一种融合五维特征的高普适性多对多关系三元组抽取方法与流程
1.本发明涉及一种融合多维特征开放场景下三元组抽取方法,涉及自然语言处理技术领域。
背景技术:
2.随着大数据时代的到来,海量的数据充斥着我们的生活,如何从庞杂的数据中筛选出重要信息,高效地利用是重要的研究方向。三元组抽取可以从海量的文本中获取结构化信息,从而描述客观世界中的概念、实体间的复杂关系,提供了一种更好地组织、管理和理解互联网海量信息的能力。同时,从非结构化文本中提取关系三元组是构建大规模知识图的关键,经过数据融合后的三元组将成为智能问答、信息检索、推荐系统等上层人工智能应用的重要数据基础。
3.然而在进行限定域三元组抽取时,需要针对三元组中的特定关系类型事先进行定义,但是如果更换抽取场景,关系类型发生变化后,原先的模型几乎抽取不到三元组,这就得重新定义关系类型并标注数据集,而且这个标注过程相当耗时,成本几乎无法接受。因此,设计开放场景下的三元组抽取模型十分必要,该模型无需在新业务场景标注新关系类型和数据,而是可以直接抽取三元组,经过属性归一和实体对齐之后这些三元组将成为知识图谱的核心数据;经过统计和关联分析这些三元组的关系词和实体类型可以用于揭示领域的热点技术、新兴方向和知识体系。此外,由于不需要事先定义关系类型,开放场景中将抽取大量的低频关系,这些低频关系也具有一定的意义,如:图谱问答系统,只要抽取结果是正确的,一个高频的关系和低频关系的回答方式并没有差异,因此只要能保证开放场景下的三元组抽取准确率达到一定水准,相较于限定关系抽取而言则具有不可替代的优势。
4.大多数现有的三元组方法用于处理一对一关系问题,不能有效地处理一个句子包含多个相互重叠的关系三元组的场景,在解决同一句子中的多个关系三元组共享相同实体的重叠三元组问题中捉襟见肘。棘手的是,现实场景中大部分实体间都包含多种复杂的关联关系,如果不能解决该问题,那么知识图谱则不完整,图谱中本该关联的实体成为独立的孤岛,直接影响到图谱的预测和推理功能。因此进行多对多关系三元组的抽取研究是知识图谱落地的重要步骤,是知识图谱支撑上层应用的重要保障。
技术实现要素:
5.本发明的目的是:实现多对多关系三元组的抽取。
6.为了达到上述目的,本发明的技术方案是提供了一种融合五维特征的高普适性多对多关系三元组抽取方法,其特征在于,包括以下步骤:第一步:数据准备准备用于训练实体识别模型的实体识别语料以及用于三元组分类引擎训练的三元组分类语料,其中,取语义角色类型为施事者作为头实体、受事者作为尾实体、施事者及受事者对应的谓词作为关系,同组出现的语义角色构成结构为《头实体,关系,尾实体》的三
元组;第二步:构建用于进行实体抽取的实体识别模型,包括以下步骤:步骤1、生成底层自然语言处理特征对文本进行分句,再使用底层自然语言处理工具hanlp对文本中的每句句子进行分词,生成分词的词性、语义角色、语义依存和句法依存四个维度特征;步骤2、引入bert预训练词向量基于步骤1中的分词结果,使用基于词颗粒度中文wobert的预训练模型,为每句句子生成维度为n的分词预训练向量,这样就得到了每句句子的预训练句子向量{y1,y2,
…
,yi,
…
,yn},yi为预训练句子向量中的第i个预训练词向量;步骤3、引入依存关系,具体包括以下步骤:步骤301、根据语义和句法依存关系的类别,生成相应类别的语义依存关系超平面、句法依存关系超平面、语义依存关系向量、句法依存关系向量;步骤302、找出每句句子中独立的分词,将该分词作为根节点,为每句句子分别建立语义依存树以及句法依存树,由语义依存树以及句法依存树的所有节点分别组成当前句子的包含有语义依存关系的句子向量{sdp1,sdp2,
…
,sdpi,
…
,sdpn}和包含有句法依存关系的句子向量{sep1,sep2,
…
,sepi,
…
,sepn},其中,sdpi为当前句子向量中第i个包含有语义依存关系的词向量,sepi为当前句子向量中第i个包含有句法依存关系的词向量;语义依存树以及句法依存树中,除根节点向量为第二步得到对应分词的预训练词向量外,其他节点的向量为依赖节点的预训练词向量在相应关系的语义依存超平面或句法依存关系中的投影和语义依存关系向量或句法依存向量的翻译;步骤4:引入词性和语义角色在基于词颗粒度中文wobert中随机初始化维度为k
pos
×
n的向量以及维度为k
srl
×
n的向量,其中,k
pos
和k
srl
分别表示词性和语义角色的种类数量,根据每个句子中各个分词的词性和语义角色类型,为每个句子生成表示词性的句子向量{pos1,pos2,
…
,posi,
…
,posn}以及表示语义角色的句子向量{srl1,srl2,
…
,srli,
…
,srln},其中,posi为当前句子向量中第i个表示词性的词向量,srli为当前句子向量中第i个表示语义角色的词向量;步骤5:使用lex-bert v2中的共享位置嵌入的方法,将步骤2、步骤3及步骤4得到的五种维度的词向量进行拼接,获得五维特征词向量;步骤6:实体识别模型基于五维特征词向量进行实体识别,并利用实体识别语料对实体识别模型进行训练,直至模型收敛,并得到模型收敛时的所有类别的语义和句法依存关系的关系超平面以及关系向量;第三步:构建用于判断实体识别模型抽取的实体是否构成三元组的三元组分类引擎:三元组分类引擎使用textcnn分类网络对包含语义和句法依存特征的实体对进行分类,判断是否构成三元组,其中,三元组分类引擎的输入是三元组间的语义和句法依存关系,输入顺序为头实体《-》关系、尾实体《-》关系、头实体《-》尾实体,其中,x《-》y表示x依赖y的语义和句法依存关系类型集合和y依赖x的语义和句法依存关系类型集合;使用训练实体识别模型得到的所有类别的语义和句法依存关系的关系向量初始化依赖关系并嵌入字典,该字典随着三元组分类引擎所采用的textcnn分类网络利用三元组分类语料一起训练。
7.优选的,步骤302中,若节点x2与节点x1存在某个类别的语义依存关系或句法依存关系,则当前类别的语义依存关系超平面或句法依存关系超平面向量为w,当前类别的语义依存向量或句法依存向量为r,方向为x1依赖x2,则语义依存树或句法依存树中,节点x1的向量为翻译向量t1,则有t1=r-y
⊥2,其中,y
⊥2为步骤2得到节点x2所对应的预训练词向量y2在当前类别的语义依存关系超平面或句法依存关系超平面中的投影。
8.优选的,将训练完成的实体抽取模型和三元组分类引擎结合,首先从海量文本中抽取三类实体,再使用三元组分类引擎进行实体间关系的预测,最终实现文本的多对多关系三元组抽取。
9.本发明无需事先定义实体间的关系类型,不受抽取领域的限制,可以实现三元组的自动抽取,降低了三元组抽取的标注成本提高抽取效率。不同于其他抽取技术,本发明侧重于从底层自然语言处理特征角度对文本进行分析,不仅可以有效实现三元组实体间的复杂多对多关系抽取,还可以增强模型的普适性。
10.与现有技术相比,本发明具有如下优点:1)普适性:本发明通过实例抽取层和关系层加入文本磁层的自然语言处理特征,这些特征可以从文本的句法结构、语义依存信息、词性特征和语义角色特征的角度等最基础的词性特征,对文本进行分析,较业内现有的三元组抽取方法,可以使得模型较为普遍地适用于各种领域的三元组抽取;2)多对多:本发明中的第三层关系分类层,可以对不同组合的三元组进行关系分类,相较于实体和关系联合抽取模型,可以有效解决实体的重叠问题。
附图说明
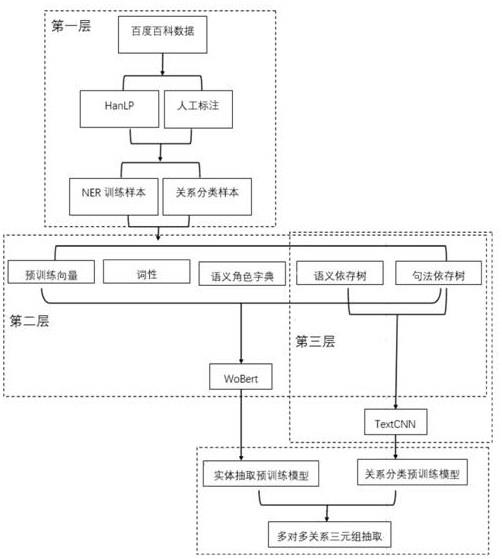
11.图1为本发明的架构图;图2为本发明的完整设计流程图。
具体实施方式
12.下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本技术所附权利要求书所限定的范围。
13.名词解释:句法依存:句法依存(dependency parsing,dp)通过分析语言单位内成分之间的依存关系揭示其句法结构。直观来讲,依存句法分析识别句子中的“主谓宾”、“定状补”这些语法成分,并分析各成分之间的关系。
14.语义依存:语义依存分析(semantic dependency parsing,sdp),分析句子各个语言单位之间的语义关联,并将语义关联以依存结构呈现。使用语义依存刻画句子语义,好处在于不需要去抽象词汇本身,而是通过词汇所承受的语义框架来描述该词汇,而论元的数目相对词汇来说数量总是少了很多的。语义依存分析目标是跨越句子表层句法结构的束
缚,直接获取深层的语义信息。
15.语义角色标注:语义角色标注(semantic role labeling,srl)是一种浅层的语义分析技术,标注句子中某些短语为给定谓词的论元(语义角色),如施事、受事、时间和地点等。
16.词性:是一种语言中词的语法分类,是以语法特征(包括句法功能和形态变化)为主要依据、兼顾词汇意义对词进行划分的结果。
17.三元组:在自然语言处理领域,三元组指spo三元组,分别是一个句子的主语(subject)、谓语(predicate)、宾语(object)。
18.开放关系抽取:关系抽取(ie)就是从非结构化文本中抽取出结构化的三元组信息,形成《论元1,关系,论元2》这种形式。传统的关系抽取需要人工标注一定数量特定领域的少量关系和对应实体作为训练集,切换到一个新的领域时就又得重新定义规则重新标注数据,非常的费时费力。banko et al.首次提出了oie(open information extraction)这个概念,不局限于一小部分提前已知的关系,而是抽取文本各种类别的关系,实现从海量数据中提取各种三元组知识的需求。
19.多对多关系:指从句子中抽取的部分三元组共享相同实体。
20.transh:transh 是zhen wang 等人在2014年提出的一种对于transe模型的改进方案,这个模型的具体思路是将三元组中的关系抽象成一个向量空间中的超平面(hyperplane),每次都是将头结点或者尾节点映射到这个超平面上,再通过超平面上的平移向量计算头尾节点的差值。
21.hanlp :hanlp是由一系列模型与算法组成的java工具包,目标是普及自然语言处理在生产环境中的应用。 hanlp主要功能包括分词、词性标注、关键词提取、自动摘要、依存句法分析、命名实体识别、短语提取、拼音转换、简繁转换等等。
22.基于上述名词解释,本发明提供的一种融合五维特征的高普适性多对多关系三元组抽取方法从来自百度百科的文本数据中使用hanlp语义角色功能,生成预标注spo多对多三元组语料,采用少量人工标注的方法完成三元组标注语料的构建。采用以词为单位的wobert模型将预训练词向量与模型融合,引入关系超平面机制将语义和句法依存特征与模型融合,再使用共享位置嵌入的方法将词性和语义角色特征与模型融合,训练融合五维特征具有高普适性的实体抽取模型。构建具有方向信息的语义依存向量字典按序输入textcnn中,训练三元组分类引擎。最后,将实体抽取模型和三元组分类引擎结合,实现文本的多对多关系抽取。
23.具体而言,本发明的实现技术主要分为三层:第一层为数据准备层,用于批量生成预标注数据并辅以人工核验的方法,最终生成第二层以及第三层模型训练所需样本。第二层为实体抽取层,在该层中,本发明搭建了一种融合五种维度特征的分词表示模型,以词级实体抽取模型wobert为底生成分词的预训练词向量,加上关系超平面表示方法来映射分词间的语义和句法依存关系,生成句法和语义依存词向量;采用拼接方法将词性和语义角色特征与分词预训练向量进行融合,生成词性和语义角色词向量;采用卷积池化和全连接层将五种维度特征拼接成固定维度的词向量表示,将该向量输入词级实体抽取模型wobert进行实体识别的训练。第三层为关系分类层,使用textcnn对包含语义和句法依存特征的实体对进行分类,判断是否构成三元组。以下分别对第一层、第二层和三层进行详细说明:
第一层:数据准备层从来自百度百科的文本数据中,使用底层自然语言处理工具hanlp在文本数据中进行语义角色标注。语义角色标注将以谓词为中心标注谓词相关的语义角色,取语义角色类型为施事者(causer or experiencers)作为头实体、受事者(patient)作为尾实体和该组语义角色的谓词作为关系。同组出现的语义角色将构成结构为《头实体,关系,尾实体》的三元组。上述步骤将生成spo三元组预标注语料,辅以少量人工复核,将生成spo三元组标注语料。将spo三元组标注语料拆分为两部分:实体识别语料和三元组分类语料,其中,实体识别语料用于第二层的实体识别模型的训练,三元组分类语料用于第三层的三元组分类引擎的训练。
24.第二层:实体抽取层在实体抽取层,本发明提供了一个可以融合五维特征的实体识别(named entity recognition,ner)模型。该实体识别模型的工作流程分为五个步骤:第一步:生成底层自然语言处理特征首先对文本进行分句,再使用底层自然语言处理工具hanlp对文本中的每句句子进行分词,生成分词的词性、语义角色、语义依存和句法依存四个维度特征;第二步:引入bert预训练词向量基于第一步中的分词结果,使用基于词颗粒度中文wobert的预训练模型,为每句句子生成维度为n的分词预训练向量,这样就得到了每句句子的预训练句子向量{y1,y2,
…
,yi,
…
,yn},yi为预训练句子向量中的第i个预训练词向量;第三步:引入依存关系该步骤中,本发明提出了依存翻译(dependency translation,dt)方法,将分词之间的依赖关系采用向量翻译的模式表示出来。在介绍如何翻译依赖关系之前,首先介绍依存关系的无环性和根节点唯一性公理。第一个公理指的是任何一个词语都不能依存于两个或两个以上的词语;第二个公理指的是一个句子中只有一个词语是独立的。由上述两个公理可以得到两个重要结论:a)一句句子中除了根节点外,其他分词都依赖有且仅有一个分词存在,因此对于一个分词的dt,仅需考虑其与另一个分词的依赖关系,不需考虑与其他分词的依赖关系。
25.b)同一分词虽然只依赖一个分词,但可能被多种分词依赖,这种依存关系是一种一对多关系,不能使用简单的翻译方法进行表示,为了解决这一问题,本发明引入关系超平面来解决这种一对多关系。
26.第三步具体包括以下步骤:步骤301、首先根据语义和句法依存关系的类别,生成相应类别的关系超平面和关系向量。在基于词颗粒度中文wobert的向量字典中随机初始化维度为k
sdp
×
n的语义依存超平面、维度为k
sep
×
n的句法依存超平面、维度为k
sdp
×
n的语义依存关系向量和维度为k
sep
×
n的句法依存关系向量,语义依存关系向量以及句法依存关系向量在各自类别中符合正态分布。其中,k
sdp
表示语义依存的种类数,k
sep
表示句法依存的种类数。
27.步骤302、找出每句句子中独立的分词,将该分词作为根节点,为每句句子分别建立语义依存树以及句法依存树,由语义依存树以及句法依存树的所有节点分别组成当前句子的包含有语义依存关系的句子向量{sdp1,sdp2,
…
,sdpi,
…
, sdpn}和包含有句法依存关
系的句子向量{sep1,sep2,
…
,sepi,
…
,sepn},其中,sdpi为当前句子向量中第i个包含有语义依存关系的词向量,sepi为当前句子向量中第i个包含有句法依存关系的词向量。
28.语义依存树以及句法依存树中,除根节点向量为第二步得到对应分词的预训练词向量外,其他节点的向量为依赖节点的预训练词向量在相应关系的语义依存超平面或句法依存关系中的投影和语义依存关系向量或句法依存向量的翻译。
29.例如:分词x2与分词x1存在施事关系。施事关系的语义依存超平面向量为w
agt
,施事关系的语义依存向量为r
agt
,方向为x1依赖x2。语义依存树中,分词x1对应的节点的依赖节点为分词x2对应的节点,则分词x1对应的节点的向量为翻译向量t1,则有t1=r
agt-y
⊥2,其中,y
⊥2为第二步得到分词x2所对应的预训练词向量y2在施事关系语义依存超平面中的投影,y
⊥2=y
2-w
agtty2 w
agt
,w
agtt
y2=|w
agt
||y
2 |cosθ表示预训练词向量y2在w
agt
方向上投影的长度,w
agt
表示施事关系超平面法向量,θ表示y2与施事关系超平面的夹角。
30.第四步:引入词性和语义角色在基于词颗粒度中文wobert中随机初始化维度为k
pos
×
n的向量以及维度为k
srl
×
n的向量,其中,k
pos
和k
srl
分别表示词性和语义角色的种类数量,根据每个句子中各个分词的词性和语义角色类型,为每个句子生成表示词性的句子向量{pos1,pos2,
…
,posi,
…
,posn}以及表示语义角色的句子向量{srl1,srl2,
…
,srli,
…
,srln},其中,posi为当前句子向量中第i个表示词性的词向量,srli为当前句子向量中第i个表示语义角色的词向量;第五步:使用lex-bert v2中的共享位置嵌入的方法,将第二步、第三步及第四步得到的五种维度的词向量进行拼接,获得五维特征词向量。
31.第六步:实体识别模型基于五维特征词向量进行实体识别,并利用实体识别语料对实体识别模型进行训练,直至模型收敛,并得到模型收敛时的所有类别的语义和句法依存关系的关系超平面以及关系向量。
32.第三层:关系分类层不同于一般的分类模型输入句子的预训练向量,关系分类层中的三元组分类引擎的输入是三元组间的语义和句法依存关系,输入顺序为头实体《-》关系、尾实体《-》关系、头实体《-》尾实体,其中,x《-》y表示x依赖y的语义和句法依存关系类型集合和y依赖x的语义和句法依存关系类型集合。使用训练第二层模型得到的所有类别的语义和句法依存关系的关系向量初始化依赖关系并嵌入字典,该字典随着三元组分类引擎所采用的textcnn分类网络利用三元组分类语料一起训练,依赖关系集合通过个textcnn分类网络对2*3*4的卷积层(考虑到部分三元组间依赖关系较少,降低了卷积核窗口大小)、最大池化层(提取特征)和全连接层抽取浅层特征并完成分类任务的训练。
33.最后,将训练完成的实体抽取模型和三元组分类引擎结合,首先从海量文本中抽取三类实体,再使用三元组分类引擎进行实体间关系的预测,最终实现文本的多对多关系三元组抽取。
34.本发明采用transh关系超平面机制,头实体将在不同依存关系空间中分别投影,尾实体的关系超平面嵌入则为头实体投影与依存关系嵌入的翻译,该设计解决依存关系中存在的多对一关系问题,将语义和句法上独立的分词间的依存特征融入分词的表示中,更为精确且极大地丰富了词向量的表示;本发明构建的这一套管道式三元组抽取方案,将庞大的词向量预训练模型和高性能底层自然语言处理特征有机结合,增加模型语义理解能
力,从而提升模型处理多场景任务的能力,为构建大规模知识图谱奠基。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1