用于异常检测的设备和方法与流程
本发明总体上涉及异常检测,更具体地,涉及一种使用自动编码器来检测异常的设备和方法。
背景技术:
1、异常检测通常涉及检测异常情况的任务。该任务广泛适用于诸如保障、安全、质量控制、故障监测、工艺控制等的各种应用。遍及各种应用,异常检测的目的通常是关于需要进一步调查以及潜在地响应行动的不寻常情况发出警报,以减轻任何有害问题。由于信息流巨大,人工调查和响应会成本高昂,因此异常检测系统也提供有助于说明检测原因的信息以便指导调查和适当响应将是有用的。
2、传统异常检测器使用重构输入数据的自动编码器,并且使用输入数据和重构数据之间的重构损失来检测输入数据中的异常。训练异常检测器中的主要问题之一是缺乏具有异常的训练数据。因此,被配置为检测异常的自动编码器目前基于正常的非异常数据来训练。仅在非异常数据上训练自动编码器的概念被称为单类学习,其中单类学习对“正常”(非异常)数据样本的数据分布进行建模。在这种方法中,自动编码器的重构损失充当输入数据示例(在测试时间给出)是否异常的指标,较高的重构误差指示异常,因为一般原理是自动编码器应该学习有效地重构正常数据,但对于异常数据具有较高的误差。因此,对误差进行阈值处理起到异常检测器的作用。
3、然而,用于异常检测的单类分类器可能无法正确地处理真实世界实际应用的丰富上下文,其中,用于异常检测的输入数据包括多个可能的异构特征。因此,需要一种异常检测器,其单独地分析输入数据的各个特征,以检测异常和/或提供说明所检测到的异常的原因的信息。
技术实现思路
1、一些实施方式基于这样的认识:难以获得标记的异常数据以便训练异常检测器检测异常。因此,使用无监督异常检测方法,其包括使用正常数据来训练异常检测器。当异常数据输入到已使用正常或良性数据训练的异常检测器时,它然后可检测异常数据。这种训练在本文中被称为单类分类器。
2、然而,输入数据包括多个特征。用于异常检测的单类分类器训练无法单独地分析输入数据的各个特征。因此,即使当前异常检测器检测到异常时,它们也无法提供关于输入数据的哪个特征被确定为异常的信息。这种信息对于指导所检测到的异常的调查可能非常有用。例如,一些实施方式基于这样的认识:输入数据的不同特征对异常的贡献可能不同。单独但联合地分析不同的特征可改进异常检测的准确性。
3、另外地或另选地,一些实施方式基于这样的认识:有时异常训练数据可用,但数量不足以训练多类分类器。一些实施方式基于这样的认识:当一些类训练不足时,单类分类器仍比多类分类器优选。因此,对于单类分类器的训练,忽略了异常训练数据的量不足,这是遗憾的。
4、为了解决这一问题,一些实施方式代替使用可用异常训练数据来训练多类分类器,使用异常训练数据来调整单类分类器的异常检测的阈值。这些实施方式单独或与复合损失函数组合可改进异常检测的准确性,而不会增加其训练的复杂度。
5、例如,一些实施方式对结构化序列数据执行异常检测,其中数据样本包含不同类型特征的混合。一些特征是类别,一些是来自大词汇表的词语,一些是数值。处理序列数据需要将与不同类型的特征对应的不同类型的值组合,以便检测异常。这些变化的数据类型出现在诸如互联网代理日志的序列数据中,其中一些字段是类别(命令、协议、错误代码等),一些是词语(域名、url路径、文件名等),其它是数值(数据大小、字符统计、定时等)。
6、一些实施方式使用利用单类标签模型训练的异常检测器来执行互联网代理日志数据中的异常检测,以检测对网络物理系统的网络攻击以及计算机网络中的其它恶意活动。该异常检测器的目标是帮助将网络攻击的检测和响应自动化,并且进一步提供数据为何出现异常的说明,以便指导调查和适当响应。原始互联网业务日志数据包括来自许多不同用户的互联网业务请求的日志条目,这些不同数据流在日志数据记录中固有地交织。因此,所提出的异常检测器首先将不同用户生成的日志条目的序列解交织,然后独立地处理各个用户的序列。在交织的同时简单处理所有序列的替代方案可能使自动编码器的训练过载,具有附加的不必要的复杂度。
7、一些实施方式基于这样的认识:互联网代理日志数据包括具有不同特征的异构混合的数据样本。一些特征自然地出现在数据中(代理日志条目包含数值、类别和文本字段)。互联网代理日志数据是一种序列数据。在该序列数据中,在各个序列内,数据被结构化为不同类型特征的混合。一些特征是类别,一些是来自大词汇表的词语,一些是数值。特别是,对于与互联网业务日志对应的序列数据,关键原始特征是http命令和访问的url。http命令是来自有限可能性集合(例如,get、post、head等)的类别特征的示例。然而,url由许多不同部分组成,包括协议(例如,最常见的“http”、“https”或“ftp”)、域名和顶级域,而且还可能包括子域、路径、文件名、文件扩展名和参数。尽管协议和顶级域是类别变量,但url的其余部分是可来自非常大的词汇表的一般词语和符号。因此,为了处理url特征,在一些实施方式中,url被分解为:将协议和顶级域视为类别特征,将域名和子域视为来自大词汇表的词汇,并且在路径和参数上计算数值统计。
8、为了处理域和子域词语,使用从训练数据形成最常见词语的词汇表。最常见集合之外的词语可被标记为“其它”组。然而,必要词汇表仍会非常大,使得难以处理词汇表的大小。因此,为了在训练期间处理词汇表的大小,可使用词嵌入模块,其中可针对url中存在的多个特征中的各个特征预训练词嵌入模块,以将各个词语转换为较小维度的特征向量,而非使用非常大的独热(one-hot)类别编码。因此,代替原始域/子域词语使用这些嵌入向量(即,特征向量)作为处理的特征以供自动编码器使用。
9、在一些实施方式中,对于具有数量可管理的类别的其它类别特征,类别集合可减少至仅训练期间最常见的那些,并且将其余标记“其它”类别。
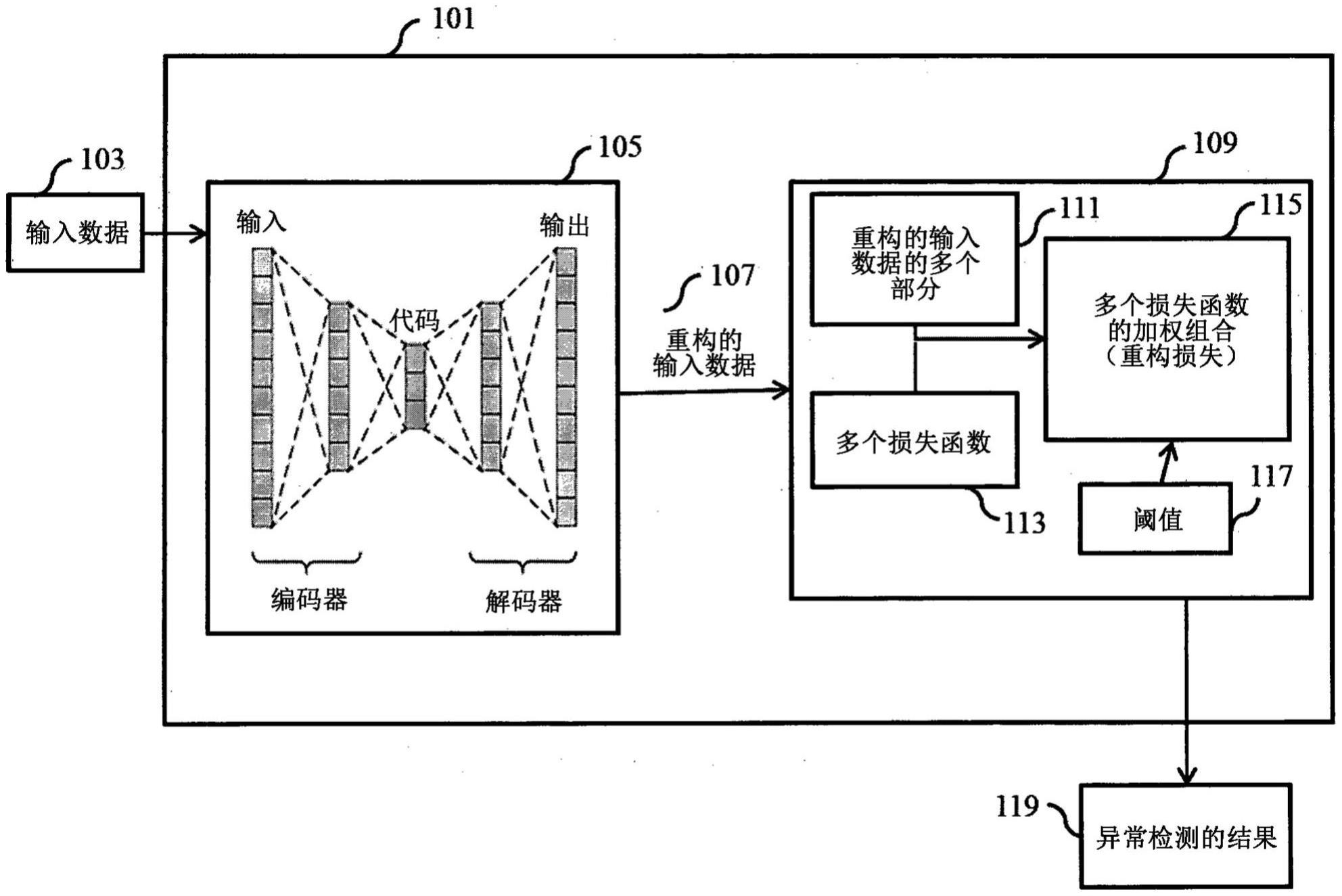
10、在一些实施方式中,异常检测器基于序列数据的多个特征将输入的序列数据的各个序列分解为多个字段。此外,与各个字段中所包括的各个特征对应的数据被向量化并级联,并提供给自动编码器。训练自动编码器以压缩并重构级联数据。通过将各个个体特征的个体损失组合来计算自动编码器训练的总体重构损失。对于嵌入的词语特征,以词嵌入特征向量的均方误差或平均绝对误差的形式测量损失。对于类别特征,通过交叉熵损失来测量损失。对于数值特征,通过数值的均方误差或平均绝对误差来测量损失。这些个体损失项作为加权平均全部被组合,以形成总体重构损失。
11、在一些实施方式中,为了覆盖不同类型的结构化序列数据,异常检测器包括灵活结构,其从以下当中提供特征选择:需要嵌入的类别特征、需要独热编码的类别特征或数值特征。因此,该灵活结构提供了为所选特征自适应地选择最佳损失函数集合的损失函数选择机制。
12、一些实施方式基于这样的认识:从数据特征的异构混合检测异常是具有挑战性的任务。异常检测器检测异常的一般方法也可应用于具有异构特征混合的其它形式的数据。例如,在计算机视觉任务中,图像的不同颜色通道可提供不同级别的信息。此外,图像可利用类似对象检测、骨架跟踪等的各种工具来预处理,这除了原始像素值之外还会产生不同的特征。在视听数据中,声音是作为混合的一部分的另一异构特征。视频数据也可除了原始图像之外还具有预处理的运动向量。例如,如果收集自各种传感器模态,则生理数据也可包括异构特征。
13、异构特征混合可利用自动编码器来处理,自动编码器联合地编码和解码所有特征,并且总体重构损失被表述为各个特征的个体损失项的加权和,其中各个损失项是该特征所特定的并且适合于该特征(例如,对于互联网代理数据:数值特征的均方误差、类别的交叉熵等)。对损失项应用权重,因为损失项可处于不同的尺度,但这些权重也可用于强调更重要的特征而不强调不太重要的特征。然而,假定数据仅包含正常样本的训练,难以知道对于区分未知类型的异常哪些特征是最重要的。因此,产生了确定并最佳地利用最重要特征的挑战。
14、在训练之后,通过确定总体重构损失并与可调阈值进行比较,自动编码器可应用于检测新数据示例中的异常。此外,为了获得异常检测中的可说明性的程度,可检查个体损失项以发现哪个(哪些)特征尤其对损失的贡献最大。这将突显最难以压缩和重构的特征,这表明它们可能是使特定数据示例异常的根源。因此,这种类型的信息可为后续调查者潜在地标出感兴趣的最异常特征。
15、因此,首先使用无监督训练离线训练自动编码器,然后利用在测试时间提供反馈的用户所生成的有限量的标记数据(监督学习)进一步在线调整自动编码器。代替在总体重构损失的计算中保持静态损失项权重和用于声明异常的固定阈值,可基于来自用户的反馈以监督方式调整这些权重和阈值。
16、此外,在将异常检测结果提供给用户的同时,用户可提供反馈,其中该反馈向异常检测器指示误警报和漏检,这为较小信息数据示例集合提供标签。利用用户所标出的这种较小标记数据集合,异常检测器可重新调整损失项权重以改进检测性能。
17、为此,重构损失被视为作为与输入数据的多个特征中的各个特征对应的个体损失项和权重的函数计算的得分。利用用户为较小示例集合指示的真实标签,基于所标记的较小示例集合来调节权重以改进检测性能。这可按在线方式实现,针对各个标记的示例仅增量地进行较小调节,因为在操作期间获得来自用户的反馈有限。在示例实施方式中,可具体地针对真实标签(通过用户反馈提供)与从重构损失和阈值计算的分类得分之间的二进制分类交叉熵损失以对权重的梯度下降步骤来实现该调节。
18、此外,在反馈中,用户还可大致指示在误警报对漏检权衡曲线上用户希望在哪里操作(即,用户可指示用户是希望具有更好的检测率,代价是误警报更多,还是用户希望具有更少的警报,代价是漏检更多)。因此,用于比较总体重构损失以检测异常的阈值响应于用户的反馈而增大/减小。然而,为了进行阈值的校准调节以实现用户所指示的特定权衡点,通过用户反馈生成的标记示例的较小集合可用于调整阈值,使得异常检测器以期望的误警报对漏检权衡执行。
19、因此,实施方式之一公开了一种异常检测器,该异常检测器包括:输入接口,其被配置为接受输入数据;至少一个处理器;以及存储器,其上存储有形成异常检测器的模块的指令,其中至少一个处理器被配置为执行异常检测器的模块的指令。所述模块包括:自动编码器,其包括被训练以对输入数据进行编码的编码器以及被训练以对编码的输入数据进行解码以重构输入数据的解码器。所述模块还包括分类器,其被训练以确定指示所接受的输入数据与重构的输入数据之间的差异的重构损失,其中重构损失包括评估重构的输入数据的多个部分的重构损失的多个损失函数的加权组合、不同类型的损失函数或二者。分类器模块还被配置为当重构损失高于阈值时,检测重构的输入数据中的异常。异常检测器还包括输出接口,其被配置为渲染异常检测的结果。
20、因此,实施方式之一公开了一种用于检测异常的方法。该方法包括以下步骤:接收输入数据;对输入数据进行编码;对编码的输入数据进行解码,以重构输入数据。该方法还包括以下步骤:确定指示所接受的输入数据与重构的输入数据之间的差异的重构损失,其中重构损失包括评估重构的输入数据的多个部分的重构损失的多个损失函数的加权组合、不同类型的损失函数或二者;当重构损失高于阈值时,检测重构的输入数据中的异常;以及渲染异常检测的结果。
- 还没有人留言评论。精彩留言会获得点赞!