一种用于医疗票据OCR的医保目录匹配方法与流程
一种用于医疗票据ocr的医保目录匹配方法
技术领域
1.本发明属于医疗票据ocr技术领域,尤其涉及一种用于医疗票据ocr的医保目录匹配方法。
背景技术:
2.医疗保险已经深入人心,是保障大众生活质量的重要组成部分,很多人不但参保社会医疗保险,还参保了商业补充医疗保险。随着社会的发展,人口流动性非常大,目前医疗保险应用场景非常复杂,还未完全做到各地各部门之间数据互通。在很多场景中,医疗保险的报销或者理赔都需要提供纸质的费用凭证。采用医疗票据ocr识别技术可以快速地把这些纸质的费用凭证数据电子化。但是由于各种历史原因,各地各部门提供的医疗费用明细与当地的医保目录库可能存在一定的差异;另外ocr识别技术提供的识别结果可能存在误识别、英文或者符号半角全角不统一等情况。所以这些电子化后的费用凭证数据能正常入库的关键是需要一套有效的方法保证这些费用数据能够与医保目录库正确匹配。
技术实现要素:
3.为解决上述问题,本发明提出一种用于医疗票据ocr的医保目录匹配方法,将名称上有差异的同类医疗费用目录关联起来,为进一步提升医保业务系统有效性和易用性提供基础。
4.为实现上述目的,本发明提供了一种用于医疗票据ocr的医保目录匹配方法,所述方法包括,
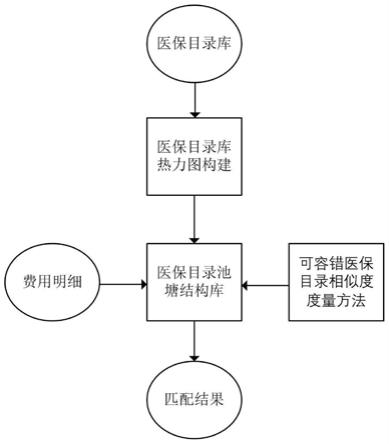
5.基于医保目录库中的医保目录构建医保目录库热力图;
6.设置医保目录相似度度量方法,所述医保目录相似度度量方法包括双目录相似度度量方法与费用-目录相似度度量方法;
7.基于所述医保目录库热力图与所述双目录相似度度量方法构建医保目录池塘结构库;
8.基于所述费用-目录相似度度量方法与所述医保目录池塘结构库对医疗票据ocr的费用明细进行搜索,完成所述医保目录匹配。
9.可选地,构建所述医保目录库热力图的方法为:
10.获取所述医保目录的关键字字频表;
11.基于所述关键字字频表对医保目录的每个条目中的字符进行关键字匹配,获取所述医保目录的热力数据;
12.基于所述热力数据中的元素建立所述医保目录库热力图。
13.可选地,获取所述关键字字频表的方法为:
14.对所述医保目录进行去非中文字符处理,获得纯中文字符的医保目录,对所述纯中文字符的医保目录的条目进行中文分词,获得分词集合,对所述分词集合去重,采用人工的方式纠正错误分词,并对所述纠正后的分词再次去重,得到医保目录关键字集合,统计所
述医保目录中每个中文字符的出现频率,获得字符频率表,基于所述字符频率表获取所述医保目录关键字集合中的每条关键字中每个字符的频率,计算所述关键字的全部字符频率均值,将所述频率均值作为所述关键字的字频,在所述关键字集合中加入对应的所述字频,获得关键字字频表。
15.可选地,获取所述医保目录的热力数据的方法为:
16.建立空链表,基于所述关键字字频表对所述医保目录的每个条目中的字符进行关键字匹配,基于匹配结果,将所述关键字的起止位置插入所述空链表中,插入所述关键字的起止位置后的所述空链表即所述医保目录的热力数据。
17.可选地,构建所述医保目录池塘结构库的方法为:
18.建立与所述医保目录库热力图相同长度的标志位数据,基于所述双目录相似度度量方法,获取所述标志位数据的双目录相似度,基于所述标志位数据的值与所述标志位数据的双目录相似度获取相似度阈值参数;
19.基于所述双目录相似度度量方法获取所述医保目录库热力图的双目录相似度,基于所述医保目录库热力图的双目录相似度与所述相似度阈值参数建立所述医保目录池塘结构库。
20.可选地,所述医保目录匹配的方法为:
21.预设相似度阈值,基于所述费用-目录相似度度量方法与所述医保目录池塘结构库对医疗票据ocr的费用明细进行搜索,获取所述医疗票据ocr的费用明细的费用-目录相似度,基于所述预设相似度阈值与所述费用-目录相似度完成所述医保目录池塘结构库的搜索,对搜索结果进行汇总,完成医保目录匹配。
22.可选地,所述双目录相似度度量方法的表达式为:
[0023][0024]
其中,q为匹配数,hs与hd分别为两条医保目录对应的关键字位置链表,ω(
·
)表示医保目录对应的关键字链表长度。
[0025]
可选地,所述费用-目录相似度度量方法为:
[0026]
基于所述医疗票据ocr的费用明细与所述医保目录库中的医保目录进行字符相似度匹配,完成所述费用-目录相似度度量。
[0027]
与现有技术相比,本发明具有如下优点和技术效果:
[0028]
本发明提供的一种用于医疗票据ocr的医保目录匹配方法,首先,根据医疗票据ocr中识别的费用明细可能存在的误识别的情况,设计了一种医保目录库热力图建立方法,呈现医保目录库的关键信息的分布情况。其次,提出了可容错的医保目录相似度度量方法,以保证医疗票据中部分内容误识别的费用明细也可以正确匹配医保目录。最后,根据医保目录相似度度量方法创建医保目录库池塘结构,以加快医保目录库的匹配速度。本发明能够应用于医疗保险相关系统中,提高系统的易用性和有效性。
附图说明
[0029]
构成本技术的一部分的附图用来提供对本技术的进一步理解,本技术的示意性实
施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:
[0030]
图1为本发明实施例的一种用于医疗票据ocr的医保目录匹配方法流程示意图。
具体实施方式
[0031]
需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本技术。
[0032]
需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
[0033]
实施例一
[0034]
如图1所示,本实施例中提供一种用于医疗票据ocr的医保目录匹配方法,包括:
[0035]
基于医保目录库中的医保目录构建医保目录库热力图;
[0036]
构建医保目录库热力图的方法为:获取医保目录的关键字字频表;基于关键字字频表对医保目录的每个条目中的字符进行关键字匹配,获取医保目录的热力数据;基于热力数据中的元素建立医保目录库热力图。
[0037]
进一步地,获取关键字字频表的方法为:对医保目录进行去非中文字符处理,获得纯中文字符的医保目录,对纯中文字符的医保目录的条目进行中文分词,获得分词集合,对分词集合去重,采用人工的方式纠正错误分词,并对纠正后的分词再次去重,得到医保目录关键字集合,统计医保目录中每个中文字符的出现频率,获得字符频率表,基于字符频率表获取医保目录关键字集合中的每条关键字中每个字符的频率,计算关键字的全部字符频率均值,将频率均值作为关键字的字频,在关键字集合中加入对应的字频,获得关键字字频表。
[0038]
进一步地,获取医保目录的热力数据的方法为:建立空链表,基于关键字字频表对医保目录的每个条目中的字符进行关键字匹配,基于匹配结果,将关键字的起止位置插入空链表中,插入关键字的起止位置后的空链表即医保目录的热力数据。
[0039]
在本实施例中,获取医保目录的热力数据的方法具体为:对于医保目录的每个条目m,建立一个与条目m等长的热力数据f,并把f的所有元素初始化0,创建一个表示关键字字符位置的空链表h。从第一个字符开始与关键字字频表的关键字进行匹配,先判断该字符是否是中文字符,如果不是,则从下一个开始;否则取出关键字字频表中一个关键字,计算关键字长度s,判断字符串m[0,s-1]中是否存在非中文字符,如果存在,则取出关键字字频表中的下一个关键字,重新开始;否则比较字符串m[0,s-1]和关键字字符串是否相等。如果相等,则把该关键字字频数据赋予f[0,s-1],并把关键字的起止位置0和s-1插入到链表h中,从条目m的第s个字符开始与关键字字频表的关键字进行匹配;否则,从条目m的第二个字符开始与关键字字频表的关键字进行匹配。以此类推直至条目m的所有字符处理完成。
[0040]
在本实施例中,基于热力数据中的元素建立医保目录库热力图的方法为:扫描f的所有元素求得最大的元素值mf,逐个处理f的每个元素f(i),令f(i)=mf-f(i)+1。对于医保目录的每个条目m,先统计其对应的热力数据f所有元素的总和,f的每个元素值再除以总和,实现对f的归一化。经上述处理后,建立起医保目录库的热力图。
[0041]
设置医保目录相似度度量方法,所述医保目录相似度度量方法包括双目录相似度
度量方法与费用-目录相似度度量方法;
[0042]
在本实施例中,医保目录相似度度量方法有两种,一种是双目录相似度度量方法;另一种为费用-目录相似度度量方法。令s和d分别为两条医保目录,hs和hd分别表示它们对应的关键字位置链表,并令匹配数q=0。先根据hs的第一项hs(0)的内容得到s中的关键字子字符串,逐个与根据ld内容得到的d中的关键字子字符串进行比较。如果存在关键字子字符串匹配,则令q=q+1,并结束该轮比较。取出hs的下一项继续比较直至与取完所有项。根据如下公式计算双目录相似度:
[0043][0044]
式中ω(
·
)表示医保目录对应的关键字链表长度。
[0045]
令s为医疗票据中识别得到的费用明细,m为医保目录以及其对的热力数据f,令相似度ρ=0,k=1。先取出s中的第一个字符与d中的第j=k字符开始逐个向后比较,如果出现第一个s(1)=m(j)时,则令ρ=ρ+f(j),令k=j+1,并结束该次比较;否则继续比较直至与所有m中的字符比较完成,令k=k+1。采用相同的方法,取出s中的第二个字符与m中的第j=k字符开始逐个向后比较,直至s中所有的字符都比较完成。最终的相似度ρ即为费用-目录相似度。
[0046]
基于所述医保目录库热力图与所述双目录相似度度量方法构建医保目录池塘结构库;
[0047]
进一步地,构建所述医保目录池塘结构库的方法为:建立与所述医保目录库热力图相同长度的标志位数据,基于所述双目录相似度度量方法,获取所述标志位数据的双目录相似度,基于所述标志位数据的值与所述标志位数据的双目录相似度获取相似度阈值参数;基于所述双目录相似度度量方法获取所述医保目录库热力图的双目录相似度,基于所述医保目录库热力图的双目录相似度与所述相似度阈值参数建立所述医保目录池塘结构库。
[0048]
在本实施例中,构建所述医保目录池塘结构库的方法具体为:
[0049]
令l表示医保目录库,在医保目录库l中搜索最优的相似度阈值t参数。建立一个与l长度相等的标志位数据g,t在区间[0.3,0.8]中以0.1的步长进行搜索。把g的所有元素初始化为-1。从l的第一个条目l(s)开始,如果标志位g(s)的值为-1,则与它之后的条目l(j)逐条计算双目录相似度,如果标志位g(j)的值为-1且双目录相似度大于t,则把条目l(j)对应的标志位g(j)的值置为s。直至条目l(s)与医保目录库中所有的条目l(j)都比较完成,则把l(s)对应的标志位g(s)的值也置为s。按相同的方法从下一个条目开始对医保目录库l进行处理,直至l所有条目标志位g都不为-1。统计g中相同值的元素个数,并计算元素个数大于3的所有元素个数的方差,取方差最小的阈值t作为最优的阈值参数t
*
。
[0050]
先创建一个空的医保目录池塘结构库p。从l的最后一个条目l(e)开始,与它之前的条目l(j)逐条计算双目录相似度,如果相似度大于t
*
,则把条目l(j)移动到临时库t中,并把条目l(j)对应的热力数据f也插入临时库t中。直至条目l(e)与医保目录库中所有的条目l(j)都比较完成,则把l(e)也移动到临时库t中,并把其对应的热力数据f也插入临时库t中。把临时库t作为一个新池塘,把l(e)作为该池塘索引条目,并把它们插入到池塘结构库p
中。按相同的方法对医保目录库l进行处理,直至l为空,就建立起一个医保目录池塘结构库p。
[0051]
基于费用-目录相似度度量方法与医保目录池塘结构库对医疗票据ocr的费用明细进行搜索,完成医保目录匹配。
[0052]
进一步地,医保目录匹配的方法为:预设相似度阈值,相似度阈值为0.3,基于费用-目录相似度度量方法与医保目录池塘结构库对医疗票据ocr的费用明细进行搜索,获取医疗票据ocr的费用明细的费用-目录相似度,基于预设相似度阈值与所述费用-目录相似度完成医保目录池塘结构库的搜索,对搜索结果进行汇总,完成医保目录匹配。
[0053]
在本实施例中,医保目录匹配的具体方法为:对于医疗票据中识别得到的费用明细s,采用并行的方式在医保目录池塘结构库的搜索,以快速得到匹配的结果。根据分配的处理器的资源数量k按顺序把医保目录池塘结构库p划分成k等份,每份对应一个线程进行独立处理。当查询一条费用明细s时,每个线程与对应份内的每条索引条目计算费用-目录相似度,当相似度大于0.3时,则根据索引条目找到对应的池塘,然后与池塘中条目逐条计算费用-目录相似度,当相似度大于0.3时,则记录该匹配的条目以及相似度。当所有的线程计算完成时,汇总每个线程所匹配的条目和相似度,根据相似度对条目进行从大到小排序,取前10个结果作为输出,即为医保目录匹配结果。
[0054]
以上所述,仅为本技术较佳的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应该以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1