将经训练的人工智能模型转换为可信赖的人工智能模型的制作方法
本发明涉及一种用于将经训练的人工智能模型转换为可信赖的人工智能模型的计算机实现的方法和系统。
背景技术:
1、用于促进在现实生活应用中引导决策的人工智能(ai)系统被广泛接受,被部署模型的可信赖性是关键。不仅在诸如自主驾驶或计算机辅助诊断系统(cds)的安全关键应用中,而且在工业中的动态开放世界系统中,对于域内样本(“已知未知”)以及域外样本(“未知未知”)的预测而言,预测模型能够感知不确定并且产生良好校准,因此是可信赖的,这一点至关重要。特别地,在工业和物联网设置中,部署的模型可能在整个生命周期中遇到远离输入域的错误和不一致的输入。此外,例如由于资产的磨损、维护程序或使用模式的改变等,输入数据的分发可能逐渐远离训练数据的分发。欧盟委员会最近公布的“可信赖人工智能伦理准则”(https://ec.europa.eu/digital-single-market/en/news/ethics-guidelines-trustwor thy-ai)也强调了这种设置中技术稳健性和安全性的重要性,要求可信赖的ai应该是合法、合乎伦理和稳健-既从技术角度考虑,又考虑到其社会环境。
2、在传统方法中,为每个新资产或新环境训练新模型。然而,这是昂贵的,因为在获取新的训练数据的过程中必须停止生产,标记是昂贵的,并且训练模型的过程也以人力和it资源的高成本来实现。
3、此外,基于输入数据检测域漂移的统计方法是已知的。这些方法对于单个数据集是高度特定的。由于已知的方法不能确定潜在的数据漂移对精度的影响,因此模型的再训练以及数据生成过程是必要的。
4、解决预测不确定性的常用方法包括训练神经网络(nn)的后处理步骤和训练概率模型,包括贝叶斯和非贝叶斯方法。然而,从头开始训练这种固有不确定性感知模型是以高计算成本实现的。此外,需要高度专业化的知识来实现和训练这种模型。
5、然而,虽然对于越来越强的域漂移或扰动的增加的预测熵可以是不确定性感知的指标,但是简单的高预测熵不足以进行可信赖的预测。例如,如果熵过高,则该模型将产生缺乏自信的预测,类似地,如果熵过低,则预测将是过自信的。
技术实现思路
1、考虑到现有技术中所描述的缺点,因此本发明的目的是提供一种用于提供可信赖的人工智能模型的方法和相应的计算机程序产品以及设备。
2、这些目的通过独立权利要求的主题来解决。在从属权利要求中提出了有利的实施例。
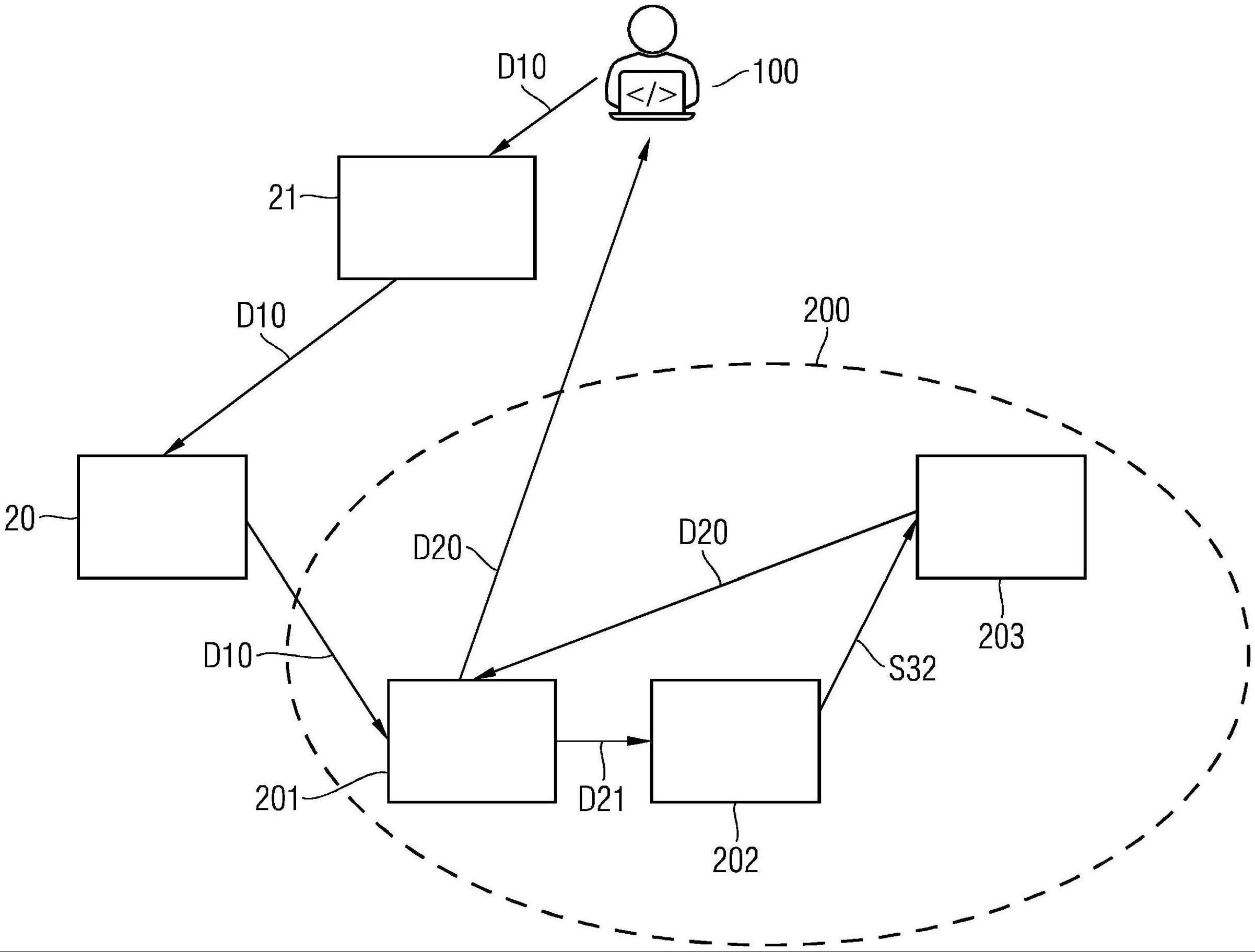
3、本发明涉及一种用于将经训练的人工智能模型转换为可信赖的人工智能模型的计算机实现的方法,
4、-经由web服务平台的用户界面提供经训练的人工智能模型,
5、-提供基于经训练的人工智能模型的训练数据的验证数据集,
6、-由web服务平台的计算部件基于验证数据集生成通用样本,
7、-通过基于通用样本来优化校准来转换经训练的人工智能模型。
8、提供一种传统的经训练人工智能(ai)模型作为所提出的方法的输入。可以使用任何经训练的ai模型,并且对模型的训练水平或成熟度水平或精度没有具体要求。经训练的模型的质量越高,该方法执行得越容易和越快。此外,提供的可信赖的人工智能模型具有相应的更好的质量。
9、作为ai模型,例如使用基于ai的分类器。例如,可以使用机器学习模型,例如可以根据ai模型要用于的应用使用基于深度学习的模型、神经网络、逻辑回归模型、随机森林模型、支持向量机模型,或者以决策树为基础的基于树的模型。
10、已经用于训练模型或者为了训练模型而生成或收集的任何训练数据集可以用于提取验证数据集。由此,验证数据集可以是训练数据或训练数据的子集或一部分,或者可以从训练数据导出。验证数据集尤其包括一组标记的样本对,也称为样本。
11、由web服务平台的计算部件执行ai模型的转换。因此,经由web服务平台的用户界面向计算部件提供输入,即经训练的人工智能模型以及验证数据集。这样的用户界面可以由任何可应用的前端来实现,例如由web应用来实现。
12、可以经由web服务平台的相同用户界面来提供验证数据集。此外,训练数据集可以由用户界面提供,并且验证数据集由计算部件从训练数据导出。
13、基于验证数据集,生成通用样本。这些通用样本反映域漂移,由此优选地生成多个通用样本,反映不同水平或不同程度的域漂移。换言之,生成表示不同扰动强度的多个通用样本。这些扰动可以反映对预期的域内样本的可预测的或可预见的或可能的影响,或者它们可以可替代地反映样本的纯随机修改,或者它们还可以可替代地反映在生成对抗性样本的意义上的特定预期修改。因此,优选地生成范围从域内样本到域外样本的频谱。更详细的样本是样本对。一对包括输入对象、尤其是矢量或矩阵以及期望的输出值或标签,也称为监督信号。据此,模型输入可以被等同地称为输入对象,并且模型输出可以被等同地称为输出值或标签。来自验证数据集的样本的输入适于反映域漂移。
14、基于生成的通用示例,优化校准。这可以例如在适配ai模型的步骤,特别是神经网络的权重内,或者在后处理ai模型的输出的步骤内实现。
15、基于通用样本优化校准产生ai模型,其确保不同类别的分类器的预测概率的可解释性。优化校准与其中精度被优化的传统方法相对。此外,与传统方法相比,不仅使用攻击方面的对抗性样本,而且使用基于域漂移(尤其是具有变化的扰动水平的域漂移)的样本。将通用样本的生成与基于那些通用样本的校准的优化相结合是优于传统方法的微分器,并导致本文所描述的优点。
16、校准经优化,使得所谓的置信度得分(意味着特定类别的概率)与精度相匹配。因此,从可信赖的ai模型导出的置信度对应于一定程度的确定性。
17、当借助于生成的通用样本执行校准时,置信度与通用样本中反映的所有扰动水平的精度相匹配。
18、因此,优化校准的步骤将置信度得分或概率与通用样本的整个范围上的精度联系起来。经过校准的可信赖的ai模型利用与模型的实际预测功率相匹配的置信度(例如熵)来预测经过良好校准的不确定性。
19、该方法使得能够通过使用不确定性感知校准优化方法将ai模型转换为可信赖的ai模型。可信赖的ai模型确定域内样本以及域外样本的可信赖的概率。
20、实施例中的可信赖的ai模型是基于ai模型的适配模型,并且例如根据神经网络内的节点权重来适配,或者在其他实施例中是包括后处理算法的扩展ai模型。
21、以有利的方式,使用利用所提出的方法获得的可信赖的ai模型来避免过自信预测。使用可信赖的ai模型,用户知道当置信度降低时精度也以协调的方式降低,使得用户可以对何时再训练或替换ai模型作出明智的决定。此外,通过分析现实生活场景中给定输入的可信赖的ai模型的精度,接收关于预测质量的即时反馈。以有利的方式,用户立即知道ai模型是否可以例如在新的环境(例如新的工厂)中使用,或者它是否需要被再训练,潜在地大大节省了不必要的数据收集和模型训练的努力。
22、提出了一种自动转换传统神经网络的方法。对于所提出的方法,不需要专业的科学家来提供修改的神经网络的定制实现。外行的用户能够在任何机器学习开发流水线中集成可信赖度。因此,可信赖的ai可以使大量没有专业知识的应用从业者可访问。
23、利用优化校准的转换方法,ai模型的体系结构或结构不受影响,使得可信赖的ai模型可以直接部署用于预期的用例或应用,而无需进一步的强制验证阶段。对于基于ai模型的再训练或ai模型的输出的后处理的转换方法,情况尤其如此。该方法的这些特征使得能够作为web服务来使用,从而从预先训练的ai模型开始,该转换尤其由云平台提供作为服务。
24、根据实施例,通过优化校准,在置信度水平上表示任何通用样本的不确定性感知。在ai模型实现了一定程度的不确定性的情况下,预测的分类在分类器的给定类别中均匀分布。这例如产生低且均匀分布的置信度得分。这例如通过在不确定分类结果的情况下分配高熵来实现,并且例如经由适配ai模型的目标函数或ai模型的后处理输出来实现。
25、取决于用于转换经训练的ai模型的具体方法,执行ai模型的再训练或ai模型的输出的后处理或任何进一步合适的转换方法。对于再训练方法,如果经训练的ai模型是基本上成熟的经训练的ai模型,则优选地仅需要小的验证数据集。在仅粗略预训练的ai模型的情况下,优选地执行基于更全面的验证数据集的再训练。对于后处理方法,在结构或体系结构方面对ai模型没有影响,尤其是没有调整权重,使得经训练的ai模型优选地以改进的水平提供,使得可以在转换之后直接应用校准的可信赖的ai模型。
26、根据实施例,为了生成通用样本,通过域漂移修改验证数据集。更具体地,通过表示域漂移的算法修改验证数据集。例如,可以通过添加噪声信号修改验证数据集的样本。优选地,以表示工业环境的典型漂移的方式修改验证数据集,例如由于受污染的摄像机镜头、振动等。
27、根据实施例,为了生成通用样本,根据扰动强度修改验证数据集。通过这种修改,实现了不同水平的扰动。优选地,生成反映从工业环境内的典型域漂移到真正反映域外样本的修改范围的扰动的通用样本。
28、根据实施例,转换包括应用基于熵的损失项,其激励不确定性感知。这种基于熵的损失项优选地用于基于神经网络的ai模型。优选地,除了方便的损失项之外还提供熵损失项,例如交叉熵损失项。利用这些组合的损失项,在不确定性的情况下,激励神经网络朝向均匀分布的softmax输出。
29、根据实施例,转换还包括通过应用校准损失项执行ai模型的再训练。通过将基于熵的损失项与校准损失项组合,对于接近或类似于验证数据或训练数据的输入,增加了模型的技术稳健性。
30、根据实施例,执行以下步骤:
31、-基于经训练的ai模型的当前输出和验证数据集的相应地面真值数据计算验证数据集的分类交叉熵损失;
32、-通过从当前输出中去除非误导证据并将剩余的当前输出分布在预定数量的类别上计算预测性熵损失;
33、-通过将用预定第一损失因子λs加权的预测性熵损失加到分类交叉熵损失计算组合损失,其中0≤λs≤1;
34、-检查再训练是否收敛到收敛速度的预定下限;
35、-在再训练不收敛的情况下,基于组合损失和预定训练速度η更新ai模型的权重,其中0<η≤1;以及
36、-在再训练收敛的情况下,停止ai模型的再训练。
37、在不确定性的情况下,用所提出的组合损失项激励高熵激励该模型朝向均匀分布的概率分布,例如softmax函数的输出。
38、根据实施例,还执行以下步骤:
39、-通过在ai模型中正向传播通用样本的通用输入数据生成通用样本的扰动输出;
40、-将校准损失计算为预期校准误差的欧几里德范数,其对被分组为预定数量的等间隔箱的扰动输出取得加权平均,每个箱具有相关联的平均置信度和精度;
41、-检查再训练是否收敛到收敛速度的预定下限;
42、-在训练不收敛的情况下,基于组合损失和预定训练速度η(其中0<η≤1),第一次更新ai模型的权重;
43、-在训练不收敛的情况下,基于用预定的第二损失因子λadv(其中0≤λadv≤1)加权的校准损失和预定的训练速度η,第二次更新ai模型的权重;以及
44、-在训练收敛的情况下,停止训练。
45、利用所提出的校准损失项,ai模型的技术稳健性对于由验证数据集或验证数据集的训练样本以及潜在的各种扰动水平构建的输入而增加。
46、根据实施例,人工智能模型是神经网络。
47、更详细地描述具有组合损失项和校准损失项的一个实施例。一种再训练神经网络以便将经训练的神经网络转换为可信赖的神经网络的计算机实现的方法,包括以下步骤:接收针对预定数量c个类的验证输入数据x=(x1…xn)和相应地面真值数据y=(y1…yn)的验证数据集t。因此,n大于1(n>1)并且c大于或等于1(c≥1)。再训练神经网络的步骤包括迭代训练步骤:选择验证子集、生成当前输出、计算分类交叉熵损失、计算预测性熵损失、计算组合损失、提供扰动水平、生成通用样本集、生成扰动输出、计算校准损失、检查训练是否收敛、第一次更新权重、第二次更新权重并且停止训练。在选择验证子集的训练步骤中,从验证集t中选择验证输入数据xb和相应地面真值数据yb的验证子集b。因此,验证子集的基数大于零并且小于验证集的基数(0<|b|<|t|).
48、在生成当前输出的再训练步骤中,通过在神经网络中正向传播训练子集b的验证输入数据xb来生成针对子集b的神经网络当前输出。在计算分类交叉熵损失的再训练步骤中,基于训练子集b的当前输出和相应地面真值数据yb计算子集b的分类交叉熵损失lcce。在计算预测性熵损失的再训练步骤中,通过从当前输出中去除非误导性证据并将剩余的当前输出分布在预定数量c个类上计算预测性熵损失ls。在计算组合损失的再训练步骤中,通过将用预定第一损失因子λs加权的预测性熵损失ls加到分类交叉熵损失lcce计算组合损失l。由此,第一损失因数λs大于或等于零并且小于或等于1(0≤λs≤1)。
49、在提供或采样扰动水平的再训练步骤中,以从0到1的值随机采样扰动水平εb。在生成通用样本集的再训练步骤中,通过对验证子集b的验证输入数据xb应用从预定义扰动集中随机选择的并且用扰动水平εb加权的扰动来生成通用输入数据xg的通用样本集bg。因此,通用输入数据的基数等于验证子集的验证输入数据的基数(|xadv|=|xb|)。在生成扰动输出的再训练步骤中,通过在计算校准损失的训练步骤中在神经网络中正向传播通用样本集bg的通用输入数据xg生成通用样本集bg的神经网络的扰动输出,校准损失lg被计算为预期校准误差ece的欧几里德范数(l2范数)。期望的校准误差ece对被分组为预定数量m个等间隔的箱的扰动输出取得加权平均,每个箱具有相关联的平均置信度和精度。从而预定数量m大于1(m>1)。
50、在检查训练是否收敛的再训练步骤中,检查训练是否收敛到收敛速度的预定下限。在第一次更新权重的步骤中,在训练不收敛的情况下,基于组合损失l和预定训练速度η,其中预定训练速度η大于0且小于或等于1(0<η≤1),第一次更新神经网络的权重。
51、在第二次更新权重的步骤中,在训练不收敛的情况下,基于用预定第二损失因子λg加权的校准损失lg和预定训练速度η,其中预定第二损失因子λg大于或等于0且小于或等于1(0≤λadv≤1),第二次更新神经网络的权重。在停止训练的步骤中,在训练收敛的情况下停止神经网络的训练。
52、所接收的验证数据集t还包括相应地面真值数据y。地面真值数据y包括地面真值数据y1到yn的多个样本,其对应于验证输入数据x1到xn的各个样本。相应地面真值数据给出待由神经网络推导出的信息。
53、每对验证输入数据的样本和地面真值数据x1、y1到xn、yn的相应的样本属于一个类别。
54、例如,验证输入数据x1到xn的样本可以是示出手写数字的不同图像,而地面真值数据y1到yn的相应样本可以是将由神经网络推导出的相应数字。类可以是c=10类,其中每个类代表一个数(0到9)。这里,c=10类可以用以下方式进行独热编码:
55、0对应于1000000000
56、1对应于0100000000
57、2对应于0010000000
58、3对应于0001000000
59、4对应于0000100000
60、5对应于0000010000
61、6对应于0000001000
62、7对应于0000000100
63、8对应于0000000010
64、9对应于0000000001
65、作为另一示例,验证输入数据x1到xn的样本可以是不同的医学图像数据,如磁共振图像、计算机断层摄影图像、声谱图像等,并且地面真值数据y1到yn的相应样本可以是其中医学图像数据的每个像素或体素被分配有将由nn推导出的不同类型的组织或器官的相应图。类可以是c=3类,其中每个类代表一种类型的组织。这里,c=3类可以用以下方式进行独热编码:
66、正常组织对应于100
67、肿瘤组织对应于010
68、纤维组织对应于001
69、可替代地,类可以是c=4类,其中每个类代表一种类型的器官。这里,c=4类可以用以下方式进行独热编码:
70、肺组织对应于1000
71、心脏组织对应于0100
72、骨对应于0010
73、其它组织对应于0001
74、作为另一示例,验证输入数据x1到xn的样本可以是不同物理量(如力、温度、速度等)的变化过程的数据,并且地面真值数据y1到yn的相应样本可以是要由神经网络推导出的机器的各个状态。类可以是c=3类,其中每个类代表机器的一个状态。这里,c=3类可以用以下方式进行独热编码:
75、正常操作对应于100
76、启动阶段对应于010
77、故障对应于001
78、作为另一示例,验证输入数据x1到xn的样本可以是关于不同主题(如政治、体育、经济、科学等)的文本,而地面真值数据y1到yn的相应样本可以是由神经网络推导出的各个主题。类可以是c=4类,其中每个类代表一个主题。这里,c=4类可以用以下方式进行独热编码:
79、政治对应于1000
80、体育对应于0100
81、经济对应于0010
82、科学对应于0001
83、根据实施例,转换包括后处理ai模型的输出。有利地,当执行后处理时,不必为了将ai模型转换为可信赖的ai模型而对ai模型进行再训练。因此,不必提供ai模型的详细结构信息。这意味着甚至可以用所提出的方法转换黑盒分类器。后处理步骤本身可以解释为学习后处理模型的步骤,并且不与web服务平台的用户提供的ai模型的训练混合。
84、后处理可以是参数的或非参数的。参数后处理方法的示例是普拉特方法,其应用将预测模型的输出映射到校准的概率输出的s形转换。使用最大似然估计框架学习s形转换函数的参数。最常见的非参数方法基于分箱(zadrozny和elkan 2001)或保序回归(zadrozny和elkan 2002)。例如,使用由naeini,m.p.,cooper,g.f.和hauskrecht,m.(2015年1月)引入的直方图分箱用于使用贝叶斯分箱获得良好校准的概率。
85、对于后处理,再次生成通用样本并将其馈送到经训练的ai模型中。然后校准用通用样本影响的经训练的ai模型的输出。
86、在实施例中,以连续和代表性方式生成覆盖从域内样本到真正的域外样本的整个频谱的一组样本。例如,将快速梯度符号方法应用于验证数据集以生成具有变化扰动强度的通用样本。更具体地,对于验证集中的每个样本,计算相对于每个输入维度的损失的导数,并记录该梯度的符号。如果不能解析地计算梯度,例如对于决策树,则执行第0阶近似,使用有限差分计算梯度。然后将噪声ε在其梯度方向上加到每个输入维度。
87、优选地,对于每个样本,随机选取噪声水平,使得通用验证集包括来自域漂移的整个频谱的代表性样本。对于图像数据,应用仿射图像转换,例如旋转、平移等,以及图像破坏,如模糊、斑点噪声等。
88、根据实施例,在后处理步骤的过程中,通过基于通用样本优化校准度量确定用于转换未归一化logit的单调函数的参数。例如,使用严格单调函数,尤其是分段温度缩放函数或普拉特缩放函数或单调函数的其它相关参数化,将分类器的未归一化logit转换为分类器的后处理logit。然后通过基于通用样本优化校准度量确定函数的参数,例如温度。这种校准度量例如是对数似然度、brier得分、nelder mead或预期校准误差。基于通用样本而不是基于验证数据集(或训练数据集)执行例如温度缩放(即,学习温度)导致良好校准的ai模型在域偏移下被扩展以包括后处理步骤。
89、另一优点是该方法对精度没有负面影响。该方法确保分类器不仅对于域内预测受到良好地校准,而且在域漂移下也产生良好校准的预测。
90、根据上述方法,其中人工智能模型是分类器,尤其是深度神经网络、梯度增强决策树、xgboost、支持向量机、随机森林和神经网络中的一个。
91、根据实施例,验证数据集是经训练的人工智能模型的训练数据的子集。优选地,用户只需要提供训练数据的这个子集,而不需要提供整个训练数据集。
92、根据实施例,通过修改经训练的人工智能模型的训练数据生成验证数据集。修改训练数据以生成验证数据的方法步骤可以是由web服务平台的计算单元执行的方法步骤的一部分,或者可以预先执行,使得用户仅经由用户界面提供验证数据集。
93、根据实施例,经由web服务平台的用户界面提供经过转换的人工智能模型,尤其是作为可下载文件。以有利的方式,用户输入不一定可信赖的ai模型并接收经过转换的可信赖的ai模型。
94、本发明还涉及一种包括指令的计算机程序产品,该指令在由计算部件执行时使计算部件执行根据前述权利要求中任一项的方法。计算部件例如是处理器,并且例如可连接到人机接口。计算机程序产品可被实施为函数、例程、程序代码或可执行对象,尤其是存储在存储设备上的函数、例程、程序代码或可执行对象。
95、本发明还涉及一种用于将经训练的人工智能模型转换为可信赖的人工智能模型的系统,包括:
96、-用户界面部件,其使得能够提供经训练的人工智能模型,
97、-存储器,其存储经训练的人工智能模型和用户分配信息,
98、-计算部件,其用于基于验证数据集生成通用样本,其中验证数据集是基于经训练的人工智能模型的训练数据确定的,并且用于通过基于通用样本优化校准转换经训练的人工智能模型。
99、例如,计算部件可以包括中央处理单元(cpu)和可操作地连接到cpu的存储器。
100、有利地,该系统使得外行的用户能够在可分离的步骤内将他们的预先训练的ai模型转换为可信赖的ai模型,包括随时使用该系统的选项,例如在具有校准的ai模型的信任的再训练阶段之后灵活地使用该系统,例如,由于使用ai模型的应用程序或场景发生变化,这是必要的。
101、根据实施例,该系统的用户界面可以经由web服务访问。这使得用户能够灵活地提供ai模型和相应的训练数据或验证数据。用户可以透明地概观关于ai模型和相应数据的数据和信息的提供程度。
102、根据实施例,存储器和计算部件在云平台上实现。这使得能够灵活地适应web服务被请求的程度,尤其是在计算能力方面。
103、此外,可以使用云计算平台灵活地处理关于服务器位置的客户特定要求。
104、本发明的其他可能的实现或可替代的解决方案还包括以上或以下关于实施例描述的特征的组合(本文并未明确提及)。本领域技术人员还可以将单独的或孤立的方面和特征加到本发明的最基本的形式中。
- 还没有人留言评论。精彩留言会获得点赞!