一种街道场景视频实例分割方法及系统
1.本发明涉及无人驾驶领域,具体涉及一种街道场景视频实例分割方法及系统。
背景技术:
2.环境感知是无人驾驶技术研究中的关键问题之一,为车辆在交通场景下的路径规划和决策、控制执行提供重要依据。车辆在行驶过程中需要实时获取环境信息并进行处理,目前常见的环境感知方法根据获取环境信息的传感器类型主要分为雷达、多传感器信息融合以及视觉的方法。雷达设备成本高并且只能识别深度信息而无法获取纹理和色彩;多传感器信息融合的方法成本更高并且技术难度大;而视觉的方法具有成本低,能获取纹理和色彩信息等优点,因此具有更广阔的研究和应用价值。
3.但现有技术中存在多类型纵横比锚框采用单一感受野采样导致边缘特征提取不充分和特征金字塔高层特征空间位置细节信息匮乏的技术问题。
技术实现要素:
4.本技术通过提供了一种街道场景视频实例分割方法及系统,解决了现有技术中存在多类型纵横比锚框采用单一感受野采样导致边缘特征提取不充分和特征金字塔高层特征空间位置细节信息匮乏的技术问题。达到了通过所述街道场景视频实例分割模型解决边缘特征提取不充分和补偿特征金字塔高层特征空间位置细节信息的技术效果。
5.鉴于上述问题,本技术提供了一种街道场景视频实例分割方法及系统。
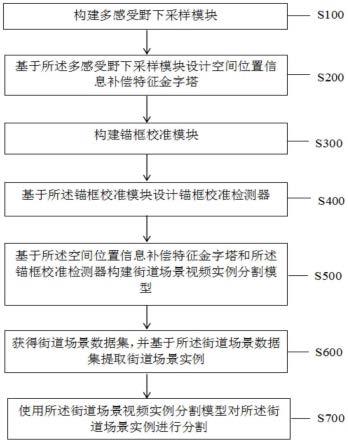
6.第一方面,本技术提供了一种街道场景视频实例分割方法,所述方法包括:构建多感受野下采样模块;基于所述多感受野下采样模块设计空间位置信息补偿特征金字塔;构建锚框校准模块;基于所述锚框校准模块设计锚框校准检测器;基于所述空间位置信息补偿特征金字塔和所述锚框校准检测器构建街道场景视频实例分割模型;获得街道场景数据集,并基于所述街道场景数据集提取街道场景实例;使用所述街道场景视频实例分割模型对所述街道场景实例进行分割。
7.另一方面,本技术提供了一种街道场景视频实例分割系统,所述系统包括:第一构建单元,所述第一构建单元用于构建多感受野下采样模块;第一执行单元,所述第一执行单元用于基于所述多感受野下采样模块设计空间位置信息补偿特征金字塔;第二构建单元,所述第二构建单元用于构建锚框校准模块;第二执行单元,所述第二执行单元用于基于所述锚框校准模块设计锚框校准检测器;第三构建单元,所述第三构建单元用于基于所述空间位置信息补偿特征金字塔和所述锚框校准检测器构建街道场景视频实例分割模型;第三执行单元,所述第三执行单元用于获得街道场景数据集,并基于所述街道场景数据集提取街道场景实例;第四执行单元,所述第四执行单元用于使用所述街道场景视频实例分割模型对所述街道场景实例进行分割。
8.第三方面,本发明提供了一种街道场景视频实例分割系统,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现第一
方面所述方法的步骤。
9.本技术中提供的一个或多个技术方案,至少具有如下技术效果或优点:
10.1.由于采用了构建多感受野下采样模块;使用构建好的多感受野下采样模块设计空间位置信息补偿特征金字塔;构建锚框校准模块;使用构建好的所述锚框校准模块设计锚框校准检测器;根据所述空间位置信息补偿特征金字塔和所述锚框校准检测器,构建街道场景视频实例分割模型;采集街道场景数据集,并且基于所述街道场景数据集对街道场景实例进行提取;进一步使用所述街道场景视频实例分割模型对所述街道场景实例进行分割的技术方案,本技术通过提供了一种街道场景视频实例分割方法及系统,达到了通过所述街道场景视频实例分割模型解决边缘特征提取不充分和补偿特征金字塔高层特征空间位置细节信息的技术效果。
11.2.由于采用了以baseline(骨干网)作为对照,设置 baseline+sl-fpn组、baseline+afc组和baseline+afc+sl-fpn组进行实验的方法,对检测和分割平均精度以及分割速度进行比较,达到了基于所述空间位置信息补偿特征金字塔和所述锚框校准检测器构建而来的街道场景视频实例分割模型(baseline+afc+sl-fpn组)检测、分割精度和检测时间综合结果最佳的技术效果。
12.上述说明仅是本技术技术方案的概述,为了能够更清楚了解本技术的技术手段,而可依照说明书的内容予以实施,并且为了让本技术的上述和其它目的、特征和优点能够更明显易懂,以下特举本技术的具体实施方式。
附图说明
13.图1为本技术实施例一种街道场景视频实例分割方法的流程示意图;
14.图2为本技术实施例一种街道场景视频实例分割方法的多感受野下采样模块架构图;
15.图3为本技术实施例一种街道场景视频实例分割方法的空间位置信息补偿特征金字塔架构图;
16.图4为本技术实施例一种街道场景视频实例分割方法的锚框校准架构图;
17.图5为本技术实施例一种街道场景视频实例分割方法的锚框校准预测图;
18.图6为本技术实施例一种街道场景视频实例分割方法的原型掩膜分支图;
19.图7为本技术实施例一种街道场景视频实例分割方法的街道场景视频实例分割模型的整体网络结构图;
20.图8为本技术实施例一种街道场景视频实例分割系统的结构示意图;
21.图9为本技术实施例示例性电子设备的结构示意图。
22.附图标记说明:第一构建单元11,第一执行单元12,第二构建单元13,第二执行单元14,第三构建单元15,第三执行单元16,第四执行单元17,电子设备300,存储器301,处理器302,通信接口 303,总线架构304。
具体实施方式
23.本技术通过提供了一种街道场景视频实例分割方法及系统,解决了现有技术中存在多类型纵横比锚框采用单一感受野采样导致边缘特征提取不充分和特征金字塔高层特
征空间位置细节信息匮乏的技术问题。达到了通过所述街道场景视频实例分割模型解决边缘特征提取不充分和补偿特征金字塔高层特征空间位置细节信息的技术效果。
24.目前常见的环境感知方法根据获取环境信息的传感器类型主要分为雷达、多传感器信息融合以及视觉的方法。雷达设备成本高并且只能识别深度信息而无法获取纹理和色彩;多传感器信息融合的方法成本更高并且技术难度大;而视觉的方法具有成本低,能获取纹理和色彩信息等优点,因此具有更广阔的研究和应用价值。现有技术中存在多类型纵横比锚框采用单一感受野采样导致边缘特征提取不充分和特征金字塔高层特征空间位置细节信息匮乏的技术问题。
25.针对上述技术问题,本技术提供的技术方案总体思路如下:
26.本技术提供了一种街道场景视频实例分割方法,所述方法包括:构建多感受野下采样模块;使用构建好的多感受野下采样模块设计空间位置信息补偿特征金字塔;构建锚框校准模块;使用构建好的所述锚框校准模块设计锚框校准检测器;根据所述空间位置信息补偿特征金字塔和所述锚框校准检测器,构建街道场景视频实例分割模型;采集街道场景数据集,并且基于所述街道场景数据集对街道场景实例进行提取;进一步使用所述街道场景视频实例分割模型对所述街道场景实例进行分割。
27.在介绍了本技术基本原理后,下面将结合说明书附图来具体介绍本技术的各种非限制性的实施方式。
28.实施例一
29.如图1所示,本技术实施例提供了一种街道场景视频实例分割方法,其中,所述方法包括:
30.步骤s100:构建多感受野下采样模块;
31.具体而言,感受野(receptive field)是卷积神经网络每一层输出的特征图上的像素点在输入图片上映射的区域大小。现有的视频实例分割技术中多类型纵横比锚框往往采用单一感受野采样,从而导致边缘特征提取不充分的问题,构建多感受野下采样模块(mrfs),所述多感受野下采样模块能够使用多个不同感受野的卷积核对目标图像进行卷积操作。使用所述多感受野下采样模块对目标图像卷积操作后,不同感受野下采样获得的特征图需要进行相加、激活和归一化,才能获得下采样结果。
32.步骤s200:基于所述多感受野下采样模块设计空间位置信息补偿特征金字塔;
33.进一步的,如图3所示,所述基于所述多感受野下采样模块设计空间位置信息补偿特征金字塔,本技术实施例步骤s200包括:
34.步骤s210:获取骨干网中c2-c5层特征,进行通道数量压缩;
35.步骤s220:将压缩通道数量后的所述c5层作为p5层;
36.步骤s230:所述p5层使用双线性插值上采样与c4特征图融合获得p4层;
37.步骤s240:所述p4层使用双线性插值上采样后与c3特征图融合获得p3层;
38.步骤s250:所述c2层利用所述多感受野下采样模块对特征图进行下采样,与经过卷积处理的p3层特征图进行相加后,再经过一次卷积处理后获得f3层;
39.步骤s260:所述f3层经过所述多感受野下采样模块进行下采样操作后,与经过一次卷积处理的p4进行相加,获得f4层;
40.步骤s270:所述f4层经过所述多感受野下采样模块进行下采样操作与经过一次卷
积处理后的p5进行相加,获得f5层;
41.步骤s280:所述f5层经过一次卷积得到f6层,所述f6层经过一次卷积得到f7层。
42.具体而言,特征金字塔是目前用于目标检测、语义分割、行为识别等方面比较重要的一个部分,对于提高模型性能具有非常好的表现。所述空间位置信息补偿特征金字塔构建优选过程如下,使用ci 标记图像骨干网中每一层的特征图,获取骨干网中c2-c5层特征,其中,所述骨干网优选为resnet50,resnet50首先对输入做了卷积操作,之后包含4个残差块(residualblock),最后进行全连接操作以便于进行分类任务。获取c2-c5层特征后,通过一个1
×
1的卷积核将通道数量压缩为256。用pi标记图像top-down结构每个特征图,例如p5代表对应c5大小的特征图。将压缩通道数量后的所述c5层作为p5层。由于所述p5层要和所述p4层进行融合所以需要通过双线性插值上采样与c4特征图达成一致,才能进行融合获得所述p4 层。同理所述p4层通过双线性插值上采样后与c3特征图融合获得 p3层。将c2层利用多感受野下采样模块对特征图进行下采样,然后与经过一次3
×
3卷积操作后的p3层特征图进行相加,再经过一次3
ꢀ×
3的卷积操作就可以得到f3层。f3层经过多感受野下采样模块进行下采样操作与经过一次3
×
3卷积操作后的p4层进行相加得到f4 层。f4层经过多感受野下采样模块进行下采样操作与经过一次3
×
3 卷积操作后p5进行相加得到f5层。所述f5层经过一次卷积得到f6 层,所述f6层经过一次卷积得到f7层。
43.上述获得f3、f4、f5层的过程可以通过如下公式表示:
44.f
iout
=conv3×3(mrfs(f
i-1
)+conv3×3(fi))
45.其中,conv3×3(g)表示卷积核为3
×
3的卷积操作;mrfs(g)为多感受野下采样模块;f
i-1
为上一层浅层特征图;fi为当前层特征图;f
iout
为输出特征图。即当前层特征图经过3
×
3的卷积操作与经过多感受野下采样模块下采样的上一层浅层特征图相加之后,在经过一次3
×
3 的卷积操作,可获得当前层的输出特征图。基于多感受野下采样模块设计空间位置信息补偿特征金字塔,能够有效改善现有视频实例分割技术中的特征金字塔高层特征空间位置细节信息匮乏的问题。
46.步骤s300:构建锚框校准模块;
47.步骤s400:基于所述锚框校准模块设计锚框校准检测器;
48.具体而言,所述锚框校准模块的构建过程如下:首先预设一组不同尺度不同位置的锚框,如图4所示,使用与锚框纵横比匹配的卷积核对特征图进行卷积处理,获得预定数目的新的特征图。进一步,再将输出的预定数目的新特征图拼接起来,通过一个1
×
1的卷积核将拼接之后的特征图通道数量降回到拼接前的通道数量即可。通过使用多个锚框校准模块设计锚框校准检测器。锚框校准检测器的检测过程包括但不限于:将特征图通过一个3
×
3卷积操作提取特征后送入 bbox、class和mask检测分支中,基于bbox、class和mask检测分支获得检测结果包括边界框、类别和掩膜系数。bbox、class和mask 检测分支即为三个锚框校准模块。三个锚框校准模块的输出通道不一样,bbox分支输出通道数为4a;class分支输出通道数为ca;mask 分支输出通道数为ka;其中a为每个像素点生成锚框数取值为3;c为类别数;k为掩膜系数。
49.步骤s500:基于所述空间位置信息补偿特征金字塔和所述锚框校准检测器构建街道场景视频实例分割模型;
50.进一步的,如图6-7所示,本技术实施例s500还包括:
51.步骤s510:采用所述resnet作为骨干网提取特征;
52.步骤s520:采用所述空间位置信息补偿特征金字塔进行多尺度特征融合,并对高层特征空间位置细节信息进行补偿;
53.步骤s530:基于所述锚框校准检测器,获得边界框、类别和掩膜系数;
54.步骤s540:使用原型掩膜分支生成原型掩膜;
55.步骤s550:所述原型掩膜与所述掩膜系数进行线性组合,获得实例掩膜。
56.具体而言,街道场景视频实例分割模型的整体网络结构如图7所示,包括:以resnet作为骨干网对目标图像进行特征提取,使用空间位置信息补偿特征金字塔,进行多尺度特征融合并且对高层特征空间位置细节信息补偿。使用所述锚框校准检测器获得输出的边界框、类别(例如人、车、滑板、狗等)以及掩膜系数。所述原型掩膜分支如图6所示,使用所述原型掩膜分支生成原型掩膜后,使用所述原型掩膜与所述掩膜系数进行线性组合,获得实例掩膜。通过所述实例掩膜可以对实例进行检测和分割。举不受限制的一例街道场景视频实例分割模型的构建过程包括但不限于,使用resnet50作为骨干网,选择余弦退火(cosine annealing)衰减学习率。实验平台为ubuntu18.04 操作系统,内存16g,cpu为amd ryzen 7 3700x,gpu为nvidiagtx3070的台式计算机。深度学习框架为pytorch1.7,采用cuda11.0 和cudnn8.0.5加速工具包加速网络训练。基于pytorch深度学习框架搭建,训练时共迭代80000次,batch size大小为6,初始学习率为 0.00005。每10000次迭代保存一个街道场景视频实例分割模型,采用最后一个街道场景视频实例分割模型验证模型精度。
57.步骤s600:获得街道场景数据集,并基于所述街道场景数据集提取街道场景实例;
58.步骤s700:使用所述街道场景视频实例分割模型对所述街道场景实例进行分割。
59.具体而言,所述街道场景数据集由大量街道上的日常场景视频构成,从所述街道场景数据集提取街道场景实例,街道场景实例包括人、滑板、轿车、狗、火车、摩托车和卡车等。将街道场景数据集划分为训练集和验证集,训练集和验证集中的实例数量比为预设比例,优选为9:1。使用所述街道场景视频实例分割模型对所述街道场景实例进行分割,使用验证集对街道场景视频实例分割模型进行验证。通过所述街道场景视频实例分割模型能够改善边缘特征提取不充分和特征金字塔高层特征空间位置细节信息匮乏的问题。
60.进一步的,如图2所示,本技术实施例步骤s100还包括:
61.步骤s110:所述多感受野下采样模块包括第一分支、第二分支、第三分支和第四分支;
62.步骤s120:分别使用所述第一分支、所述第二分支、所述第三分支、所述第四分支对图像进行特征提取,获得第一特征图、第二特征图、第三特征图和第四特征图;
63.步骤s130:将所述第一特征图、所述第二特征图、所述第三特征图、所述第四特征图进行相加、激活和归一化后,获得输出结果。
64.进一步的,所述获得输出结果,本技术实施例步骤s130包括:
65.步骤s131:获得所述输出结果的公式如下:
66.p
cc
=convi×j(convi×j(f
in
))
67.p
pc
=convi×j(pooli×j(f
in
))
68.69.其中,p
cc
表示为两个串联的卷积;p
pc
表示为先池化再卷积;convi×j(g)表示卷积核为i
×
j的卷积操作;pooli×j(g)表示池化核为i
×
j的池化操作;f
in
表示输入的特征图;mrfs表示最终输出;relu为激活函数; bn为归一化。
70.具体而言,所述多感受野下采样模块采用四个分支,其中有三个分支是卷积操作采样,其区别在于卷积核的尺寸不一样即感受野不一样。第一个分支先采用1
×
1的卷积核对特征图进行卷积操作,其主要作用是实现跨通道的信息组合,增加非线性特征。然后再通过一个 3
×
3的卷积核,步长为2的卷积操作对图像进行下采样获得所述第一特征图。第二个分支先使用5
×
3步长为(2,1)的卷积对特征图的长(w)方向进行采样操作,然后再使用一个3
×
5步长为(1,2) 的卷积对特征图的宽(h)方向进行采样操作,获得所述第二特征图。第三个分支先使用3
×
1步长为(2,1)的卷积对特征图的长(w) 方向进行采样操作,然后再使用一个1
×
3步长为(1,2)的卷积对特征图的宽(h)方向进行采样操作,获得所述第三特征图。第四个分支先用核为3
×
3,步长为2的平均池化操作,然后使用1
×
1卷积增加特征图的非线性特征,获得第四特征图。最后将四个分支所得到的特征图进行相加、激活和归一化后获得所述输出结果。获得所述输出结果公式如下:
71.p
cc
=convi×j(convi×j(f
in
))
72.p
pc
=convi×j(pooli×j(f
in
))
[0073][0074]
其中,p
cc
表示为两个串联的卷积;p
pc
表示为先池化再卷积; convi×j(g)表示卷积核为i
×
j的卷积操作;pooli×j(g)表示池化核为i
×
j的池化操作;f
in
表示输入的特征图;mrfs表示最终输出;relu为激活函数; bn为归一化,由可知,最终输出为三个p
cc
累加之后加上p
pc
后,经过relu函数激活后归一化得到的,其中p
cc
为将输入的特征图进行两个卷积的串联,p
pc
为将输入的特征图先池化后卷积。
[0075]
进一步的,如图4所示,所述构建锚框校准模块,本技术实施例步骤s300还包括:
[0076]
步骤s310:应用与锚框纵横比匹配的卷积核对特征图进行卷积,获得预定数量的输出特征图;
[0077]
步骤s320:将所述输出特征图进行拼接,并使用第一预设尺寸卷积核将拼接之后的特征图通道数量降回到拼接前的通道数量;
[0078]
步骤s330:所述锚框校准模块可表示为:
[0079]fout
=conv1×1(cat(conv5×3(f
in
)+conv3×5(f
in
)+conv3×3(f
in
)))
[0080]
其中,convi×j(g)表示卷积核为i
×
j的卷积操作;cat(g)表示将特征图拼接;f
in
表示输入的特征图;f
out
表示输出的特征图。
[0081]
进一步的,如图5所示,所述基于所述锚框校准模块设计锚框校准检测器,步骤s330包括:
[0082]
步骤s331:使用bbox、class和mask检测分支设计所述锚框校准检测器,其中,所述bbox、class和mask检测分支为三个锚框校准模块,bbox分支输出通道数为4a;class分支输出通道数为ca; mask分支输出通道数为ka;其中,a为每个像素点生成锚框数取值为3;c为类别数;k为掩膜系数。
[0083]
具体而言,如图4所示,特征图应用与锚框纵横比匹配的卷积核卷积后得到预定数量的输出特征图,预定数量的输出特征图优选为三个,即使用三个卷积核卷积后获得三个新特征图。进一步,将输出的三张新特征图拼接起来,所述第一预设尺寸卷积核为1
×
1的卷积核,通过一个1
×
1的卷积核将拼接之后的特征图通道数量降回到拼接前的通道数量。锚框校准模块可表示为:
[0084]fout
=conv1×1(cat(conv5×3(f
in
)+conv3×5(f
in
)+conv3×3(f
in
)))
[0085]
其中,convi×j(g)表示卷积核为i
×
j的卷积操作;cat(g)表示将特征图拼接;f
in
表示输入的特征图;f
out
表示输出的特征图。通过上述公式,将三个输入的特征图分别用与锚框纵横比匹配的卷积核进行卷积处理,卷积核尺寸分别为5
×
3、3
×
5、3
×
3,卷积处理后通过cat(g)命令进行拼接,在通过1
×
1的卷积核对通道数量还原。
[0086]
进一步而言,使用bbox、class和mask三个检测分支设计锚框校准检测器。其中bbox、class和mask检测分支为三个锚框校准模块,bbox分支输出通道数为4a;class分支输出通道数为ca;mask 分支输出通道数为ka;其中a为每个像素点生成锚框数取值为3;c为类别数;k为掩膜系数。bbox检测分支用于检测边界框,class检测分支用于检测类别,mask检测分支用于检测掩膜系数。由于a为每个像素点生成锚框数,取值为3,可以得到bbox分支输出通道数为12,class分支输出通道数为3c,mask分支输出通道数为3k。
[0087]
综上所述,本技术实施例所提供的一种街道场景视频实例分割方法及系统具有如下技术效果:
[0088]
1.由于采用了构建多感受野下采样模块;使用构建好的多感受野下采样模块设计空间位置信息补偿特征金字塔;构建锚框校准模块;使用构建好的所述锚框校准模块设计锚框校准检测器;根据所述空间位置信息补偿特征金字塔和所述锚框校准检测器,构建街道场景视频实例分割模型;采集街道场景数据集,并且基于所述街道场景数据集对街道场景实例进行提取;进一步使用所述街道场景视频实例分割模型对所述街道场景实例进行分割的技术方案,本技术通过提供了一种街道场景视频实例分割方法及系统,达到了通过所述街道场景视频实例分割模型解决边缘特征提取不充分和补偿特征金字塔高层特征空间位置细节信息的技术效果。
[0089]
实施例二
[0090]
将youtube-vis公开数据集作为数据来源,从youtube-vis公开数据集中提取所需的数据,构建街道场景数据集,进行一种街道场景视频实例分割方法的效果验证。具体过程如下:
[0091]
从youtube-vis数据集提供的标签文件中提取出所需的街道场景实例;并将街道场景数据集划分为训练集和验证集,训练集和验证集中的实例数量比为9:1。
[0092]
实验所用数据集详细数据:实例分为人、滑板、轿车、狗、火车、摩托车和卡车等七类。其中,训练集有329个视频片段,总帧数为7212,包含603个实例,验证集中有53个视频片段,总帧数为1097,包含88个实例。数据具体内容如表1,训练集和验证集中的实例数量比为9:1。
[0093]
表1街道场景数据集实例数量
[0094][0095]
实验参数:主干网使用的是resnet50;选择余弦退火(cosineannealing)衰减学习率。实验平台为ubuntu18.04操作系统,内存16g, cpu为amd ryzen 7 3700x,gpu为nvidia gtx3070的台式计算机。深度学习框架为pytorch1.7,采用cuda11.0和cudnn8.0.5加速工具包加速网络训练。基于pytorch深度学习框架搭建,训练时共迭代80000次,batch size大小为6,初始学习率为0.00005。每10000 次迭代保存一个模型,采用最后一个模型验证模型精度。
[0096]
表2模型验证结果
[0097][0098]
如表2所示,与baseline结果相比,可知空间位置信息补偿特征金字塔(sl-fpn)提升网络检测和分割的平均精度分别提升7.76%和4.75%;锚框校准(afc)提升网络检测和分割的平均精度分别提升8.63%和5.09%;空间位置信息补偿特征金字塔和锚框校准一起使用检测和分割平均分别达到了38.73%和37.03%,与baseline相比检测和分割平均精度分别提升9.26%和6.46%,速度达到每秒分割26 帧。
[0099]
实施例三
[0100]
基于与前述实施例中一种街道场景视频实例分割方法相同的发明构思,如图8所示,本技术实施例提供了一种街道场景视频实例分割系统,其中,所述系统包括:
[0101]
第一构建单元11,所述第一构建单元11用于构建多感受野下采样模块;
[0102]
第一执行单元12,所述第一执行单元12用于基于所述多感受野下采样模块设计空间位置信息补偿特征金字塔;
[0103]
第二构建单元13,所述第二构建单元13用于构建锚框校准模块;
[0104]
第二执行单元14,所述第二执行单元14用于基于所述锚框校准模块设计锚框校准检测器;
[0105]
第三构建单元15,所述第三构建单元15用于基于所述空间位置信息补偿特征金字塔和所述锚框校准检测器构建街道场景视频实例分割模型;
[0106]
第三执行单元16,所述第三执行单元16用于获得街道场景数据集,并基于所述街
道场景数据集提取街道场景实例;
[0107]
第四执行单元17,所述第四执行单元17用于使用所述街道场景视频实例分割模型对所述街道场景实例进行分割。
[0108]
进一步的,所述系统包括:
[0109]
第一获得单元,所述第一获得单元用于分别使用所述第一分支、所述第二分支、所述第三分支、所述第四分支对图像进行特征提取,获得第一特征图、第二特征图、第三特征图和第四特征图;
[0110]
第二获得单元,所述第二获得单元用于将所述第一特征图、所述第二特征图、所述第三特征图、所述第四特征图进行相加、激活和归一化后,获得输出结果。
[0111]
进一步的,所述系统包括:
[0112]
第五执行单元,所述第五执行单元用于获取骨干网中c2-c5层特征,进行通道数量压缩;
[0113]
第六执行单元,所述第六执行单元用于将压缩通道数量后的所述 c5层作为p5层;
[0114]
第三获得单元,所述第三获得单元用于所述p5层使用双线性插值上采样与c4特征图融合获得p4层;
[0115]
第四获得单元,所述第四获得单元用于所述p4层使用双线性插值上采样后与c3特征图融合获得p3层;
[0116]
第五获得单元,所述第五获得单元用于所述c2层利用所述多感受野下采样模块对特征图进行下采样,与经过卷积处理的p3层特征图进行相加后,再经过一次卷积处理后获得f3层;
[0117]
第六获得单元,所述第六获得单元用于所述f3层经过所述多感受野下采样模块进行下采样操作后,与经过一次卷积处理的p4进行相加,获得f4层;
[0118]
第七获得单元,所述第七获得单元用于所述f4层经过所述多感受野下采样模块进行下采样操作与经过一次卷积处理后的p5进行相加,获得f5层;
[0119]
第八获得单元,所述第八获得单元用于所述f5层经过一次卷积得到f6层,所述f6层经过一次卷积得到f7层。
[0120]
进一步的,所述系统包括:
[0121]
第九获得单元,所述第九获得单元用于应用与锚框纵横比匹配的卷积核对特征图进行卷积,获得预定数量的输出特征图;
[0122]
第七执行单元,所述第七执行单元用于将所述输出特征图进行拼接,并使用第一预设尺寸卷积核将拼接之后的特征图通道数量降回到拼接前的通道数量。
[0123]
进一步的,所述系统包括:
[0124]
第八执行单元,所述第八执行单元用于使用bbox、class和mask 检测分支设计所述锚框校准检测器,其中,所述bbox、class和mask 检测分支为三个锚框校准模块,bbox分支输出通道数为4a;class分支输出通道数为ca;mask分支输出通道数为ka;其中a为每个像素点生成锚框数取值为3;c为类别数;k为掩膜系数。
[0125]
进一步的,所述系统包括:
[0126]
第九执行单元,所述第九执行单元用于采用所述resnet作为骨干网提取特征;
[0127]
第十执行单元,所述第十执行单元用于采用所述空间位置信息补偿特征金字塔进
行多尺度特征融合,并对高层特征空间位置细节信息进行补偿;
[0128]
第十获得单元,所述第十获得单元用于基于所述锚框校准检测器,获得边界框、类别和掩膜系数;
[0129]
第一生成单元,所述第一生成单元用于使用原型掩膜分支生成原型掩膜;
[0130]
第十一获得单元,所述第十一获得单元用于所述原型掩膜与所述掩膜系数进行线性组合,获得实例掩膜。
[0131]
示例性电子设备
[0132]
下面参考图9来描述本技术实施例的电子设备。
[0133]
基于与前述实施例中一种街道场景视频实例分割方法相同的发明构思,本技术实施例还提供了一种街道场景视频实例分割系统,包括:处理器,所述处理器与存储器耦合,所述存储器用于存储程序,当所述程序被所述处理器执行时,使得系统以执行第一方面任一项所述的方法。
[0134]
该电子设备300包括:处理器302、通信接口303、存储器301。可选的,电子设备300还可以包括总线架构304。其中,通信接口303、处理器302以及存储器301可以通过总线架构304相互连接;总线架构304可以是外设部件互连标(peripheral component interconnect,简称pci)总线或扩展工业标准结构(extended industry standardarchitecture,简称eisa)总线等。所述总线架构304可以分为地址总线、数据总线、控制总线等。为便于表示,图9中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
[0135]
处理器302可以是一个cpu,微处理器,asic,或一个或多个用于控制本技术方案程序执行的集成电路。
[0136]
通信接口303,使用任何收发器一类的装置,用于与其他设备或通信网络通信,如以太网,无线接入网(radio access network,ran), 无线局域网(wireless local area networks,wlan),有线接入网等。
[0137]
存储器301可以是rom或可存储静态信息和指令的其他类型的静态存储设备,ram或者可存储信息和指令的其他类型的动态存储设备,也可以是电可擦可编程只读存储器(electrically erasableprogrammable read-only memory,eeprom)、只读光盘(compact discread-only memory,cd-rom)或其他光盘存储、光碟存储(包括压缩光碟、激光碟、光碟、数字通用光碟、蓝光光碟等)、磁盘存储介质或者其他磁存储设备、或者能够用于携带或存储具有指令或数据结构形式的期望的程序代码并能够由计算机存取的任何其他介质,但不限于此。存储器可以是独立存在,通过总线架构304与处理器相连接。存储器也可以和处理器集成在一起。
[0138]
其中,存储器301用于存储执行本技术方案的计算机执行指令,并由处理器302来控制执行。处理器302用于执行存储器301中存储的计算机执行指令,从而实现本技术上述实施例提供的一种街道场景视频实例分割方法。
[0139]
可选的,本技术实施例中的计算机执行指令也可以称之为应用程序代码,本技术实施例对此不作具体限定。
[0140]
本技术实施例提供了一种街道场景视频实例分割方法,其中,所述方法包括:构建多感受野下采样模块;使用构建好的多感受野下采样模块设计空间位置信息补偿特征金字塔;构建锚框校准模块;使用构建好的所述锚框校准模块设计锚框校准检测器;根据所述空
间位置信息补偿特征金字塔和所述锚框校准检测器,构建街道场景视频实例分割模型;采集街道场景数据集,并且基于所述街道场景数据集对街道场景实例进行提取;进一步使用所述街道场景视频实例分割模型对所述街道场景实例进行分割。
[0141]
本领域普通技术人员可以理解:本技术中涉及的第一、第二等各种数字编号仅为描述方便进行的区分,并不用来限制本技术实施例的范围,也不表示先后顺序。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。“至少一个”是指一个或者多个。至少两个是指两个或者多个。“至少一个”、“任意一个”或其类似表达,是指的这些项中的任意组合,包括单项(个)或复数项(个)的任意组合。例如,a,b, 或c中的至少一项(个、种),可以表示:a,b,c,a-b,a-c,b-c,或a-b-c,其中a,b,c可以是单个,也可以是多个。
[0142]
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行所述计算机程序指令时,全部或部分地产生按照本技术实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(dsl))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存取的任何可用介质或者是包括一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,dvd)、或者半导体介质(例如固态硬盘(solid state disk,ssd))等。
[0143]
本技术实施例中所描述的各种说明性的逻辑单元和电路可以通过通用处理器,数字信号处理器,专用集成电路(asic),现场可编程门阵列(fpga)或其它可编程逻辑装置,离散门或晶体管逻辑,离散硬件部件,或上述任何组合的设计来实现或操作所描述的功能。通用处理器可以为微处理器,可选地,该通用处理器也可以为任何传统的处理器、控制器、微控制器或状态机。处理器也可以通过计算装置的组合来实现,例如数字信号处理器和微处理器,多个微处理器,一个或多个微处理器联合一个数字信号处理器核,或任何其它类似的配置来实现。
[0144]
本技术实施例中所描述的方法或算法的步骤可以直接嵌入硬件、处理器执行的软件单元、或者这两者的结合。软件单元可以存储于 ram存储器、闪存、rom存储器、eprom存储器、eeprom存储器、寄存器、硬盘、可移动磁盘、cd-rom或本领域中其它任意形式的存储媒介中。示例性地,存储媒介可以与处理器连接,以使得处理器可以从存储媒介中读取信息,并可以向存储媒介存写信息。可选地,存储媒介还可以集成到处理器中。处理器和存储媒介可以设置于 asic中,asic可以设置于终端中。可选地,处理器和存储媒介也可以设置于终端中的不同的部件中。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程
和/或方框图一个方框或多个方框中指定的功能的步骤。
[0145]
尽管结合具体特征及其实施例对本技术进行了描述,显而易见的,在不脱离本技术的精神和范围的情况下,可对其进行各种修改和组合。相应地,本说明书和附图仅仅是本技术的示例性说明,且视为已覆盖本技术范围内的任意和所有修改、变化、组合或等同物。显然,本领域的技术人员可以对本技术进行各种改动和变型而不脱离本技术的范围。这样,倘若本技术的这些修改和变型属于本技术及其等同技术的范围之内,则本技术意图包括这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1