一种数据查看引擎动态调用方法与流程
1.本发明涉及数据加工技术领域,具体为一种数据查看引擎动态调用方法。
背景技术:
2.在大数据场景下,通过数据挖掘建模从大量、繁杂的数据中挖掘出有价值的规律是常见且重要的工作。数据挖掘是人工智能和数据库领域研究的热点问题,所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程,数据挖掘是通过分析每个数据,从大量数据中寻找其规律的技术,主要有数据准备、规律寻找和规律表示三个步骤。数据准备是从相关的数据源中选取所需的数据并整合成用于数据挖掘的数据集;规律寻找是用某种方法将数据集所含的规律找出来;规律表示是尽可能以用户可理解的方式将找出的规律表示出来,数据挖掘的任务有关联分析、聚类分析、分类分析、异常分析、特异群组分析和演变分析等,由于数据挖掘的工作不是一蹴而就的,用户需要经过大量的尝试,其中80%的工作都是在对大量的数据做清洗、加工、试建模等工作,在这一过程中,用户需要经常查看操作后生成的数据以了解工作的进展。然而由于用户查看数据的频率比较高,而且涉及到的数据量通常会很大,因为在大数据场景中,数据量经常是gb甚至于pb级的,运算此量级的数据需要大规模的服务器集群资源才能完成,频繁查看大量数据会耗费大量的网络资源和计算资源,而且读取全量数据的速度会比较低下,导致建模效率较低,用户并发弱。
3.为此,我们提出一种数据查看引擎动态调用方法。
技术实现要素:
4.鉴于上述和/或现有一种数据查看引擎动态调用方法中存在的问题,提出了本发明。
5.因此,本发明的目的是提供一种数据查看引擎动态调用方法,通过在数据挖掘过程中,针对不同的用户需求场景,提供不同的计算引擎,分别处理不同数据量的数据,从而解决在数据挖掘频繁读取并查看全量数据带来的网络资源和计算资源的浪费,提升查看数据的效率,从而推动建模效率的提高。
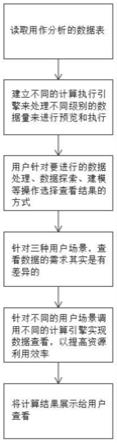
6.为解决上述技术问题,根据本发明的一个方面,本发明提供了如下技术方案:一种数据查看引擎动态调用方法,其包括具体步骤如下:s1,读取用作分析的数据表:用户通过一种编程语言,从数据源中读取要分析用的数据表;s2,建立不同的计算执行引擎来处理不同级别的数据量来进行预览和执行,预览为取部分数据进行执行,执行为取全部数据进行执行,用于预览的资源可为单机服务器配置,资源消耗较小支持用户并发数较大,全量数据执行为基于多服务器的hadoop的分布式计算引擎,为服务器集群,资源消耗较大且并发用户较小,根据此配置初始化不同两级的执行引擎,为后续用户操作提供数据处理支持;
s3,用户针对要进行的数据处理、数据探索、建模等操作选择查看结果的方式:用户使用编程语言,对数据进行加工处理,也就是进行各种行之间或列之间的操作,而在进行操作时,用户会面临如下三种操作场景:场景一:用户对数据做了处理,想查看数据处理的结果;场景二:用户数据生成了可视化图形、图表等,想查看可视化结果;场景三:用户使用数据挖掘算法应用全量数据进行建模;s4,针对三种用户场景,查看数据的需求其实是有差异的:针对场景一,用户查看数据的目的是确认操作结果是否正确且有效,在这种情况下,考虑到数据量非常大,用户只需要查看部分数据,也就是通过预览即可掌握操作的结果是否正确且有效;针对场景二,由于图形和报表的生成需要用到全量数据,因此这些操作需要用到全量数据才能实现;针对场景三,应用数据挖掘算法建模的过程需要用到全量数据,因此查看建模结果需要用到全量数据才能实现;s5,针对不同的用户场景调用s2提供的不同的计算引擎实现数据查看,以提高资源利用效率;如果操作是场景一,则从全量数据中抽取前n条数据,可以根据用户的选择进行配置,由于数据量小,应用单机服务器配置的计算引擎就可以进行计算,也就是将选中的数据全部交给一台服务器来做计算,并将计算结果返回并提供给用户预览;如果操作是场景二或场景三则使用服务器集群类进行计算,也就是将全部数据划分成若干小块,给集群中的每台服务器分配其中的一块任务,任务分头执行完毕后,将每一块的结果进行汇总,形成全量数据的结果,并将结果提供给用户查看;s6,将s5的计算结果展示给用户查看。
7.作为本发明所述的一种数据查看引擎动态调用方法的一种优选方案,其中:所述s1中,编程语言为sql、r、python中的其中一种。
8.作为本发明所述的一种数据查看引擎动态调用方法的一种优选方案,其中:所述s2中,部分数据可进行配置,且数据范围设置为100到100000条记录。
9.作为本发明所述的一种数据查看引擎动态调用方法的一种优选方案,其中:所述s2中,当服务器集群需要增加并发时,则需要增加服务器配置。
10.作为本发明所述的一种数据查看引擎动态调用方法的一种优选方案,其中:所述s2中,执行引擎为预览引擎和执行引擎。
11.作为本发明所述的一种数据查看引擎动态调用方法的一种优选方案,其中:所述s2中,单机服务器配置是处理小数据量的,而服务器集群是处理大数据量的。
12.作为本发明所述的一种数据查看引擎动态调用方法的一种优选方案,其中:所述s5中,配置的数据范围设置为100到100000条记录。
13.与现有技术相比:1.用户通过一种编程语言,从数据源中读取要分析用的数据表,其中,编程语言为sql、r、python中的其中一种,实现获得读取用作分析的数据表,读取后,建立不同的计算执行引擎来处理不同级别的数据量来进行预览和执行,预览为取部分数据进行执行,执行为
取全部数据进行执行,用于预览的资源可为单机服务器配置,资源消耗较小支持用户并发数较大,全量数据执行为基于多服务器的hadoop的分布式计算引擎,为服务器集群,资源消耗较大且并发用户较小,并根据此配置初始化不同两级的执行引擎,从而为后续用户操作提供数据处理支持,用户使用编程语言,对数据进行加工处理,也就是进行各种行之间或列之间的操作,而在进行操作时,用户会面临如下三种操作场景:场景一、用户对数据做了处理,想查看数据处理的结果;场景二、用户数据生成了可视化图形、图表等,想查看可视化结果;场景三、用户使用数据挖掘算法应用全量数据进行建模,从而实现用户针对要进行的数据处理、数据探索、建模等操作选择查看结果,其中,针对场景一,用户查看数据的目的是确认操作结果是否正确且有效,在这种情况下,考虑到数据量非常大,用户只需要查看部分数据,也就是通过预览即可掌握操作的结果是否正确且有效;针对场景二,由于图形和报表的生成需要用到全量数据,因此这些操作需要用到全量数据才能实现;针对场景三,应用数据挖掘算法建模的过程需要用到全量数据,因此查看建模结果需要用到全量数据才能实现,并针对不同的用户场景调用不同的计算执行引擎,从而根据不同的计算引擎实现数据查看,以提高资源利用效率;如果操作是场景一,则从全量数据中抽取前n条数据,可以根据用户的选择进行配置,由于数据量小,应用单机服务器配置的计算引擎就可以进行计算,也就是将选中的数据全部交给一台服务器来做计算,并将计算结果返回并提供给用户预览;如果操作是场景二或场景三则使用服务器集群类进行计算,也就是将全部数据划分成若干小块,给集群中的每台服务器分配其中的一块任务,任务分头执行完毕后,将每一块的结果进行汇总,形成全量数据的结果,并将结果提供给用户查看,从而实现本发明在满足用户正常查看的情况下,动态且高效地应用有限的计算资源,促进资源节约和高效利用,在同等资源下有利于支持更多的计算;2.通过本发明提升了查看数据的效率,相对于单线程计算引擎,分布式计算引擎在计算过程中增加了数据分块和资源管理的过程,对于小数据量来说这些反而增加了负担,因此对于小数据量的计算,单线程引擎更加有效;3.通过本发明更加高效的利用现有的计算资源,更好的满足用户的计算需求。
附图说明
14.图1为本发明流程示意图。
具体实施方式
15.为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明的实施方式作进一步地详细描述。
16.本发明提供一种数据查看引擎动态调用方法,具有提高全量数据的读取速度和检测效率的作用,请参阅图1,包括具体步骤如下:s1,读取用作分析的数据表:用户通过一种编程语言,从数据源中读取要分析用的数据表,其中,编程语言为sql、r、python中的其中一种;s2,建立不同的计算执行引擎(分配计算机cpu、内存资源大小不一样)来处理不同级别的数据量来进行预览和执行,预览为取部分数据(可进行配置,且数据范围设置为100到100000条记录)进行执行,执行为取全部数据进行执行,用于预览的资源可为单机服务器
配置,资源消耗较小支持用户并发数较大,全量数据执行为基于多服务器的hadoop的分布式计算引擎,为服务器集群,资源消耗较大且并发用户较小(需要增加并发则需要增加服务器配置),根据此配置初始化不同两级的执行引擎(预览引擎和执行引擎),为后续用户操作提供数据处理支持,其中,单机服务器配置是处理小数据量的,而服务器集群是处理大数据量的(至少10000条以上记录);s3,用户针对要进行的数据处理、数据探索、建模等操作选择查看结果的方式:用户使用编程语言,对数据进行加工处理,也就是进行各种行之间或列之间的操作,例如去除缺失值(从全部数据中删除任意一列中存在缺失值的行),派生新字段(将两列或多列之间进行数学运算生成新的列),生成图形(使用指定的列作图),建模(从数据中寻找并量化特定的规律),而在进行操作时,用户会面临如下三种操作场景:场景一:用户对数据做了处理,想查看数据处理的结果;场景二:用户数据生成了可视化图形、图表等,想查看可视化结果;场景三:用户使用数据挖掘算法应用全量数据进行建模;s4,针对三种用户场景,查看数据的需求其实是有差异的:针对场景一,用户查看数据的目的是确认操作结果是否正确且有效,在这种情况下,考虑到数据量非常大,用户只需要查看部分数据,也就是通过预览即可掌握操作的结果是否正确且有效;针对场景二,由于图形和报表的生成需要用到全量数据,因此这些操作需要用到全量数据才能实现;针对场景三,应用数据挖掘算法建模的过程需要用到全量数据,因此查看建模结果需要用到全量数据才能实现;s5,针对不同的用户场景调用s2提供的不同的计算引擎实现数据查看,以提高资源利用效率;如果操作是场景一,则从全量数据中抽取前n条数据,可以根据用户的选择进行配置(设置数据范围为100到100000条记录),由于数据量小,应用单机服务器配置的计算引擎就可以进行计算,也就是将选中的数据全部交给一台服务器来做计算,并将计算结果返回并提供给用户预览;如果操作是场景二或场景三则使用服务器集群类进行计算,也就是将全部数据划分成若干小块,给集群中的每台服务器分配其中的一块任务,任务分头执行完毕后,将每一块的结果进行汇总,形成全量数据的结果,并将结果提供给用户查看;s6,将s5的计算结果展示给用户查看。
17.虽然在上文中已经参考实施方式对本发明进行了描述,然而在不脱离本发明的范围的情况下,可以对其进行各种改进并且可以用等效物替换其中的部件。尤其是,只要不存在结构冲突,本发明所披露的实施方式中的各项特征均可通过任意方式相互结合起来使用,在本说明书中未对这些组合的情况进行穷举性的描述仅仅是出于省略篇幅和节约资源的考虑。因此,本发明并不局限于文中公开的特定实施方式,而是包括落入权利要求的范围内的所有技术方案。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1