一种可重映射的GPU主存访问管理方法和系统与流程
一种可重映射的gpu主存访问管理方法和系统
技术领域
1.本发明涉及计算机技术领域,特别是涉及一种可重映射的gpu(graphics processing unit,图形处理器)主存访问管理方法和系统。
背景技术:
2.在采用gpu进行图形渲染时,渲染数据一般存储在gpu的显存中和/或cpu(central processing unit,中央处理器)的主存中,在进行渲染过程中,cpu可以将渲染指令发送给gpu,渲染指令中包括数据在显存和主存上的存储地址,gpu根据该存储地址就可以读取相应的存储数据,并对数据进行渲染处理后就可以得到渲染后的图像。一般情况下,gpu使用显存效率更高,访问速度更快。但是,对于一些特殊应用场景,例如显存耗尽,或者需要cpu频繁操作且gpu需要访问的空间,或是一些特殊应用,例如opencl(open computing language,开放运算语言),gpu需要使用到主存,甚至是大量主存。
3.对于pcie(peripheral component interconnect express)独立显卡,一般属于numa(non-uniform-memory-access)显卡,gpu和cpu是异构的,其寻址空间也是相互独立的,gpu访问主存必须经过pcie的映射。由于pcie映射资源的限制,以及gpu寻址空间的限制,gpu不可能直接访问所有主存。目前的方案要么将部分主存空间经pcie直接映射到gpu主存地址空间,让gpu访问部分主存,要么采用iommu(input/output memory management unit,输入/输出内存管理单元)将主存地址映射到gpu主存地址空间。前一种方案访问主存有限制,后一种方案要增加一级映射,影响效率。
技术实现要素:
4.针对现有技术的缺陷,本发明的目的在于提供一种可重映射的gpu主存访问管理方法和系统,旨在突破gpu访问主存的限制,使得gpu访问主存更高效。
5.为解决上述问题,按照本发明的一个方面,提供了一种可重映射的gpu主存访问管理方法和系统,包括以下步骤:
6.(1)根据预设的gpu所需主存地址空间的范围,将主存地址空间分为两个池,定义为直通池和映射池;
7.(2)从直通池进行空间分配,若gpu所需分配主存地址空间为连续的且大小小于或等于预设的最大连续空间阈值,转到步骤(3),否则转到步骤(4);
8.(3)分配连续的主存空间和物理地址给gpu,若成功,转到步骤(9),否则转到步骤(4);
9.(4)分配非连续的主存空间和物理地址链表给gpu,若成功,转到步骤(9),否则转到步骤(5);
10.(5)从映射池进行空间分配,若gpu所需分配主存地址空间为连续的,转到步骤(6),否则转到步骤(7);
11.(6)分配连续的主存空间和物理地址给gpu,若成功,转到步骤(8),否则分配失败;
12.(7)分配非连续的主存空间和物理地址给gpu,若成功,转到步骤(8),否则分配失败;
13.(8)配置atu(address translation unit,地址转换单元)进行映射处理;
14.(9)通过gmmu(gpu memory management unit,图形处理器内存管理单元)页表建立gpu虚拟地址和gpu物理地址及gpu物理地址链表的映射关系。
15.进一步的,直通池大小为gpu主存地址空间大小,且从0地址开始,剩下的主存空间即为映射池。
16.进一步的,步骤(2)从直通池进行空间分配中,gpu所需分配主存地址空间以等量线性映射的方式映射到直通池。
17.进一步的,步骤(2)从直通池进行空间分配中,cpu物理地址和gpu物理地址为线性偏移关系。
18.进一步的,步骤(8)中通过配置atu,重建相应gpu物理地址与cpu物理地址的映射关系。
19.进一步的,步骤(9)中gmmu页表访问的方式为:
20.(a)gpu读入gpu虚拟地址;
21.(b)根据gpu虚拟地址,查询gmmu页表计算获得gpu物理地址;
22.(c)查询gpu物理地址是否在主存地址空间范围中,若是,则gpu通过atu映射访问对应主存物理地址,否则gpu直接访问显存物理地址。
23.按照本发明的另一个方面,提供一种可重映射的gpu主存访问管理系统,其特征在于,包括:主存分配器模块、gpu主存地址空间管理模块、atu映射管理模块和gmmu管理模块;
24.所述主存分配器模块用于在整个主存空间分配连续或非连续主存,且可以根据池标记控制分配主存的cpu物理地址是在直通池还是映射池,若分配连续空间成功时,该模块可以获得cpu物理地址,若分配非连续空间成功时,该模块可以获得cpu物理地址链表;
25.所述gpu主存地址空间管理模块用于管理gpu主存地址空间的gpu物理地址的分配和释放;
26.所述atu映射管理模块用于维护gpu主存地址空间的gpu物理地址与cpu物理地址映射关系表,当从映射池分配空间时,需要通过atu映射管理模块重建相应gpu物理地址与cpu物理地址映射关系;
27.所述gmmu管理模块用于维护gmmu页表,管理gpu虚拟地址与gpu物理地址的映射关系。
28.总体而言,本发明的技术方案与现有技术相比,用于取得下列有益效果:
29.本发明提供gpu主存访问管理方法,优先使用直通池分配主存空间,在大部分应用情况下降低了映射复杂度,提升了映射效率及gpu访问主存效率;另外还提供了一套主存访问管理系统,通过gmmu管理模块和atu映射管理模块灵活的进行重映射,以达到gpu访问整个主存空间的目的。
附图说明
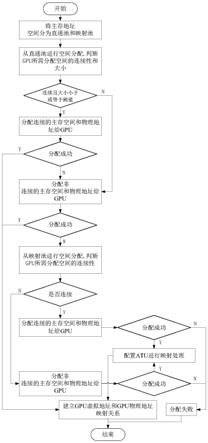
30.图1为本发明实施例提供的gpu主存访问管理方法流程图;
31.图2为本发明实施例提供的地址映射关系示意图;
32.图3为本发明实施例提供的主存分配流程图;
33.图4为本发明实施例提供的gpu访问主存流程图;
34.图5为本发明实施例提供的gpu主存访问管理系统模块框图。
具体实施方式
35.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
36.如图1所示,本发明的实施例提供了一种可重映射的gpu主存访问管理方法,所述方法包括如下步骤:
37.首先根据gpu主存地址空间范围将主存空间分为两个池,定义为直通池和映射池。直通池大小即为gpu主存地址空间大小,且从0地址开始。剩下的主存空间即为映射池。
38.现在的主流cpu平台均为64位地址空间,gpu主存地址空间范围肯定是小于64位的,比如gpu主存地址空间范围为0x0~0xffffffff共4gb。那么主存空间直通池为0x0~0xffffffff,即为所有32位地址。映射池即为0xffffffff以上的所有地址空间。默认情况下,atu映射管理模块将gpu主存地址空间等量线性映射到直通池。此时gpu物理地址与cpu物理地址相等,即偏移量为0。
39.如图2所示,当分配gpu需要访问的主存空间时;
40.首先判断上层传递的连续标记参数是否为1,若是则进入下一步,若否则进入直通池分配非连续空间流程;
41.然后,比较分配空间大小与最大连续空间阈值,例如为4mb。若分配空间小于4mb,则进入下一步直通池分配连续空间流程;反之,则进入直通池分配非连续空间流程。
42.当分配连续主存空间时,优先从直通池分配连续空间;如果分配失败,则从直通池分配非连续空间;若分配失败,则从映射池分配连续空间;若分配失败,则从映射池分配非连续空间,若分配失败,则分配gpu需要访问的主存空间失败。当分配非连续主存空间时,优先从直通池分配非连续空间;若分配失败,则从映射池分配非连续空间,若分配失败,则分配gpu需要访问的主存空间失败。
43.若主存分配器从直通池分配连续空间成功,则获得已分配连续空间的cpu物理地址,即32位地址,此地址记为c_addr1。已分配连续空间记为s1。随后通过gpu主存地址空间管理模块分配s1的gpu物理地址,记为g_addr1,此时g_addr1=c_addr1,即偏移量为0。若g_addr1已被占用,即gpu主存地址空间管理模块分配s1的gpu物理地址失败,则返回主存分配器重新从直通池分配连续空间,并释放之前申请的连续空间。若gpu主存地址空间管理模块分配s1的gpu物理地址成功,则下一步通过gmmu管理模块将g_addr1写入gmmu页表,并获得gpu虚拟地址gv_addr1,至此分配主存成功,分配流程结束。
44.若主存分配器从直通池分配非连续空间成功,则获得已分配非连续空间的cpu物理地址链表,链表包含n个连续空间,此地址链表记为c_addr2[n]。已分配非连续空间记为s2。随后通过gpu主存地址空间管理模块获得s2的gpu物理地址链表,记为g_addr2[n],此时g_addr2[0]=c_addr2[0],g_addr2[1]=c_addr2[1],
…
,g_addr2[n-1]=c_addr2[n-1]。若g_addr2[n]其中至少一个地址空间已被占用,即gpu主存地址空间管理模块分配s2的gpu
物理地址链表失败,则返回主存分配器重新从直通池分配连续非空间,并释放之前申请的非连续空间。若gpu主存地址空间管理模块分配s2的gpu物理地址链表成功,则下一步通过gmmu管理模块将g_addr2[n]写入gmmu页表,并获得gpu虚拟地址gv_addr2(连续),至此分配主存成功,分配流程结束。
[0045]
若主存分配器从映射池分配连续空间成功,则获得已分配连续空间的cpu物理地址,即64位地址,此地址记为c_addr3。已分配连续空间记为s3。随后通过gpu主存地址空间管理模块获得s3的gpu物理地址,记为g_addr3,此时g_addr3为32位范围内且不与其他gpu物理地址重合。若gpu主存地址空间管理模块分配s3的gpu物理地址失败,则表示gpu主存地址空间已被耗尽,主存分配失败。若gpu主存地址空间管理模块分配s3的gpu物理地址成功,则下一步通过atu映射管理模块将c_addr3与g_addr3建立映射关系。随后通过gmmu管理模块将g_addr3写入gmmu页表,并获得gpu虚拟地址gv_addr3,至此分配主存成功,分配流程结束。
[0046]
若主存分配器从映射池分配非连续空间成功,则获得已分配非连续空间的cpu物理地址链表,链表包含n个连续空间,此地址链表记为c_addr4[n],且这n个地址均为64位地址,已分配非连续空间记为s4。随后通过gpu主存地址空间管理模块获得s4的gpu物理地址,记为g_addr4,此时g_addr4为32位范围内且不与其他gpu物理地址重合。若gpu主存地址空间管理模块分配s4的gpu物理地址失败,则表示gpu主存地址空间已被耗尽,主存分配失败。若gpu主存地址空间管理模块分配s4的gpu物理地址成功,则下一步通过atu映射管理模块将c_addr4[n]与g_addr4建立映射关系。随后通过gmmu管理模块将g_addr4写入gmmu页表,并获得gpu虚拟地址gv_addr4,至此分配主存成功,分配流程结束。
[0047]
如图3、4所示gpu访问主存流程为:
[0048]
首先,gpu读入gpu虚拟地址gv_addr进行访问。
[0049]
随后,gpu通过虚拟地址gv_addr查询gmmu页表计算gpu物理地址g_addr。
[0050]
随后,gpu查询g_addr是否在主存地址空间范围,若是,则gpu通过atu映射访问对应主存物理地址c_addr;若否,则gpu直接访问显存物理地址。
[0051]
如图5所示,本发明实施例还公开了一种可重映射的gpu主存访问管理系统,其包括如下功能模块:
[0052]
主存分配器模块,用于在整个主存空间分配连续或非连续主存,且可以根据池标记控制分配主存的cpu物理地址是在直通池还是映射池。若分配连续空间成功时,该模块可以获得cpu物理地址。若分配非连续空间成功时,该模块可以获得cpu物理地址链表。
[0053]
gpu主存地址空间管理模块,管理gpu主存地址空间的gpu物理地址的分配,释放等。从直通池分配连续空间成功时,该模块分配与cpu物理地址相对应的gpu物理地址,此时gpu物理地址与cpu物理地址为线性偏移关系(实施例中为相等关系,即偏移为0),若相应gpu物理地址已被占用,则返回主存分配器重新从直通池分配连续空间,并释放之前申请的连续空间;从直通池分配非连续空间成功时,该模块分配与cpu物理地址链表相对应的gpu物理地址链表,此时gpu物理地址链表与cpu物理地址链表为线性偏移关系(实施例中为相等关系,即偏移为0),若相应gpu物理地址已被占用,则返回主存分配器重新从直通池分配非连续空间,并释放之前申请的非连续空间;从映射池分配连续或非连续空间成功时,该模块从gpu主存地址空闲空间中分配相对应的gpu物理地址,若gpu主存地址空间管理模块分
配失败,则表示gpu主存地址空间已被耗尽,主存分配失败。该模块产生的gpu物理地址与主存分配器产生的cpu物理地址通过atu映射管理模块建立映射关系。
[0054]
atu映射管理模块,维护gpu主存地址空间的gpu物理地址与cpu物理地址映射关系表,默认情况下,将gpu主存地址空间以等量线性映射的方式映射到直通池;当从映射池分配空间时,需要通过atu映射管理模块重建相应gpu物理地址与cpu物理地址映射关系。
[0055]
gmmu管理模块:维护gmmu页表,管理gpu虚拟地址与gpu物理地址的映射关系。
[0056]
本实施例提供的一种可重映射的gpu主存访问管理系统的执行方式与上述gpu主存访问管理方法基本相同,故不作详细赘述。
[0057]
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1