集时间越长,噪声贡献越小,即信噪比(snr)越高。在这一方面,采集周期越长,在图像域中获得所需影像花费的时间就越长。
[0082]
在另一方面,投影数据也能够说是与等待期的长度相关联。同样,直到饱和阶段开始的等待时间越长,在扫描中可获得的投影数据的质量总体上越好,因为更多的造影剂已经累积在感兴趣部位。但是同样,这也是有时间成本的。
[0083]
虽然能够针对重建阶段定义另一种数据与时间的关联性。例如,具体地,对于在图像域中开始以进行到最终输出图像的迭代重建器,可能需要多次迭代以实现可接受的收敛,并且因此实现其输出图像的图像质量。总体上,允许重建算法运行的时间越长,执行的迭代次数越多,并且(最终)输出图像的图像质量越好。因此,能够说输出影像与重建时间段的长度相关联。
[0084]
所提出的机器学习模块允许缩短上述定义的三个时间段δtw、δta和δtr中的任意一个、任意两个或优选全部三个时间段。上述时间段中的任何一个时间段能够相应地利
用早期采集开始时间t*(另一时间点)缩短为δt*、δta*和δtr*,如图1b所示。因此,利用新提出的机器学习模块mlm,能够将到达图像域中的期望的发射影像的总时间缩短高达50%或者甚至更多。
[0085]
具体而言,机器学习模块允许将患者的等待时间缩短到缩短的等待时间δtw*,这与大约60分钟的完全等待时间相比可以少到15或20分钟。完全等待时间总体上是所使用的示踪剂类型的函数,也可以取决于患者的某些生物特征,如年龄、性别、体重、病史等。常规上,等待时间通常由协议规定,以实现良好的图像质量,如高snr、高对比度等。然而,利用所提出的机器学习模块,能够缩短等待时间,因为患者在更短的等待时间或缩短的等待时间段δt*之后被允许进入采集时间段。机器学习模块被配置为将与缩短的等待时间相关联的早期投影数据映射到表示后期投影数据的近似的另一个投影数据集。在本文中,后期投影数据涉及,如果如用于所述患者类型和/或所使用的示踪剂的常规规定那样,完全等待期δtw已经耗尽的话将获得的投影数据。
[0086]
除了或替代等待时间缩短,还能够以这种方式缩短采集时间,并且机器学习组件或类似的机器学习组件将在缩短的采集时间段δta期间采集的这种早期投影数据映射到表示后期投影数据的另一投影数据集。如果患者在检查区域停留更长的规定的时间段δta,将可获得后期预测数据。同样,该采集时间段总体上是针对所使用的示踪剂类型和/或患者的生物特征而规定的。
[0087]
在所提出的机器学习模块的另一个应用场景中,这能够与迭代类型的重建器结合使用,以缩短重建δtr。更具体地,由重建器在i次迭代循环的过程中产生的中间影像由机器学习模块映射到不同版本的中间影像中。不同版本是对将在更多的迭代循环j》i之后已经可以获得的中间影像的估计。机器学习模块因此允许跨越计算成本高昂的迭代循环|j-i|。在本实施例中提出的机器学习模块可以因此被理解为“迭代助推器”。中间影像的新版本可以随后反馈到重建器recon中,以继续迭代循环。所提出的机器学习模块允许缩短重建时间,但也可以帮助避免可被公式化为优化问题的潜在的重建算法陷入到在优化中使用的目标函数的局部最小值中。这种局部最小值陷阱可能会导致不真实的图像。
[0088]
为了使机器学习模块mlm实现相应时间段的上述缩短,在训练数据上适当地训练机器学习模块,这将在下面更详细地解释。机器学习模块在训练期间学习在甚至是有噪声的投影数据或影像中拾取足够的对比度,从而以更高的信噪比充分逼近图像信号,这在常规上导致更长的时间段,如图1b所示。虽然可以使用单个机器学习模块来实现所有三个时间段的缩短,但这在本文中是没有必要的,可以训练和使用、定制相应的专用机器学习模块来缩短三个时间段中相应的一个。
[0089]
与缩短的等待时间和/或缩短的采集时间相关联的投影数据在本文中将被称为早期投影数据,而不是与相应的较长时间段相关联的后期投影数据。该术语延续到图像域中,以定义可根据早期投影数据重建的早期成像器,以及可从后期投影数据重建的后期成像器。因此,所提出的机器学习模块允许从早期投影数据/早期影像足够逼近地计算后期投影数据/后期影像,如果已经观察了常规的较长的时间段,将可获得所述后期投影数据/后期影像。类似的概念适用于迭代循环,其中能够由机器学习模块从在重建迭代过程中产生的早期中间影像(处于早期循环i)估计更多的后期中间影像(处于后期循环j)。
[0090]
本文提出的机器学习方法在概念上可以理解为:在早期投影数据/早期重建和后
期投影数据/后期重建之间,以及相应地在重建迭代背景下的早期中间影像和后期中间影像之间,存在潜藏的潜在的“未知的”映射。机器学习模块能够从适当定义的训练数据范例中学习这些潜在的映射。在训练期间,基于训练数据适配机器学习模块的初始模型的参数,这将在下面更详细地描述。
[0091]
所设想的训练数据可以包括从历史记录获得的或适当合成的范例影像或范例投影数据。此外,训练数据可以可选地包括非图像类型的情境(contextual)数据cxd,其描述所使用的示踪剂的类型和/或患者的生物特征,如年龄、性别、体重、病史等。
[0092]
看来尽管snr较低,但所提出的机器学习方法已经允许从早期数据中拾取后期数据。具体地,在倾斜上升阶段,看上去已经存在由放射线示踪剂发射的足够的辐射。因此,利用机器学习,无需如传统协议指令的那样等待饱和阶段才开始。利用机器学习,采集期能够因此更早地开始,并且甚至可以被缩短。假设在缩短的等待时间δtw之后采集的数据中已经充分存在所想要的结构信息。由于在倾斜上升阶段期间血液池清除不完全,有用的结构数据看起来仅被当前背景信号部分掩蔽。所提出的机器学习方法有助于减少这种掩蔽效应,以从掩蔽的数据中恢复未掩蔽的、后期数据的适当估计。类似地,看起来机器学习方法可以从i)比先前使用的采集周期更短的早期、低snr投影数据中,或从ii)图像域中的中间影像中拾取足够的结构图案,甚至在通常使用的迭代次数更少之后。
[0093]
机器学习模块的训练发生在预备训练阶段,其中调整初始化模型以获得预训练的机器学习模块。在训练之后,在部署阶段,充分预训练的机器学习模块可以随后用于在临床使用期间计算上述数据。
[0094]
下文将更详细地描述训练阶段和部署阶段。机器学习模块能够在投影域或图像域中使用。因此,相对于由重建器recon实施的重建时期,可以在预处理时期或后处理时期使用机器学习模块。此外,机器学习模块还可以在重建过程内的内部处理实施例中使用,以减少迭代循环并因此缩短重建时间。
[0095]
现在将首先参考图2-5中的部署阶段更详细地描述后处理、预处理和内部处理实施例,其中假设机器学习模型已经基于训练数据被充分训练为预训练的学习模块mlm。图6-9更详细地探讨了学习阶段。
[0096]
现在首先转到部署阶段,现在参考图2,其示出了数据处理部分dps,其具有被配置为用于等待时间缩短的预训练的机器学习模块。广义地说,预训练的机器学习模块mlm将从缩短的等待时间δta*之后采集的早期投影重建的pet投影数据作为输入,并预测用于后期发射图像v’的估计值。预测的后期发射图像v’被预期近似地匹配活动分布对比度,如果完整的等待期与(后期)标准开始时间t一起使用,所述活动分布对比度将是已经可通过从后期可采集的投影数据重建实现的。预训练的机器学习模块mlm因此校正对比度图案中的典型动态变化以及噪声属性和图像清晰度中的变化,从而使得根据估计的图像v’的单个示踪剂分布的结果可视化很好地近似匹配当前建立的医学标准。
[0097]
继续参考图2,在部署后学习中,在早期开始时间t*处在缩短的等待时间δtw*之后,采集(0)早期投影数据(例如,在pet列表模式下)。早期投影数据被馈送(8)到pet重建模块recon以获得早期发射影像。重建的早期图像表示空间活动分布。可选地,将早期投影数据存储在专利数据库pdb或另一合适的存储器中。可选地,如也可以在训练阶段中所做的那样(下文将进一步讨论),重建的早期pet影像由采样器smp以子集(本文中称为“补丁”)进
行子采样(9)。补丁优选地具有与训练阶段相同的大小。补丁被馈送(10)到机器学习模块mlm中,并被单独转换为补丁(11),其利用在t处开始的后期/标准采集基于在完全等待时间之后采集的投影数据估计用于后期影像的这种补丁。然后由汇编器asb根据其原始位置重新汇编(12)所估计的补丁,以形成可以用于临床诊断的估计的后期3d发射图像v’。在图2以及下面的图中,位置由位置索引“p”索引,符号(p,t,k)指示用于时间“t”的位置“p”处的补丁“k”是为了便于检索的用于数据库存储的可选索引。
[0098]
图2中的机器学习模块mlm在图像域中进行操作,作为后处理器进行后重建。在图2中的后处理实施例的变体中,机器学习模块mlm可以在投影域中进行操作。在这种预处理实施例中,机器学习模块mlm已被预训练为从与示踪剂施用之后的缩短的等待时间段相关联的投影数据中预测与完全等待时间段相关联的后期投影数据。重建器recon随后使用对后期投影数据的估计来重建后期图像v’。采样器/汇编器设置同样是可选的,并且在图3-11中的所有下述实施例中也是可选的。
[0099]
现在参考图3,其示出了系统的框图,所述系统包括机器学习模块mlm的后处理实施例,所述机器学习模块mlm预训练为基于以缩短的采集时间采集的早期投影数据来处理早期pet图像。
[0100]
更详细地,以更短的扫描持续时间采集关于患者的投影数据(例如,在pet列表模式或正弦图模式下),并且将如此获得的早期投影数据馈送(1)到pet重建器recon中。可选地,数据存储在患者数据库dbd中。早期的并且因此有噪声的重建的pet图像可选地由采样器smp在优选地具有与训练步骤中相同大小的补丁中进行子采样(参见下图)。通过训练的ann将补丁单独地转换成补丁估计值所述补丁估计值近似于在标准扫描时间(13)从后期投影数据可获得的图像信息。估计值由汇编器asb重新汇编,形成可用于临床诊断或其他用途的最终的3d图像v’。
[0101]
现在参考图4,其用作机器学习模块mlm在投影域中进行操作的预处理器。以更短的扫描持续时间采集患者投影数据(例如,以pet列表模式格式),然后将其馈送到可选的pet重排模块pp,以将投影数据转换为pet正弦图格式(10)。由于缩短的采集时间,有噪声的pet正弦图(11)可选地以补丁进行子采样,优选地具有与训练阶段中使用的相同大小。补丁由预训练的机器学习模块mlm单独转换为与标准采集扫描时间段(13)相关联的补丁估计值估计的补丁由汇编器asb重新汇编,以形成用于完整pet正弦图(14)λ’的估计值。重建器recon可以使用估计的后期正弦图来重建与用于临床诊断的标准扫描时间相关联的输出3d pet图像v’。重新分箱器pp是可选的,机器学习模块mlm可以在列表模式下对投影数据λ进行操作。
[0102]
现在参考图5中的系统,其中预训练的机器学习模块mlm被配置为用于与重建器recon协同进行内部处理,以将重建时间缩短到缩短的时间段
[0103]
以更短的扫描持续时间或标准采集时间采集患者投影数据λ(例如,在pet列表模式下)。然后将投影数据馈送到pet重建(9)中,所述pet重建优选为迭代类型。在迭代pet重建循环期间的每个或每k》1次之后,或者实际上在随机选择的迭代步骤(10)中,在给定的迭代步骤(11)中可用的中间pet图像可选地被子采样为补丁优选地具有与训练阶段中相同的大小。通过训练的ann将补丁单独转换为补丁估计值所述补丁估计值表示与后期迭
代步骤相关联的图像信息(13)。在估计的补丁中,图像信息能够因此表示更完全积聚的图像信息。由asb重新汇编补丁,以形成新的中间3d pet图像v’(14),其可以由重建器recon使用,用于下一次或多次迭代(15),或者,如果满足停止条件,则中间图像v’可以作为用于临床诊断或其他应用的最终输出提供。
[0104]
参考图6-9,现在将更详细地描述上述图2-5中的系统的训练阶段。训练阶段在相应的训练系统ts上实施。通过基于训练数据适配机器学习模型m的计算机化训练系统ts来获得相应训练的机器学习模块mlm。训练系统的总体设置以及如何核对合适的训练数据将在图6-9中描述。机器学习模型(优选人工神经网络类型的)和训练算法将在图10、11和15中详细描述。
[0105]
更一般地说,通过使用如本文所述的实施例中的到补丁中的子采样,机器学习模块mlm可以操作为提供更好的、更稳健的噪声降低,因为本文所使用的早期图像/投影数据或缩短的等待期投影数据/影像总体上是具有低snr的高噪声的。
[0106]
然而,对于早期图像/投影数据,与对于缩短的等待期投影数据/影像相比,优选不同地选择补丁大小。例如,在早期图像/投影数据实施例中,补丁大小被选择得足够小,以使机器学习模块mlm成为“解剖结构不可知的”。解剖学上不可知论防止在训练和推理期间由网络mlm检测到大量解剖特征,并将网络mlm的学习和推理能力集中在不受实际解剖结构影响的噪声降低上。否则,如果没有所述解剖结构不可知的特性,网络可能在存在病理或非典型解剖结构的情况下表现得不可预测。然而,在用于等待期缩短的实施例中,优选不将补丁大小选择得太小。网络应当优选不要变成解剖结构不可知的。具体地,在用于等待期缩短的实施例中,由于示踪剂的行为、其累积和倾斜上升等对于不同的器官/组织类型是不同的,因此优选机器学习模块应当知道解剖背景。如果是可选的,则对补丁进行子采样,并且在用于等待期缩短的实施例中,可以具体地完全忽略。
[0107]
现在首先转到图6,其示出了用于训练如在图2中使用的用于机器学习模块mlm的训练模型m的训练系统ts。附图进一步描述了在实施例中如何采集训练数据。
[0108]
现在首先谈及训练数据取得。对于给定患者,为了训练初始化模型m,可以使用在两个不同的采集开始时间(t,t*)处以及因此针对两个不同等待时间段采集的原始患者投影数据λ。在实施例中,模型是具有一组预加载的初始参数(也称为权重)的人工神经网络。用于在设定时间t*和t上的两次不同采集的历史数据集可以作为针对给定患者的成对数据从患者研究数据库中检索。可以从保存在pacs或其他医学数据存储库中的历史数据中获得训练数据。可以假设用于t*、t的两个数据集的采集时间段相等,但在本文中并非限制于此,因为不同持续时间δta和δta*的采集时间段可以替代用于训练数据。图6中的相应投影数据分别指示为λ[δta]和λ[δta*]。采集期可能是标准采集期。
[0109]
为了在初始训练阶段实现更高的灵活性,可以从pacs或其他医学数据存储库中检索执行动态pet扫描的历史研究成果。在这种类型的pet协议中,在整个采集期间多次采集成像器孔内的某些或每种床位(沿着患者的纵轴z)的投影数据,从而自动产生在不同的起始时间t*和t处采集的投影数据。具体地,在动态pet中,采集基本上在示踪剂使用之后立即开始,以采集投影数据(优选地以列表模式),从中能够重建每个体素的辐射对时间曲线。所述曲线也称为“时间-活动曲线”(tac)。因此,通过将早期数据(图像或保护数据)与后期数据(图像或者投影数据)配对以形成训练数据对,包括相应的成对的训练输入及其相关联目
标,能够从动态pet数据中取得训练数据。以下将更详细地解释训练方面。
[0110]
在tb扫描中,历史pet数据可以与不同的床位有关。用于不同开始时间的数据可能不一定代表相同的解剖结构。通过基于解剖结构对抗策略训练模型m,如所提及的对来自训练数据的补丁的采样,可以消除这种潜在问题。因此,学习能够更好地关于不同的噪声图案,而不是解剖结构的细节。以这种方式,可以利用更大的训练数据池。
[0111]
优选地,全身pet扫描器可以用于以列表或正弦图模式具体地采集动态pet投影数据λ,所述列表或正弦图模式在示踪剂注射后的例如15-90分钟的长采集时间段内覆盖大fov。通过使用动态扩展的pet原始数据,可以稍后决定合适的t*选择,或者用依赖于t*的训练数据训练若干网络模型m。通过这样做,不需要精确地知道t*,这简化了临床常规,例如,如果不能在t*=15分钟之后执行患者扫描,仅替代地在例如t*=30分钟之后执行患者扫描。但是,本文中不一定需要全身pet设置,并且动态pet采集可以实际上用具有不沿图像轴z覆盖整个患者的标准孔的扫描器来代替。总体上,在动态采集协议中,与标准(非动态)协议中每种床位的单个静态pet图像相反,通过获得重建的pet图像的时间序列,能够确认示踪剂在体内是如何分布的。
[0112]
现在涉及训练过程,作为模型m训练的初始步骤,通过采样器smp将所识别的历史患者数据采样到先前提到的空间子样本或“补丁”中。在本实施例中,如上所示,补丁大小优选地选择为使得其保留所选区域的解剖背景,因为这对于学习期间的正确的对比度调整是有用的。备选地,在等待时间缩短的实施例中不使用采样到补丁中。
[0113]
作为使用采样的范例,继续参考图6,对于给定的患者,从患者研究数据库(1)中检索在t处采集的数据集并对其进行重建(2)。随后,从得到的重建影像导出补丁,并将其存储(3)到补丁数据库mem中。类似地处理(4、5、6)在t*处采集的数据。以允许针对每个患者研究检索用于相同空间位置的匹配补丁对的方式来组织补丁数据库mem。
[0114]
在训练过程中,模型m(例如多层卷积神经网络)被提供有成对的随机t*-补丁作为输入,并将所链接的t-补丁作为预测目标。所得到的预测误差由目标函数f量化。可以使用诸如反向传播的学习策略来改进目标函数,具体地,改进关于预测目标的模型m的精确度以及由模型m为当前参数集提供的估计值。使用多个,例如所有可用的补丁对继续模型m的训练,直到实现停止传导(stopping conduction),例如直到达到某一总体预测质量水平。通过基于从历史动态pet数据中进行选择使用上述训练数据获取,能够基于来自单个患者的投影数据来训练模型m。基于动态pet协议的上述训练数据集获取对于使用全身pet的成像器是不必要的。
[0115]
此外,对于本文所设想的所有实施例,对动态pet的依赖不是必需的,而是可以替代使用来自标准pet的投影数据。此外,可以使用来自多个患者的数据替代来自单个患者的数据。可以在医学数据存储库中适当地查询数据,以定位从在不同开始时间处采集的投影数据重建的历史图像。
[0116]
不同于基于在图像域中的重建影像训练模型m,可以将图6中的相同训练方案替代地应用于投影域中的投影数据。
[0117]
现在参考图7,其示出了用于训练模型m的训练系统ts的示意图,所述模型m是如在图3的用于采集时间缩短的机器学习模块mlm中所使用的模型m。
[0118]
具体地,(1)通过患者研究数据库中(例如pacs中)的适当数据库搜索/查询来定位
历史患者数据,如pet列表模式数据中的投影数据或重建的pet影像。
[0119]
作为用于模型m的训练的准备,从数据库中检索投影数据(例如,以列表模式格式),并由下采样器ds进行下采样。例如,创建多个副本,其中,事件条目的数量(4)显著减少。这能够例如通过利用预定义的采样概率集进行随机采样来实现,或者,次优选地,通过确定性采样,例如通过删除每个第k个条目,k>1来实现。
[0120]
下采样列表模式文件被重建为pet图像,其表示更短的采集持续时间δta*:δt1、δt2、
…
、δtn(5)。可选地,如在上述实施例中那样,使用解剖结构不可知方案。例如,使用采样器smp设置。例如,基于重建影像,导出k个空间补丁并将其存储在补丁数据库pdb(7)中。类似地,从原始影像创建来自完全相同的空间子体积的k个补丁并且也存储在相同(或不同)的补丁数据库(8)中。然后,针对同一空间位置的两个补丁定义训练数据对。
[0121]
在训练过程中,使用中的模型m被提供有作为训练输入的一些表示较短采集持续时间δta*的补丁来自原始(完整数据集)重建(9)的空间上匹配的对应补丁形成用于训练输入的相应目标。
[0122]
以此方式,模型m试图从表示较短δta*的空间下采样补丁预测表示较长采集期δta的高质量(例如,较高snr)补丁所得到的预测误差可以用于(例如,经由反向传播或其他机器学习技术)改进训练数据集中的多个(优选地所有)可用补丁对的ann精确度,直到例如达到特定的总体预测性能水平。
[0123]
图7的训练方法可以替代地应用于投影域,因此训练中不是必须需要重建器。正弦图模式格式可以优选地用于投影域实施例中。同样,解剖结构不可知方案是可选的。
[0124]
现在参考图8,其示出了用于训练模型m的训练系统ts的示意图,所述模型m是如在投影域中在用于图4的采集时间缩短的机器学习模块mlm中所使用的模型m。
[0125]
具体地,(1)通过患者研究数据库(例如pacs)中的适当数据库搜索/查询来定位历史患者数据,如pet列表模式数据中的投影数据。
[0126]
作为用于模型m的训练的准备,从数据库中检索列表模式数据中的投影数据,并对其进行下采样。换言之,创建多个副本,其中,事件条目(3)的数量显著减少,例如少于总集合的70%或甚至少于50%。如之前在图7中所示,这能够通过下采样器ds用预定义的采样概率集随机采样或通过确定性采样来实现。原始的和下采样的列表模式文件都重排为3d或4d pet正弦图(4)。如果不使用飞行时间信息(tof),3d正弦图就足够了,而4d正弦图则与tof一起使用。下采样投影表示更短的采集持续时间δta*:δt1、δt2、
…
、δtn(5)。然后,可以形成逐个补丁数据对,并将其存储在补丁数据库(7)中,每个数据对包括与上述图7中描述的相同空间位置相关的补丁。然后,通过使用替代的成对的正弦图补丁类似于图7中的方案来执行训练。同样,基于补丁的学习是可选的,学习可以替代地在来自不同患者的成对的完整正弦图上进行。同样,从补丁进行学习允许更稳健的学习。能够基于来自单个患者的数据进行训练。
[0127]
如图6-8所示,可以使用反向传播,根据基于训练输入补丁的模型训练输出,和与用于多个(优选所有)对的训练输入补丁相关联的目标之间的不匹配,来调整模型参数。
[0128]
现在参考图9,其示出了用于训练模型m的训练系统ts的示意图,所述模型m是如图
5的用于重建时间缩短的机器学习模块mlm中所使用的模型m。
[0129]
具体地,历史患者数据,包括pet列表模式数据中的投影数据和重建的pet影像,位于患者研究数据库中(例如pacs中)。
[0130]
作为用于训练模型m的准备,从数据库中检索列表模式数据,并使用指定的迭代次数nit迭代地重建所述列表模式数据,以获得中间图像。将在早期迭代循环中获得的中间图像与在后期迭代循环中获得的中间图像进行匹配,以形成训练对(vj,vk),其中k>j表示迭代循环。可以使用针对不同患者的配对。图像对(vj,vk)可以可选地由采样器smp分解成对应的补丁对作为替代,迭代重建影像的历史数据可能已经包括已存储的中间图像,而不仅仅是最终图像,因此可能不需要执行上述重建,并且可以容易地形成早期循环和后期循环中间图像的配对。
[0131]
然后,向模型m提供早期循环中间图像vj或补丁作为训练输入。模型m产生训练输出,所述训练输出与后期交互循环图像vk或补丁进行比较。基于所述比较,调整模型的参数以改善预测性能。
[0132]
可选地,下采样可以用于表示更短和更长的采集时间,从而将该训练方法与图7-8所示的训练方法相结合。具体地,对于每个中间迭代结果,生成表示更短采集持续时间δta*:tδ1、δt2、
…
、δtn(5)的pet图像集,产生n x i个中间pet图像。从这些图像中,导出k个空间子采样补丁并将其存储在补丁数据库mem(7)中。类似地,来自完全相同的空间子体积的k个补丁也被创建并存储到补丁数据库mem(8)中。
[0133]
在训练过程中,向模型m提供表示较短采集持续时间t*和nit不同收敛状态的多个(优选全部)补丁k,与来自作为目标的原始(完整数据集)最终重建的pet图像(9)的匹配补丁k一起作为输入。
[0134]
然后,模型尝试从与δt*相关联的下采样的中间补丁预测与时间t相关联的(较)高质量的补丁。在反向传播训练算法或其他算法中使用所得到的预测误差,以改善模型对于优选所有可用的补丁的预测精确度,直到满足条件,例如,达到特定的总体预测性能。为了改善机器学习的性能,训练输入数据可以包括分别表示所述早期扫描数据、短扫描数据或早期迭代数据的数据(在两个或更多个时间点)的时间序列。
[0135]
总体上,上述训练系统ts中的每一个能够与一个或多个(或全部)其他训练系统相结合。
[0136]
现在参考图10,更详细地转向机器学习模型m。优选地,模型m是人工神经网络。图10示出了前馈型神经网络m的示意性框图。网络m优选地以未完全连接的层卷积。
[0137]
在功能和概念上,本文所使用的神经网络m的操作是一种回归,其中,学习了i)早期投影数据λ或早期重建图像v与ii)后期投影数据λ’或后期重建图像v’之间的先验的未知的潜在关系。模型可以被理解为充当降噪器,因为与缩短的等待时间或采集时间相关联的早期数据(投影或重建图像)预计将形成与更长(更传统)的等待时间和采集时间相关联的后期数据的低snr版本。早期数据被回归到其降噪后的后期版本。因此,影像是端到端映射的。由于在用于迭代pet重建算法的迭代循环期间,不同时期的影像之间存在类似的关系,并且能够将神经网络m训练为学习这种关系。神经网络nn优选地是判别监督机器学习模型,其被实施为解决本文所设想的回归化(regressional)图像到图像任务。
[0138]
可以由上述计算机化训练系统ts训练模型m。在训练中,训练系统ts适配模型nn的
初始(模型)参数集θ。在神经元网络模型的背景下,参数在本文中有时被称为权重。训练数据可以通过模拟生成,也可以从现有历史影像中取得,如可以从诸如pacs的医学图像数据库或类似数据库/存储库中找到的历史影像,如上述在图6-9中所示。因此,可以关于机器学习模型nn定义两个处理阶段:训练阶段和部署(或推断)阶段。
[0139]
在训练阶段,在部署阶段之前,通过基于训练数据适配其参数来训练模型。一旦经过训练,模型可以用于部署阶段,以将(并非来自训练数据的)早期数据v、λ、vi降噪为在临床使用期间用于任何给定患者pat的更高snr的版本v’、λ’、vk,k>i。训练可以是一次性操作,也可以用新的训练数据重复进行。
[0140]
机器学习模型m可以存储在一个(或多个)计算机存储器mem’中。预训练模型m可以被部署为机器学习组件,所述机器学习组件可以运行在例如桌面计算机、工作站、膝上型计算机等计算设备pu上,或者运行在分布式计算架构中的多个这样的设备上。优选地,为了实现良好的吞吐量,计算设备pu包括支持诸如多核设计的并行计算的一个或多个处理器(cpu)。在一个实施例中,使用gpu(图形处理单元)。
[0141]
现在更详细地参考图10,其示出了前馈结构中的卷积神经网络m。网络m包括以级联方式分层布置的多个计算节点,其中数据流从左到右并因此从层到层行进。本文不排除递归网络。已发现卷积网络在处理图像数据时产生良好的结果。
[0142]
在部署中,早期数据应用于输入层il。然后,早期数据v、λ或vi传播通过一系列隐藏层l
1-ln(仅示出了两个,但可能有一个或两个,或多于三个),然后在输出层ol处出现,作为用于早期数据的降噪版本的后期数据v'、λ'或v
k,k》i
的估计值。后期数据输出v'、λ'或v
k,k》i
具有与早期输入v、λ或vi相同的大小。网络m可以被认为是具有深度架构,因为它具有一个以上的隐藏层。在前馈网络中,“深度”是输入层il与输出层ol之间的隐藏层的数量,而在递归网络中,深度是隐藏层的数量乘以通路(passes)的数量。
[0143]
为了计算和内存分配效率,网络的层、以及实际上的输入和输出影像、以及隐藏层之间的输入和输出(本文称为特征图)能够表示为二维或更高维的矩阵(“张量”)。维度和条目的数量表示上述大小。
[0144]
优选地,隐藏层包括一系列卷积层,本文中表示为层l1
–
l
n-k,k》1
。卷积层的数量至少为一个,例如为2-5个或任何其他数量。该数量可能达到两位数。
[0145]
在实施例中,在一系列卷积层的下游,可以有一个或多个完全连接的层,但并非在所有实施例中都是这种情况,并且实际上优选地,在实施例中本文所设想的架构中不使用完全连接。
[0146]
每个隐藏lm层和输入层il实施一个或多个卷积算子cv。每个层lm可以实施相同数量的卷积算子cv,或者对于一些或所有层,数量可以不同。
[0147]
卷积算子cv在其相应的输入上实施卷积运算。卷积算子可以概念化为卷积核。它可以被实施为包括形成本文中称为权重的过滤元件的条目的矩阵,以形成模型参数θ的至少一部分。具体地是在学习阶段被调整的这些权重。第一层il通过其一个或多个卷积算子处理输入的早期数据v、λ、vi。特征图是卷积层的输出,在一个层中每个卷积算子对应一个特征图。然后,将早期层的特征图输入到下一层,以产生更高一代的特征图,依此类推,直到最后一层ol将所有特征图组合到输出体积v’中。最后一个组合器层也可以实现为卷积,所述卷积将估计值v’、λ’或v
k,k》i
提供为输出特征图,所述输出特征图具有与相应的输入数据
v’,λ’或v
k,k》i
相同的大小。
[0148]
输入层il和一些或所有隐藏层中的卷积算子优选地是3d的。即,在空间维度上存在卷积,以更好地说明所有3个空间维度中的空间相关性。
[0149]
卷积层中的卷积算子cv与完全连接层的区别在于,卷积层的输出特征图中的条目不是作为该层的输入而接收的所有节点的组合。换言之,卷积核仅应用于输入体积v的子集,或应用于从早期卷积层接收的特征图。输出特征图中每个条目的子集都不同。因此,卷积算子的运算能够被概念化为在输入上的“滑动”,类似于从经典信号处理中已知的经典卷积运算中的离散过滤器内核。因此命名为“卷积层”。在完全连接的层中,通常通过处理输入层的所有节点来获得输出节点。
[0150]
卷积算子的步长(stride)能够选择为1或大于1。步长定义如何选择子集。大于1的步长相对于该层中输入的尺寸减小了特征图的尺寸。本文中优选步长为1。为了保持特征图的尺寸与输入影像的尺寸相对应,在实施例中可以应用零填补层p。这允许对甚至是位于已处理特征图边缘的特征图条目进行卷积。
[0151]
对在投影域或图像域中的图像类型的数据在图2-9中(无论是投影域还是图像域)的上述处理能够通过共同处理非图像类型的数据来增强,如生物特征、与处理后的图像类型相关的患者的病史。非图像类型的数据在本文也称为背景数据xcd,因为这种数据为图像类型的数据提供背景。当以神经网络时间设置表示时,非图像数据通常导致稀疏的数据。可以使用嵌入或其他编码技术将非图像类型的数据适当地转换为“伪图像”,然后可以将所述“伪图像”与图像类型的数据一起处理。如图10底部所示,可以使用具有多线结构(multi-strand)处理的神经网络架构。
[0152]
在多线结构处理中,存在分别处理输入图像数据和非图像数据的一个或多个单独层的附加线结构。在实施例中,这些一个或多个附加线结构的输出(图10中仅示出了一个线结构)随后被合并,并与图像类型的数据一起处理,以计算输出的后期数据v’、λ’或vk,k》i。
[0153]
图10底部示出了一个这样的单独的线结构,作为附加序列的级联层l
′
1-m
。可能存在一个、两个、三个或更多这样的层。优选地,非图像数据处理线结构l1’
、l2’
、
…
l
m’包括处理将非图像数据嵌入到伪图像中的完全连接的层。具体地,在非图像数据处理线结构l
′
1-m
中可以只存在这样的完全连接层(不包括卷积层)。伪图像与由图像类型处理线结构l
1-ln中的一个或多个隐藏层产生的特征图级联或合并。在实施例中,通过在非图像处理线结构l
′
1-m
中使用自动编码器架构来实现嵌入操作,以获得用于能够被馈送到图像处理线结构l
′
1-n
中的非图像数据的适当表示(伪图像)。
[0154]
多线结构处理架构可以包括去卷积层,所述去卷积层包括充当对卷积算子的准逆算子的去卷积算子。这允许多分辨率处理。具有多分辨率能力的神经网络模型的范例包括如在olaf ronneberger等人在“u-net:convolutional networks for biomedical image segmentation”中报告的u-net架构,出版在navab n.等人(eds)的“medical image computing and computer-assisted intervention
–
miccai 2015”(lecture notes in computer science,第9351卷,第234页)。
[0155]
代替将图像类型的输入数据v、λ、vi作为整体处理,采样器smp可以首先将图像数据v、λ、vi采样到上述补丁中,然后将补丁通过网络m进行传递。
[0156]
应当理解,图10中的上述模型m仅根据了一个实施例,并非限制本公开。本文还设
想了具有比本文所描述的更多或更少或不同功能的其他神经网络架构,例如池化层或分出层或其他。此外,本文设想的(回归化)图像到图像模型根本不一定是神经网络类型的。此外,在备选实施例中,本文还设想了基于从训练数据进行采样的经典的统计回归方法。还有其他技术,可以包括bayesian网络,或随机场,例如markov型随机场等。
[0157]
现在参考图11更详细地解释本文中可以使用的训练系统ts和机器学习模型m。
[0158]
在上述用于cnn类型模型m的架构中,cnn模型nn的所有卷积/去卷积滤波器核的权重w的总和定义机器学习模型的配置。对于每个层的权重可以不同,并且,每个层可以包括多个卷积算子,其中一些或每一个卷积算子具有不同的核设置w。在训练阶段中被学习的是这些权重wj,其中,索引j在本文的层和卷积算子上运行。一旦训练阶段结束,完全学习的权重,与其中布置了节点的架构一起能够存储在一个或多个存储器mem’中,并且能够用于部署。
[0159]
更详细地,图11示出了一种训练系统ts,其用于训练参数,即训练如在图10或其他附图中讨论的卷积神经网络中的机器学习模型的权重。
[0160]
训练数据包括数据对k(xk,yk)。训练数据包括针对每个对子k(索引k与上面用于指定特征图的生成的索引无关)的训练输入数据xk和相关联的目标yk。因此,具体地对于本文主要设想的监督学习方案,以对子k来组织训练数据。但是,应当注意,本文不排除非监督学习方案。
[0161]
训练输入数据xk可以从在实验室中或先前在诊所中采集并保存在图像库中的历史图像数据中获得。目标yk或“地面实况”可以代表低噪声图像的范例,而xk是对应的具有较高噪声水平的图像。本文中不需要对子xk、yk代表用于同一患者的完全相同的解剖结构。
[0162]
与图2-9中的上述实施例一致,训练输入数据xk可以包括早期投影数据λ或早期影像v。相关联的目标yk分别包括后期投影数据λ和后期影像v’。对于内部处理实施例,训练输入数据xk包括用于早期迭代循环i的中间重建图像vi,相关联的目标yk是用于后期迭代循环j>i的中间重建图像vj。
[0163]
在训练阶段,机器学习模型m的架构,如图10所示的cnn网络,预先填充了初始权重集。模型nn的权重θ表示参数化m
θ
,训练系统ts的一个目标是基于训练数据(xk,yk)对来优化和适配参数θ。换言之,学习能够在数学上公式化为优化方案,其中,尽管可以替代使用最大化效用函数的双重公式,但成本函数f被最小化。
[0164]
现在假设成本函数f的样板,所述成本函数f测量聚合的残差,即,由神经网络模型nn估计的数据与根据一些或所有训练数据对k的目标之间产生的误差:
[0165]
argmin
θ
f=∑k||m
θ
(xk)
–
yk||
ꢀꢀꢀ
(1)
[0166]
在公式(1)及以下公式中,函数m()表示应用于输入x的模型nn的结果。成本函数可以是基于像素/体素的,例如l1或l2成本函数。在训练中,训练对的训练输入数据xk通过初始化的网络m传播。具体地,在输入il处接收用于第k对的训练输入xk,所述训练输入xk通过模型,然后在输出ol处作为输出训练数据m
θ
(x)输出。使用合适的措施||
·
||,例如ρ范数、平方差或其他措施,以测量由模型m产生的实际训练输出m
θ
(xk)与期望目标yk之间的差,本文也称为残差。
[0167]
输出训练数据m(xk)是用于与所应用的输入训练图像数据xk相关联的目标yk的估计值。总体上,该输出m(xk)与当前考虑的第k对的相关联的目标yk之间存在误差。然后,可以
使用诸如反向/前向传播或其他基于梯度的方法的优化方案来适配模型nn的参数θ,以减少用于所考虑的对子(xk,yk)的残差或来自完整训练数据集的训练对的子集。
[0168]
在由更新器up针对当前对子(xk,yk)更新模型的参数θ的第一内部环路中的一次或多次迭代之后,训练系统ts进入第二外部环路,在第二外部环路中相应地处理下一个训练数据对x
k+1
,y
k+1
。更新器up的结构取决于所使用的优化方案。例如,由更新器up管理的内部环路可以通过在前向/反向传播算法中的一次或多次前向和反向传递来实施。在适配参数时,将所有训练对的聚合(例如求和)残差考虑到当前对,以改进目标函数。能够通过将目标函数f配置为诸如针对每个对子考虑的一些或所有残差的公式(1)中的平方残差的和来形成聚合残差。也可以设想其他代数组合而不是平方和。
[0169]
可选地,训练系统包括采样器smp,以将原始训练输入图像数据采样到子体积中,然后,基于这些子体积来训练模型m,而不是作为整体一次处理训练输入影像v、λ或vi。由于执行了解剖结构不可知的学习范式,这允许实现更好的学习。
[0170]
可选地,可以使用一个或多个批次的标准化算子(“bn”,未示出)。成批的标准化算子可以集成到模型m中,例如耦合到层中的一个或多个卷积算子cv。bn算子允许减轻消失的梯度效应,其在模型m的学习阶段中,在基于梯度的学习算法期间经历的重复的前向和反向传递中,梯度幅度的逐渐减小。成批的标准化算子bn可以在训练中使用,也可以在部署中使用。
[0171]
图11所示的训练系统能够考虑用于所有学习方案,具体地用于监督方案。在可选择实施例中,本文还可以设想无监督学习方案。可以使用gpu来实施训练系统ts。
[0172]
完全训练的机器学习模块mlm可以存储在一个或多个存储器或数据库中。它可以作为云服务提供。能够免费提供接入,或者也能够经由许可证付费或按使用付费方案授予其使用权。
[0173]
参考图12-15中的流程图,现在将解释用于支持核成像的方法的实施例。以下方法可以是在上述图1-11中的系统的操作的基础上。但是,以下讨论的方法也能够理解为以其自身因素进行教导,不一定实践在上述任何系统架构中。
[0174]
更详细地,首先转到图12,其示出了通过缩短上述施用示踪剂之后的患者等待时间δtw来支持核成像的流程图。方法可以在重建之前的预处理中使用,或者在重建之后的后处理中使用。换言之,方法适用于投影域或图像域。
[0175]
首先转到投影域中的应用,在向患者施用造影剂之后,并且在通常针对所述患者和/或示踪剂规定的缩短的等待时间之后,在步骤s1210处,在患者所在的发射成像设备中开始投影数据采集。具体地,由于缩短的等待时间δtw,可以在倾斜上升阶段开始投影数据采集,而不是通常在常规方法中进行的饱和阶段。
[0176]
该操作步骤s1210产生早期投影数据,其随后在步骤s1220被接收到机器学习模块中,所述机器学习模块已经用训练数据进行了预训练,例如,如上或如下在图15处所描述的。
[0177]
在步骤s1230处,预训练的机器学习模块处理早期投影数据,并计算后期投影数据的估计值,如果投影数据采集在通常针对患者和/或所使用的示踪剂规定的完全等待期之后已经开始,将获得所述后期投影数据。
[0178]
在步骤s1240处,估计的投影数据随后传递给重建器,以基于估计的后期投影数据
在图像域中重建发射影像。
[0179]
在步骤s1250处,如此重建的影像随后可用于显示、存储或其他处理。
[0180]
这种等待时间缩短方法也可以替代地在图像域中应用。在本实施例中,根据步骤s1210在缩短的等待时间之后收集的投影数据现在首先在步骤s1240处用重建器以通常的方式重建为第一版本,以产生早期图像,并且随后在步骤s1230处由机器学习模块处理该早期图像,以产生后期图像的估计值,如果在耗尽通常针对患者和/或所使用的示踪剂规定的完全等待期之后已经使用了后期投影数据,获得所述后期图像。
[0181]
在图12的上述预处理和后处理实施例中的每一个中,不需要在步骤s1230处由机器学习模块处理后期数据集和/或后期图像。
[0182]
在投影域中的优选实施例中,如上所述的解剖学上不可知性通过采样步骤s1215来培养,其中,早期投影数据被分解成补丁(子集),正是这些补丁在步骤s1235处被机器学习模块分别处理为估计的投影数据的相应子集。然后,在步骤s1235处将如此产生的估计的后期投影数据的补丁重新汇编成估计的后期投影,然后在步骤s1240处进行重建。备选地,首先将子集单独重建为体积部分,然后在步骤s1235后重建处进行汇编。
[0183]
在图像域的实施例中,也可以使用分解成子集s1235和重新汇编s1235,其中,是重建图像的第一版本被分解成子集,然后在步骤s1230处,由机器学习模块处理这些图像域子集,以产生用于后期图像的子集的估计值。然后,可以将估计的子集重新汇编为最终的后期估计值v’。
[0184]
现在参考图13中的流程图,其示出了支持发射成像的方法的另一个实施例。该实施例允许缩短采集时间并如下进行。与图12中的方法类似,该方法也可以在投影域中作为预处理或在图像域中作为后处理来实践。
[0185]
首先参考在投影域中实践的实施例,在步骤s1310处,通过患者位于其孔内的发射成像设备以缩短的采集时间采集早期投影数据。
[0186]
如图12中所述,缩短的采集时间段可以在完全等待期之后开始,或者可以在缩短的等待期之后开始。换言之,图12中的方法可以与图13中的方法结合使用,也可以不与图13中的方法结合使用。
[0187]
然后,在步骤s1320处,在预训练的机器学习模块处接收具有缩短的采集时间的早期投影数据。
[0188]
缩短的采集时间比通常用于示踪剂和/或给定患者生物特征的采集时间要短。在缩短的采集期中收集的投影数据可以具有相对低的snr。利用所提出的方法,能够缩短采集期,从而相对于给定的特定snr阈值,剂量乘以所述采集时间段的乘积被减小。在某些情况下,可实现每个位置的扫描时间为2分钟或更短,降至1分钟。
[0189]
然后在步骤s1330处,机器学习模块从早期投影数据估计用于后期投影数据的估计值,如果使用了完全采集时间段δta,将获得所述后期投影数据。
[0190]
然后,在步骤s1340处,由重建器将估计的后期投影数据重建为图像域中的重建影像。
[0191]
然后,在步骤s1350处,基于在缩短的时间段δta中收集的投影数据,使后期图像数据v’可用于显示、存储或以其他方式进行处理。
[0192]
如之前在图12所示,该方法也可以在图像域中实践。在该实施例中,机器学习模块
在步骤s1320处接收的不是投影数据,而是从早期投影数据重建的早期影像。在步骤s1330处,在该实施例中,机器学习模块随后在图像域中从该早期图像估计估计的后期图像,如果用于收集投影数据的完全采集时间段已经耗尽的话,获得所述估计的后期图像。
[0193]
同样,如图12所示,同样首先将整个投影数据或图像集分解为子集,并且用机器学习模块相应地处理子集,随后重新汇编所估计的子集,以获得完全投影数据集和/或图像,可以比处理整个投影数据集或图像集更为有益。
[0194]
现在参考图14中的流程图,其示出了支持核成像的方法的另一实施例。该方法能够单独使用,也能够与图12、13中描述的一种或两种方法结合使用。
[0195]
图14中的方法被配置为用于内部处理,其中,机器学习模块现在在重建过程期间与重建器联合操作。具体地,本文设想了迭代重建,机器学习模型以与重建器recon交错方式在迭代之间进行操作。现在首先更详细地参考总体上的迭代重建算法,这种类型的算法可以公式化为用于改进目标函数的迭代过程。具体地,可以根据成本函数的优化,具体地,成本函数的最小化来定制该过程。成本函数测量迭代期间提供的估计的影像与实际观察的投影测量值λ的匹配程度。系统矩阵用于将重建影像前向投影到投影域中,并用实际测量的投影数据λ估计该预测的投影。实际测量的数据λ与根据系统矩阵预测的投影之间的偏差能够通过成本函数进行量化。在迭代中,预测的影像被适配为降低成本函数,因此算法向正确的影像收敛。还设想了上述优化的双重公式,其包括效用函数的最大化。
[0196]
更详细地,迭代发射成像重建算法能够描述如下(为简单起见,不包括任何衰减校正):
[0197]
λ=a[fi]
ꢀꢀꢀ
(2)
[0198][0199]
λ是列表或帧模式下的发射投影数据
[0200]
a是描述从图像域前向投影到投影域的系统矩阵
[0201]fi
是要重建的发射图像域中的影像中的第i个体素
[0202]
g是在迭代i期间的更新后的体素f的更新函数。
[0203]
g的性质取决于所使用的优化算法。g的实施例包括基于以下数值方法或技术中的任何一种或多种的更新函数:梯度下降、随机梯度方法、共轭梯度、nelder-mead期望最大化(em)、最大似然方法或任何其他方法。
[0204]
在迭代重建中,目标是调整体素值,以使根据(2)||λ=a[fi]||的残差变得足够小,例如低于预定义阈值。
[0205]
重建可以以列表模式或以帧或正弦图模式进行。
[0206]
在重建期间,系统矩阵a可以是一次性预先计算的,也可以是“实时的”。在后一种情况下,不需要将整个矩阵保存在内存中。为了节省内存空间,在重建期间,但需要时,只计算系统矩阵的一部分。
[0207]
在发表于“2006ieee nuclear science symposium conference record”的w.wang的“systematic and distributed time-of-flight list mode pet reconstruction”(2006年,第1715-1722页)中描述了本文中可使用的迭代重建方案。
[0208]
现在更详细地转向用于与重建相关的内部处理的方法,重建算法处理投影数据,
所述投影数据可以是早期或后期类型的,以在步骤s1410中经由一次或多次迭代从其产生在预训练的机器学习模块m处被接收的图像域vi中的第一输入图像。
[0209]
然后,机器学习模块在步骤s1420处从该输入图像vi估计中间图像v’。该中间图像v’是用于中间图像的估计值,在重建器执行了更多次迭代i+k(其超过了在步骤1410中为了输入图像的重建而耗费的迭代周期i)的情况下,可以获得所述中间图像。
[0210]
然后,在步骤s1430处,重建器可选地继续迭代循环,但这一次基于新的中间图像v’来产生一系列一个或多个中间图像。因此,机器学习本质上允许跨越k次迭代,k>1。
[0211]
在步骤s1440处,基于用户请求或一旦满足停止传导,就终止迭代。
[0212]
然后,在步骤s1450处,输出终端ma处的当前中间图像,作为最终图像v
i+1
,所述最终图像随后可以被显示、存储或以其他方式处理。
[0213]
在实施例中,也能够在机器学习模块已经产生新的中间图像v’之后中止迭代,因为这可能已经被认为是最终图像的良好近似。
[0214]
此外,应当理解,方法能够在预先设置的或随机的迭代循环步骤间隔上或者在用户请求时通过迭代循环多次实践。在实施例中还设想以特定迭代步骤在显示设备上显示示出到目前为止获得的影像,然后决定是否继续迭代,具体地,是否使用机器学习模块来给予重建过程以推动,从而加速向最终输出v
i+1
的收敛。
[0215]
根据(2),估计的中间影像v’允许指导重建迭代,以更好地避免成本||λ=a[fi||的局部最小值。
[0216]
同样,如在图12-13中的实施例中,可以分别在上游和下游存在应用s1420机器学习模块鼓励如上所述的解剖结构不可知性的样本步骤s1415和重新汇编步骤s1425。
[0217]
现在参考图15中的流程图,其示出了在上述图12-14的实施例中使用的用于训练机器学习模块的训练方法。
[0218]
根据在图12、13或14中所使用的实施例以及该实施例是实践在图像域中还是投影域中,在步骤s1500中获取和核对合适的训练数据。优选地,本文设想了监督学习方案,尽管这并非是必须的,因为本文也设想了无监督的学习设置。
[0219]
在监督学习中,训练数据包括适当的数据对项目,每个数据对包括训练输入数据并且与目标训练输出数据相关联。具体地,如图12、13所示,这些数据对包括早期投影数据和后期投影数据和/或(从早期投影数据重建的)早期影像和(从后期投影数据重建的)后期图像数据。如上所述,早期和后期投影数据涉及在缩短的等待时间和/或缩短的采集时间段之后收集的投影数据,而后期投影数据是在耗尽完全等待时间和/或耗尽完全采集时间段之后收集的。能够通过例如从历史数据记录(如pacs)中检索影像或投影数据来将其配对。
[0220]
类似地,用于图14中的内部处理实施例的适当训练的数据对可以用作由迭代重建器产生的中间影像,可以存储在存储器中,并且能够稍后进行访问。然后,可以通过将在较早的迭代步骤i处获得的早期中间图像vi与在较晚的迭代步骤j(j>i)处获得的后期中间图像或最终图像vj进行配对来定义数据对(x,y)=(vi,vj)。
[0221]
训练数据可以通过模拟生成,或者可以作为来自诸如his中的pacs的数据库,或其他数据库或存储库的历史数据收集。
[0222]
继续参考图15,在步骤s1510处,以数据对(xk,yk)的形式接收训练数据。每一数据对包括训练输入xk和相关联的目标xk,yk,如上述图11中所定义的。
[0223]
在步骤s1520处,将训练输入xk应用于初始化的机器学习模型nn以产生训练输出。
[0224]
训练输出m(xk)与相关目标yk的偏差或残差由成本函数f来量化。在步骤s1530处,在内部环路中的一次或多次迭代中适配模型的一个或多个参数,以改进成本函数。例如,模型参数适配为减少由成本函数测量的残差。在使用卷积的nn模型m的情况下,参数具体地包括卷积算子的权重w。
[0225]
然后,训练方法在外部环路中返回到步骤s610,在步骤s610中馈送下一对训练数据。在步骤s1520中,适配模型的参数,使得所考虑的所有数据对的聚合残差减少,特别是最小化。成本函数对聚合的残差进行量化。在内部环路中可以使用前向-反向传播或类似的基于梯度的技术。
[0226]
更一般地,调整模型nn的参数以改进目标函数f,所述目标函数f是成本函数或效用函数。在实施例中,成本函数被配置为测量聚合残差。在实施例中,通过对所考虑的所有数据对的所有或一些残差求和来实施残差的聚合。方法可以实施在一个或多个通用处理单元ts上,优选具有能够用于并行处理以加速训练的处理器。
[0227]
训练方法可以包括预处理步骤s1515,以在步骤s1510处将输入体积v采样为一个或多个子体积补丁然后,步骤s1520基于如上所述的子体积而不是整个体积,通过使用空间上对应的补丁作为目标来进行。对多个这样的子体积重复所述方法,直到已经覆盖了想要的部分,例如整个体积。采样可以是随机的或确定性的。
[0228]
在准备步骤s15100中,获取训练数据。在一个实施例中,从历史动态pet数据中选择用于不同等待时间的数据,如上在图6中所述。备选地,在历史投影数据中,优选在列表模式下,或者以预定方式或者随机地删除列表条目,以产生下采样版本的投影数据。原始的完整的投影数据列表保留为目标,而下采样版本作为相关联的训练输入。
[0229]
如前所述,根据图12-14中的两种或三种方法可以组合使用,也可以不组合使用。如果组合使用,在本文中可以训练和使用相应的不同的机器学习模块mlm1-3(在附图中未具体指定),以分别缩短等待时间、扫描时间和重建时间。
[0230]
数据处理部分dps或训练系统ts的组件可以实施为一个或多个软件模块,在一个或更多个通用处理单元pu(诸如与成像器nia相关联的工作站)上运行,或者在与一组成像器相关联的服务器计算机上运行。
[0231]
备选地,数据/图像处理部分dps或训练系统ts的一些或所有组件可以以软件或硬件来布置。硬件可以包括适当编程的微控制器或微处理器,例如fpga(现场可编程门阵列),或者作为集成到成像系统nir中的硬连线ic芯片、专用集成电路(asic)。在其他实施例中,图像/数据处理部分dps或训练系统ts可以实施在软件和硬件二者中、部分实施在软件中、以及部分实施在硬件中。
[0232]
数据处理部分dps或训练系统ts的不同组件可以实施在单个数据处理单元pu上。可选择地,一些或多个组件实施在不同的处理单元pu上,可能以分布式架构远程布置并且可连接在适当的通信网络中,例如在云设置或客户端服务器设置等中。
[0233]
本文描述的一个或多个特征能够被配置或实施为编码在计算机可读介质内的电路和/或其组合。电路可以包括分立和/或集成电路、片上系统(soc)元素,其特征在于,适配为在适当的系统上执行根据前述实施例之一的方法的方法步骤。
[0234]
因此,计算机程序元素可以存储在计算机单元上,计算机单元也可以是本发明实
施例的一部分。这种计算单元可以适配为执行或引发执行上述方法的步骤。此外,它可以适配为操作上述设备的组件。计算机单元能够适配为自动进行操作和/或执行用户的命令。计算机程序可以加载到数据处理器的工作存储器中。因此,数据处理器可以配备为执行本发明的方法。
[0235]
本发明的这个范例性实施例既包括从一开始就使用本发明的计算机程序,也包括通过更新将现有程序变成使用本发明程序的计算机程序。
[0236]
此外,计算机程序元素可以能够提供所有必要的步骤来实现上述方法的范例性实施例的过程。
[0237]
根据本发明的其他范例性实施例,提供一种计算机可读介质,例如cd-rom,其中,计算机可读介质具有存储在其上的计算机程序元素,素数计算机程序元素由前面的部分描述。
[0238]
计算机程序可以存储和/或分布在适当的介质(具体地,但不一定是非暂时性介质)上,例如与其他硬件一起提供或作为其他硬件的一部分提供的光学存储介质或固态介质,但也可以以其他形式分布,例如经由互联网或其他有线或无线电信系统。
[0239]
然而,计算机程序也可以通过例如万维网的网络呈现,并且能够从这样的网络下载到数据处理器的工作存储器中。根据本发明的其他范例性实施例,提供一种用于使计算机程序元素可用于下载的介质,所述计算机程序元素被设置为执行根据本发明之前所描述的实施例之一的方法。
[0240]
必须注意,本发明的实施例是参考不同主题描述的。具体地,参考方法类型权利要求描述了一些实施例,而参考设备类型权利要求描述了其他实施例。但是,本领域技术人员将从以上和以下的描述中得出,除非另有通知,除了属于一种类型的主题的特征的任何组合之外,与不同主题相关的特征之间的任何组合也被视为与本技术一起公开。但是,所有特征都能够组合,提供的协同效应不仅仅是特征的简单总和。
[0241]
虽然在附图和前面的描述中已经详细说明和描述了本发明,但是这种说明和描述应当被认为是说明性的或范例性的,而不是限制性的。本发明不限于所公开的实施例。本领域技术人员通过对附图、公开内容和从属权利要求的研究,可以理解并实现对所公开实施例的其他变化。
[0242]
在权利要求中,“包括”一词不排除其他元素或步骤,不定冠词“一”或“一个”不排除多个。单个处理器或其他单元可以实现权利要求中记载的若干项的功能。仅在相互不同的从属权利要求中记载了某些措施这一事实并不表明这些措施的组合不能有利地使用。权利要求中的任何附图标记不应被解释为限制保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1