基于目标特征时空对齐的视频跟踪系统及方法
1.本发明涉及的是一种视频跟踪领域的技术,具体是一种基于目标特征时空对齐的视频跟踪系统及方法。
背景技术:
2.视频跟踪,即对视频中多个感兴趣的目标进行定位,同时对所有目标根据其特征进行编号,记录连续的运动轨迹。
3.现有的视频跟踪方法包括基于tracking-by-detection框架的算法,例如deepsort算法,对每一帧进行目标检测,将前后帧检测到的目标进行关联,得到一系列轨迹。这种方法仅是把普通的关联和分配算法和目标检测器结合到一起,跟踪效果依赖于目标检测性能的好坏,当目标位于密集场景时和目标或镜头迅速移动情况下,这种依赖位置关联的算法在跟踪时容易丢失目标,造成精度下降。
4.现有基于检测和跟踪联合的算法,例如fairmot算法,该类算法将目标检测和关联联合训练,增加匹配和关联之间的特征耦合关系,对两者同时进行提升。该类算法在目标位置处对特征信息进行采样,但是此特征提取方法仅仅作用于物体的物理位置中心却忽视了前后帧的联系以及物体的物理形状、遮挡程度等时空信息,造成该处的特征包含了其他不相干目标的信息,使得提取出的特征不具有代表性。
5.此外,在基于深度学习的视频跟踪的方法中,通常采用交叉熵损失对目标重识别任务进行监督学习,每个目标是被单独考虑的,同一轨迹的目标检测框分到同一类。而在运用在跟踪上时,需要将目标和上一帧所有目标进行相似度计算,并根据结果进行匹配。该类型的方法由于没有考虑到不同目标之间的差异性而造成前后帧目标失配或错配。
技术实现要素:
6.本发明针对现有技术存在的上述不足,提出一种基于目标特征时空对齐的视频跟踪系统及方法,充分利用目标间的位置关系和前后帧目标的运动特征,并增强不同目标之间的区分度,筛选出最有代表性的目标特征,在视频跟踪时能更为准确地预测和区分目标,可以更加精准地匹配前后帧目标,增强物体类别预测的稳定性。
7.本发明是通过以下技术方案实现的:
8.本发明涉及一种基于目标特征时空对齐的视频跟踪系统,包括:全局特征提取模块、目标位置预测模块、目标特征提取模块和目标跟踪模块,其中:全局特征提取模块将当前帧与参考帧同时输入特征提取网络,得到当前帧以及参考帧的特征图并进行邻帧相似度计算;目标位置预测模块根据特征图预测出各个像素点上存在目标的概率,得到当前帧的热力图(heatmap),再使用参考帧的heatmap对其进行时序信息增强,得到目标的物理中心位置;目标特征提取模块根据特征图预测各个像素点上的特征,即全局的特征,再对目标物理中心位置进行采样位置偏移得到目标特征中心位置,在全局特征上对目标特征中心位置进行采样,得到目标特征;目标跟踪模块根据目标位置和目标特征将各个目标与历史轨迹
匹配,使用当前帧的目标信息更新轨迹状态。
9.所述的参考帧是指用于与当前帧进行比较,通过两者的差异推断出各个目标的运动信息的帧。在本系统中参考帧取邻近的上一帧,第一帧的参考帧取其本身。
10.所述的邻帧相似度是指:将当前帧特征图的各个像素点与参考帧特征图对应位置及其邻域的点进行相似度计算,得到的相似度包含空间相关信息,在时序上则表现为由目标移动造成的差异,提供目标的运动信息使后续步骤中的像素点偏移预测得更为准确。
11.所述的heatmap,表示各个像素点上存在目标的概率的矩阵,将矩阵上目标概率的极大值点所处位置作为目标的物理中心位置。
12.所述的时序信息增强是指:采用参考帧的位置信息弥补因目标运动或遮挡造成当前帧的位置信息缺失,具体为:将邻帧相似度输入目标位置预测模块的可变形卷积预测卷积时像素点的偏移,再将参考帧的heatmap通过该可变形卷积得到邻帧残差,再用邻帧残差对当前帧的heatmap进行修正,即将两者直接叠加得到调整后的heatmap,使得到的heatmap既反映当前帧的目标位置,又融合了历史轨迹的信息。
13.所述的采样位置偏移是指:在特征图上添加新的预测分支预测各个像素点从物理中心位置到特征中心位置的偏移使用该偏移在修正过后的位置进行采样。
14.所述的采样,通过特征互信息方法得到目标特征,具体为:通过计算采样位置与周围像素点的特征互信息,特征互信息越多,则组成特征的权重越高,以此来选取公有的特征,滤除不相干的目标特征。
15.所述的特征提取网络的训练过程中,将不同目标特征的正交性加入标准进行监督学习,即对于不同的目标i,j,其对应特征向量fi、fj,σ(f
ifjt
)趋近于0,对于两个相同的目标i,σ(f
ifit
)趋近于1,其中:σ()表示激活函数,在本系统中采用sigmoid激活函数。技术效果
16.与现有常规技术手段相比,本发明通过在特征图上添加特征采样位置偏移分支,预测特征图上各个像素的在x,y轴上的偏移弥补目标物理位置中心与特征位置中心不一致的问题。通过在各个目标的中心位置施加预测的偏移,采样插值得到更具有代表性的目标特征fi;同时通过使用上一帧的位置信息增强更新当前帧的位置信息。是指:通过计算前后两帧的邻帧相似度,得到视频中目标的运动信息,输入可变形卷积中预测偏移,再将参考帧的heatmap送入到可变形卷积中,得到邻帧残差,将当前帧初始的heatmap做信息融合,更新为当前帧的heatmap,使用上一帧的信息增强更新当前帧的信息。同时本发明提出了一种新的损失函数,使得不同目标的特征具有正交性,在跟踪时对于判别不同目标具有更好的区分度。
附图说明
17.图1为本发明原理图;
18.图2为本发明系统示意图;
19.图3为本发明各网络分支结构示意图。
具体实施方式
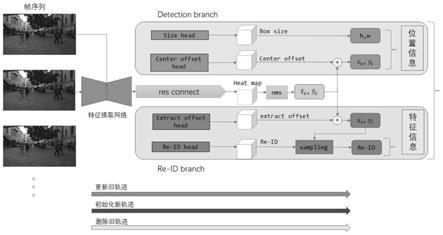
20.如图1和图2所示,为本实施例涉及的一种基于目标特征时空对齐的视频跟踪系统,包括:全局特征提取模块、目标位置预测模块、目标特征提取模块和目标跟踪模块。
21.如图3所示,所述的全局特征提取模块包括:特征提取网络和邻帧相似度计算单元,其中:特征提取网络根据待测视频的原始帧与参考帧,生成对应的原始帧以及参考帧的特征图,下采样后其大小为(c,h,w)。邻帧相似度计算单元计算得到的两个特征图之间的邻帧相似度。
22.所述的邻帧特征图相似度计算采用空间相关的方法,即将当前帧特征图上的各像素点与参考帧对应位置及其邻域的像素点都做一次相似度计算,得到的相似度矩阵上各点值为值为其中:邻域0≤i,j<k,邻域大小为(k,k),q
xy
为位于当前帧的特征图(x,y)上的向量,q
′
ij
为上一帧对应位置邻域上一点的向量,得到大小为(h,w,k2)的相似度矩阵。
23.所述的目标位置预测模块包括:热力图分支(heatmap)、中心偏移分支(centeroffset)和矩形框尺寸分支(boxsize),其中:热力图分支采用邻帧残差连接的手段融合时序信息生成当前帧的heatmap,预测特征图上存在目标的概率,物体中心值预期为1,周围的值随着与目标中心的距离递增呈指数衰减,将目标概率的极大值点所处位置作为目标的中心位置。中心偏移分支用于预测目标中心位置的偏移oi,弥补下采样时带来的量化误差,对在heatmap中预测的中心位置施加偏移得到最终的物体中心位置矩形框尺寸分支用于预测各个目标对应框的长宽si。
24.所述的邻帧残差连接是指:将邻帧相似度计算时得到的相似度矩阵送入可变形卷积中预测卷积时像素点的偏移,再将具有目标历史位置信息的参考帧的heatmap输入可变形卷积中预测邻帧残差,对当前帧的heatmap进行调整修正,得到更新后的heatmap,再根据heatmap得到目标的中心位置。
25.所述的可变形卷积是指卷积核在每一个元素上额外增加了一个参数方向参数的卷积,在卷积时可以根据视频目标的形状动态地调整卷积的范围。
26.所述的邻帧残差是指用于弥补因目标运动或遮挡造成的目标位置信息的丢失,用历史帧的位置信息对当前帧的位置信息进行增强。
27.对于目标位置预测模块得到的三组位置相关参数heatmap、center offset和box size,分别采用对应的损失函数进行监督训练。
28.所述的目标特征提取模块包括:特征提取分支(identity)和采样偏移分支(extract offset),其中:特征提取分支输出全局目标特征信息,在特征图上每个像素点上生成128维的特征向量f,代表该位置可能存在目标的特征。采样偏移分支在特征图上每个像素点上分别生成x,y方向上的偏移通过在目标位置预测模块预测出的目标中心位置施加该偏移,得到特征中心位置在该位置对全局目标特征信息进行采样,得到该目标的特征,最后采用特征正交化约束目标的特征信息。
29.优选地,本实施例通过特征互信息采样的方式得到偏移之后的坐标值,通过插值更为准确地得到特征信息,具体为:
30.①
设当前帧第i个目标的特征中心位置临近的四个整数坐标点分别是其特征向量分别为首先计算四个特征向量之间的互信息:
31.②
选取某一特征向量互信息之和作为该特征向量代表的特征与目标特征的相似程度,经过归一化后作为该特征向量的权重
32.③
通过重复步骤
①
和
②
提取出四点中共有的特征,而对于不相关的信息可以得到有效的抑制,则位于点q(x,y)的特征向量可以通过以下插值得到:
33.所述的特征正交化是指:对于采样后得到的第i个目标类别的特征向量fi,在训练时为每个目标类别用标准正态分布初始化一个特征向量作为第j类的类模板mj,将特征向量fi与类模板mj做内积并经过sigmoid函数,当两者特征越相近,得到的值越接近1,最终的目标特征损失为采用该损失函数对网络生成的目标特征进行监督训练,使得网络预测出的不同目标的特征具有正交性,更加有区分度。
34.所述的目标跟踪模块:对于初始帧,根据得到的位置和特征信息初始化为一系列轨迹。对于后续帧,根据目标的位置和特征信息将各个目标与历史轨迹匹配,更新当前帧的轨迹状态,创建新的轨迹或者删除消逝的轨迹。
35.经过具体实际实验,在基于pytorch的具体环境设置下,在mot17训练数据集上进行训练和测试,以30次训练迭代,采用adam优化器,其中前20次迭代学习率取10-4
,后10次迭代学习率衰减值10-5
,以mota为测试指标,mota表达式为其中fn是误判数,fp是漏检数,idsw是目标发生身份切换的数目,在mot17测试数据集上得到的结果如表1所示,相比基准指标提升了1.6%,误判数和漏检数都有了一定量的减少。
36.表1实验结果 fairmot本系统fn3792633267fp128958123579mota(%)69.671.2(+1.6)
37.综上,说明目标特征更具代表性,减少了其他不相干信息的混叠,其目标的特征信息得到了增强,对不同目标区分度更加明显,对同一目标匹配更为精准,表明目标特征时空对齐对提升视频跟踪的准确性有一定效果。
38.上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1