背景技术:
1、机器学习是指基于观察到的数据来训练统计模型的过程。例如,此类机器学习模型的一种众所周知的形式是神经网络。神经网络包括多个节点,这些节点通过链路(有时称为边缘)互连。节点和边缘通常在软件中实现。一个或多个节点的输入边缘从整体上形成网络的输入,而一个或多个其他节点的输出边缘从整体上形成网络的输出,而网络内各个节点的输出边缘形成至其他节点的输入边缘。每个节点表示其(诸)输入边缘的函数,该函数通过各自的权重加权,结果在其(诸)输出边缘上输出。可基于经验数据(训练数据)的集合逐渐调整权重,以便趋向于网络将针对给定输入来输出期望值的状态。
2、图1a通过例示的方式给出了示例神经网络101的简化表示。示例神经网络包括节点104的多个层102:输入层102i、一个或多个隐藏层102h和输出层102o(尽管这种分层结构不是必需的)。实际上,每个层中可能有许多节点,但为了简单起见,仅例示了几个节点。每个节点104被配置成通过对输入到该节点的值执行函数来生成输出。至一个或多个节点的输入从整体上形成神经网络的输入,一些节点的输出形成至其他节点的输入,而一个或多个节点的输出从整体上形成网络的输出。
3、在网络的一些或全部节点处,至该节点的输入通过各自的权重进行加权。权重可以定义给定层中的节点与神经网络的下一层中的节点之间的连接性。权重可以采用单个标量值的形式,或可被建模为概率分布。当权重由分布定义时(如在贝叶斯模型中),神经网络可以是完全概率性的并捕获不确定性的概念。各节点之间的连接106的值也可以被建模为分布。这在图1b中被示意性地例示出。分布可以用参数化分布(例如,平均值μ和标准偏差σ或方差σ2)的样本集合或参数集合的形式表示。
4、网络通过对输入层处的数据输入进行操作并基于该输入数据来调整由一些或全部节点施加的权重来学习。有不同的学习方法,但一般来说,在图1a中通过网络从左到右进行总体误差的计算的前向传播,以及在图1a中通过网络从右到左进行误差的反向传播。在下一个周期中,每个节点都会考虑反向传播的误差并产生权重的经修正的集合。通过这种方式,可以训练网络以执行其期望的操作。
5、至网络的输入通常是向量,向量的每个元素表示不同的对应特征。例如,在图像识别的情形中,该特征向量的元素可以表示不同的像素值,或者在医学应用中,不同的特征可以表示不同症状或患者的问卷回答。网络的输出可以是标量或向量。输出可以被称为标签,例如在图像中是否识别出某个物体(诸如大象)的分类,或者医学示例中的患者诊断。
6、图1c示出了一种简单的布置,其中神经网络被布置成基于输入特征向量生成标签。在训练阶段期间,包括大量输入数据点x的经验数据被提供给神经网络,每个数据点包括特征向量的示例值集合,标有各自对应的标签y的值。
7、标签y可以是单个标量值(例如,表示大象或非大象)或向量(例如,其元素表示不同的可能分类结果的独热向量,诸如大象、河马、犀牛等)。可能的标签值可以是二进制的,或者可以是表示百分比概率的软值。在许多示例数据点上,学习算法调整权重以减少经标记的分类和由网络预测的分类之间的总体误差。一旦用适当数量的数据点进行训练,则可以将未标记的特征向量输入到神经网络,并且网络可以基于输入的特征值和经调整的权重来预测分类的值。
8、这种方式的训练有时被称为监督办法。其他办法也是可能的,诸如其中输入训练数据中的每个数据点最初没有被标记的强化办法。相反,学习算法从猜测每个点的相应标签开始,然后被告知它是否正确,从而随着每一个这样的反馈逐渐调整权重。另一示例是一种无监督的办法,其中输入数据点根本没有被标记,而是让学习算法在训练数据中推断出其自身结构。本文的术语“训练”不一定具体限于有监督的、强化的或无监督的办法。
9、机器学习模型也可以由一个以上的组成神经网络形成。这方面的一个示例是自动编码器,诸如变分自动编码器(vae)。在自动编码器中,编码器网络被布置成将观察到的输入向量xo编码为潜在向量z,并且解码器网络被布置成将潜在向量解码回输入向量的真实世界特征空间。实际输入向量xo与解码器预测的输入向量版本之间的差异被用于调整编码器和解码器的权重,以便例如基于证据下界(elbo)函数来最小化总体差异的度量。潜在向量z可以被认为是输入特征空间中信息的压缩形式。在变分自动编码器(vae)中,潜在向量z的每个元素被建模为概率或统计分布,诸如高斯分布。在此情形中,对于z的每个元素,编码器学习分布的一个或多个参数,例如分布的中心点和扩展的度量。例如,中心点可以是平均值,扩展可以是方差或标准差。然后从所学习的分布中随机采样输入到解码器的元素的值。一旦训练,自动编码器可被用于从随后观察到的特征向量xo中估算缺失值。替换地或附加地,可以训练第三网络以从潜在向量中预测分类y,然后一旦训练,就用于预测后续未标记观察的分类。
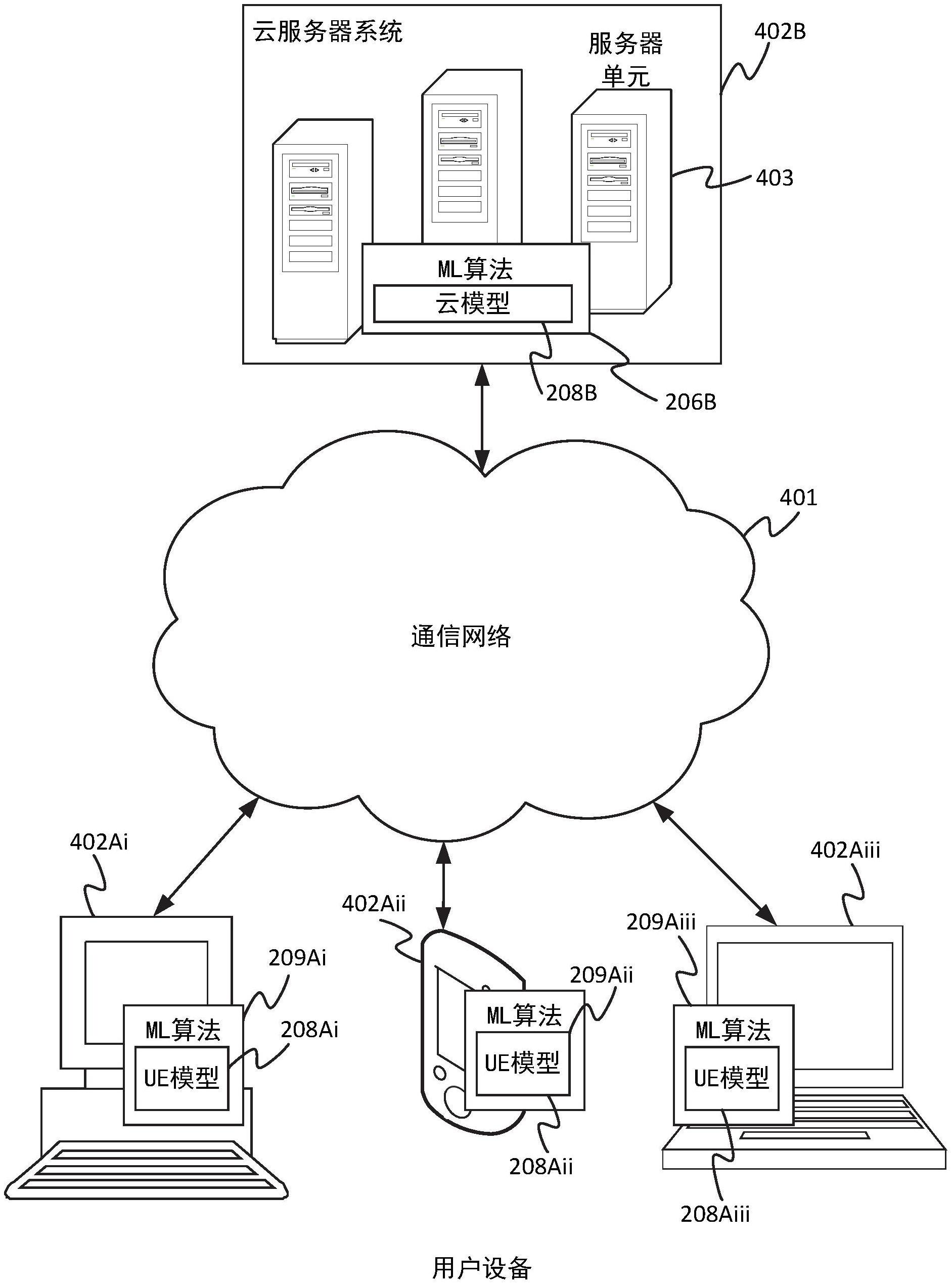
10、已知在服务器系统上(例如在包括位于不同地理位置的多个服务器单元的云服务器系统上)实现机器学习模型。不同用户的不同客户端设备可以将它们从其设备捕捉的数据发送到服务器系统以便训练服务器侧模型。
11、最近,人们有兴趣采用更分布式的办法,由此在每个用户设备上实现本地机器学习模型以及在服务器系统上实现中心模型。
12、在诸如云之类的服务器系统上实现模型的问题是将诸如音频和图像数据之类的大量数据从用户设备上传到云所需的上传带宽。如果从用户设备捕捉到的数据被直接上传到云,另一个问题是用户隐私。
13、为解决这些问题而提出的一种办法被称为“联合学习”。联合学习是分布式办法的一种形式,即再次在多个客户端设备和服务器系统中的每一者上实现神经网络形式的模型。然而,并非在各模型之间共享实际的训练数据,而是基于其自身的本地数据来训练每个客户端设备和云系统上的模型。此外,模型参数(即神经网络的权重)在客户端和云侧之间共享,并应用算法以在不同组成模型的权重之间进行插值或混合,以便共享不同模型已积累的知识,而不共享实际输入数据。
技术实现思路
1、然而,联合学习办法的一个问题是,这要求所有模型都具有相同的基本模型架构。一些联合学习算法声称允许异构模型,但由于它们基于共享模型参数,因此模型仍必须在至少某种程度上共享基本的公共架构。其他真正异构的办法需要从客户端到服务器侧共享完整的训练数据集。
2、根据本文公开的一个方面,提供了一种由第一计算机装备执行的方法。该方法包括:获得包括值集合的输入数据点,每个值是输入特征向量的不同元素的值,输入特征向量中的元素包括多个元素子集,每个子集包括特征向量的元素中的一者或多者。该方法进而包括:将所述输入数据点输入到所述第一计算机装备上的第一机器学习模型以基于所述输入数据点生成至少一个相关联的输出标签。该方法进一步包括:向第二计算机装备发送部分数据点,所述部分数据点包括所述特征向量的仅一部分的值,所述部分包括元素子集中的一者或多者但不包括所述元素子集中的一个或多个其他子集;以及向与所述部分数据点相关联的所述第二计算机装备发送所述相关联的标签,从而使得所述第二计算机装备基于所述部分数据点和所述相关联的标签来在所述第二计算机装备上训练第二机器学习模型。
3、在实施例中,第一计算机装备可以是客户端设备,而第二计算机装备可以是服务器系统(例如,包括位于不同物理位置的多个服务器单元的云服务器系统)。
4、由于客户端和服务器侧模型(或更一般地,第一和第二模型)是以部分输入数据点加上输出标签的方式进行通信,这有利地避免了共享来自客户端的完整特征向量的需要,同时也实现了分布式机器学习的完全模型无关的办法。换言之,因为模型之间的通信仅在特征数据和标签(模型的输入和输出)方面进行,而不是模型参数(模型的内部结构),所以所公开的办法可以在任意两个机器学习模型之间工作,而不管其模型架构如何。例如,这些可能在权重或节点的数量、节点之间的互连结构或甚至机器学习模型的类型方面有所不同(例如,一个是vae,一个不是、或者一个是cnn,而另一个是rnn、或者甚至一个包括神经网络而另一个由机器学习模型而非神经网络形成等)。但同时,如果来自特征向量的某些选择数据出于隐私原因是敏感的,或者其出于带宽的考虑上传会很麻烦,或者由于某些其他原因无法被服务器侧访问,那么其仍然可以从发送到服务器的数据中省略。例如,在机器学习应用中,用户侧的模型可以使用音频和视频两者来添加唇读或面部表情,为学习和预测提供信息。然而,用户可以避免上传视频的需要,而只上传由其本地模型生成的音频和标签(在本例中为文本)。然后,服务器侧模型可以基于音频和提供的标签进行学习。例如,这可以被用于基于客户端的附加洞察在现场逐步更新对服务器侧模型的训练。
5、提供本
技术实现要素:
以便以简化的形式介绍以下在具体实施方式中还描述的概念的选集。本公开内容并不旨在标识所要求保护的主题的关键特征或必要特征,也不旨在用于限制所要求保护的主题的范围。所要求保护的主题也不限于解决在此指出的任何或所有缺点的实现。