基于人工智能的图像描述生成方法、装置、设备及介质与流程
1.本技术涉及到人工智能技术领域,特别是涉及到一种基于人工智能的图像描述生成方法、装置、设备及介质。
背景技术:
2.图像描述就是对图像自动生成一段描述性的文字。图像描述的模型不仅要检测出图像中的物体、识别出图像中的文本、理解物体之间的相互关系,最后还要将图像信息用语言准确地描述出来。图像中的文本对人类理解图片信息是至关重要的,当模型试图理解含文本的图像时,不仅仅是目标检测,还有理解图像的文本并且将它联系环境进行理解。比如,图像是“砖墙上有一个红色圆环,圆环的直径上有一个文本区域,文本区域中有一段文字mornington crescent”,目前的图像描述的模型识别出“砖墙上有一个标志”,但是不足以理解“墙上的红色圆环里写着mornington crescent”。由于目前的图像描述的模型无法理解图像的文本并且将它联系环境进行理解,导致无法详尽描述出图片中丰富的信息。
技术实现要素:
3.本技术的主要目的为提供一种基于人工智能的图像描述生成方法、装置、设备及介质,旨在解决现有技术在进行图像描述时,图像描述的模型无法理解图像的文本并且将它联系环境进行理解,导致无法详尽描述出图片中丰富的信息的技术问题。
4.为了实现上述发明目的,本技术提出一种基于人工智能的图像描述生成方法,所述方法包括:
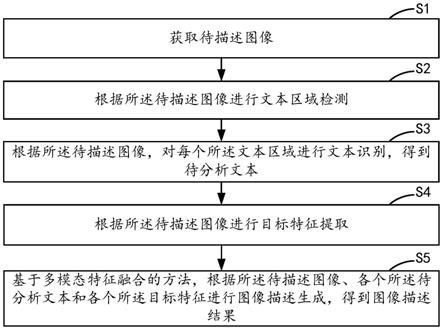
5.获取待描述图像;
6.根据所述待描述图像进行文本区域检测;
7.根据所述待描述图像,对每个所述文本区域进行文本识别,得到待分析文本;
8.根据所述待描述图像进行目标特征提取;
9.基于多模态特征融合的方法,根据所述待描述图像、各个所述待分析文本和各个所述目标特征进行图像描述生成,得到图像描述结果。
10.进一步的,所述根据所述待描述图像进行文本区域检测的步骤,包括:
11.对所述待描述图像进行下采样处理,得到下采样特征;
12.对所述下采样特征进行上采样处理,得到上采样特征;
13.对所述上采样特征进行级联处理,得到待分析特征层;
14.根据所述待分析特征层进行文本概率图预测,得到目标文本概率图;
15.根据所述待分析特征层进行动态阈值图预测,得到目标动态阈值图;
16.根据所述目标文本概率图和所述目标动态阈值图进行可微分二值化计算,得到可微分二值化图;
17.根据所述可微分二值化图进行所述文本区域生成。
18.进一步的,所述根据所述待描述图像,对每个所述文本区域进行文本识别,得到待
分析文本的步骤,包括:
19.根据每个所述文本区域,从所述待描述图像中提取图像区块,得到文本图像区块;
20.采用基于卷积神经网络得到的模型,对每个所述文本图像区块进行预设高度的特征图提取,得到特征图集;
21.将每个所述特征图集中的各个所述特征图按位置进行排序,得到时序特征图集;
22.将每个所述时序特征图集输入基于循环神经网络得到的模型进行文本识别,得到每个所述文本区域对应的所述待分析文本,其中,采用预设标签字典中的各个预设标签作为所述基于循环神经网络得到的模型的嵌入层的输出维度的预测标签,所述预设标签包括:文本和占位符。
23.进一步的,所述根据所述待描述图像进行目标特征提取的步骤,包括:
24.对所述待描述图像进行图像特征图提取,得到待分析图像特征图;
25.采用基于区域生成网络得到的模型,根据所述待描述图像进行目标候选区域提取;
26.根据每个所述目标候选区域,从所述待分析图像特征图中提取图像特征,得到目标外观特征;
27.根据每个所述区域图像特征进行分类预测,得到分类预测结果,其中,分类预测的分类标签包括:多个物体标签和一个背景标签;
28.根据每个所述目标外观特征进行位置回归处理,得到目标位置信息;
29.采用基于全卷积网络得到的模型,根据每个所述目标外观特征进行掩膜图生成,得到目标掩膜图;
30.将同一所述目标候选区域对应的所述目标外观特征、所述目标位置信息和所述目标掩膜图作为一个所述目标特征。
31.进一步的,所述基于多模态特征融合的方法,根据所述待描述图像、各个所述待分析文本和各个所述目标特征进行图像描述生成,得到图像描述结果的步骤,包括:
32.根据每个所述目标特征进行特征融合,得到第一融合特征;
33.根据所述待描述图像,对每个所述待分析文本进行特征融合,得到第二融合特征;
34.采用基于迭代的transformer得到的模型,根据各个所述第一融合特征和各个所述第二融合特征进行词预测,得到词预测结果;
35.采用基于动态指针网络得到的模型,根据所述词预测结果和各个所述待分析文本进行图像描述生成,得到所述图像描述结果。
36.进一步的,所述根据每个所述目标特征进行特征融合,得到第一融合特征的步骤,包括:
37.获取一个所述目标特征作为待处理目标特征;
38.对所述待处理目标特征中的目标位置信息进行编码,得到目标位置编码;
39.对所述待处理目标特征中的目标外观特征和所述目标位置编码进行线性变化边以映射到第一预设维数的向量嵌入空间,得到所述待处理目标特征对应的所述第一融合特征;
40.重复执行所述获取一个所述目标特征作为待处理目标特征的步骤,直至完成所述目标特征的获取。
41.进一步的,所述根据所述待描述图像,对每个所述待分析文本进行特征融合,得到第二融合特征的步骤,包括:
42.获取任一个所述待分析文本作为待处理文本;
43.根据所述待处理文本进行第二预设维数的词向量编码,得到文本块词向量;
44.根据所述待处理文本,从所述待描述图像中进行图像特征提取,得到文本块图像特征;
45.对所述待处理文本进行第三预设维数的文本编码,得到文本块编码特征;
46.根据所述待描述图像,对所述待处理文本进行位置信息确定,得到文本位置信息;
47.对所述文本位置信息进行编码,得到文本位置编码;
48.对所述文本块词向量、所述文本块图像特征、所述文本块编码特征和所述文本位置编码进行线性变化边以映射到第四预设维数的向量嵌入空间,得到所述待处理文本对应的所述第二融合特征;
49.重复执行所述获取任一个所述待分析文本作为待处理文本的步骤,直至完成所述待分析文本的获取。
50.本技术还提出了一种基于人工智能的图像描述生成装置,所述装置包括:
51.图像获取模块,用于获取待描述图像;
52.文本区域检测模块,用于根据所述待描述图像进行文本区域检测;
53.文本识别模块,用于根据所述待描述图像,对每个所述文本区域进行文本识别,得到待分析文本;
54.目标特征提取模块,用于根据所述待描述图像进行目标特征提取;
55.图像描述生成模块,用于基于多模态特征融合的方法,根据所述待描述图像、各个所述待分析文本和各个所述目标特征进行图像描述生成,得到图像描述结果。
56.本技术还提出了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述任一项所述方法的步骤。
57.本技术还提出了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一项所述的方法的步骤。
58.本技术的基于人工智能的图像描述生成方法、装置、设备及介质,其中方法首先根据所述待描述图像进行文本区域检测,根据所述待描述图像,对每个所述文本区域进行文本识别,得到待分析文本,然后根据所述待描述图像进行目标特征提取,最后基于多模态特征融合的方法,根据所述待描述图像、各个所述待分析文本和各个所述目标特征进行图像描述生成,得到图像描述结果。通过基于多模态特征融合的方法将理解的图像的文本联系环境进行理解以生成图像描述,从而实现将图像的丰富信息用语言详尽完整地表达出来,提高了图像描述的准确性。
附图说明
59.图1为本技术一实施例的基于人工智能的图像描述生成方法的流程示意图;
60.图2为本技术一实施例的基于人工智能的图像描述生成装置的结构示意框图;
61.图3为本技术一实施例的计算机设备的结构示意框图。
62.本技术目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
63.为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。
64.参照图1,本技术实施例中提供一种基于人工智能的图像描述生成方法,所述方法包括:
65.s1:获取待描述图像;
66.s2:根据所述待描述图像进行文本区域检测;
67.s3:根据所述待描述图像,对每个所述文本区域进行文本识别,得到待分析文本;
68.s4:根据所述待描述图像进行目标特征提取;
69.s5:基于多模态特征融合的方法,根据所述待描述图像、各个所述待分析文本和各个所述目标特征进行图像描述生成,得到图像描述结果。
70.本实施例首先根据所述待描述图像进行文本区域检测,根据所述待描述图像,对每个所述文本区域进行文本识别,得到待分析文本,然后根据所述待描述图像进行目标特征提取,最后基于多模态特征融合的方法,根据所述待描述图像、各个所述待分析文本和各个所述目标特征进行图像描述生成,得到图像描述结果。通过基于多模态特征融合的方法将理解的图像的文本联系环境进行理解以生成图像描述,从而实现将图像的丰富信息用语言详尽完整地表达出来,提高了图像描述的准确性。
71.对于s1,可以获取用户输入的待描述图像,也可以从数据库中呼气待描述图像,还可以从第三方应用系统中获取待描述图像。
72.待描述图像,是需要采用语言描述的图像。
73.对于s2,采用基于db(differentiable binarization)算法得到的模型,对所述待描述图像进行文本区域检测。
74.文本区域也就是待描述图像中的文本对应的文本框对应的区域。
75.可以理解的是,所述待描述图像对应一个或多个文本区域。
76.对于s3,采用基于crnn(an end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition)网络得到的模型,根据所述待描述图像,对每个所述文本区域进行文本识别,将每个所述文本区域对应的文本作为一个待分析文本。
77.也就是说,待分析文本与所述文本区域一一对应。
78.待分析文本包括:文字和/或符号。
79.对于s4,采用基于mask-rcnn(语义分割的算法)网络得到的模型,对所述待描述图像进行每个目标的目标特征提取。
80.目标包括:物体、背景。
81.目标特征包括:目标外观特征、目标位置信息和目标掩膜图。目标外观特征,是目标的外观特征,也就是从目标对应的图像块中提取得到的图像特征。目标位置信息,是目标在待描述图像中的位置信息。目标掩膜图,是根据目标外观特征生成的掩膜图(也就是,mask图)。
82.对于s5,基于多模态特征融合的方法,首先将各个所述待分析文本对应的各种特
征映射到经过学习得到的通用向量嵌入空间,将各个所述目标特征对应的各种特征映射到经过学习得到的通用向量嵌入空间,然后将映射特征输入到基于多层transformer网络得到的模型中,得到在预定义码表的范围内预测词语,最后从识别出的token(所述待分析文本中的词)和在预定义码表的范围内预测的词语中选择一个词作为当前输出,将最后输出的各个词按输出顺序组合成句子,将该句子作为图像描述结果,其中,基于多层transformer网络得到的模型在循环解码的过程中,会采用自回归的方式,将前一个输出的词作为当前输入的一部分。
83.也就是说,图像描述结果是对待描述图像进行语音描述的句子。
84.在一个实施例中,上述根据所述待描述图像进行文本区域检测的步骤,包括:
85.s21:对所述待描述图像进行下采样处理,得到下采样特征;
86.s22:对所述下采样特征进行上采样处理,得到上采样特征;
87.s23:对所述上采样特征进行级联处理,得到待分析特征层;
88.s24:根据所述待分析特征层进行文本概率图预测,得到目标文本概率图;
89.s25:根据所述待分析特征层进行动态阈值图预测,得到目标动态阈值图;
90.s26:根据所述目标文本概率图和所述目标动态阈值图进行可微分二值化计算,得到可微分二值化图;
91.s27:根据所述可微分二值化图进行所述文本区域生成。
92.现有的db算法是直接预测文本区域的概率图,然后根据人为设定的阈值判断每个像素是文字还是背景,这种处理方式过于粗暴,对于边界的检测往往比较难,单一的阈值会导致边界不够准确;并且自然场景中存在大量密集文本,不够准确的边界会让密集文本检测效果很差。为了解决上述问题,本实施例实现了对待描述图像分别进行下采样、上采样和级联处理,然后对级联处理的得到的特征层分别进行文本概率图预测和动态阈值图预测,最后根据文本概率图和动态阈值图进行可微分二值化计算,根据计算结果生成文本区域,实现了更关注边界区域,可微分二值化可以将阈值的设定放在模型的判定层中,让模型自行判断不同像素点设定的阈值大小,提高了边界识别的准确性,提高了密集文本检测效果,提高了图像描述的准确性。
93.对于s21,采用预设图像分割模型,对所述待描述图像进行下采样处理,将下采样得到的特征作为下采样特征。
94.可选的,预设图像分割模型是基于fcn(fully convolutional network)网络训练得到的模型。可以理解的是,预设图像分割模型还可以是基于其他神经网络训练得到的模型,在此不做限定。
95.对于s22,采用预设图像分割模型,对所述下采样特征进行上采样处理,将上采样得到的特征作为上采样特征。通过预设图像分割模型先分别进行下采样和上采样,可以很好的利用高层特征和低层特征,便于检测各种尺度的文本区域,高层感受野大以用来检测大的文本区域,低层用来检测小的文本区域,从而使得到的上采样特征包含高层丰富的语义信息、以及低层丰富的表征信息,使特征表达更加完善。
96.对于s23,对所述上采样特征中的各个特征级联为一个特征层,将级联处理得到的特征层作为待分析特征层。
97.对于s24,采用预设文本概率图预测模型,根据所述待分析特征层进行文本概率图
预测,将预测得到的文本概率图作为目标文本概率图。
98.文本概率图,是计算像素属于文本的概率形成的图。
99.预设文本概率图预测模型,是采用多个第一训练样本对神经网络训练得到的模型。第一训练样本包括:第一图像样本和每个像素的第一标定值。第一图像样本是包含文本的图像。每个像素的第一标定值,是第一图像样本中的每个像素是否为文本区域的标定值。每个像素的第一标定值的取值有两个,分别是0(不是文本区域)和1(是文本区域)。
100.对于s25,采用预设动态阈值图预测模型,根据所述待分析特征层进行动态阈值图预测,将预测得到的动态阈值图作为目标动态阈值图。
101.动态阈值图是根据各个像素的动态阈值形成的图。
102.预设动态阈值图预测模型,是采用多个第二训练样本对神经网络训练得到的模型。第二训练样本包括:第二图像样本和每个像素的第二标定值。第二图像样本是包含文本的图像。每个像素的第二标定值,是第二图像样本中的每个像素是否为文本区域边界的标定值。每个像素的标定值的取值有两个,分别是0(不是文本区域边界)和1(是文本区域边界)。
103.对于s26,可微分二值化图中第i行第j列的像素点的可微分二值化计算公式为:
[0104][0105]
其中,p
ij
是所述目标文本概率图中的第i行第j列的像素点的概率,t
ij
是所述目标动态阈值图中的第i行第j列的像素点的阈值,k是放大因子,k是常数,e是自然常数。
[0106]
对于s27,将所述可微分二值化图中,值大于预设阈值的像素点作为文本区域的像素点,值小于或等于预设阈值的像素点作为非文本区域的像素点,将相邻的文本区域的像素点连通成图形块,将每个图形块作为一个文本区域。
[0107]
在一个实施例中,上述根据所述待描述图像,对每个所述文本区域进行文本识别,得到待分析文本的步骤,包括:
[0108]
s31:根据每个所述文本区域,从所述待描述图像中提取图像区块,得到文本图像区块;
[0109]
s32:采用基于卷积神经网络得到的模型,对每个所述文本图像区块进行预设高度的特征图提取,得到特征图集;
[0110]
s33:将每个所述特征图集中的各个所述特征图按位置进行排序,得到时序特征图集;
[0111]
s34:将每个所述时序特征图集输入基于循环神经网络得到的模型进行文本识别,得到每个所述文本区域对应的所述待分析文本,其中,采用预设标签字典中的各个预设标签作为所述基于循环神经网络得到的模型的嵌入层的输出维度的预测标签,所述预设标签包括:文本和占位符。
[0112]
本实施例文本区域对应的文本图像区块进行预设高度的特征图提取,将特征图按位置进行排序生成时序特征图集,然后将每个所述时序特征图集输入基于循环神经网络得到的模型进行文本识别,因将特征图按位置进行排序生成时序特征图集,减少了特征图的宽度,有利于模型的训练;因图像经过基于卷积神经网络得到的模型进行特征提取后的宽度为图像从左到右被预测的次数,所以分割次数越多,越不容易漏掉字符,但是次数过多容
易产生一个字符被多次识别的情况,从而导致无法判断是否有重复的字符,影响了文字识别的准确性,本实施例通过预设标签包括:文本和占位符,实现将占位符作为预设标签,相同字符用占位符分开,在解码时相同字符对应的编码之间没有占位符对应的编码,则只需要把相同的字符保留一个,从而进一步提高了文字识别的准确性。
[0113]
对于s31,从所述待描述图像中提取与每个所述文本区域对应的图像区块,将提取的每个图像区块作为一个文本图像区块。
[0114]
对于s32,采用基于卷积神经网络(cnn)得到的模型,对每个所述文本图像区块进行预设高度的特征图提取,也就是说,特征图的高度与预设高度相同,将提取得到的各个特征图作为特征图集。
[0115]
对于s33,将每个所述特征图集中的各个所述特征图按位置进行排序,从而得到一个将位置的顺序作为时序的时序特征图集。
[0116]
对于s34,将每个所述时序特征图集输入基于循环神经网络得到的模型进行文本识别,因采用预设标签字典中的各个预设标签作为所述基于循环神经网络得到的模型的嵌入层的输出维度的预测标签,所以文字识别结果的范围是预设标签字典中的预设标签。
[0117]
因图像经过基于卷积神经网络得到的模型进行特征提取后的宽度为图像从左到右被预测的次数,所以分割次数越多,越不容易漏掉字符,但是次数过多容易产生一个字符被多次识别的情况,从而导致无法判断是否有重复的字符,影响了文字识别的准确性,通过将占位符也作为预设标签,实现将占位符作为预设标签,相同字符用占位符分开,在解码时相同字符对应的编码之间没有占位符对应的编码,则值需要把相同的字符保留一个,从而进一步提高了文字识别的准确性。
[0118]
预设标签字典包括:预设标签和编码,预设标签和编码一一对应设置。
[0119]
可选的,将占位符对应的编码设为0。
[0120]
比如,用26个字母的文本作为预设标签,将占位符对应的编码设为0,当预测的标签的编码为[2,2,2,0,15,15,0,15,15,11]时,“15,15,0,15,15”之间有0(占位符对应的编码)则可以确定是两个重复的字符,“2,2,2”中没有0则可以确定表述的是一个字符,因此确定待分析文本为book,
[0121]
又比如,用26个字母的文本作为预设标签,将占位符对应的编码设为0,当预测的标签的编码为[0,0,2,15,15,15,15,0,11,11]时,“15,15,15,15”中没有0则可以确定表述的是一个字符,因此确定待分析文本为bok,在此举例不做具体限定。
[0122]
基于循环神经网络得到的模型,是基于双向lstm(长短期记忆人工神经网络)网络得到的模型。
[0123]
在一个实施例中,上述根据所述待描述图像进行目标特征提取的步骤,包括:
[0124]
s41:对所述待描述图像进行图像特征图提取,得到待分析图像特征图;
[0125]
s42:采用基于区域生成网络得到的模型,根据所述待描述图像进行目标候选区域提取;
[0126]
s43:根据每个所述目标候选区域,从所述待分析图像特征图中提取图像特征,得到目标外观特征;
[0127]
s44:根据每个所述区域图像特征进行分类预测,得到分类预测结果,其中,分类预测的分类标签包括:多个物体标签和一个背景标签;
[0128]
s45:根据每个所述目标外观特征进行位置回归处理,得到目标位置信息;
[0129]
s46:采用基于全卷积网络得到的模型,根据每个所述目标外观特征进行掩膜图生成,得到目标掩膜图;
[0130]
s47:将同一所述目标候选区域对应的所述目标外观特征、所述目标位置信息和所述目标掩膜图作为一个所述目标特征。
[0131]
本实施例基于resnet-fpn得到的模型、基于roi align方法、基于全卷积网络得到的模型提取出了每个目标特征,目标特征包括所述目标外观特征、所述目标位置信息和所述目标掩膜图,为后续理解目标之间的相互关系提供了基础,为基于多模态特征融合的方法将理解的图像的文本联系环境进行理解以生成图像描述提供了基础。
[0132]
对于s41,采用基于resnet-fpn得到的模型,对所述待描述图像进行图像特征提取,将提取得到的图像特征作为待分析图像特征图。
[0133]
fpn,全称为feature pyramid network,是一种通用架构,可以结合各种骨架网络使用,比如vgg(深度卷积神经网络),resnet(残差网络)等。
[0134]
对于s42,采用基于区域生成网络得到的模型,根据所述待描述图像进行目标候选区域提取,其中,基于区域生成网络得到的模型采用预设尺寸的框(也称为先验框,anchor),预测属于目标的候选区域,将预测的每个候选区域作为一个目标候选区域。
[0135]
基于区域生成网络得到的模型,也就是基于rpn(regionproposal network)得到的模型。
[0136]
对于s43,基于roi align方法,从所述待分析图像特征图中提取与每个所述目标候选区域对应的图像特征图,将每个所述目标候选区域对应的图像特征作为目标外观特征。
[0137]
roi align,是区域特征聚集方法。
[0138]
其中,roi align方法首先将roi(实线部分)映射到feature map(虚线部分)上;然后将feature map均分为2*2个单元,设每个单元内包含四个采样点,每个采样点都不是整数坐标,因此这里需要用双线性插值对每个采样点进行估值;最后在每个单元内进行池化计算,每个单元得到一个值,从而得到2*2的feature map。
[0139]
对于s44,因分类预测的分类标签包括:多个物体标签和一个背景标签,根据每个所述区域图像特征进行分类预测,以预测所述区域图像特征对应的图像是背景还是物体。可以理解的是,这里预测的物体是预测具体为哪种物体。
[0140]
可选的,采用基于fc layer(全连接层)和softmax激活函数(回归分类函数)得到的模型,根据每个所述区域图像特征进行分类预测,得到分类预测结果。
[0141]
对于s45,根据每个所述目标外观特征进行目标的位置回归处理,将预测的位置信息作为目标位置信息。
[0142]
可选的,采用基于fc layer和bbox regressor得到的模型,根据每个所述目标外观特征进行位置回归处理。
[0143]
bbox regressor,也就是边框回归器。
[0144]
目标位置信息包括:也就是目标对应的检测框的位置信息。
[0145]
对于s46,采用基于全卷积网络得到的模型,根据每个所述目标外观特征进行逐个像素的掩膜预测,根据掩膜预测结果得到目标掩膜图。
[0146]
对于s47,将同一所述目标候选区域对应的所述目标外观特征、所述目标位置信息和所述目标掩膜图作为一个所述目标特征,也就是说,所述目标特征中的所述目标外观特征、所述目标位置信息和所述目标掩膜图均对应同一个目标。可以理解的是,所述目标特征的数量可以为一个,也可以为多个。
[0147]
在一个实施例中,上述基于多模态特征融合的方法,根据所述待描述图像、各个所述待分析文本和各个所述目标特征进行图像描述生成,得到图像描述结果的步骤,包括:
[0148]
s51:根据每个所述目标特征进行特征融合,得到第一融合特征;
[0149]
s52:根据所述待描述图像,对每个所述待分析文本进行特征融合,得到第二融合特征;
[0150]
s53:采用基于迭代的transformer得到的模型,根据各个所述第一融合特征和各个所述第二融合特征进行词预测,得到词预测结果;
[0151]
s54:采用基于动态指针网络得到的模型,根据所述词预测结果和各个所述待分析文本进行图像描述生成,得到所述图像描述结果。
[0152]
本实施例先对目标特征进行特征融合,然后对待分析文本进行特征融合,最后采用基于迭代的transformer得到的模型根据两个特征融合的结果进行词预测,最后根据词预测的结果和待分析文本进行图像描述生成,实现了基于多模态特征融合的方法将理解的图像的文本联系环境进行理解以生成图像描述,从而将图像的丰富信息用语言详尽完整地表达出来,提高了图像描述的准确性。
[0153]
对于s51,将各个所述目标特征对应的各种特征映射到经过学习得到的通用向量嵌入空间,将映射后的特征作为第一融合特征。
[0154]
对于s52,根据所述待描述图像,将各个所述待分析文本对应的各种特征映射到经过学习得到的通用向量嵌入空间,将映射后的特征作为第二融合特征。
[0155]
对于s53,基于迭代的transformer得到的模型的输入包括:所述第一融合特征、所述第二融合特征和上一个时刻预测出的词。比如,在预测第3个词时,预测得到的第2个词将作为上一个时刻预测出的词输入基于迭代的transformer得到的模型。
[0156]
transformer的结构也是由encoder(编码)和decoder(解码)组成,并且transformer是利用attention(注意力)机制来解决自然语言翻译问题。
[0157]
其中,所述第一融合特征、所述第二融合特征和历史预测出的词输入基于迭代的transformer得到的模型得到矩阵shape,shape=(m+n+p,d),d是预设维度,m是历史预测的词,n是当前时刻预测的词,p是当前时刻的时间步,标识已经预测的词的数量,p的初始值为1。
[0158]
词预测结果中包括一个或多个词。
[0159]
对于s54,基于动态指针网络得到的模型,也就是基于dpn(dynamic pointer network)得到的模型。
[0160]
采用基于动态指针网络得到的模型,对所述词预测结果和各个所述待分析文本进行概率分布的建模,以用于决定从所述词预测结果和所述待分析文本中的哪个中选择词出来作为图像描述的词。可以理解的是,将采用基于动态指针网络得到的模型选择的词进行句子拼接,将拼接得到的句子作为所述图像描述结果。
[0161]
在一个实施例中,上述根据每个所述目标特征进行特征融合,得到第一融合特征
的步骤,包括:
[0162]
s511:获取一个所述目标特征作为待处理目标特征;
[0163]
s512:对所述待处理目标特征中的目标位置信息进行编码,得到目标位置编码;
[0164]
s513:对所述待处理目标特征中的目标外观特征和所述目标位置编码进行线性变化边以映射到第一预设维数的向量嵌入空间,得到所述待处理目标特征对应的所述第一融合特征;
[0165]
s514:重复执行所述获取一个所述目标特征作为待处理目标特征的步骤,直至完成所述目标特征的获取。
[0166]
本实施例将目标特征的各种特征进行线性变化边以映射到第一预设维数的向量嵌入空间,从而为实现了基于多模态特征融合的方法将理解的图像的文本联系环境进行理解以生成图像描述提供了基础。
[0167]
对于s511,从各个所述目标特征中获取任一个所述目标特征,将获取的所述目标特征作为待处理目标特征。
[0168]
对于s512,对所述待处理目标特征中的目标位置信息进行编码,得到目标位置编码。
[0169]
目标位置编码表述为xmin是横向像素点位置最小值,ymin是纵向像素点位置最小值,xmax是横向像素点位置最大值,ymax是纵向像素点位置最大值,wim是宽度,him是高度。
[0170]
对于s513,对所述待处理目标特征中的目标外观特征和所述目标位置编码进行线性变化边以映射到第一预设维数的向量嵌入空间,采用公式表述为:
[0171][0172]
其中,ln是linear normalization,也就是线性的归一化处理;w1和w2是预设常量,是所述待处理目标特征中的目标外观特征,是所述目标位置编码。
[0173]
公式的计算结果即为所述待处理目标特征对应的所述第一融合特征。
[0174]
对于s514,重复执行步骤s511至步骤s514,直至完成所述目标特征的获取。当完成所述目标特征的获取时,意味着完成了每个目标特征的特征融合。
[0175]
在一个实施例中,上述根据所述待描述图像,对每个所述待分析文本进行特征融合,得到第二融合特征的步骤,包括:
[0176]
s521:获取任一个所述待分析文本作为待处理文本;
[0177]
s522:根据所述待处理文本进行第二预设维数的词向量编码,得到文本块词向量;
[0178]
s523:根据所述待处理文本,从所述待描述图像中进行图像特征提取,得到文本块图像特征;
[0179]
s524:对所述待处理文本进行第三预设维数的文本编码,得到文本块编码特征;
[0180]
s525:根据所述待描述图像,对所述待处理文本进行位置信息确定,得到文本位置信息;
[0181]
s526:对所述文本位置信息进行编码,得到文本位置编码;
[0182]
s527:对所述文本块词向量、所述文本块图像特征、所述文本块编码特征和所述文本位置编码进行线性变化边以映射到第四预设维数的向量嵌入空间,得到所述待处理文本对应的所述第二融合特征;
[0183]
s528:重复执行所述获取任一个所述待分析文本作为待处理文本的步骤,直至完成所述待分析文本的获取。
[0184]
本实施例将待分析文本的各种特征进行线性变化边以映射到第一预设维数的向量嵌入空间,从而为实现了基于多模态特征融合的方法将理解的图像的文本联系环境进行理解以生成图像描述提供了基础。
[0185]
对于s521,从各个所述待分析文本中获取任一个所述待分析文本,将获取的所述待分析文本作为待处理文本。
[0186]
对于s522,根据所述待处理文本进行第二预设维数的fasttext(浅层网络)词向量编码,将编码得到的fasttext词向量作为文本块词向量。
[0187]
可选的,第二预设维数设为300。
[0188]
fasttext词向量,是采用fasttext生成的词向量。fasttext是词向量计算和文本分类工具。
[0189]
对于s523,采用基于faster rcnn(目标检测算法)得到的模型,从所述待描述图像中提取出与所述待处理文本对应的图像特征作为文本块图像特征。
[0190]
对于s524,采用phoc(pyramidal histogram of characters)编码方法,对所述待处理文本进行第三预设维数的文本编码,将编码得到的数据作为文本块编码特征。
[0191]
可选的,第三预设维数设为604维。
[0192]
对于s525,根据所述待描述图像,对所述待处理文本对应的文本区域进行位置信息确定,将确定的位置信息作为文本位置信息。
[0193]
文本位置信息,是所述待处理文本对应的文本区域在所述待描述图像中的位置信息。
[0194]
对于s526,对所述文本位置信息进行编码,将编码得到的数据作为文本位置编码。
[0195]
对于s527,对所述文本块词向量、所述文本块图像特征、所述文本块编码特征和所述文本位置编码进行线性变化边以映射到第四预设维数的向量嵌入空间,采用公式表述为:
[0196][0197]
其中,ln是linear normalization,也就是线性的归一化处理;w3、w5和w6是预设常量,是所述文本块词向量,是所述文本块图像特征,是所述文本块编码特征,是所述文本位置编码。
[0198]
公式计算结果即为所述待处理文本对应的所述第二融合特征。
[0199]
对于s528,重复执行步骤s521至步骤s528,直至完成所述待分析文本的获取。当完成所述待分析文本的获取时,意味着完成了每个所述待分析文本的特征融合。
[0200]
参照图2,本技术还提出了一种基于人工智能的图像描述生成装置,所述装置包括:
[0201]
图像获取模块100,用于获取待描述图像;
[0202]
文本区域检测模块200,用于根据所述待描述图像进行文本区域检测;
[0203]
文本识别模块300,用于根据所述待描述图像,对每个所述文本区域进行文本识别,得到待分析文本;
[0204]
目标特征提取模块400,用于根据所述待描述图像进行目标特征提取;
[0205]
图像描述生成模块500,用于基于多模态特征融合的方法,根据所述待描述图像、各个所述待分析文本和各个所述目标特征进行图像描述生成,得到图像描述结果。
[0206]
本实施例首先根据所述待描述图像进行文本区域检测,根据所述待描述图像,对每个所述文本区域进行文本识别,得到待分析文本,然后根据所述待描述图像进行目标特征提取,最后基于多模态特征融合的方法,根据所述待描述图像、各个所述待分析文本和各个所述目标特征进行图像描述生成,得到图像描述结果。通过基于多模态特征融合的方法将理解的图像的文本联系环境进行理解以生成图像描述,从而实现将图像的丰富信息用语言详尽完整地表达出来,提高了图像描述的准确性。
[0207]
参照图3,本技术实施例中还提供一种计算机设备,该计算机设备可以是服务器,其内部结构可以如图3所示。该计算机设备包括通过系统总线连接的处理器、存储器、网络接口和数据库。其中,该计算机设计的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机程序和数据库。该内存器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的数据库用于储存基于人工智能的图像描述生成方法等数据。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现一种基于人工智能的图像描述生成方法。所述基于人工智能的图像描述生成方法,包括:获取待描述图像;根据所述待描述图像进行文本区域检测;根据所述待描述图像,对每个所述文本区域进行文本识别,得到待分析文本;根据所述待描述图像进行目标特征提取;基于多模态特征融合的方法,根据所述待描述图像、各个所述待分析文本和各个所述目标特征进行图像描述生成,得到图像描述结果。
[0208]
本实施例首先根据所述待描述图像进行文本区域检测,根据所述待描述图像,对每个所述文本区域进行文本识别,得到待分析文本,然后根据所述待描述图像进行目标特征提取,最后基于多模态特征融合的方法,根据所述待描述图像、各个所述待分析文本和各个所述目标特征进行图像描述生成,得到图像描述结果。通过基于多模态特征融合的方法将理解的图像的文本联系环境进行理解以生成图像描述,从而实现将图像的丰富信息用语言详尽完整地表达出来,提高了图像描述的准确性。
[0209]
本技术一实施例还提供一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现一种基于人工智能的图像描述生成方法,包括步骤:获取待描述图像;根据所述待描述图像进行文本区域检测;根据所述待描述图像,对每个所述文本区域进行文本识别,得到待分析文本;根据所述待描述图像进行目标特征提取;基于多模态特征融合的方法,根据所述待描述图像、各个所述待分析文本和各个所述目标特征进行图像描述生成,得到图像描述结果。
[0210]
上述执行的基于人工智能的图像描述生成方法,首先根据所述待描述图像进行文本区域检测,根据所述待描述图像,对每个所述文本区域进行文本识别,得到待分析文本,
然后根据所述待描述图像进行目标特征提取,最后基于多模态特征融合的方法,根据所述待描述图像、各个所述待分析文本和各个所述目标特征进行图像描述生成,得到图像描述结果。通过基于多模态特征融合的方法将理解的图像的文本联系环境进行理解以生成图像描述,从而实现将图像的丰富信息用语言详尽完整地表达出来,提高了图像描述的准确性。
[0211]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本技术所提供的和实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可以包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram以多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双速据率sdram(ssrsdram)、增强型sdram(esdram)、同步链路(synchlink)dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
[0212]
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、装置、物品或者方法不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、装置、物品或者方法所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括该要素的过程、装置、物品或者方法中还存在另外的相同要素。
[0213]
以上所述仅为本技术的优选实施例,并非因此限制本技术的专利范围,凡是利用本技术说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本技术的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1