一种基于标签的司法案例推荐方法与流程
1.本发明涉及计算机应用技术领域,尤其涉及一种基于标签的司法案例推荐方法。
背景技术:
2.基于内容的推荐(content-based recommendation)是信息过滤技术的延续与发展,它是建立在项目的内容信息上做出推荐的,而不需要依据用户对项目的评价意见,更多地需要用机器学习的方法从关于内容的特征描述的事例中得到用户的兴趣资料。在基于内容的推荐系统中,项目或对象是通过相关的特征的属性来定义,系统基于用户评价对象的特征,学习用户的兴趣,考察用户资料与待预测项目的相匹配程度。用户的资料模型取决于所用学习方法,常用的有决策树、神经网络和基于向量的表示方法等。
3.传统技术使用tf/idf计算案例相关性;案例标签人工分类处理;协同过滤推荐,推荐方法的主要瓶颈是在权衡方面:随着推荐变得越来越细,就很容易将人们限制在一个已经受益的领域。标签体系可以动态扩展推荐维度;推荐方法的结果除了依赖于算法的选择之外,对数据也比较敏感,如何避免人工标签对推荐系统的结果带来的偏差,都需要更多的突破。根据描述得知,存在以下问题:1)tf/idf处理案例相关性需要大量计算,随着数据量增多,计算量呈指数形式增长。2)使用标签系统,但是存在大量的人工处理,主观的处理方式对推荐系统的结果带来的偏差。3)推荐方式没有区分场景,无法达到预期效果。
技术实现要素:
4.为了解决上述技术所存在的不足之处,本发明提供了一种基于标签的司法案例推荐方法。
5.为了解决以上技术问题,本发明采用的技术方案是:一种基于标签的司法案例推荐方法,包括如下步骤:
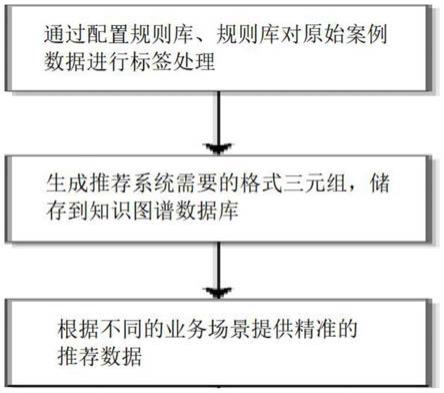
6.s1通过配置规则库、规则库对原始案例数据进行标签处理;
7.s2生成推荐系统需要的格式三元组,储存到知识图谱数据库;
8.s3根据不同的业务场景提供精准的推荐数据。
9.进一步地,s1通过配置规则库、规则库对案例数据进行标签处理包括如下步骤:
10.s11为原始案例数据设立规则库;
11.s12利用规则库中的规则组,利用自然语言处理系统对原始案例数据进行属性识别抽取;
12.s13通过大数据计算平台对识别的属性进行归类,生成结构化标签数据,结构化标签数据统一汇总成标签库。
13.进一步地,述s2生成推荐系统需要的格式三元组,储存到知识图谱数据库包括如下步骤:
14.s21基于s13生成的结构化标签数据,识别推荐相关联的标签实体;
15.s22基于知识库对实体进行标签消歧,同名异义折分,异名同义合并,生成实体唯
一id;
16.s23识别案例与实体之间依赖关系,生成三元组并入库。
17.进一步地,s12利用规则库中的规则组,利用自然语言处理系统对原始案例数据进行属性识别抽取包括如下步骤:
18.s111定义调用任务接口,开始计算任务的入口;
19.s112获取一个标签类目下的所有标签或者一个标签对应的规则;
20.s113从任务队列中读取需要计算的数据。
21.进一步地,s13通过大数据计算平台对识别的属性进行归类,生成结构化标签数据,结构化标签数据统一汇总成标签库包括如下步骤:
22.s131流程调用计算单一规则,并将计算结果按预期进行类型转换、属性更新,复杂个性规则通过动态脚本引擎计算结果;
23.s132流程执行一个标签对应的一个或多个规则并将规则计算结果按预期设置返回,实现一个标签计算;
24.s133计算一个类目下所有标签。
25.本发明公开了一种基于标签的司法案例推荐方法,应用本发明所提供的技术方案,可以达到如下有益效果:
26.1)利用规则库大幅度提高属性识别的准确性,规则库可动态扩展实现个性化推荐。
27.2)依托于大数据计算技术,提高数据吞吐量,并且减少人工标注的主观性数据偏差。
28.3)根据实际应用抽象多类推荐场景,实现精准化推荐,对辅助办案、案例发现提供帮助,提高工作效率。
附图说明
29.图1为本发明的流程示意图。
30.图2为本发明的三元组数据生成示意视图。
31.图3为知识图谱数据示意图。
32.图4为累计权重计算示意图。
具体实施方式
33.下面结合附图和具体实施方式对本发明作进一步详细的说明。
34.本发明为了快速准确的对案件打标签,提供多种案例推荐方式。实现案例从原始文本文档开始,根据规则库、标签库的配置,使用大数据批量计算,快速处理数据,并利用知识图谱技术根据业务场景实现快速推荐,使用利用知识图谱可以提高查询及推荐结果的深度和广度。具体如下
35.(一)如图1所示的标签处理
36.s1通过配置规则库、规则库对原始案例数据进行标签处理;
37.(二)如图2所示的三元组关系生成
38.s2生成推荐系统需要的格式三元组,储存到知识图谱数据库;
39.(二)三元组关系生成
40.s3根据不同的业务场景提供精准的推荐数据。
41.s1通过配置规则库、规则库对案例数据进行标签处理包括如下步骤:
42.s11为原始案例数据设立规则库,规则库的设置规则:
43.a.每个规则组处理一个属性;
44.b.规则类型可以是正则表达式、决策树、内部函数调用、外部api等方式;
45.c.每个规则设置终止逻辑;
46.d.规则间计算结果可以传递;
47.e.在多个规则都无效的情况下给出默认值;
48.f.返回内容进行数据类型转换;
49.g.有多个返回值的情况可以设置返回值处理方法;
50.h.返回值支持操作方式设置(如:新增,更新,替换)。
51.规则设置成功后,也可以供其他数据项使用,积累成规则库。
52.从已有规则或新建规则中按数据处理要求及顺序,生成数据处理规则组,规则组按以管道流的形式处理数据,后续规则可以使用前面已经处理规则的结果,直至数据项处理完成。
53.s12利用规则库中的规则组,利用自然语言处理系统对原始案例数据进行属性识别抽取;s12利用规则库中的规则组,利用自然语言处理系统对原始案例数据进行属性识别抽取包括如下步骤:
54.s111定义调用任务接口,开始计算任务的入口;
55.s112获取一个标签类目下的所有标签或者一个标签对应的规则;
56.s113从任务队列中读取需要计算的数据。
57.s13通过大数据计算平台对识别的属性进行归类,生成结构化标签数据,结构化标签数据统一汇总成标签库。s13通过大数据计算平台对识别的属性进行归类,生成结构化标签数据,结构化标签数据统一汇总成标签库包括如下步骤:
58.s131流程调用计算单一规则,并将计算结果按预期进行类型转换、属性更新,复杂个性规则通过动态脚本引擎计算结果;
59.s132流程执行一个标签对应的一个或多个规则并将规则计算结果按预期设置返回,实现一个标签计算;
60.s133计算一个类目下所有标签。
61.s2生成推荐系统需要的格式三元组,储存到知识图谱数据库包括如下步骤:
62.实体提取:s21基于s13生成的结构化标签数据,识别推荐相关联的标签实体;
63.实体识别:s22基于知识库对实体进行标签消歧,同名异义折分,异名同义合并,生成实体唯一id(实体编码);
64.三元组数据构建:s23识别案例与实体之间依赖关系,生成三元组并入库。
65.设计标签库,根据属性集自定义标签计算逻辑:
66.指定标签特征值,即标签的判定条件;
67.某一属性值等于(大于、小于、包含、不包含、count(*)》1)某个值,或多个值;多个属性混合判断,即上述多个条件的逻辑与(and)、逻辑或(or)操作最终判断条件结果为真时
打指定标签;选取特征值需要的属性集,即上述a步骤中涉及的所有属性;配置运算逻辑,通过值域划分、名称映射、ai分类等方式进行打标签操作。
68.数据计算:
69.使用大数据平台批量处理案例,生成结构化标签数据,保存至文档数据库。
70.三元组数据生成:
71.基于步骤3生成的标签数据,识别推荐相关联的标签实体。
72.基于知识库对实体进行消歧,同名异义折分,异名同义合并,生成实体唯一id。
73.识别案例与实体之间依赖关系,生成(案例、关系、标签)三元组并入库,如(案例a,发生地,城市a),(案例a,当事人,李某),(案例a,处理时间,2019-01-23)。
74.下面结合具体案例,根据实际的业务场景,抽象多种推荐方式:
75.通过指定关联关系递归推荐数据,并根据路径深度返回不同结果;
76.如图3所示的知识图谱数据为例,从案例a1为起点,指定关系“关联案件”,推荐过程如下:
77.与a1关联案件直接推荐案例a4,路径深度为1;
78.递归与a4关联案件间接推荐案例a7,a3,a5,路径深度为2;
79.递归深度为2的a7无关联案件,a7分支递归结束;
80.递归深度为2的a3关联案件推荐案例a9,a2,a5,路径深度为3,因为a5已在推荐结果中,a5深度保持2;
81.递归深度为2的a5关联案件推荐案例a2,a8,a6,路径深度3,a2已存在,去重;
82.递归深度为3的案例a9,a2,a8,a6,所有关联案件都已经在推荐结果中,无深度为4的案例,递归结束;
83.通过两实体间命中路径的累计权重进行推荐。
84.如图3所示的知识图谱数据为例,包括案例1和案例2两个案例,通过以下的关系命中多个实体,每个命中的关系按以下表格设置初始权重。
85.关系名权重关键字50(每命中同一关键字)关联公司30执法机关20行政区划20
86.权重计算过程如下:
87.案例1与案例2:命中相同的关联公司,即a公司,权重为30,累计权重为30;
88.案例1与案例2:发生在同一行政区划发生地,即b地区,权重为20,累计权重50;
89.案例1与案例2:被同一执法机关执行,即环保局,权重为20,累计权重70;
90.案例1与案例2:命中三个关键字,“环境保护”、“大气污染”、“生产”,权重为50*3=150,累计权重为220;
91.在图数据库分别按上述方法与起点案例计算命中的累计权重和,并案权重和值从大到小排序,取前5条结果作为处理结果。
92.智能调整权重:
93.初始状态每条数据会设置默认权重,根据收集推荐数据的浏览情况,主要有以下
几个权重加分项:
94.1)对点击率高的数据;
95.2)用户在页面的停留时间长的数据;
96.3)1天内回看的次数多的数据。
97.减分项:
98.1)页面打开停留时间小于平均阅读时长;
99.2)数据权重每天根据以上逻辑统计汇总,重新生成新的权重,推荐时权重高的优先推荐。
100.应用本发明所提供的技术方案,可以达到如下有益效果:
101.1)利用规则库大幅度提高属性识别的准确性,规则库可动态扩展实现个性化推荐。
102.2)依托于大数据计算技术,提高数据吞吐量,并且减少人工标注的主观性数据偏差。
103.3)根据实际应用抽象多类推荐场景,实现精准化推荐,对辅助办案、案例发现提供帮助,提高工作效率。
104.上述实施方式并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的技术方案范围内所做出的变化、改型、添加或替换,也均属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1