一种基于情感预训练模型的故事结尾生成方法
1.本发明涉及自然语言处理技术领域,具体涉及一种基于情感预训练模型的故事结尾生成方法。
背景技术:
2.故事结局生成是为一个不完整的故事生成结局句子的任务,任务的主要挑战是如何生成合理且通顺的句子,并且要符合故事情节的发展。早期的工作主要基于序列到序列(seq2seq)模型,由于不能很好的理解故事内容,容易导致生成通用的不连贯回复。之后的工作在的基础上进行情感生成的探索,通过高斯函数将情感强度引入解码器内核层来控制输出的情绪,在生成多样性上做出了一定的进步,但依然没有改进结尾与故事上下文之间缺少联系以及生成的结尾句子逻辑不通顺的问题。之后有工作结合采用增量编码方案和常识知识,来表示故事中跨越的上下文线索以及促进故事理解,但太过于依赖常识性知识,会使得模型习惯性的从常识知识中获取信息,而不是故事上下文,这样会导致生成的句子与故事上下文内容不一致的情况,同时此类工作的模型在情感一致性上也有待提升。
技术实现要素:
3.为了解决现有的故事结尾文本生成算法生成内容不相关或情感不一致的问题,本发明提供一种基于情感预训练模型的故事结尾生成方法,具体方案如下:
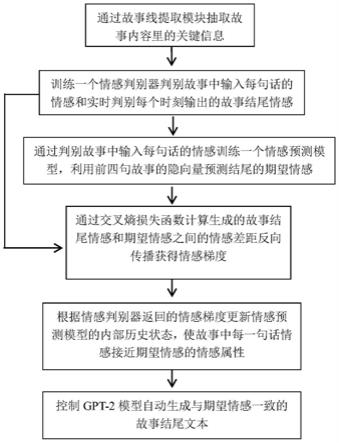
4.一种基于情感预训练模型的故事结尾生成方法,包括如下步骤:通过故事线提取模块抽取故事内容的关键信息,训练一个用于判别故事中输入每句话情感和实时判别每个时刻输出的故事结尾情感的情感判别器,通过情感判别器判别故事中输入每句话的情感训练一个利用前四句故事隐向量预测结尾期望情感的情感预测模型,计算生成过程中情感判别器实时判别每个时刻输出的故事结尾情感和情感预测模型的期望情感之间的差距反向传播获得情感梯度,根据情感判别器返回的情感梯度更新gpt-2模型的内部历史状态,使故事中输入每句话的情感接近期望情感的情感属性,控制gpt-2模型自动生成与期望情感一致的故事结尾文本。
5.进一步地,所述情感判别器和情感预测模型的训练步骤如下:
6.s1,抽取故事中的故事线,将其拼接到原始故事的结尾增强数据;
7.s2,通过交叉熵损失函数训练能自左向右自动回归生成句子的gpt-2模型,通过步骤s1中故事线的增强数据来微调gpt-2模型参数;
8.s3,冻住步骤s2中的gpt-2模型参数,通过sst-5数据集训练一个用于判别故事中输入每句话情感和实时判别每个时刻输出的故事结尾情感判别器;
9.s4,通过步骤s3中的情感判别器判定故事中每一句话的情感的情感向量来训练一个利用前四句故事的隐向量来预测我们结尾所期望情感的情感预测模型。
10.进一步地,所述步骤s2中训练gpt-2模型的交叉熵损失函数,优化目标为最大化如下似然:
[0011][0012]
其中,表示损失函数,p表示概率,ui为语料中第i个词汇,k为窗口大小。
[0013]
进一步地,所述控制gpt-2模型自动生成故事结尾文本的步骤如下:
[0014]
s5.s5.生成过程中,通过交叉熵损失函数计算步骤s3中训练的情感判别器实时判别每个时刻输出的故事结尾情感和步骤s4中训练的情感预测模型的期望情感之间的情感差距;
[0015]
s6.通过步骤s5中所计算的情感差距反向传播获得情感梯度,将情感梯度当作扰动添加到gpt-2模型的隐向量中,用于下一个词的计算;根据情感判别器返回的梯度,更新gpt-2模型内部历史状态h
t
,然后根据得到的新的输出概率分布进行采样并生成新的单词o
t+1
;
[0016]
s7.通过步骤s6的情感梯度反馈,将情感预测模型内部的历史状态h更新为再通过gpt-2模型根据新历史来生成更接近步骤s4中所计算的期望情感所需求的句子;
[0017]
s8.通过softmax函数生成按位置的前馈层产生目标词条的输出分布,生成故事结尾文本,再通过贝叶斯公式将生成过程重写如下:
[0018]
p(x|a)
∝
p(a|x)p(x)
[0019]
其中,a表示情感属性,x表示文本,p(x|a)表示在情感a上生成文本x的概率,p(a|x)表示情感判别器鉴别文本x属于情感属性a的概率,p(x)表示gpt-2模型建模过程中文本的生成概率。
[0020]
控制gpt-2模型生成与期望情感一致的故事结尾文本,生成过程的解码器输出的结果为产生文字序列的下标,且每个文字在词典中都有唯一的标识,根据下标找到对应文字。
[0021]
进一步地,所述步骤s5中计算情感判别器实时判别每个时刻输出的故事结尾情感和情感预测模型的期望情感之间情感差距的交叉熵损失函数如下:
[0022][0023]
其中,表示损失函数,e
p
表示情感预测模型所预测故事结尾期望情感的情感向量,e5为训练语料中情感判别器实时判别每个时刻输出的故事结尾情感的情感向量,训练语料为roc-stories公开数据集。
[0024]
进一步地,所述步骤6中的内部历史状态h
t
主要包括包括k
t
,v
t
矩阵,即:
[0025]ot+1
,h
t+1
=gpt(x
t
,h
t
)
[0026][0027]
其中,a表示情感属性,x表示文本,p(x|a)表示在情感a上生成文本x的概率,p(x)表示gpt-2模型建模过程中文本的生成概率。
[0028]
进一步地,将所述情感判别器鉴别文本x属于情感属性a的概率p(a|x)重写为p(a|h
t
+δh
t
),然后对δh
t
进行基于梯度的更新,具体过程如下所示:
[0029]
[0030][0031]
其中,p表示概率,a代表情感属性,γ代表情感控制强度,算子表示对情感梯度求导,δh
t
为进行梯度更新后的状态。
[0032]
进一步地,所述步骤s8中的故事结尾文本生成的softmax函数如下:
[0033][0034]
其中,p表示概率,u为文本的上下文向量,we为词条的嵌入矩阵,δh
t
为进行梯度更新后的状态。
[0035]
进一步地,所述故事内容的关键信息包括故事中的关键人物、关键事件、事件发生的关键地点,所述提取模块采用yake算法,从原始句子中抽取多个n-gram的关键词。
[0036]
本发明的优点
[0037]
本发明提供的基于情感预训练模型的故事结尾生成方法,是一种基于gpt-2模型作为骨架的神经网络算法,利用预训练模型在捕捉语义和语法方面的优势,结合故事线模块对内容主线走势的判断以及情感判定器对于故事情感走向的捕捉,生成在内容和情感上一致的故事结局。本方法考虑了在情感维度上的一致性问题,利用故事线来强调故事走向,增强gpt-2模型理解故事里的关键信息能力,同时设计了情感预测模块和情感判定器,能够条件式的生成与故事上下文情感一致的结尾句子。
附图说明
[0038]
图1为本发明基于情感预训练模型的故事结尾生成方法的流程图。
具体实施方式
[0039]
下面结合附图和具体实施例对本发明作进一步地解释说明,需要注意的是,本具体实施例不用于限定本发明的权利范围。
[0040]
如图1所示,本实施例提供的一种基于情感预训练模型的故事结尾生成方法,包括如下步骤:
[0041]
s1,抽取故事中的故事线,将其拼接到原始故事的结尾,起到数据增强的作用;
[0042]
所述故事线指的是在故事开始、故事发展、故事高潮/转折、故事结尾等过程中,在故事上下文中按先后顺序抽取出来的表示故事发展走向的关键词组成的故事演进线索。
[0043]
所述故事内容的关键信息包括故事中的关键人物、关键事件、事件发生的关键地点。
[0044]
所述提取模块采用yake算法,从原始句子中抽取多个n-gram的关键词,在本方法中设置n为3。
[0045]
s2,使用交叉熵损失函数训练gpt-2模型,gpt-2模型是一个通过大规模语料训练的无监督预训练模型,能自左向右自动回归生成句子。通过步骤s1中故事线的增强数据来微调gpt-2模型参数;训练gpt-2模型的交叉熵损失函数,优化目标为最大化如下似然:
[0046][0047]
其中,表示损失函数,p表示概率,ui为语料中第i个词汇,k为窗口大小。
[0048]
s3,冻住步骤s2中的gpt-2模型参数,通过sst-5数据集训练一个用于判别故事中输入每句话情感和实时判别每个时刻输出的故事结尾情感的情感判别器;情感判别器为分类器。
[0049]
情感判别器有两个作用:(1)在情感预测阶段是用于判别故事中输入每句话的情感,该过程的目的是预测一个期望情感来指导结尾句子的情感生成。(2)在条件生成阶段用于实时判别每个时刻输出的故事结尾情感,因为一个句子是由多个词组成的,生成阶段是一个词一个词不断生成的,生成过程中需要每生成一个词就要判定一次情感。
[0050]
s4,通过步骤s3中情感判别器判定故事中输入每句话情感的情感向量来训练一个利用前四句故事的隐向量来预测我们结尾所期望情感的预测模型,该情感预测模型的优化目标为最大余弦相似度的。
[0051]
s5.生成过程中,通过交叉熵损失函数计算步骤s3中训练的情感判别器实时判别每个时刻输出的故事结尾情感和步骤s4中训练的情感预测模型的期望情感之间的情感差距;计算该情感差距的损失函数如下:
[0052][0053]
其中,表示损失函数,e
p
表示情感预测模型所预测故事结尾期望情感的情感向量,e5为训练语料中情感判别器实时判别每个时刻输出的故事结尾情感的情感向量,训练语料为roc-stories公开数据集。
[0054]
s6.通过步骤s5中所计算的情感差距反向传播获得情感梯度,将情感梯度当作扰动添加到gpt-2模型的隐向量中,用于下一个词的计算;根据情感判别器返回的梯度,更新gpt-2模型内部历史状态h
t
,然后根据得到的新的输出概率分布进行采样并生成新的单词o
t+1
;由于内部历史状态h
t
主要包括k
t
,v
t
矩阵,即:
[0055]ot+1
,h
t+l
=gpt(x
t
,h
t
)
[0056][0057]
其中,a表示情感属性,x表示文本,p(x|a)表示在情感a上生成文本x的概率,,p(x)表示gpt-2模型建模过程中文本的生成概率。
[0058]
s7.通过步骤s6的情感梯度反馈,将情感预测模型内部的历史状态h更新为再通过gpt-2模型根据新历史来生成更接近步骤s4中所计算的期望情感所需求的句子;将所述情感判别器鉴别文本x属于情感属性a的概率p(a|x)重写为p(a|h
t
+δh
t
),然后对δh
t
进行基于梯度的更新,具体过程如下所示:
[0059][0060][0061]
其中,p表示概率,a代表情感属性,γ代表情感控制强度,算子表示对情感梯度求导,δh
t
为进行梯度更新后的状态;
[0062]
在gpt-2模型建模生成概率p(x)的同时,能够建模出p(x|a)这样的概率模型,即基于某个属性a,生成文本x。而情感判定器能做到鉴别文本的情感属性p(a|x)。所以为了使
gpt-2模型能够控制输出文本的情感,我们用贝叶斯公式将生成过程重写如下:
[0063]
p(x|a)
∝
p(a|x)p(x)
[0064]
其中,a表示情感属性,x表示文本,p(x|a)表示在情感a上生成文本x的概率,p(a|x)表示情感判别器鉴别文本x属于情感属性a的概率,p(x)表示gpt-2模型建模过程中文本的生成概率。
[0065]
s8.最终通过softmax函数生成按位置的前馈层产生目标词条的输出分布,也就是最终需要生成的故事结尾文本:
[0066][0067]
其中p表示概率,u为文本的上下文向量,we为词条的嵌入矩阵,δh
t
为进行梯度更新后的状态。
[0068]
控制gpt-2模型生成与期望情感一致的故事结尾文本,生成过程的解码器输出的结果为产生文字序列的下标,且每个文字在词典中都有唯一的标识,根据下标找到对应文字。
[0069]
下面通过在roc-stories语料库上评估本实施例基于预训练模型的故事结尾生成方法。该roc-stories公开数据集包含98162个故事。将数据集划分为训练集、验证集和测试集,分别有90000个故事、4081个故事和4081个故事。
[0070]
在自动评价环节,按以下三个部分对本实施例的方法以及现有技术的方法进行了对比评估:
[0071]
(1)内容:使用bleu指标测量生成句与参考句的一致程度,其中bleu-n指的是在n-gram的词汇上的匹配程度,数值越大越好。
[0072]
(2)多样性:使用distinct(dist)评价指标来评价生成句子的多样性,其中dist-n指的是在n-gram的词汇上的多样性程度,数值越大越好。
[0073]
(3)情感属性:使用一个额外分类器(classifier),将结尾句与预测句之间的情感分类匹配比例作为情感评价分数,以百分比的形式呈现,数值越大越好。
[0074]
在roc-stories语料的训练过程中,使用1e-5的学习率和adam优化器进行5个epochs的训练。在生成过程中,使用beam search以及使用top-k sampling以及0.4的softmax温度来平衡流畅性和多样性之间的权衡。与现有技术的方法相比,本实施例在内容一致性和情感一致方面得到了有效提高。
[0075]
具体的,在本实施例中,情感预测模型是基于transformer(vaswani a,shazeer n,parmar n,et al.attention is all you need[c]//advances in neural information processing systems.2017:5998-6008.)框架来实现的,训练目标为最小化余弦相似度。情感判别器是在gpt-2(radford a,wu j,child r,et al.language models are unsupervised multitask learners[j].openai blog,2019,1(8):9.)的基础上添加了一个线性mlp的分类层实现的,训练目标为最小化交叉熵损失函数。
[0076]
最终本实施例的方法和其他现有技术的方法在评估指标上的对比如表格1所示:
[0077]
表1:
[0078]
模型bleu-1bleu-2bleu-3bleu-4dist-2dist-4classifierie+msa24.738.373.221.5886.7066.0739.72
t-cvae26.069.154.142.1286.8263.3939.85mlgcn-dp24.088.614.242.3587.7165.7740.87plan&write23.747.163.041.5087.7363.1939.42ke-gpt225.229.024.152.1788.2166.6239.59grf24.468.403.872.0388.9367.1837.04ours26.0110.295.102.8389.6671.4743.32
[0079]
通过本实施例的结果可以看出这我们的方法相比现有技术的方法,对容易出现的生成句式单一的问题有了一定的改进,产生的故事结尾能呈现出更多的信息,有较好的内容一致性和情感一致性。
[0080]
以上实施案例仅为本发明的优选实施例,并不用于限制本发明,对于本领域的技术人员来说,在基于本发明的基础上可以进行各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,这些都属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1