一种基于本体知识库的自然语言领域数据集自动标注方法与流程
1.本发明涉及语义分析技术领域,具体来说是一种基于本体知识库的自然语言领域数据集自动标注方法。
背景技术:
2.本体是一种结构化表示真实世界知识的工具,是知识工程领域的热门话题。本体知识库保存了大量的本体信息,因此包含了丰富的可利用的信息。本体知识库不仅包含了本体自身的详细信息,还构建了本体之间的关系信息。利用这些本体信息和本体关系信息,能够描述真实世界的信息。
3.自然语言处理领域往往以数据集为前提,在数据集的基础上才能进行相关自然语言理解、自然语言生成的任务。然而在自然语言处理领域,研究人员们更注重任务本身,更多的是设计算法、模型完成自然语言处理的相关任务,忽略了数据集的重要性。自然语言处理相关的任务诸如命名实体识别、文本分类、知识库问答等,一般需要数据集标注命名实体信息、文本类别信息、问句及其答案信息等。一般的自然语言处理领域数据集制作流程是:1.收集语料;2.清洗数据;3.人工标注数据集。这种传统的方法收集的语料往往存在很多噪声,因此需要数据清洗工作。然后通过人工的方式对语料逐条地进行命名实体信息、文本类别信息、问句及其答案信息的识别与标注工作。这种方法费时、费力,对于制作大规模、批量化的任务性的数据集是严峻的。
4.考虑到本体知识库中包含丰富的真实世界的信息,如何通过利用本体知识库的有用信息,实现自动化、批量化地制作自然语言处理领域的数据集进行自动标注工作,已成为急需解决的技术问题。
技术实现要素:
5.本发明的目的是解决了自然语言领域数据集需人工标注的缺陷,提供一种基于本体知识库的自然语言领域数据集自动标注方法来解决上述问题。
6.为了实现上述目的,本发明的技术方案如下:
7.一种基于本体知识库的自然语言领域数据集自动标注方法,包括以下步骤:
8.11)本体知识库的准备和预处理:根据自然语言处理任务所属垂直领域类型,选择本体知识库作为构建自然语言处理数据集的基础;利用本体开发工具加载所述本体知识库;
9.12)本体知识库本体属性和本体关系的抽取:统计加载的本体知识库信息,作为自动标注数据集的基础先验知识;本体知识库信息包括本体信息、本体关系信息;
10.13)领域用户自然语言表述习惯的建模:收集本体知识库领域的文献、网站、规范书构建语料库,对语料库语料文本进行词性标注,作为语料的用户自然语言表述习惯,利用词性结构复杂度,通过二重筛选抽取得到本体知识库领域用户自然语言表述习惯语义;
11.14)构建自然语言模板库:根据用户自然语言表述习惯语义,以本体关系信息作为
先验知识,构建自然语言模板库;
12.15)结合本体知识库信息填充自然语言模板并根据任务类型自动标注数据:遍历本体知识库本体信息,利用本体信息作为先验知识填充自然语言模板库,根据自然语言处理任务不同实现自动标注,生成任务型数据集。
13.所述本体知识库本体属性和本体关系的抽取包括以下步骤:
14.21)统计加载的本体知识库本体信息、本体关系信息及本体知识库中的所有实例信息,其包括实例名、实例类别,将其作为本体知识库的本体信息;
15.22)统计加载的本体知识库的关系信息,包括本体关系类型、本体关系数量、满足本体关系的知识,将其作为所述本体知识库本体关系信息;
16.23)本体知识库的本体信息通过本体信息完整度筛选得到的有效本体集合,本体信息完整度定义为:给定本体e,其信息完整度e由公式(1)计算得到:
[0017][0018]
所述公式(1)中的fullname表示本体e的名称;
[0019]
24)本体知识库的本体关系信息通过关系表征系数筛选得到的有效本体关系集合,关系表征系数用来确定关系在所述本体知识库中的重要性;
[0020]
关系表征系数定义为:对于给定有向关系r,存在本体a、b满足关系r,即a-[r]-》b;那么所述给定有向关系的表征系数r通过公式(2)计算得到:
[0021][0022]
所述公式(2)中,count(r)表示所述给定有向关系r的统计数量,ri表示所述给定本体知识库的关系集合中的第i个有向关系,i={1,2,
…
,n},n表示所述关系集合大小,r[a&b]表示a、b中至少有一个本体在所述给定本体知识库中由公式(1)计算得到的信息完整度为0,即本体信息不完整。
[0023]
所述领域用户自然语言表述习惯的建模包括以下步骤:
[0024]
31)收集本体知识库领域的文献、网站、规范书,构建本体知识库领域的语料库,其用于分析、抽取本体知识库领域用户的自然语言表述习惯,作为先验知识;
[0025]
32)利用本体知识库本体信息构建完备特征词典:通过将本体知识库本体关系信息及其同义词、短语添加至特征词典,构建成本体知识库完备特征词典;
[0026]
33)利用本体知识库完备特征词典对语料库中的文本进行词性标注,词性标注结果即为文本的词性结构,以词性结构作为文本的用户自然语言表述习惯;
[0027]
34)对用户自然语言表述习惯进行筛选:
[0028]
利用tf-idf算法选择在语料库中文本文件的关键词性结构,tf-idf计算如公式(3)所示:
[0029]
[0030][0031]
tf-idf=tf*idf
[0032]
所述公式(3)中,expi表示任意词性结构,files表示语料库中的所有文本文件,file|express表示包含所述给定词性结构express的文本文件,tf表示给定词性结构express在所述语料库给定所述文本中出现频率;idf为所述语料库中的总文本数除以包含所述给定词性结构express的文本总数得到的商,再对商取对数得到,tf-idf值是tf与所述idf的乘积;
[0033]
35)对用户自然语言表述习惯进一步筛选,利用词性结构复杂度滤除结构简单、语义不明确的词性结构,获取所述本体知识库领域相关用户自然语言表述习惯语义;
[0034]
所述词性结构复杂度解释为:对于给定词性结构,统计其包含的词性总数n,词性种类数c,那么其词性结构复杂度p由公式(4)计算得到:
[0035]
p=c*log(1+n/c),n/c≥1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0036]
所述词性结构复杂度的特征表现为:
[0037]
351)当给定词性结构所包含词性总数n不变时,给定词性结构所包含的词性种类数越多,即c越大,词性结构越复杂;反之,词性结构越简单;
[0038]
352)当给定词性结构所包含词性种类数c不变时,给定词性结构所包含的词性总数越多,即n越大,词性结构越复杂;反之,词性结构越简单。
[0039]
所述构建自然语言模板库包括以下步骤:
[0040]
41)从本体知识库选定本体关系,并从完备特征词典中选择与选定本体关系同义的词或短语,添加了限定词,作为模板先验知识;
[0041]
42)从用户自然语言表述习惯语义中选定词性结构作为模板的词性结构;
[0042]
43)用模板先验知识按照模板的词性结构构造模板,模板的待填充项为本体知识库本体实例信息,即要求模板语义为选定的本体关系信息;
[0043]
44)重复41)步骤-43步),直至本体知识库所有本体关系均有对应模板,则自然语言模板库构建完成。
[0044]
所述结合本体知识库信息填充自然语言模板并根据任务类型自动标注数据包括以下步骤:
[0045]
51)选定本体实例、本体实例关系,作为先验知识;
[0046]
52)根据本体实例关系,从自然语言模板库中选择对应本体实例关系的模板;
[0047]
53)用本体实例填充所述模板,生成数据集语料;
[0048]
54)根据自然语言处理任务类型,结合先验知识,自动标注所述语料;
[0049]
55)重复上述51)-55)步骤,直至所述本体知识库遍历所有本体信息和对应本体关系信息,则任务型数据集构建完成。
[0050]
有益效果
[0051]
本发明的一种基于本体知识库的自然语言领域数据集自动标注方法,与现有技术相比利用本体知识库中的本体信息、本体关系信息,融合本体知识库领域相关用户自然语言表述习惯语义,自动标注数据集,解决了没有充分利用本体知识库,人工进行数据标注方法的费时、费力问题。
[0052]
本发明通过整合本体知识库中的本体信息、本体关系信息,将这些已知的信息作为先验知识,填充至模板中构造语料,可以通过自动标注的方法对语料进行标注,构建自然语言处理任务相关的数据集。此外,通过分析本体知识库相关领域用户的自然语言表述习惯,提取本体知识库相关领域用户的自然语言表述习惯语义,利用领域相关用户自然语言表述习惯语义辅助生成模板。通过这种方式生成的模板融合了本体知识库相关领域用户的自然语言表述习惯,更切合实际表达方式。本发明通过构造模板的方式,利用本体知识库的先验知识,实现自动标注的数据集构建方法。
附图说明
[0053]
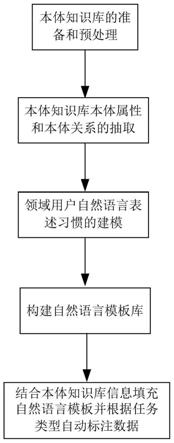
图1为本发明的方法顺序图;
[0054]
图2为本发明实施例提供的方法中融合了本体知识库领域相关用户自然语言表述习惯的自然语言模板库的构建示意图;
[0055]
图3为本发明实施例提供的方法中的用户自然语言表述习惯示意图;
[0056]
图4为本发明实施例提供的方法中的融合了本体知识库领域相关用户自然语言表述习惯的自然语言模板示意图;
[0057]
图5为本发明实施例中自然语言领域数据集自动标注方法示意图。
具体实施方式
[0058]
为使对本发明的结构特征及所达成的功效有更进一步的了解与认识,用以较佳的实施例及附图配合详细的说明,说明如下:
[0059]
如图1所示,本发明所述的一种基于本体知识库的自然语言领域数据集自动标注方法,包括以下步骤:
[0060]
第一步,本体知识库的准备和预处理:根据自然语言处理任务所属垂直领域类型,选择本体知识库作为构建自然语言处理数据集的基础,本体知识库通常使用rdf资源描述框架;利用本体开发工具加载所述本体知识库。
[0061]
第二步,本体知识库本体属性和本体关系的抽取:统计加载的本体知识库信息,作为自动标注数据集的基础先验知识;本体知识库信息包括本体信息、本体关系信息。其具体步骤如下:
[0062]
(1)统计加载的本体知识库本体信息、本体关系信息及本体知识库中的所有实例信息,其包括实例名、实例类别,将其作为本体知识库的本体信息。
[0063]
(2)统计加载的本体知识库的关系信息,包括本体关系类型、本体关系数量、满足本体关系的知识,将其作为所述本体知识库本体关系信息。
[0064]
(3)本体知识库的本体信息通过本体信息完整度筛选得到的有效本体集合,本体信息完整度定义为:给定本体e,其信息完整度e由公式(1)计算得到:
[0065][0066]
所述公式(1)中的fullname表示本体e的名称。
[0067]
(4)本体知识库的本体关系信息通过关系表征系数筛选得到的有效本体关系集合,关系表征系数用来确定关系在所述本体知识库中的重要性;
[0068]
关系表征系数定义为:对于给定有向关系r,存在本体a、b满足关系r,即a-[r]-》b;那么所述给定有向关系的表征系数r通过公式(2)计算得到:
[0069][0070]
所述公式(2)中,count(r)表示所述给定有向关系r的统计数量,ri表示所述给定本体知识库的关系集合中的第i个有向关系,i={1,2,
…
,n},n表示所述关系集合大小,r[a&b]表示a、b中至少有一个本体在所述给定本体知识库中由公式(1)计算得到的信息完整度为0,即本体信息不完整。
[0071]
第三步,领域用户自然语言表述习惯的建模:收集本体知识库领域的文献、网站、规范书构建语料库,对语料库语料文本进行词性标注,作为语料的用户自然语言表述习惯,利用词性结构复杂度,通过二重筛选抽取得到本体知识库领域用户自然语言表述习惯语义。
[0072]
用户自然语言表述习惯是指用户进行自然语言表述过程中的习惯使用的语法、句法结构,以及用户习惯使用的连词、介词、感情词等。现实场景(文献、网站、规范书等)中存在大量领域用户自然语言表述,但是,其中存在大量的噪音(非习惯性表述内容)。因此,建模领域用户自然语言表述习惯有益于还原现实场景中用户的自然语言表述内容,增强方法的适应性。
[0073]
领域用户自然语言表述习惯的建模的具体步骤如下:
[0074]
(1)收集本体知识库领域的文献、网站、规范书,构建本体知识库领域的语料库,其用于分析、抽取本体知识库领域用户的自然语言表述习惯,作为先验知识。
[0075]
(2)利用本体知识库本体信息构建完备特征词典:通过将本体知识库本体关系信息及其同义词、短语添加至特征词典,构建成本体知识库完备特征词典。
[0076]
(3)利用本体知识库完备特征词典对语料库中的文本进行词性标注,词性标注结果即为文本的词性结构,以词性结构作为文本的用户自然语言表述习惯。
[0077]
(4)对用户自然语言表述习惯进行筛选。
[0078]
利用tf-idf算法选择在语料库中文本文件的关键词性结构,即选择能够表征文本特性的自然语言表述习惯。tf-idf计算如公式(3)所示:
[0079][0080][0081]
tf-idf=tf*idf
[0082]
所述公式(3)中,expi表示任意词性结构,files表示语料库中的所有文本文件,file|express表示包含所述给定词性结构express的文本文件,tf表示给定词性结构express在所述语料库给定所述文本中出现频率;idf为所述语料库中的总文本数除以包含所述给定词性结构express的文本总数得到的商,再对商取对数得到,tf-idf值是tf与所述idf的乘积。
[0083]
(5)对用户自然语言表述习惯进一步筛选,利用词性结构复杂度滤除结构简单、语
义不明确的词性结构,获取所述本体知识库领域相关用户自然语言表述习惯语义;
[0084]
所述词性结构复杂度解释为:对于给定词性结构,统计其包含的词性总数n,词性种类数c,那么其词性结构复杂度p由公式(4)计算得到:
[0085]
p=c*log(1+n/c),n/c≥1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0086]
所述词性结构复杂度的特征表现为:
[0087]
a1)当给定词性结构所包含词性总数n不变时,给定词性结构所包含的词性种类数越多,即c越大,词性结构越复杂;反之,词性结构越简单;
[0088]
a2)当给定词性结构所包含词性种类数c不变时,给定词性结构所包含的词性总数越多,即n越大,词性结构越复杂;反之,词性结构越简单。
[0089]
第四步,构建自然语言模板库:如图2所示,根据用户自然语言表述习惯语义,以本体关系信息作为先验知识,构建自然语言模板库。所述构建自然语言模板库包括以下步骤:
[0090]
(1)从本体知识库选定本体关系,并从完备特征词典中选择与选定本体关系同义的词或短语,添加了限定词,作为模板先验知识。
[0091]
(2)从用户自然语言表述习惯语义中选定词性结构作为模板的词性结构。
[0092]
(3)用模板先验知识按照模板的词性结构构造模板,模板的待填充项为本体知识库本体实例信息,即要求模板语义为选定的本体关系信息。
[0093]
(4)重复(1)-(3)步,直至本体知识库所有本体关系均有对应模板,则自然语言模板库构建完成。
[0094]
第五步,结合本体知识库信息填充自然语言模板并根据任务类型自动标注数据:遍历本体知识库本体信息,利用本体信息作为先验知识填充自然语言模板库,根据自然语言处理任务不同实现自动标注,生成任务型数据集。其具体步骤如下:
[0095]
(1)选定本体实例、本体实例关系,作为先验知识。
[0096]
(2)根据本体实例关系,从自然语言模板库中选择对应本体实例关系的模板。
[0097]
(3)用本体实例填充所述模板,生成数据集语料。
[0098]
(4)根据自然语言处理任务类型,结合先验知识,自动标注所述语料。
[0099]
(5)重复上述(1)-(5)步骤,直至所述本体知识库遍历所有本体信息和对应本体关系信息,则任务型数据集构建完成。
[0100]
在此,下面提供上述方法的一个具体实施例。
[0101]
根据上述第一步,本体知识库的准备和预处理。本实施例选取农业领域覆盖面广、信息丰富的本体知识库agrirdf。agrirdf包含了一系列农产品信息,如中药材、农资产品、水产业、畜牧业、种植业;包含了一系列农作物病虫害,如农作物害虫、农作物病害、病害虫属性;包含了一系列行政区划,如省级、市级、县级。利用本体开发工具prot
égé
加载所述本体知识库。
[0102]
根据上述第二步,本体知识库本体属性和本体关系抽取。统计本体知识库agrirdf信息,包括本体知识库本体信息,本体知识库本体关系信息;其中,本体知识库agrirdf本体信息是通过本体信息完整度筛选得到的有效本体集合,根据公式(1)统计得到所述给定本体知识库agrirdf中的8034个本体中筛选得到的有效本体共三类:农产品、病虫害、行政区划,有效本体集合大小为7282。
[0103]
本体知识库agrirdf本体关系信息是有效本体关系集合,对于公式(2),在所述本
体知识库agrirdf中,共有关系类型数量为21,关系总数5903,设置所述表征系数阈值为0.5%,对于所述本体知识库agrirdf中关系“产地”,count(r)为1297,count(r[a&b])为0,则所述关系“产地”对应的表征系数r=(1297-0)/5903=21.97%,大于所述给定表征阈值,即所述关系“产地”在所述给定本体知识库agrirdf中能够有效表征所述本体知识库。
[0104]
利用上述方法统计得到所述给定本体知识库agrirdf中的5903条本体关系中筛选得到有效本体关系共4种:产地、包含、属于、原料是/用来制作,有效本体关系集合大小为5806。
[0105]
根据上述第三步,建模本体知识库agrirdf领域相关用户自然语言表述习惯。其中,对应的具体步骤如下:
[0106]
(1)对于本体知识库agrirdf,所属垂直领域为农业,本实施例从相关农业网站安徽农网收集科普文章7篇、从安徽农网、惠农网、中国农业科技信息网收集农知问答模块(归并为3个文本文件),共10个农业领域相关的文本文件作为语料库;
[0107]
(2)在本体知识库agrirdf中,由所有本体信息如葡萄、草莓、西瓜、西瓜叶枯病等构建特征词典;然后对所有关系信息设定同义词或短语,如关系“产地”,设定同义词或短语“适合种植”、“来源于”等,将所述同义词或短语添加至特征词典,构建所述给定本体知识库agrirdf的完备特征词典;
[0108]
(3)如图3所示为用户自然语言表述习惯示意图。其中,给定用户自然语言表述句子为“哪里适合种植葡萄?”,词性标注结果为:{(哪里,r),(适合,v),(种植,v),(葡萄,n),(?,x)}。其中r表示代词,v表示动词,n表示名词,x表示字符串。则所述给定用户自然语言表述句子的词性结构表述为“r/v/v/n/x”。
[0109]
(4)根据公式(3)计算tf-idf值对用户自然语言表述习惯进行第一重筛选。在本体知识库agrirdf中,所述语料库中的文本文件数量count(files)为10,设置topk为50,对于给定词性结构express:“r/v/v/n/x”,在给定所述语料库的一个文本中出现的次数count(express)为25,所述给定文本的词性结构总数为341,所述语料库中包含所述给定词性结构express的文件数count(file|express)为10,则所述tf=25/341=0.073,所述idf=log(10/10+1)=0.3,则所述tf-idf=tf*idf=0.022。
[0110]
(5)根据公式(4)计算词性结构复杂度对用户自然语言表述习惯进行第二重筛选。对于公式(4),设定所述复杂度阈值为1,以图3所示为例,语料中的词性总数n=5,词性种类数c=4,其中对数取常用对数。那么其词性结构复杂度计算为p=4*log(1+5/4)≈1.41。
[0111]
根据上述第四步,构建自然语言模板库。参见图4,在本体知识库agrirdf中,给定本体关系类型“产地”,从所述完备特征词典中选择与“产地”相关的同义词或短语“适合种植”,“适合养殖”,作为先验知识;接着从用户自然语言表述习惯语义中选定词性结构“r/v/v/n/x”作为模板词性结构;然后利用所述先验知识按照所述模板词性结构构造模板“哪里适合种植*?”,其中“*”为带填充项;将所述构造的模板添加至模板库。
[0112]
根据上述第五步,结合本体知识库信息填充自然语言模板并根据任务类型自动标注数据。如图5所示,在所述给定本体知识库agrirdf中,给定本体“草莓”,以及其对应的本体关系“产地”,选择自然语言模板库中按照上述方法由“产地”关系构造的自然语言模板,根据不同的任务对模板进行填充和标注。其中标注过程是根据所述本体知识库先验知识自动完成的。
[0113]
下面详细说明图5中的命名实体识别数据集自动标注过程:
[0114]
首先,将给定本体“草莓”和给定本体关系“产地”作为给定先验知识,对于自然语言模板“哪里适合种植*?”,用所述先验知识“草莓”填充所述模板中的“*”部分。已知所述先验知识“草莓”是命名实体,模板中的其他部分是非命名实体,那么利用bio标注法即可进行标注。同理,对于其他给定本体作为所述先验知识,可以快速、便捷的填充、标注数据,实现批量化、高效的自动标注数据,制作数据集。
[0115]
下面详细说明图5中的句子分类数据集自动标注过程:
[0116]
首先,将给定本体“草莓”和给定本体关系“产地”作为给定先验知识,对于自然语言模板“哪里适合种植*”,用所述先验知识“草莓”填充所述模板中的“*”部分。已知所述自然语言模板属于所述给定本体关系,即所述自然语言模板所表达内容与所述给定本体关系“产地”有关,即可根据所述先验知识自动判定模板填充后的语料所属类别,进行标记即可。在本发明实施例中将所属语料标记为类别“1”。同理,对于其他给定本体作为先验知识,填充所述给定本体关系的模板,可以自动标注填充后语料所属的句子类别。
[0117]
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是本发明的原理,在不脱离本发明精神和范围的前提下本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明的范围内。本发明要求的保护范围由所附的权利要求书及其等同物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1