用于建模和控制部分可测量系统的方法和系统与流程
本发明总体上涉及用于建模和控制部分和完全可测量系统的方法和系统,可测量系统包括机械系统。
背景技术:
1、近年来,强化学习(rl)已经在许多不同的环境中取得了突出的结果,并且已经显示出了提供用于从零开始学习不同的控制应用的自动化框架的潜力。然而,无模型rl(mfrl)算法可能需要与环境的大量交互以便解决所指派的任务。由于与环境交互的时间和成本,数据低效率限制了rl在现实应用中的潜力。特别地,当应对机械系统时,关键的是在最少可能量的试验之后学习任务,以减少磨损并避免对系统的任何损坏。
2、需要开发一种在模型学习之前和策略优化之前考虑建模和过滤不同分量的方法。
技术实现思路
1、本发明的一些实施方式的目的是提供一种克服上述限制的有前景的方式,该方式是基于模型的强化学习(mbrl),其基于使用来自交互的数据来构建环境的预测模型并利用其规划控制动作。mbrl通过使用模型从可用数据中提取更有价值的信息来提高数据效率。
2、本发明的一些实施方式基于以下认识:mbrl方法仅在它们的模型准确地类似于真实系统时有效。因此,确定性模型可能受到模型不准确性的极大影响,并且为了捕获不确定性,随机模型的使用变得必要。高斯过程(gp)由于其处理不确定性和提供原则性随机预测的内在能力而通常精确地用在rl方法中的一类贝叶斯模型。此外,pilco(概率推断学习控制)可以是成功的mbrl算法,其使用gp模型和基于梯度的策略搜索来实现在模拟以及真实系统中解决不同控制问题时的实质性数据效率。在pilco中,长期预测是通过分析计算的,通过矩匹配用高斯分布近似每个时刻的下一状态的分布。以此方式,以封闭形式计算策略梯度。然而,使用矩匹配可能引入两个相关挑战。(i)矩匹配允许仅对单峰分布进行建模。这一事实除了是对系统动态的潜在不正确假设之外,还引入了与初始条件相关的相关限制。特别地,对单峰分布的使用的限制使处理多峰初始条件复杂化,并且即使当系统初始状态是单峰时也是潜在的限制。例如,在初始方差高的情况下,由于对初始条件的依赖性,最优解可能是多峰的。(ii)只有在考虑平方指数(se)核和可微分成本函数时,矩的计算才被证明是易于处理的。特别地,对核选择的限制可能非常严格,因为具有se核的gp对后验估计器施加平滑特性,并且可能在训练期间未看到的数据中示出较差的泛化特性。
3、此外,本发明的一些实施方式基于以下认识:pilco已经激发了若干其它mbrl算法,mbrl算法试图以不同方式对其改进。在deep-pilco中已经解决了由于使用se核而引起的限制,其中可以使用贝叶斯神经网络对系统演变进行建模,并且组合基于粒子的方法和矩匹配来计算长期预测。结果显示,与pilco相比,deep-pilco需要与系统的更大量的交互以便学习任务。这一事实表明,由于表征模型所需的相当大量的参数,使用神经网络(nn)在数据效率方面可能不是有利的。更明确的方法可以使用nn的概率集合来对系统动态的不确定性进行建模。尽管模拟的高维度系统中的结果是肯定的,但是数值结果显示,当考虑诸如推车倒倒立摆基准的低维系统时,gp比nn的数据效率更高。在真实系统上开始强化学习过程以进行控制之前,另选路线可使用模拟器来学习gp模型的先验。该模拟的先验可以在没有可用数据点的状态空间的区域中改进pilco的性能。然而,该方法需要可能不总是对用户可用的准确模拟器。一些挑战可能是由于在采用无梯度策略优化的black-drops中解决了基于梯度的优化。一些实施方式基于以下认识:可以使用不可微分的成本函数,并且可以利用黑盒优化器的并行化来改进计算时间。利用该策略,black-drops实现了与pilco类似的数据效率,但是显著增加了渐近性能。
4、此外,本发明的一些实施方式基于以下认识:存在其它方法专注于改善长期预测的准确性、克服由于矩匹配引起的近似问题。一种尝试可以是依赖基于的粒子方法计算长期分布的方法。根据当前策略和提前一步gp模型,可以模拟从初始状态分布采样的一批粒子的演变。然后,使用粒子轨迹来近似预期的累积成本。可以使用策略来计算策略梯度,其中通过固定初始随机种子,概率马尔可夫决策过程(mdp)被变换为具有确定性转变的等效部分可观察mdp。与pilco相比,获得的结果不令人满意。不良的性能归因于策略优化方法,特别是不能逃离由多峰分布生成的多个局部最小值。另一种基于粒子的方法可以是pipps,其中策略梯度用所谓的重新参数化技巧而不是pegasus策略来计算。给定分布pθ(·),用θ来进行参数化,重新参数化技巧提供了用于从pθ(·)生成样本的另选方法,使得这些样本是关于θ可微分的。在随机变分推断(svi)中已经成功地引入了重新参数化技巧。与其中仅需要几个样本来估计梯度的svi中获得的结果相反,由于其爆炸幅度和随机方向,可能存在与利用重新参数化技巧计算的梯度相关的若干问题。为了克服这些问题,提出了总传播算法,其中再参数化技巧与似然比梯度组合。该算法与pilco类似地执行,其中梯度计算和存在附加噪声的性能有一些改进。
5、一些实施方式公开了名为蒙特卡罗概率学习控制推断(mc-pilco)的mbrl算法。类似于pilco,mc-pilco是策略梯度算法,其使用gp来描述提前一步系统动态,并且依赖于基于粒子的方法来近似长期状态分布,而不是使用矩匹配。通过在相关联的随机计算图上反向传播、利用重新参数化技巧来获得预期累积成本关于策略参数的梯度。与pipps不同,他们专注于获得梯度的准确估计,我们可以将优化问题解释为随机梯度下降(sgd)问题。在神经网络的背景下已经深入研究了该问题,其中使用梯度的噪声估计来优化过参数化模型。分析和实验研究显示,所采用的成本函数和非线性激活函数的形状可以显著影响sgd算法的性能。通过本领域中获得的与前的基于粒子的方法相关的结果的激励,我们考虑使用更复杂的策略和更平缓的成本函数(即较少成本惩罚)。在策略优化期间,我们还考虑策略参数应用丢弃(dropout)技术,以便提高逃离局部最小值的能力,从而获得更高性能的策略。所提出的选择的有效性在模拟中进行了分析和验证。首先,考虑到模拟的推车倒立摆作为一个常见的基准系统,用于比较mc-pilco与pilco和black-drops。结果显示,mc-pilco优于pilco和black-drops,后两者可以被认为是基于gp的mbrl的最先进算法。其次,为了评估更高维系统中mc-pilco的行为,我们将其应用于模拟的ur5机器人臂。所考虑的任务包括学习能够跟踪期望轨迹的关节空间控制器,并得以成功完成。这些结果证实,可以在mbrl中有效地使用重新参数化技巧,并且蒙特卡罗方法在正确考虑成本函数、丢弃技术和复杂/丰富策略的使用的情况下,不会遇到梯度估计问题,这与文献中通常所述的不同。
6、此外,不同于先前将gp与基于粒子的方法组合的工作,我们展示了这种策略的一个重要优势,即,采用不同核函数的可能性。我们考虑使用由se核和多项式核组合而成的核函数以及半参数模型。在模拟和真实的furuta摆实验中获得的结果表明,使用这样的核显著提高了数据效率,限制了学习任务所需的交互时间。
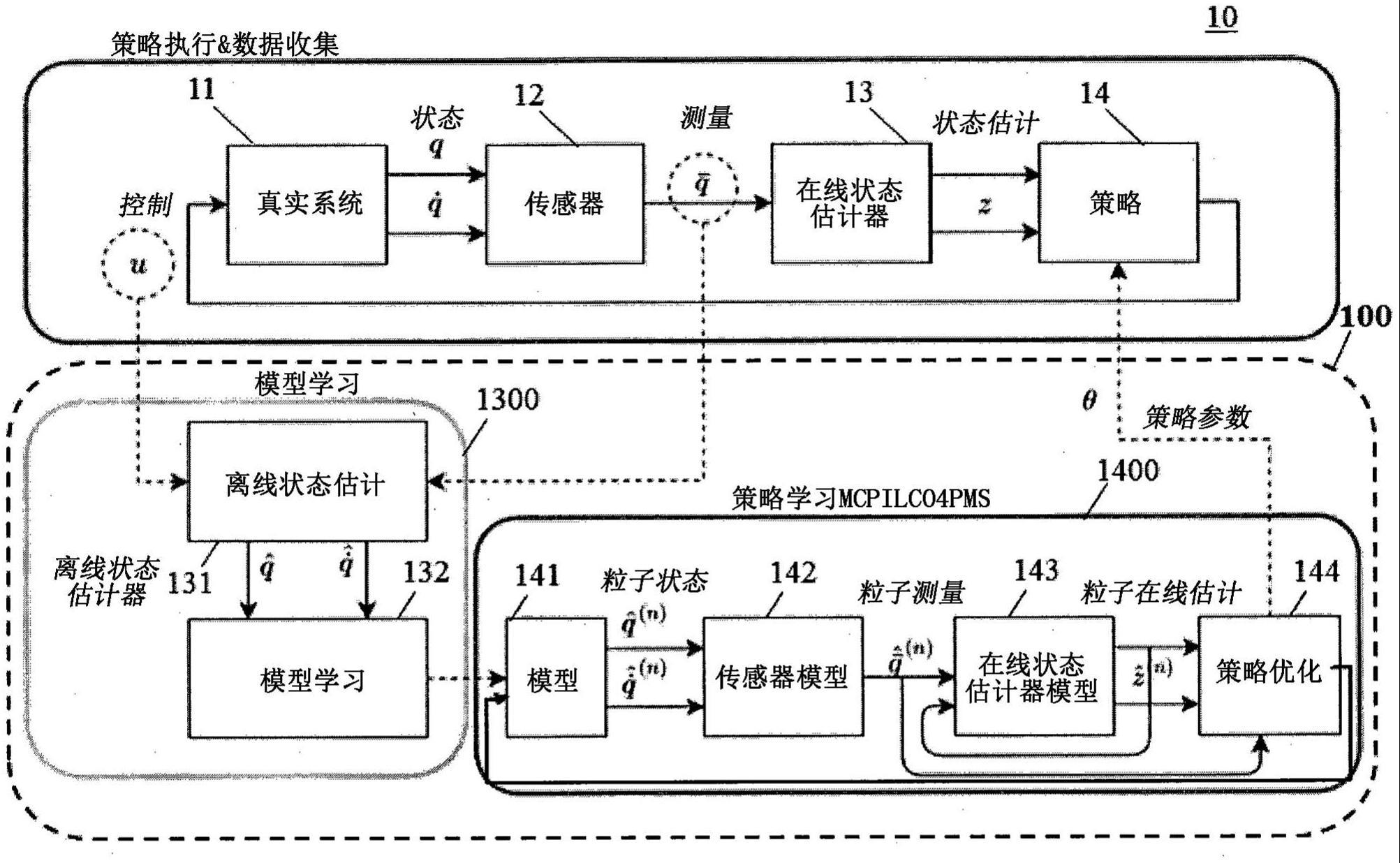
7、最后,在部分可测量系统中应用和分析mc-pilco,并且被称为mc-pilco4pms。与通常假设状态是完全可测量的模拟环境不同,真实系统的状态可能是部分可测量的。例如,大多数时候,在真实机器人系统中只有位置可直接测量,而速度通常借助估计器(诸如状态观测器、卡尔曼滤波器和具有低通滤波器的数值微分)来计算。特别地,控制器(即,策略)使用在线状态估计器的输出工作,由于噪声和实时计算约束,在线状态估计器可能引入显著的延迟以及与策略训练期间使用的滤波后的数据相关的不一致。在这种情况下,我们验证了在策略优化期间,重要的是区分由模型生成的状态(其旨在描述真实系统状态的演变)与提供给策略的状态。实际上,向控制策略提供模型预测相当于假设直接测量系统状态,如前所述,这在真实系统中是不可能的。这种错误的假设可能会由于在线状态估计器引起的失真的存在而损害训练策略进入真实系统的有效性。因此,在策略优化期间,我们根据由gp模型预测的系统状态的演变,通过对测量系统和在真实系统中使用的在线估计器两者建模而计算出观察到的状态的估计值。然后,我们将观察到的状态的估计值提供给策略。以此方式,我们旨在获得与在线滤波引起的延迟和失真相关的鲁棒性。所提出的策略的有效性已经在模拟和两个真实系统(furuta摆和球盘系统)中进行了测试。所获得的性能证实了在策略优化期间考虑真实系统中滤波器的存在的重要性。
8、本发明的一些实施方式基于以下认识:可以提供一种用于控制系统的控制器,该系统包括配置成控制系统的策略。在这种情况下,所述控制器可以包括:与所述系统连接的接口,所述接口配置成经由测量所述系统的传感器获取动作状态和测量状态;存储器,所述存储器用于存储包括模型学习模块和策略学习模块的计算机可执行程序模块;处理器,所述处理器配置成执行所述程序模块的步骤。此外,所述步骤包括:离线建模,以使用所述模型学习程序基于所述动作状态和测量状态生成离线学习状态,其中,所述模型学习模块包括离线状态估计器和模型学习模块,其中,所述离线状态估计器估计所述离线状态并将其提供给所述模型学习程序,其中,所述策略学习模块包括系统模型、传感器模型、在线状态估计器模型以及策略优化程序,其中,所述系统模型生成近似真实系统状态的粒子状态,其中,传感器模型近似粒子测量值,粒子测量值基于粒子状态近似真实系统上的测量值,其中,在线状态估计器模型配置成基于粒子测量值和可能的先前粒子在线估计生成粒子在线估计,其中,策略优化程序生成策略参数;将离线状态提供给策略学习模块以生成策略参数;以及基于策略参数更新系统的策略以操作系统。
9、根据本发明的另一实施方式,提供一种用于控制车辆的运动的车辆控制系统。车辆控制系统可以包括控制器,控制器可以包括连接到系统的接口,该接口配置成经由测量系统的传感器获取动作状态和测量状态;存储器,用于存储包括模型学习模块和策略学习模块的计算机可执行程序模块;处理器,配置成执行所述程序模块的步骤。此外,所述步骤包括:离线建模,以使用所述模型学习程序基于所述动作状态和测量状态生成离线学习状态,其中,所述模型学习模块包括离线状态估计器和模型学习模块,其中所述离线状态估计器估计离线状态并将其提供给所述模型学习程序,其中,所述策略学习模块包括系统模型、传感器模型、在线状态估计器模型以及策略优化程序,其中,系统模型生成近似真实系统状态的粒子状态,其中,传感器模型近似粒子测量值,粒子测量值基于粒子状态近似真实系统上的测量值,其中,在线状态估计器模型配置成基于粒子测量值和可能的先前粒子在线估计生成粒子在线估计,其中,策略优化程序生成策略参数;将离线状态提供给策略学习模块以生成策略参数;以及基于策略参数更新系统的策略以操作系统,其中,所述控制器连接到所述车辆的运动控制器和测量所述车辆的运动的车辆运动传感器,其中,所述控制系统基于所述运动的测量数据生成策略参数,其中,所述控制系统将所述策略参数提供给所述车辆的运动控制器以更新所述运动控制器的策略单元。
10、此外,本发明的一些实施方式提供一种用于控制机器人的运动的机器人控制系统。该机器人控制系统可以包括:连接到系统的接口,该接口配置成经由测量系统的传感器获取动作状态和测量状态;存储器,用于存储包括模型学习模块和策略学习模块的计算机可执行程序模块;处理器,配置成执行所述程序模块的步骤。此外,所述步骤包括:离线建模以使用所述模型学习程序基于所述动作状态和测量状态生成离线学习状态,其中,所述模型学习模块包括离线状态估计器和模型学习模块,其中,所述离线状态估计器估计所述离线状态并将所述离线状态提供给所述模型学习程序,其中,所述策略学习模块包括系统模型、传感器模型、在线状态估计器模型以及策略优化程序,其中,系统模型生成近似真实系统状态的粒子状态,其中,传感器模型近似粒子测量值,粒子测量值基于粒子状态近似真实系统上的测量值,其中,在线状态估计器模型配置成基于粒子测量值和可能的先前粒子在线估计生成粒子在线估计,其中,策略优化程序生成策略参数;将离线状态提供给策略学习模块以生成策略参数;以及基于策略参数更新系统的策略以操作系统,其中,所述控制器连接到所述机器人的执行器控制器和配置成测量所述机器人的状态的传感器,其中,所述控制系统基于所述传感器的测量数据生成策略参数,其中,所述控制系统将所述策略参数提供给所述机器人的执行器控制器以更新所述执行器控制器的策略单元。
- 还没有人留言评论。精彩留言会获得点赞!