一种基于雷达数据航迹信息的碎片化预统计方法与流程
1.本发明涉及雷达监测技术领域,具体地说,是一种基于雷达数据航迹信息的碎片化预统计方法,用于对雷达实时监测数据进行统计分析,以空间换时间的策略,提升统计分析的性能和效率。
背景技术:
2.低空无人机管控系统作为综合管理软件平台,具备无人机目标跟踪、监视,飞行轨迹绘制,威胁判断、告警,目标飞行数据流盘和重演等基础功能。无人驾驶航空器(以下简称无人机),作为信息时代高技术含量的产物,无人机已成为世界各国加强国防建设和加快信息化建设的重要标志。无人机的广泛使用在带给人们方便的同时,也给国家空中安全带来了潜在威胁。无人机被定义为“低小慢”目标,具有飞行高度低、运动速度慢、雷达散射面积小等特点,其自身的这些特性决定了它难 利用单一探测手段对其进行探测,而探测是拦截与打击的必要前提。系统聚焦无人机的安全管控问题,针对机场、会展、人群聚集地、安全布防区等使用场景,提供机动、灵活、实时、多方式的区域化“察打一体”反无人机系统。通过“区域化预警、实时化跟踪、可控化处置、集中化管理”,对无人机进行从“发现到跟踪再到处置”的一体化管控。满足政府、部队、民航、监狱、重要活动安保、各类敏感区域等现实市场需求。
3.低空无人机管控系统主要分为侦测、反制、回溯三部分,固侦测为24小时全天候保障,雷达侦测数据每日产生百万级航迹数据,因此,对航迹数据进行归类和统计成为了难点。
4.为了解决上述问题,本发明提出了一种碎片化预统计方法,可以大大提高雷达实时监测的统计效率和整体性能。
技术实现要素:
5.本发明的目的在于提供一种基于雷达数据航迹信息的碎片化预统计方法,实现对雷达实时监测数据进行统计分析的功能,具有提升统计分析的性能和效率的效果。
6.本发明通过下述技术方案实现:一种基于雷达数据航迹信息的碎片化预统计方法,括以下步骤:步骤s1.在低空无人机管控系统中根据雷达设备采集雷达数据,通过驱动设备将雷达数据发送至调用端;步骤s2.创建redis缓存队列,等待存入航迹信息,key值为目标id,value值为树状结构航迹统计对象;步骤s3.低空无人机管控系统开启接收线程,调用端持续接收雷达数据,每次收到数据后都进行数据清洗操作和数据聚类操作;步骤s4.低空无人机管控系统开启消费线程,轮询检测redis缓存队列,从缓存队列中筛选出航迹已结束的数据集合,获取已结束航迹统计对象的集合;
步骤s5.判断获取到的航迹统计对象的集合是否为空,如果是,返回步骤s4,等待下一次轮询检测;如果否,将集合中的数据存入数据库中,并将已存入的数据从redis队列中剔除。
7.本技术方案的目的是解决雷达实时监测产生大量航迹信息,进行统计分析时,效率过慢,性能低的问题,此方法将统计压力碎片化,分散提前到入库前缓存中进行统计,从而实现对千亿级数据进行快速归类、整理、统计,有效提高查询性能和统计回溯能力为了更好地实现本发明,进一步地,步骤s2包括:调用端接收雷达数据,获取目标id,根据编号规则对目标id进行重新编号,生成编号后的目标id,根据航迹编号生成树状结构对象,获取单次航迹统计信息;将编号后的目标id作为key值,树状结构对象作为value值存放至redis缓存队列中,并根据树状结构对象获取航迹完整信息。
8.为了更好地实现本发明,进一步地,编号规则包括id_时间戳的编号规则。
9.为了更好地实现本发明,进一步地,步骤s2中的树状结构航迹统计对象包括目标id、危险等级、开始时间、结束时间、出现次数、最大高度、最小高度、最大距离、最小距离、最快速度、创建时间和完整航迹点集合信息。
10.为了更好地实现本发明,进一步地,步骤s3中的数据清洗的操作包括: 将接收到的原始雷达数据进行清理,获取原始数据中目标id,根据编号规则对目标id进行重新编号;根据原始数据创建航迹点信息结构体,获取航迹点信息对象。
11.为了更好地实现本发明,进一步地,步骤s3中的数据聚类的操作包括:根据航迹点信息对象中的目标id判断redis缓存队列中是否存在key值为目标id的数据,如果是,从redis缓存队列中取出该树状结构航迹统计对象,如果否,新建树状结构航迹统计对象;根据航迹点信息统计修改树状结构航迹统计对象,最后将树状航迹统计对象存入redis缓存队列中。
12.为了更好地实现本发明,进一步地,步骤s3中修改树状结构航迹统计对象并加入redis缓存队列的方法包括:将所述信息的统计字段进行更新,并将接收的轨迹点信息添加到所述信息detaillist字段集合中。
13.为了更好地实现本发明,进一步地,步骤s4中从缓存队列中筛选出航迹已结束的数据集合的方法包括:当结束时间超过预设的时间阈值时,判定为航迹结束,获取航迹结束的集合进行处理;判断获取的数据是否为为空,如果是,不做任何操作;如果否,将获取的集合进行存入数据库操作。
14.为了更好地实现本发明,进一步地,步骤s4中判断航迹已结束的方法包括:以完整航迹点集合中最后一个点的时间作为结束时间,通过航迹点的结束时间及丢失点数判定航迹是否结束;当丢失点数超过预设的次数阈值且结束时间超过预设的时间阈值时,判定为航迹结束。
15.为了更好地实现本发明,进一步地,步骤s5中开启消费线程的方法包括:轮询检测redis缓存队列,将航迹结束的树状航迹统计对象集合数据存入数据库中后并将其数据从redis队列中剔除。
16.本发明与现有技术相比,具有以下优点及有益效果:(1)本发明通过读取缓存这块额外的内存,避免了频繁的资源消耗,加快了程序的计算统计速度;(2)本发明采用碎片化预统计,将统计压力碎片化,分散提前到入库前,缓存中进行统计,既能得到完整航迹信息和单次航迹统计信息,又为后续统计得到更多基础统计信息,大大降低后续统计分析时间。
17.(3)本发明采用延迟入库策略,使用线程任务处理方式,减轻了数据库即时压力,提高程序的稳定性。
附图说明
18.本发明结合下面附图和实施例做进一步说明,本发明所有构思创新应视为所公开内容和本发明保护范围。
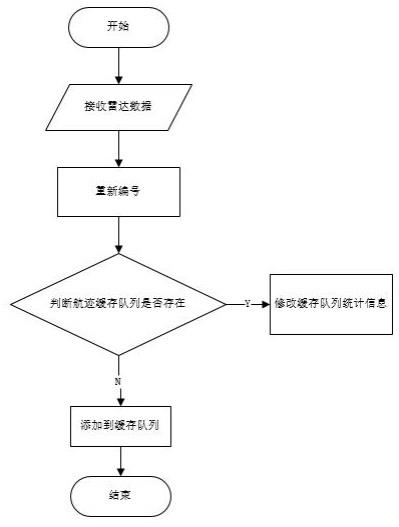
19.图1为本发明公开的一种基于雷达数据航迹信息的碎片化预统计方法的接收线程流程图。
20.图2 为本发明公开的一种基于雷达数据航迹信息的碎片化预统计方法中消费线程路程图。
21.图3为本发明公开的一种基于雷达数据航迹信息的碎片化预统计方法中树状结构航迹统计对象示意图。
22.图4为本发明公开的一种基于雷达数据航迹信息的碎片化预统计方法中航迹统计数据示意图。
23.图5为本发明公开的一种基于雷达数据航迹信息的碎片化预统计方法中采集的雷达数据示意图。
具体实施方式
24.为了更清楚地说明本发明实施例的技术方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,应当理解,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例,因此不应被看作是对保护范围的限定。基于本发明中的实施例,本领域普通技术工作人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
25.在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“设置”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;也可以是直接相连,也可以是通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
26.实施例1:本实施例的一种基于雷达数据航迹信息的碎片化预统计方法,如图1-图5所示,本
实施例采用空间换时间的理念,将雷达数据存到了缓存队列中,重新取得这些雷达数据进行修改统计时会花费大量的资源和时间,而通过读取缓存这块额外的内存,避免了频繁的资源消耗,加快了程序的计算统计速度。碎片化预统计,将统计压力碎片化,分散提前到入库前,缓存中进行统计,既能得到完整航迹信息和单次航迹统计信息,又为后续统计得到更多基础统计信息,大大降低后续统计分析时间。同时,将航迹完整信息进行聚类,每次接收到航迹信息都需要在redis缓存队列中判断编号后的目标id是否存在,如果是,修改缓存队列统计信息并在航迹信息中加入详细信息,将所述航迹信息从redis缓存队列中剔除,如果否,在缓存队列中增加一条航迹数据。最后根据树状结构对象判断新增加的航迹是否为完整轨迹,如果是,将redis缓存队列中的数据存入数据库中,所述航迹信息从redis缓存队列中剔除。
27.实施例2:本实施例在实施例1的基础上做进一步优化,由于接收到的目标id是随机编号,有可能重复,固将接收到的目标id进行重新编号,编号规则为:id_时间戳,保证了目标id在系统中唯一。将目标id作为key值,树状结构对象作为value值存放到redis缓存队列中。如图3所示为本实施例中的树状结构航迹统计对象信息示意图。如图2所示,读取缓存队列,判断是否为完整轨迹(航迹是否结束)
→
获取完整轨迹
→
入库。
28.本实施例的其他部分与实施例1相同,故不再赘述。
29.实施例3:本实施例在上述实施例1的基础上做进一步优化,本实施例将雷达数据航迹信息进行重新编号,使用时间戳保证其编号唯一。
30.本实施例的其他部分与上述实施例1相同,故不再赘述。
31.实施例4:本实施例在上述实施例1的基础上做进一步优化,如图4所示为本实施例中航迹统计数据信息。本实施例的其他部分与上述实施例1相同,故不再赘述。
32.实施例5:本实施例在上述实施例1的基础上做进一步优化,如图5所示,将接收到的原始雷达数据进行清理,获取原始数据中目标id,根据编号规则对目标id进行重新编号,增加其可读性,保证存入redis缓存队列时id不重复。根据原始数据创建航迹点信息结构体,从而获取航迹点信息对象。
33.本实施例的其他部分与上述实施例1相同,故不再赘述。
34.实施例6:本实施例在上述实施例1的基础上做进一步优化,将重新编号的轨迹信息放入哈希缓存队列中,根据编号进行聚类,并根据后续航迹信息进行统计信息累加统计,哈希队列采用红黑树算法固查找及修改性能高。将轨迹信息进行聚类,每次接收到航迹信息都需要在redis缓存队列中判断目标id是否存在,如存在则将该条信息的统计字段进行更新,且将该条轨迹信息添加到detaillist字段中。redis缓存队列拥有高吞吐量,读的速度是110000次/s,写的速度是81000次/s,超高的性能能够满足频繁读写要求本实施例的其他部分与上述实施例1相同,故不再赘述。
35.本实施例的其他部分与上述实施例1相同,故不再赘述。
36.实施例7:本实施例在上述实施例1的基础上做进一步优化,在本实施例中,接收端收到目标id为001的航迹点数据,判断redis缓存队列中是否存在key值为001的数据,如果是,从redis队列中取出该条数据,根据001航迹点的信息重新统计航迹信息,如出现次数、最高危险等级、结束时间、最大高度、最小高度、最快速度、最小速度等信息,并且将航迹点记录添加至detaillist字段集合中,然后将统计信息重新写入redis缓存队列中。如果不存在,根据001航迹点的信息新构建一个航迹对象且赋值,统计信息出现次数增加1次,结束时间为航迹点开始时间,最大速度为当前航迹点速度等,将航迹点记录添加至detaillist字段集合,将赋值的航迹信息对象添加至redis缓存队列中。这样做的优点是航迹统计对象中既有统计数据,又有完整轨迹点集合。
37.本实施例的其他部分与上述实施例1相同,故不再赘述。
38.实施例8:本实施例在上述实施例1的基础上做进一步优化,在本实施例中,redis缓存队列中航迹统计对象的endtime字段是根据航迹点的探测时间不断更新的,固最后一个点出现的时间为航迹统计对象的endtime字段的时间,当endtime的时间超过预设的时间阈值时,后续没有探测到新的轨迹点,我们则判定航迹结束。预设的时间阈值可以根据需求配置,对于时间的阀值,值越大,入库等待时间越久,一般设定为15s。时间阈值根据现场情况配置,如果配置的数值大,采集的数据也就相对更精确,是本领域内技术人员所熟知的配置技术手段。
39.本实施例的其他部分与上述实施例1相同,故不再赘述。
40.实施例9:本实施例在上述实施例1的基础上做进一步优化,在本实施例中,首先我们需要获取到航迹结束的集合进行处理,有可能获取的数据为空(因为航迹还未结束),如果为空我们就不做任何操作,如果不为空,我们将获取的集合进行存入数据库操作。其中获取已结束的集合需要做一个判断,就是如何判断已结束,判断条件为结束时间》预设的时间阈值(15s)。
41.丢失点数也可以根据需求配置,一般配置为4次。同样的,丢失点次数阈值根据现场情况配置,如果配置的数值大,采集的数据也就相对更多,冗余数据也多。也是本领域内技术人员所熟知的配置技术手段。
42.本实施例的其他部分与上述实施例1相同,故不再赘述。
43.实施例10:本实施例在上述实施例1的基础上做进一步优化,在本实施例中,为防止缓存队列内存溢出,开启线程进行消费,通过航迹点最后的结束时间及丢失点数判定航迹是否结束,航迹结束即可将缓存队列中精简统计信息及详细内容分别存入索引数据库中,以外键关系进行关联,轮询检测redis缓存队列,将航迹结束的树状航迹统计对象集合数据存入数据库中后并将其数据从redis队列中剔除,以防止队列无限增大导致内存溢出。将已存入数据库中的数据从缓存队列中剔除,保证其队列健康。系统启动时开启消费线程,轮询检测redis缓存队列,进行消费出队,完整航迹点(detaillist集合)最后一个点的时间作为结束时间,通过航迹点的结束时间及丢失点数判定航迹是否结束。丢失点数超过预设的次数阈值(4
次)且结束时间超过预设的时间阈值(15s)。,则判定为航迹结束。即可将redis缓存队列中的数据存入数据库中,最后将该条航迹信息从redis缓存队列中剔除,保证队列健康和防止内存溢出等问题。
44.本实施例的其他部分与上述实施例1相同,故不再赘述。
45.以上所述,仅是本发明的较佳实施例,并非对本发明做任何形式上的限制,凡是依据本发明的技术实质对以上实施例所做的任何简单修改、等同变化,均落入本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1