一种风景体验影响因子及其情感倾向、重要度的分析方法与流程
1.本发明属于景区的影响因子评价技术领域,具体涉及一种风景体验影响因子及其情感倾向、重要度的分析方法。
背景技术:
2.风景体验是大众在风景游览过程中对风景感知、认知、体会和感受总和,由风景环境体验和风景本体体验两部分构成。风景体验不局限于在单一的物体或场所中,而是包括在一个人在游览过程中获得的全部风景体验。风景体验的最高层次是风景审美,但是大多数的风景体验停留在感知和认知层面。对于风景体验影响因子贡献率的量化和排序方法,一般运用因子分析模型法(kaltenborn and bjerke 2002,qi et al.2013,康传德2007)、结构方程模型(song et al.2012,周芷莙2016)、模糊综合评价法(曲畅2016)、重要性-绩效表现分析法(ipa分析法)(luo et al.2021)、生态位模型(yu et al.2020,周彬et al.2014)、解释结构模型(ism)(han et al.2019,zhang et al.2020,廖秋林et al.2012)等方法进行研究,其中结构方程模型结合了因素分析和路径分析,在分析时同时考虑因子结构和因子关系,是目前相对完善的模型,最优模型可以得到估计参数和拟合指数,且结构方程基于协方差分析法、偏最小二乘法(rajaratnam et al.2014)和贝叶斯法,与机器学习方法有交叉(吴兵福2006)。
3.但由于游客自身因素和景区的独特性,各种模型在实际运用中存在不适用性,如这些方法事先确定影响因素,主观性太强;因子分析模型在计算时运用最小二乘法会失效;结构方程无法判断模型的正确性,只能通过寻找模型的错误找到最佳模型,因而需要对模型进行反复训练等。目前在影响因素排序方面的研究较少,一般运用回归分析法和结构方程模型的路径分析进行排序(史春云et al.2008)。近两年,随着人工智能的发展,影响因素研究中逐渐引入机器学习和深度学习的方法。如部分研究尝试运用最大熵模型、朴素贝叶斯等机器学习方法(plunz et al.2019,zhang et al.2019),百度api(双向lstm结构)、长短期记忆模型循环神经网络(lstm)等深度学习方法模型算法(wang et al.2020)。这些研究发掘了景点美感度、游客满意度等因素,但并未对风景体验进行研究,也未对影响风景体验的因子及其影响程度进行排序。
技术实现要素:
4.针对以上技术问题,本发明提供一种风景体验影响因子及其情感倾向、重要度的分析方法。
5.为了实现上述目的,本发明采用如下技术方案:
6.一种风景体验影响因子及其情感倾向、重要度的分析方法,从社会媒介入手,利用大数据的方式获取公众对风景的体验评价,基于最大熵模型,依据参数在正态分布中的假设检验结果p值来筛选过滤无统计学意义的风景体验影响因子,根据权重的正负性风景体验情感认知的态度倾向,根据t值筛选影响因子并进行影响重要程度的排序。
7.进一步地,基于最大熵模型基于最大熵理论,在所有的满足约束条件的模型中,其信息熵最大;若植物、空气等风景体验影响因子为随机变量x,风景体验积极消极倾向性为y,随机变量x的概率分布为p(x),则熵h(x)的计算公式为:
8.h(x)=-∑
x
p(x,y)logp(x)。
9.进一步地,当熵值取最大时,即为最大熵模型,表达式如下:
[0010][0011]
其中p(y|x)为条件概率分布,p(x,y)为联合概率分布。
[0012]
进一步地,采用梯度下降法对参数进行训练,其参数即为权重;为了研究风景体验影响因子与游客的体验之间的相关性大小,引入t值对最大熵模型求解后的参数进行分析,其计算公式为:
[0013][0014]
其中为样本平均值,s为标准差,n为样本总量,即评论总数,μo为总体平均数,假设为0。
[0015]
进一步地,根据网络文本提取影响风景体验的高频词汇作为所述风景体验影响因子,并把这些词汇风划分为风景本体影响因子和风景环境影响因子。
[0016]
进一步地,所述风景本体影响因子包括地形地貌、空气和天气;所述风景环境影响因子包括价格、人流量、管理、服务态度、游览设施和标识服务。
[0017]
本发明具有如下有益效果:
[0018]
不同于传统研究风景体验的方法,本方法从社会媒介入手,利用大数据的方式获取公众对风景的体验评价,来对风景体验进行研究,最大熵模型可依据参数在正态分布中的假设检验结果p值来筛选过滤无统计学意义的影响因素,可以根据权重的正负值判断风景体验因素的积极消极倾向,根据t值筛选影响因素并进行影响重要程度的排序,将传统方法中“满意度-重要度”等指标有机统一,其排序结果更科学合理,而朴素贝叶斯模型等方法的互信息值均为正值,无法直接判断因素的积极、消极倾向。
附图说明
[0019]
图1为本发明流程图;
[0020]
图2为不同模型对比图。
具体实施方式
[0021]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0022]
一种风景体验影响因子及其情感倾向、重要度的分析方法,从社会媒介入手,利用大数据的方式获取公众对风景的体验评价,基于最大熵模型,依据参数在正态分布中的假设检验结果p值来筛选过滤无统计学意义的风景体验影响因子,根据权重的正负性风景体
验情感认知的态度倾向,根据t值筛选影响因子并进行影响重要程度的排序。
[0023]
基于最大熵模型基于最大熵理论,在所有的满足约束条件的模型中,其信息熵最大;若植物、空气等风景体验影响因子为随机变量x,风景体验积极消极倾向性为y,随机变量x的概率分布为p(x),则熵h(x)的计算公式为:
[0024]
h(x)=-∑
x
p(x,y)logp(x)。
[0025]
当熵值取最大时,即为最大熵模型,表达式如下:
[0026][0027]
其中p(y|x)为条件概率分布,p(x,y)为联合概率分布。
[0028]
由于本研究研究的问题本质上是一个二分类问题,所以最大熵模型的学习转换为对logistic回归的凸优化问题。采用梯度下降法对参数进行训练,其参数即为权重;为了研究风景体验影响因子与游客的体验之间的相关性大小,引入t值对最大熵模型求解后的参数进行分析,其计算公式为:
[0029][0030]
其中为样本平均值,s为标准差,n为样本总量,即评论总数,μo为总体平均数,假设为0。
[0031]
根据网络文本提取影响风景体验的高频词汇作为风景体验影响因子,并把这些词汇风划分为风景本体影响因子和风景环境影响因子。
[0032]
风景体验本体影响因子包括地形地貌、空气和天气;风景环境影响因子包括价格、人流量、管理、服务态度、游览设施和标识服务。
[0033]
具体实例数据见表1、表2
[0034]
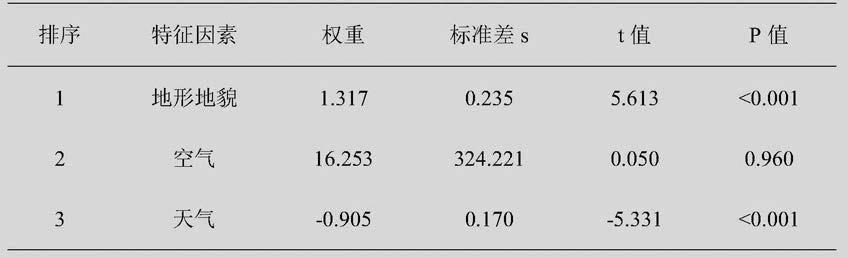
由表1可知,地形地貌和天气的p值小于0.001,影响显著。水体、动物、植物这三个因素影响极小被最大熵模型过滤,而空气因素的p值为0.96,不具有统计学意义。根据权重的正负性,地形地貌的权重大于零,为风景体验正向影响因素;天气的权重小于0,为风景体验负向影响因素。根据t值,其影响重要程度排序为地形地貌、天气。由表2可知,价格、人流量、管理、服务态度、游览设施、标识服务的p值均小于或等于0.001,影响显著。内部交通、卫生因其影响极小被最大熵模型过滤。风景环境影响因素的权重均小于零,均为负向影响风景体验;根据t值,其影响重要程度排序为价格、人流量、管理、服务态度、游览设施、标识服务。
[0035]
表1最大熵模型风景本体影响因素排序
[0036][0037]
表2最大熵模型风景环境影响因素排序
[0038][0039]
表3分类器准确率表
[0040][0041]
从图2的roc曲线可以看出,朴素贝叶斯模型的roc曲线的面积(auc)为0.79,最大熵模型的auc值为0.78,准确度分别为79%和78%,两种分类器的性能都比较优秀,且效果基本一致。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1