基于多智能体宽大强化学习的电力安全经济调度方法
1.本发明属于电力系统经济调度领域,具体涉及一种基于多智能体宽大强化学习的电力安全经济调度方法。
背景技术:
2.近年来,随着深度强化学习的发展与应用,研究人员对基于深度强化学习的经济调度问题进行了详细研究。例如:专利文献1(cn201810999580.8)提出了一种考虑输电运行弹性空间的安全经济调度优化方法,将电力系统的经济调度模型转化为典型的多阶段序贯决策模型,实现任意场景下的电力系统动态经济调度。专利文献2(cn202010812190.2)公开了一种基于双q值网络深度强化学习的微电网能量调度方法,设计了奖励函数来引导策略实现微电网运行的目标。但针对分布式经济调度,以上研究并没有涉及。
3.随着电网规模的不断扩大,分布式经济调度受到了广泛的关注。分布式系统更容易受到网络攻击,而现有的分布式经济调度算法大多忽略了这些潜在的网络攻击,这可能会对电网的安全性产生很大的影响。此外,由于可再生能源发电设备的使用和网络干扰,成本函数中通常存在不确定项,现有的规划算法与基于梯度的算法将无法解决这些不确定项。因此考虑网络攻击与不确定干扰的安全经济调度问题面临着新的挑战,是一个尚待解决的问题。
技术实现要素:
4.针对现有技术的不足,本发明提出了基于多智能体宽大强化学习的电力安全经济调度方法,针对在网络攻击与不确定干扰的情况下的分布式发电机组,提供了可行的能量管理与经济调度方案,填补现有网络攻击下分布式安全经济调度方法的空缺。
5.对于一组有n个发电机组的组合g,其分布式经济调度问题可以描述为如下带约束优化问题:
[0006][0007][0008][0009]
其中,c为总发电代价,ci为机组i的发电代价,pi为机组i的发电功率,d为环境中总用电需求,pi、分别为机组i的发电上限与下限。机组i的发电代价ci的代价函数通常被描述为如下二次函数:
[0010][0011]
其中ai、bi、ci为机组i的代价系数。考虑可再生能源发电设备和网络干扰时,需要在代价函数中引入不确定项,因此代价函数应改写为:
[0012][0013]
其中,n表示服从高斯分布的不确定项,σ是分布参数。
[0014]
基于多智能体宽大强化学习的电力安全经济调度方法,根据用电环境构建多智能体系统,以环境中的用电需求为状态,通过多智能体的强化学习,优化发电机组的输出功率,将分布式经济调度问题构建为一个通过多智能体强化学习解决的合作决策问题。多个智能体间通过通讯模块实现协作,联合计算一致性结果。具体包括以下步骤:
[0015]
步骤1、初始化多智能体强化学习的迭代次数与q估计网络、r估计网络的参数,设置贪婪算法的概率∈=1。
[0016]
步骤2、在当前时间t,观察环境中的用电需求d
i,t
,使用平均一致性,使得智能体获得网络总功率需求的信息:
[0017][0018]
其中,k为迭代次数,ε为步长,di[k]为第k次迭代智能体i的用电需求,a
ij,t
为智能体i和智能体j之间的通信权重,为多智能体网络的邻接矩阵的元素。gi为所有给智能体i发送信息的智能体的集合。有记平均用电需求为
[0019]
步骤3、为解决多智能体系统的网络安全问题,针对dos攻击与fdi(虚假数据注入)攻击进行检测。
[0020]
所述dos攻击模型为:
[0021]
λi=φ
[0022]
其中,λi表示智能体i的发送数据,φ表示空集。设置dos攻击的检测判据为d=φ。
[0023]
所述fdi攻击模型为:
[0024]
λi=xi+δi[0025]
其中,xi表示真实数据,δi表示虚假数据。采用线性距离d作为判据,设置fdi攻击的检测判据为其中δci=ci(p
i,t
)-ci(p
i,t-1
),),η
fdi
是fdi攻击的判断阈值。
[0026]
计算每个智能体的信誉值用于判断网络安全状态,所述信誉值定义如下:
[0027][0028]
其中rv
ij,t
为t时刻智能体i监测到智能体j的信誉值。
[0029]
通过信誉值调整智能体间的通信权重,实现攻击隔离:
[0030][0031]
作为优选,所述fdi攻击的判断阈值η
fdi
=0.3,初始信誉值设置为100。
[0032]
步骤4、为实现学习结果的收敛,单个智能体根据贪婪算法执行独立决策,在概率∈下随机选择输出功率,在概率1-∈下选择q值最大的输出功率。概率∈会随着训练次数不
断减小,使得算法收敛于最优策略。
[0033]
步骤5、多智能体协作求解满足用电需求的输出功率组合,计算输出功率与平均用电需求的偏差使用平均一致性得到多智能体间的平均偏差使用平均一致性得到多智能体间的平均偏差根据平均偏差e
i,t
调整可输出功率:
[0034][0035]
步骤6、根据步骤5调整后的输出功率执行动作a
i,t
,并观察环境,获得环境反馈的奖励r
i,t+1
、下一时间的用电需求d
i,t+1
以及是否结束训练的标志d
t
。通过q表评估状态-动作价值,确定如何执行输出功率能够获得更大的累积奖励。
[0036]
将当前时间的用电需求d
i,t
和奖励r
i,t+1
输入r估计网络中,对奖励进行拟合,得到r
′
i,t+1
。使用平均一致性将得到的评价奖励作为多智能体的联合奖励,记为
[0037]
步骤7、为了消除训练数据间的关联性,将智能体i训练元组《s
i,t
,a
i,t
,r
i,t+1
,s
i,t+1
》按步存储在经验池中。重复步骤2~6多次,从经验池中随机抽取样本,更新q表、q估计网络与r估计网络;
[0038]
所述q估计网络用于q表的拟合,采用神经网络拟合q表实现连续状态空间的强化学习,所述q估计网络的训练损失函数为:
[0039][0040]
其中,为q估计网络拟合参数,s
i,t
为用电需求d
i,t
对应的环境状态,yi为训练标签:
[0041][0042]
使用联合奖励更新q表:
[0043][0044]
其中,β为学习率,γ为衰减系数,maxaq(.,.)为根据a求最大值。
[0045]
所述r估计网络为宽大强化学习的核心,用于针对代价函数不确定项给即时奖励r
i,t
带来的不确定性,采用神经网络拟合奖励分布,消除不确定性,所述r估计网络的训练损失函数为:
[0046][0047]
其中,为r估计网络拟合参数。
[0048]
步骤8、更新贪婪算法中的概率∈:
[0049][0050]
步骤9、观察环境中的用电需求。当用电需求发生变化时,更新最优输出方案并返
回步骤2;当用电需求没有发生变化时,进入步骤3;当环境中无用电需求时,结束。
[0051]
本发明具有以下有益效果:
[0052]
1、相比于现有的经济调度算法,本方法通过多智能体强化学习与协作,求解总发电需求和联合奖励,提高灵活性和泛化能力。
[0053]
2、结合宽大强化学习与基于信誉值的安全隔离方案,解决了在出现网络攻击的情况下,或由于干扰而导致的不确定成本的情况下的电力系统安全经济调度问题,弥补了现有方法的不足。
附图说明
[0054]
图1是基于宽大强化学习的安全经济调度方法的整体架构图;
[0055]
图2是基于多智能体宽大强化学习的电力安全经济调度方法的流程图;
[0056]
图3是实施例中的多智能体网络拓扑结构图与机组参数;
[0057]
图4是实施例1中发电代价随训练次数变化的结果;
[0058]
图5是实施例2中发电代价随训练次数变化的结果;
[0059]
图6是实施例2中5号机组随训练次数变化的结果。
具体实施方式
[0060]
以下结合附图对本发明作进一步的解释说明;
[0061]
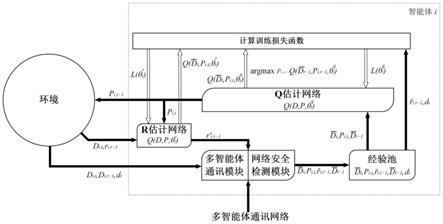
图1是基于宽大强化学习的安全经济调度方法的整体架构图,具体包括环境、多智能体网络以及多个相互协作的智能体。
[0062]
所述环境包括所有除智能体以外的部分,是自然存在的,本方法通过整合环境的变量,将分布式经济调度问题构建为一个可通过多智能体强化学习解决的合作决策问题。分布式经济调度问题存在于环境中,强化学习的动作为发电机组的输出功率,状态为环境中存在的用电需求,即时奖励与环境可以计算的发电代价相关。
[0063]
智能体处于环境中,可以观察并获取其状态,据此决策并执行相应动作,通过环境反馈的奖励优化其策略,找到最优的输出功率。
[0064]
所述智能体部署了基于宽大强化学习的安全经济调度方法,处于环境中,可以观察并获取环境的状态,根据获得的信息进行决策并执行相应动作,通过q表评估其状态-动作的价值,以确定执行哪一种动作可以获得更大的累积奖励。智能体通过q估计网络、r估计网络和经验池改进决策能力,找到最优的输出功率。
[0065]
q估计网络用于q表的拟合,采用神经网络拟合q表可以实现连续状态空间的强化学习,也是本发明体现泛化能力的基础。r估计网络为宽大强化学习的核心,用于针对代价函数不确定项给即时奖励ri带来的不确定性,采用神经网络拟合奖励分布。经验池用于消除训练数据间的关联性,存储了智能体的单步训练元组,每次的q表更新都是从经验池中随机抽取批训练。
[0066]
多智能体网络的通讯通过多智能体通讯模块实现,智能体通过接收、发送消息给其邻居智能体,可以使得整个多智能体系统对需要的变量达到一致性,用于总发电需求、联合奖励的求解。
[0067]
网络安全检测模块用于解决多智能体系统的网络安全问题,基于信誉度的方法针
对dos攻击fdi攻击进行检测与隔离。
[0068]
所述多智能体网络即由多个配置了本方法的智能体组成的网络,初始通信拓扑给定。
[0069]
如图2所示,基于多智能体宽大强化学习的电力安全经济调度方法具体包括以下步骤:
[0070]
步骤(1):观察环境并获取观察元组,多智能体协作求解总用电需求;
[0071]
步骤(2):检测网络攻击,并执行安全隔离;
[0072]
步骤(3):独立决策获取发电输出;
[0073]
步骤(4):多智能体协作求解满足用电需求的输出组合;
[0074]
步骤(5):执行动作并获取奖励,评估状态-动作价值;
[0075]
步骤(6):达到一定训练次数,从经验池抽取样本,更新q估计网络与r估计网络;
[0076]
步骤(7):更新贪婪算法探索与开发平衡;
[0077]
步骤(8):判断用电需求是否有变化,若是,更新最优输出方案,进入步骤(1),若否,返回步骤(2);
[0078]
步骤(9):输出结果。
[0079]
根据上述步骤部属智能体,进行电力安全经济调度。
[0080]
实施例1
[0081]
如图3所示,本实施例为4机组系统,设置为没有机组受到网络攻击。根据本方法进行电力安全经济调度,在总用电需求为800mw的发电代价随训练变化的结果如图4,根据训练结果可知本方法可以有效解决分布式经济调度问题。
[0082]
实施例2
[0083]
本实施例为5机组系统,其中1~4号机组的参数与实施例1的参数相同,5号机组设置为会随机受到网络攻击。在总用电需求为800mw的条件下采用本方法与现有技术分别进行电力安全经济调度,发电代价随训练变化的结果如图5所示,5号机组的信誉度随训练变化的结果如图6所示。由训练结果可知,本方法可以有效应对网络攻击,并且在解决分布式经济调度问题时可以有效降低成本。在5号机组受到攻击时,本方法可以降低其信誉度,实现攻击隔离,从而应对网络攻击。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1