一种基于深度学习的特征点检测与描述子生成方法
1.本公开属于图像处理技术领域,特别涉及一种基于深度学习的特征点检测与描述子生成方法。
背景技术:
2.在图像处理中,特征点是指图像灰度值发生剧烈变化的点或者在图像边缘上曲率较大的点。特征点通常包含点在图像上的位置信息,而描述子通常是一个向量,它描述了特征点周围像素点的信息。特征点检测与描述是计算机视觉领域最基础、最重要的研究领域之一,能够精确地提取并描述图像中的特征点是很多计算机视觉任务的前置任务,比如相机标定、位姿估计、立体匹配、同时定位与构图 (simultaneous localization and mapping,slam)、三维重建等。
3.特征点检测器的设计,需要考虑抗噪性、尺度不变性、视点不变性、光照不变性、快速检测和描述等几个。传统的特征点检测器设计复杂,一般只能兼顾以上某一个或者某几个方面,尤其对光照和尺度变化的鲁棒性较差,难以适应多变的实际场景。由于深度学习在当前计算机视觉任务中的优异表现,基于深度神经网络的方法逐渐成为该领域的研究热点。目前,具有代表性的深度学习通用模型有如下两种: 1)superpoint、r2d2等方法前端共享一个特征编码网络,后端分成两个分支解码网络,同时进行特征点的检测和描述子的生成。2) d2-net和aslfeat等方法使用单个网络进行图像特征的提取,特征向量直接作为描述子向量,而特征点的位置由特征向量预测得到。上述方法在实际应用中存在以下问题:首先,特征点的定位精度不足,通过可视化神经网络的各层后发现,经过多层卷积以后图像原本的细节特征丢失,边缘位置发生偏移,这就导致了特征点的定位精度降低;其次,特征点的独特性不足,也就是提取的特征点中存在大量描述子相似的点,而相似的点会给后续任务带来大量的误匹配,进而导致位姿估计的精度降低。
技术实现要素:
4.鉴于此,本公开提供了一种基于深度学习的特征点检测与描述子生成方法,包括如下步骤:
5.s100:构建新的卷积神经网络;
6.s200:利用所述新的卷积神经网络预测输入图像的特征点并且生成描述子向量;
7.其中,所述新的卷积神经网络结构由两部分组成,第一部分为编码器,用于输入图像的特征编码;第二部分为3个解码器,第一个解码器生成描述子特征图,第二个解码器生成特征点的独特性特征图,第三个解码器由不同层的神经网络特征拼接作为输入生成准确度特征图。
8.通过上述技术方案,本方法利用神经网络预测输入图像的特征点并且生成描述子向量。与其他深度学习的方法相比,本方法生成的特征点具有更高的定位精度和独特性,有助于提高特征点匹配的性能以及后续任务的精度。
9.本方法带来的有益效果为:首先,针对特征点的定位精度不足的问题,本方法采用浅层与深层特征融和的操作,为特征点检测器中引入底层细节特征,并且利用图像的梯度作为损失函数,从而提高检测器的定位精度。其次,针对特征点的独特性不足的问题,设计了独特性损失函数,将假定的特征点与图像中所有的其他特征点的描述子进行比较,度量其独特性。最后,使用hpatches数据集和aachen-dayand night数据集,充分证实了本方法在图像匹配和视觉定位等具体任务中的优异表现。
附图说明
10.图1是本公开一个实施例中所提供的一种基于深度学习的特征点检测与描述子生成方法流程图;
11.图2是本公开一个实施例中基于深度学习的特征点检测与描述子生成方法的结构图;
12.图3(a)至图3(c)是本公开一个实施例中不同层特征图的可视化示意图;
13.图4(a)、图4(b)是本公开一个实施例中网格图像与简单几何图像示意图;
14.图5(a)至图5(c)是本公开一个实施例中r2d2与本方法的热力图对比图。
具体实施方式
15.参见图1,在一个实施例中,其公开了一种基于深度学习的特征点检测与描述子生成方法,包括如下步骤:
16.s100:构建新的卷积神经网络;
17.s200:利用所述新的卷积神经网络预测输入图像的特征点并且生成描述子向量;
18.其中,所述新的卷积神经网络结构由两部分组成,第一部分为编码器,用于输入图像的特征编码;第二部分为3个解码器,第一个解码器生成描述子特征图,第二个解码器生成特征点的独特性特征图,第三个解码器由不同层的神经网络特征拼接作为输入生成准确度特征图。
19.在这个实施例中,通过多层特征融合将浅层特征引入检测器,解决特征点的位置偏移问题;并且提出深浅层特征损失函数,从而提高特征点的定位精度。设计损失函数对特征点的独特性进行评价,只保留具有较高独特性的点,以防止后续错误匹配。在通用的图像匹配和视觉定位数据集上对本方法进行评测,实验结果显示优于现有方法,其中在hpatches数据集上平均匹配精度提升到73.2%,而在aachenday-night数据集上的高精度定位部分也有了显著提升。
20.确定神经网络的结构如图2所示,由两部分组成,第一部分为解码器,解码器是前端共享的特征提取层,它是由全卷积的l2-net组成,用于输入图像的特征编码;第二部分为3个解码器分支,第一个解码器生成描述子的特征图,第二个解码器生成特征点的独特性特征图,第三个解码器由不同层的神经网络特征拼接作为输入,并最终生成准确度特征图。
21.在另一个实施例中,所述编码器由9个卷积层构成,前6个卷积层采用大小为3的卷积核,后三个卷积层采用大小为2的卷积核。
22.在另一个实施例中,所述编码器中采用膨胀卷积代替一般卷积与下采样过程。
23.就该实施例而言,为保证特征层分辨率不变的同时增强感受野,我们采用膨胀卷
积代替一般卷积与下采样过程。
24.在另一个实施例中,所述由不同层的神经网络特征拼接作为输入具体是指:由编码器的第一层、第二层、第三层和第九层特征拼接作为输入。
25.就该实施例而言,对于神经网络的第二部分包括3个解码器分支,用于不同学习任务的解码器网络。第一个解码器生成描述子特征图,它对图像的每一个像素点都用一个d维的向量进行描述。第二个解码器生成特征点的独特性特征图,它可以排除描述子相似的点,防止特征点的误匹配。第三个解码器生成特征点的准确度特征图,它可以提供准确并且可重复的特征点的位置。为了提高特征点定位的精度,保证特征图包含对浅层细节特征的感知,这一部分采用了特征融合操作。图2中展示了采取第一层,第二层,第三层以及第九层卷积层的输出进行拼接的特征融合操作。
26.在另一个实施例中,采用深浅层特征损失函数来训练所述准确度特征图。
27.就该实施例而言,图3(a)为神经网络第一层特征图的可视化表示,图3(b)为神经网络第五层特征图的可视化表示,图3(c) 为神经网络第九层特征图的可视化表示。通常基于深度学习的特征点检测算法是通过多层卷积网络生成图像的特征点响应图,然后挑选其中响应值较大的点作为特征点。但是如图3(a)至图3(c)所示,神经网络不同层生成的可视化结果表明,经过多层卷积后,图像的细节特征已经发生了模糊和偏移。因此,这说明只对高层特征进行特征点检测会导致特征点的定位精度下降。
28.而从图3(a)至图3(c)的可视化结果中可以发现,浅层的神经网络对细节特征有较好的保留,因此,本方法引入浅层特征对高层特征进行约束,从而提高特征点的位置准确度。如图2所示,将神经网络的第一层、第二层、第三层和第九层进行特征拼接操作,在此基础上再进行特征点位置的预测。
29.此外,还将浅层特征引入到损失函数中,从而增强特征图的细节信息。这种方式有助于检测器对特征点的定位,而且不会降低描述子的性能。
30.具体而言,本方法设计了深浅层特征loss。我们令i和i
′
作为同一个场景的两张图像,令为它们之间的真值对应,h和w 分别为图像的长和宽。受启发于key.net,我们对图像i和i
′
分别在不同方向求一阶导和二阶导,得到底层特征如下:
[0031][0032]ix
,iy,i
x
×iy
,和分别表示图像在x和y方面的一阶导数及其组合,i
xx
,i
yy
,i
xy
,i
xx
×iyy
和则是图像在x,y以及xy方向上的二阶导数及其组合,将以上梯度信息组合作为底层特征lf。然后设计损失函数让准确度特征图a与底层特征lf相对应。我们采用a与lf之间的余弦相似度来度量深浅层特征损失。(以下用coshl表示),即我们定义了一组重叠的图像p={p},它包含所有n
×
n的图像块 {1,...,w}
×
{1,...,h},并将损失定义为:
[0033][0034]
其中,a表示准确度特征图,lf表示底层特征,为一组部分重叠的图像,a[p]和lf[p]表示从a和lf中提取的扁平n
×
n的特征,在本实验中n的值取为8。coshl表示a与lf之间的余弦相似度。另外,同r2d2中一样,我们还令a与a
′
之间的余弦相似度最大化(以下
称为 cosim),来保证图像中的特征点可以被重复检测:
[0035][0036]
其中a[p]和a
′
[p]表示从a和a
′
中提取的扁平n
×
n块。最后,总的准确度损失如下:
[0037][0038]
在另一个实施例中,所述独特性损失函数为:
[0039][0040]
其中,我们采用一对匹配的图像i和i’作为输入,x为图像i的像素点,d(x)为点x的独特性响应,k为点的数量;nx为利用描述子计算的独特性指标, n
x
=∑
n∈n,p∈p
1(cos(m
x
,m
′n)>max(cos(m
x
,m
′
p
))),x是输入图像i中的特征点,m
x
是x的描述子向量;集合n是图像i中的一个特征点x在输入图像i’中的负样本点集合,m
′n是负样本点的描述子向量;集合p是特征点x的正样本点集合,m
′
p
是正样本点的描述子向量;cos(
·
)表示计算二者的余弦相似度,1(
·
)表示其内部不等式成立时输出1,否则输出0。
[0041]
就该实施例而言,为剔除相似程度较大的特征点,从而提升检测算法提取特征点的质量,本方法对每个特征点进行独特性评价,从而提出了独特性损失函数。如果点x的描述子m
x
越独特,则n
x
的值越小, d
x
越接近于1;反之如果图像i
′
中有许多描述子向量与m
x
相似,那么n
x
越大,d
x
接近于0。d
x
表示点x的独特性响应,k表示点的数量。
[0042]
在另一个实施例中,采用可微近似的平均精度ap作为损失函数来训练所述描述子特征图。
[0043]
就该实施例而言,同时,为了训练描述子,优化其正负样本之间的距离,采用了可微近似的平均精度ap作为描述子的损失函数。相比于triplet损失函数,ap损失函数采用的litewise优化方法更容易被优化。因为listwise排序只需要保证匹配的图像块在所有不匹配的图像块之前,而忽略正确匹配和不匹配各自内部之间的排序。具体而言,对于图像i,每个d维的描述子m
x
都描述了以x为中心的k
×
k 大小的图像块,k在本实验中设置为16,图像i
′
中有与m
x
对应的描述子m
x
′
。我们希望m
x
与m
x
′
尽可能的相似,因此我们需要最大化ap:
[0044][0045]
其中,i和i’表示匹配的图像,x表示图像i中的一个像素点, m
x
和m
′
x
表示在图像i和i’中的图像块。u表示i和i’之间的映射关系,k为点的数量,ap(
·
)表示计算图像块的近似平均精度值。
[0046]
在另一个实施例中,采用独特性损失函数来训练所述独特性特征图。
[0047]
就该实施例而言,除了准确度特征图,神经网络还输出了独特性特征图用来解决相似特征点的问题。独特性特征图的解释如下:如图 4(a)所示的网格图像,网格线的交点处通常会被提取成为特征点,但是交点附近的图像彼此之间比较相似,如果被提取成特征
点,在后续的图像匹配任务中可能会造成误匹配,导致位姿估计精度下降,因此我们希望网格交点处的独特性响应值比较低,这样就可以避免提取交点作为特征点。而对于图4(b)所示的图像,三角形的三个顶点通常会被提取成为特征点,顶点之间的相似度比较低,我们就希望这三个点处独特性响应值比较高,这样提取这三个点作为特征点可以避免图像的误匹配。
[0048]
描述子的总体损失函数如下所示:
[0049][0050]
式中,i和i
′
表示匹配的图像对,m和m’表示图像对i和i
′
对应的描述子特征图,u表示图像对之间的对应关系,x表示图像i中的一个像素点,x
′
表示该点在图像i
′
中的位置,d和d
′
表示图像对i和i
′
对应的独特性特征图。
[0051]
综上,最终总体损失函数如下式所示,其由特征点检测损失和描述子损失两部分组成:
[0052]
在另一个实施例中,所述卷积神经网络进行训练过程中,采用数据增强的方法对数据集进行预处理,生成训练集。
[0053]
就该实施例而言,本方法采用的训练数据集主要由aachen数据集构成,并采用数据增强的方法对数据集进行扩展。测试集采用 hpatches数据集,共包含108个场景(包括52个照明变化和56个视角变化)。
[0054]
本文采用数据增强方法对图像检索数据集oxford and parisretrieval数据集以及视觉定位数据集aachen day-night数据集进行预处理,生成训练集。其中,对oxford and paris retrieval数据集进行单应性变换,主要用来模拟视角的变换,生成的新图像和原图像共同作为一对匹配的图像用于训练;对aachen day-night数据集进行了三种数据增强的操作,第一种是单应性变换,同样用来模拟视角的变换,第二种是图像风格转换和单应性变换,主要用来模拟光照和视角的变化,第三种是采用sfm模型和epicflow方法从同一场景中获取最佳匹配关系的图像对,模拟实际场景中的光照和视角变换。
[0055]
在另一个实施例中,实验过程中,我们使用adam优化器将训练过程优化到25个epoch,固定学习率为0.0001,权重衰减为0.0005,批处理大小为4,图像裁剪为192
×
192。另外,我们实验是通过 pytorch实现的,使用单个nvidia rtx 2080ti卡完成训练和测试,训练时间在12小时以内。
[0056]
对于和涉及的图像采样问题,在图像i
′
中,我们将正样本位置定义为距离真实位置的3像素半径内,而负样本位置定义为距离真实位置的9到11像素之间。随机采样的位置在11像素以外。
[0057]
在测试时,我们用多尺度检测的方法对输入图像进行特征点检测。我们在输入图像上以l=1024像素开始以不同比例对训练后的网络多次检测,并每次对其进行2
1/4
下采样,直到l<256像素,其中 l表示图像的尺寸。我们采用大小为3的非极大值抑制(nms)来删除空间上过于接近的检测。对于每个尺度,我们在r中找到局部最大值,并从d的相应位置获取特征点的独特性,从m的相应位置获取描述子m
x
,m
x
的得分由a
xdx
计算得到。最后,我们保留所有尺度上最好的k个描述子,即我们得到准确且独特的特征点。
[0058]
图5(a)至图5(c)中我们以棋盘格图像作为输入,可视化了 r2d2和本方法检测到的特征点位置、准确性和独特性热力图,图中的颜色越浅,该点就越准确或独特。从图5(a)的特征点位置图像中我们可以发现,与r2d2相比,本方法可以获得更准确的特征点位置,提取的特征点均位于图像的边缘区域;从图5(b)独特性热力图中可以看出,本方法的独特性可以更好地消除具有相同纹理的区域;从图5(c)中我们可以看出,本方法生成的准确度热力图能更好的确定棋盘格的边缘和交点位置,而r2d2则有一定的偏差。此外,我们还进行了图像匹配和视觉定位实验,以探索检测器的性能。
[0059]
为了对实验结果进行评价,在hpatches数据集上实现了图像匹配任务,从而定量的评估本方法。图像匹配任务是评价特征点检测器性能常用的标准,也是特征点检测的一个重要应用。hpatches数据集共包含116个场景。为了与r2d2和d2-net等流行的检测器进行比较,我们选择了其中108个场景(包括52个光照变化和56个视角变化场景)。
[0060]
评价指标主要包括平均匹配准确度(mean matching accuracy, mma)、可重复性(repeatability)和匹配分数(matching score)。平均匹配准确度是用来综合评价特征点位置和描述子性能的指标。即将第一张图像与第二张图像的描述子进行匹配,计算匹配距离最近的点是否是特征点对;可重复性是用来评价特征点的位置性能的指标,计算两幅图中提取出来的点的距离表示重复率,即在第一张图中某个特征点在第二张图中被检测出来的概率;匹配分数是计算整个神经网络可以恢复的真值对应点与公共视区中特征点数量的平均比例。
[0061]
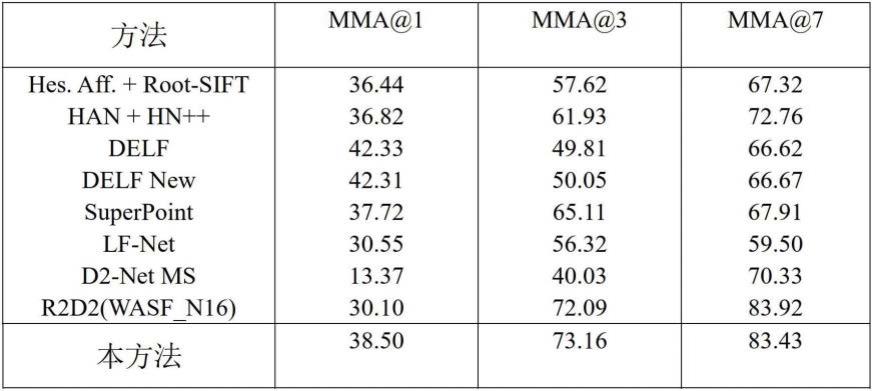
将本方法与delf、superpoint、lf-net等进行比较,结果如表 1所示。可以看出,在不同的误差阈值下,本方法的性能比现有的方法明显更好。例如,本方法在1个像素和3个像素的误差阈值下的 mma优于r2d2,这表明本方法可以有效提高特征点的定位精度。
[0062][0063]
表1
[0064]
我们还使用了原始的r2d2模型(wsf_n16、wasf_n16)进行比较。结果如表2所示。在3个像素的误差阈值下,与wsf_n16的61.83%和wasf_n16的63.56%相比,本方法的重复性为68.47%,这证明了我们的方法的优势。此外,本方法的匹配分数和可重复性也比r2d2 高。
[0065][0066]
表2
[0067]
最后,我们使用视觉定位基准来评估我们的检测器在实际计算机视觉任务中的性能。视觉定位是估计给定图像相对于参考场景表示的 6自由度相机姿态的问题。我们使用的评价数据集是aachenday-night数据集。该数据集包含4328张参考图像和98张夜间查询图像。我们根据参考图像及其位姿估计98个夜间查询图像的相应位姿。结果为在三个给定的平移和旋转误差容限内定位的查询图像的百分比,即(0.25m,2
°
)、(0.5m,5
°
)和(5m,10
°
)。
[0068]
结果如表3所示。可以发现,我们的方法在高精度条件下的性能优于其他方法,并且明显优于r2d2(wasf_n16)。
[0069][0070]
表3
[0071]
尽管以上结合附图对本发明的实施方案进行了描述,但本发明并不局限于上述的具体实施方案和应用领域,上述的具体实施方案仅仅是示意性的、指导性的,而不是限制性的。本领域的普通技术人员在本说明书的启示下和在不脱离本发明权利要求所保护的范围的情况下,还可以做出很多种的形式,这些均属于本发明保护之列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1