政策文件智能解析与结构化方法及系统与流程
1.本发明属于人工智能技术领域,具体涉及政策文件智能解析与结构化方法及系统。
背景技术:
2.政策是政府机关为了统筹社会的健康发展,设定的奋斗目标以及为了实现该目标需要采取的步骤和措施。特别的,为了推动经济的进步和产业结构的优化,权力机关会经常性的下发具有引导性的政策文本,这些政策文本往往包含了具体的奖励措施和对应的条件,对象一般是企业和个人。政策奖励意味着企业可以享受到的权益,而政策条件则是享受该权益所需要满足的条件。
3.面对庞大的政策文本,个人或企业往往难以根据自身所具有的条件申报对应的奖励。现有的政策软件及网站往往也只是简单对政策文本进行分类,没有深入政策解析其奖励措施和申报条件。
4.现有的政策解析技术十分简单,通常针对大量政策,人工将政策拆解,并且将知识归纳到数据库中;或者使用正则表达式对政策中一些固定的表达拆解;另外,或者采用基于自然语言处理技术,对政策文本进行语义解析。
5.因此,现有的政策解析技术存在以下缺点:1.人工解析费时费力,且需要一定的专家知识,并且人工成本过高;2.基于正则表达式的自动解析方法严重依赖于正则表达式编写人员所接触到的政策文本,对于其未见过的政策描述的拟合性极差,并且基于正则表达式的解析方式容易有规则冲突,造成解析失败。
6.3.基于语义解析的方法要优于基于正则表达式的自动解析方法,但是目前的政策解析技术都只是对政策的简单解析,例如无法做到政策条件和奖励文本的精准识别,也缺少对政策条件和奖励关系识别的支持,泛化性能不强,且准确率不高。
7.政策有着复杂度高,文本超长的特点,以往的语义解析技术无法实现直接对超长文本建立端到端的模型,会造成特征的缺失,在这种情况下,无法做到全局的条件和奖励的关系对应,只能识别奖励文本周围出现的部分限制条件;另外,以往的语义解析技术只能做到简单的条件奖励的文本识别,无法归纳意义相近的条件,在政策数量极多的情况下,会使数据量变得非常庞大,这样会对数据库的构建以及后续的使用造成不便。
8.因此,设计一种节约人工成本,能实现对复杂政策文本的深度解析,能自动抽取政策文本的奖励措施和申报条件的政策文件智能解析与结构化方法及系统,就显得十分重要。
9.例如,申请号为cn201910542701.0的中国专利文献描述的一种政策研究解读方法、系统、存储介质和服务器,录入政策原文件,对政策原文件进行分析解读,为政策原文件制定用于企业申报指引的知识库,用户通过知识库的指引可快速获知自身是否具备申报资格,若用户具备申报资格,还可以向系统提出申报请求,系统自动为其进行项目申报。虽然
通过研究各项政府扶持政策后,把政策转化为企业便于理解的各项指标,并录入保存知识库,便于企业快速获知理解各种政策,为企业节省大量政策解读时间,提高企业的申报效率和项目通过率,满足使用要求,但是其缺点在于,无法抽取政策文本的奖励措施,进而无法通过实现解析政策的奖励措施以及对应的申报条件信息,来进行快速解读,方案使用具有局限性。
技术实现要素:
10.本发明是为了克服现有技术中,现有的政策解析技术存在需要依靠人力梳理,费时费力,且人工成本过高的问题,提供了一种节约人工成本,能实现对复杂政策文本的深度解析,能自动抽取政策文本的奖励措施和申报条件的政策文件智能解析与结构化方法及系统。
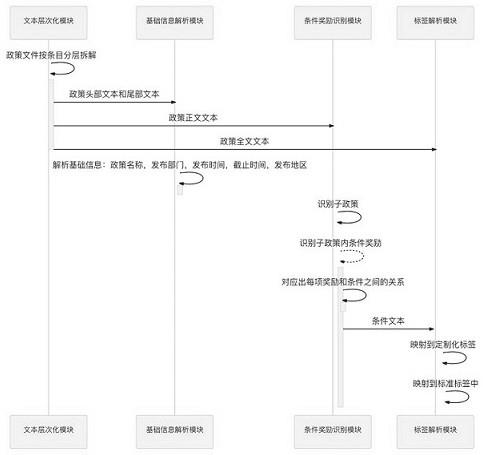
11.为了达到上述发明目的,本发明采用以下技术方案:政策文件智能解析与结构化方法,包括如下步骤;s1,将政策文件按条目分层进行拆解,获得不同分层层级的数据并以数据结构树的形式进行存储;s2,对数据结构树的不同区域进行数据识别,获得需要的政策文件信息数据;s3,使用图卷积网络和基于已建立的政策预训练模型训练出的政策条件奖励识别模型,识别出包含奖励措施和奖励措施对应的申报条件信息;s4,根据已建立的政策预训练模型,以增加下游任务的形式,训练出政策标签提炼模型,将申报条件信息提炼成标签,同时将各个奖励措施归纳到对应的行业和产业领域。
12.作为优选,步骤s2包括如下步骤:步骤s21,在数据结构树中政策的头部及尾部区域,以正则表达式与命名实体识别结合的方式识别政策名;步骤s22,在数据结构树中政策的头部及尾部区域,以命名实体识别的方式识别发布部门;步骤s23,在数据结构树中政策的头部及尾部区域,以关键词检索的方式识别发布地区;步骤s24,在数据结构树中政策的头部及尾部区域,识别发布时间,截止时间,并将不同风格的时间描述成统一格式文本。
13.作为优选,所述政策预训练模型的构建方法如下:将获取到的真实政策文本,权力机关文书以及维基百科文本进行数据清洗,去除非自然语言部分,所述自然语言部分包括图片和链接;将文本用句号隔开,限制最大长度为512,超出最大长度部分截断;将文本转换成训练需要的数据中,每个字符以90%的概率保持不变,10%的概率使用字符[mask]替换当前字符;将两个句子拼接到一起作为输入,按照[句子1,句子2]的方式送入基于变换器的双向编码器表示模型,基于变换器的双向编码器表示模型在训练中的输出为:预测句子1,句子2是否连贯,并且预测字符[mask]原本对应的字符;根据反向传播原理来更新政策预训练模型的参数,完成训练目的。
[0014]
作为优选,步骤s3包括如下步骤:s31,将数据结构树视为一个含有多个节点的有向无环图,每个节点均对应一段文本,利用政策预训练模型将每段文本均计算为一个低维向量;s32,利用图卷积网络,让每个节点的低维向量与周围节点的低维向量结合,重新计算一个新的向量,并将所述新的向量替代节点原来的低维向量;s33,根据所述新的向量,识别出包含奖励措施和奖励措施对应的申报条件信息;s34,在政策预训练模型的基础上,增加信息识别的下游任务模块并训练为政策条件奖励识别模型,识别出申报条件信息中的具体条件信息和奖励措施中的具体奖励信息。
[0015]
作为优选,步骤s4包括如下步骤:s41,根据已有标注的包含标签的条件文本数据,基于政策预训练模型增加下游标签提炼任务,以训练政策标签提炼模型;s42,利用政策标签提炼模型,进行条件值识别,将申报条件信息提炼成标签;s43,将各个奖励措施归纳到对应的行业和产业领域。
[0016]
作为优选,步骤s43还包括如下步骤:当奖励措施对应的申报条件信息内无明显行业和产业领域时,则自动将所述奖励措施纳入到政策文件所适用的行业和产业领域。
[0017]
本发明还提供了政策文件智能解析与结构化系统,包括;文本层次化模块,用于将政策文件按条目分层进行拆解,获得不同分层层级的数据并以数据结构树的形式进行存储;基础信息解析模块,用于对数据结构树的不同区域进行数据识别,获得需要的政策文件信息数据;条件奖励识别模块,用于根据图卷积网络和政策条件奖励识别模型,识别出包含奖励措施和奖励措施对应的申报条件信息;标签解析模块,用于根据已建立的政策预训练模型,以增加下游任务的形式,训练出政策标签提炼模型,将申报条件信息提炼成标签,同时将各个奖励措施归纳到对应的行业和产业领域。
[0018]
作为优选,政策文件智能解析与结构化系统还包括:政策预训练模型构建模块,用于使用若干个真实政策文本,权力机关文书以及维基百科文本,对基于变换器的双向编码器表示模型进行预训练,构建政策预训练模型。
[0019]
作为优选,所述条件奖励识别模块还包括:政策条件奖励识别模型构建模块,用于在预训练政策模型的基础上,增加信息识别的下游任务模块并训练为政策条件奖励识别模型,以识别出申报条件信息中的具体条件信息和奖励措施中的具体奖励信息。
[0020]
作为优选,政策文件智能解析与结构化系统还包括:政策标签提炼模型构建模块,用于根据已有标注的包含标签的条件文本数据,以增加下游任务的形式,对政策预训练模型进行训练,得到政策标签提炼模型。
[0021]
本发明与现有技术相比,有益效果是:(1)本发明打造了一套用于结构化政策文本的规则引擎,对于各种复杂的政策文本,都可以将政策文本按条目分层拆解开来,同时可以将文本的不同部分应用于下游不同的识别任务,提升下游任务的识别准确率;(2)本发明创
新性地将图卷积网络融入,将每个条目的文本视为节点,利用图卷积网络的节点关系拟合能力,配合规则引擎拆解出的结构化数据,可以对超长政策文本建模,并能识别所有层级中条件和奖励之间的关系;(3)本发明将人工智能方法和专家指导模块进行有机结合 ,提炼出一些通用的标签,通过引入命名实体识别模型,在冗长的条件文本中,提炼出有价值的特征值,为后续的使用提供了简洁,可靠的数据。
附图说明
[0022]
图1为本发明政策文件智能解析与结构化方法的一种流程图;图2为本发明实施例所提供的某地区政策文件的一种示意图;图3为利用本发明将图2中的文本进行分层拆解的一种示意图;图4为利用本发明将图2中的文本进行识别并解析的一种示意图;图5为利用本发明将图2中的文本进行识别具体条件信息和奖励信息以及将条件信息标签化过程的一种示意图。
具体实施方式
[0023]
为了更清楚地说明本发明实施例,下面将对照附图说明本发明的具体实施方式。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,并获得其他的实施方式。
[0024]
实施例1:如图1所示的政策文件智能解析与结构化方法,包括如下步骤;s1,将政策文件按条目分层进行拆解,获得不同分层层级的数据并以数据结构树的形式进行存储;s2,对数据结构树的不同区域进行数据识别,获得需要的政策文件信息数据;s3,使用图卷积网络和基于已建立的政策预训练模型训练出的政策条件奖励识别模型,识别出包含奖励措施和奖励措施对应的申报条件信息;s4,根据已建立的政策预训练模型,以增加下游任务的形式,训练出政策标签提炼模型,将申报条件信息提炼成标签,同时将各个奖励措施归纳到对应的行业和产业领域。
[0025]
进一步的,步骤s2包括如下步骤:步骤s21,在数据结构树中政策的头部及尾部区域,以正则表达式与命名实体识别结合的方式识别政策名;步骤s22,在数据结构树中政策的头部及尾部区域,以命名实体识别的方式识别发布部门;步骤s23,在数据结构树中政策的头部及尾部区域,以关键词检索的方式识别发布地区;其中,发布地区并按照行政区域划分形成-省(自治区、直辖市)-市-县区结构;步骤s24,在数据结构树中政策的头部及尾部区域,识别发布时间,截止时间,并将不同风格的时间描述成统一格式文本;如2020年7月八日下午三点零五分,2020年7月8号15:05,都将统一成2010-07-08 15:05。
[0026]
进一步的,所述政策预训练模型的构建方法如下:将获取到的真实政策文本,权力机关文书以及维基百科文本进行数据清洗,去除非自然语言部分,所述自然语言部分包括图片和链接;将文本用句号隔开,限制最大长度为512,超出最大长度部分截断;将文本转换成训练需要的数据中,每个字符以90%的概率保持不变,10%的概率使用字符[mask]替换当前字符;将两个句子拼接到一起作为输入,按照[句子1,句子2]的方式送入基于变换器的双向编码器表示模型,基于变换器的双向编码器表示模型在训练中的输出为:预测句子1,句子2是否连贯,并且预测字符[mask]原本对应的字符;根据反向传播原理来更新政策预训练模型的参数,完成训练目的。
[0027]
进一步的,步骤s3包括如下步骤:s31,将数据结构树视为一个含有多个节点的有向无环图,每个节点均对应一段文本,利用政策预训练模型将每段文本均计算为一个低维向量;s32,利用图卷积网络,让每个节点的低维向量与周围节点的低维向量结合,重新计算一个新的向量,并将所述新的向量替代节点原来的低维向量;s33,根据所述新的向量,识别出包含奖励措施和奖励措施对应的申报条件信息;s34,在政策预训练模型的基础上,增加信息识别的下游任务模块并训练为政策条件奖励识别模型,识别出申报条件信息中的具体条件信息和奖励措施中的具体奖励信息。
[0028]
其中,下游任务模块的做法是:输入文本,政策预训练模型会给出文本中每一个字的向量,使用softmax计算出该字符属于条件信息或者奖励信息的概率,最后就能得到该文本的具体条件文本或者具体奖励文本。
[0029]
进一步的,步骤s4包括如下步骤:s41,根据已有标注的包含标签的条件文本数据,基于政策预训练模型增加下游标签提炼任务,以训练政策标签提炼模型;增加下游任务模块的做法是:输入文本和标签,政策预训练模型会给出文本中每一个字的向量,然后利用条件随机场算法综合这些向量和这些向量的顺序得出文本中字符属于某些标签概率。
[0030]
s42,利用政策标签提炼模型,进行条件值识别,将申报条件信息提炼成标签;s43,将各个奖励措施归纳到对应的行业和产业领域。
[0031]
进一步的,步骤s43还包括如下步骤:当奖励措施对应的申报条件信息内无明显行业和产业领域时,则自动将所述奖励措施纳入到政策文件所适用的行业和产业领域。
[0032]
如图1所示,本发明还提供了政策文件智能解析与结构化系统,包括;文本层次化模块,用于将政策文件按条目分层进行拆解,获得不同分层层级的数据并以数据结构树的形式进行存储;基础信息解析模块,用于对数据结构树的不同区域进行数据识别,获得需要的政策文件信息数据;条件奖励识别模块,用于根据图卷积网络和政策条件奖励识别模型,识别出包含奖励措施和奖励措施对应的申报条件信息;
标签解析模块,用于根据已建立的政策预训练模型,以增加下游任务的形式,训练出政策标签提炼模型,将申报条件信息提炼成标签,同时将各个奖励措施归纳到对应的行业和产业领域。
[0033]
进一步的,政策文件智能解析与结构化系统还包括:政策预训练模型构建模块,用于使用若干个真实政策文本,权力机关文书以及维基百科文本,对基于变换器的双向编码器表示模型进行预训练,构建政策预训练模型。
[0034]
进一步的,所述条件奖励识别模块还包括:政策条件奖励识别模型构建模块,用于在预训练政策模型的基础上,增加信息识别的下游任务模块并训练为政策条件奖励识别模型,以识别出申报条件信息中的具体条件信息和奖励措施中的具体奖励信息。
[0035]
进一步的,政策文件智能解析与结构化系统还包括:政策标签提炼模型构建模块,用于根据已有标注的包含标签的条件文本数据,以增加下游任务的形式,对政策预训练模型进行训练,得到政策标签提炼模型。
[0036]
基于本发明的技术方案,在具体实施和操作过程中的一个政策文件解析过程如图2至图5所示:首先判断数据的格式,并用不同的工具,将政策文件内的文字提取出来。如果是图片,则利用ocr能力将文字提取出来,采用pdf、doc的解析工具包进行直接转换和提取。
[0037]
以政策《2018年某地区扶持产业发展政策》为例,输入文本如图2,正文部分略。
[0038]
利用本发明提供的规则引擎将文本层模块化,如图3所示。利用文中的标号,通过规则引擎,将文本层级化,并将不同标号和其下的内容组织在一起,即实现步骤s1的过程。
[0039]
接着在基础信息解析模块,将上文本层次化模块中层次化内容的头部和尾部数据送入基础信息模块,解析出如图4所示的基础信息。
[0040]
再利用图卷积网络模型,识别正文各个段落之间的条件奖励关系,具体实现是将各个节点的文本通过bert模型向量化,然后将向量以层次化的结构输入图卷积网络模型,让图卷积网络拟合节点之间的关系,然后将各个节点之间的关系识别出来。例如,第十、附则中的一些条件限制是针对该政策中所有的子政策,即要享受该政策的某条子政策,除了要满足该子政策中的条件,还需要满足第十、附则中的条件限制。如图5所示的a模块,由图卷积网络模型识别出条件奖励关系。进一步由政策条件奖励识别模型识别得到条件信息和奖励信息,并得到他们的条件奖励关系。
[0041]
最后,在上一步解析出来的条件中,需要将其标签化,如图5所示b模块,在模块a中识别出的条件语句中,识别出其中的标签信息。也就是将条件再次精炼,纳入到一定的标签中,方便后续的检索与使用。例如针对下列子政策:【对某区医疗机构首次获得国家药品(器械)临床试验机构(gcp)资质(i期、ii期、iii期)的,给予一次性奖励20万元。】有条件:【某区医疗机构首次获得国家药品(器械)临床试验机构(gcp)资质(i期、ii期、iii期)】精炼出的标签为:企业所在地:某区;
企业类型:医疗机构;企业资质:国家药品(器械)临床试验机构(gcp)资质(i期、ii期、iii期)。
[0042]
本发明融合多种技术手段,基于规则引擎与语义解析技术打造的政策解析技术可以自动解析复杂,超长的政策文件,并运用专家提炼的通用特征来缩减条件范围,可以极大减少政策梳理需要的人力投入,解析后的政策信息能更简单、快速、精准地被使用者检索到;本发明利用规则引擎,结合图卷积网络聚合文本特征,提炼条件信息缩减奖励的搜索空间,能够极大增强政策解析能力。
[0043]
以上所述仅是对本发明的优选实施例及原理进行了详细说明,对本领域的普通技术人员而言,依据本发明提供的思想,在具体实施方式上会有改变之处,而这些改变也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1