使用控制观测嵌入的辅助任务训练动作选择神经网络的制作方法
背景技术:
1、本说明书涉及使用机器学习模型处理数据。
2、机器学习模型接收输入并基于接收到的输入生成输出,例如预测输出。一些机器学习模型是参数模型,并基于接收到的输入和模型参数的值生成输出。
3、一些机器学习模型是深度模型,其采用多层模型为接收到的输入生成输出。例如,深度神经网络是包括输出层和一个或多个隐藏层的深度机器学习模型,每个隐藏层对接收到的输入应用非线性变换以生成输出。
技术实现思路
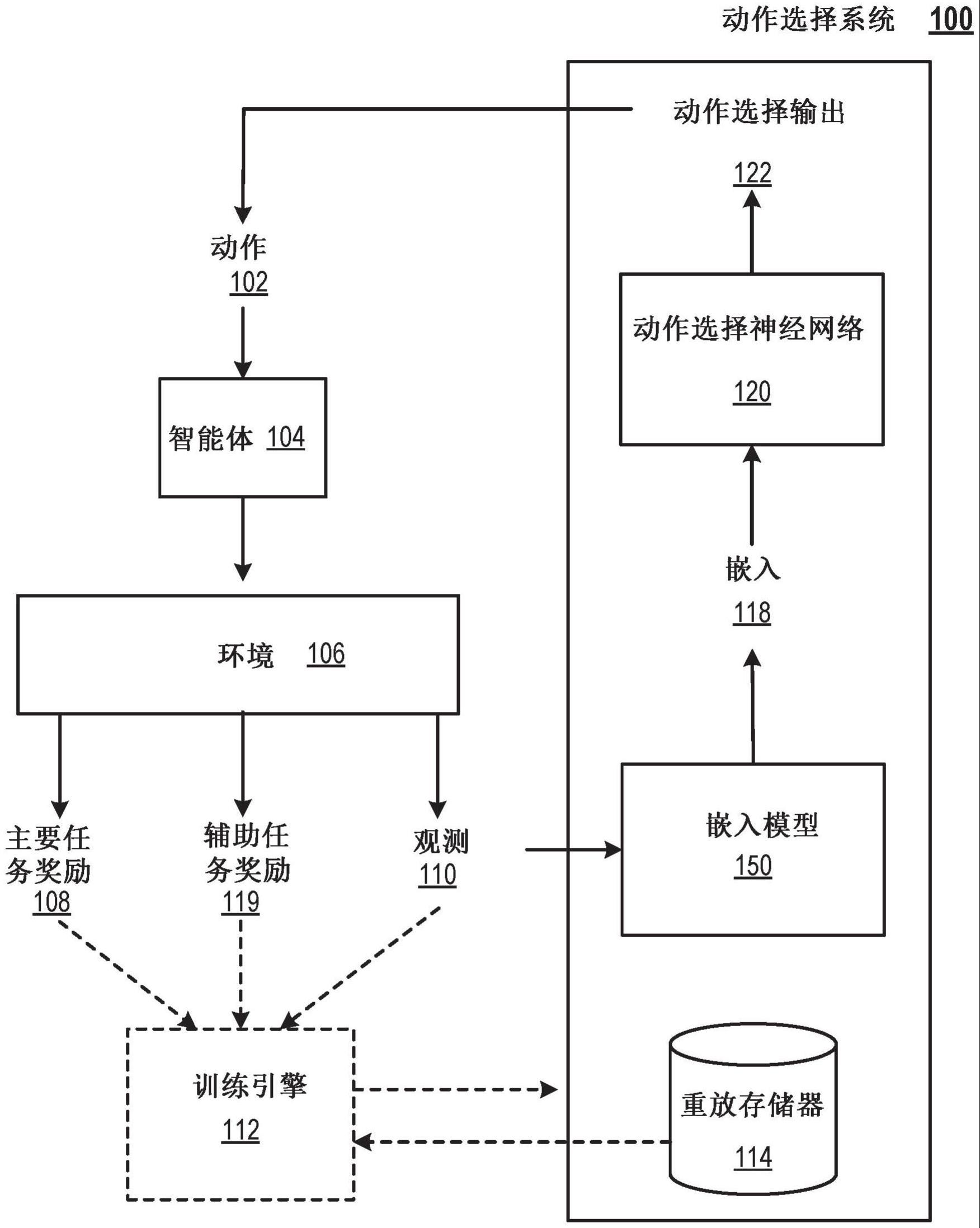
1、本说明书总体上描述了一种系统,该系统在一个或多个位置的一个或多个计算机上实现为计算机程序,用于训练具有多个参数的动作选择神经网络,该神经网络用于控制与环境交互的智能体。动作选择神经网络可以被配置为处理输入,该输入包括表征环境状态的观测的嵌入,以生成动作选择输出,该动作选择输出包括可以由智能体执行的一组可能动作中每个动作的相应动作分数。
2、贯穿本说明书,实体的“嵌入”(例如,环境的观测)可以是指实体作为数值的有序集合的表示,例如数值的向量或矩阵。可以生成实体的嵌入,例如,作为处理表征实体的数据的神经网络的输出。
3、根据第一方面,提供了一种用于训练具有多个参数的动作选择神经网络的方法,该方法用于选择要由与环境交互的智能体执行的动作,其中动作选择神经网络被配置为处理包括表征环境状态的观测的输入以生成动作选择输出,该动作选择输出包括可以由智能体执行的一组可能动作中每个动作的相应动作分数,并基于动作分数从一组可能动作中选择要由智能体执行的动作。该方法包括获得表征在一时间步处的环境状态的观测,使用嵌入模型处理观测以生成观测的较低维嵌入,其中观测的较低维嵌入具有多个维度,基于嵌入的特定维度的值确定时间步的辅助任务奖励,其中辅助任务奖励与控制嵌入的特定维度的值的辅助任务相对应,至少部分地基于时间步的辅助任务奖励确定时间步的总体奖励,以及使用强化学习技术,基于时间步的总体奖励,确定对动作选择神经网络的多个参数的值的更新。
4、在一些实施方式中,控制嵌入的特定维度的值的辅助任务包括最大化或最小化嵌入的特定维度的值。
5、在一些实施方式中,确定时间步的辅助任务奖励包括确定表征多个时间步中的每个时间步处的环境状态的相应观测的嵌入的特定维度的最大值,确定表征所述多个时间步中的每个时间步处的环境状态的相应观测的嵌入的特定维度的最小值,以及基于以下因素确定时间步的辅助任务奖励:(i)在该时间步处的嵌入的特定维度的值,(ii)与嵌入的特定维度相对应的最大值,以及(iii)与嵌入的特定维度相对应的最小值。
6、在一些实施方式中,确定时间步的辅助任务奖励包括确定以下的比率:(i)与嵌入的特定维度相对应的最大值和在该时间步处的嵌入的特定维度的值之间的差,以及(ii)与嵌入的特定维度相对应的最大值和最小值之间的差。
7、在一些实施方式中,确定时间步的辅助任务奖励包括确定以下的比率:(i)在该时间步处的嵌入的特定维度的值和与嵌入的特定维度相对应的最小值之间的差,以及(ii)与嵌入的特定维度相对应的最大值和最小值之间的差。
8、在一些实施方式中,方法进一步包括根据任务选择策略从一组可能的辅助任务中选择控制嵌入的特定维度的值的辅助任务,其中每个可能的辅助任务与控制嵌入的相应维度的值相对应。
9、在一些实施方式中,强化学习技术是离策略强化学习技术。
10、在一些实施方式中,嵌入模型包括随机矩阵,并且使用嵌入模型处理观测包括:将随机矩阵应用于观测的向量表示以生成观测的投影,以及将非线性激活函数应用于观测的投影。
11、在一些实施方式中,该方法进一步包括通过将观测展平成向量来生成观测的向量表示。
12、在一些实施方式中,嵌入模型包括嵌入神经网络。
13、在一些实施方式中,嵌入神经网络包括自动编码器神经网络的编码器神经网络。
14、在一些实施方式中,自动编码器神经网络是变分自动编码器(vae)神经网络。
15、在一些实施方式中,变分自动编码器神经网络是β变分自动编码器(β-vae)神经网络。
16、在一些实施方式中,使用嵌入模型处理观测以生成观测的较低维嵌入包括:使用编码器神经网络处理观测以生成定义潜在空间上的概率分布的参数,以及基于潜在空间上的概率分布的均值确定观测的较低维嵌入。
17、在一些实施方式中,观测包括图像并且观测的较低维嵌入包括图像中的多个关键点中的每一个的相应坐标。
18、在一些实施方式中,观测包括图像并且观测的较低维嵌入包括表征图像中的空间颜色分布的一组统计。
19、在一些实施方式中,该方法进一步包括确定与环境中的智能体正在执行的主要任务相对应的时间步的主要任务奖励,以及基于时间步的辅助任务奖励和时间步的主要任务奖励确定时间步的总体奖励。
20、在一些实施方式中,智能体是与真实世界环境交互的机械智能体,并且由智能体执行的主要任务包括物理地操纵环境中的对象。
21、在一些实施方式中,观测包括图像,并且其中使用嵌入模型处理观测以生成观测的较低维嵌入包括:处理图像以生成一组多个注意力掩码,其中每个注意力掩码定义了图像的相应区域,并且注意力掩码共同定义了图像的分区:通过处理(i)注意力掩码和(ii)图像,使用自动编码器神经网络的编码器神经网络为每个注意力掩码生成相应的嵌入,以及基于每个注意力掩码的相应嵌入的组合确定观测的较低维嵌入。
22、根据第二方面,提供了一种系统,包括:一个或多个计算机;以及被通信耦合到所述一个或多个计算机的一个或多个存储设备,其中所述一个或多个存储设备存储指令,所述指令在由所述一个或多个计算机执行时,使所述一个或多个计算机执行任何前述的方面的相应方法的操作。
23、根据第三方面,提供了存储指令的一个或多个非暂时性计算机存储介质,所述指令在由一个或多个计算机执行时,使所述一个或多个计算机执行任一前述方面的相应方法的操作。
24、可以实施本说明书中描述的主题的特定实施例以实现以下优点中的一个或多个。
25、本说明书中描述的系统可以训练动作选择神经网络,该神经网络用于使用来自一个或多个辅助任务的辅助任务奖励来控制与环境交互的智能体。每个辅助任务可以与控制(例如,最大化或最小化)使用嵌入模型生成的环境观测的嵌入的相应维度的值相对应。使用辅助任务奖励训练动作选择神经网络可以鼓励智能体有效地探索环境,并且从而可以加速智能体执行“主要”(例如,主)任务的训练,例如,在环境中物理操纵对象。特别是,使用辅助任务奖励可以使智能体通过更少的训练迭代和使用比其他方式所需的更少的训练数据在主要任务上达到可接受的性能水平,并且因此可以减少训练期间的计算资源消耗。计算资源可以包括例如存储器和计算能力。
26、本说明书中描述的系统可用于加速用于控制机器人或其他机械智能体的动作选择神经网络的训练。例如,系统可以在模拟数据上训练动作选择神经网络,例如表征模拟机器人与模拟环境的交互。该系统可以通过鼓励机器人通过学习执行辅助任务——例如,控制模拟观测嵌入的维度——来有效探索其模拟环境,从而加速动作选择神经网络在模拟数据上的训练。在模拟数据上被训练后,经过训练的动作选择神经网络可以被部署来控制真实世界机器人在真实世界环境中高效地执行任务。因此,提供了用于选择要由与真实世界环境交互的智能体执行的动作的方法,包括执行用于基于模拟(或真实世界)的环境的观测来训练具有多个参数的动作选择神经网络的方法的第一阶段,随后是基于真实世界环境的观测使用经过训练的动作选择网络来选择智能体在与真实环境交互时执行的动作的一个或多个步骤的第二阶段。在每个阶段,对真实世界环境的观测是由感测真实世界环境的传感器(例如相机)获得的。
27、本说明书中描述的系统可以使用辅助任务训练动作选择神经网络,这能够需要最少的手动设计工作。特别是,系统用户无需由专家手动设计的辅助任务(这能够既困难又耗时),只需指定用于生成观测嵌入的嵌入模型。大量传统嵌入模型,例如变分自动编码器,是可轻松获得的而无需手动设计工作。
28、本说明书的主题的一个或多个实施例的细节在附图和下面的说明书中阐述。从说明书、附图和权利要求中,主题的其他特征、方面和优点将变得显而易见。
- 还没有人留言评论。精彩留言会获得点赞!